在 PyTorch 中搭建卷积神经网络(CNN),最常见的两种实现方式是常规逐层定义法 和 **nn.Sequential 堆叠法 **。本文将以 CIFAR10 分类任务的经典网络为例,详细讲解两种写法的实现、差异、优缺点及适用场景,附完整可运行代码与注释,方便直接复现与学习。
一、网络结构总览
本文实现的是一个 3 层卷积 + 池化 + 全连接的经典 CNN 结构,适配 CIFAR10 32×32 图像分类任务,图形、结构如下:
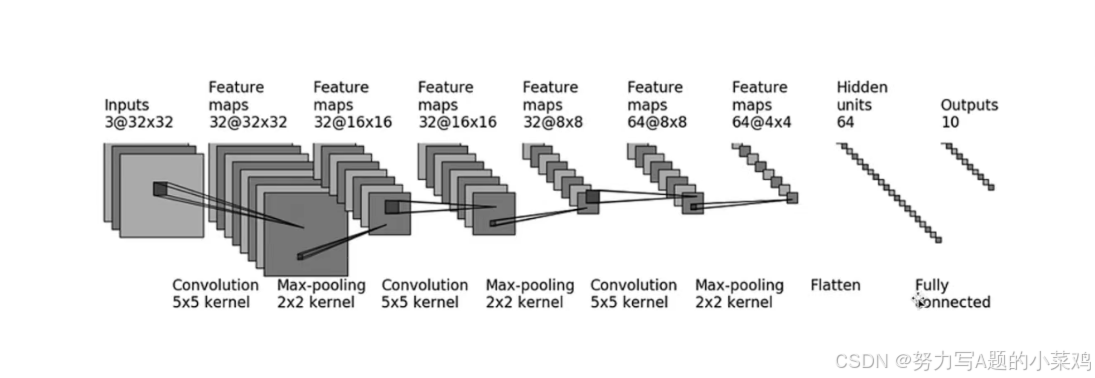
- 输入层:3 通道 32×32 图像(CIFAR10 标准格式)
- 卷积块 1 :Conv2d (3→32, 5×5, padding=2) → MaxPool2d (2×2),输出
32@16×16 - 卷积块 2 :Conv2d (32→32, 5×5, padding=2) → MaxPool2d (2×2),输出
32@8×8 - 卷积块 3 :Conv2d (32→64, 5×5, padding=2) → MaxPool2d (2×2),输出
64@4×4 - 展平层 :将
64@4×4特征图转为一维向量64×4×4=1024 - 全连接层:Linear (1024→64) → Linear (64→10),输出 10 类分类结果
二、方法一:常规逐层定义法
1. 完整代码(带详细注释)
python
运行
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
# 自定义卷积神经网络类,继承 nn.Module(所有 PyTorch 模型的基类)
class Tudui(nn.Module):
def __init__(self):
# 调用父类 nn.Module 的初始化方法,必须写,否则模型参数无法被正确注册
super(Tudui, self).__init__()
# -------------------------- 卷积+池化层定义 --------------------------
# 第1层卷积:输入通道3(RGB图像),输出通道32,卷积核5×5,padding=2(保持输入输出尺寸不变)
# 输入形状:[batch, 3, 32, 32] → 输出形状:[batch, 32, 32, 32]
self.conv1 = Conv2d(
in_channels=3,
out_channels=32,
kernel_size=5,
padding=2
)
# 第1层池化:2×2最大池化,步长默认2,特征图尺寸减半
# 输入形状:[batch, 32, 32, 32] → 输出形状:[batch, 32, 16, 16]
self.maxpool1 = MaxPool2d(kernel_size=2)
# 第2层卷积:输入通道32,输出通道32,卷积核5×5,padding=2
# 输入形状:[batch, 32, 16, 16] → 输出形状:[batch, 32, 16, 16]
self.conv2 = Conv2d(
in_channels=32,
out_channels=32,
kernel_size=5,
padding=2
)
# 第2层池化:2×2最大池化,尺寸减半
# 输入形状:[batch, 32, 16, 16] → 输出形状:[batch, 32, 8, 8]
self.maxpool2 = MaxPool2d(kernel_size=2)
# 第3层卷积:输入通道32,输出通道64,卷积核5×5,padding=2
# 输入形状:[batch, 32, 8, 8] → 输出形状:[batch, 64, 8, 8]
self.conv3 = Conv2d(
in_channels=32,
out_channels=64,
kernel_size=5,
padding=2
)
# 第3层池化:2×2最大池化,尺寸减半
# 输入形状:[batch, 64, 8, 8] → 输出形状:[batch, 64, 4, 4]
self.maxpool3 = MaxPool2d(kernel_size=2)
# -------------------------- 展平层+全连接层定义 --------------------------
# Flatten展平层:将 [batch, 64, 4, 4] 的特征图转为 [batch, 1024] 的一维向量
# 64×4×4=1024,是单张图片经过卷积池化后的特征总数
self.flatten = Flatten()
# 全连接层1:输入1024维,输出64维隐藏层特征
self.linear1 = Linear(in_features=1024, out_features=64)
# 全连接层2:输入64维,输出10维,对应CIFAR10的10个分类
self.linear2 = Linear(in_features=64, out_features=10)
# 前向传播方法:定义数据在网络中的流动路径,必须实现
def forward(self, x):
# 第1个卷积+池化块
x = self.conv1(x) # 卷积计算
x = self.maxpool1(x) # 池化下采样
# 第2个卷积+池化块
x = self.conv2(x)
x = self.maxpool2(x)
# 第3个卷积+池化块
x = self.conv3(x)
x = self.maxpool3(x)
# 展平特征图,转为一维向量
x = self.flatten(x)
# 全连接层计算,得到分类结果
x = self.linear1(x)
x = self.linear2(x)
return x
# -------------------------- 模型测试 --------------------------
if __name__ == "__main__":
# 实例化模型
model = Tudui()
print("模型结构:")
print(model)
# 模拟一批CIFAR10输入数据:batch_size=64,通道3,高宽32×32
input = torch.ones((64, 3, 32, 32))
# 前向传播,获取输出
output = model(input)
print("\n输入形状:", input.shape)
print("输出形状:", output.shape) # 输出应为 torch.Size([64, 10])2. 核心特点解析
- 逐层定义 :在
__init__中为每一层(卷积、池化、全连接)单独定义实例,每个层都有独立的变量名(如self.conv1、self.maxpool1)。 - 前向调用 :在
forward方法中,按数据流动顺序逐行调用各层,手动控制数据流向。 - 灵活性强 :可以在
forward中任意插入自定义操作,比如打印中间层形状、添加分支结构、条件判断等。
三、方法二:nn.Sequential 堆叠法
1. 完整代码(带详细注释)
python
运行
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
# 自定义卷积神经网络类,继承 nn.Module
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# 使用 nn.Sequential 按顺序堆叠所有层,一次性定义整个网络结构
# Sequential 会自动按列表顺序执行层,无需在 forward 中逐行调用
self.model = Sequential(
# -------------------------- 卷积+池化块 --------------------------
# 第1个卷积+池化块:Conv2d → MaxPool2d
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
# 第2个卷积+池化块:Conv2d → MaxPool2d
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
# 第3个卷积+池化块:Conv2d → MaxPool2d
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
# -------------------------- 展平层+全连接层 --------------------------
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
# 前向传播方法:直接将数据喂给 Sequential 实例,一行代码完成所有计算
def forward(self, x):
x = self.model(x)
return x
# -------------------------- 模型测试 --------------------------
if __name__ == "__main__":
# 实例化模型
model = Tudui()
print("模型结构:")
print(model)
# 模拟一批CIFAR10输入数据
input = torch.ones((64, 3, 32, 32))
# 前向传播,获取输出
output = model(input)
print("\n输入形状:", input.shape)
print("输出形状:", output.shape) # 输出应为 torch.Size([64, 10])2. 核心特点解析
- 一次性堆叠 :在
__init__中使用nn.Sequential,将所有层按数据流动顺序放入列表,一次性完成网络定义。 - 极简前向 :
forward方法只需一行代码x = self.model(x),无需手动调用每一层。 - 线性执行 :层的执行顺序完全由
Sequential中的列表顺序决定,无法插入分支或自定义操作,适合线性结构的网络。
四、两种方法对比总结
表格
| 对比维度 | 常规逐层定义法 | nn.Sequential 堆叠法 |
|---|---|---|
| 代码结构 | 层定义分散,forward 逐行调用,代码行数多 |
层定义集中在 Sequential 中,forward 极简,代码更紧凑 |
| 灵活性 | 极高,支持自定义操作、分支结构、条件判断、中间层调试 | 较低,仅支持线性堆叠,无法插入额外逻辑 |
| 可读性 | 对新手友好,每一层的调用顺序清晰可见 | 结构一目了然,适合快速搭建简单网络 |
| 调试难度 | 调试方便,可在 forward 中任意位置打印中间层输出 |
调试不便,需拆分 Sequential 或手动获取中间层输出 |
| 适用场景 | 复杂网络、多分支结构、需要调试中间层的场景 | 简单线性网络、快速搭建原型、结构固定的场景 |
五、关键注意事项
- 效果完全等价:两种写法实现的网络结构、计算流程、参数数量完全一致,训练效果无差异,只是代码组织方式不同。
Sequential线性执行:层的执行顺序严格按照列表顺序,无法调整或分支,因此不适合 ResNet 等带残差连接的复杂网络。- 中间层调试 :如果需要查看中间层输出形状,常规写法更方便;使用
Sequential时,可通过拆分多个Sequential或手动获取中间层输出实现。 - 推荐使用场景 :简单 CNN 优先使用
nn.Sequential简化代码;复杂多分支网络优先使用常规写法保证灵活性。
六、运行结果说明
两种写法运行后,模型输出形状均为 torch.Size([64, 10]),表示:
- 批次大小 64:一批处理 64 张图片
- 输出维度 10:对应 CIFAR10 的 10 个分类结果
你可以基于这两种写法,为网络添加 nn.ReLU 激活函数、nn.Dropout 层,或调整卷积核数量、池化方式,进一步优化模型性能。