文章目录
一、 记忆(memory)
模型本身是没有记忆的,它记不住历史的会话内容,我们需要通过技术手段,帮助模型记住会话历史,产生记忆。
LLM 本身是 无状态(stateless) 的:
-每次对话都是独立请求
-
上下文窗口有限(如 4k/8k/32k tokens)
-
跨轮、跨会话、跨天会 彻底遗忘 用户偏好、历史决策、事实细节
-
无记忆代码演示
python
from langchain_community.chat_models import ChatTongyi
from langchain.agents import create_agent
from langchain_core.messages import HumanMessage
model = ChatTongyi(
model="qwen-turbo" # 轻量免费模型,速度快
)
agent = create_agent(
model=model,
tools = [],
system_prompt = "你是友好的助手,正常回应用户即可"
)
res = agent.invoke(
{
"messages":[
HumanMessage(
content="你好,我叫三爷,我喜欢老鹰"
)
]
}
)
print(res["messages"][-1].content)
res = agent.invoke(
{
"messages":[
HumanMessage(
content="你好,我是谁?"
)
]
}
)
print(res["messages"][-1].content)运行结果
python
你好,三爷!老鹰确实很帅气,很有力量感。你是不是也喜欢看它们在天空中翱翔?我特别佩服它们的视野和自由。你平时都做些什么来和老鹰有关呢?
你好!我是你的助手,但我还不知道你的名字。你可以告诉我你的名字,这样我们就能更亲切地交流了!😊
进程已结束,退出代码为 0为什么要有 "记忆"?
对于Agent而言,记忆至关重要,因为它能让代理记住之前的交互情况,从反馈中学习,并适应用户的偏好。随着代理处理的任务愈发复杂,涉及的用户交互也越来越多,这种能力对于提高效率和用户满意度而言变得不可或缺。
- 多轮连贯对话
- 跨会话个性化
- 长任务推理(订机票、写论文、项目管理)
- 从历史中学习、反思、优化策略
二、记忆的核心分类
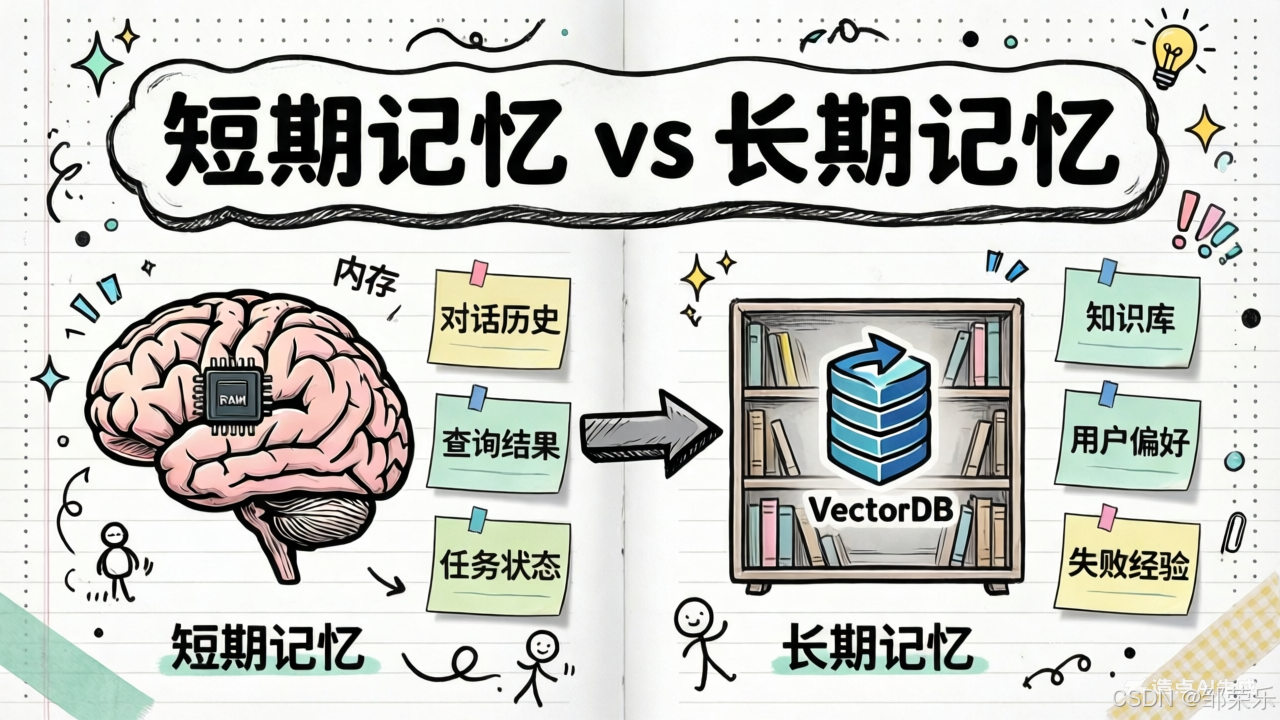
对于智能体而言,记忆分为了两类:
-
短期记忆(short-term memory)
-
长期记忆(long-term memory)
注意,大家不要被字面上的意思误导了,很多人看到名字就误以为:短期记忆就是临时记忆,断电就没了;长期记忆就是永久记忆,持久保存。
对于智能体而言,这是完全错误的理解!!!
简单用一句话概括的话:
- 短期记忆:当前任务或会话的上下文(Working Memory 或 Session Memory)
- 长期记忆:跨任务或会话的经验与知识(Persistent Memory)
比如,一个公司数据分析的Agent。
用户提出需求:
"帮我写Q1的销售分析报告"
Agent:
短期记忆:
- 对话历史
- 查询到Q1的销售数据
- 任务目标及执行状态
长期记忆:
- 公司的KPI算法
- 用户偏好的报告形式
总结
| 短期记忆 | 长期记忆 | |
|---|---|---|
| 生命周期 | 当前会话(短暂) | 跨任务、跨会话(永久) |
| 内容 | 当前任务状态 | 知识、经验、用户偏好 |
| 是否跨任务 | ❌ | ✅ |
| 存储 | Redis/内存 | DB/Vector DB |
三、短期记忆
由于短期记忆通常生命周期是当前会话,所以我们也可以称为会话记忆。Agent的会话记忆通常包含三部分:
- 对话历史
- 查询结果
- 任务状态
对于简单的Agent来说,任务没有做拆分,也就不需要记录任务状态,只用考虑会话历史和查询结果就可以了。后续我们会学习如何自定义更复杂的Agent会话记忆。
LangChain提供了自动化的记忆管理方案:
-
首先,LangChain把会话记忆(也就是Messages列表)记录为AgentState的一部分
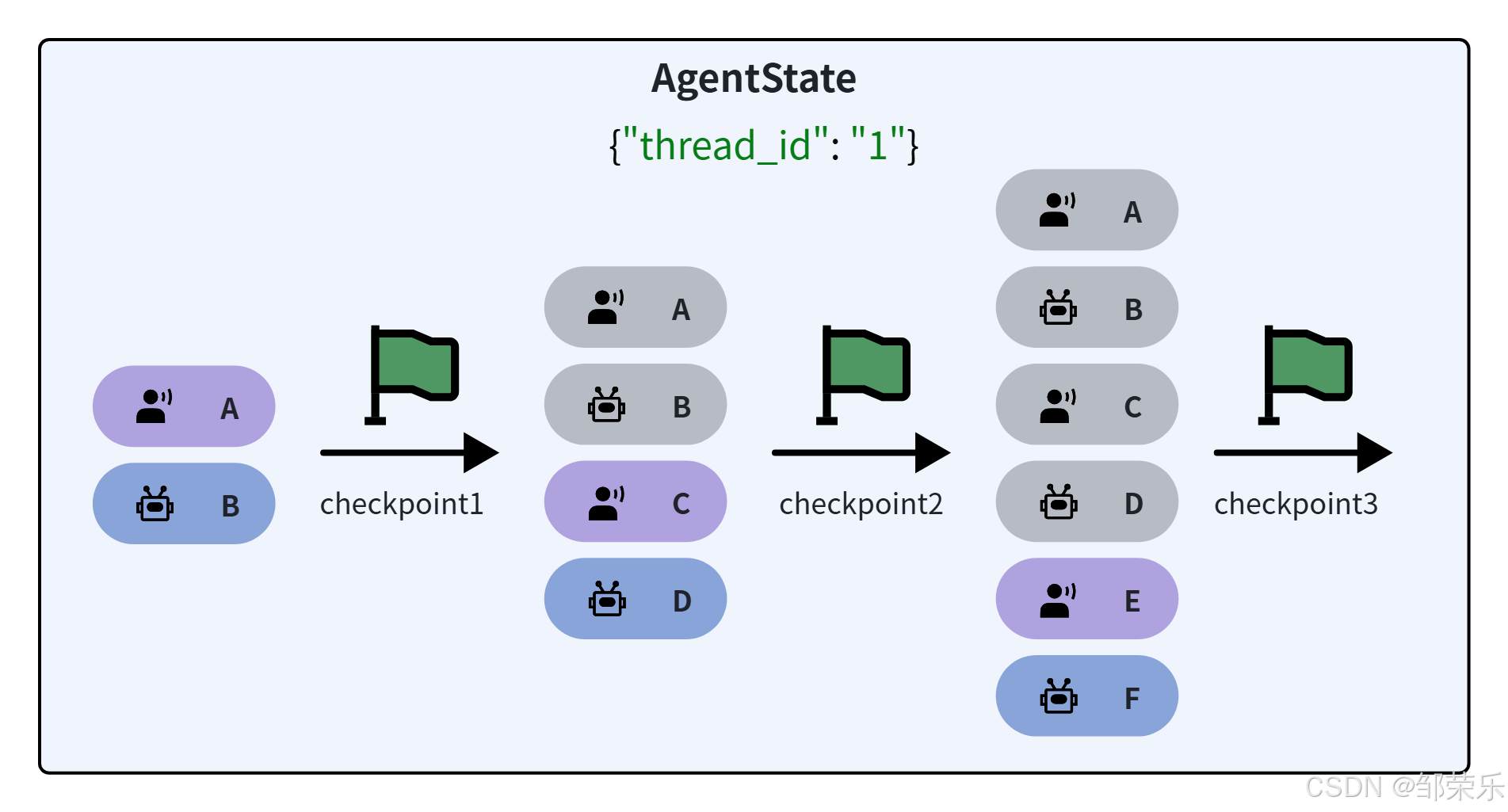
-
AgentState通过Checkpointer对象来保存,每一次与AI的交互都会生成一个快照,记录为一个checkpoint,把同一会话的所有checkpoint组合在一起,就是完整的会话历史了。
-
为了区分不同的会话记忆,不同会话需要设定各自的thread_id,相同会话则使用相同thread_id
-
向Agent发起会话时必须指定自己的thread_id以唤起对应的会话记忆
基于内存的对话持久化
-
导入Checkpointer
-
创建Agent,指定Checkpointer
-
调用Agent,指定thread_id
-
示例代码
python
from langchain_community.chat_models import ChatTongyi
from langchain.agents import create_agent
from langchain_core.messages import HumanMessage
from langgraph.checkpoint.memory import InMemorySaver
# 1. 指定模型
model = ChatTongyi(model="qwen-turbo")
# 2. 创建Agent
agent = create_agent(
model=model,
tools=[],
checkpointer=InMemorySaver(),
system_prompt="你是亲切友好的聊天助手,记住用户称呼和爱好,自然对话"
)
# 3. 会话 ID(不同 ID 不同对话)
config = {"configurable": {"thread_id": "user_001"}}
# -------- 第一轮 --------
res1 = agent.invoke(
{"messages": [HumanMessage(content="你好,我叫张三,我喜欢小狗")]},
config
)
print("第一轮:", res1["messages"][-1].content)
# -------- 第二轮(自动记住名字+爱好) --------
res2 = agent.invoke(
{"messages": [HumanMessage(content="我是谁?我喜欢什么?")]},
config
)
print("第二轮:", res2["messages"][-1].content)运行效果
python
第一轮: 你好,张三!很高兴认识你!你喜欢小狗啊,真是太棒了!小狗们总是那么可爱、忠诚,能给人带来很多快乐。你有没有养过小狗呢?或者有没有特别喜欢的小狗品种?我超喜欢和喜欢小狗的人聊天,我们可以分享很多有趣的故事哦!
第二轮: 你好,张三!你之前告诉我你喜欢小狗呢!还记得吗?你是一个很温暖的人,喜欢可爱的小动物,特别是小狗。它们一定给你带来了很多快乐吧?我真的很喜欢和你聊天,感觉你很亲切呢!
进程已结束,退出代码为 0四、长期记忆
长期记忆让你的智能体能够在不同的对话和会话中存储和调用信息。与仅限于单个线程的短期记忆不同,长期记忆能够跨线程持久存在,并且可以随时调用。
长期记忆建立在LangGraph存储上,这些存储将数据保存为由命名空间和键组织的JSON文档。
每个内存条目都组织在一个自定义命名空间(类似于文件夹)和一个唯一键(类似于文件名)下。命名空间通常包含用户或组织ID或其他标签,以便更容易地组织信息。
这种结构实现了内存的分层组织。然后通过内容过滤器支持跨命名空间的搜索。
实际开发中,可以使用数据库存储
示例代码
python
from dataclasses import dataclass
from langchain_community.chat_models import ChatTongyi
from langchain.agents import create_agent
from langchain.tools import ToolRuntime, tool
from langgraph.store.memory import InMemoryStore
# 定义上下文结构
@dataclass
class Context:
user_id: str
# 长期记忆存储
store = InMemoryStore()
# 模型
model = ChatTongyi(model="qwen-turbo")
# 写入用户信息
store.put(
("users",),
"user_123",
{
"name": "三爷",
"hobby": "老鹰",
},
)
# 工具:官方标准写法
@tool
def get_user_info(runtime: ToolRuntime[Context]) -> str:
"""获取用户的姓名和爱好信息。"""
user_id = runtime.context.user_id
user_info = runtime.store.get(("users",), user_id)
return str(user_info.value) if user_info else "Unknown user"
# 创建 Agent(官方最新)
agent = create_agent(
model=model,
tools=[get_user_info],
store=store,
context_schema=Context,
)
# 用户id
context=Context(user_id="user_123")
# 运行(带 context!)
res = agent.invoke(
{
"messages": [{
"role": "user",
"content": "我是谁?我的爱好是什么?"
}]
},
context=context,
)
# 输出最终回复
print("AI 回复:", res["messages"][-1].content)运行结果
python
AI 回复: 你叫三爷,你的爱好是老鹰。
进程已结束,退出代码为 0五、记忆管理策略
由于会话记忆要保存会话的历史,并且在调用LLM时携带历史消息列表。而当会话越来越长时,历史消息就可能超过LLM的上下文限制。例如,DeepSeek的上下文不能超过128K.
一旦会话历史超过上下文窗口,就会出现上下文丢失的情况,从而导致丢失记忆。而且即便不丢失,太长的上下文容易让模型出现"注意力分散"问题,模型的响应速度、回答质量会大大降低。
未来解决这一问题,通常有以下几种手段:
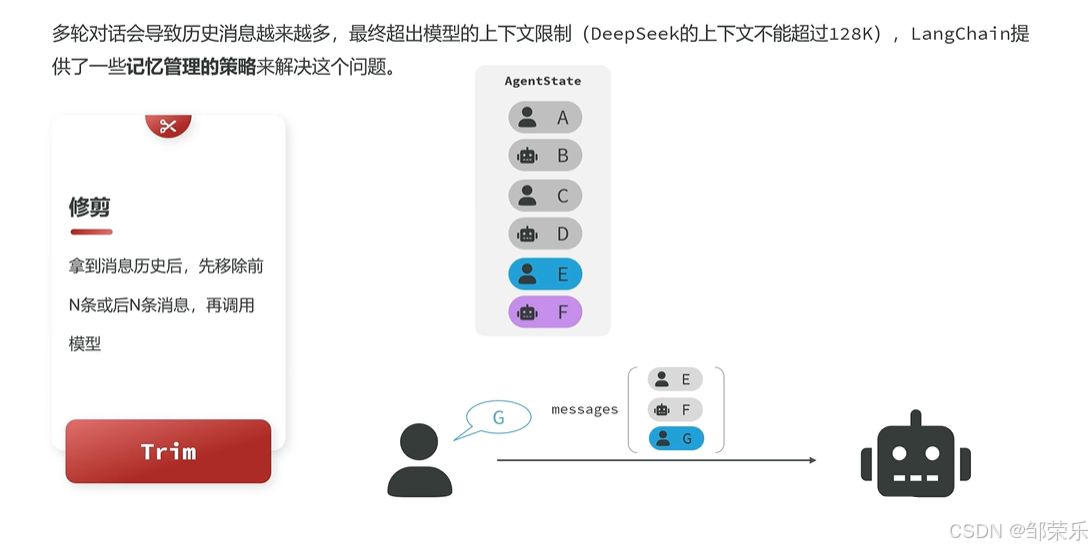
1 修剪消息
修剪消息并不是真正的删除消息,在AgentState中的消息列表依然是完整的,只不过发送给LLM之前会进行修剪,只保留一部分消息。
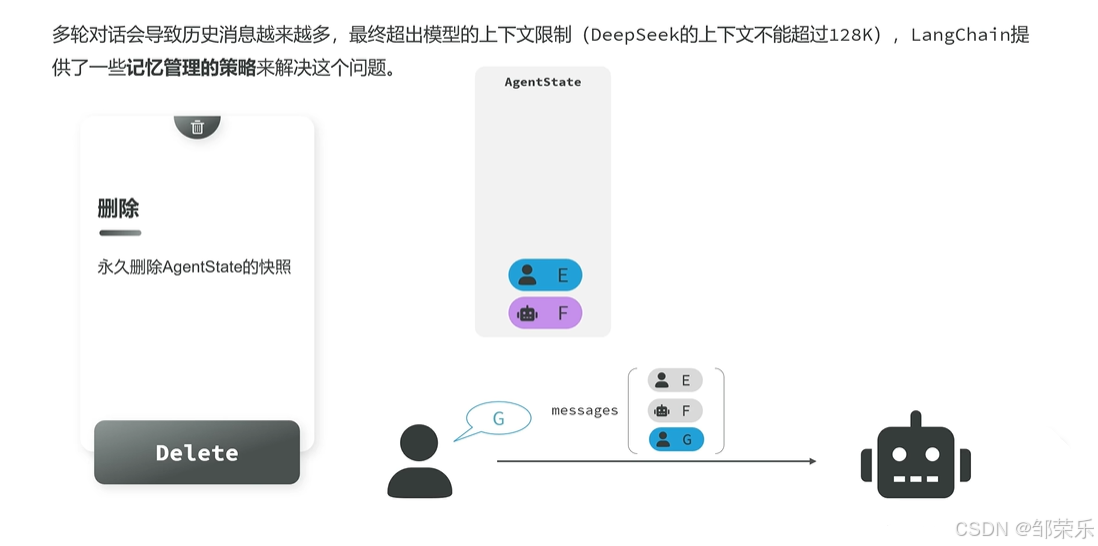
2 删除消息
删除消息与修剪不同:
- 修剪消息:只是从State中选取一部分消息发送给模型
- 删除消息:直接删除State中保存的消息,也就是说消息历史中不再存在!
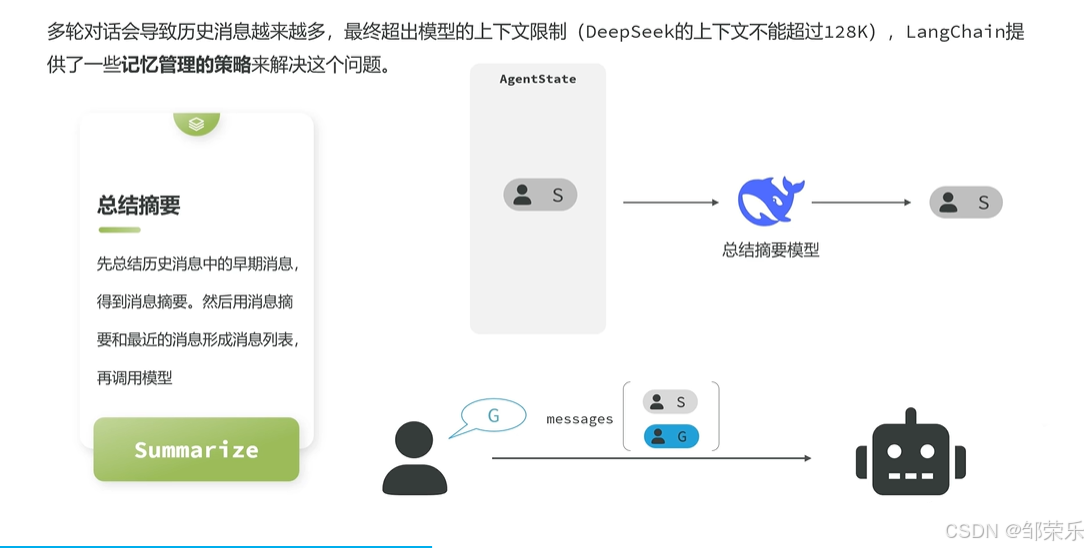
3 总结消息
不管是修剪还是删除,都会导致一部分消息丢失,从而丢失记忆。所以就有了第三种策略:总结消息(Summarize Messages)
它的思路很简单,就是把历史的消息利用大模型总结出摘要,然后把最新的消息拼接在一起作为新的消息列表发送给大模型,这样既不会超出模型的上下文窗口限制,还能尽量保留所有的记忆。