前言
先问你一个问题。
你刷朋友圈,下拉刷新------你看到的动态,是怎么到你手机上的?
如果你的答案是"后台查数据库,SELECT * FROM feed ORDER BY create_time DESC"------那再问一个。
你关注的某个用户有 100 个粉丝。他发了一条动态。这 100 个粉丝同时下拉刷新------数据库要执行 100 次 SELECT,每次都扫描全表、做多表 JOIN、按时间排序。100 个人没问题。10 万人呢?100 万人呢?
这两个问题,就是 Feed 流系统的核心难点。不是"能不能查出数据",而是写的时候多做一点,还是读的时候多做一点------这笔账怎么算。
这篇文章,我把 O2O 平台(Online to Offline,线上到线下本地服务平台)里 Feed 流推送 + 附近商户检索的完整设计拆开,从推模式的 ZSET(Redis 有序集合,按 score 自动排序)收件箱、时间游标分页,到大 V 场景的推拉结合冷热分离,再到 Redis GEO 的 GeoHash 底层原理------每一层都有代码,每一个设计决策都有"为什么"。
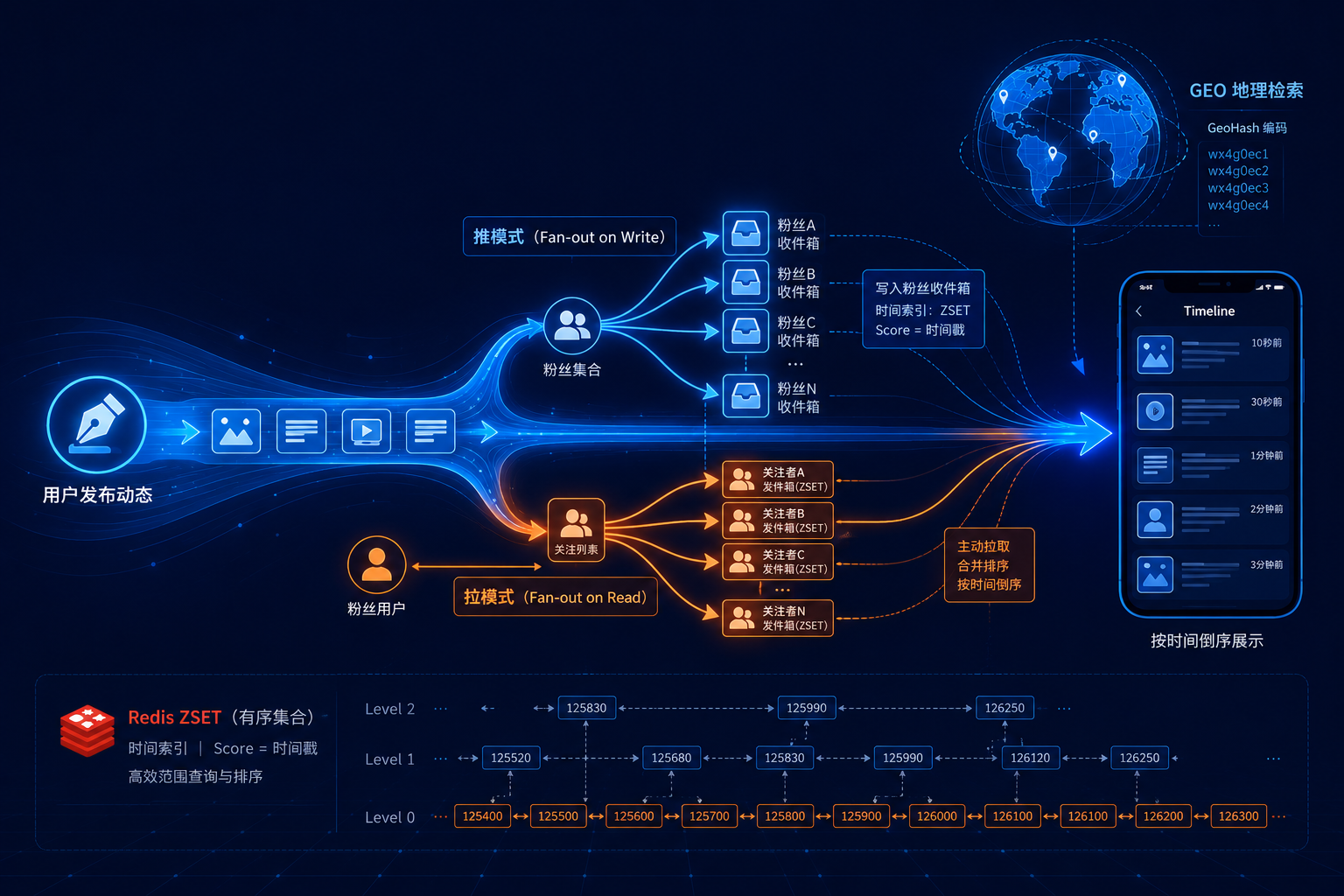
一、Feed 流到底难在哪?
先画边界。Feed 流不是"查数据排序"五个字能概括的------本质上是一个读写扩散的权衡问题:
┌─ 写扩散 ──────── 发一条动态要写 N 个收件箱
│
用户发动态 ──→ Feed 系统 ─┼─ 读扩散 ──────── 刷一次 Timeline 要查 M 个发件箱
│
├─ 翻页重复 ────── 传统 offset 对新数据不免疫
│
├─ 存储膨胀 ────── 收件箱无限增长,Redis 内存撑爆
│
└─ 大 V 困境 ────── 粉丝过亿,推模式写扩散是灾难五个问题,本质上只围绕一个核心决策:推模式还是拉模式。这个决策影响后面所有的架构设计。
推模式(Push / Fan-out on Write)
用户发动态时,把这条动态 ID 主动写入所有粉丝的 Redis ZSET 收件箱。粉丝读 Timeline 时,直接从自己的收件箱按时间倒序拉取------读操作极快,O(logN+M)(对数级复杂度,数据量翻倍,查询步数只加一步)。
代价是写扩散:发 1 条动态,要写 N 次(N = 粉丝数)。
拉模式(Pull / Fan-out on Read)
用户发动态时只写一条到自己发件箱。粉丝读 Timeline 时,实时查询所有关注人的发件箱,按时间合并排序------写操作极轻,O(1)。
代价是读扩散:刷 1 次 Timeline,要查 M 个发件箱(M = 关注数),再合并排序。
选型的本质
推模式 拉模式
写扩散 / 读轻 写轻 / 读扩散
发动态成本 O(N),N=粉丝数 O(1)
读Timeline成本 O(logN+M),读自己收件箱 O(M*logK),查M个发件箱再合并
适用场景 读多写少,粉丝量可控 读少写多,存在大V
典型产品 微信朋友圈 微博(大V用拉模式)我的项目是校园 O2O 平台------用户量千级,大 V 粉丝最多几百人,用户每天刷 Timeline 的频率远高于发动态的频率。读多写少 + 粉丝量小 → 推模式。
下面逐层拆解。
二、核心设计:推模式 + ZSET 收件箱
2.1 为什么是 ZSET?
收件箱的核心需求只有一个:按时间倒序取最新 N 条。
ZSET(Redis 有序集合,底层是跳表)天然满足------member(成员,相当于"学号")存动态 ID,score(分值,相当于"总分")存发布时间戳。ZREVRANGEBYSCORE(按 score 范围倒序取元素)按时间倒序取,时间复杂度 O(logN+M)。不需要去 MySQL 做 ORDER BY create_time DESC 的全表扫描。
2.2 发布动态(写扩散)
java
// hm-dianping/src/main/java/com/hmdp/service/impl/BlogServiceImpl.java
@Service
public class BlogServiceImpl implements IBlogService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private BlogMapper blogMapper;
@Autowired
private FollowService followService;
// ========== 发布动态(写扩散 - Fan-out on Write) ==========
@Transactional
public void publishBlog(Blog blog) {
// 1. 保存博文到 MySQL(持久化,正文存储)
blogMapper.insert(blog);
// 2. 查询所有粉丝 ID
List<Long> followerIds = followService.getFollowerIds(blog.getUserId());
// 3. 推送到每个粉丝的收件箱(ZSET)
// member = 博文ID
// score = 发布时间戳(毫秒)
long score = System.currentTimeMillis();
for (Long followerId : followerIds) {
String inboxKey = "feed:inbox:" + followerId;
redisTemplate.opsForZSet().add(inboxKey, blog.getId().toString(), score);
// 收件箱容量限制:保留 score 最高的 1000 条
redisTemplate.opsForZSet()
.removeRange(inboxKey, 0, -1001);
}
}
}关键细节:
- 博文正文存 MySQL,收件箱只存 ID 。ZSET 里只有 Long 型 ID + Long 型时间戳,一条记录约 100 字节;正文放 MySQL 用
selectBatchIds批量查 - ZREMRANGEBYRANK(按排名删除元素)在 ZADD(向 ZSET 添加元素)之后执行。每次写入后裁剪超出的旧数据,保证收件箱永不超过 1000 条
-1001的语义 :ZRANGE(按排名范围取元素)按 score 升序排列,removeRange(inboxKey, 0, -1001)删除排名从 0 到倒数第 1001 的全部元素------保留 score 最高的 1000 条,删除旧的
2.3 读取 Timeline(时间游标分页)
java
// ========== 读取 Timeline(时间游标分页) ==========
public List<Blog> getTimeline(Long userId, Long cursor, int size) {
String inboxKey = "feed:inbox:" + userId;
// 游标分页:按 score 范围查询,替代传统 offset
// cursor = 上一次返回的最后一条的 score(时间戳)
// 查询 score 在 [0, cursor) 区间内的前 size 条
Set<ZSetOperations.TypedTuple<String>> tuples = redisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(
inboxKey,
0, // min score(0 = 最早的时间戳)
cursor - 1, // max score(cursor 的上一条,不包含 cursor 本身)
0, // offset(从 score 范围内匹配的第一条开始)
size // 取多少条
);
if (tuples == null || tuples.isEmpty()) {
return List.of();
}
// 提取博文 ID 列表
List<Long> blogIds = tuples.stream()
.map(t -> Long.valueOf(t.getValue()))
.toList();
// 批量查 MySQL 获取博文详情(正文、点赞数、评论数等)
List<Blog> blogs = blogMapper.selectBatchIds(blogIds);
// 按收件箱顺序重新排序(MySQL IN 查询不保证顺序)
Map<Long, Blog> blogMap = blogs.stream()
.collect(Collectors.toMap(Blog::getId, b -> b));
return blogIds.stream()
.map(blogMap::get)
.filter(Objects::nonNull)
.toList();
}
}关键细节:
- cursor 初始值 :第一页传
System.currentTimeMillis()(当前时间戳),表示"从现在开始往前翻" - cursor 更新:每次返回的最后一条的 score 作为下一次请求的 cursor
cursor - 1:减 1 是为了不包含上一次的最后一条,防止重复(因为reverseRangeByScoreWithScores的 max 是 inclusive 的)- MySQL 查回后重新排序 :
selectBatchIds底层是WHERE id IN (...),MySQL 不保证返回顺序与 IN 列表一致,必须按收件箱的原顺序重新排列
✅ 推模式 + ZSET 方案解决了:读 Timeline 的延迟问题------粉丝直接从自己的收件箱取,O(logN+M) 毫秒级返回,不依赖数据库 JOIN 和排序;写扩散的代价在粉丝量千级的校园场景完全可接受
❌ 但还需要解决:翻页重复(offset 对新数据不免疫)→ 下一章的时间游标分页;收件箱无限膨胀 → 第四章的容量上限;大 V 写扩散爆炸 → 第五章的推拉结合
三、时间游标分页:为什么不用 offset?
3.1 offset 分页的致命缺陷
传统分页用 SQL 的 LIMIT + OFFSET:
sql
-- 第一页
SELECT * FROM feed WHERE user_id = 1 ORDER BY create_time DESC LIMIT 10 OFFSET 0;
-- 第二页
SELECT * FROM feed WHERE user_id = 1 ORDER BY create_time DESC LIMIT 10 OFFSET 10;问题不在于 SQL------在于两次查询之间,数据变了。
第一页请求 → 返回动态 #100 ~ #91(最新的 10 条)
↓
用户 A 发了一条新动态 #101(插入到最前面)
↓
第二页请求 → OFFSET 10 → 跳过 #100 ~ #91?
不------#101 插到最前面,原来的 #100 变成了第 2 条,#91 变成了第 11 条
→ 用户第二页看到的是 #91 ~ #82
→ #91 重复了!(第一页最后一条 = 第二页第一条)Redis ZSET 的 ZREVRANGE 也有同样的问题------两次 ZREVRANGE key start stop 调用之间,新写入的 score 会改变整个排序。
3.2 时间游标如何解决
核心思路:不用"跳过前 N 条",而是用"score 小于某个值的后 N 条"。
java
// 第一页:cursor = 当前时间戳
reverseRangeByScoreWithScores("feed:inbox:" + userId,
0, // 最小 score(0 = 最早)
cursor - 1, // 最大 score(当前时间 - 1)
0, // 从这个 score 范围内的第一条开始
10); // 取 10 条
// 假如返回的最后一条 score = 1718352000000
// 第二页:cursor = 1718352000000
reverseRangeByScoreWithScores("feed:inbox:" + userId,
0, // 最小 score
cursor - 1, // 最大 score = 1718351999999
0,
10);本质区别:
offset 分页: 游标分页:
"给我第 21~30 条" "给我 score < X 的最近 10 条"
↓ ↓
依赖"第几条"这个绝对位置 依赖"score 值"这个相对位置
↓ ↓
新数据插入 → 绝对位置漂移 新数据 score > X → 不在查询范围内
→ 翻页重复/遗漏 → 对增量数据天然免疫3.3 游标分页的两个限制
① 不能跳页。 用户不能直接跳到第 5 页------只能一页一页往下翻。但对于 Feed 流,没人会跳到第 50 页看一周前的动态,这个限制可以接受。
② score 碰撞。 两条动态同一毫秒发布怎么办?简单方案:score = timestamp * 1000 + (blogId % 1000),用博文 ID 的后几位打破碰撞。
🔑 小鱼点睛
面试官问"游标分页能不能跳页"是在考你对这个方案局限性的理解------不回避短板,而是讲清楚为什么这个短板在你的场景里可以接受,这才是合格的架构回答。同时可以提一句:如果产品真的需要跳页(比如微博的"跳到指定日期"),可以改用"时间戳游标 + 日期索引"的混合方案------先定位到日期,再在该日期内用游标翻页。
四、ZSET 收件箱容量:会不会无限增长?
4.1 容量上限 + 淘汰策略
每个用户的收件箱 feed:inbox:{userId} 是一个 ZSET。不设上限的话,用户量上来后 Redis 内存会无限膨胀。
我的方案:每用户最多 1000 条。
java
// 每次写入后立即裁剪
redisTemplate.opsForZSet().add(inboxKey, blogId, score);
redisTemplate.opsForZSet().removeRange(inboxKey, 0, -1001);
// ↑ ↑
// rank 0 rank=倒数第1001
// 删除最旧的 保留最新的1000条4.2 内存估算
每条记录 ≈ 100 字节 (member 8B + score 8B + ZSET 内部跳表开销 ~84B;跳表 = Skip List,一种多层链表结构,查找时像坐电梯一样跳过不必要的楼层,因此效率为 O(logN))
1000 条 × 100B = 100KB / 用户
10 万用户 ≈ 10GB(Redis 可承受)实际上,大量用户不活跃,收件箱是空的或只有几十条------实际占用远小于理论最大值。
4.3 面试官的追问:用户量到了一千万怎么办?
10GB × 100 = 1TB,单机 Redis 扛不住。此时两个手段:
① Redis Cluster(集群)分片。 按 userId hash(哈希,一种将任意数据映射到固定范围数字的算法)分布收件箱,每个分片独立承担一部分用户:
hash(userId) % 分片数 → 定位到具体 Redis 节点
feed:inbox:{userId} 只存在一个节点上② 冷热分离。 30 天未登录的用户清空收件箱,登录时用拉模式冷启动(冷启动 = 用户登录时才临时聚合 Timeline,而不是一直维护着收件箱):
java
// 用户登录时
if (user.getLastLoginTime().before(thirtyDaysAgo)) {
// 清空收件箱(太久没登录,里面全是过期数据)
redisTemplate.delete("feed:inbox:" + userId);
// 拉模式冷启动:实时聚合所有关注人的最新动态
List<Blog> coldStart = pullModeGetTimeline(userId);
// 重建收件箱(预热)
rebuildInbox(userId, coldStart);
}✅ 容量上限防住了:单用户内存上限可控 → 可以线性推算集群总容量
❌ 但防不住:突发热点------某个大 V 一夜爆火,粉丝从 500 涨到 50 万,推模式写扩散瞬间爆炸。这就是下一节要解决的问题。
五、大 V 场景:推拉结合(冷热分离)
5.1 推模式的致命弱点(阿克琉斯之踵)
推模式有一个前提假设------每个用户的粉丝量不大。这个假设在校园 O2O 平台成立(用户量千级,粉丝最多几百人),但一旦出现大 V(粉丝百万级),推模式写扩散的代价是灾难性的:
普通用户发动态:ZADD 500 次 → 500 个粉丝收件箱,瞬间完成
大 V 发动态: ZADD 500 万次 → 500 万次网络 IO,Redis 主线程阻塞这就是微博/推特早期踩过的坑------纯推模式在大 V 面前直接崩溃。
5.2 推拉结合的方案
不是我发明------这是微博/推特的经典架构,核心思路:按用户类型做路由。
| 用户类型 | 判定标准 | 动态分发方式 |
|---|---|---|
| 普通用户 | 粉丝 < 1万 | 推模式:发动态 → 写入所有粉丝收件箱 |
| 大 V | 粉丝 ≥ 1万 | 拉模式:发动态 → 只写自己的发件箱,不扩散 |
| 活跃用户 | 近 7 天登录 | 收件箱里包含:普通关注者的推内容 + 关注大 V 的拉内容(聚合) |
| 非活跃用户 | 近 30 天未登录 | 不维护收件箱,登录时临时聚合 → 重建收件箱 |
5.3 聚合逻辑实现
java
/**
* 推拉结合模式下的 Timeline 读取。
* 普通用户的内容在收件箱里(推),大 V 的内容需要实时拉取。
*/
public List<Blog> getTimelineMixed(Long userId, Long cursor, int size) {
// 1. 从自己的收件箱取(普通用户的推内容)
Set<ZSetOperations.TypedTuple<String>> inbox = redisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(
"feed:inbox:" + userId,
0, cursor - 1, 0, size
);
// 2. 查询自己关注的大 V 列表
List<Long> bigVIds = bigVService.getFollowedBigVs(userId);
if (bigVIds.isEmpty()) {
// 没有关注大 V → 纯推模式,直接返回收件箱内容
return fetchBlogsFromTuples(inbox);
}
// 3. 并发从大 V 的发件箱拉取最新动态
List<CompletableFuture<List<ZSetOperations.TypedTuple<String>>>> futures = bigVIds.stream()
.map(uid -> CompletableFuture.supplyAsync(() ->
redisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(
"feed:outbox:" + uid,
0, cursor - 1, 0, size / 2
)
))
.toList();
// 4. 合并所有来源,按 score 降序排序
List<ZSetOperations.TypedTuple<String>> allTuples = new ArrayList<>();
if (inbox != null) allTuples.addAll(inbox);
for (CompletableFuture<List<ZSetOperations.TypedTuple<String>>> future : futures) {
try {
List<ZSetOperations.TypedTuple<String>> result = future.get(200, TimeUnit.MILLISECONDS);
if (result != null) allTuples.addAll(result);
} catch (TimeoutException e) {
// 大 V 发件箱查询超时 → 降级,跳过这个大 V
log.warn("大V发件箱查询超时,降级跳过 uid={}", uid);
}
}
// 按 score 降序排序,取前 size 条
allTuples.sort((a, b) -> Double.compare(b.getScore(), a.getScore()));
List<ZSetOperations.TypedTuple<String>> topTuples = allTuples.stream()
.limit(size).toList();
return fetchBlogsFromTuples(topTuples);
}关键设计:
- 并发拉取 :大 V 的发件箱查询用
CompletableFuture(Java 异步编程工具------把多个任务同时扔出去执行,最后一起收结果,不用一个一个排队等)并发执行,不串行等待 - 超时降级:单个大 V 查询超时 200ms 则跳过,不阻塞整体返回
- size/2 策略:每个大 V 只取半页,因为最终还要合并,取太多浪费
5.4 更进一步:Timeline 温缓存
在推和拉之间加一层"温缓存"(介于热数据 Redis 和冷数据 MySQL 之间的中间层------有 TTL 的短期缓存,比 Redis 永久数据"凉"一点,比 MySQL"热"一点,所以叫"温")------给大 V 粉丝预聚合好的 Timeline,TTL(Time To Live,缓存过期时间)很短(1-2 分钟):
大 V 发动态 → 只写自己的发件箱(O(1))
↓
粉丝读 Timeline → 查 Timeline 缓存
↓ 命中 → 直接返回(O(1))
↓ 未命中 → 聚合所有关注者的发件箱 → 写入缓存(TTL 1min) → 返回这样,即使是大 V 粉丝的 Timeline 读取,大部分请求也命中缓存------只要缓存 TTL 足够短,用户感知不到延迟。
🔑 小鱼点睛
面试官问"大 V 怎么办"不是在期待你推翻推模式------而是在考你"能不能看到问题的边界,并给出合理的权衡"。推拉结合就是业界标准答案------它承认推模式的天花板,同时给出了平滑过渡的方案。如果面试官继续追问"百万大 V 发一条动态,推拉结合里拉模式要查百万粉丝的关注列表",你的回应是:实际上不需要------大 V 的粉丝读 Timeline 时,是从自己的关注列表里查到大 V,再去大 V 发件箱拉取。这是 O(粉丝关注数) 的复杂度,不是 O(大V粉丝数)。
六、附近商户检索:Redis GEO 实战
6.1 为什么不用 MySQL 空间函数?
MySQL 8.0 有 ST_Distance_Sphere,但有两个问题:
sql
-- MySQL 方式:计算每个商户到用户位置的距离,排序取最近 20 个
SELECT *, ST_Distance_Sphere(POINT(115.85, 28.68), POINT(lng, lat)) AS distance
FROM shop
ORDER BY distance
LIMIT 20;- 全表扫描:即使建了空间索引 SPATIAL INDEX(专门加速地理位置查询的索引类型,MySQL 用 R 树实现),对于"附近商户"这种 OLTP(Online Transaction Processing,在线事务处理------用户实时操作型业务)高频查询,毫秒级延迟很难保证
- 磁盘 IO:MySQL 的数据在磁盘上(B+树------一种多叉平衡树,叶子节点存数据页,适合磁盘按块读取),Redis 的数据在内存里(跳表),本质差距
Redis GEO 在内存中基于 ZSET 实现,5km 半径检索几百毫秒 → 降到几毫秒。
6.2 初始化 + 检索
java
// hm-dianping/src/main/java/com/hmdp/service/impl/ShopServiceImpl.java
@Service
public class ShopServiceImpl implements IShopService {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private ShopMapper shopMapper;
// ========== 启动时加载商户坐标到 Redis GEO ==========
@PostConstruct // Spring 注解:Bean 初始化完成后自动执行,适合做"启动时预加载数据"这种一次性工作
public void initShopGeo() {
List<Shop> shops = shopMapper.selectAll();
for (Shop shop : shops) {
// GEOADD shop:geo longitude latitude member
redisTemplate.opsForGeo().add("shop:geo",
new Point(shop.getLongitude(), shop.getLatitude()),
shop.getId().toString());
}
}
// ========== 附近商户检索 ==========
public List<Shop> searchNearby(double longitude, double latitude,
int radiusKm, int limit) {
String geoKey = "shop:geo";
// GEOSEARCH:Redis 6.2+ 统一替代 GEORADIUS / GEORADIUSBYMEMBER
GeoSearchCommandArgs args = GeoSearchCommandArgs.newGeoSearchArgs()
.includeDistance() // 返回距离
.sortAscending() // 按距离升序
.limit(limit); // 最多返回 N 条
GeoResults<RedisGeoCommands.GeoLocation<String>> results =
redisTemplate.opsForGeo().search(
geoKey,
// 搜索中心:用户当前坐标
new GeoReference.GeoCoordinateReference(longitude, latitude),
// 搜索半径:5km
new Distance(radiusKm, DistanceUnit.KILOMETERS),
args
);
// 解析结果
List<Shop> shops = new ArrayList<>();
for (GeoResult<RedisGeoCommands.GeoLocation<String>> result : results) {
String shopId = result.getContent().getName();
double distance = result.getDistance().getValue(); // 距离(km)
Shop shop = shopMapper.selectById(Long.valueOf(shopId));
shop.setDistance(distance);
shops.add(shop);
}
return shops;
}
}6.3 GEOSEARCH vs GEORADIUS
Redis 6.2 之前有两个命令:GEORADIUS(按坐标搜)和 GEORADIUSBYMEMBER(按已存在的成员位置搜)。Redis 6.2 用 GEOSEARCH 统一替代:
旧:GEORADIUS shop:geo 115.85 28.68 5 km WITHDIST ASC
新:GEOSEARCH shop:geo FROMLONLAT 115.85 28.68 BYRADIUS 5 km WITHDIST ASC
旧:GEORADIUSBYMEMBER shop:geo "shop:1001" 5 km WITHDIST ASC
新:GEOSEARCH shop:geo FROMMEMBER "shop:1001" BYRADIUS 5 km WITHDIST ASC一个命令支持按坐标搜 + 按成员搜 + 圆形搜 + 矩形搜,API 更干净。
✅ GEO 工程方案防住了:高频附近商户查询的延迟------内存检索替代磁盘 IO,毫秒级返回;地理位置查询的复杂度------GEOSEARCH 一个命令覆盖所有搜索模式,API 统一不散乱
❌ 但还没讲透:GEOSEARCH 凭什么毫秒级?底层用了什么数据结构?边界情况怎么处理?→ 下一章拆 GeoHash 底层原理
七、GeoHash 底层:5km 毫秒级返回的秘密
7.1 Redis GEO 底层就是 ZSET
Redis 没有为 GEO 单独实现数据结构------它复用了 ZSET。GEO 的每个操作,最终都落在 ZSET 的命令上:
GEOADD → ZADD (经纬度编码成 score,member 不变)
GEOSEARCH → ZSCAN (在 score 范围上做过滤 + 距离计算)7.2 GeoHash 编码原理
GeoHash 的核心思想:把二维的经纬度编码成一维的字符串------通过不断对经纬度范围做二分逼近。
以南昌红谷滩(115.85°E, 28.70°N)为例:
经度编码(范围 -180, 180)
Step 1: 115.85 在 [0, 180] 右半 → bit=1, 区间缩到 [0, 180]
Step 2: 115.85 在 [90, 180] 右半 → bit=1, 区间缩到 [90, 180]
Step 3: 115.85 在 [90, 135] 左半 → bit=0, 区间缩到 [90, 135]
Step 4: 115.85 在 [112.5, 135] 右半 → bit=1, 区间缩到 [112.5, 135]
... 重复 15 次纬度编码(范围 -90, 90)
Step 1: 28.70 在 [0, 90] 右半 → bit=1, 区间缩到 [0, 90]
Step 2: 28.70 在 [0, 45] 左半 → bit=0, 区间缩到 [0, 45]
Step 3: 28.70 在 [22.5, 45] 右半 → bit=1, 区间缩到 [22.5, 45]
... 重复 15 次交叉合并
把经度和纬度的 bit(二进制位,0 或 1)交替合并------经度放偶数位,纬度放奇数位:
经度: 1 1 0 1 ...
纬度: 1 0 1 ...
↓ 交叉合并
合并: 11 10 01 ... → 每 5 位转成一个 Base32 字符
↑ Base32 = 用 32 个字符(0-9, a-z 去掉 a/i/l/o)
来表示二进制数据的编码方式最终得到的字符串如 wtc6v------前缀越相同,位置越接近(这是 GeoHash 的核心性质,让我们能做前缀索引)。
7.3 精度对照
| GeoHash 长度 | 精度 | 适用场景 |
|---|---|---|
| 5 位 | ±2.4km | 城市级别 |
| 6 位 | ±0.61km | 区/镇级别 |
| 7 位 | ±0.076km | 街道级别 |
| 8 位 | ±0.019km | 建筑级别 |
7.4 为什么毫秒级返回
GEOSEARCH 的执行过程:
1. 将搜索中心的经纬度编码成 GeoHash
2. 根据搜索半径确定需要扫描的 GeoHash 范围(通常 1-9 个格子)
3. 每个格子对应 ZSET 的一段 score 范围 → ZRANGEBYSCORE 查候选集
4. 对候选集逐一计算 Haversine 距离(球面距离公式------地球是球体,不能用平面上两点间直线距离的勾股定理,必须用经纬度算弧面距离),过滤出满足半径的成员
5. 按距离排序返回第 3 步是 O(logN + M)------跳表索引定位 + 顺序扫描,全部在内存中完成,没有磁盘 IO。
第 4 步只在候选集上做精确距离计算------GeoHash 前缀匹配已经把大部分无关数据排除掉了,候选集通常很小。
综合下来,5km 半径检索几百个商户 → 几毫秒。
7.5 边界效应:为什么不能只搜一个格子
GeoHash 有一个著名的坑------前缀相同 ≠ 距离接近(存在边界效应)。
两个位置可能非常接近(比如相距 10 米),但刚好在 GeoHash 格子边界的两侧------它们的 GeoHash 前缀不同:
格子A 格子B
┌──────────┐ ┌──────────┐
│ 商户1 │ │ 商户2 │
│ ●─────┼────┼──● │ ← 两个商户只隔了 10 米
│ │ │ │ 但分属不同 GeoHash 格子
└──────────┘ └──────────┘解决方案:搜索时不仅搜当前格子,还搜周围 8 个格子 (3×3 的 GeoHash 邻域)。这就是 GEOSEARCH 内部帮你做的事------Spring Data Redis 的 GeoSearchCommandArgs 默认会扩展邻域格子。
✅ GEO 方案防住了:MySQL 空间查询的高延迟 → Redis 内存检索毫秒级返回;GeoHash 前缀匹配快速缩小候选集 → O(logN+M) 时间复杂度
❌ 但防不住:GEO 数据需要预热加载------重启后 `@PostConstruct` 全量加载,商户量大(百万级)时启动慢;商户坐标变更需要同步更新 Redis,没有自动同步机制(需配合 Outbox + 消息队列做 GEO 更新)
八、总结
Feed 流设计决策树
你的场景是?
/ \
读多写少 写多读少
/ \
粉丝量多大? 拉模式
/ \
粉丝 < 1万 粉丝 ≥ 1万
/ \
推模式 推拉结合
ZSET收件箱 普通用户→推
时间游标分页 大V→拉
容量上限1000 Timeline温缓存核心金句
推模式和拉模式的本质不是"哪个更好",而是"你把复杂度放在写的时刻,还是读的时刻"------选哪个,取决于你的用户是读得多还是写得多,你的粉丝量是百级还是亿级。
一条动态的完整旅程
用户发动态
│
├─→ [ 判断用户类型 ]
│ ├─ 普通用户 → 推模式
│ │ ├─→ 博文存 MySQL(持久化)
│ │ └─→ 动态ID ZADD 进所有粉丝的 ZSET 收件箱
│ │ └─→ 收件箱 > 1000 条?→ ZREMRANGEBYRANK 淘汰旧数据
│ │
│ └─ 大 V → 拉模式
│ └─→ 博文存 MySQL + 动态ID ZADD 进自己的发件箱
│
▼
粉丝刷 Timeline
│
├─→ [ 查自己的 ZSET 收件箱 ](推内容,O(logN+M))
├─→ [ 并发查关注大 V 的发件箱 ](拉内容,超时降级)
├─→ [ 按 score 降序合并 ]
├─→ [ 时间游标分页返回 ](对增量数据免疫)
│
▼
附近商户检索
│
├─→ 用户坐标 → GeoHash 编码
├─→ GEOSEARCH 搜索中心邻域格子
├─→ ZSET score 范围查询(候选集,O(logN+M))
├─→ Haversine 精确过滤(排除边界效应的误召回)
└─→ 按距离升序返回(毫秒级)📖 附录:术语速查表
正文中遇到看不懂的名词,回这里查。每个术语的详细原理在对应章节里都有展开。
| 术语 | 一句话解释 | 类比帮助理解 |
|---|---|---|
| Feed 流 | 朋友圈/微博那种"持续刷新看动态"的信息流 | 像刷抖音------不断下滑,看新内容 |
| Timeline | 个人主页的时间线,即"按时间倒序排列的动态列表" | 你的朋友圈页面 |
| 推模式(Push) | 用户发动态时,把动态主动塞进每个粉丝的收件箱 | 快递员把包裹送到每家每户门口 |
| 拉模式(Pull) | 用户发动态时只存自己那,粉丝自己来取 | 快递放在驿站,收件人自己去拿 |
| 写扩散 | 发 1 条动态,要往 N 个粉丝那里各写 1 次 | 复印 N 份传单,挨家挨户发 |
| 读扩散 | 刷 1 次 Timeline,要从 M 个关注者那里各读 1 次再合并 | 想看最新消息,得跑 M 个朋友家各问一遍 |
| ZSET | Redis 的"有序集合"------每个元素带一个分数(score),自动按分数排序 | 班级成绩排名表------学号是 member,总分是 score,按分排序 |
| score | ZSET 中每个元素关联的分值,用来排序 | 成绩排名里的"总分" |
| member | ZSET 中的元素本身(这里是动态 ID) | 成绩排名里的"学号" |
| offset 分页 | 传统的"跳过前 N 条,取后 M 条"分页方式 | 翻书:翻过前 10 页,看第 11 页 |
| 游标分页(Cursor) | 用上一次最后一条的 score 作为"锚点",取它之前的 N 条 | 书签:每次从上次读到的那行继续往下读 |
| 大 V | 粉丝量极大的用户(百万/千万级) | 微博上的明星、大网红 |
| 冷热分离 | 活跃用户的数据放快速存储(Redis),不活跃的用慢速方案(MySQL) | 常用的东西放桌上,不常用的收柜子里 |
| GeoHash | 把经纬度(二维坐标)编码成一串字母数字(一维字符串)的算法 | 把地图切成一个个小格子,每个格子编个号 |
| Haversine 公式 | 计算地球球面上两点之间真实距离的数学公式 | 地球是圆的,不是平的------不能用勾股定理算两点距离 |
| TTL | Time To Live,数据在缓存中存活的时间,到期自动删除 | 牛奶的保质期------过期就扔 |
| 跳表(Skip List) | ZSET 底层的数据结构,一种多层链表,查找效率 O(logN) | 电梯------每层都停是普通链表,跳表是"快速电梯"只停关键楼层 |
| B+ 树 | MySQL InnoDB 索引的数据结构,数据存在叶子节点,适合磁盘读写 | 一本字典的目录------先查目录(索引),再翻到正文页(数据) |
| O(logN) | 时间复杂度表示法------数据量翻倍,查询步数只多一步 | 二分查找:100 万条数据,最多比 20 次就能找到 |
| O(1) | 不管数据量多大,查询步数始终是常数 | 直接翻到书的第 50 页------不管书有 100 页还是 1000 页 |
| Redis Cluster | Redis 集群------把数据分片存到多台机器上,突破单机内存限制 | 一个仓库不够放 → 开分仓,按规则决定东西放哪个仓 |
| SPATIAL INDEX | MySQL 的空间索引,用于加速地理位置查询 | 在地图上给每个区域建个快速索引,不用全地图扫描 |
| OLTP | 在线事务处理------用户实时操作型的业务(如下单、发动态) | 收银台结账------一个接一个实时处理 |
| @PostConstruct | Spring 注解------在 Bean 初始化完成后自动执行的方法 | 游戏加载完后的"自动存档" |
*我是程序员小鱼,持续输出 Java 后端面试系列,关注不迷路。🐟*