开篇先说结论:如果你已经是 Java 后端开发者,转向 AI Agent 开发并不是"从零学编程",而是把原来熟悉的 Web 服务、接口调用、数据建模、异步处理、日志监控、安全治理,迁移到一个更偏"模型调用 + 工具编排 + 数据检索 + 状态管理"的技术栈里。
Java 更像一套工程化、强约束、适合长期维护的大型系统语言;Python 更像 AI 生态里的"胶水语言",适合快速接入模型、实验算法、调用框架、串联工具和验证 Agent 流程。真正做 AI Agent,不是只会 Python 语法就够了,而是要理解大模型 API、Prompt、结构化输出、Function Calling、RAG、Memory、Tool、Agent Loop、异步流式响应、评测与可观测性这些知识点。
这篇文章面向已经熟悉 Java 的开发者,目标是给你一份从 Java 转 AI Agent 开发的快速学习指南:先讲 Java 和 Python 的核心差异,再用代码对比 AI 应用开发中常见能力的两种实现方式,最后给一条可执行的学习路线。
文章目录
-
- [一、Java 和 Python 的定位差异](#一、Java 和 Python 的定位差异)
- [二、从 Java 思维切换到 Python 思维](#二、从 Java 思维切换到 Python 思维)
-
- [1. 类型:从强类型到动态类型](#1. 类型:从强类型到动态类型)
- [2. 代码组织:从分层架构到轻量模块](#2. 代码组织:从分层架构到轻量模块)
- [3. 依赖管理:从 Maven/Gradle 到 pip/uv/poetry](#3. 依赖管理:从 Maven/Gradle 到 pip/uv/poetry)
- [三、AI Agent 开发到底要学哪些知识点](#三、AI Agent 开发到底要学哪些知识点)
- [四、调用大模型 API:Java 与 Python 对比](#四、调用大模型 API:Java 与 Python 对比)
-
- [Java:用 HttpClient 调用 Chat Completions](#Java:用 HttpClient 调用 Chat Completions)
- [Python:用 OpenAI SDK 调用](#Python:用 OpenAI SDK 调用)
- [Java 开发者要注意什么](#Java 开发者要注意什么)
- [五、Prompt 模板:从字符串拼接到可维护模板](#五、Prompt 模板:从字符串拼接到可维护模板)
- 六、结构化输出:让模型结果能被程序消费
-
- [Java:定义 DTO 接收模型输出](#Java:定义 DTO 接收模型输出)
- [Python:用 Pydantic 校验](#Python:用 Pydantic 校验)
- [七、Function Calling:Agent 调工具的核心机制](#七、Function Calling:Agent 调工具的核心机制)
-
- Java:工具接口设计
- Python:函数就是天然工具
- [工具 Schema 示例](#工具 Schema 示例)
- [八、Agent Loop:从一次问答到多步执行](#八、Agent Loop:从一次问答到多步执行)
-
- Java:状态机思路
- [Python:快速实现 ReAct 循环](#Python:快速实现 ReAct 循环)
- 九、RAG:让模型回答基于你的知识库
-
- [Java:RAG 服务接口思路](#Java:RAG 服务接口思路)
- [Python:RAG 最小实现](#Python:RAG 最小实现)
- [十、Memory:Agent 为什么需要记忆](#十、Memory:Agent 为什么需要记忆)
- 十一、异步、并发与流式输出
-
- [Java:CompletableFuture 并发调用](#Java:CompletableFuture 并发调用)
- [Python:async/await 并发调用](#Python:async/await 并发调用)
- 十二、流式响应:让用户更快看到结果
-
- [Java:Spring WebFlux 返回流](#Java:Spring WebFlux 返回流)
- [Python:FastAPI StreamingResponse](#Python:FastAPI StreamingResponse)
- [十三、LangChain、Spring AI、LangChain4j 怎么选](#十三、LangChain、Spring AI、LangChain4j 怎么选)
- [十四、可观测性:AI 应用必须能排障](#十四、可观测性:AI 应用必须能排障)
-
- [Python 日志示例](#Python 日志示例)
- [十五、安全治理:Agent 比普通接口更需要边界](#十五、安全治理:Agent 比普通接口更需要边界)
-
- [Python 工具执行前的安全检查示例](#Python 工具执行前的安全检查示例)
- [十六、测试与评测:AI 应用不能只靠肉眼试](#十六、测试与评测:AI 应用不能只靠肉眼试)
-
- [Python 简单评测示例](#Python 简单评测示例)
- [十七、Java 转 AI Agent 的推荐学习路线](#十七、Java 转 AI Agent 的推荐学习路线)
-
- [阶段 1:Python 工程基础](#阶段 1:Python 工程基础)
- [阶段 2:大模型 API 与 Prompt](#阶段 2:大模型 API 与 Prompt)
- [阶段 3:结构化输出与工具调用](#阶段 3:结构化输出与工具调用)
- [阶段 4:RAG 知识库问答](#阶段 4:RAG 知识库问答)
- [阶段 5:Agent Loop 与 Memory](#阶段 5:Agent Loop 与 Memory)
- [阶段 6:生产化工程](#阶段 6:生产化工程)
- [十八、Java 和 Python 在 AI Agent 项目里的协作架构](#十八、Java 和 Python 在 AI Agent 项目里的协作架构)
- 十九、常见误区
-
- [误区 1:会 Python 就会 AI Agent](#误区 1:会 Python 就会 AI Agent)
- [误区 2:Prompt 写长一点就稳定](#误区 2:Prompt 写长一点就稳定)
- [误区 3:RAG 等于向量库](#误区 3:RAG 等于向量库)
- [误区 4:Agent 可以直接操作所有工具](#误区 4:Agent 可以直接操作所有工具)
- [误区 5:AI 应用不需要传统工程能力](#误区 5:AI 应用不需要传统工程能力)
- 二十、总结
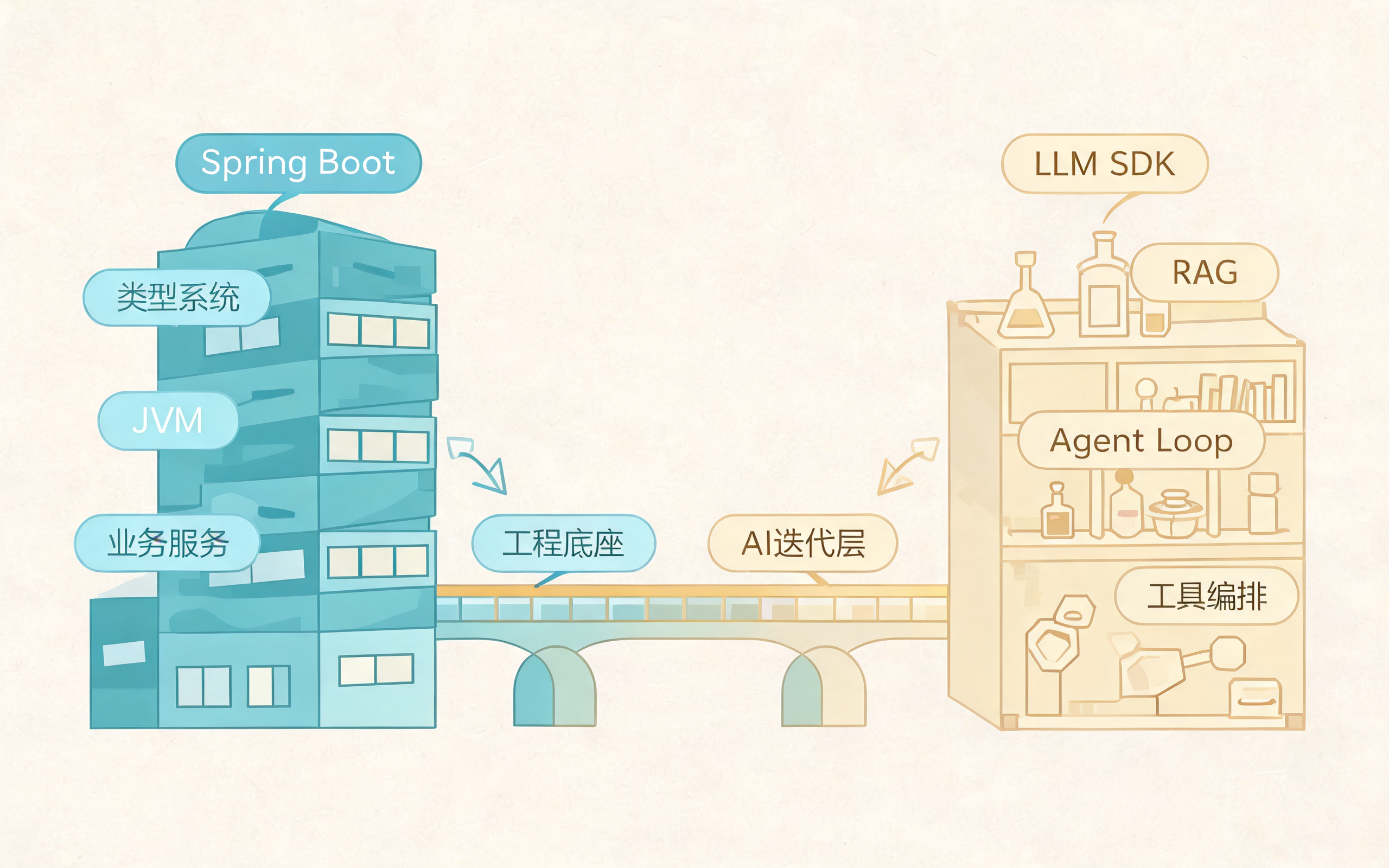
Java 与 Python 定位差异:工程底座与 AI 迭代层
一、Java 和 Python 的定位差异
Java 和 Python 都能开发 AI 应用,但它们在 AI Agent 项目里的角色经常不同。
Java 的优势是:
- 类型系统强,重构安全,适合多人协作的大型工程;
- Spring Boot、Spring Cloud、网关、鉴权、监控、消息队列生态成熟;
- JVM 性能稳定,线程模型、连接池、GC、部署体系成熟;
- 很适合承载企业后端、业务中台、模型网关、权限服务、审计服务。
Python 的优势是:
- AI/ML 生态最完整,OpenAI SDK、LangChain、LlamaIndex、Transformers、PyTorch、FastAPI 等资料最多;
- 写法短,适合快速实验 Prompt、Agent Loop、RAG 流程;
- 数据处理和脚本自动化很方便,适合把模型、向量库、工具 API 串起来;
- 大量 AI Agent 示例、框架和论文复现默认都是 Python。
一句话概括:
Java 更适合做"稳定的生产底座",Python 更适合做"AI 能力的快速迭代层"。
很多团队最终会采用混合架构:Java 继续承载核心业务服务,Python 负责 Agent 编排、RAG、模型实验和工具调用;等 Python 侧流程稳定后,再把高并发、高治理要求的部分沉淀为 Java 服务。
二、从 Java 思维切换到 Python 思维
Java 开发者学习 Python,最容易卡住的不是语法,而是思维方式。
1. 类型:从强类型到动态类型
Java 里类型通常写得很明确:
java
public class ChatRequest {
private String userId;
private String message;
public ChatRequest(String userId, String message) {
this.userId = userId;
this.message = message;
}
public String getUserId() {
return userId;
}
public String getMessage() {
return message;
}
}Python 可以写得很轻:
python
def build_request(user_id: str, message: str) -> dict:
return {
"user_id": user_id,
"message": message,
}但在 AI 应用里,我不建议完全放弃类型。因为 Agent 会传递很多结构化数据,比如工具参数、模型响应、检索结果、执行状态。推荐使用 dataclass 或 Pydantic:
python
from pydantic import BaseModel, Field
class ChatRequest(BaseModel):
user_id: str = Field(description="用户 ID")
message: str = Field(description="用户输入")Java 的类型约束通常在编译期发现问题;Python 的类型约束更多依赖运行时校验、测试和 IDE 类型提示。
2. 代码组织:从分层架构到轻量模块
Java 后端常见分层:
text
controller -> service -> repository -> client -> domainPython AI 项目也需要分层,但通常更轻:
text
app/
api.py # FastAPI 入口
llm.py # 大模型客户端
prompts.py # Prompt 模板
tools.py # 工具定义
rag.py # 检索增强
memory.py # 记忆管理
agent.py # Agent 执行循环
observability.py # 日志与追踪不要把 Python 项目写成一堆散落脚本。Agent Demo 可以是脚本,生产 Agent 必须有清晰边界。
3. 依赖管理:从 Maven/Gradle 到 pip/uv/poetry
Java Maven 示例:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>Python 常见写法:
bash
uv add fastapi uvicorn openai pydantic httpx或 requirements.txt:
text
fastapi
uvicorn
openai
pydantic
httpxAI Agent 项目建议固定版本,尤其是 LangChain、OpenAI SDK、向量库客户端这类变化快的包。否则今天能跑的链路,过几周可能因为依赖升级出现参数不兼容。
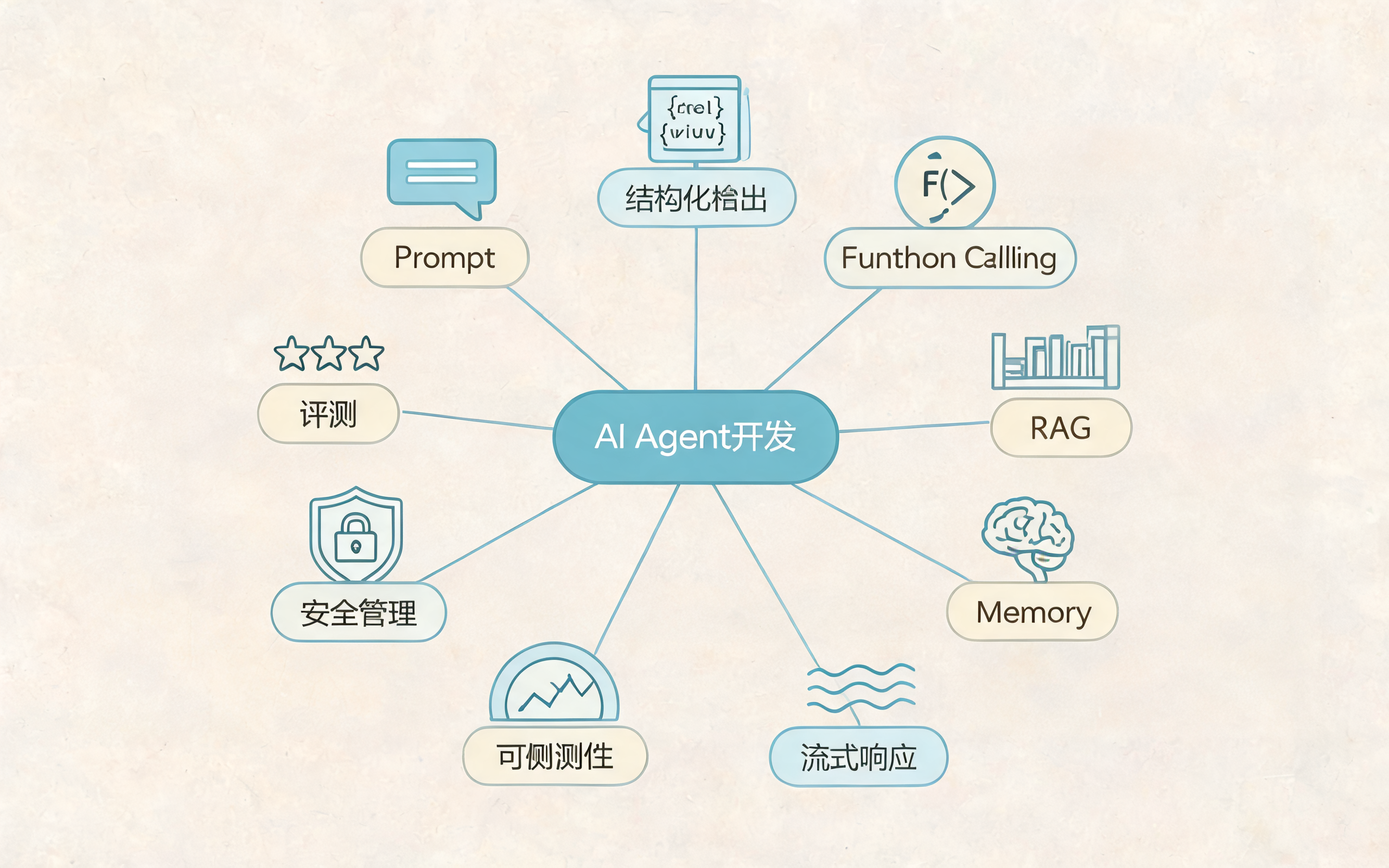
AI Agent 开发知识地图:从 Prompt 到安全评测
三、AI Agent 开发到底要学哪些知识点
从 Java 转 AI Agent,不要只学 Python 语法。建议按下面这张地图补齐能力:
| 模块 | 要学什么 | 为什么重要 |
|---|---|---|
| Python 基础 | 类型、函数、类、异常、包管理、虚拟环境 | 能读懂大多数 AI 示例 |
| HTTP/API | REST、鉴权、超时、重试、错误码 | 大模型和工具基本都靠 API 调用 |
| LLM 调用 | messages、temperature、stream、token、模型路由 | 所有 AI 应用的入口 |
| Prompt | System/User、变量填充、模板、少样本示例 | 决定模型行为边界 |
| 结构化输出 | JSON Schema、Pydantic、输出解析、重试修复 | 让模型结果可被程序使用 |
| Function Calling | 工具 Schema、参数校验、执行结果回填 | Agent 能行动的基础 |
| RAG | 文档切分、Embedding、向量库、召回、Rerank | 让模型使用企业知识 |
| Memory | 短期上下文、长期记忆、偏好、任务状态 | 支撑多轮协作和长任务 |
| Agent Loop | Plan、Act、Observe、Reflect、Stop | 让模型从问答变成执行者 |
| 异步与流式 | SSE、async/await、队列、超时取消 | 提升交互体验和吞吐 |
| 可观测性 | trace_id、请求体摘要、响应、耗时、错误码 | 方便排障和评估效果 |
| 安全治理 | 最小权限、脱敏、人工确认、沙箱、审计 | Agent 上生产的前提 |
| 评测 | 黄金集、自动评分、人工复核、回归测试 | 防止 Prompt 或模型升级导致效果倒退 |
下面进入代码对比。
四、调用大模型 API:Java 与 Python 对比
AI 应用的第一步通常是调用大模型。
Java:用 HttpClient 调用 Chat Completions
java
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
public class LlmClient {
private final HttpClient httpClient = HttpClient.newHttpClient();
private final String apiKey;
public LlmClient(String apiKey) {
this.apiKey = apiKey;
}
public String chat(String userMessage) throws Exception {
String body = """
{
"model": "gpt-4o-mini",
"messages": [
{"role": "system", "content": "你是一个客服工单助手,只输出简洁建议。"},
{"role": "user", "content": "%s"}
],
"temperature": 0.2
}
""".formatted(userMessage.replace("\"", "\\\""));
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://api.openai.com/v1/chat/completions"))
.header("Authorization", "Bearer " + apiKey)
.header("Content-Type", "application/json")
.POST(HttpRequest.BodyPublishers.ofString(body))
.build();
HttpResponse<String> response = httpClient.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() >= 400) {
throw new RuntimeException("LLM API error: " + response.statusCode() + ", body=" + response.body());
}
return response.body();
}
}Java 原生 HTTP 写法比较啰嗦,但你可以清楚控制超时、重试、日志、异常和连接池。
Python:用 OpenAI SDK 调用
python
from openai import OpenAI
client = OpenAI()
def chat(user_message: str) -> str:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "你是一个客服工单助手,只输出简洁建议。"},
{"role": "user", "content": user_message},
],
temperature=0.2,
)
return response.choices[0].message.contentPython 版本短很多,适合快速实验。你可以把更多精力放在 Prompt、输出结构、工具设计和业务逻辑上。
Java 开发者要注意什么
不要因为 Python 示例短,就忽略工程问题。真实项目里仍然要封装:
- API Key 读取与隔离;
- 超时设置;
- 429 限流处理;
- 5xx 重试;
- 请求体摘要日志;
- 响应脱敏;
- trace_id 贯穿;
- 模型和供应商可配置。
五、Prompt 模板:从字符串拼接到可维护模板
Java 开发者常习惯把 Prompt 当字符串拼接:
java
public class PromptBuilder {
public String buildTicketPrompt(String ticketText) {
return """
你是一个售后工单助手。
请判断下面工单的优先级,并给出处理建议。
工单内容:
%s
""".formatted(ticketText);
}
}Python 也可以这样写:
python
def build_ticket_prompt(ticket_text: str) -> str:
return f"""
你是一个售后工单助手。
请判断下面工单的优先级,并给出处理建议。
工单内容:
{ticket_text}
""".strip()但 Agent 项目里,Prompt 最好像代码一样管理:
python
from string import Template
TICKET_PROMPT = Template("""
你是一个售后工单助手。
你的任务:
1. 判断工单优先级:P0/P1/P2/P3
2. 给出处理建议
3. 说明是否需要人工介入
约束:
- 不要编造订单状态
- 如果信息不足,输出需要补充的信息
- 输出 JSON
工单内容:
$ticket_text
""")
def build_ticket_prompt(ticket_text: str) -> str:
return TICKET_PROMPT.substitute(ticket_text=ticket_text)Prompt 管理的关键不是"写得像文学作品",而是要可版本化、可测试、可回滚。
六、结构化输出:让模型结果能被程序消费
AI Agent 不能只返回一段自然语言。很多时候你需要模型输出结构化结果,比如工单优先级、下一步动作、工具参数。
Java:定义 DTO 接收模型输出
java
public record TicketAnalysis(
String priority,
boolean needHumanReview,
String reason,
String suggestedAction
) {}你可以用 Jackson 解析 JSON:
java
import com.fasterxml.jackson.databind.ObjectMapper;
public class OutputParser {
private final ObjectMapper mapper = new ObjectMapper();
public TicketAnalysis parse(String json) throws Exception {
return mapper.readValue(json, TicketAnalysis.class);
}
}Python:用 Pydantic 校验
python
from pydantic import BaseModel, Field
class TicketAnalysis(BaseModel):
priority: str = Field(description="P0/P1/P2/P3")
need_human_review: bool
reason: str
suggested_action: str
raw = """
{
"priority": "P1",
"need_human_review": true,
"reason": "用户涉及退款争议,需要人工确认订单状态",
"suggested_action": "查询订单和支付状态后转人工复核"
}
"""
analysis = TicketAnalysis.model_validate_json(raw)
print(analysis.priority)Python 的 Pydantic 在 AI 应用里非常常用,因为它可以同时承担:
- 参数 Schema;
- 输出校验;
- 类型提示;
- 错误信息;
- JSON 序列化。
模型输出不是天然可靠的。结构化输出一定要配合校验、失败重试和兜底策略。
七、Function Calling:Agent 调工具的核心机制
Function Calling 的本质是:把可调用的业务能力描述给模型,让模型决定是否调用、用什么参数调用,然后程序执行工具,再把结果交回模型。
假设我们有一个"查询订单状态"的工具。
Java:工具接口设计
java
public interface Tool<I, O> {
String name();
String description();
O execute(I input);
}
public record QueryOrderInput(String orderId) {}
public record QueryOrderOutput(String orderId, String status, boolean refundable) {}
public class QueryOrderTool implements Tool<QueryOrderInput, QueryOrderOutput> {
@Override
public String name() {
return "query_order";
}
@Override
public String description() {
return "根据订单 ID 查询订单状态和是否可退款";
}
@Override
public QueryOrderOutput execute(QueryOrderInput input) {
// 实际项目中这里调用订单系统
return new QueryOrderOutput(input.orderId(), "PAID", true);
}
}Python:函数就是天然工具
python
from pydantic import BaseModel
class QueryOrderInput(BaseModel):
order_id: str
class QueryOrderOutput(BaseModel):
order_id: str
status: str
refundable: bool
def query_order(params: QueryOrderInput) -> QueryOrderOutput:
# 实际项目中这里调用订单系统
return QueryOrderOutput(
order_id=params.order_id,
status="PAID",
refundable=True,
)Python 的优势是定义轻,函数、类型和 Schema 可以快速组合。Java 的优势是接口边界清晰,适合复杂工具系统、权限检查、审计和长期维护。
工具 Schema 示例
Function Calling 通常需要把工具描述成 JSON Schema:
python
query_order_schema = {
"type": "function",
"function": {
"name": "query_order",
"description": "根据订单 ID 查询订单状态和是否可退款",
"parameters": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "订单 ID"
}
},
"required": ["order_id"]
}
}
}工具设计时要记住三点:
- 工具描述要清楚,否则模型不知道什么时候调用;
- 参数要严格校验,否则会出现空参数、错字段、幻觉字段;
- 高风险工具必须有人审或权限控制,比如退款、删除、发消息、改配置。
八、Agent Loop:从一次问答到多步执行
传统聊天应用通常是"一问一答"。Agent 的核心是多步循环:
text
用户目标 -> 模型规划 -> 调用工具 -> 观察结果 -> 判断是否继续 -> 输出结果Java:状态机思路
Java 更适合把 Agent Loop 显式建模成状态机:
java
public enum AgentStepType {
PLAN,
ACT,
OBSERVE,
FINISH
}
public record AgentStep(
AgentStepType type,
String content
) {}
public class AgentRunner {
private static final int MAX_STEPS = 5;
public String run(String userGoal) {
String context = userGoal;
for (int i = 0; i < MAX_STEPS; i++) {
AgentStep step = planNextStep(context);
if (step.type() == AgentStepType.FINISH) {
return step.content();
}
if (step.type() == AgentStepType.ACT) {
String toolResult = executeTool(step.content());
context += "\n工具结果:" + toolResult;
}
}
return "任务未在最大步数内完成,建议转人工处理。";
}
private AgentStep planNextStep(String context) {
// 实际项目中这里调用 LLM
return new AgentStep(AgentStepType.FINISH, "已完成分析");
}
private String executeTool(String toolCall) {
return "工具执行结果";
}
}Python:快速实现 ReAct 循环
python
MAX_STEPS = 5
def run_agent(user_goal: str) -> str:
context = [
{"role": "user", "content": user_goal}
]
for step in range(MAX_STEPS):
decision = call_llm_for_next_action(context)
if decision["type"] == "finish":
return decision["answer"]
if decision["type"] == "tool_call":
tool_name = decision["tool_name"]
tool_args = decision["arguments"]
observation = execute_tool(tool_name, tool_args)
context.append({
"role": "tool",
"content": observation,
})
return "任务达到最大执行步数,建议转人工处理。"
def call_llm_for_next_action(context: list[dict]) -> dict:
# 实际项目中这里调用大模型,并解析结构化输出
return {"type": "finish", "answer": "已完成分析"}
def execute_tool(tool_name: str, arguments: dict) -> str:
# 根据 tool_name 路由到具体工具函数
return "工具执行结果"Agent Loop 必须有停止条件。没有最大步数、最大耗时、最大工具调用次数的 Agent,很容易在异常场景里无限循环或不断烧 token。
九、RAG:让模型回答基于你的知识库
RAG(Retrieval-Augmented Generation)是 AI 应用开发绕不开的能力。它解决的问题是:模型不知道你的企业文档、订单规则、产品说明、内部 SOP,那就先检索相关知识,再把知识放进上下文让模型回答。
Java:RAG 服务接口思路
java
public record DocumentChunk(String id, String text, double score) {}
public interface VectorStore {
List<DocumentChunk> similaritySearch(String query, int topK);
}
public class RagService {
private final VectorStore vectorStore;
private final LlmClient llmClient;
public RagService(VectorStore vectorStore, LlmClient llmClient) {
this.vectorStore = vectorStore;
this.llmClient = llmClient;
}
public String answer(String question) throws Exception {
List<DocumentChunk> chunks = vectorStore.similaritySearch(question, 5);
String context = chunks.stream()
.map(DocumentChunk::text)
.reduce("", (a, b) -> a + "\n---\n" + b);
String prompt = """
请只根据下面资料回答问题。如果资料不足,请说不知道。
资料:
%s
问题:
%s
""".formatted(context, question);
return llmClient.chat(prompt);
}
}Python:RAG 最小实现
python
from dataclasses import dataclass
@dataclass
class DocumentChunk:
id: str
text: str
score: float
def similarity_search(query: str, top_k: int = 5) -> list[DocumentChunk]:
# 实际项目中这里调用向量库,如 Milvus、Qdrant、pgvector、Elasticsearch
return [
DocumentChunk("doc-1", "退款规则:已支付未发货订单可申请退款。", 0.91),
DocumentChunk("doc-2", "高风险退款需要人工复核。", 0.86),
]
def rag_answer(question: str) -> str:
chunks = similarity_search(question, top_k=5)
context = "\n---\n".join(chunk.text for chunk in chunks)
prompt = f"""
请只根据下面资料回答问题。如果资料不足,请说不知道。
资料:
{context}
问题:
{question}
""".strip()
return chat(prompt)RAG 不是"向量库一接就完事"。真正影响效果的是:
- 文档切分粒度;
- metadata 设计;
- query 改写;
- 混合检索;
- rerank;
- 上下文压缩;
- 引用来源;
- 召回失败兜底;
- 权限过滤。
Java 后端开发者可以把 RAG 理解成一个"搜索系统 + LLM 总结器"。搜索质量决定上限,Prompt 只是在已有资料上做组织和表达。
十、Memory:Agent 为什么需要记忆
Memory 和 RAG 不完全一样。
RAG 通常检索外部知识,比如产品文档、制度、接口说明。Memory 更像 Agent 与用户或任务过程相关的状态,例如:
- 当前任务目标;
- 用户偏好;
- 已完成步骤;
- 已调用工具结果;
- 上一次失败原因;
- 长期协作规则。
Java:任务状态对象
java
import java.time.Instant;
import java.util.ArrayList;
import java.util.List;
public class AgentMemory {
private String userId;
private String currentGoal;
private List<String> observations = new ArrayList<>();
private Instant updatedAt = Instant.now();
public void addObservation(String observation) {
observations.add(observation);
updatedAt = Instant.now();
}
public List<String> recentObservations(int limit) {
int from = Math.max(0, observations.size() - limit);
return observations.subList(from, observations.size());
}
}Python:轻量记忆实现
python
from dataclasses import dataclass, field
from datetime import datetime
@dataclass
class AgentMemory:
user_id: str
current_goal: str
observations: list[str] = field(default_factory=list)
updated_at: datetime = field(default_factory=datetime.utcnow)
def add_observation(self, observation: str) -> None:
self.observations.append(observation)
self.updated_at = datetime.utcnow()
def recent_observations(self, limit: int = 5) -> list[str]:
return self.observations[-limit:]Memory 的难点不是存,而是什么该存、什么时候存、谁能看、多久过期、如何召回。建议遵循:
- 默认不存敏感信息;
- 写入长期记忆要有来源和时间;
- 偏好类记忆要可撤销;
- 任务状态和用户偏好分开存;
- 召回时做权限过滤和时效过滤。
十一、异步、并发与流式输出
AI 应用经常会遇到慢请求:模型生成慢、RAG 检索慢、工具调用慢。如果所有操作都同步阻塞,用户体验会很差。
Java:CompletableFuture 并发调用
java
import java.util.concurrent.CompletableFuture;
public class ParallelAgentService {
public CompletableFuture<String> handle(String question) {
CompletableFuture<String> profileFuture = CompletableFuture.supplyAsync(() -> queryUserProfile(question));
CompletableFuture<String> policyFuture = CompletableFuture.supplyAsync(() -> queryPolicy(question));
return profileFuture.thenCombine(policyFuture, (profile, policy) -> {
String prompt = "用户信息:" + profile + "\n规则资料:" + policy + "\n问题:" + question;
try {
return new LlmClient(System.getenv("OPENAI_API_KEY")).chat(prompt);
} catch (Exception e) {
throw new RuntimeException(e);
}
});
}
private String queryUserProfile(String question) {
return "普通会员";
}
private String queryPolicy(String question) {
return "已支付未发货订单可申请退款";
}
}Python:async/await 并发调用
python
import asyncio
async def query_user_profile(question: str) -> str:
await asyncio.sleep(0.1)
return "普通会员"
async def query_policy(question: str) -> str:
await asyncio.sleep(0.1)
return "已支付未发货订单可申请退款"
async def handle(question: str) -> str:
profile, policy = await asyncio.gather(
query_user_profile(question),
query_policy(question),
)
prompt = f"用户信息:{profile}\n规则资料:{policy}\n问题:{question}"
return chat(prompt)Python 的异步写法非常适合 I/O 密集型 AI 应用,比如并发查多个知识库、并发调用多个工具、流式返回模型输出。
十二、流式响应:让用户更快看到结果
AI 聊天产品通常会流式输出,不等模型全部生成完。
Java:Spring WebFlux 返回流
java
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import java.time.Duration;
@RestController
public class StreamController {
@GetMapping(value = "/chat/stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> stream(@RequestParam String q) {
return Flux.just("正在分析问题...", "查询相关资料...", "生成处理建议...", "完成")
.delayElements(Duration.ofMillis(300));
}
}Python:FastAPI StreamingResponse
python
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
import asyncio
app = FastAPI()
async def token_generator(question: str):
for token in ["正在分析问题...", "查询相关资料...", "生成处理建议...", "完成"]:
yield f"data: {token}\n\n"
await asyncio.sleep(0.3)
@app.get("/chat/stream")
async def stream(question: str):
return StreamingResponse(
token_generator(question),
media_type="text/event-stream",
)如果你熟悉 Java SSE,再学 Python FastAPI 流式响应会很快。关键是注意:连接超时、客户端断开、模型中断、异常事件、心跳保活。
十三、LangChain、Spring AI、LangChain4j 怎么选
Java 开发者转 AI Agent,经常会问:我一定要用 Python LangChain 吗?不一定。
常见选择:
- Python LangChain:资料最多,生态最完整,适合学习 Agent/RAG/Tool/Chain;
- LlamaIndex:偏数据连接、知识库、RAG;
- AutoGen/CrewAI:偏多 Agent 协作实验;
- LangGraph:偏状态机式 Agent,适合复杂流程;
- Spring AI:适合 Spring 技术栈团队,把 AI 能力接入 Java 后端;
- LangChain4j:Java 生态里比较常用的 LLM 应用开发框架。
我的建议:
- 学概念和快速实验,用 Python;
- 做企业 Java 系统接入,用 Spring AI 或 LangChain4j;
- 做复杂 Agent 状态编排,重点理解 LangGraph 的状态机思想;
- 不要被框架绑架,先把 LLM、Prompt、Tool、RAG、Memory、Eval 这些底层概念吃透。
十四、可观测性:AI 应用必须能排障
Java 后端开发者很重视日志、指标、链路追踪。这一点在 AI Agent 里更重要。
一次 Agent 请求至少应该记录:
- trace_id;
- user_id 或租户信息;
- 模型名称;
- Prompt 版本;
- 工具调用名称;
- 工具参数摘要;
- 检索命中文档 ID;
- token 消耗;
- 各阶段耗时;
- 错误码;
- 是否触发人工确认;
- 最终结果状态。
Python 日志示例
python
import logging
import time
import uuid
logger = logging.getLogger("agent")
def handle_request(user_id: str, question: str) -> str:
trace_id = str(uuid.uuid4())
start = time.time()
try:
logger.info("agent_request_start", extra={
"trace_id": trace_id,
"user_id": user_id,
"question_len": len(question),
})
answer = rag_answer(question)
logger.info("agent_request_success", extra={
"trace_id": trace_id,
"latency_ms": int((time.time() - start) * 1000),
})
return answer
except Exception as e:
logger.exception("agent_request_failed", extra={
"trace_id": trace_id,
"error_type": type(e).__name__,
})
raise注意:日志要脱敏,不要把 API Key、身份证、手机号、完整支付信息、隐私内容直接打出来。
十五、安全治理:Agent 比普通接口更需要边界
传统后端接口通常是用户点按钮,服务执行固定动作。Agent 不一样,它可能会根据上下文主动决定调用哪个工具,所以安全边界必须更严格。
建议至少做这些控制:
- 最小权限:Agent 只拿当前任务需要的工具;
- 工具分级:只读工具、低风险写工具、高风险写工具分开;
- 人工确认:退款、删除、发通知、改配置等动作必须确认;
- 参数校验:模型生成的工具参数不能直接信;
- 沙箱隔离:文件、网络、命令执行要有限制;
- 凭据保护 :不要把长期密钥直接暴露给
Agent; - 审计日志:谁触发、模型为什么调用、参数是什么、结果是什么,都要能追溯;
- 提示注入防护:外部文档、网页、邮件、工单内容都只能当数据,不能当系统指令。
Python 工具执行前的安全检查示例
python
from enum import Enum
class RiskLevel(str, Enum):
READ = "read"
LOW_WRITE = "low_write"
HIGH_WRITE = "high_write"
TOOL_RISK = {
"query_order": RiskLevel.READ,
"create_ticket_note": RiskLevel.LOW_WRITE,
"refund_order": RiskLevel.HIGH_WRITE,
}
def execute_tool_safely(tool_name: str, arguments: dict, approved: bool = False):
risk = TOOL_RISK.get(tool_name)
if risk is None:
raise ValueError(f"未知工具:{tool_name}")
validate_arguments(tool_name, arguments)
if risk == RiskLevel.HIGH_WRITE and not approved:
return {
"status": "need_approval",
"message": "该操作风险较高,需要人工确认后执行",
"tool": tool_name,
"arguments_summary": summarize_arguments(arguments),
}
return execute_tool(tool_name, arguments)这段代码表达的核心思想是:模型可以建议动作,但程序必须控制动作是否真的执行。
十六、测试与评测:AI 应用不能只靠肉眼试
Java 项目通常有单元测试、集成测试、接口测试。AI Agent 也需要测试,只是测试对象更复杂。
至少要测这些:
- Prompt 改动后,典型问题是否仍然答对;
- 工具参数是否稳定生成;
- RAG 召回是否命中正确资料;
- 结构化输出是否能通过 Schema;
- 高风险操作是否触发人工确认;
- 异常场景是否降级,而不是无限重试;
- 模型升级后效果是否退化。
Python 简单评测示例
python
from pydantic import BaseModel
class EvalCase(BaseModel):
question: str
expected_keywords: list[str]
cases = [
EvalCase(
question="用户已支付但未发货,可以退款吗?",
expected_keywords=["可申请退款", "未发货"],
),
EvalCase(
question="高风险退款是否需要人工复核?",
expected_keywords=["人工复核"],
),
]
def test_rag_answer_quality():
for case in cases:
answer = rag_answer(case.question)
for keyword in case.expected_keywords:
assert keyword in answer这不是完美评测,但它能避免最基本的回归问题。随着项目成熟,可以继续引入 LLM-as-Judge、人工标注集、线上反馈和灰度实验。
十七、Java 转 AI Agent 的推荐学习路线
如果你已经会 Java 后端,我建议按下面 6 个阶段学习。
阶段 1:Python 工程基础
目标:能读写常见 Python AI 项目。
重点学:
- Python 语法、函数、类、异常;
- venv/uv/pip/poetry;
- dataclass、typing、Pydantic;
- requests/httpx;
- FastAPI;
- pytest。
建议练习:用 FastAPI 写一个 /chat 接口,内部调用大模型 API。
阶段 2:大模型 API 与 Prompt
目标:理解 LLM 应用的基本输入输出。
重点学:
- messages 格式;
- system/user/assistant role;
- temperature、top_p、max_tokens;
- streaming;
- token 成本;
- Prompt 模板与版本管理。
建议练习:做一个客服工单分析接口,输出优先级、原因和建议动作。
阶段 3:结构化输出与工具调用
目标:让模型结果进入程序流程。
重点学:
- JSON Schema;
- Pydantic 校验;
- Function Calling;
- 工具注册表;
- 参数校验;
- 错误重试;
- 高风险工具确认。
建议练习:做一个订单助手,能查询订单、判断退款条件,但退款动作必须人工确认。
阶段 4:RAG 知识库问答
目标:让模型基于企业资料回答。
重点学:
- 文档加载;
- 文档切分;
- Embedding;
- 向量数据库;
- TopK 召回;
- Rerank;
- 引用来源;
- 权限过滤。
建议练习:把一份售后规则文档切分入库,做一个带引用来源的问答接口。
阶段 5:Agent Loop 与 Memory
目标:让模型能多步执行任务。
重点学:
- ReAct;
- Plan-Act-Observe;
- Self-Reflection;
- 最大步数;
- 任务状态;
- 短期上下文;
- 长期记忆;
- 失败恢复。
建议练习:做一个"工单处理 Agent",能读取工单、查规则、查订单、判断是否转人工、生成处理建议。
阶段 6:生产化工程
目标:让 Agent 能上线、能排障、能迭代。
重点学:
- 日志脱敏;
- trace_id;
- token 成本监控;
- 模型路由;
- 限流熔断;
- 沙箱;
- 权限;
- 评测集;
- 灰度发布;
- 人工反馈闭环。
建议练习:把前面的工单 Agent 做成一个可观测、可评测、可回滚的小系统。
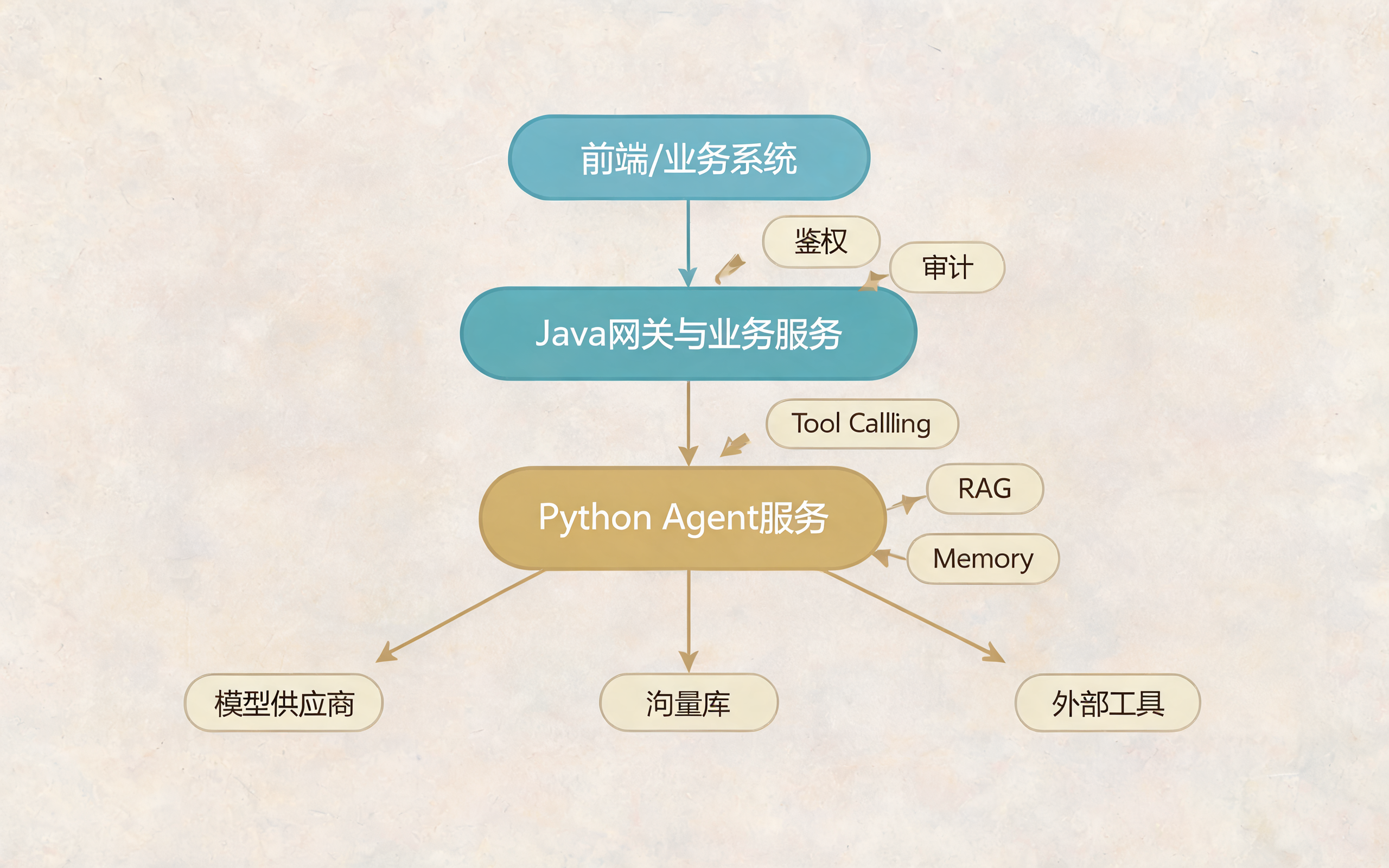
Java 与 Python 协作架构:业务边界与 Agent 编排
十八、Java 和 Python 在 AI Agent 项目里的协作架构
实际项目中,不一定要"放弃 Java,全面改 Python"。更常见的架构是两者协作。
text
前端/业务系统
↓
Java 网关与业务服务
- 鉴权
- 用户与租户
- 订单/支付/工单系统
- 审计日志
- 限流熔断
↓
Python Agent 服务
- LLM 调用
- Prompt 编排
- Tool Calling
- RAG
- Memory
- Eval
↓
模型供应商 / 向量库 / 外部工具这种方式有几个好处:
- Java 继续负责稳定业务边界;
- Python 快速迭代 AI 能力;
- 高风险动作仍由 Java 业务服务做权限和事务控制;
- Agent 只通过受控 API 调用业务能力;
- 后续稳定能力可以逐步服务化或迁回 Java。
十九、常见误区
误区 1:会 Python 就会 AI Agent
Python 只是入口。Agent 开发的核心是模型行为控制、工具边界、RAG 质量、状态管理和安全治理。
误区 2:Prompt 写长一点就稳定
Prompt 不是越长越好。稳定性来自清晰任务、结构化输出、可校验工具、失败重试、评测集和日志。
误区 3:RAG 等于向量库
向量库只是存储和召回组件。RAG 还包括切分、metadata、权限、rerank、引用、上下文压缩和答案约束。
误区 4:Agent 可以直接操作所有工具
生产环境里,Agent 不应该拥有无限工具权限。它应该通过工具注册、权限分级、人工确认和审计来行动。
误区 5:AI 应用不需要传统工程能力
恰恰相反,AI 应用更需要传统工程能力。因为模型不确定性更高,日志、测试、评测、监控、安全边界都更重要。
二十、总结
对 Java 开发者来说,转 AI Agent 开发的关键不是"抛弃 Java",而是补上 Python 与 AI 应用开发的能力拼图。
你需要掌握:
- Python 基础与工程组织;
- 大模型 API 调用;
- Prompt 模板与版本管理;
- 结构化输出;
- Function Calling 与工具系统;
- RAG 知识库;
- Memory 与任务状态;
- Agent Loop;
- 异步与流式响应;
- 可观测性、安全治理和评测。
如果你已经有 Java 后端经验,其实优势很大。你熟悉接口、权限、日志、事务、缓存、队列、监控和稳定性,这些正是 Agent 从 Demo 走向生产最需要的能力。Python 只是帮你更快进入 AI 生态,而真正决定系统能不能上线的,仍然是工程能力。
最好的学习方式不是一口气看完所有框架,而是从一个小项目开始:做一个工单处理 Agent。它包含 LLM 调用、结构化输出、工具调用、RAG、Memory、人工确认、日志和评测。把这个项目做完整,你就已经跨过了从 Java 后端到 AI Agent 开发的第一道门槛。