
大模型很强。它会写代码,会总结,会分析,会对话。
但它有三个硬伤:不知道你的私有数据,训练知识会过期,上下文窗口也不是无限大。
RAG 就是为了解决这三个问题。它不是让模型重新训练一次,也不是把所有资料都塞给模型。它的核心动作很简单:回答之前,先去知识库里找资料。
RAG = 检索 + 生成。检索负责找依据,生成负责把依据说成人话。
一、为什么大模型需要外挂知识库?
先看一个真实场景。
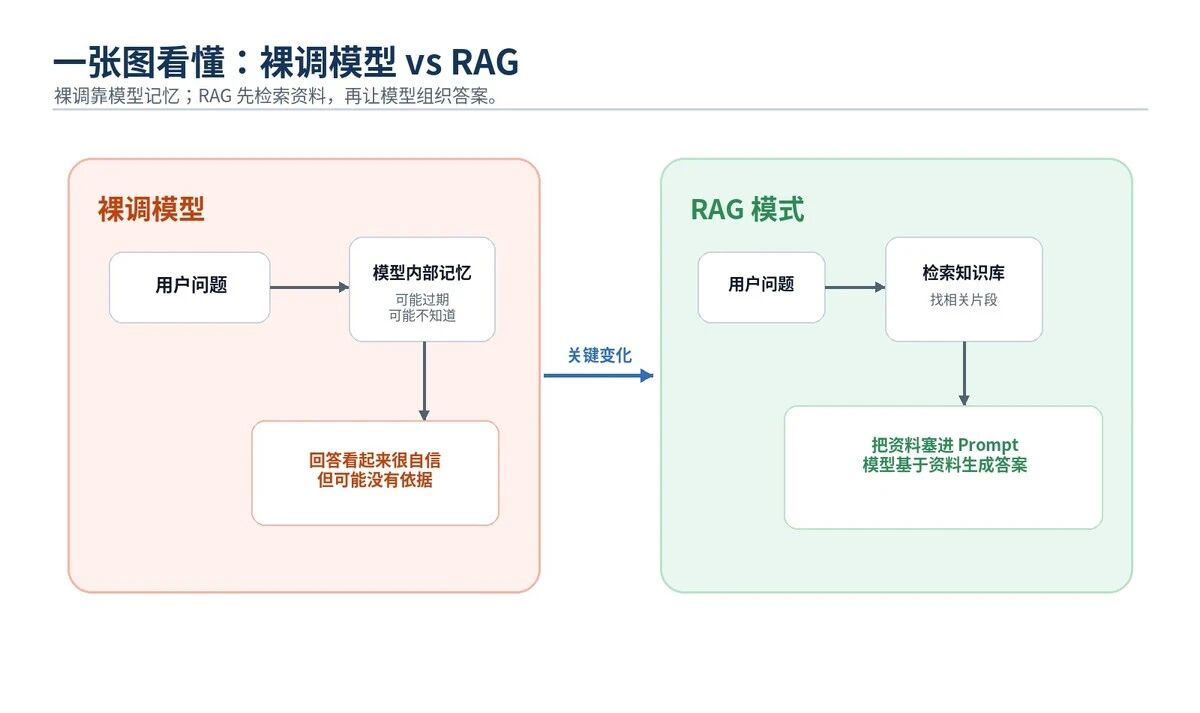
你问模型:"我们公司 2026 年最新版报销制度里,差旅住宿标准是多少?"
模型如果没有接入你的内部制度文档,它只能猜。猜得再像,也不是答案。
这就是裸调模型的风险:回答流畅,不代表回答正确。
1. 模型知识会过期
大模型的训练数据通常有截止时间。训练之后发生的新政策、新公告、新产品文档,它天然不知道。
LangChain 官方 Retrieval 文档也明确指出,LLM 有两个关键限制:上下文有限,以及训练知识是静态的;Retrieval 通过在查询时获取外部知识来解决这些问题。
2. 模型不知道你的私有数据
企业真正有价值的数据,往往不在公开互联网里。比如:合同、制度、客服 FAQ、订单状态、研报库、内部知识库、产品手册、故障工单。
这些内容不能指望模型"天生知道"。必须在用户提问时动态检索。
3. 模型上下文不是无限大
就算你有 10 万页文档,也不能全部塞进 Prompt。上下文窗口再大,也不是数据库。
RAG 的做法是:只找和当前问题最相关的几段资料,把它们作为上下文交给模型。
二、RAG 的本质:不是训练模型,而是给模型递资料
很多人第一次听 RAG,会误以为它是微调模型。不是。
微调是改变模型参数。RAG 不改模型参数。RAG 是在模型回答前,把相关资料临时放进上下文。
这就像考试。微调是让学生重新学习。RAG 是允许学生开卷查资料。
三、LangChain 里的 RAG 组件地图
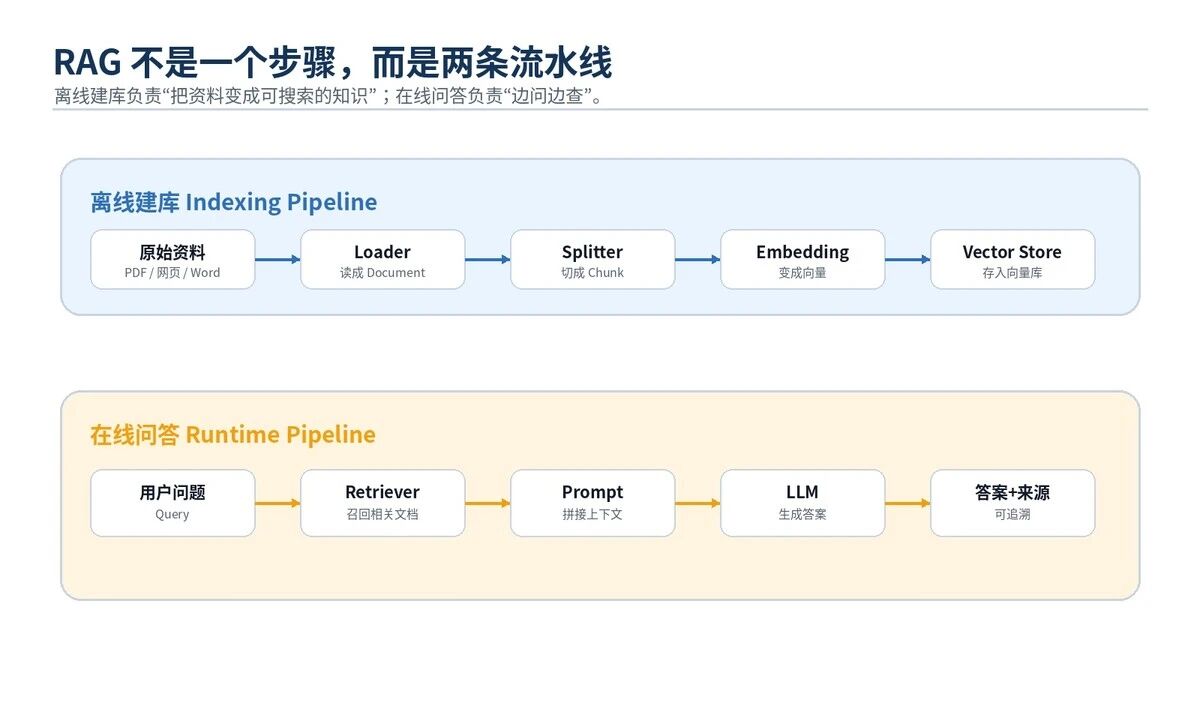
LangChain 做 RAG,不是一个神秘黑盒。它把整个流程拆成了一组小组件。

|---------------------|----------|--------------------------------------|
| 组件 | 作用 | 通俗理解 |
| Document Loader | 读取外部资料 | PDF、网页、Word、Markdown、数据库 |
| Document | 标准文档对象 | page_content、metadata、id |
| Text Splitter | 切分长文档 | 把大文档切成可检索小块 |
| Embedding | 文本向量化 | 把文本变成数字向量 |
| Vector Store | 存储与相似度搜索 | Milvus、Chroma、FAISS、Qdrant、ES Vector |
| Retriever | 检索入口 | 输入问题,返回 Document 列表 |
| Prompt | 组织上下文 | 把问题和资料拼成模型输入 |
| Model | 生成答案 | 基于资料回答,而不是凭空编 |
四、RAG 的最小单位 Document
在 LangChain 里,RAG 不是直接处理"PDF 文件"。PDF、网页、Markdown、数据库记录,最后都要转换成 Document。
Document 是 RAG 里的最小知识单元。它一般代表一个文档片段,也就是我们常说的 Chunk。

源码里,Document 继承自 BaseMedia。BaseMedia 提供 id 和 metadata,Document 自己提供 page_content。
简化后的源码结构,不是完整源码
class BaseMedia:
id: str | None
metadata: dict
class Document(BaseMedia):
page_content: str
type: Literal"Document" = "Document
这里要抓住一个核心点:Document 不是 Message。
Message 是模型对话里的消息。Document 是检索流水线里的资料。
这两个概念不能混。前面第四章讲过 Messages;这一章讲的是知识库里的 Document。
五、VectorStore 做了什么?
VectorStore 是向量数据库的统一抽象。
它的任务不是生成答案。它只负责两件事:存文档,搜相似文档。
从源码看,VectorStore 把 Document 拆成 texts 和 metadatas,再交给具体向量库实现。
简化后的源码逻辑
texts = doc.page_content for doc in documents
metadatas = doc.metadata for doc in documents
vectorstore.add_texts(texts, metadatas, ids=ids)
这一步很关键。
模型看的是文本,向量库搜的是向量,但工程系统追踪的是 metadata。
所以生产环境里,metadata 不能随便写。至少要有 source、page、title、doc_id、created_at、version 等字段。否则模型答错了,你根本追不回来源。
六、Retriever 为什么是 RAG 的核心入口?
Retriever 是 RAG 运行时的入口。
用户提问后,Retriever 接收 query,返回一组 Document。
LangChain 官方也把 Retriever 定义为:输入非结构化查询,输出 Document 列表。它比 Vector Store 更通用,因为它不一定自己存文档。
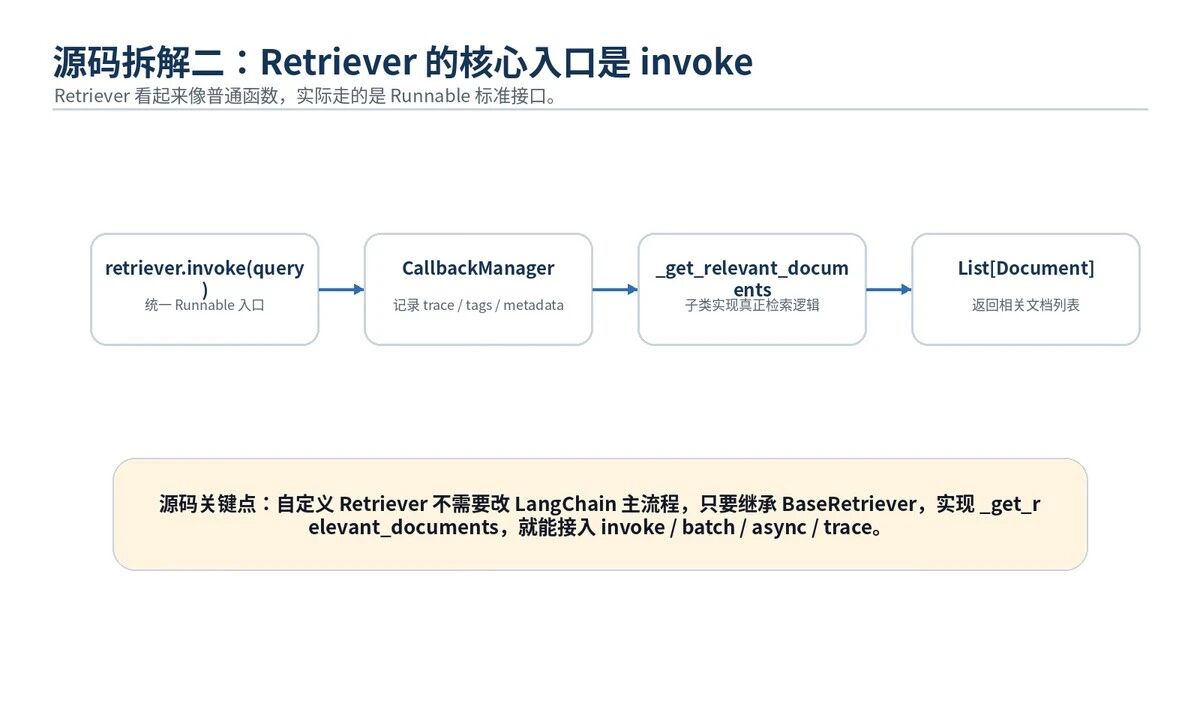
BaseRetriever 继承 RunnableSerializable,所以它天然支持 invoke、ainvoke、batch、abatch。
这就是 LangChain 的工程味道:Retriever 不是孤立工具函数,而是可组合、可追踪、可异步、可批处理的 Runnable。
简化后的源码执行链
result = retriever.invoke("用户问题")
invoke 内部大致做三件事:
1. 准备 config / callbacks / metadata
2. 触发 on_retriever_start
3. 调用 _get_relevant_documents(query)
4. 触发 on_retriever_end,返回 ListDocument
所以自定义 Retriever 的核心不是重写 invoke,而是实现 _get_relevant_documents。
你可以把 ES 检索、数据库检索、API 搜索、图数据库检索、混合检索都封装成 Retriever。
七、VectorStoreRetriever 只是一个路由器
很多人以为 VectorStoreRetriever 很复杂。其实它的核心很直白。
VectorStore.as_retriever() 会返回一个 VectorStoreRetriever。这个对象保存了 vectorstore、search_type、search_kwargs。
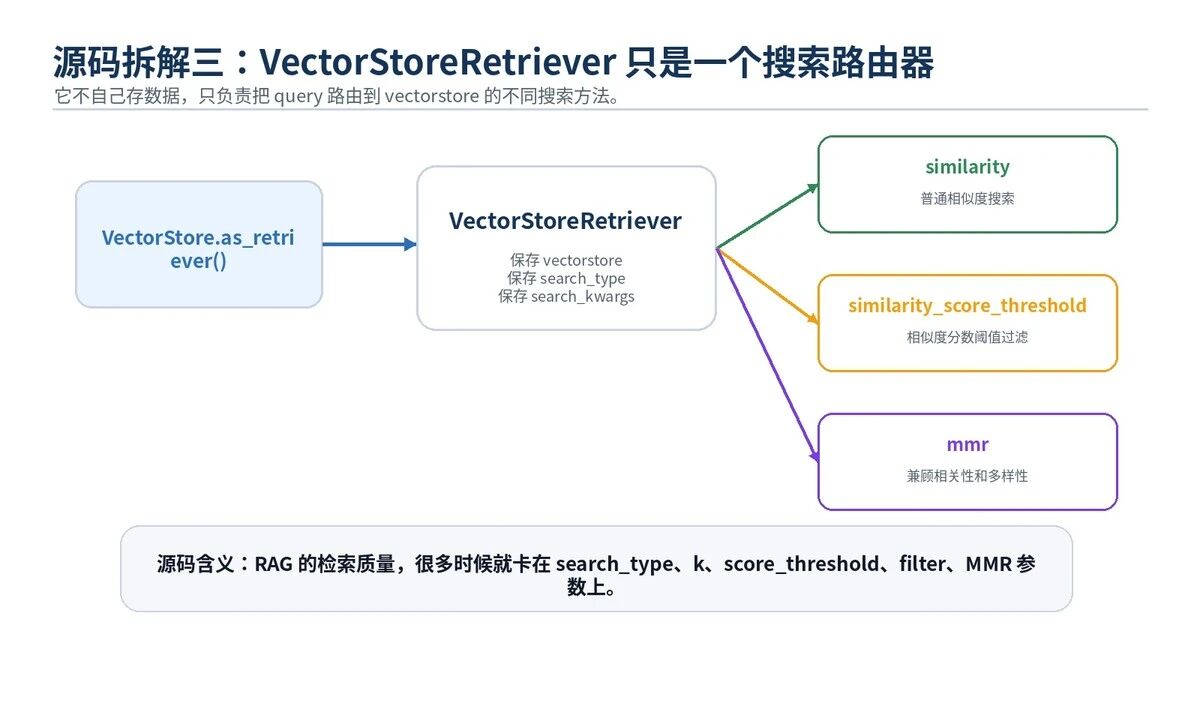
源码里支持三类常用搜索方式:
similarity:普通相似度搜索,适合大多数基础 RAG。
similarity_score_threshold:带分数阈值,只保留超过相关度的结果。
mmr:最大边际相关性,既看相关性,也看结果之间的多样性。
简化后的源码逻辑
if search_type == "similarity":
docs = vectorstore.similarity_search(query, **kwargs)
elif search_type == "similarity_score_threshold":
docs = vectorstore.similarity_search_with_relevance_scores(query, **kwargs)
elif search_type == "mmr":
docs = vectorstore.max_marginal_relevance_search(query, **kwargs)
这段逻辑很短,但很重要。
RAG 的效果,很多时候不是模型不行,而是这里的参数没调好:k 太小,召回不全;k 太大,噪声太多;没有 filter,跨业务文档乱召回;没有阈值,低相关资料也进了 Prompt。
八、RAG 的三种架构:2-Step、Agentic、Hybrid
RAG 不是只有一种写法。LangChain 官方 Retrieval 文档把 RAG 架构分成 2-Step RAG、Agentic RAG、Hybrid RAG。
1. 2-Step RAG:简单、稳定、快
固定流程:先检索,再生成。
适合 FAQ、文档问答、产品手册、内部制度查询。
优点是可控。缺点是不够灵活。无论问题需不需要检索,它都先检索。
2. Agentic RAG:让模型决定是否检索
Agentic RAG 把检索封装成工具。模型自己判断:要不要查知识库,查哪个知识库,查几次。
适合研究助手、多工具助手、多源知识库。
缺点是不可控因素更多,延迟和成本也更不稳定。
3. Hybrid RAG:生产环境更常见
Hybrid RAG 会在固定检索和模型判断之间加校验步骤。
比如:先召回,再重排,再判断资料是否足够,再决定是否二次检索,最后生成答案并引用来源。
金融、医疗、法律、企业知识库,更适合这种方式。
九、企业项目里 RAG 应该怎么落地?
不要把 LangChain 当成整个系统。它只是 AI 服务里的核心编排层。
真正上线时,外面还要有业务系统、权限、任务调度、日志、缓存、评测、后台配置。
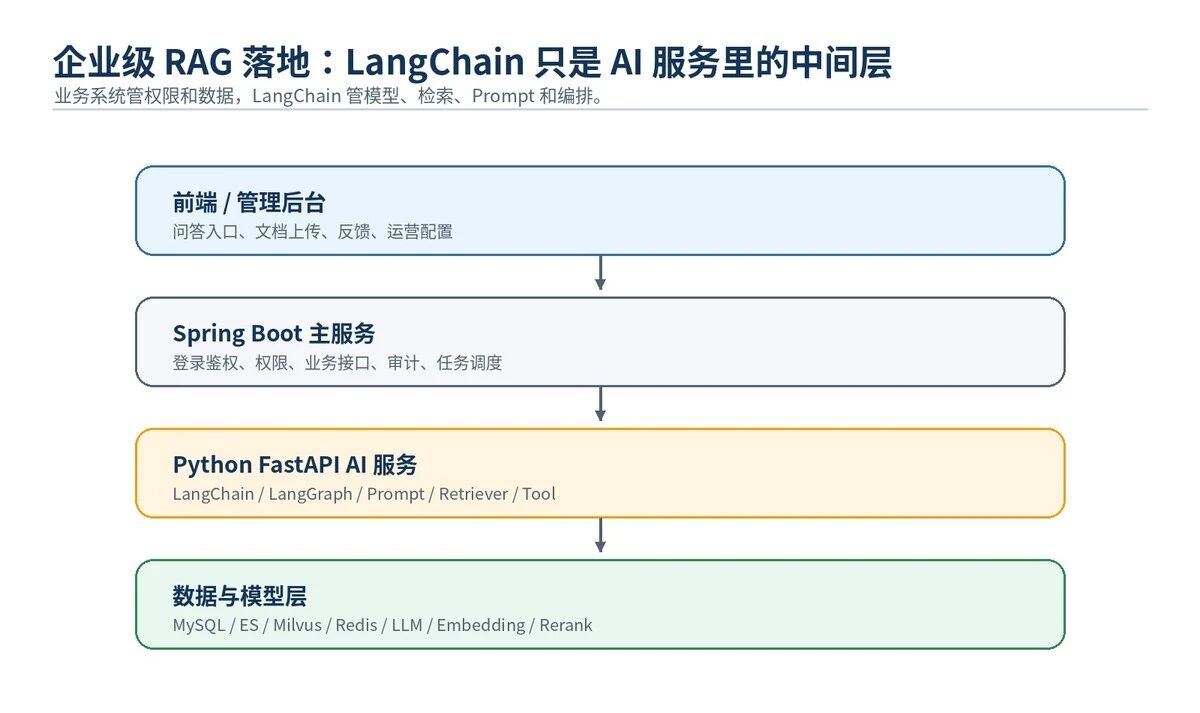
推荐架构很清晰:
Spring Boot 负责用户、权限、业务接口、管理后台、审计日志。
Python FastAPI 负责 LangChain、LangGraph、RAG、模型调用、工具调用。
Milvus / ES / MySQL / Redis 负责数据存储、检索、缓存。
LangSmith 或自建 Trace 负责观察每次检索和生成链路。
十、RAG 准确率优化的关键点
很多人做 RAG,上来就换大模型。
这不一定对。
如果检索回来的资料就是错的,模型再强也只能把错资料说得更流畅。
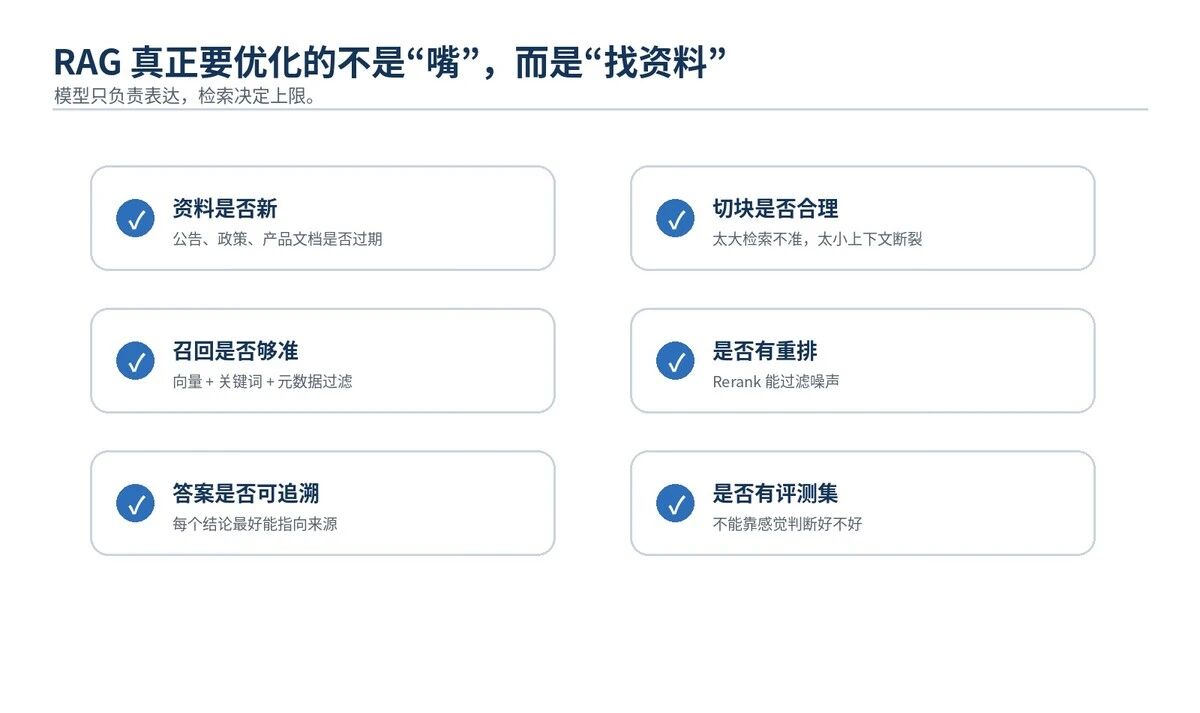
1. 数据源要干净
脏数据进库,脏答案出库。
文档版本、发布时间、来源、业务域必须管理好。
2. Chunk 要合理
Chunk 太大,检索不准;Chunk 太小,上下文断裂。
企业文档最好按标题、章节、段落结构切,而不是机械按字符切。
3. 检索要混合
纯向量检索擅长语义相似,但对编号、股票代码、订单号、专有名词不一定稳定。
生产环境常用:向量召回 + BM25 关键词召回 + 元数据过滤 + RRF 融合 + Rerank。
4. 答案要可追溯
RAG 的底线不是"看起来像对的"。
底线是:每个关键结论都能追到来源。
没有来源的回答,不要轻易上线到高风险场景。
十一、源码脉络总结

RAG 的本质,就是这条链。
Loader 负责读。Splitter 负责切。Embedding 负责变向量。VectorStore 负责存和搜。Retriever 负责取。Prompt 负责组织。Model 负责表达。
十二、总结
RAG 不是微调模型,而是回答前检索外部知识。
大模型的三个硬伤:知识过期、私有数据不知道、上下文有限。
LangChain 的 RAG 组件是模块化的,可以单独替换。
Document 是最小知识单元,Retriever 是运行时核心入口。
VectorStoreRetriever 本质是 search_type 路由器。
生产级 RAG 的关键不是"模型会不会说",而是"资料找得准不准"。
下一章,我们继续往下拆:Document Loader。也就是 LangChain 如何读取 PDF、网页、Word、Markdown、数据库,把它们变成标准 Document。