
1. Tensor 是 PyTorch 的基本单位
PyTorch 里,模型吃进去的是 Tensor,参数保存的是 Tensor,梯度也是 Tensor,GPU 上跑的还是 Tensor。
你可以把 Tensor 理解成"加强版数组"。但这个说法不够准确。
|---------------------------------------------------|
| **一句话:**Tensor = 数据 + 形状 + 类型 + 设备 + 内存布局 + 梯度关系。 |
普通数组只关心数值。Tensor 还关心这些数在哪里、怎么排、用什么精度、是否参与反向传播、由哪个后端执行。
官方 README 对 PyTorch 的核心定位很直接:它提供类似 NumPy 的 Tensor 计算,并且带强 GPU 加速;同时提供基于 autograd 的神经网络能力。
2. Tensor 的维度:别被高维吓住
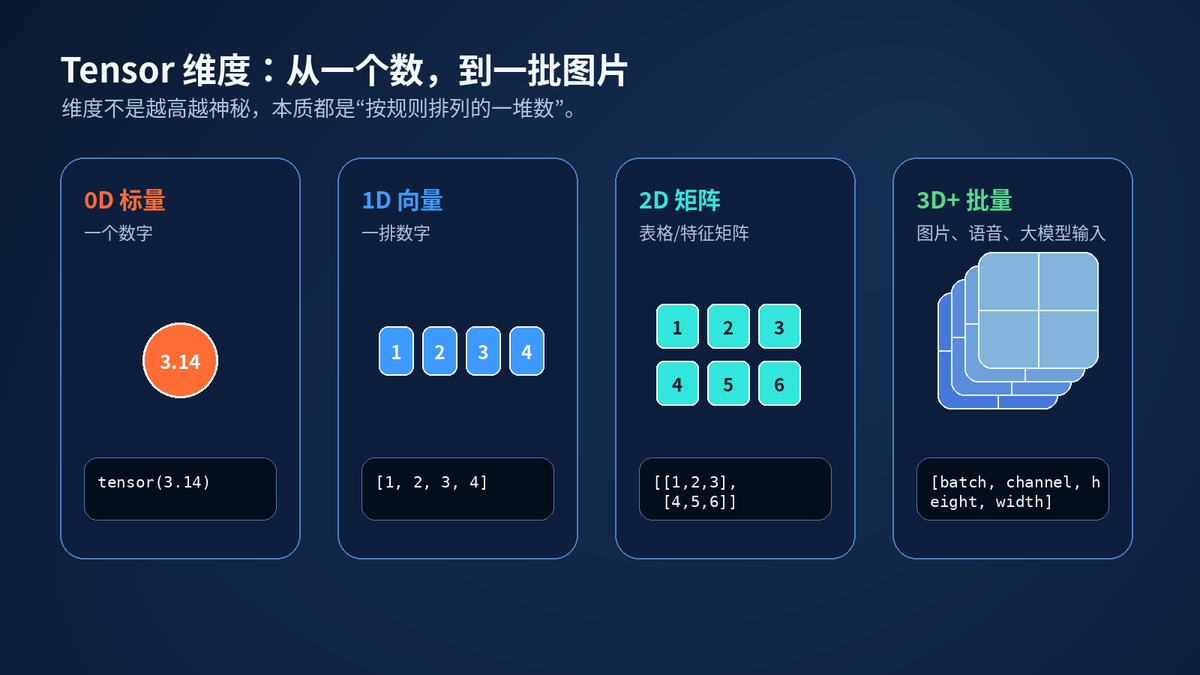
Tensor 维度从标量、向量、矩阵到批量数据。
0 维 Tensor 是一个数。1 维 Tensor 是一排数。2 维 Tensor 像一张表。3 维、4 维 Tensor 就是很多张表叠起来。
图像分类里,常见输入是 batch, channel, height, width。文本模型里,常见输入是 batch, sequence_length。大模型里,Embedding 后会变成 batch, sequence_length, hidden_size。
import torch
x = torch.tensor(\[1, 2, 3, 4, 5, 6])
print(x.shape) # torch.Size(2, 3)
print(x.ndim) # 2
print(x.dtype) # torch.int64
print(x.device) # cpu
这段代码简单,但它暴露了 Tensor 的四个核心入口:shape、ndim、dtype、device。后面所有训练问题,很多都能回到这四个字段上排查。
3. Tensor 的本体:不是一个字段,而是一组元信息
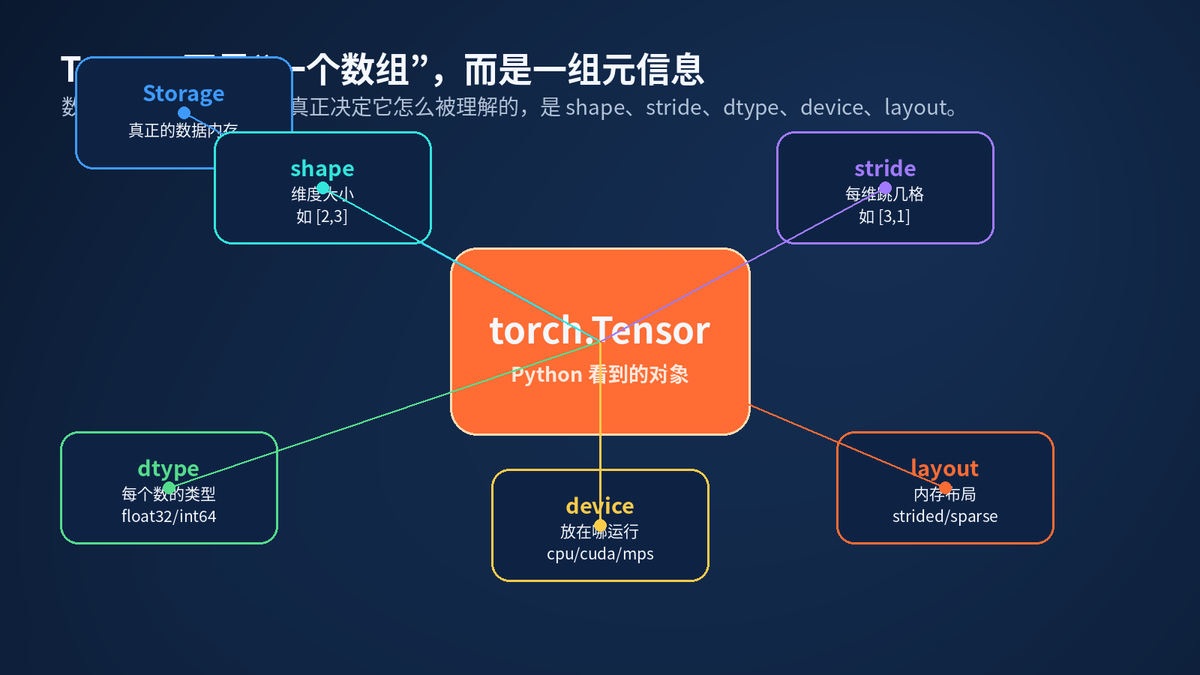
Tensor 的核心组成:Storage、shape、stride、dtype、device、layout。
很多人以为 Tensor 本身就是一坨连续数据。其实更准确地说:Tensor 是一套"解释数据的规则"。
Storage 保存真实数据。shape 决定看成几行几列。stride 决定从一个元素走到下一个元素,要在底层内存里跳几步。dtype 决定每个数字占多大空间。device 决定这块数据放在 CPU、CUDA GPU 还是 MPS 后端。
所以,同一块 Storage,可以被不同的 shape 和 stride 解释成不同的 Tensor 视图。这个思想非常关键。它决定了 view、transpose、permute 为什么可以很快。
4. dtype 和 device:Tensor 的两张身份证

dtype 决定数值格式,device 决定计算设备。
dtype 管"一个数怎么存"。float32、float16、bfloat16、int64,本质都是数字格式。
device 管"这些数在哪算"。CPU 上的 Tensor 不能直接和 CUDA Tensor 混算。因为一个在主机内存,一个在显存。它们不是同一个地方。
x = torch.randn(2, 3, dtype=torch.float32, device='cpu')
有 NVIDIA GPU 时常见写法
x = x.to('cuda')
Apple Silicon 上常见写法
x = x.to('mps')
|-----------------------------------------------------------|
| **工程经验:**模型、输入、标签必须放在正确设备上。尤其是模型在 cuda,输入还在 cpu,是新手最常见错误。 |
训练大模型时,dtype 更敏感。float32 稳,但显存大。float16 和 bfloat16 更省显存,也更快,但要配合混合精度和数值稳定性策略。
5. Storage + Stride:Tensor 真正难懂的地方
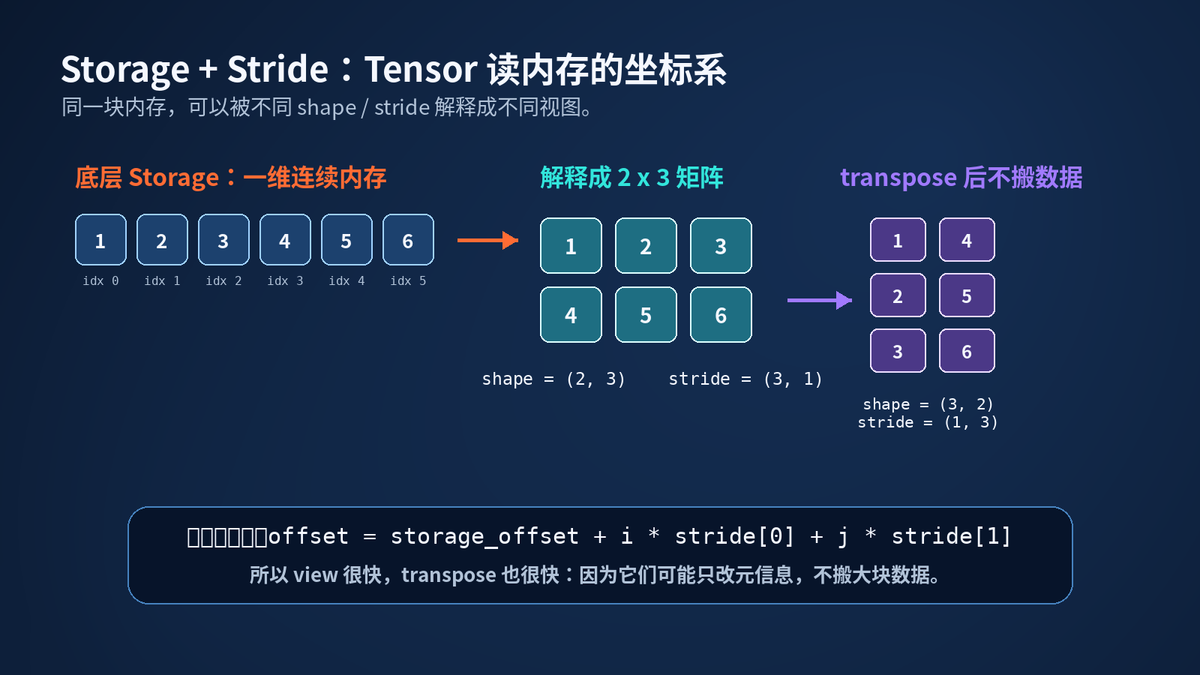
Storage 是底层一维内存,Stride 决定多维坐标怎么映射到内存。
假设底层 Storage 是 1, 2, 3, 4, 5, 6。如果 shape 是 (2, 3),stride 是 (3, 1),它就被解释成两行三列。
访问第 i 行第 j 列时,PyTorch 不是真的去找"二维数组"。它会算一个内存偏移:offset = storage_offset + i * stride0 + j * stride1。
这就是 Tensor 的强大之处:很多变形操作,不需要搬数据,只改元信息。
x = torch.arange(1, 7).reshape(2, 3)
print(x)
tensor(\[1, 2, 3,
4, 5, 6])
print(x.stride()) # (3, 1)
y = x.t()
print(y.shape) # torch.Size(3, 2)
print(y.stride()) # (1, 3)
print(y.is_contiguous()) # False
transpose 之后,数据没有重新排列。只是读取顺序变了。所以它很快。但代价是:新 Tensor 可能不连续。
6. view、reshape、permute:看起来像一类,其实不一样
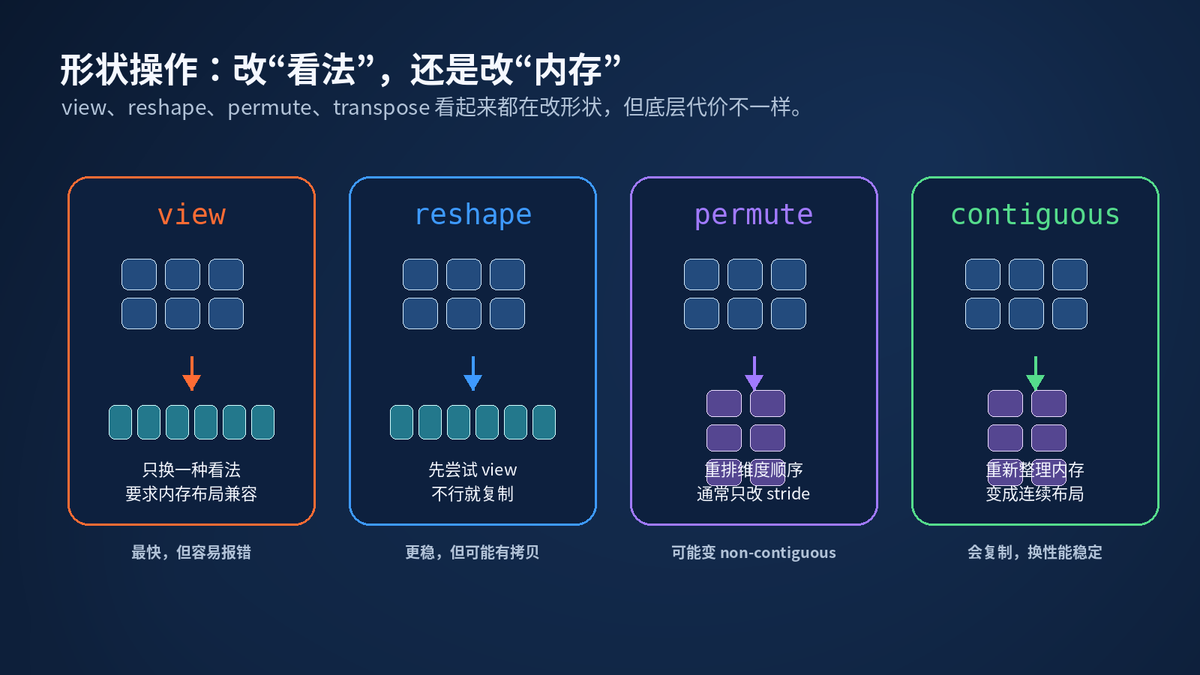
view 是"换一种看法"。它要求底层内存布局满足条件。满足就快,不满足就报错。
reshape 更温和。它会先尝试返回 view。实在不行,就复制一份连续内存。
permute 和 transpose 常常只改 stride,不搬数据。所以它们很快,但会让 Tensor 变成 non-contiguous。
contiguous 则相反。它会把数据重新整理成连续内存。可能慢,但后续算子更稳定。
x = torch.arange(12).reshape(3, 4)
y = x.t() # 转置后通常 non-contiguous
y.view(12) # 可能报错
z = y.reshape(12) # 更安全,必要时会复制
z2 = y.contiguous().view(12)
|--------------------------------------------------------------------|
| **记忆方式:**view 快,但挑内存;reshape 稳,但可能偷偷复制;permute 改顺序;contiguous 真整理。 |
7. Tensor 创建:不要只会 torch.tensor
PyTorch 创建 Tensor 的方式很多。每种方式都有明确场景。
torch.tensor 适合从 Python 数据创建新 Tensor。torch.zeros、torch.ones、torch.randn 适合快速初始化。torch.empty 只分配内存,不保证内容干净。from_numpy 可以和 NumPy 共享内存,要注意副作用。
a = torch.tensor(1, 2, 3) # 从 Python 数据创建
b = torch.zeros(2, 3) # 全 0
c = torch.ones(2, 3) # 全 1
d = torch.randn(2, 3) # 正态分布随机数
e = torch.empty(2, 3) # 只分配,不初始化
推荐:跟随已有 Tensor 的 dtype 和 device
f = torch.zeros_like(d)
g = torch.randn_like(d)
工程里更推荐使用 zeros_like、ones_like、randn_like。它们能自动继承已有 Tensor 的 dtype 和 device,减少设备不一致问题。
8. 广播机制:小 Tensor 为什么能和大 Tensor 相加
广播不是复制一堆数据。广播是让小 Tensor 按规则"看起来像"大 Tensor。
例如,一个 2, 3 的矩阵加一个 3 的向量,PyTorch 会把 3 看成每一行都可用。
x = torch.tensor(\[1, 2, 3, 4, 5, 6])
bias = torch.tensor(10, 20, 30)
print(x + bias)
tensor(\[11, 22, 33,
14, 25, 36])
广播让代码更短,也让计算更高效。但广播也容易隐藏 shape 问题。模型输出和标签维度不一致时,可能不会立刻报错,而是悄悄广播,最后 loss 变得很奇怪。
9. Tensor 在底层长什么样
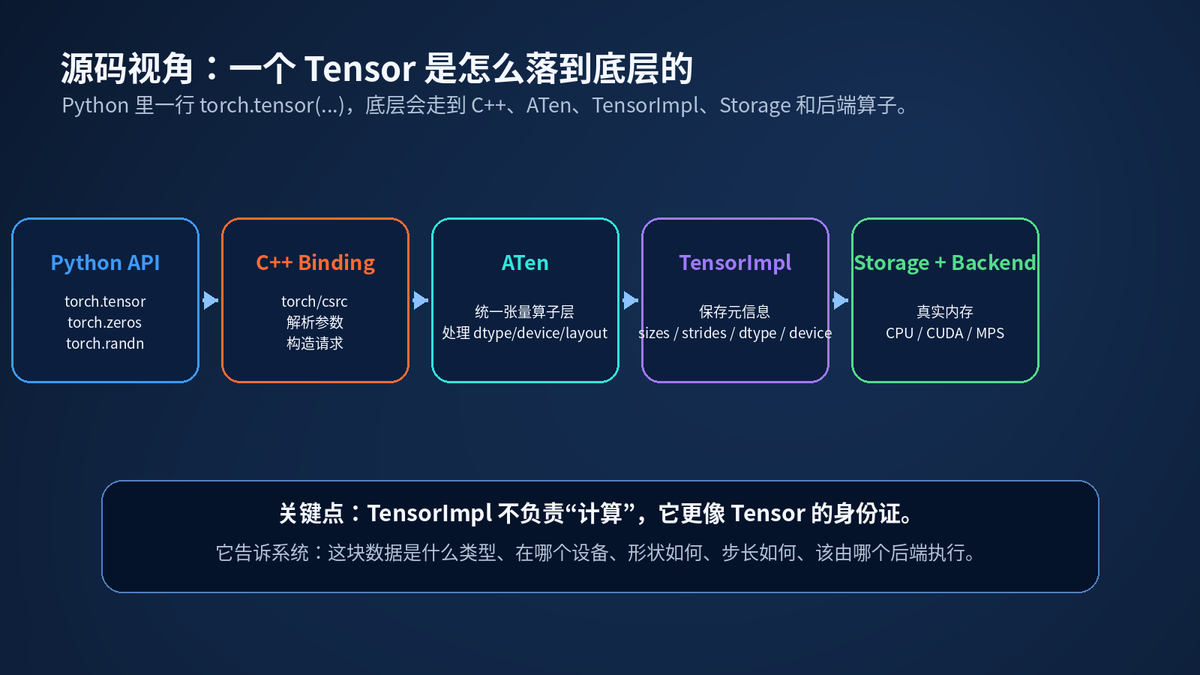
在 Python 里,Tensor 看起来是一个 Python 对象。但 PyTorch 不是纯 Python 框架。关键数据结构和高性能算子主要在 C++ 层。
从源码角度看,Tensor 的核心不是 Python 这层壳,而是底层的 TensorImpl。TensorImpl 负责保存 Tensor 的核心元信息,例如 sizes、strides、dtype、device、layout、storage 等。
你可以把 TensorImpl 理解成 Tensor 的身份证。它不等于真实数据,也不等于计算本身。它告诉 PyTorch:这块数据如何被解释,应该走哪个后端。
// 简化理解,不是完整源码
class TensorImpl {
Storage storage_; // 数据存在哪里
SizesAndStrides sizes_; // shape 和 stride
TypeMeta dtype_; // 数据类型
Device device_; // cpu / cuda / mps
DispatchKeySet key_set_; // 该走哪个后端算子
};
真正执行加法、矩阵乘法、卷积时,PyTorch 会根据 dtype、device、layout、dispatch key 选择对应后端实现。CPU 走 CPU kernel,CUDA 走 CUDA kernel,MPS 走 MPS 后端。
这也是为什么 Tensor 的 device 不一致会报错:它们背后可能根本不是同一套执行后端。
10. Tensor 和自动求导的关系
Tensor 还可以带梯度关系。只要 requires_grad=True,PyTorch 就会在你做计算时记录操作,构建反向传播图。
x = torch.tensor(2.0, requires_grad=True)
y = x * x + 3 * x
y.backward()
print(x.grad) # tensor(7.)
这段代码里的 x 不只是一个数字。它还带着 requires_grad 标记。y 的计算过程会被 autograd 记录。调用 backward 后,梯度会回到 x.grad。
后面讲自动求导时,我们会深入 grad_fn、叶子节点、计算图、反向传播引擎。现在只需要记住:能求导,是 Tensor 的核心能力之一。
11. 新手最容易踩的坑

第一个坑:模型在 GPU,输入在 CPU。报错通常很长,但核心就一句:device 不一致。
第二个坑:标签 dtype 错。分类任务里的 CrossEntropyLoss 通常希望 target 是类别索引,也就是 long/int64。
第三个坑:transpose 后直接 view。因为 Tensor 可能已经 non-contiguous。
第四个坑:reshape 以为零成本。它不一定复制,但也不保证不复制。性能敏感时要小心。
第五个坑:对参与求导的 Tensor 乱用原地操作,例如 add_、relu_、copy_。原地操作可能破坏 autograd 需要的中间值。
12. 总结
Tensor 是 PyTorch 的第一块地基。学 PyTorch,不要先背 API。先理解 Tensor 的本质。
它不是数组。它是"数据 + 元信息 + 设备 + 内存视图 + 梯度能力"的组合体。
shape 决定外形。dtype 决定数值格式。device 决定计算位置。stride 决定如何读内存。storage 保存真实数据。requires_grad 决定是否进入自动求导。
理解这些,你再看 nn.Module、DataLoader、autograd、CUDA、分布式,就不会觉得它们是孤立模块。它们全都围绕 Tensor 运转。