你有没有遇到过这样的场景:昨天花了半小时跟 AI 把一个 Bug 的根因讲清楚了,今天新开一个对话,对方又一脸懵地从零问起。每次都要重新交代背景,像是在跟一个永远刚入职的实习生打交道。
根本原因很简单:现在大多数 AI Agent 的"记忆"只存在于当前 context window 里。窗口结束,记忆清零。
这篇文章介绍怎么用 Mem0 + Easysearch 给 Agent 装上一块真正的长期记忆------跨会话、可语义检索、在本地跑,数据完全自己掌控。
整体架构
用户 ↔ AI Agent(Trae / Cursor / VS Code 等)
↓ MCP 协议
Mem0 OpenMemory MCP Server
↓ HTTPS
Easysearch 集群
┌──────────────────┐
│ 记忆向量索引 │
│ kNN 语义检索 │
└──────────────────┘写记忆 :Agent 发现有价值的信息(Bug 根因、架构决策、约定命名......)时,调用 add_memories,MCP Server 用 Embedding 模型将文本向量化后写入 Easysearch。
读记忆 :Agent 开始新任务前,调用 search_memory,MCP Server 把问题向量化后在 Easysearch 做 kNN 检索,把语义最相关的历史记忆注入到 Prompt 里。
整条链路在本地跑,LLM 和 Embedding 模型可以接任意 OpenAI 兼容的 API,包括阿里云百炼、DeepSeek、本地 Ollama 等。
部署:4 步搞定
第一步:准备 Easysearch 集群
如果你已有 Easysearch 集群,直接跳到第二步。
没有的话,用 Docker 30 秒拉起一个单节点:
sh
# 生成随机 admin 密码
echo "EASYSEARCH_INITIAL_ADMIN_PASSWORD=$(openssl rand -hex 10)" | tee .env
# 启动容器
docker run -d --name easysearch \
--ulimit memlock=-1:-1 \
--env-file ./.env -p 9200:9200 \
-v easysearch-data:/app/easysearch/data \
-v easysearch-config:/app/easysearch/config \
-v easysearch-logs:/app/easysearch/logs \
infinilabs/easysearch:latest验证一下:
sh
curl -ku 'admin:<你的密码>' https://127.0.0.1:9200
# 看到 "You Know, For Easy Search!" 就好了第二步:拉取 Mem0 的 Easysearch 分支
官方 Mem0 仓库还没有合并 Easysearch 支持,需要用 INFINI Labs 维护的 fork:
sh
git clone https://github.com/infinilabs/mem0.git && cd mem0
git checkout feat/easysearch第三步:配置 MCP Server
编辑 openmemory/api/.env,这是整个配置的核心:
ini
USER=steve # 你的名字,用于隔离不同用户的记忆
# 语言模型------写入时用来整理、去重记忆
LLM_PROVIDER=openai
LLM_MODEL=deepseek-r1
LLM_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
# Embedding 模型------把文本变成向量
EMBEDDER_PROVIDER=openai
EMBEDDER_MODEL=text-embedding-v4
EMBEDDER_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
EASYSEARCH_EMBEDDING_DIMS=1024 # 必须与模型实际输出维度一致!
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxx
# Easysearch 连接信息
EASYSEARCH_URL=https://127.0.0.1:9200
EASYSEARCH_USER=admin
EASYSEARCH_PASSWORD=xxxxxxxxxxxxxxxx几个容易踩坑的地方:
EASYSEARCH_EMBEDDING_DIMS必须 和你选的 Embedding 模型输出维度完全一致。text-embedding-v4默认是 1024,text-embedding-3-small是 1536。填错了写入会报错。EASYSEARCH_URL用https://,Easysearch 默认启用 TLS。- 本地开发时 MCP Server 会跳过证书验证(等价于
curl -k)。生产环境建议换成受信 CA 颁发的证书,或者把 Easysearch 的自签名 CA 导出后加到REQUESTS_CA_BUNDLE。
第四步:启动 MCP Server
sh
cd openmemory/api
python3 -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt \
&& pip uninstall -y mem0ai \
&& pip install -e "../../[extras]"
uvicorn main:app --host 0.0.0.0 --port 8765看到这个就说明服务起来了:
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8765 (Press CTRL+C to quit)接入 Agent 工具
配置 MCP Server 地址
在你的 Agent 工具(Cursor、VS Code Copilot 等)的 MCP 配置添加 URL 为
http://localhost:8765/mcp/<客户端ID>/http/<用户名>的 server。
<客户端ID>随便起,用来区分不同工具(trae、cursor、vscode......)<用户名>要和.env里的USER保持一致
给 Agent 配一个强制 SOP 的 Skill
光有 MCP 工具还不够------Agent 不会主动去用。需要通过一个全局 Skill 把"任务前检索记忆、任务后保存发现"变成强制流程:
markdown
name: memory
description: "MANDATORY MEMORY PROTOCOL. You MUST call `search_memory` before any action and `add_memories` after any significant discovery."
### STEP 1: 任务开始前,必须先检索记忆
调用 `search_memory`,关键词:当前任务涉及的实体、技术栈、具体问题。
不要假设你了解这个项目,先查记忆。
### STEP 2: 执行任务
留意"知识点"------那些不在代码库里但对后续工作极有价值的信息。
### STEP 3: 任务结束前,评估是否有新知识需要保存
满足以下任一条件,调用 `add_memories`:
- 做了架构/方案选型决策
- 找到了某个诡异 Bug 的根因
- 发现了特定的环境变量或命令才能让东西跑起来
- 约定了命名规范
- 挖出了隐含的业务逻辑
判断标准:如果明天来一个全新的 Agent 做这个任务,这条信息能帮它省 5 分钟以上吗?能的话就存。把这个 Skill 设置为全局生效,之后每个项目都会自动走这套流程。
实际效果
开启记忆后,Agent 的表现会有几个明显变化:
能跨会话积累经验,不再重复询问。调试过的 Bug、踩过的坑、确定下来的方案,都会沉淀下来。项目越做越久,Agent 越来越"懂"这个项目。
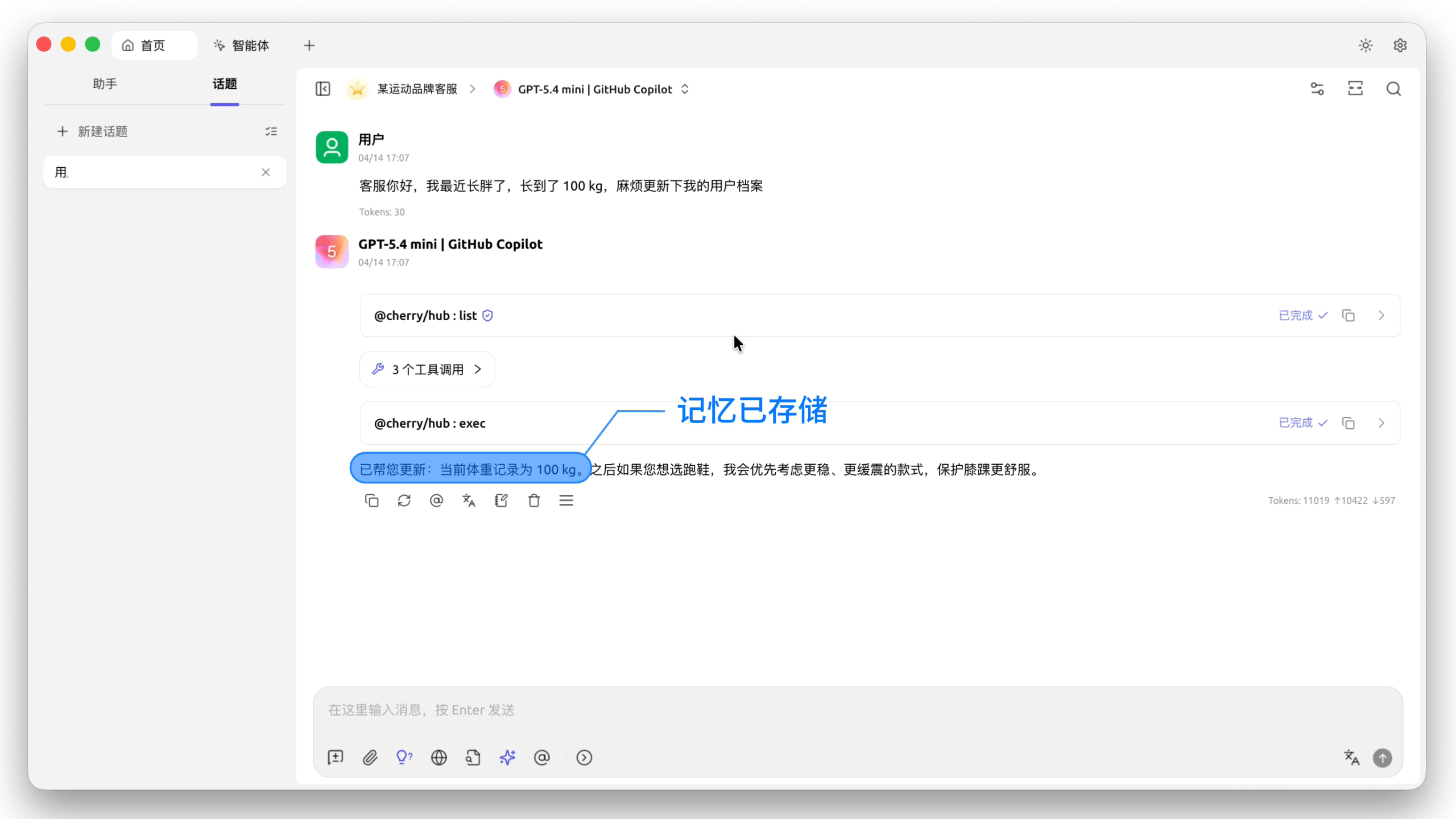
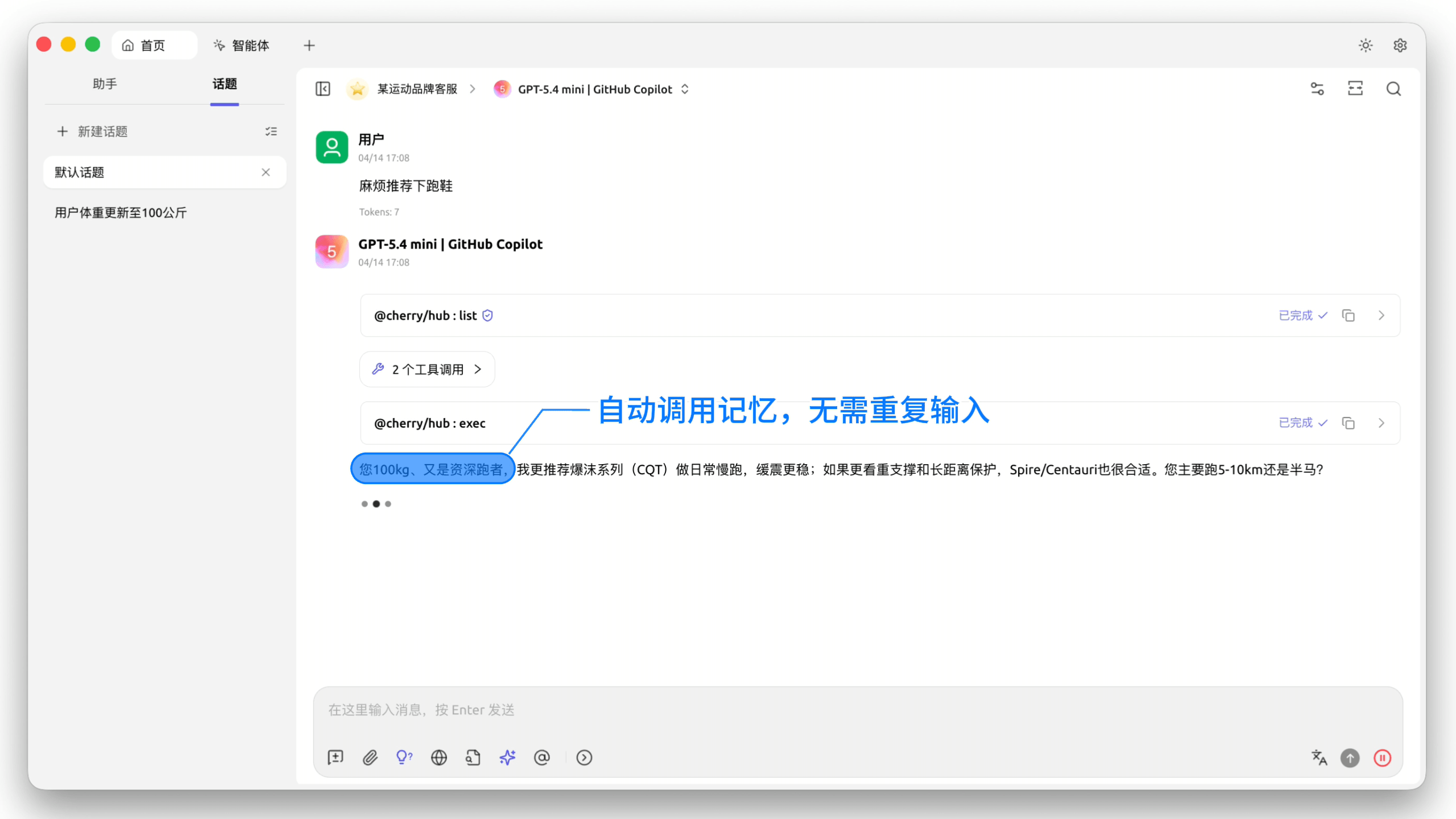
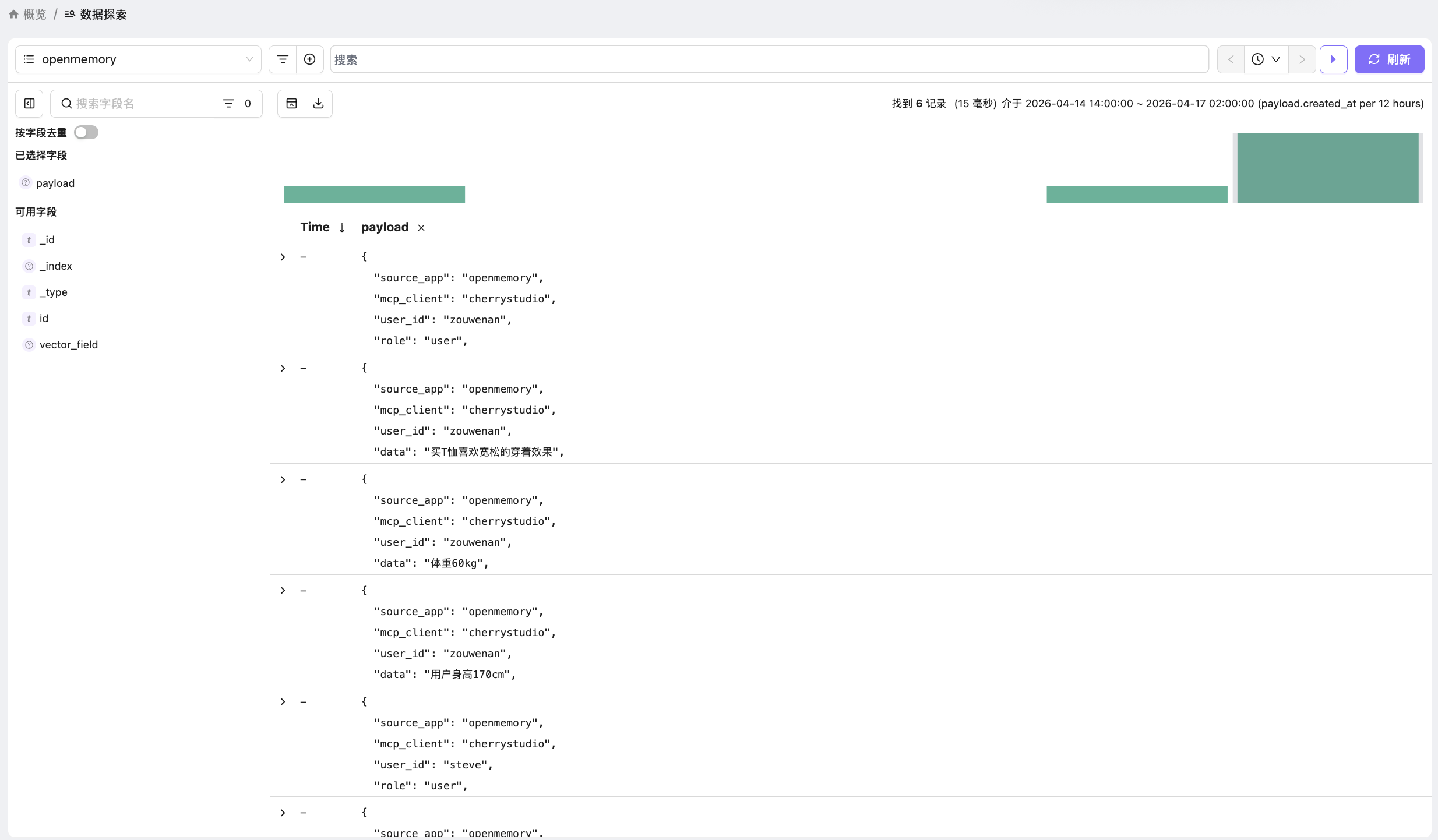
记忆可检索、可审计。所有记忆都存在 Easysearch 里,可以直接查索引看有哪些条目,不满意的可以删掉重写,完全透明可控。
演示视频
下面的视频展示了接入记忆后的实际效果 ------ Agent 在新会话中自动检索历史记忆,并将相关上下文融入回答,不再需要重复交代背景。
让 AI 记得你是谁 ------ 基于 Easysearch 的企业级 AI 记忆
代码和文档
- INFINI Labs Mem0 fork:github.com/infinilabs/mem0(
feat/easysearch分支) - 详细集成文档:Easysearch 官方文档 · Mem0 集成
- Easysearch 官网