六月初,AI 圈被一句话点燃了
2026 年 6 月 7 日,OpenClaw 作者 Peter Steinberger 在 X 上发了一条帖子:
You shouldn't be prompting coding agents anymore. You should be designing loops that prompt your agents.
(你不该再亲自 Prompt 编码 Agent 了。你应该设计一套 Loop,由它去 Prompt Agent。)
短短一句话,浏览量迅速突破到了 820万 。Tech Twitter 上,有人把它称为「六月最短的争议句」------支持和质疑的帖子刷了一屏又一屏。Firecrawl 的博客写得很直白:A six-word sentence has tech Twitter in a chokehold this month.
争议还没降温,Google 工程师 Addy Osmani 第二天就发表了长文 Loop Engineering,把这个正在发酵的概念正式命名、拆解成可落地的框架。
随后一周里,MindStudio、AlphaMatch、Firecrawl 等团队相继发文解读------一个新术语,几乎在一夜之间从「大佬语录」变成了「2026 年 AI 编程的方法论」。
而 Steinberger 那句话,并非空穴来风。
早在这之前的 6 月 2 日,Anthropic Claude Code 负责人 Boris Cherny 在 WorkOS 的 Unplugged 活动上说了几乎一模一样的话------这段发言随后被剪成短视频,在 X 上广泛传播:
I don't prompt Claude anymore. I have loops that are running. They're the ones that are prompting Claude and figuring out what to do. My job is to write loops.
(我已经不再 Prompt Claude 了。我有一些 Loop 在跑,它们负责 Prompt Claude、决定下一步该做什么。我的工作,是写这些 Loop。)

到 2026 年 3 月,Claude Code 项目本身已 100% 由 Claude Code 自主维护 。据他披露,当时已有约 4% 的公开 GitHub commit 来自 Claude Code。这样的工作流,从「手写代码」→「Prompt Agent 写代码」→「写 Loop 让 Agent 自己 Prompt 自己」------三次抽象层级跃迁,全部发生在不到一年的时间里。
Osmani 在博客里引用了上述两位的话,并给出了自己的定义:
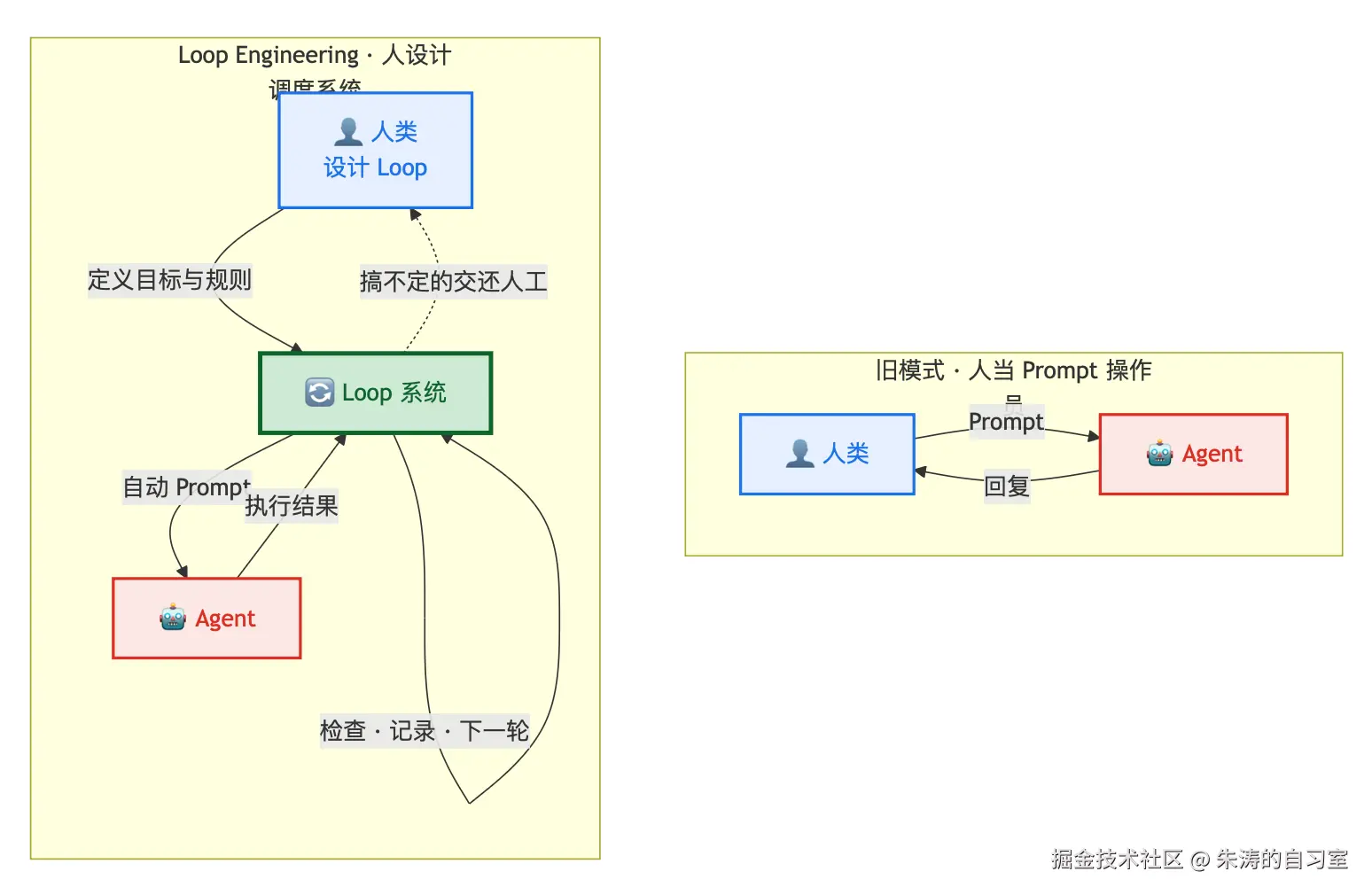
Loop Engineering = 用系统设计,替代你本人充当 Agent 的 Prompt 操作员。
Loop 是一个递归目标:你定义目的和停止条件,系统自动迭代,直到完成为止。你设计的是「发现工作 → 分发 → 执行 → 检查 → 记录 → 决定下一轮」------而不是坐在 Chat 窗口里,一个 turn 接一个 turn 地打字。
Cherny 说得很清楚:工作并没有变轻松,变的是杠杆点。
过去比的是谁 Prompt 写得好;现在比的是谁 Loop 设计得巧。Osmani 也提醒:这还早,Token 成本可以差几个数量级,Verification 比以往任何时候都更依赖工程师本人------但 Codex 的 Automations、/goal,Claude Code 的 /loop、hooks、Sub-agents,骨架已经长进产品里了。
一旦看清这个形状,争论该用哪个工具反而次要;关键是你的 Loop 能不能转起来。
什么是 Loop Engineering?
如果你刚在社区里刷过 Harness Engineering------给 Agent 搭环境、定规矩、建反馈------先别慌:很多团队还没完全吃透,Loop 的概念又火了。
Osmani 有个比喻很贴切:Harness 是跑道;Loop 是跑道上的调度系统。 前者管单个 Agent 怎么安全地跑;后者管谁去找活、谁去干、谁去验收、什么条件下收工。
Osmani 把一套能转起来的 Loop 拆成五块积木,加一块外部记忆。不必记工具名,先理解分工。
Automations------Loop 的心跳。 没有定时触发,Loop 就只是你手动跑过一次的脚本。Automations 负责按节奏自动发现工作:CI 昨晚红了、Issue 堆了、某个模块上周刚改过。Codex 有 Automations 面板,Claude Code 有 /loop 和 cron;本质一样------让 Loop 自己去找活干,而不是你每天早上打开 IDE 想「今天让 Agent 干啥」。
Worktrees------并行时不踩脚。 两个 Agent 同时改同一个文件,和两个人没沟通就 commit 同一行一样麻烦。Git worktree 给每个任务独立的 checkout 和分支;Codex 内置了 per-thread worktree,Claude Code 也支持 --worktree 和 subagent 级隔离。并行是 Loop 的乘数,worktree 是并行的前提。
Skills------项目知识外置。 Agent 每次 Session 都是冷启动,Context 里的空洞会被它用自信的错误填满。Skill(SKILL.md)把约定、构建步骤、踩坑记录写进磁盘,Loop 每一轮都能读到。Intent 写一次,Loop 每一轮复用,而不是反复从头解释项目。
Connectors------Loop 碰到真实世界。 只会读文件系统的 Loop 很小。MCP 和各类 Connector 让 Loop 能查 Issue、读 CI 日志、发 Slack、调 staging API。差一步开 PR、差一步更新 ticket,Loop 就还是半成品。
Sub-agents------写的人不要自己判卷。 让同一个模型写完代码再宣布「没问题」,它几乎一定会偏袒自己。Loop 里常见的拆法是:一个 Agent 探索、一个实现、一个审查。Claude Code 的 Task subagents、Codex 的 .codex/agents/ 都是这个思路。Maker 和 Checker 分离,是 Loop 无人值守时还能信得过结果的前提。
State / Memory------Agent 会忘,磁盘不会。 进度、试过的方案、哪些过了哪些没过,必须落在外部------Markdown 文件、Linear board、AGENTS.md,任何形式都行。模型跨 Session 失忆;Loop 能接力,靠的是 State,不是聊天记录。
拼起来:一个晨间 Triage(分拣) Loop
Osmani 给了一个很具体的例子。
每天早上,Automation 自动跑一轮:读昨天的 CI 失败、新开的 Issue、近期 commit,把值得处理的事项分拣出来。
每一项开独立 worktree,Sub-agent A 起草修复,Sub-agent B 对照 Skill 和现有测试做审查。
Connector 负责开 PR、更新 ticket。Loop 处理不了的,进 Triage inbox 等人看。
State 文件记下「试过什么、过了什么、还剩什么」------明天 Automation 醒来,从同一页接着干。
到这一步,Loop 已经能发现工作、写代码、审代码、开 PR、记状态。
听起来闭环了。
但仔细想一个问题:它怎么知道「做完了」?
Loop 的「完成条件」,通常停在哪里
Codex 和 Claude Code 里的 /goal,是最接近「Loop 自己收工」的机制:写一条机器能检查的停止条件,Loop 一轮轮跑,直到成立------常见是 lint 干净、单测全绿、类型检查通过,Sub-agent 再补一层 diff 审查。
对后端、CLI、纯库,这往往够用。
但对 App、Web、跨端 UI,「命令 exit 0」不等于「产品没问题」:界面对不对、真机能不能跑、流程通不通,都不在源码和终端日志里。 于是多数 Coding Loop 实际停在代码可合并;验产品这一步,还是人编译、安装、点点点。
Loop 名义上在转,验证这条支路往往仍是开环的。
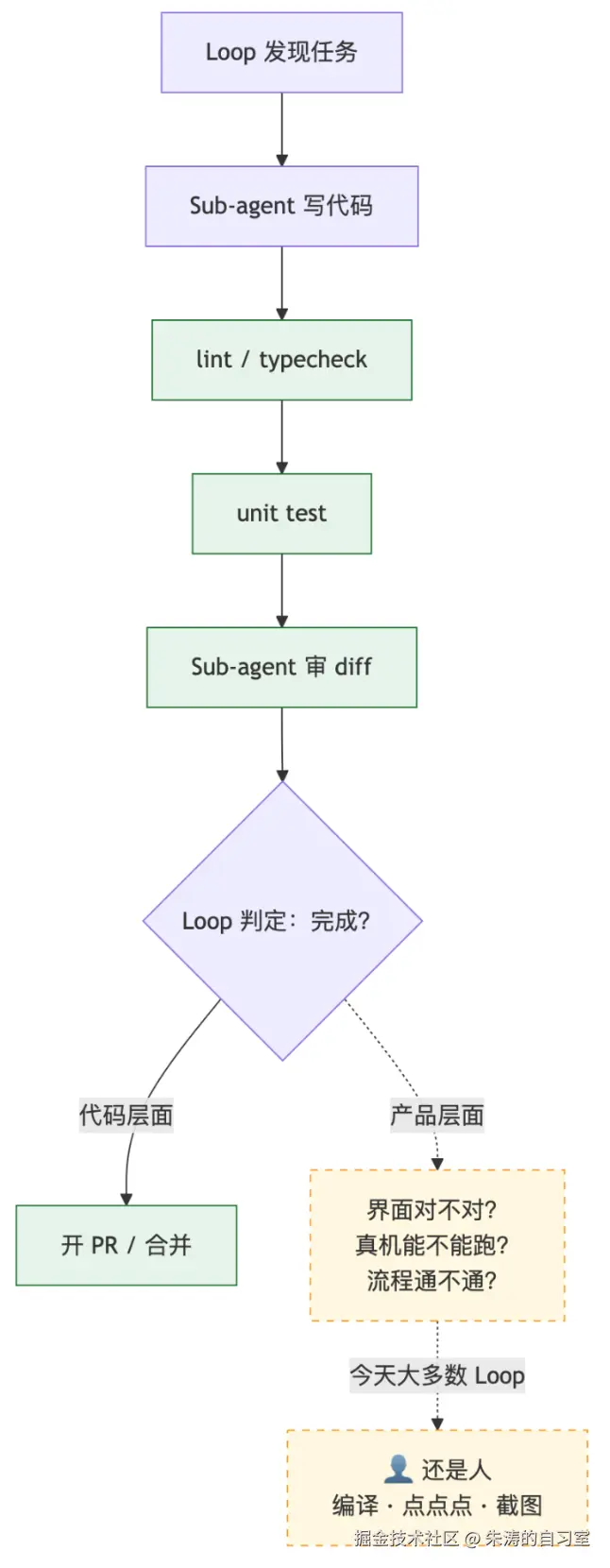
产品验没验过,谁来干? 做 App、做 Web 的团队,会先撞上这个问题。
Coding Agent 看不见屏幕
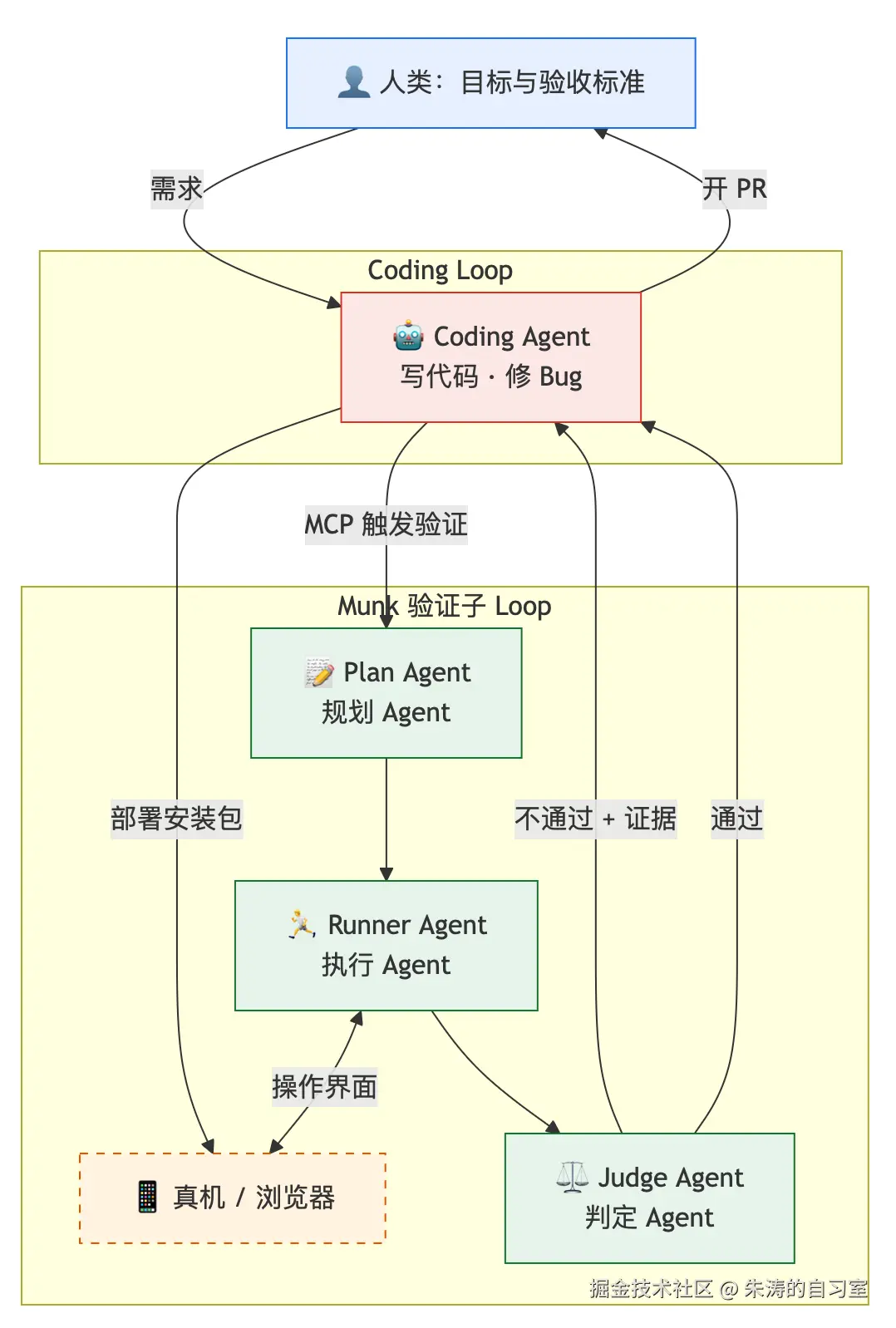
团队通常会试三条路,但都很难形成 验证子 Loop------Coding Agent 旁边那条能自己转、能判定、能把证据送回去的自动化支路:
-
人肉测试。代码 Loop 转得飞起,产品还是你挨个验。人不是 Connector,没法被/goal调度,瓶颈只是从 Prompt 挪到了点屏幕。 -
让 Coding Agent 写 Playwright、XPath。脚本能进 CI,但 UI 一改就挂,维护成本不低。更致命的是:写测试和判测试往往是同一个 Agent------前面强调「写的人不要自己判卷」,这里恰恰是自己考自己,进了 CI 也不等于 Loop 可信。 -
上云端视觉大模型逐帧看。理论上说得通,一次完整回归的截图量,就足以让 Token 账单在 Loop 转完之前叫停------验证太贵,Loop 转不起,又回到 Cherny 那条规律。
三条路要么把你嵌回 Loop,要么让 Agent 同源判卷,要么贵到无法日常运转。
我们缺的不是一个简单的测试框架,而是验证子 Loop。 它至少要具备三件事------也就是前面讲的 Connector、Sub-agents、State,在「验产品」时各自该干什么:
- Connector------连得上真机/浏览器,验完自动把结果送回 Coding Agent,不用人截图粘贴
- Sub-agents------点的和判的不是同一个 Agent,不能自己说自己过了
- State------验过什么、哪一步挂了,写进文件;别只留在聊天记录里
换句话说,要实现 AI 研发的 Loop 闭环,就必须让 AI 实现 E2E 测试。这一点在移动端领域尤为重要。
这也是我做 Munk AI 这个开源项目的原因。
拼起来:一条带「验产品」的功能交付 Loop
我从在几个月前开始做 Munk AI ,它的功能很简单,那就是:让 AI 控制 Android iOS,去做真机 E2E 测试。
它能接到 Cursor、Claude Code、Trae 的日常开发流程,跑在你本机。
还是用一个例子------开发「删除账号」功能,lint、单测、真机验证都过,才开 PR。
你先用自然语言把需求说清楚,比如:「用户可以在设置页删除账号,确认后回到登录页,再次登录时旧数据不可见。」Coding Agent 据此写代码,把 App 装到手机或浏览器上------这一步和平时一样。接下来交给 Munk。它先看需求,再看代码 Diff 摘要,再在设备上按用户路径操作一遍:设置 → 账号 → 删除 → 确认。然后将操作记录交给另一个 Agent 来判定:测试是否通过。第一次可能过不了。比如确认弹窗被键盘挡住,点不到「确认」。这时候,判定的 Agent 不会只丢一句「失败了」:它把卡在哪一步、当时屏幕长什么样打包送回 Coding Agent。Agent 改代码、重新安装,自动接着验------条件没满足,就不停。第二次通过了,Coding Agent 再去开 PR。
整条链路就是:你说清要什么 → 系统自动跑 → 搞不定的带着证据回来 → 下一轮接着干。 差别在于,收工条件里多了一条------产品在真机上真的验过了。
写在最后
不管是 Harness Engineering 还是 Loop Engineering,它们最终的目标,都是为了:
- 让 AI 工作表现更
稳定; - 让 AI 工作时间更
持久; - 让 AI 工作能更
自主;
Munk AI 的目标,就是:打通移动端 AI 真机测试,这条链路。
Loop Engineering 要在移动端更稳的落地,就离不开 AI 真机测试。
Munk AI 是我们做「移动端 AI 测试」这条支路的开源尝试,还在早期。
如果你也在用 AI 写代码、苦于总要自己点点点,欢迎一起来试:
- 👀 安装体验、文档与更新 :munk.sh
- ⭐ Star 开源仓库 :github.com/chaxiu/munk...
- 🐦 关注 X / Twitter,看后续实践与更新 :x.com/iBoyCoder
- 📮 关注公众号「朱涛的自习室」:Loop Engineering、AI 测试与 Munk 的落地笔记会陆续更新 · *