分页别写太顺手,LIMIT 背后还有排序和边界
MySQL 里写分页,最常见的就是 limit。取前几条写 limit 10,分页写 limit 10 offset 20,老代码里还经常能看到 limit 20, 10 这种逗号写法。切到 KingbaseES 后,这几个写法不能靠印象判断,先在当前环境里跑一遍。
这次准备了一张很小的表,只有 30 行数据。字段也故意简单:id、title、category、score、created_at。id 手动写死,后面查分页结果时不用猜顺序。
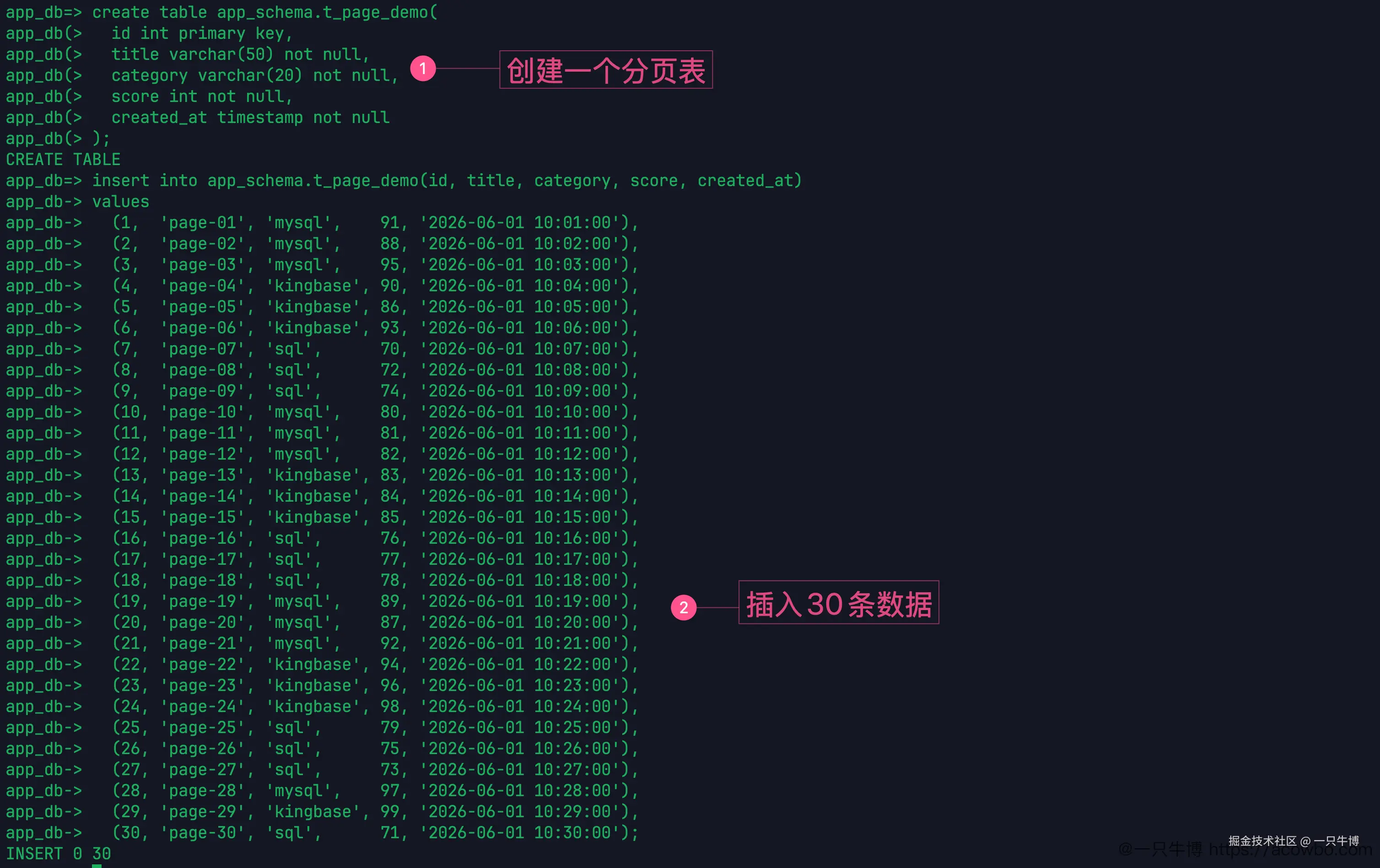
这张表没有用自增主键,也没有放太多业务字段,原因很简单:分页实验先别让数据本身干扰判断。id 从 1 到 30 固定下来,后面看到 1-5、6-10、11-15,就能马上判断 offset 有没有按预期生效。score 暂时只是辅助字段,不在这里展开排行榜或同分排序。
这类小表不能拿来谈性能。30 行数据只适合验证语法和结果位置,不能说明大表分页代价。性能问题留到后面单独测,这里先把 SQL 写法跑明白。
表建好以后,从最简单的 limit 5 开始:
sql
select id, title, category, score
from app_schema.t_page_demo
order by id
limit 5;结果返回 1 到 5。这个写法和 MySQL 习惯一致,在当前 V009R001C010 环境里可以直接跑。
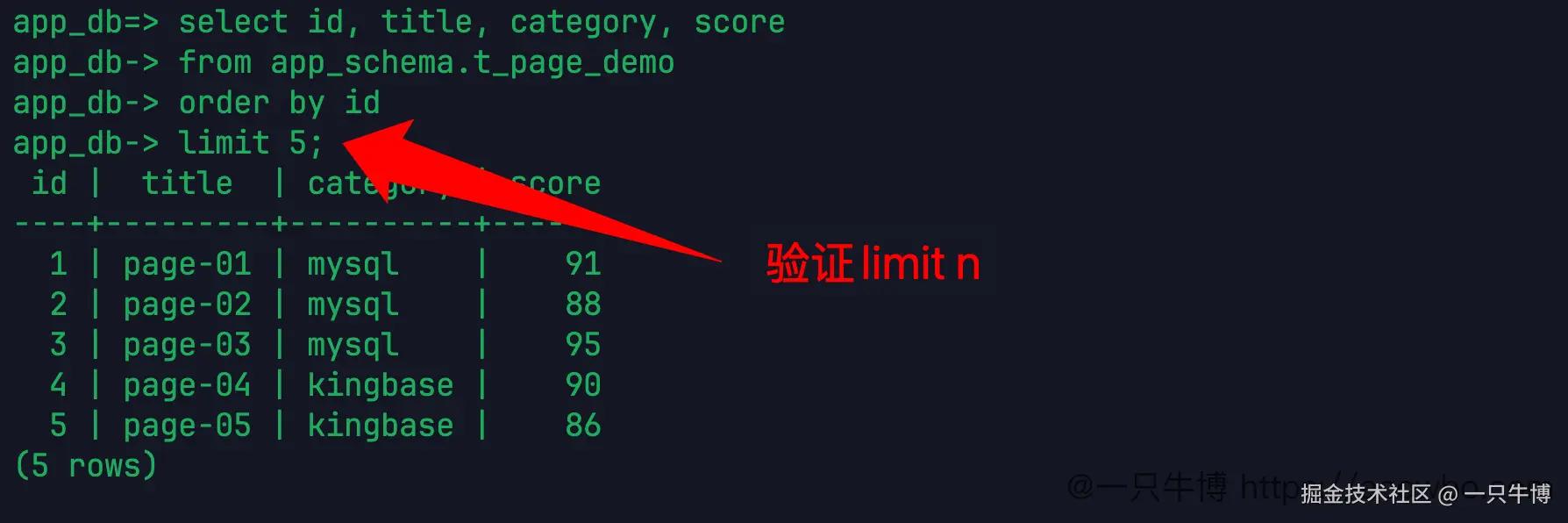
这里有一个细节不要省:order by id。如果只是取几条临时看数据,不写排序也能返回结果;但只要叫"前 5 条",就应该先说清楚按什么顺序算前 5 条。这里按 id 排,返回 1 到 5 才有明确含义。
接着看分页。limit 5 offset 0 返回第一页,limit 5 offset 5 返回第二页,limit 5 offset 10 返回第三页。当前输出分别是 1-5、6-10、11-15。
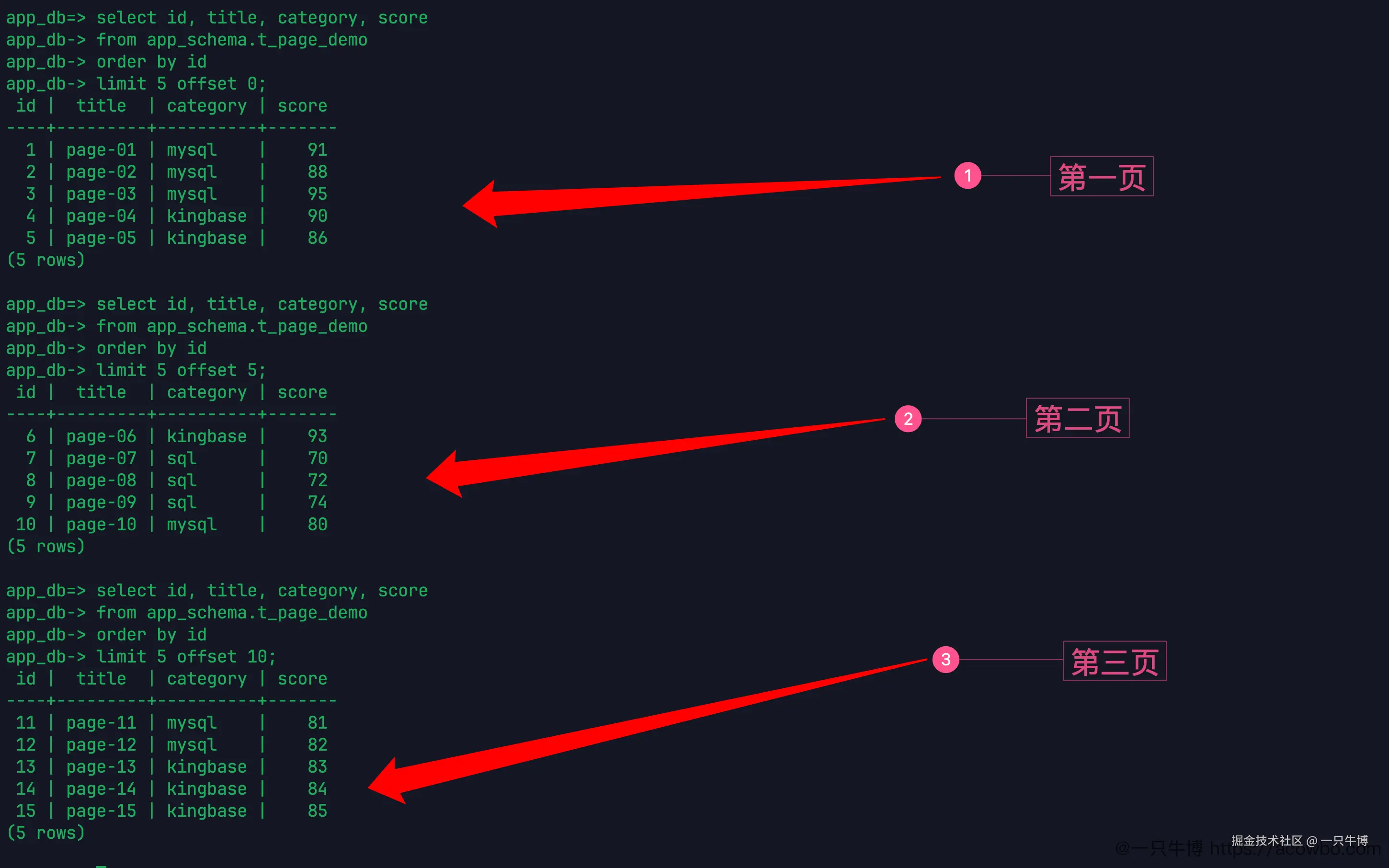
这组结果说明 limit n offset m 可以按 MySQL 用户熟悉的方式理解:先跳过 m 条,再取 n 条。实际写接口分页时,页码通常会被换算成 offset,比如每页 5 条,第 3 页就是 offset 10。
MySQL 里还有一种常见写法:
sql
limit 10, 5它的意思是跳过 10 条,再取 5 条。当前环境里这条也执行成功,返回 11 到 15。

这个结果对迁移比较友好。旧 SQL 里如果已经有 limit offset,count,至少当前版本下不会一上来就因为这个语法报错。不过文章里只能写"当前环境验证通过",不能写成所有版本、所有兼容模式都一定支持。
除了 limit,KingbaseES 也可以使用 fetch first:
sql
select id, title, category, score
from app_schema.t_page_demo
order by id
fetch first 5 rows only;返回结果同样是 1 到 5。再加上 offset:
sql
select id, title, category, score
from app_schema.t_page_demo
order by id
offset 10 rows fetch first 5 rows only;返回 11 到 15。
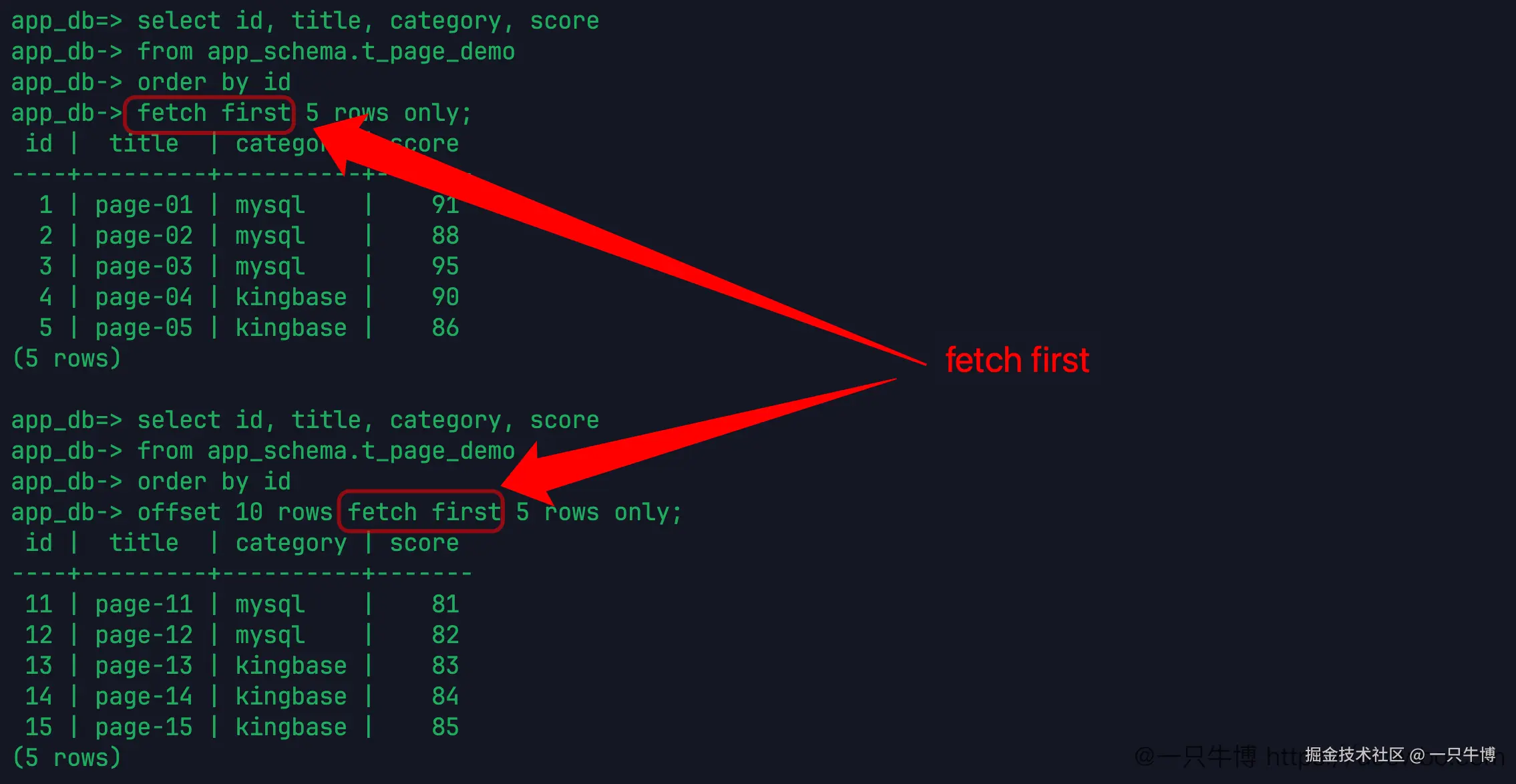
这套写法比 limit 长一点,更像标准 SQL 的表达。日常从 MySQL 迁过来,不一定马上把所有分页都改成 fetch first。先知道它能用就够了:以后看官方文档、看 Oracle 风格 SQL、看其他人写的查询,不至于把它当成陌生语法。
如果项目里原来大量使用 MySQL 写法,优先验证 limit 能否保留,改动最小。fetch first 更适合在新 SQL、跨数据库 SQL 或团队规范要求时使用。两边都能跑时,不急着为了统一而统一,先看现有代码和迁移成本。
最后看一下不写 order by 的情况:
sql
select id, title, category, score
from app_schema.t_page_demo
limit 5;小表里返回的还是 1 到 5。再写:
sql
select id, title, category, score
from app_schema.t_page_demo
offset 5 limit 5;返回 6 到 10。表面看起来没问题,但这不能当成业务规则。SQL 没有声明排序时,结果顺序不应该被分页逻辑依赖。
同一张材料里再补了一条带 order by id 的查询,返回仍然是 1 到 5。差别不在这次小表输出,而在 SQL 是否把顺序说清楚了。分页接口、列表查询、导出预览,只要结果要给人看或者要翻页,就不要省排序字段。
真实业务里还会遇到另一种情况:排序字段本身不唯一。比如按创建时间倒序,某一秒内可能有多条记录;按分数倒序,也可能很多记录同分。这种列表最好再补一个唯一字段,例如 order by created_at desc, id desc。这样翻页时顺序更明确,也方便排查"上一页和下一页有重复数据"的问题。
当前这组实验可以收成几条:
text
limit 5 当前环境可用
limit 5 offset 10 当前环境可用
limit 10, 5 当前环境可用,MySQL 迁移时比较友好
fetch first 5 rows only 当前环境可用
offset ... fetch first 当前环境可用真正要少犯错的是排序。limit 和 fetch first 都只是限制返回条数;哪几条会被返回,还是要看 order by。分页 SQL 可以先按 MySQL 的习惯写起来,但每条分页查询都要问一句:这个列表到底按什么字段稳定排序。
这组实验没有证明深分页性能,也没有比较不同写法的执行计划。它只解决入口问题:从 MySQL 过来,常见分页语法在当前环境里怎么写,哪些地方不能因为小表返回正常就省略。后面遇到大表再单独看执行计划。