来源
这个比赛的github仓库,race_tests目录下有三个算子,拉取源码操作如下,记得切换分支
bash
cd /data
git clone https://github.com/tile-ai/tilelang-metax.git
cd tilelang-metax
git checkout race这里来看看moe算子的实现思路
torch baseline
先看torch baseline,路径是race_tests/moe/ref_fusedmoe.py。
MoE定义
全称Mixture of Expert,混合专家。
传统LLM的思路是一个超大FFN层,包含百科全书式的知识,每次推理时都由这个大FFN层推理。这样推理很慢,并且实际上大部分参数是根本没用的,比如你问个hello,并不需要知道光荣革命和凝聚态物理的知识,但是这些参数还是参与推理了
MoE最早是谷歌提出的,被deepseek实际应用到LLM推理中,解决的就是FFN层过大的问题。解决思路是:把大的FFN拆成多个小FFN,每个小FFN就是一个专家,每次推理时,推理文本先经过一个路由层router,计算出每个token和每个专家的匹配度。对于每个token,找出匹配度最高的topk个专家,只用这几个专家进行推理,大大降低了激活参数量,降低了显存占用,提高了推理速度。
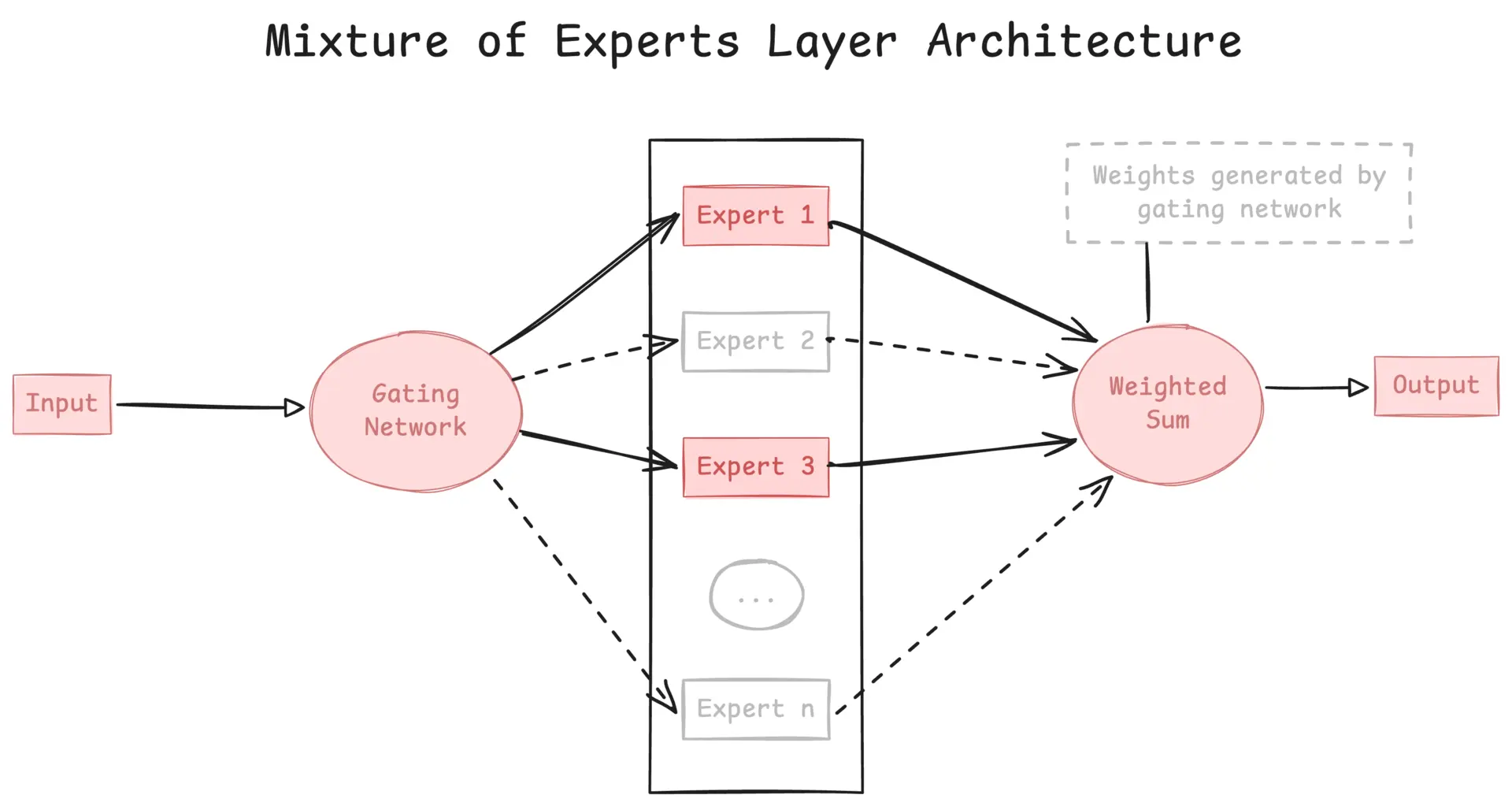
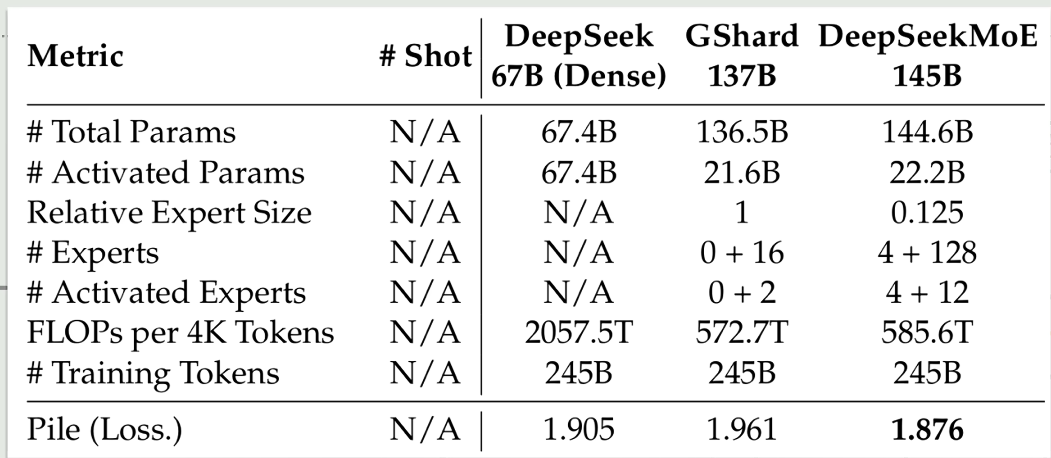
deepseek的实验表明,moe模型达到相同的表现分数,推理开销只有稠密模型的三分之一左右,也就是这里的激活参数量,稠密模型需要67B,MoE只需要22B。(代价是,需要更大的整体参数量,因为每次激活的参数终归是变少了,会损失一定智能,需要更大的知识库,不过这是空间换时间,可以接受)
所以整体的模型只用分成两部分
- router路由计算每个token对每个专家的分数,得到对于每个token,topk的专家
- 每个token利用这topk个专家推理,然后加权叠加。
ref_kernel接口
对外接口是这个函数ref_kernel
- 传入参数分别是:推理文本,模型参数,模型配置
- 推理文本shape是batch大小,文本长度,词向量长度
- 模型参数包含多个专家,每个专家是个微型FFN层,用的是SwiGLU,一个特殊的GLU层,包含三个矩阵
gate = SiLU(x @ W_gate) # d_hidden → d_expert
up = x @ W_up # d_hidden → d_expert
out = (gate * up) @ W_down # d_expert → d_hidden
我们把这三个矩阵参数分别填入每个专家里 - 最后调用moe推理接口进行推理
py
def ref_kernel(data: Tuple[torch.Tensor, Dict, Dict]) -> torch.Tensor:
"""
Reference implementation of DeepSeek-style Mixture of Experts using PyTorch.
Args:
data: Tuple of (input: torch.Tensor, weights: Dict[str, torch.Tensor], config: Dict)
- input: Input tensor of shape [batch_size, seq_len, hidden_dim]
- weights: Dictionary containing model weights
- config: Dictionary containing model configuration parameters
Returns:
Tuple containing:
- output: Processed tensor [batch_size, seq_len, d_model]
"""
input_tensor, weights, config = data
num_experts = config["n_routed_experts"]
moe = MoETorch(config)
# Fill in the given weights of the model
moe.gating_network.W_g.weight = nn.Parameter(weights["router.weight"])
for i in range(num_experts):
gate_proj_weight = weights[f"experts.{i}.0.weight"]
up_proj_weight = weights[f"experts.{i}.1.weight"]
down_proj_weight = weights[f"experts.{i}.2.weight"]
# Transpose weights to match expected shape for nn.Linear
moe.experts[i].W_gate.weight = nn.Parameter(gate_proj_weight.t())
moe.experts[i].W_up.weight = nn.Parameter(up_proj_weight.t())
moe.experts[i].W_down.weight = nn.Parameter(down_proj_weight.t())
output = moe(input_tensor)
return outputMoE类
前面接口调用的类,forward里就是moe算子的主要流程
expert_indices, expert_scores = self.gating_network(x)首先调用路由函数,计算输入的每个token的路由结果,结果包含每个token对应的topk个专家的编号,以及每个专家的权重x_flat = x.view(-1, hidden_dim)把输入文本的batch,seq_len两个维度展平,只保留词向量长度这个维度,现在的shape是B\*S,hid_dim,因为推理时batch并不重要,忽略。routed_output_flat = self.moe_infer(x_flat, flat_expert_indices, flat_expert_weights)把输入,topk专家编号,专家权重传给推理函数,对每个token进行推理routed_output = routed_output_flat.view(*orig_shape)最后把shape再恢复到和输入一样的三维张量,分batch,seq_len,hid_dim
init则是初始化
self.experts = nn.ModuleList([ExpertTorch(config) for _ in range(config["n_routed_experts"])]),用传入的配置参数,声明每个专家的shape,这里只有shape,具体参数在ref_kernel函数里直接赋值的- 类似的
self.gating_network = MoEGateTorch(config)也是声明路由层的shape,没有参数。
py
class MoETorch(nn.Module):
def __init__(self, config: Dict):
super().__init__()
self.config = config
self.experts = nn.ModuleList([ExpertTorch(config) for _ in range(config["n_routed_experts"])])
self.gating_network = MoEGateTorch(config)
def forward(self, x: torch.Tensor) -> torch.Tensor:
expert_indices, expert_scores = self.gating_network(x)
batch_size, seq_len, hidden_dim = x.shape
orig_shape = x.shape
x_flat = x.view(-1, hidden_dim)
flat_expert_indices = expert_indices.view(-1)
flat_expert_weights = expert_scores.view(-1, 1)
routed_output_flat = self.moe_infer(x_flat, flat_expert_indices, flat_expert_weights)
routed_output = routed_output_flat.view(*orig_shape)
return routed_outputmoe_infer
上面引用的推理函数,已经知道每个token需要路由到哪些专家了,逐个token进行推理。用了一些py语法糖,可读性略差,需要时刻注意张量形状。
expert_cache = torch.zeros_like(x)结果数组,大小和输入完全相同B\*S,hid_dim,也就是输入的每个token,都会计算推理结果idxs = flat_expert_indices.argsort()把路由结果数组,按排序,并且返回排序后值在原数组中的下标,比如3,2,1排序后是1,2,3,但是排序后下标是3,2,1,这是为了把相同专家的推理请求排到一起,但是推理时需要知道每个请求的原始编号,所以返回不是值而是原始下标counts = flat_expert_indices.bincount().cpu().numpy()转到值域上,类似于用一个列表构造了一个dict,对于列表中每个出现的值计数,比如1,1,2,2,3,3会变成2,2,2tokens_per_expert = counts.cumsum()对计数数组做前缀和,还是前面的例子,会变成2,4,6,这样实际上就能得到,每个专家对应的区间,比如第一个专家的推理请求,都在区间[0,2),第二个专家的请求都在[2,4)token_idxs = idxs // num_per_tok,把请求下标转成token编号,这一步这样考虑,输入的flat_expert_indices的shape是B \* S \* topk,每个长度topk的区间,都是同一个token的请求,那么我们把这个数组的下标,除以topk,也就能得到每个下标所在的token区间编号,比如topk=2的话,0,1都是第一个token的请求,0/2=0,1/2=0,就能知道这两个请求都是token_id=0的请求for expert_id, end_idx in enumerate(tokens_per_expert):这里就是在利用我们前面的前缀和数组,得到每个专家的推理请求所在的区间,一次性处理,这样的好处是不用反复拷贝专家,构造一次专家就把这个专家的推理请求全部做完了,对硬件流水线也友好expert = self.experts[expert_id]获取当前专家exp_token_idxs = token_idxs[start_idx:end_idx]取出当前专家的推理请求的token编号expert_tokens = x[exp_token_idxs]取出需要推理的token,这是个py语法糖,可以对\[\]传入一个下标列表,那么会取出这个列表里的下标的元素,构成一个列表expert_out = expert(expert_tokens)对这些token,调用专家推理的forward,得到推理结果expert_out.mul_(flat_expert_weights[idxs[start_idx:end_idx]])结果需要乘上每个token,和当前专家的路由权重,路由权重的构造方法和前面看取出token的方法类似,也是给\[\]传入一个列表,只是注意这里的下标数组构造,收从idxs数组构造的,不是token_idxs,因为一个token对不同专家的权重是不同的expert_cache.scatter_reduce_(0, exp_token_idxs.view(-1, 1).repeat(1, x.shape[-1]), expert_out, reduce="sum")最后调用scatter_reduce_接口,把把每个token的结果,累加到对应位置。比如token_id=0的结果,需要累加到expert_cache0的位置上。- 最后
@torch.no_grad()是因为这里没有反向传播,不需要维护梯度,降低计算开销。
py
@torch.no_grad()
def moe_infer(self, x: torch.Tensor, flat_expert_indices: torch.Tensor, flat_expert_weights: torch.Tensor) -> torch.Tensor:
expert_cache = torch.zeros_like(x)
idxs = flat_expert_indices.argsort()
counts = flat_expert_indices.bincount().cpu().numpy()
tokens_per_expert = counts.cumsum()
num_per_tok = self.config["n_experts_per_token"]
token_idxs = idxs // num_per_tok
for expert_id, end_idx in enumerate(tokens_per_expert):
start_idx = 0 if expert_id == 0 else tokens_per_expert[expert_id - 1]
if start_idx == end_idx:
continue
expert = self.experts[expert_id]
exp_token_idxs = token_idxs[start_idx:end_idx]
expert_tokens = x[exp_token_idxs]
expert_out = expert(expert_tokens)
expert_out.mul_(flat_expert_weights[idxs[start_idx:end_idx]])
expert_cache.scatter_reduce_(0, exp_token_idxs.view(-1, 1).repeat(1, x.shape[-1]), expert_out, reduce="sum")
return expert_cacheExpertTorch
专家层,上一个moe_infer里每个token的具体推理就是调用这个类的forward
self.W_gate = nn.Linear(self.d_hidden, self.d_expert, bias=False)初始化时同样只构造shape,不管具体数值,此时数值都是随机值。注意gate和up,都是把输入的hid_dim,词向量长度,映射到d_expert,也就是专家推理过程中的隐藏层,最后down再把隐藏层映射回词向量长度- 推理表达式可以写成 FFN SwiGLU ( x ) = ( Swish ( x W g a t e ) ⊗ x W u p ) W d o w n \text{FFN}{\text{SwiGLU}}(x) = \left( \text{Swish}(xW{gate}) \otimes xW_{up} \right) W_{down} FFNSwiGLU(x)=(Swish(xWgate)⊗xWup)Wdown
- 先计算门控结果
gate = self.act_fn(self.W_gate(x)) - 再把门控结果和up结果逐元素相乘,注意不是矩阵乘法。然后再down映射回词向量长度
out = self.W_down(gate * self.W_up(x))
py
class ExpertTorch(nn.Module):
def __init__(self, config: Dict, d_expert: Optional[int] = None):
super().__init__()
self.config = config
self.act_fn = nn.SiLU()
self.d_hidden: int = config["d_hidden"]
self.d_expert: int = config["d_expert"] if d_expert is None else d_expert
self.W_gate = nn.Linear(self.d_hidden, self.d_expert, bias=False)
self.W_up = nn.Linear(self.d_hidden, self.d_expert, bias=False)
self.W_down = nn.Linear(self.d_expert, self.d_hidden, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
gate = self.act_fn(self.W_gate(x))
out = self.W_down(gate * self.W_up(x))
return outMoEGateTorch
路由层也很简单,路由计算分数,本质上是一个矩阵乘法。
self.W_g = nn.Linear(self.d_hidden, self.num_experts, bias=False)把输入的B \* S,hid_dim,映射到B \* S,num_experts,也就是每个推理请求,都返回一个num_experts长的列表,表示这个token和各个专家的权重,这实际上就是一个 x W r o u t e xW_{route} xWroute的矩阵乘法- 然后分数可能很大,但我们只关系相对权重,用softmax映射回0,1
scores = logits.softmax(dim=-1) - 利用分数列表,计算出前topk的分数和下标
topk_scores, topk_indices = torch.topk(scores, k=self.top_k, dim=-1, sorted=False),这里为了降低baseline运算量没有排序,只是为了演示流程。实际肯定要排序
py
class MoEGateTorch(nn.Module):
def __init__(self, config: Dict):
super().__init__()
self.top_k: int = config["n_experts_per_token"]
self.num_experts: int = config["n_routed_experts"]
self.d_hidden: int = config["d_hidden"]
self.W_g = nn.Linear(self.d_hidden, self.num_experts, bias=False)
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
logits = self.W_g(x)
scores = logits.softmax(dim=-1)
topk_scores, topk_indices = torch.topk(scores, k=self.top_k, dim=-1, sorted=False)
return topk_indices, topk_scores总结
到这里就没了,整体算子不算很复杂,只有moe_infer做了点小优化,复杂了点。
整体流程:
- 输入逐个token计算路由,计算和每个专家的匹配得分
- 路由过程就是输入和路由矩阵做一个矩阵乘法 x W r o u t e xW_{route} xWroute
- 每个token,取出得分topk的专家,要知道这些专家的编号,和与这些专家的具体匹配度
- 接下来根据定义是每个token,计算topk的专家的推理结果,根据匹配度加权求和
- 但是为了优化,改变一下计算顺序。首先枚举每个专家,对于一个专家取出它所有的推理请求,一次性处理,然后把这些请求累加回结果数组对应token的位置
- 推理中就是一个SwiGLU的过程