一、mem0与mem0ai的区别?


二、mem0ai
mem0ai - Dify MarketplaceSelf-hosted mode mem0 plugin, async_mode enabled by default. Write ops (Add/Update/Delete) are non-blocking in async mode, Read ops (Search/Get/History) always wait; in sync mode all operations block. Supports dynamic log level configuration. Performance optimizations: smart memory classification (33% LLM call reduction), token-aware processing with tiktoken.![]() https://marketplace.dify.ai/plugins/beersoccer/mem0ai
https://marketplace.dify.ai/plugins/beersoccer/mem0ai
GitHub - beersoccer/mem0_dify_plugin: A powerful Dify plugin integrating Mem0 AI for intelligent, long-term memory management. Features local-only execution, asynchronous operations, and a comprehensive toolset for adding, searching, and managing user memories with advanced filtering and metadata support. · GitHubA powerful Dify plugin integrating Mem0 AI for intelligent, long-term memory management. Features local-only execution, asynchronous operations, and a comprehensive toolset for adding, searching, and managing user memories with advanced filtering and metadata support. - beersoccer/mem0_dify_plugin![]() https://github.com/beersoccer/mem0_dify_plugin
https://github.com/beersoccer/mem0_dify_plugin

本地托管模式的 mem0 插件, async_mode 默认开启 。 异步模式下写操作(Add/Update/Delete)非阻塞,读操作(Search/Get/History) 始终等待,同步模式下所有操作阻塞直至完成 。支持动态日志级别配置。性能优化:智能记忆分类(LLM调用减少33%),使用tiktoken进行token感知处理。
集成 Mem0 AI 智能记忆层的 Dify 全功能插件(支持私有化部署,配套统一私有化客户端| View on GitHub )
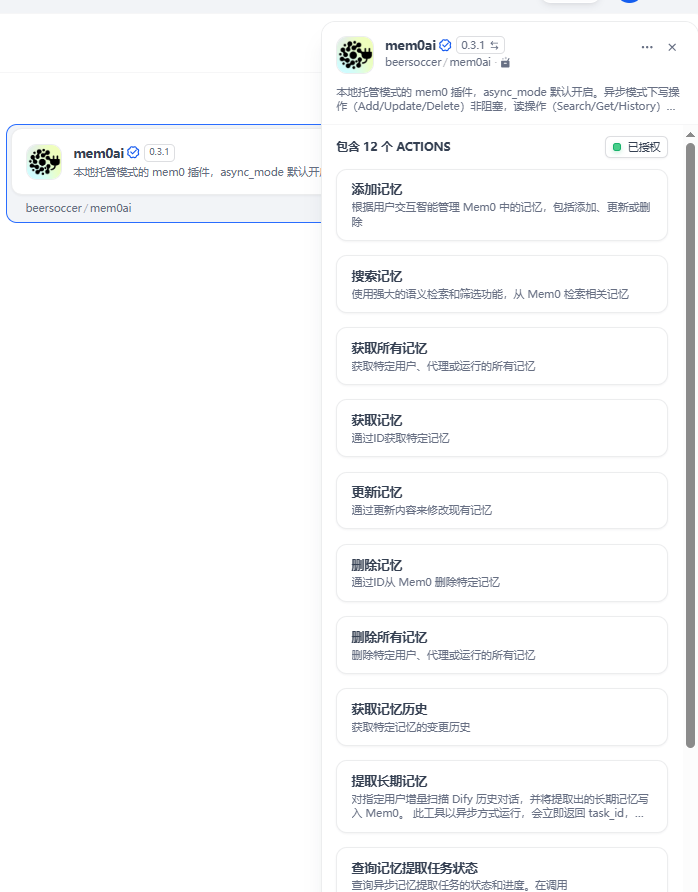
完整记忆管理(共计 12 项工具)
✅ 添加记忆(add_memory) :依据用户对话交互智能完成记忆新增、更新或删除
✅ 搜索记忆(search_memory) :使用高级筛选条件( " 与/或 " 逻辑)并设置 " top_k " 限制进行搜索,返回时间戳字段(最新创建时间/更新时间)
✅ 获取所有记忆(get_all_memories) :分页罗列全部记忆数据
✅ 获取记忆(get_memory) :调取指定记忆详情内容
✅ 更新记忆(update_memory) :对已有记忆内容进行编辑更新
✅ 删除记忆(delete_memory) :移除指定单条记忆
✅ 删除所有记忆(delete_all_memories) :依托筛选条件批量清空记忆
✅ 获取记忆历史(get_memory_history) :追溯记忆历次修改记录
✅ 提取长期记忆(extract_long_term_memory) :从 Dify 会话记录中自动抽取语义记忆/情景记忆/程序记忆三类长效记忆
✅ 查询记忆提取任务状态(check_extraction_status) :查询异步记忆提取任务的状态和进度
✅ 获取用户Checkpoint(get_user_checkpoint) :查询指定用户 / 应用的记忆提取断点状态
✅ 记忆遗忘清理(forget_memories) :按遗忘规则定期淘汰低留存度记忆,自动清理失效的提取断点数据
进阶功能特性
私有化部署模式:对接本地自建 Mem0 服务(采用 JSON 配置文件)
极简本地配置: 配置文件划分为 5 大 JSON 配置块:LLM, Embedder, Vector DB, Graph DB (optional), Reranker (optional )
数据维度限定:user_id (required for add), agent_id, run_id
自定义元数据:支持自定义 JSON 格式元数据,拓展记忆上下文信息
筛选语法:兼容 Mem0 私有化原生 JSON 筛选语法
相似度分值归一化:自动适配各类距离 / 相似度算法后端,统一输出 0~1 区间标准相似度分数
记忆生命周期管控:基于访问日志生成遗忘曲线,可自定义硬性过期时长 (TTL) 管控记忆留存周期
双语国际化:支持中文、英文双语言
异步开关配置: 默认开启异步模式 ;异步下写入操作(新增 / 修改 / 删除)非阻塞执行,读取操作(检索 / 查询 / 查历史)同步等待结果;同步模式下所有接口操作均阻塞直至执行完毕 。
本地设置:
git clone https://github.com/beersoccer/mem0_dify_plugin.git
cd mem0_dify_plugin
pip install -r requirements.txt
python -m main # Run locally 本地运行Testing 测试:
# 运行YAML验证
for file in tools/*.yaml; do
python3 -c "import yaml; yaml.safe_load(open('$file'))" && echo "✅ $(basename $file)"
done三、 dify使用mem0ai插件
3.1、配置
具体配置可参考: mem0_dify_plugin/CONFIG.md at main · beersoccer/mem0_dify_plugin · GitHub
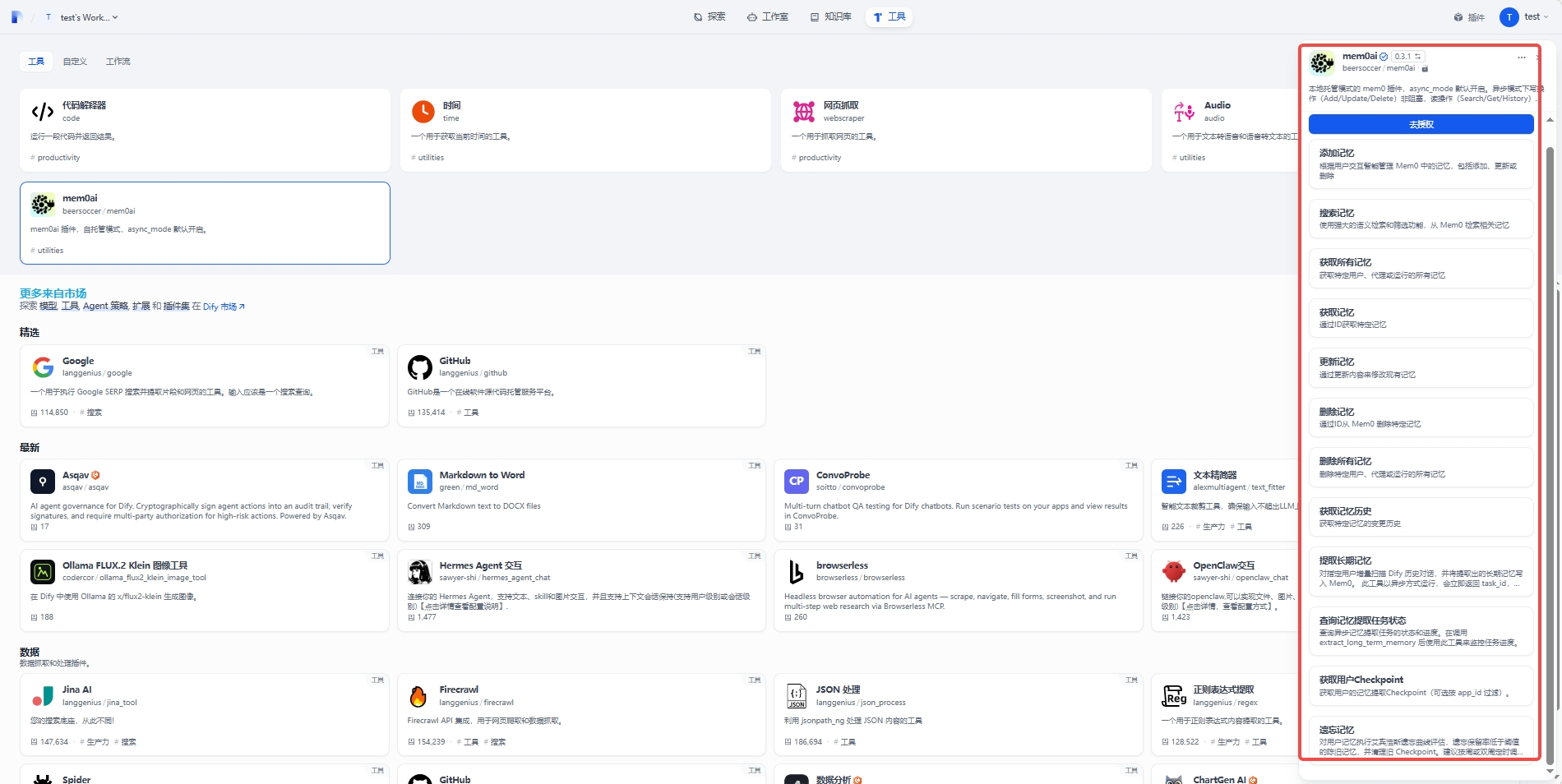
点击"去授权":
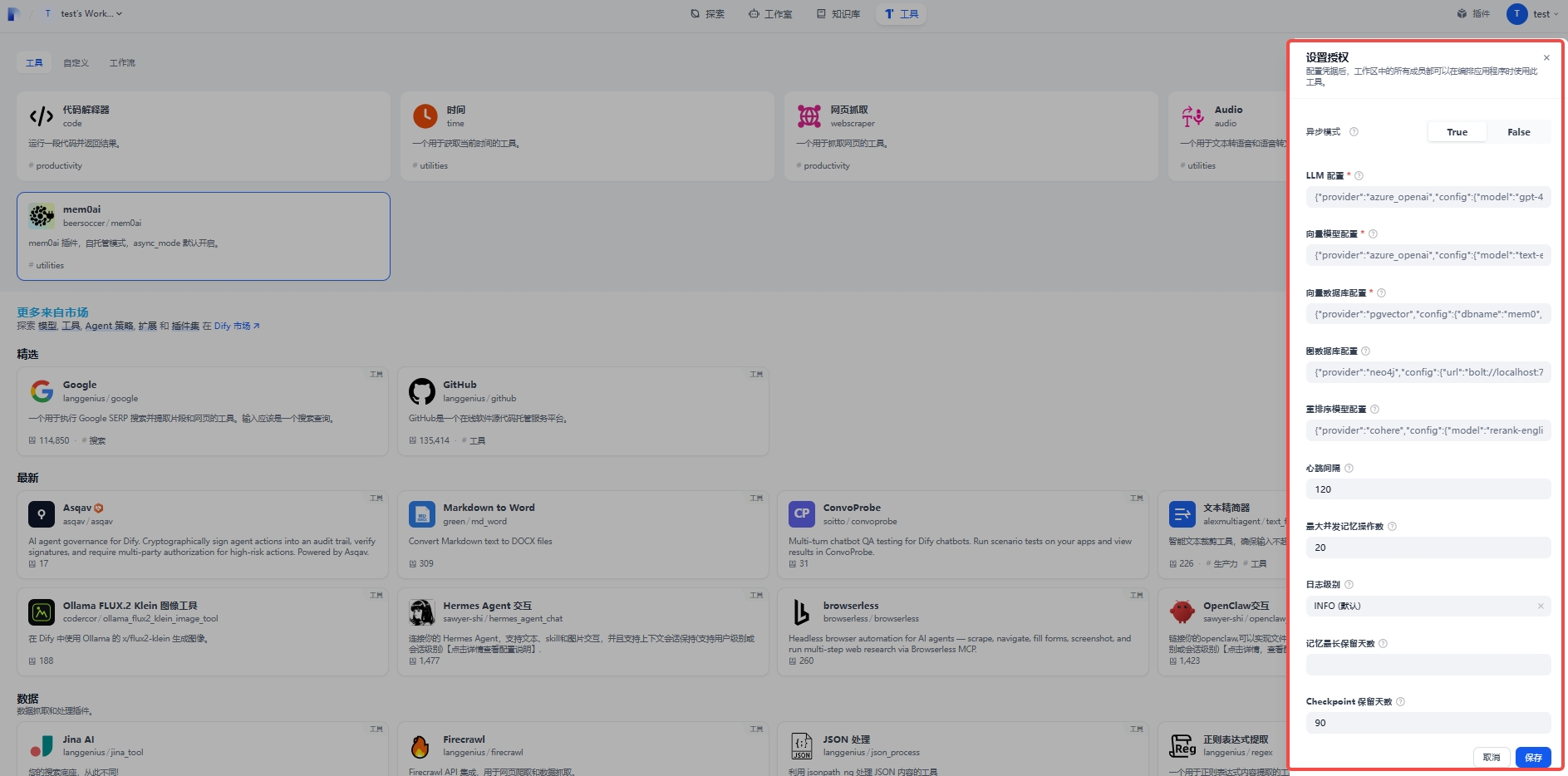
3.2、LLM配置*
Azure OpenAI Example (Standard / Legacy):
{
"provider": "azure_openai",
"config": {
"model": "gpt-4o-mini",
"temperature": 0.1,
"max_tokens": 256,
"azure_kwargs": {
"azure_deployment": "gpt-4o-mini",
"api_version": "2024-10-21",
"azure_endpoint": "https://<your-resource>.openai.azure.com/",
"api_key": "<your-azure-openai-api-key>",
"default_headers": {
"CustomHeader": "Mem0_Dify_Plugin"
}
}
}
}
OpenAI Example:
{
"provider": "openai",
"config": {
"model": "gpt-4o-mini",
"temperature": 0.1,
"max_tokens": 256,
"api_key": "<your-openai-api-key>"
}
}
Ollama Example (Local):
{
"provider": "ollama",
"config": {
"model": "llama3.1:8b",
"ollama_base_url": "http://localhost:11434",
"temperature": 0.1,
"max_tokens": 256
}
}
3.3、向量模型配置*
Azure OpenAI Example:
{
"provider": "azure_openai",
"config": {
"model": "text-embedding-3-small",
"azure_kwargs": {
"api_version": "2024-10-21",
"azure_deployment": "text-embedding-3-small",
"azure_endpoint": "https://<your-resource>.openai.azure.com/",
"api_key": "<your-azure-openai-api-key>",
"default_headers": {
"CustomHeader": "Mem0_Dify_Plugin"
}
}
}
}
OpenAI Example:
{
"provider": "openai",
"config": {
"model": "text-embedding-3-small",
"api_key": "<your-openai-api-key>"
}
}
3.4、向量数据库配置*
PostgreSQL 数据库必须安装启用 pgvector 扩展
推荐配置方法 1:使用连接字符串 + psycopg3 连接池(适用于生产环境)
{
"provider": "pgvector",
"config": {
"connection_string": "postgresql://<user>:<password>@<host>:<port>/<db>?sslmode=disable&keepalives=1&keepalives_idle=30&keepalives_interval=10&keepalives_count=3&connect_timeout=5",
"collection_name": "mem0",
"embedding_model_dims": 1536,
"minconn": 10,
"maxconn": 20
}
}
推荐配置方法 2:使用单独参数结合 TCP 保活机制(适合初学者)
{
"provider": "pgvector",
"config": {
"dbname": "<db>",
"user": "<user>",
"password": "<password>",
"host": "<host>",
"port": "<port>",
"sslmode": "disable",
"minconn": 10,
"maxconn": 20
}
}
3.5、图数据库配置
Neo4j Example:
{
"provider": "neo4j",
"config": {
"url": "bolt://localhost:7687",
"username": "neo4j",
"password": "<your-neo4j-password>",
"database": "neo4j"
}
}
3.6、重排序模型配置
{
"provider": "cohere",
"config": {
"model": "rerank-english-v3.0",
"api_key": "<your-cohere-api-key>",
"top_k": 5
}
}
3.7、 测试配置-->授权
bash
# LLM
{
"provider": "openai",
"config": {
"model": "gpt-4o-mini",
"api_key": "sk-PeLxBxh7YOY55MifU......EnmUQnCG6pYLPAoT",
"openai_base_url": "https://api.c....ere.tech"
}
}
# embedding
{
"provider": "openai",
"config": {
"model": "text-embedding-3-small",
"api_key": "sk-PeLxBxh7YOY55MifU......EnmUQnCG6pYLPAoT",
"openai_base_url": "https://api.c....ere.tech"
}
}
# 向量库
{
"provider": "pgvector",
"config": {
"connection_string": "postgresql://postgres:your_password@10.69.84.14:25432/mem0?sslmode=disable&keepalives=1&keepalives_idle=30&keepalives_interval=10&keepalives_count=3&connect_timeout=5",
"collection_name": "mem0",
"embedding_model_dims": 1536,
"minconn": 10,
"maxconn": 20
}
}授权结果:
3.8、 测试配置--工作流
After completing the configuration steps above, test your setup:
1. Create a Test Workflow
- Go to Workflows in Dify Dashboard
- Create a new workflow
- Add the add_memory tool to your workflow
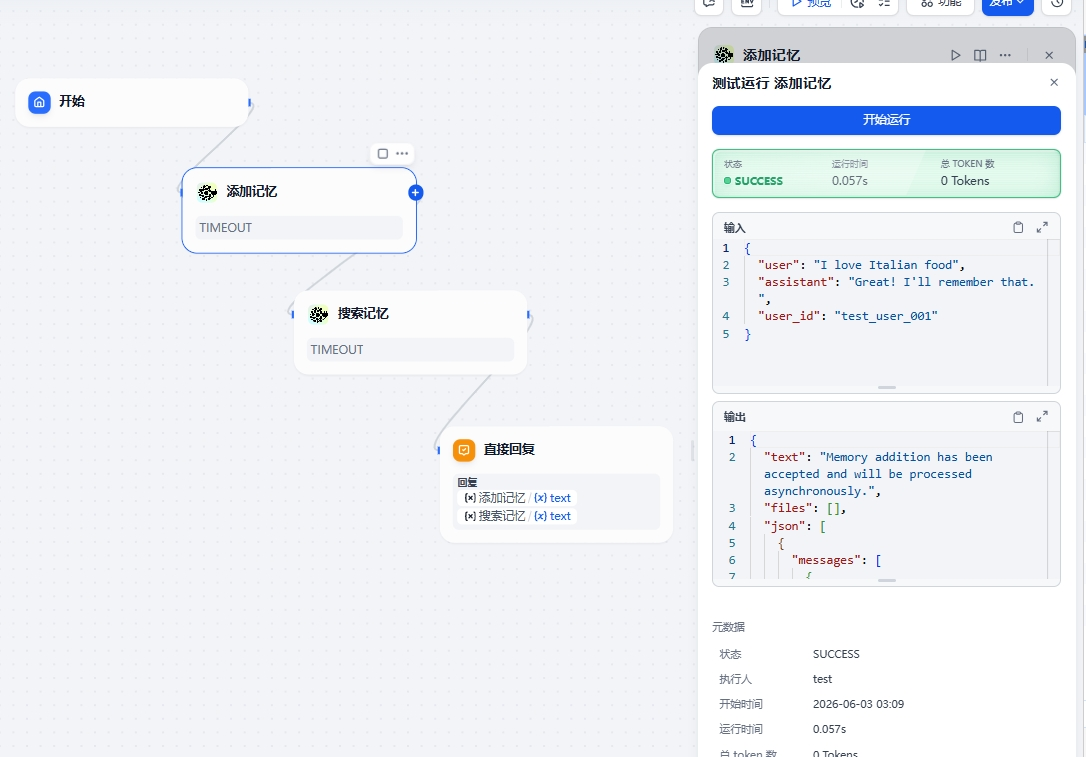
2. Test Add Memory
- Use parameters: {"user": "I love Italian food", "assistant": "Great! I'll remember that.", "user_id": "test_user_001"}
- Expected Result:
In async mode: Returns {"status": "ACCEPT", "results": {"id": "", "memory": "", "event": "ACCEPT"}}
In sync mode: Returns the actual memory object with id and memory fields
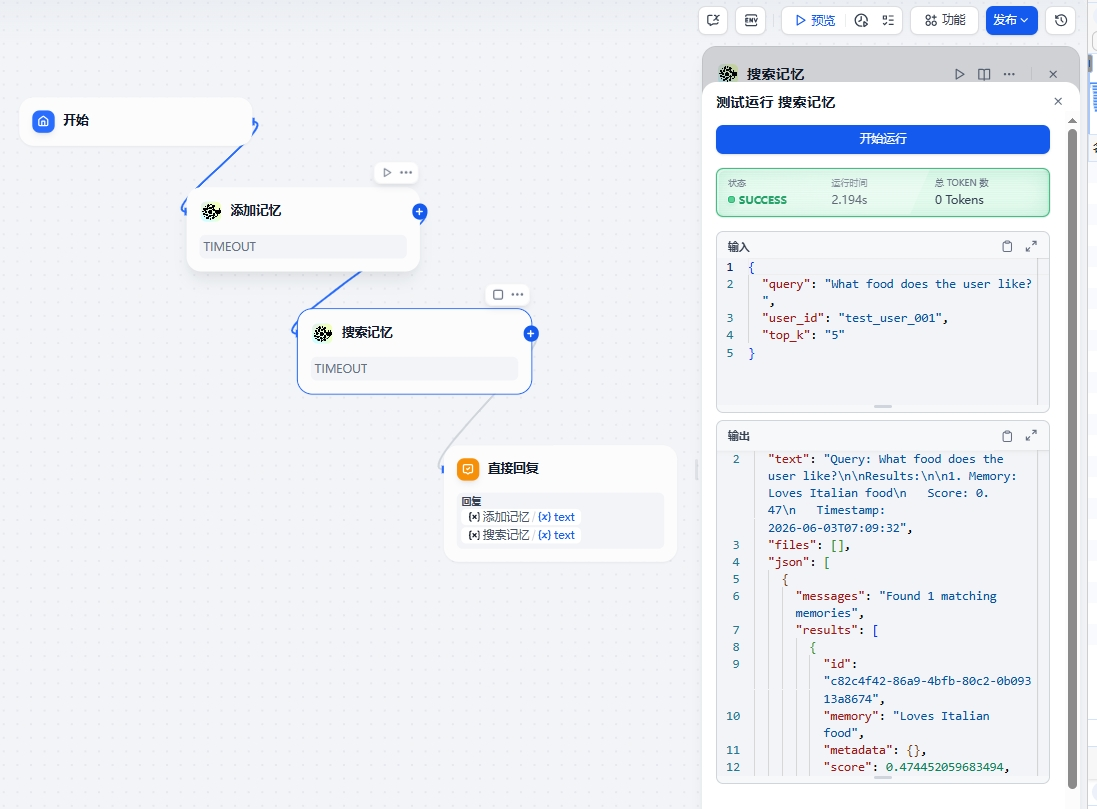
3. Test Search Memory
- Add the search_memory tool and use: {"query": "What food does the user like?", "user_id": "test_user_001", "top_k": 5}
- Expected Result: Returns a list of memories with id, memory, score (0-1 similarity), vector_distance, rerank_score (if reranker enabled), metadata, and timestamp (if available)
4. Verify Configuration
- If tools work correctly, your configuration is valid
- If you encounter errors, check the Troubleshooting section
未执行前:
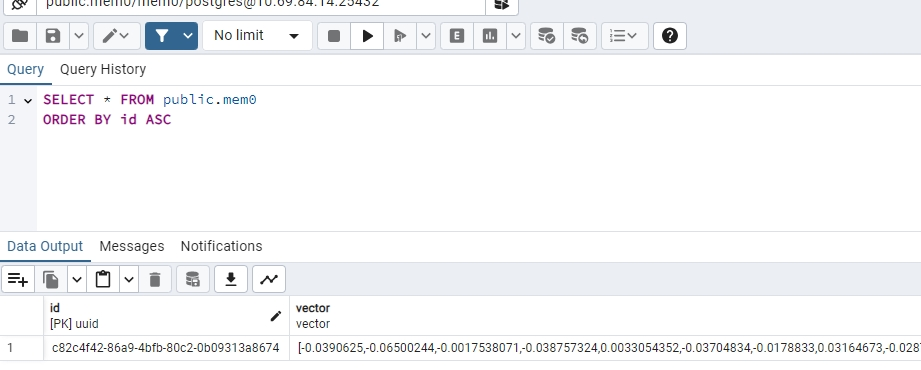
mem0表数据:
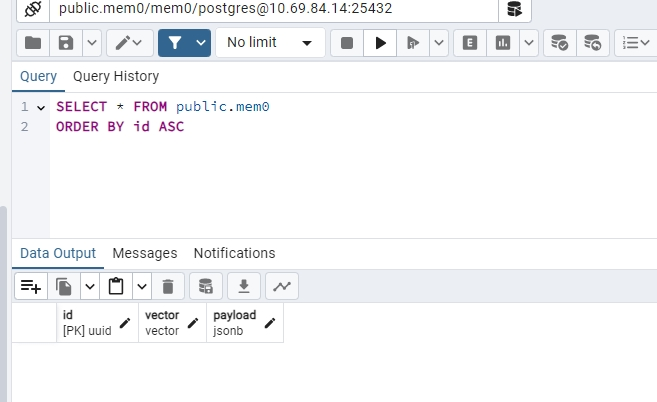
执行"添加记忆":
搜索记忆:
四、示例简述
可参考: mem0_dify_plugin/CONFIG.md at main · beersoccer/mem0_dify_plugin · GitHub
每个LLM节点前插入搜索记忆节点,LLM节点后增加一个添加记忆节点:
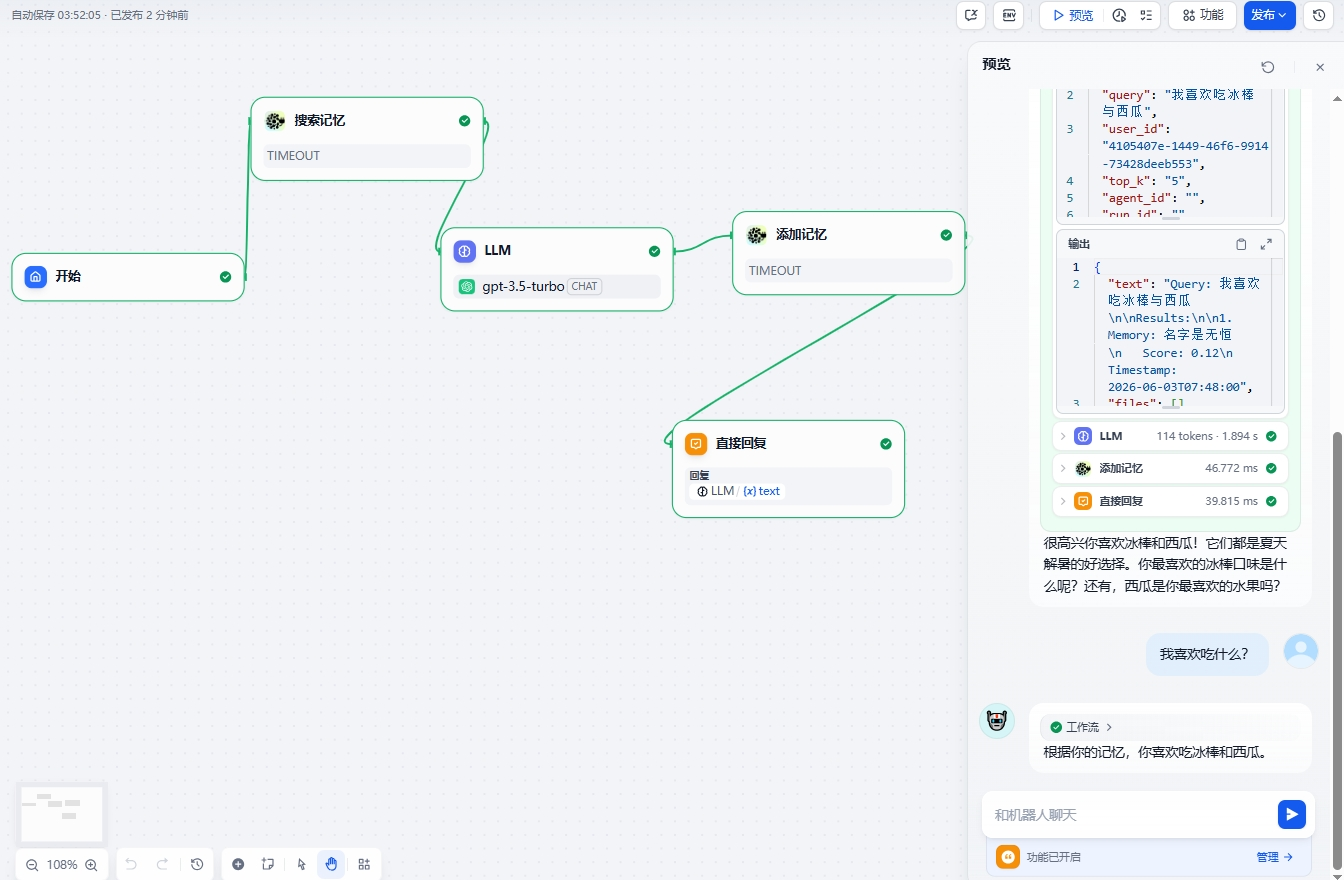
添加记忆:
在 Dify 工作流程中,添加"add_memory"工具,并配置以下参数:
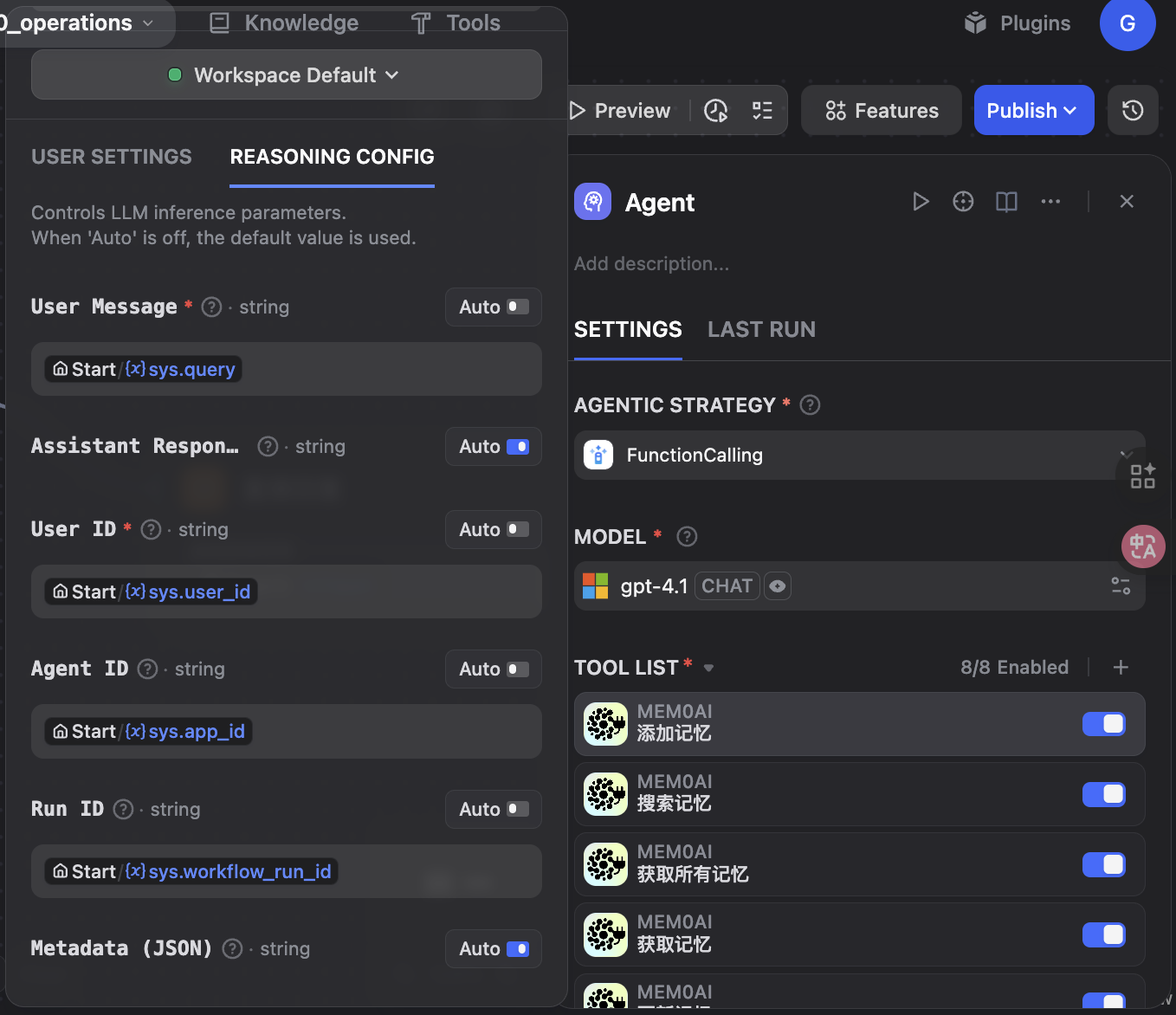
必填参数:
- user(用户消息):(例如:"我喜欢意大利美食")
- User ID(用户标识符):(例如:"alex")
可选参数:
- assistant(辅助响应):(例如:"太好了!我会记住的。")
- Agent ID(代理标识符):用于限定范围的代理标识
- RUN ID(运行标识符):用于追踪的作业运行标识符(建议使用 Dify 的workflow_run_id)
- Metadata(元数据):自定义的 JSON 格式元数据字符串
搜索记忆:
在 Dify 工作流程中,添加"search_memory"工具,并配置以下参数:
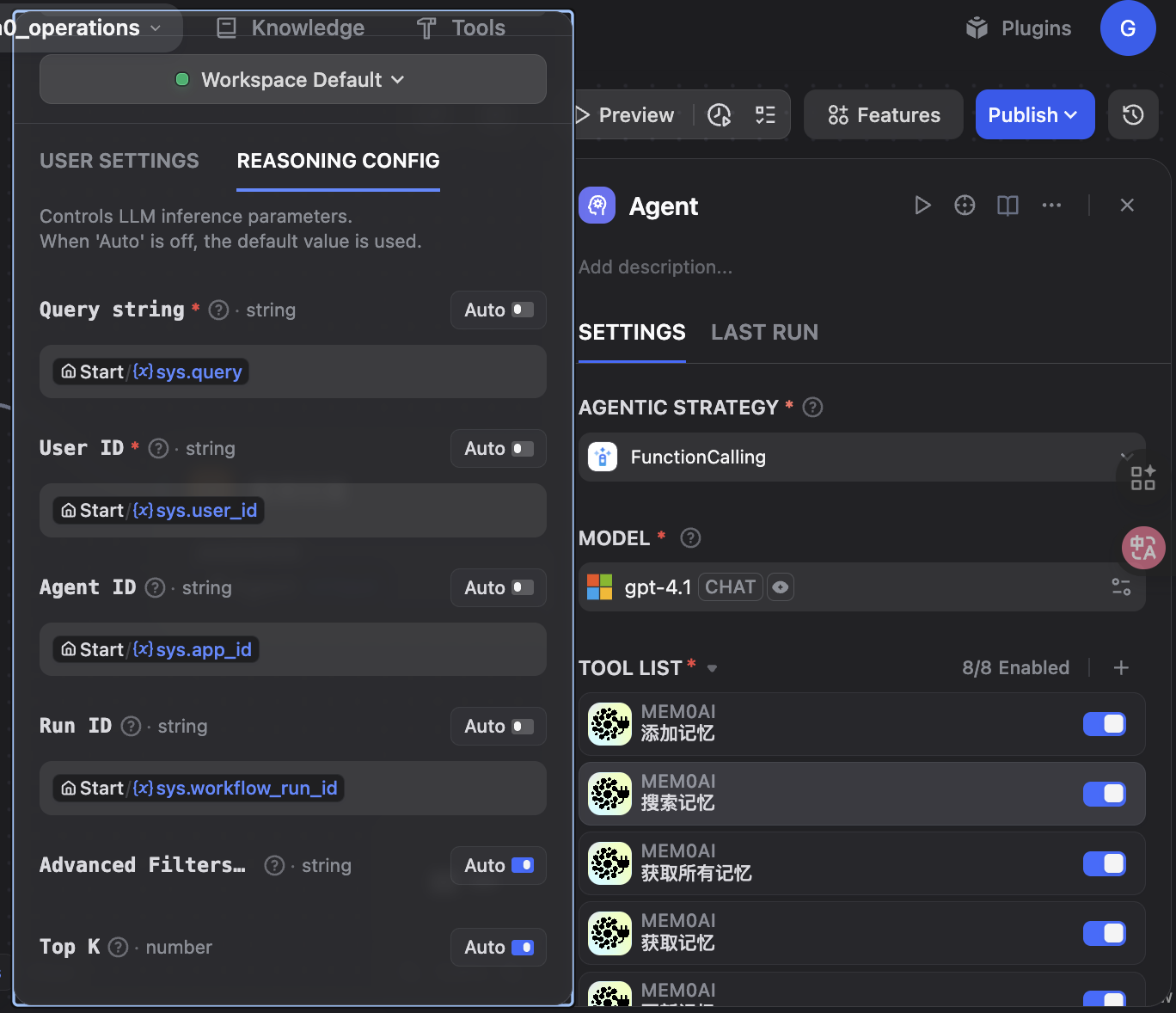
必填参数:
- Query string(查询):搜索查询(例如,"亚历克斯喜欢什么食物?")
- User ID(用户标识符):用户标识(例如,"亚历克斯")
可选参数:
- top_k:最大结果数量(默认值:5)
- filters:用于高级筛选的 JSON 过滤字符串
- agent_id:用于限定范围的代理标识符
- run_id:用于追踪的作业运行 ID要点
要点:
user_id 是执行"add_memory, search_memory, get_all_memories"操作所必需的
filters 与 metadata必须是有效的 JSON 字符串
对于" search_memory"操作,如果没有指定,则top_k 默认值为 5
run_id(可选):建议使用 Dify 的 workflow_run_id 用于调用链跟踪。注意:此参数仅用于跟踪,不作为记忆层叠或过滤的条件使用
五、错误
5.1、授权报错
PluginInvokeError: {"args":{},"error_type":"ToolProviderCredentialValidationError","message":"extension \"vector\" is not available\nDETAIL: Could not open extension control file \"/usr/local/share/postgresql/extension/vector.control\": No such file or directory.\nHINT: The extension must first be installed on the system where PostgreSQL is running."}
分析:
本地 PostgreSQL 数据库缺少 pgvector 扩展导致的。
Dockerfile:
bash
FROM postgres:15-alpine
# 安装编译依赖
RUN apk add --no-cache git build-base clang llvm-dev postgresql-dev
# 克隆并编译 pgvector
RUN cd /tmp \
&& git clone --branch v0.8.0 https://github.com/pgvector/pgvector.git \
&& cd pgvector \
&& make \
&& make install
# 清理编译依赖,减小镜像体积
RUN apk del git build-base clang llvm-dev postgresql-dev生成镜像: docker build -t postgres-with-pgvector:15-alpine .
运行下面的 SQL 命令来启用扩展: CREATE EXTENSION IF NOT EXISTS vector;
验证是否安装成功: SELECT * FROM pg_extension WHERE extname = 'vector';
或者直接 使用官方 pgvector 镜像:docker.io/pgvector/pgvector:pg15
bash
docker run -d \
--name postgres-pgvector \
-e POSTGRES_PASSWORD=your_password \
-p 5432:5432 \
pgvector/pgvector:pg15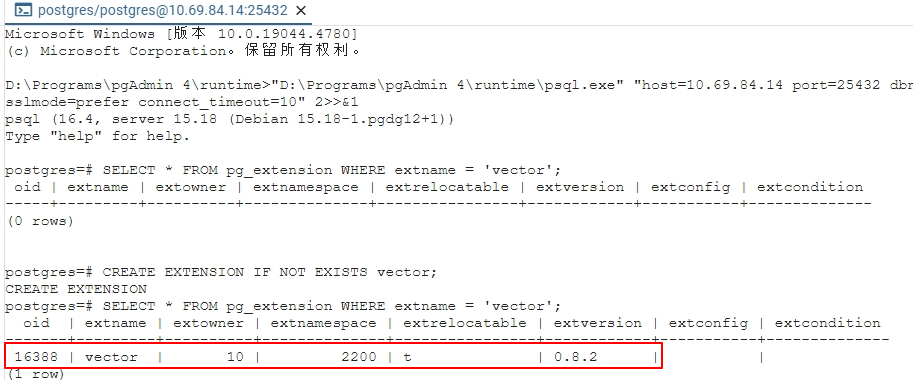
5.2、dify的插件mem0在测试时发现有时可以把问答写到pgvector,有时又没有写入。这是为何?它的写入机制是怎样的
05 | Mem0 框架分析:记忆写入的七阶段流水线------从消息到持久化的完整数据流-CSDN博客

六、参考
AI Agent 如何真正"记住你"?深度拆解 mem0 的智能记忆系统
从Mem0开始,再谈长期记忆
mem0 - Dify Marketplace
mem0ai - Dify Marketplace
Dify - Mem0
让 LLM 真正"有记忆",我做了这个 Dify 插件
Dify如何使用长期记忆mem0_哔哩哔哩_bilibili
Mem0:给 AI Agent 加上一层"可用的长期记忆"(介绍与上手) | Ningto's Blog