第一题:

这题用到了挺多知识点的。
首先就是类的定义,用class加变量名来定义,然后再想定义相关属性来使用的话,还要去定义一个函数来调用,也就是__init__,这一步非常关键,直接决定你后来的东西有没有用了。
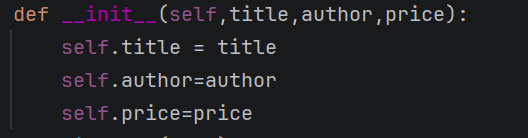
这就是最开始的写法!!!之后题目要写一个discount的写法来写出折扣,它虽然没说但是我们要自己去添加相关的错误条件的判断。这里可能出现的错误就是你输入的折扣不是一个数字,而是一个字母或者特殊字符。这时候就要用到try...except...了,那这种时候的错误叫做什么呢?应该就是值出现了错误,即ValueError,之后就是去写折扣的价格了,这里要注意要一直使用的是self.价格,这就是再类中引用价格的写法。
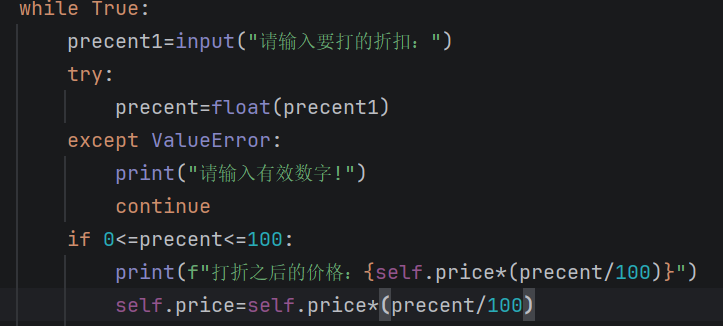
要注意的是,你在运行程序时你要让哪本书打折扣时,你在调用该函数时还要在前面加上书名的名字,即你取的变量名。


下一步就是写一个子类去继承前面的Book类,
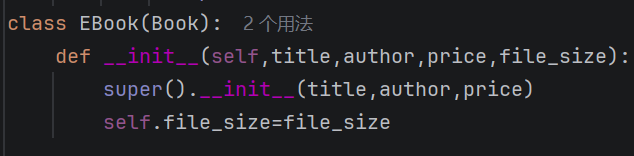
你加上一个属性很简单,就和父类写的一样即可,但是有一点难的就是,你要去写一个东西去继承父类的属性。
老样子,你要写一个__init__的函数,里面要有父类的属性同时也要包含新加的属性,那怎么继承?写一个super()后续跟上父类相关的属性就行
然后你发现它一直有一个用__str__得方法去书写书籍得信息,这中方法可以直观得感受到对象得信息,再写得时候你直接return一个格式化得东西即可,

到这里这道题就已经结束了。
第二题:

这里的第一步首先要就是写一个文件,然后把上述的东西往里写。
第二步:
就是去读取文件里的内容用到with open,为什么要到with呢?因为它可以再你读取文件结束后,自动关闭文件,

括号里的东西也是有逻辑的,第一个逗号前的就是文件名,第二个就是决定了你对这个文件要进行的操作是什么,**有'r'(只读,文件不存在会报错,可可以在这写一个文件报错,若文件存在,则从头读取),'w'(只写,文件不存在就会自动创建,若存在,就会清空所有内容,从头写),'a'(追加写入,不覆盖原内容,无文件时也会自动创建文件),'x'(无文件时自动新建,若文件存在,会直接报错)。**最后那个就是以将内容转为相关的编码表,最后的as f就是把这个文件对象命名为f,以便后续的文件操作使用。
第三步
我首先要去看下文件中有没有空格或者说是换行符,如果有,我们要使用strip来去掉,
这个的作用就是将首尾的空格全部去掉,还有lstrip的作用就是单单去掉开头的空白,rstrip的作用就是单单去掉末尾的,这里就是要使用循环来进行了: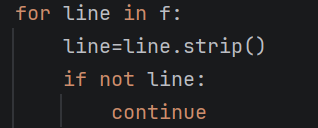
去掉所有的空行和换行符
第四步
这里呢我们就要根据你这个文件中所包含分隔每个字符的符号来进行拆分了,这题里就是以逗号来拆分的,就要使用到split,来一一分割,并用变量去接收。因为它要求是要用字典形式去接收。但这时候你要注意,因为你有三个数据,所以你整体应该是存在一个列表里的,然后你去定义一个字典类型,将多个数据存进去即可,
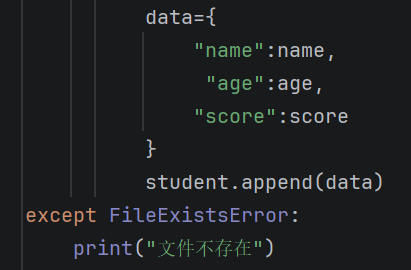
这里的student我前面已经定义这个为列表了,所以我就直接append了。
第五步:
这里题目要求我们计算平均分,那我们之要去循环我们前面的列表就行,要注意一点就是,因为我们只要每个人的分数,所以说,只要调用每个列表表的成绩那列就行,是这样的形式"score"
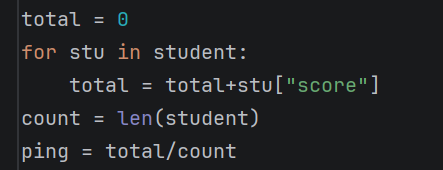
第六步:
这里就要我没将这些数据转到另一个文件里,开头还是一样,将'r'改为'w',因为我们是要再里面写文件的,你也不用先去创建一个文件,这个如果你没有文件的话,也会自动给你创建文件的。
之后就通过f.write去写入数据,再写入那三个人时也要进行循环输入,还是以列表的形式写入就ok了
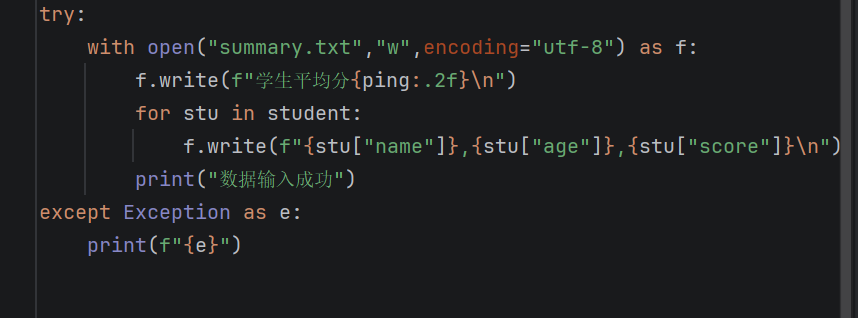
第三题:

这里就写的是conda的一些常用的命令行:
1.创建环境
conda create -n 名字 python=版本2.激活环境
conda activate 名字3.删除环境
conda remove -n 名字 --all4.装库
conda install xxx5.导出环境
conda env export > 导出的环境名6.查看所有环境
conda env list第四题:
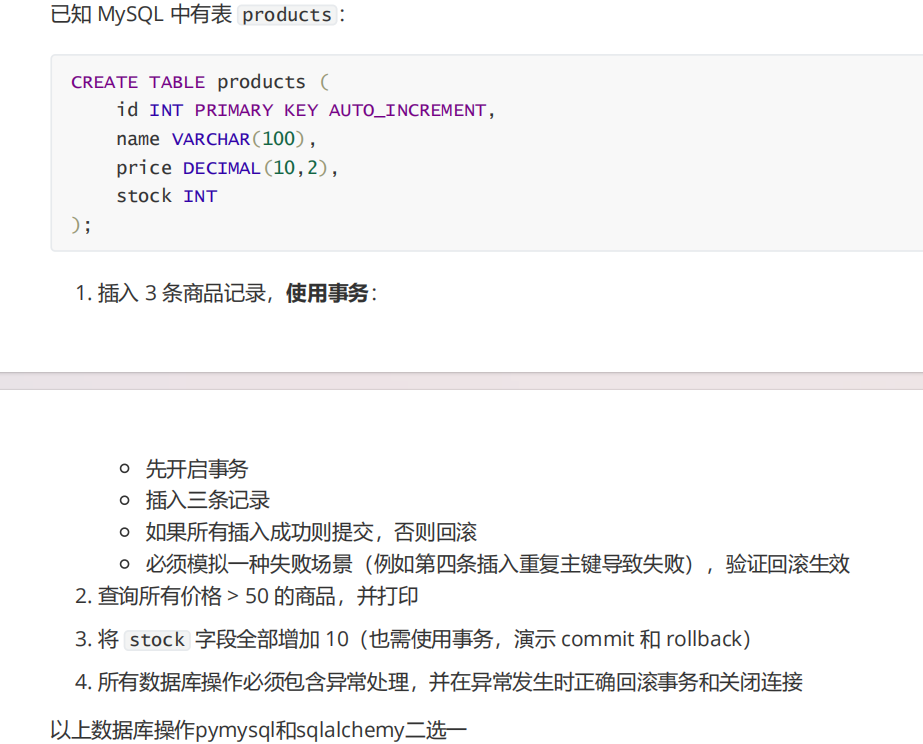
这一题的题目是这样的。
首先我使用的是sqlalchemy这个去书写相关的代码,也可以选择用原生的SQL去写,但是我觉得哪有会比较麻烦,所以我就选择使用这个去写。
首先第一步
我们要去链接上对应得数据库,这样后面我们去建表得时候就是直接建在里面了,代码是这样的
分开讲下每个部分的作用:
mysql+pymysql:就是写出sqlalchemy的写法,
//root:你就要在这后面输入你的Mysql的密码
@local....3306那里就是你的用户名以及你的接口
/的后面就是要接上你的数据库的名字,我这里就是test
最后的?charset=utf8mb4就是一个固定的输入把,可以这样去理解。。
第二步:

意思是我创建一个连接,使用这个账号去连接test库。里面的connect就是上面第一步的变量名,然后后面的echo=False是用来看你后续是否要打印出Sql语句的,False就是不用,改为True就是要。在这里面只有等号左边的名字是你可以自己随便取得,剩下得都得严格使用。
第三步:

这一步是创建以一个工厂,以便后面你会话时使用,这一步非常关键,因为你后续的session.add和session.commit都是靠这个完成的!!!
第四步:

这里就是你调用前面的工厂去生成一个会话,后续去使用,这里一定要使用session!!!
第五步:

可以理解为这是一个模板,后续所有映射数据库的表类都要继承它。才能被识别。可以说是个核心了!
第六步:
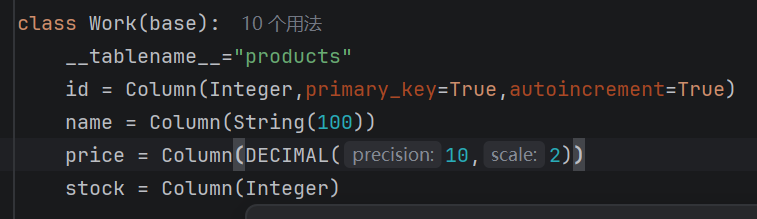
这里你就要定义一个类,名字随便你取,我这里取了Work,括号里要加上你前面的啊那个模板,这个类的第一行就是去连接你的表的名字。下来每一行就是你在那个表中所想要的字段,注意:Column时=是一定要有的,同时后面跟的是这个字段所带的类型,这里就要插入以一个知识点了,在sqlalchemy里能识别的类型名有哪些?
数字类型的有:Integer,Float,DECIMAl(精确小数).....
字符类型:String(可变字符串长度,要自己去定义长度),Text(长文本,不定义长度),CHAR(固定长度字符串)
可能你写的时候会报错,不要担心,这是因为你开头调用这个库时,没有去调用里面的这个类型,加上就可,像这样:
你可以发现在我写id那个字段时,我写了primary_key,和autoincrement这两个东西,分别有上面用呢?前一个是定义这个为主键,要求它唯一且为非空。后一个是开启自增,不用手动赋值,自动递增。
第七步:

这一步就是当你数据库中没有表时它会自动创建,如果有也没事,不吃亏。括号里的变量就是前面你搭建平台的变量!
第八步:
就到增的阶段了,因为要用到事务回滚,所以在开始写的时候就要写try:...except....的结构。要记住一点是,要去使用类,就前面你定义的东西,只有你使用了,才能去写表中应该有的东西:

之后添加进表就使用session.add和session.commit,这里可能产生的错误就是id重复了,这时候就要写一个错误即:InteerruptedError,代表的意思就是和数据库意外中断,在这下面写上session.rollback()就是一个回滚了。后面就上其他错误也是可以的:

第九步:
这里就是查的阶段,查呢我觉得大体可以分为3种。
第一种 就是查全部的东西给,这种也是最简单的,第一步就是先定义以一个变量来定义查的这个方法, ,接下来就执行原生的SQl语句,就要用到这个
,接下来就执行原生的SQl语句,就要用到这个

这里面的话scalars可以让你不用手动去拆元组,更加适配写法。最后的all是一定要加的,all代表的是全部的数据,符合我们要的要求。但是一定要记住,使用了all后,一定要用循环来去打印所有数据!!!
第二种就是通过id的唯一性来查找数据,整体没太多区别,有区别的点就在于在第一个的后面要加上where后面跟上所需判断的条件,

并且后面的all也要改为first。

因为id是唯一的只需要第一个出现的即可。
第三种就是,去查找一个变量的范围,就像这道题要找的就是价格大于50的商品。其实激素把where后面的而条件改一下即可,

但是这时候我又想了如果这个范围是左右都有那该怎么写?
只需在第一个范围后面加上另一个范围即可。像这样:

是不是非常简单!!!
第十步:
就是去增加10给每个商品的stock,相当于改了,前面两步和查一样的

都是去遍及整个表,因为这里是all所以之后要用循环去增加每一个的值,只要把你想改的值=所需要改的值就好了。

后面就是正常回滚。
到这里其实这题就已经结束了。但是这里没有涉及删的操作。我又去实现了一下:
其实有两种写法:一种就是高效直接删除,
就是直接知道要删除的目标元素,指定删除。

直接用delete去弄你设定的类即可,后面跟随的就是要改的地方。
之后就直接去执行即可:
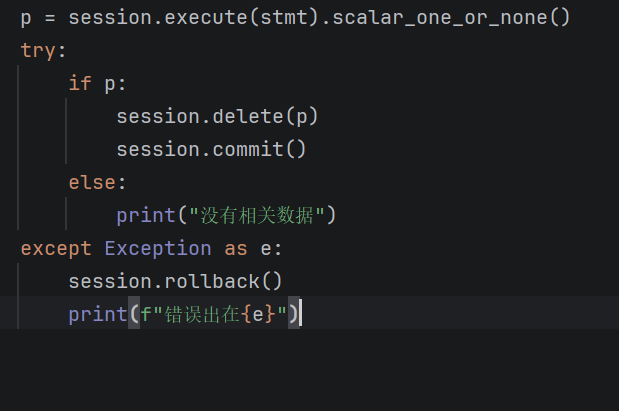
另一种就是先用数据查询,再删除对应的东西。步骤有所改变:
这是先查询,所以就先写查询对应的语句,再进行删除即可。
本题就结束了。
第五题:
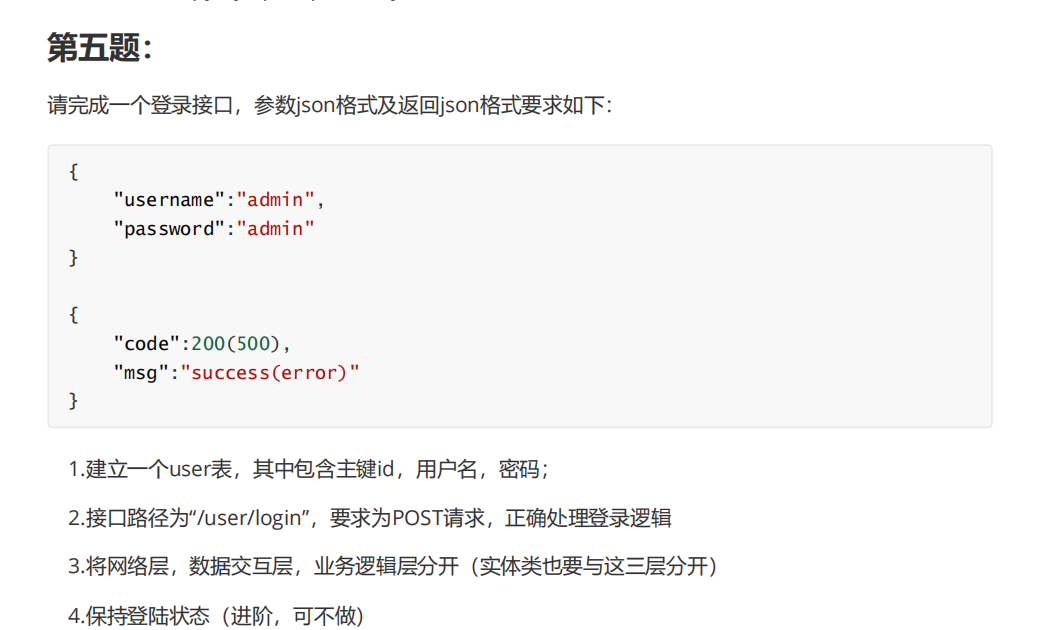
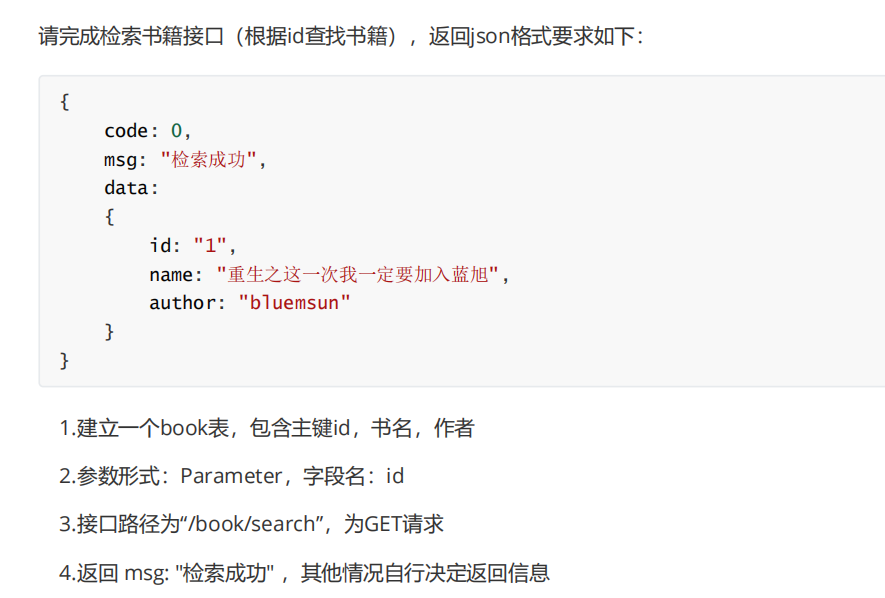
这道题要求实现一个接口,并按照三层架构划分模块,分别为控制层(表现层)、业务逻辑层、数据访问层(数据交互层)。
通俗理解:
- 控制层(Controller):接收外部请求与参数,完成基础参数校验,调用业务逻辑层处理业务,最后将处理结果封装为接口响应返回,不直接操作数据库、不编写业务规则。
- 数据访问层(数据交互层 ):仅负责与数据库进行直接交互,执行增、删、改、查等数据存取操作,只处理数据层面操作,不包含业务逻辑,和控制层无直接调用关系。
- 业务逻辑层(Service):实现项目核心业务规则、业务校验、事务管理等逻辑,调用数据访问层完成数据操作,处理后将结果交给控制层,不直接负责数据展示或接口响应返回。
首先这题前面就是常规去建表,和第四题得流程是一样得,然后其实到增删减查哪里都是一样得。要多写点地方就是后面得接口。
第一步:
我这里是用了两个库去写得,用了一个FastARI的库和pydantic库去导入BaseModel类,先用app去创建一个FASTAPI的实例,然后之后的接口都写入这里。之后还用了这个,直接对登录的类型和名字做了定义。
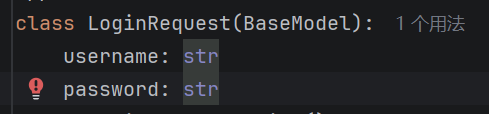
LoginRequest:自定义类名,语义为「登录请求的数据模型」,用于接收登录接口的请求体。(BaseModel):继承自pydantic.BaseModel,继承后自动获得数据解析、类型校验、自动报错等能力。
这个是因为我前面用的是类的定义去定义了层,所以要用一个变量去提取出来,
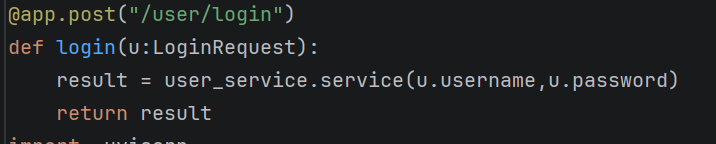
这里就是正常使用函数去返回表中的值。
最后就是正常的启动程序运行即可。
有几个注意的点就是,这个只能去处理post接口。还有就是,我这里将每个层都分装为为了一个个类让后面去调用,这样做的好处就是可以让你结构十分清晰,不会搞混。但是这时候你调用类的东西就要使用到继承。还有一个特殊的东西。

这个东西可以做到就是你这里面的函数逻辑上属于类,但是不需要用到类里面的任何方法
第六题:
这题本质也是写一个接口,前面的步骤就是到查询那一步都是没有太多区别的。这里就不过多讲述了。在这里我就没有将一个个都分装为类了。就是正常写。服务层其实也是一样的,你去调用上头的函数,任何在你的服务层就返回对应的结果即可。
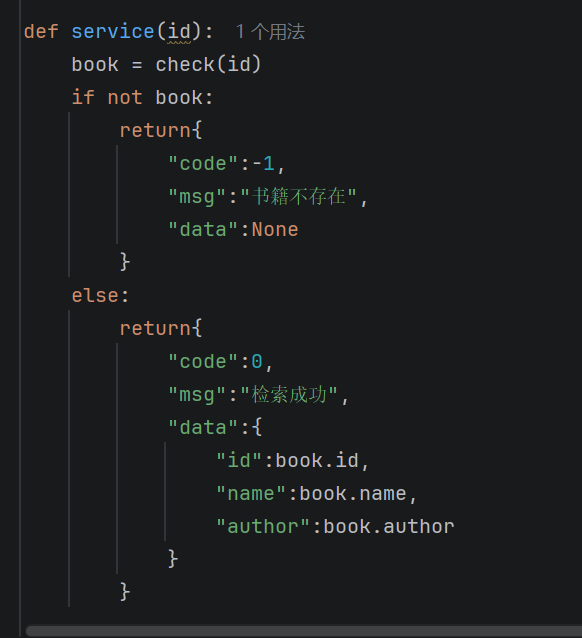
在这里想讲的重点就是最后的接口的搭建。
首先我这里使用的就是原生的方式去搭建接口。相对于使用框架来说是挺复杂的。一起来看看。
第一步就是自定义去请求处理类,去继承内置请求处理器。

为什么需要这个就因为我们后续是要用到成员的id去判断的,所以要加上这个。
下一步就是写一个get函数u,专门去处理get请求。就是要先写一个变量去接收路径

接收之后应该要有个提取把,

后面我们要在里面得到id的值,如果手动切割的话可能会有问题,所以这时候我们就可以去使用一个可以直接提取的方法,可以更轻松的得到相对应的值

这时候我们要考虑好一些特殊情况,比如处理的是其他接口,这时候我们就要返回其他东西。
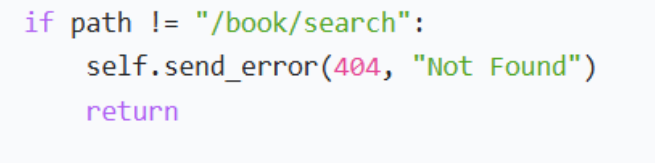
下一步就是从参数字典里获得id的值了,这里也要分为几种情况。首先就是没有传除id的参数,就直接报错,取出的值不是数字,也不对。第三个种就是正确了,才可以回到业务层去打包。
这时候到最后了,我们要手动去构造http的响应,先发动状态码200,代表成功了。后续就设置响应头,告诉那边要返回json格式,最后结束。

然后就是将字典形式转为json字符串。

在运行哪里的话就是要去定义服务的地址还要自己去创建一个http的服务器,就OK了。
最后总结一下把,我觉得通过这些题还是收获很多的,更加懂得怎么去建表啊,还有conda的一些指令也跟加了解了。明白了文件的使用方法,特别是接口那里,可选的框架多,也可以返璞归真,使用原生,这里其实我是不是很会的。整体来说我还是个小白,整篇文章若有哪里说错了,请大家多多包涵,可以评论区说出来我看看怎么处理。谢谢大家了。