1.集合通信(Collective Communications)原语
1.1 Broadcast
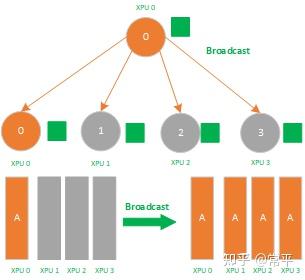
Broadcast属于1对多的通信原语,一个数据发送者,多个数据接收者,可以在集群内把一个节点自身的数据广播到其他节点上。如下图所示,圈圈表示集群中的训练加速卡节点,相同的颜色的小方块则代表相同的数据。当主节点 0 执行Broadcast时,数据即从主节点0被广播至其他节点。
1.2 Scatter
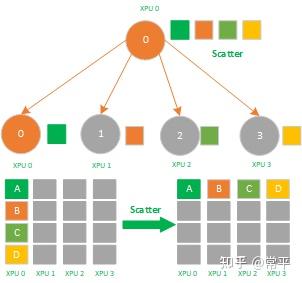
Broadcast一样,Scatter也是一个1对多的通信原语,也是一个数据发送者,多个数据接收者,可以在集群内把一个节点自身的数据发散到其他节点上。与Broadcast不同的是Broadcast把主节点0的数据发送给所有节点,而Scatter则是将数据的进行切片再分发给集群内所有的节点,如下图所示,不相同的颜色的小方块代表不相同的数据,主节点 0 将数据分为四份分发到了节点0-3。
1.3 Gather
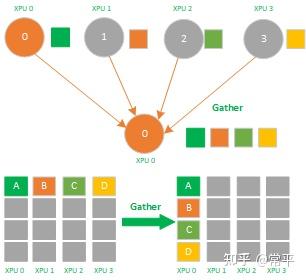
Gather操作属于多对1的通信原语,具有多个数据发送者,一个数据接收者,可以在集群内把多个节点的数据收集到一个节点上,如下图所示,不相同的颜色的小方块代表不相同的数据。
1.4 AllGather
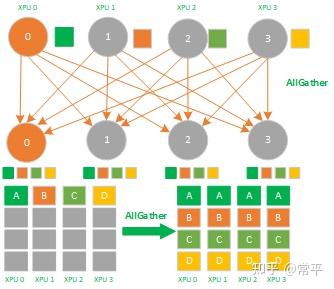
AllGather属于多对多的通信原语,具有多个数据发送者,多个数据接收者,可以在集群内把多个节点的数据收集到一个主节点上(Gather),再把这个收集到的数据分发到其他节点上(broadcast),即收集集群内所有的数据到所有的节点上。
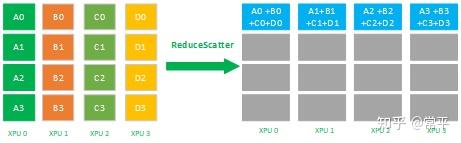
1.5 Reduce
Reduce属于多对1的通信原语,具有多个数据发送者,一个数据接收者,可以在集群内把多个节点的数据规约运算 到一个主节点上,常用的规约操作符有:求累加和SUM、求累乘积PROD、求最大值MAX、求最小值MIN、逻辑与 LAND、按位与BAND、逻辑或LOR、按位或BOR、逻辑异或LXOR、按位异或BOXR、求最大值和最小大的位置MAXLOC、求最小值和最小值的位置MINLOC等,这些规约运算也需要加速卡支持对应的算子才能生效。
Reuduce操作从集群内每个节点上获取一个输入数据,通过规约运算操作后,得到精简数据,如下图的SUM求累加和:节点0数值 5、节点1数值6、节点2数值7、节点3数值8,经过SUM运算后 累积和为 26,即得到更为精简的数值,在reduce原语里回会去调用 reduce SUM算子来完成这个求和累加。
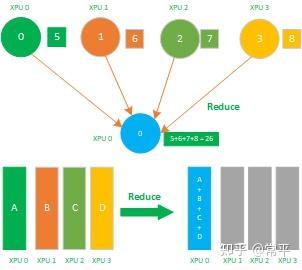
1.6 ReduceScatter
ReduceScatter属于多对多的通信原语,具有多个数据发送者,多个数据接收者,其在集群内的所有节点上都按维度执行相同的Reduce规约运算,再将结果发散到集群内所有的节点上,Reduce-scatter等价于节点个数次的reduce规约运算操作,再后面执行节点个数的scatter次操作,其反向操作是AllGather。
如下图所示,先reduce操作 XPU 0-3的数据reduce为 A(A0+A1+A2+A3) + B(B0 + B1 +B2 + B3) + C(C0 + C1 + C2 + C3) + D(D0 + D1 + D2 + D3 ) 到一张XPU上,再进行分片scatter到集群内所有的XPU卡上。
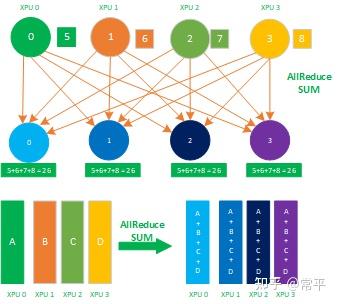
1.7 AllReduce
AllReduce属于多对多的通信原语,具有多个数据发送者,多个数据接收者,其在集群内的所有节点上都执行相同的Reduce操作,可以将集群内所有节点的数据规约运算得到的结果发送到所有的节点上。AllReduce操作可通过在主节点上执行Reduce + Broadcast或ReduceScatter + AllGather实现,如下图所示:先在主节点上执行reduce得到规约累加和26,再把这个累加和26 broadcast到其他的节点,这样整个集群内,每个节点的数值就都保持一致。
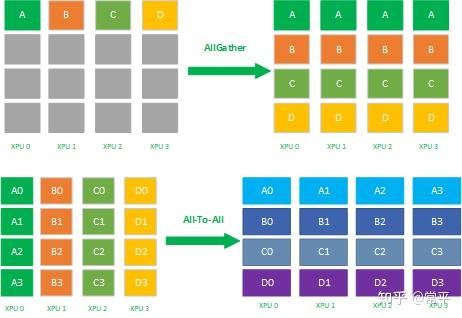
1.8 All-To-All
All-To-All操作每一个节点的数据会scatter到集群内所有节点上,同时每一个节点也会Gather集群内所有节点的数据。ALLTOALL是对ALLGATHER的扩展,区别是ALLGATHER 操作中,不同节点向某一节点收集到的数据是相同的,而在ALLTOALL中,不同的节点向某一节点收集到的数据是不同。
2.环境变量(系统配置)
- 使用方式 :在脚本中配置,或者配置在 /etc/nccl.conf 中
- 变量分类:一些环境变量用于使 NCCL 遵循系统特定的配置,可以保存在脚本和系统配置中。其他参数(列于"调试"部分)不应在生产环境中使用,也不应保留在脚本中,或仅作为临时解决方案,一旦问题解决,应立即移除。保留这些参数可能会导致程序运行不佳、崩溃或卡死。
实用性变量
NCCL_SOCKET_IFNAME
NCCL_SOCKET_IFNAME 变量指定用于通信的 IP 接口。
接受的值
定义为一个前缀列表,用于过滤 NCCL 要使用的接口。
可以提供多个前缀,用 , 符号分隔。
使用 ^ 符号,NCCL 将排除以该列表中任何前缀开头的接口。
要精确匹配(或不匹配)接口名称,请在前缀字符串开头使用 = 字符。
示例:
eth :使用所有以 eth 开头的接口,例如 eth0、eth1 等。
=eth0 :仅使用接口 eth0
=eth0,eth1 :仅使用接口 eth0 和 eth1
^docker :不使用任何以 docker 开头的接口
^=docker0 :不使用接口 docker0。
注意:默认情况下,回环接口(lo)和 docker 接口(docker*)不会被选择,除非没有其他可用接口。如果您希望优先使用 lo 或 docker* 而非其他接口,则需要使用 NCCL_SOCKET_IFNAME 显式选择它们。默认算法也会优先选择以 ib 开头的接口。设置 NCCL_SOCKET_IFNAME 将绕过自动接口选择算法,并可能使用所有匹配手动选择的接口。
测试Tips:在多网卡集群测试中,常用此变量过滤特定NIC(如ens1f0),结合nccl-tests的bandwidth测试,验证接口带宽是否饱和。如果排除docker接口,可避免容器化环境下的网络干扰。
NCCL_SOCKET_FAMILY
NCCL_SOCKET_FAMILY 变量允许用户强制 NCCL 仅使用 IPv4 或 IPv6 接口。
接受的值
设置为 AF_INET 以强制使用 IPv4,或 AF_INET6 以强制使用 IPv6。
测试Tips:IPv6测试场景中设置此变量,结合nccl-tests all_reduce_perf,检查跨节点延迟差异。默认IPv4,但大型云集群常需IPv6兼容测试。
NCCL_IB_GID_INDEX
(从 2.1.4 起)
NCCL_IB_GID_INDEX 变量定义 RoCE 模式中使用的 Global ID 索引。
请参阅 InfiniBand show_gids 命令以设置此值。
更多信息,请参阅 InfiniBand 规范 Volume 1 或供应商文档。
接受的值
默认值为 -1。
测试Tips:RoCE GID测试,设置0或1,验证IPoIB兼容性。
NCCL_IB_HCA
NCCL_IB_HCA 变量指定用于通信的 Host Channel Adapter (RDMA) 接口。
接受的值
定义为过滤 NCCL 要使用的 IB Verbs 接口的列表。该列表用逗号分隔;端口号可以使用 : 符号指定。可选前缀 ^ 表示列表是排除列表。第二可选前缀 = 表示令牌是精确名称,否则默认情况下 NCCL 将每个令牌视为前缀。
示例:
mlx5 :使用所有以 mlx5 开头的卡的所有端口
=mlx5_0:1,mlx5_1:1 :使用卡 mlx5_0 和 mlx5_1 的端口 1。
^=mlx5_1,mlx5_4 :不使用卡 mlx5_1 和 mlx5_4。
注意:使用 mlx5_1 而无前缀 = 将选择 mlx5_1 以及 mlx5_10 到 mlx5_19,如果它们存在。因此,始终推荐添加 = 前缀以确保精确匹配。
注意:NCCL 中支持的 Host Channel Adapter (HCA) 设备有固定上限 32。
测试Tips :IB卡选择测试中,设置=mlx5_0:1隔离特定端口,运行nccl-tests reduce_perf诊断RDMA瓶颈。
NCCL_IB_SL
(从 2.1.4 起)
定义Service Level(SL) 服务级别:一旦集群开启了 QoS(服务质量)、多租户、Adaptive Routing 或 拥塞控制,立刻变成性能和稳定性的"生死开关"。
1. 什么是 Service Level(SL)?
- 官方定义 (InfiniBand 规范 Volume 1):
- SL 是一个 4-bit 字段 (取值范围 0~15 ),位于每一个 InfiniBand 数据包的 Local Route Header (LRH) 中。
- 它的作用是:告诉交换机/路由器这个包属于哪一个"服务级别",从而实现流量优先级、隔离和 QoS。
- 核心机制 :
- 交换机内部有一个 SL-to-VL Mapping Table(SL 到虚拟通道的映射表)。
- 每个 SL 可以映射到一个或多个 Virtual Lane (VL)。
- 不同 VL 有独立的缓冲区和调度优先级 → 实现流量隔离(低优先级流量不会卡住高优先级)。
举个最常见的例子:
- SL = 0(默认):普通"尽力而为"流量
- SL = 1~7:高优先级、低延迟流量(如 NCCL AllReduce)
- SL = 8~15:存储、备份、管理流量(避免抢占训练网络)
2. NCCL 如何使用 NCCL_IB_SL?
NCCL 在创建所有 InfiniBand QP(Queue Pair) 时,会把这个值直接写入 LRH 的 SL 字段。
-
默认值 :0
-
接受的值:0~15(整数)
-
生效时机 :所有 NCCL 的 IB 通信(包括 AllReduce、AlltoAll、Send/Recv 等)
设置方式(最常用):把 NCCL 的所有 IB 流量提升到 SL=3(高优先级)
export NCCL_IB_SL=3
3. 什么时候必须改这个值?(真实交付案例)
| 场景 | 推荐设置 | 原因与效果 |
|---|---|---|
| 普通单租户小集群 | 默认 0 | 够用,无需改 |
| 大规模生产集群 + QoS | 1~5 | 把 NCCL 流量与存储/管理流量隔离,避免相互影响 |
| 开启 Adaptive Routing | 与 NCCL_IB_SL 配套 | 规范要求 AR 必须使用特定 SL(厂商默认通常 SL=0~3) |
| 多租户环境(共享集群) | 不同租户不同 SL | 防止一个团队的 AlltoAll 把别人卡死 |
| RoCE v2 + DCQCN 拥塞控制 | SL=1 或 2 | 与 PFC(Priority Flow Control)配合使用 |
曾经接手过一个 1024 张 H100 集群,训练一直卡在 60% 带宽。后来发现交换机开启了 QoS,默认把 SL=0 的流量降级了。我改成 NCCL_IB_SL=3 后,AllReduce 带宽直接从 180GB/s 涨到 340GB/s。
4. 与其他变量的紧密关系(千万别孤立设置)
-
NCCL_IB_TC(Traffic Class):RoCE v2 专用,配合 SL 使用(DCQCN 拥塞控制)
-
NCCL_IB_FIFO_TC:控制消息专用高优先级 TC
-
NCCL_IB_ADAPTIVE_ROUTING :开启 AR 时,必须确保 SL 是交换机允许 AR 的级别(否则 AR 失效)
-
NCCL_IB_HCA :指定哪张 IB 卡后,SL 才会应用到那张卡
最佳实践组合(交付标准模板):NCCL_IB_SL=3
NCCL_IB_TC=106
NCCL_IB_FIFO_TC=106
NCCL_IB_ADAPTIVE_ROUTING=1
NCCL_IB_TIMEOUT=20
LRH = Local Route Header(本地路由头部)
这是 InfiniBand 数据包(Packet)的最外层头部 ,也是第一个强制头部 (Link Layer Header)。
简单说:每个 IB 数据包一发出来,首先看到的就是 LRH ,它负责在同一个子网(Subnet)内完成本地路由和链路层控制。
1. LRH 的核心信息(一图秒懂)

- 长度 :固定 8 字节(64 bit)
- 位置 :紧跟在物理层 Start Delimiter 之后,是整个 IB Packet 的第一个字段
- 后面紧跟:GRH(可选)、BTH(Base Transport Header)、Payload 等
2. LRH 里到底有哪些字段?(最重要部分)
LRH 一共 8 字节,关键字段如下(从高位到低位):
| 字段 | 位宽 | 作用(NCCL 视角) |
|---|---|---|
| VL | 4bit | Virtual Lane(虚拟通道)------流量隔离核心 |
| LVer | 4bit | Link Version(链路版本,通常固定 0) |
| SL | 4bit | Service Level(服务级别) ← 这就是 NCCL_IB_SL 直接写入的地方! |
| LNH | 2bit | Link Next Header(下一个头部类型) |
| DLID | 16bit | Destination Local ID(目的本地标识符) |
| SLID | 16bit | Source Local ID(源本地标识符) |
| Raw | 4bit | Raw Traffic(原始流量标志) |
| PKey | 16bit | Partition Key(分区密钥,隔离不同租户) |
重点 :SL(Service Level)字段就藏在 LRH 第 2 个字节里 ! 这就是为什么我们设置 NCCL_IB_SL=3 时,NCCL 会把这个值直接塞进每个数据包的 LRH,交换机根据 SL 来决定走哪个 VL、是否优先调度。
3. LRH vs GRH(很多人容易混淆)
- LRH (Local Route Header):本地子网内路由用(同一子网,所有 IB 包必须有)
- GRH (Global Route Header):跨子网/路由器 时才需要(40 字节,可选)
NCCL 绝大多数通信都在同一个子网内,所以 LRH 是必须的,GRH 通常不需要。
4. 在 NCCL 测试中的实际意义
- 每个 NCCL 的 IB QP(Queue Pair)创建时,LRH 会被自动填充
- NCCL_IB_SL 的值 → 直接写入 LRH 的 SL 字段
- 如果你的交换机开启了 QoS / PFC / Adaptive Routing,LRH 的 SL 值 决定了你的 AllReduce / AlltoAll 流量会不会被降级、卡住或走 AR 路径
NCCL_IB_TC
1. 官方定义 & 基本信息
-
参数全称:NCCL_IB_TC(InfiniBand Traffic Class)
-
作用:定义 InfiniBand 流量类字段(8-bit 值)。
-
默认值:0
-
接受范围:0~255(任何整数)
-
生效范围:所有使用 IB Verbs 传输的 QP(Queue Pair),包括 AllReduce、AlltoAll 等集体操作。
-
文档引用 :InfiniBand Architecture Specification Volume 1(GRH 中的 Traffic Class 字段)或 Mellanox/NVIDIA 供应商文档。
设置方法(最常见):export NCCL_IB_TC=106 # 生产环境推荐值(根据自身网络环境进行配置)
2. 核心区别:纯 InfiniBand (IB) vs RoCE(尤其是 RoCE v2)
两种网络完全不同的实现方式和影响:
纯 InfiniBand(原生 IB,IBTA 协议)
- TC 放在哪里 ?
- 位于 Global Route Header (GRH) 的 Traffic Class 字段(8-bit)。
- GRH 只在跨子网路由时才会出现(大多数单子网集群不启用 GRH)。
- 实际作用 :
- 主要用于路由器级 QoS(跨子网时)。
- 在单子网内(99% 的训练集群),几乎无作用 !交换机主要看的是 LRH 中的 SL(Service Level) 来映射 VL。
- 什么时候有用 ?
- 大型多子网路由环境。
- 与 Adaptive Routing 配合时可辅助优先级。
- 实际影响:很小。改了也基本看不出带宽变化。
RoCE(RDMA over Converged Ethernet,尤其是 RoCE v2)
- TC 放在哪里 ?
- 直接映射到 IP 头部 :
- RoCE v2 用 IPv6 时 → 整个 8-bit Traffic Class 字段。
- RoCE v2 用 IPv4 时 → 映射到 DSCP(6-bit)+ ECN(2-bit),NCCL 取高 6 位作为 DSCP。
- 直接映射到 IP 头部 :
- 实际作用(超级重要!) :
- DCQCN 拥塞控制的核心输入(Data Center Quantized Congestion Notification)。
- PFC(Priority Flow Control)优先级映射的依据(与交换机 PFC 优先级队列绑定)。
- 让 NCCL 的数据流量(AllReduce)与控制流量、管理流量、存储流量严格隔离,避免丢包和拥塞扩散。
- 实际影响 :极大! 正确设置后,AllReduce 带宽可提升 20~50%,延迟降低 30%+;设置错会导致 DCQCN 失效、PFC 风暴、训练卡死。
| 项目 | 纯 InfiniBand (IB) | RoCE v2 |
|---|---|---|
| TC 字段位置 | GRH.Traffic Class | IP 头部(IPv6 TC 或 IPv4 DSCP) |
| 主要作用 | 跨子网路由 QoS | DCQCN 拥塞控制 + PFC 优先级 |
| 对性能影响 | 很小(单子网几乎无效) | 极大(必调参数) |
| 推荐值 | 保持默认 0 | 160(最常用)或 0 |
| 与 SL 的关系 | 辅助 SL | 与 NCCL_IB_SL 共同决定优先级 |
3. 生产环境推荐值 & 搭配方案
# RoCE 集群(强烈推荐)
NCCL_IB_TC=160 # 数据流量高优先级
NCCL_IB_FIFO_TC=160 # 控制消息也同优先级(2.22.3+)
NCCL_IB_SL=3 # 配合使用
NCCL_IB_ADAPTIVE_ROUTING=1 # AR 开启时更有效
# 纯 IB 集群
NCCL_IB_TC=0 # 默认即可
NCCL_IB_SL=3 # 重点调这个为什么 160 是黄金值?
- 160 的二进制是 映射到DSCP为40,交换机通常映射到高优先级 PFC 队列。
- NVIDIA/Mellanox 官方推荐值,所有新版驱动/交换机默认支持。
4. 实战测试验证命令
# 查看实际发包的 TC/DSCP 值(需要 root)
ibdump -d mlx5_0 -c -l 50 | grep -E "DSCP|TC|Traffic Class"
# 检查交换机侧 PFC 状态
# 在交换机上执行:
show interface ethernet <port> pfc5. 常见问题排查
- RoCE 带宽低 → 99% 是 NCCL_IB_TC 没设或设错(导致 DCQCN 不触发)。
- PFC 风暴 → TC 和交换机 PFC 优先级映射不一致。
- 纯 IB 下改了没效果 → 正常,因为 GRH 没启用。
NCCL_DEBUG
NCCL_DEBUG 是 NCCL 中最核心、最常用的调试环境变量,几乎所有 NCCL 问题排查、性能分析、挂起诊断都离不开它。
1. 四个级别详解(官方接受的值)
| 值 | 中文含义 | 输出详细程度 | 典型输出内容示例 | 推荐使用场景 | 输出量级(大致) |
|---|---|---|---|---|---|
| VERSION | 只打印版本 | 极低 | NCCL 2.29.1(程序启动时一行) | 确认 NCCL 版本(打包/部署验证) | 极少 |
| WARN | 警告 + 错误 | 低 | WARN: Call to ibv_create_qp failed 或 WARN: Got async event: Fatal Error | 生产环境监控、快速发现明显错误 | 很少 |
| INFO | 信息 + 警告 + 错误 | 中等 | 初始化拓扑、选算法、通道数、插件加载、网络接口选择、集体调用参数等 | 日常调试主力,大多数问题在这里解决 | 中等(推荐) |
| TRACE | 跟踪 + INFO + 警告 + 错误 | 极高 | 每个函数调用入口/出口、参数值、内部状态机变化、RDMA 操作细节、内存地址等 | 深度挂起分析、协议/算法 bug、极难复现问题 | 非常大 |
关键点:
- 级别是递增的:TRACE > INFO > WARN > VERSION
- 设置了高级别会自动包含低级别内容(TRACE 包含 INFO 和 WARN)
- 默认值:无(相当于不打印,除非出错时有少量输出)
2. 每个级别的典型输出内容
VERSION
NCCL 2.29.1 (May 15 2025)WARN(常见错误示例)
WARN [0] Call to ibv_create_qp failed with status 12 (IBV_WC_RETRY_EXC_ERR)
WARN [0] Got async event on device mlx5_0: Fatal Error - port down
WARN [0] NCCL Internal Error : Connection timeoutINFO(最常用,信息量适中)
NCCL INFO NET/IB : Using mlx5_0:1
NCCL INFO NET/Socket : Selected interface ens1f0
NCCL INFO Trees [0] 64/64 -> 0/64 [receive] [0] -> 0
NCCL INFO AllReduce : Using Ring algorithm
NCCL INFO Channel 00/00 : 0[170] -> 1[180] [receive] via NET/IB/0
NCCL INFO comm 0x7f... rank 0 nranks 8 cudaDev 0 busId 0000:07:00.0TRACE(非常详细,适合深度调试)
TRACE [0] ncclAllReduce entering sendbuff=0x7f... recvbuff=0x7f... count=1048576 datatype=ncclFloat op=ncclSum comm=0x7f... stream=0x7f...
TRACE [0] ncclCommInitRank : rank 0 nranks 8 uniqueId=...
TRACE [0] ncclTopoGetComp : selected Ring algo for AllReduce
TRACE [0] send 0x7f... size 4194304 to rank 1 via NET/IB qp 0x55...
TRACE [0] recv credit returned from rank 73. 推荐组合
日常基准测试 + 轻度调试(推荐起点):
export NCCL_DEBUG=INFO
export NCCL_DEBUG_SUBSYS=INIT,NET,GRAPH,TUNING,COLL,ENV
export NCCL_DEBUG_FILE=nccl_log.%h.%p.txt # 每个进程独立日志文件深度挂起 / 协议 bug 排查:
export NCCL_DEBUG=TRACE
export NCCL_DEBUG_SUBSYS=ALL # 所有子系统
export NCCL_DEBUG_FILE=trace_%h_%p.log
export NCCL_DEBUG_TIMESTAMP_FORMAT="[%F %T.%6f]" # 高精度时间戳只想看错误和版本:
export NCCL_DEBUG=WARN4. NCCL_DEBUG_SUBSYS
NCCL 把日志分成很多子系统(subsystem),你可以只看你关心的部分 ,避免日志爆炸。
常用子系统(文档完整列表):
| 子系统 | 含义 | 推荐调试场景 |
|---|---|---|
| INIT | 初始化、comm 创建 | 启动挂起、uniqueId 问题 |
| NET | 网络插件、IB/Socket 连接 | 网络超时、插件加载失败 |
| GRAPH | 拓扑检测、环/树构建 | 拓扑不对、通道数异常 |
| TUNING | 算法/协议选择 | 选错 Ring/Tree/LL128 |
| COLL | 集体操作执行 | AllReduce 卡住、数据错误 |
| ENV | 环境变量解析 | 变量没生效 |
| BOOTSTRAP | 早期引导、rank 同步 | 大规模初始化慢 |
| PROFILE | 粗粒度性能分析 | 整体耗时分布 |
| ALL | 所有子系统 | 深度分析(日志会很大) |
NCCL_DEBUG_FILE(从 2.2.12 起)
NCCL_DEBUG_FILE 变量将 NCCL 调试日志输出定向到文件。
文件名格式可以设置为 filename.%h.%p ,其中 %h 被主机名替换,%p 被进程 PID 替换。此路径不接受 ~ 字符,请先转换为相对或绝对路径。
接受的值
默认输出文件为 stdout ,除非设置此环境变量。
文件名也可以设置为 /dev/stdout 或 /dev/stderr,以将 NCCL 调试日志输出定向到这些预定义 I/O 流。这也会使输出行缓冲。
设置 NCCL_DEBUG_FILE 将导致 NCCL 创建并覆盖任何先前同名文件。
注意:如果文件名在所有作业进程中不是唯一的,则输出可能丢失或损坏。
测试Tips:日志文件测试,设置filename.%h.%p多进程诊断。
NCCL_DEBUG_TIMESTAMP_FORMAT(从 2.26 起)
NCCL_DEBUG_TIMESTAMP_FORMAT 变量允许用户更改打印调试日志消息时使用的格式。
时间打印为本地时间。这可以通过设置 TZ 环境变量更改。UTC 可通过设置 TZ=UTC 获得。TZ 的有效值如:US/Pacific、America/Los_Angeles 等。
注意,非调用 TRACE 级日志继续打印自 NCCL 调试子系统初始化以来的微秒。TRACE 日志也可以在开始时打印 strftime 格式的时间戳,如果如此配置(见 NCCL_DEBUG_TIMESTAMP_LEVELS)。(从 2.26 起)格式中的下划线渲染为空格。
接受的值
环境变量的值传递给 strftime,因此任何有效格式均有效。默认值为 [%F %T],即 [YYYY-MM-DD HH:MM:SS]。如果设置值但为空,则不打印时间戳 (NCCL_DEBUG_TIMESTAMP_FORMAT=)。
除了 strftime 支持的转换规范,还可以指定 %Xf,其中 X 是 1-9 的单个数字位。这将打印秒的分数。X 的值指示将打印多少位。例如,%3f 将打印毫秒。值用零填充。例如:[%F %T.%9f]。(注意,这只能在格式字符串中使用一次。)
测试Tips:时间戳格式自定义,设置详细格式分析日志时序。
NCCL_DEBUG_TIMESTAMP_LEVELS(从 2.26 起)
NCCL_DEBUG_TIMESTAMP_LEVELS 变量允许用户根据日志级别设置哪些日志行获取时间戳。
接受的值
值应是逗号分隔的级别列表,这些级别应有时间戳。有效级别为:VERSION、WARN、INFO、ABORT 和 TRACE。此外,ALL 可用于为所有级别开启。设置为空值将为所有级别禁用。如果值以插入符 (^) 前缀,则列出的级别将不记录时间戳,其余将记录。
默认是为 WARN 启用时间戳,但为其余禁用。
例如,NCCL_DEBUG_TIMESTAMP_LEVELS=WARN,INFO,TRACE 将为警告、信息日志和跟踪开启。或者,NCCL_DEBUG_TIMESTAMP_LEVELS=^TRACE 将为除跟踪外的所有内容开启,它们(除调用跟踪外)有自己的时间戳类型(自 nccl 调试初始化以来的微秒)。
测试Tips:级别时间戳控制,设置^TRACE简化跟踪日志。
NCCL_COLLNET_ENABLE(从 2.6 起)
启用 CollNet 插件的使用。
CollNet 是什么?
CollNet (Collective Network 的缩写)是 NCCL 2.6 引入的一种网络加速集体操作算法,核心思想是:
把部分集体操作(主要是 AllReduce 中的归约计算)卸载(offload)到网络设备 (交换机或网络接口)中去做,而不是全部在 GPU 上计算。
这能显著减少跨节点数据传输量和延迟,尤其在大规模多节点集群中效果明显。
CollNet 的关键依赖:
- 需要支持in-network computing 的网络硬件
- 最常见的是 NVIDIA 的 SHARP (Scalable Hierarchical Aggregation and Reduction Protocol)技术
- SHARP 是 Mellanox(现 NVIDIA Networking)开发的交换机级聚合/归约协议
- 通过 NCCL 的 nccl-rdma-sharp-plugins(SHARP 插件)实现
- CollNet 是 NCCL 的算法层 ,SHARP 是网络层实现之一
CollNet 的工作原理(简化版):
- 传统 Ring/Tree AllReduce:每个 GPU 都要发送/接收完整数据 → 跨节点流量巨大
- CollNet + SHARP:交换机收到部分数据后直接在交换机上做归约(sum/max 等),只把结果发给下一个节点 → 网络流量减少 50%~70%,延迟大幅降低
变体(NCCL 内部实现):
- CollNet Chain:节点内 GPU 链式排列 + 跨节点 CollNet
- CollNet Direct:节点内 All-to-All 式 + 跨节点 CollNet
- 后来演进为 NVLS (NVLink SHARP,节点内用 NVSwitch 做 SHARP)和 NVLSTree 等
什么时候需要启用 NCCL_COLLNET_ENABLE=1?
| 场景 | 是否推荐启用 | 预期收益 | 前提条件 |
|---|---|---|---|
| 小规模(< 4 节点) | 不推荐 | 收益小,甚至可能退化 | --- |
| 中大规模(8~32 节点) | 可选 | 带宽提升 20%~50% | 有 SHARP 支持的交换机 + 安装 sharp 插件 |
| 超大规模(64+ 节点) | 强烈推荐 | 带宽提升 50%+,延迟显著降低 | Mellanox/NVIDIA Quantum 交换机 + SHARP |
| 纯 IB/RoCE 但无 SHARP 硬件 | 无意义 | 不会生效(fallback 到 Ring/Tree) | --- |
| AWS EFA / GCP gVNIC 等云网络 | 通常不适用 | 云厂商网络不支持 SHARP | --- |
CollNet vs 其他算法对比
| 算法 | 需要硬件支持 | 跨节点收益 | 典型带宽提升 | 适用规模 |
|---|---|---|---|---|
| Ring | 无 | 基准 | --- | 所有 |
| Tree | 无 | 中等 | 10~30% | 中等规模 |
| CollNet | SHARP 支持的交换机 | 高 | 30~70%+ | 大规模 |
| NVLS | NVSwitch + SHARP | 极高 | 更高 | DGX/HGX 系统 |
接受的值
默认值为 0,定义并设置为 1 以使用 CollNet 插件。
测试Tips:CollNet测试,启用验证硬件加速集体。
NCCL_COLLNET_NODE_THRESHOLD(从 2.9.9 起)
节点数阈值,低于该阈值 CollNet 将不启用。
接受的值
默认值为 2,定义并设置为整数。
测试Tips:小规模集群测试,设置4避免CollNet开销。
NCCL_CTA_POLICY(从 2.29 起,遗留值从 2.27 起)
NCCL_CTA_POLICY 变量允许用户设置 NCCL 通信器的策略。CTA 在这里指的是 CUDA 中 Cooperative Thread Array (合作线程数组),即 NCCL 内核启动时每个通信通道使用的 CUDA 线程块(block)数量。CTA 数量直接影响:
- 通信性能(带宽、延迟)
- GPU 资源占用(SM 利用率、寄存器、共享内存)
- 计算与通信的重叠能力(overlap)
NCCL_CTA_POLICY 允许用户在性能、效率、零 CTA(zero-CTA 优化)之间做取舍。默认是 DEFAULT,大多数场景下表现最佳。
接受的值
设置为 DEFAULT(或 0,遗留)以使用 NCCL_CTA_POLICY_DEFAULT 策略(默认)。
设置为 EFFICIENCY(或 1,遗留)以使用 NCCL_CTA_POLICY_EFFICIENCY 策略。
设置为 ZERO(或 2,遗留)以使用 NCCL_CTA_POLICY_ZERO 策略。
使用 | 操作符设置多个非遗留策略。
有关 NCCL 策略的更多解释,请参阅。
对比表格(清晰总结)
| 策略 | 值(字符串/整数) | 核心目标 | CTA 使用策略 | 性能影响(通信) | 资源占用(GPU SM) | 计算-通信重叠 | 支持的操作(典型) | 推荐场景 | 是否默认 |
|---|---|---|---|---|---|---|---|---|---|
| DEFAULT | DEFAULT / 0 | 最大化端到端性能 | 自动动态调整(通常较高 CTA) | 最高(峰值带宽) | 中~高 | 中等 | 所有集体操作 | 标准训练/推理、nccl-tests 基准 | 是 |
| EFFICIENCY | EFFICIENCY / 1 | 资源效率优先 | 倾向使用较少 CTA | 略低(但稳定) | 低 | 较好 | 所有集体操作 | 计算密集型任务、功耗敏感、多任务并发 | 否 |
| ZERO | ZERO / 2 | 最大化 zero-CTA 重叠 | 尽可能 zero-CTA(用 CE 等) | 取决于硬件支持 | 极低(接近 0) | 极好 | AlltoAll、AllGather、Scatter、Gather(AllReduce 暂不支持) | 支持 zero-CTA 的硬件 + 特定集体操作 | 否 |
测试Tips:CTA策略调优,设置EFFICIENCY优化效率测试。
NCCL_NETDEVS_POLICY(从 2.28 起)
NCCL_NETDEVS_POLICY 变量允许用户设置网络设备分配给 GPU 的策略。
对于每个 GPU,NCCL 自动检测可用网络设备,考虑其网络带宽和节点拓扑。
接受的值
如果设置为 AUTO(默认),NCCL 还会考虑相同通信器中的其他 GPU 以分配网络设备。
在特定场景中,此策略可能导致不同通信器的不同 GPU 共享相同网络设备,从而影响性能。
如果设置为 MAX:N,NCCL 使用每个 GPU 可用网络设备中的最多 N 个。
这旨在当 AUTO 发生设备共享并影响性能时使用。
如果设置为 ALL,NCCL 将为每个 GPU 使用所有可用网络设备,不考虑其他 GPU。
测试Tips:网络设备分配测试,设置MAX:2避免共享瓶颈。
NCCL_TOPO_FILE
(从 2.6 起)
在检测拓扑前加载的 XML 文件路径。默认情况下,如果存在,NCCL 将加载 /var/run/nvidia-topologyd/virtualTopology.xml。
接受的值
可访问文件路径,描述部分或全部拓扑。
测试Tips:拓扑文件注入测试,用于模拟自定义拓扑。
NCCL_TOPO_DUMP_FILE(从 2.6 起)
检测后转储 XML 拓扑的文件路径。
接受的值
将创建或覆盖的文件路径。
测试Tips:拓扑转储,设置路径分析检测结果。
不常用变量
NCCL_SOCKET_RETRY_CNT
(从 2.24 起)
NCCL_SOCKET_RETRY_CNT 变量指定在 ETIMEDOUT、ECONNREFUSED 或 EHOSTUNREACH 错误后,NCCL 重试建立套接字连接的次数。
ETIMEDOUT、ECONNREFUSED 或 EHOSTUNREACH 是 Linux/Unix 系统下 socket(套接字)编程 中常见的 errno 错误码(定义在 头文件中),专门用于描述建立 TCP 连接或网络通信时遇到的失败情况。
1. ETIMEDOUT(连接超时)
- 中文含义:操作超时 / 连接超时
- 英文全称:Connection timed out
- errno 值:110(或 110,在大多数系统上)
- 发生场景 :
- 对端主机存在,但不响应(例如对端 NCCL 进程还没启动、防火墙丢包、网络拥塞严重)
- 路由存在,但数据包在路上"迷路"太久(跨数据中心、长距离 IB/Socket)
- NCCL 上下文:NCCL 在调用 connect() 或等待对端回复时超过内部超时(默认几秒到几十秒),就会报这个错。
- 测试Tips:我经常用 tc 命令模拟高延迟(tc qdisc add dev eth0 root netem delay 500ms),故意触发 ETIMEDOUT,然后观察 NCCL 是否通过 NCCL_SOCKET_RETRY_CNT 自动重试。
2. ECONNREFUSED(连接被拒绝)
- 中文含义:连接被拒绝
- 英文全称:Connection refused
- errno 值:111
- 发生场景 (最常见!):
- 对端根本没有进程在监听该端口(NCCL 进程还没启动、crash 了、端口被占用)
- 防火墙明确拒绝(iptables、firewalld、云安全组)
- 对端 socket 处于 TIME_WAIT 或 CLOSED 状态
- NCCL 上下文:最常见的"对端还没 ready"的情况,尤其在多节点启动顺序不对时(比如 MPI 启动 NCCL 时部分节点晚了)。
- 测试Tips:我交付时常用 nc -l -p 端口 先监听,再启动 NCCL 测试;如果故意 kill 对端进程,就能立刻重现 ECONNREFUSED。
3. EHOSTUNREACH(主机不可达)
- 中文含义:主机不可达
- 英文全称:No route to host
- errno 值:113
- 发生场景 :
- 路由问题:没有到对端 IP 的路由(网关挂了、VPC 路由表错误、跨子网没打通)
- 网络分区(交换机端口 down、光纤断、IB 子网管理器故障)
- 对端 IP 根本不存在或被 ARP 解析失败
- NCCL 上下文:多机集群中最典型的"网络不通"错误,尤其在 RoCE/Socket 模式下跨机架时。
- 测试Tips:我常用 ip route + ping 先验证路由,再跑 all_reduce_perf,一旦出现 EHOSTUNREACH,立刻检查交换机/IB 子网。
接受的值
默认值为 34,任何正值均有效。
测试Tips:网络不稳定测试(如模拟节点故障),增加此值到50+,观察重试机制在nccl-tests持续运行中的鲁棒性。默认34对应约60秒总重试时间。
NCCL_SOCKET_RETRY_SLEEP_MSEC
(从 2.24 起)
NCCL_SOCKET_RETRY_SLEEP_MSEC 变量指定在第一个 ETIMEDOUT、ECONNREFUSED 或 EHOSTUNREACH 错误后,NCCL 在重试建立套接字连接前等待的毫秒数。
对于后续错误,等待时间与错误计数线性缩放。因此,总时间将是 (N+1) N/2 NCCL_SOCKET_RETRY_SLEEP_MSEC,其中 N 由 NCCL_SOCKET_RETRY_CNT 给出。
使用 NCCL_SOCKET_RETRY_CNT 和 NCCL_SOCKET_RETRY_SLEEP_MSEC 的默认值,总重试时间约为 60 秒。
接受的值
默认值为 100 毫秒,任何正值均有效。
测试Tips:与上变量结合,用于压力测试套接字连接稳定性。设置小值(如50ms)模拟高频重试,检查CPU负载。
NCCL_SOCKET_POLL_TIMEOUT_MSEC
(从 2.28 起)
NCCL_SOCKET_POLL_TIMEOUT_MSEC 变量指定轮询的超时(毫秒),这可以减少引导期间的 CPU 使用率。通常 NCCL 会重试操作直到完成。
在尝试之间轮询应减少 CPU 负载,以便它可以从事可能使操作更快完成的活动。
接受的值
非负整数。旧行为对应于 0(默认)。如果为 0,它不会轮询,而是保持尝试推进套接字操作而无暂停。如果非零,它将在尝试再次推进操作之前轮询该时间量。
测试Tips:引导阶段CPU高负载测试中,设置100ms,观察nccl-tests启动时间减少。默认0适合低延迟场景。
NCCL_SOCKET_NTHREADS
(从 2.4.8 起)
NCCL_SOCKET_NTHREADS 变量指定套接字传输每个网络连接使用的 CPU 辅助线程数。增加此值可能会增加套接字传输性能,但以更高的 CPU 使用率为代价。
接受的值
1 到 16。在 AWS 上,默认值为 2;在具有 gVNIC 网络接口的 Google Cloud 实例上,默认值为 4(从 2.5.6 起);在其他情况下,默认值为 1。
对于通用 100G 网络,此值可以手动设置为 4。但是,NCCL_SOCKET_NTHREADS 和 NCCL_NSOCKS_PERTHREAD 的乘积不能超过 64。请参阅 NCCL_NSOCKS_PERTHREAD。
测试Tips :多线程套接字测试中,设置4,运行nccl-tests alltoall_perf,监控CPU利用率 vs 带宽提升。AWS/GCP默认优化已好。
AWS(Amazon Web Services)------ 亚马逊云科技 GCP(Google Cloud Platform)------ 谷歌云
NCCL_NSOCKS_PERTHREAD
(从 2.4.8 起)
NCCL_NSOCKS_PERTHREAD 变量指定套接字传输每个辅助线程打开的套接字数。在每个套接字速度受限的环境中,将此变量设置为大于 1 可能会改善网络性能。
接受的值
在 AWS 上,默认值为 8;在其他情况下,默认值为 1。
对于通用 100G 网络,此值可以手动设置为 4。但是,NCCL_SOCKET_NTHREADS 和 NCCL_NSOCKS_PERTHREAD 的乘积不能超过 64。请参阅 NCCL_SOCKET_NTHREADS。
测试Tips:与上结合,测试多套接字聚合带宽。设置8,适合AWS EFA测试,避免超过64限制导致崩溃。
NCCL_CROSS_NIC
NCCL_CROSS_NIC 变量控制 NCCL 是否允许环/树使用不同 NIC,导致节点间通信在不同节点上使用不同 NIC。
为了最大化节点间通信性能当使用多个 NIC 时,NCCL 尝试在节点间通信时使用相同的 NIC,以允许每个节点上的每个 NIC 连接到不同网络交换机(网络轨道)的网络设计,并避免任何流量干扰风险。
因此 NCCL_CROSS_NIC 设置依赖于网络拓扑,特别是网络结构是否轨道优化。
这对仅有 一个 NIC 的系统无效果。
接受的值
0:始终为相同环/树使用相同 NIC,以避免跨网络轨道。适合每个 NIC 交换机(轨道)的网络,具有慢速跨轨道连接。请注意,如果通信器不在每个节点上包含相同 GPU,NCCL 可能仍需跨 NIC 通信。
1:允许为相同环/树使用不同 NIC。这适合所有 NIC 从一个节点连接到相同交换机的网络,因此尝试跨相同 NIC 通信不会帮助避免流量碰撞。
2:(默认)尝试为相同环/树使用相同 NIC,但如果会导致更好性能,仍允许使用不同 NIC。
测试Tips:多NIC轨道测试中,设置0验证轨道隔离性能;设置1测试全交换机拓扑。结合nccl-tests检查跨节点AllReduce带宽。
NCCL_IB_TIMEOUT
NCCL_IB_TIMEOUT 变量控制 InfiniBand Verbs 超时。
超时计算为 4.096 µs 2 ^ timeout*,正确值依赖于网络大小。
在非常大的网络上增加该值可能有帮助,例如,如果 NCCL 在* ibv_poll_cq* 调用中以错误 12 失败。
更多信息,请参阅 InfiniBand 规范 Volume 1 的第 12.7.34 节(Local Ack Timeout)。
1. 节标题与官方定义
12.7.34 Local ACK Timeout
This field specifies the local ACK timeout value for this QP.
规范核心描述(原文大意):
- 该字段用于定义 Queue Pair (QP) 在 Reliable Communication (主要是 RC 服务)中,发送方(Requester)等待接收方(Responder)返回 ACK(Acknowledge)包 的最大时间。
- 如果超过此时间仍未收到 ACK,QP 会触发重传机制(配合后续 12.7.38 Retry Count 节)。
- 这是一个 5-bit 字段(取值范围 0~31),编码在 QP 属性中。
2. 关键计算公式(规范最核心内容)
规范明确给出的超时计算公式 为:
Timeout period = 4.096 μs × 2^(Local ACK Timeout value)
- Local ACK Timeout value 就是你设置的那个数值(NCCL 中对应
NCCL_IB_TIMEOUT)。 - 0 = 禁用超时机制(不推荐生产环境)。
- 规范特别注明:
- 实际硬件超时可能在 1× 到 4× 计算值之间波动(由于调度、架构等因素)。
- "The minimum acceptable value of Local ACK Timeout, other than zero, shall be defined by the CA vendor."(每个 HCA 厂商会强制一个最低值,通常 8~16)。
3. 常见取值与实际时间换算表(供你直接使用)
| Local ACK Timeout 值 | 计算时间(约) | NCCL 历史默认 / 推荐场景 |
|---|---|---|
| 14 | 67.1 ms | 早期 NCCL 默认(小集群) |
| 18 | 1.07 秒 | 中等规模集群 |
| 20 | 4.29 秒 | NCCL 当前默认值(2.23+)------适合大多数生产集群 |
| 22 | 17.2 秒 | 大规模 / 长距离 / 多跳网络 |
| 24 | 68.7 秒 | 超大规模集群(>512 张卡) |
| 0 | 禁用 | 仅调试用 |
(计算依据:4.096 μs × 2^N)
接受的值
NCCL 使用的默认值为 20(从 2.23 起;从 2.14 起为 18,以前为 14)。
值可以为 1-31。
注意:设置值为 0 或 >= 32 将导致无限超时值。
测试Tips:大规模集群超时测试中,设置22+,模拟大网络场景,检查nccl-tests是否挂起。
NCCL_IB_RETRY_CNT
(从 2.1.15 起)
NCCL_IB_RETRY_CNT 变量控制 InfiniBand 重试计数。
更多信息,请参阅 InfiniBand 规范 Volume 1 的第 12.7.38 节。
接受的值
默认值为 7。
测试Tips:RDMA重试机制测试,设置10,观察错误恢复在nccl-tests中的效果。
NCCL_IB_ADDR_FAMILY
(从 2.21 起)
NCCL_IB_ADDR_FAMILY 变量定义与 InfiniBand GID 关联的 IP 地址族,当 NCCL_IB_GID_INDEX 未设置时由 NCCL 动态选择。
接受的值
默认值为 "AF_INET"。
测试Tips:IPv4/IPv6 IB测试,设置AF_INET6,结合NCCL_SOCKET_FAMILY。
NCCL_IB_ADDR_RANGE
(从 2.21 起)
NCCL_IB_ADDR_RANGE 变量定义有效 GID 的范围,当 NCCL_IB_GID_INDEX 未设置时由 NCCL 动态选择。
接受的值
如果未设置,默认忽略。
GID 范围可以使用 Classless Inter-Domain Routing (CIDR) 格式为 IPv4 和 IPv6 族定义。
测试Tips:GID范围过滤测试,用于安全受限网络。
NCCL_IB_FIFO_TC
定义控制消息的 InfiniBand 流量类。
控制消息是短 RDMA 写操作,用于控制信用返回,与传输大数据段的其他 RDMA 操作相反。此设置允许这些消息使用高优先级、低延迟流量类,避免被其余流量延迟。
接受的值
默认值为 NCCL_IB_TC 设置的流量类,如果未设置则默认为 0。
测试Tips:控制消息优化测试,设置高TC,观察低延迟AllReduce。
NCCL_IB_TC 和 NCCL_IB_FIFO_TC 的关系
1. 总结关系
- NCCL_IB_TC :管大数据包(AllReduce、AlltoAll 的真正 payload)
- NCCL_IB_FIFO_TC :管控制小消息(信用返回、ACK、流控信用)
- 它们的关系 = "大哥管干活,小弟管调度" 大哥(数据)可以稍微慢一点,小弟(控制)必须极致低延迟,否则整个通信就会卡住。
2. 详细对比表
| 项目 | NCCL_IB_TC | NCCL_IB_FIFO_TC(2.22.3 引入) |
|---|---|---|
| 管什么消息 | 普通数据 RDMA 操作(大消息) | 控制消息(短 RDMA Write,用于信用返回) |
| 消息大小 | 几 KB 到几 MB | 通常 < 64 字节 |
| 为什么单独设置 | 数据流量占 99% 带宽 | 防止控制消息被大数据"淹没"导致信用耗尽 |
| 默认值 | 0 | 和 NCCL_IB_TC 保持一致(文档明确说明) |
| 推荐生产值 | 106 | 106(和上面一样) |
| 在 RoCE v2 中的作用 | 映射到 IP TC / DSCP → 决定 PFC 优先级队列 | 更关键!控制消息必须走最高优先级队列 |
| 在纯 IB 中的作用 | 较弱(主要靠 SL) | 仍有效(GRH 中的 TC) |
3. 为什么要有 NCCL_IB_FIFO_TC?
控制消息是短 RDMA Write ,用来告诉对端"我还有缓冲区,可以继续发"。
如果控制消息和大数据走同一个 TC:
- 大数据把交换机队列塞满
- 控制消息排队等 → 信用返回延迟 → 对端以为"对方没缓冲" → 暂停发送 → 整体带宽暴跌
4. 在 RoCE 和纯 IB 下的实际差别
RoCE v2(最常见):
- 两个 TC 都会映射到同一个 IP 头部
- 但交换机 PFC 配置通常把 TC=106 映射到最高优先级队列
- 所以必须把两个变量设成一样的值 (推荐 106)
纯 InfiniBand: - TC 放在 GRH(跨子网时才出现)
- 影响较小,主要还是靠 NCCL_IB_SL 决定优先级
- 可以保持默认(0),或者和数据 TC 一致也行
NCCL_IB_RETURN_ASYNC_EVENTS
IB 事件作为警告报告给用户。
如果启用,NCCL 将在致命 IB 异步事件时停止 IB 通信。
接受的值
默认值为 1,设置为 0 以禁用。
测试Tips:异步事件诊断,启用捕获IB错误日志。
NCCL_OOB_NET_ENABLE(从 2.23 起)
变量 NCCL_OOB_NET_ENABLE 启用 NCCL net 用于带外通信带外通信 OOB(out-of-band communications)。
启用 NCCL net 的使用将改变通信器初始化期间执行的 allgather 实现。
接受的值
设置为 0 以禁用,设置为 1 以启用。
测试Tips:带外通信测试,启用验证初始化性能。
NCCL_OOB_NET_IFNAME(从 2.23 起)
如果 NCCL net 启用用于带外通信(见 NCCL_OOB_NET_ENABLE),NCCL_OOB_NET_IFNAME 变量指定要使用的网络接口。
接受的值
定义为过滤 NCCL 用于带外通信的接口列表。接受的接口列表取决于 NCCL 使用的网络。
列表用逗号分隔;端口号可以使用 : 符号指定。
可选前缀 ^ 表示列表是排除列表。
第二可选前缀 = 表示令牌是精确名称,否则默认情况下 NCCL 将每个令牌视为前缀。
如果指定多个设备,NCCL 将选择列表中第一个匹配设备。
示例:
NCCL_NET="IB" NCCL_OOB_NET_ENABLE=1 NCCL_OOB_NET_IFNAME="=mlx5_1" 将使用 InfiniBand NET,接口 mlx5_1
NCCL_NET="IB" NCCL_OOB_NET_ENABLE=1 NCCL_OOB_NET_IFNAME="mlx5_1" 将使用 InfiniBand NET,列表中第一个找到的接口 mlx5_1、mlx5_10、mlx5_11 等。
NCCL_NET="Socket" NCCL_OOB_NET_ENABLE=1 NCCL_OOB_NET_IFNAME="ens1" 将使用套接字 NET,列表中第一个找到的接口 ens1f0、ens1f1 等。
测试Tips:带外接口选择,类似NCCL_SOCKET_IFNAME,用于初始化阶段隔离测试。
NCCL_UID_STAGGER_THRESHOLD(从 2.23 起)
NCCL_UID_STAGGER_THRESHOLD 变量用于触发 NCCL 等级与 ncclUniqueId 之间的通信交错,以避免 ncclUniqueId 溢出。
如果通信的 NCCL 等级数超过指定阈值,则使用等级值进行交错(见下面的 NCCL_UID_STAGGER_RATE)。
如果每个 ncclUniqueId 的 NCCL 等级数小于或等于阈值,则不执行交错。
例如,如果有 128 个 NCCL 等级、1 个 ncclUniqueId 和阈值 64,则执行交错。
但是,如果使用 2 个 ncclUniqueId 和 128 个 NCCL 等级以及阈值 64,则不执行交错。
接受的值
NCCL_UID_STAGGER_THRESHOLD 的值必须是严格正整数。
如果未指定,默认值为 256。
测试Tips:大规模UID测试,降低阈值到128,模拟溢出场景。
ncclUniqueId 是 NCCL 中最核心的初始化标识符,简单来说:
它就是一个"通信组的身份证" ------ 用来告诉所有参与的 GPU 进程/线程:"我们属于同一个 NCCL 通信组(communicator)"。
1. 官方精确定义(来自 NCCL 2.29.1 文档)
typedef struct { char internal[128]; } ncclUniqueId;- 大小 :固定 128 字节(内部是一个 opaque 数组,不透明,你不能直接读写里面的内容)。
- 类型:不透明结构体(opaque struct),只能通过 NCCL API 操作。
2. 它到底是干什么用的?
NCCL 初始化 communicator 的标准流程(99% 的代码都是这么写的):
-
一个进程 (通常是 rank 0)生成它:
ncclUniqueId id; ncclGetUniqueId(&id); // ← 只调用一次! -
把这个 id 通过任意 CPU 方式广播给所有其他 rank(共享内存、文件、MPI、TCP、etcd 都行)。
-
所有 rank 用同一个 id 初始化 communicator:
ncclCommInitRank(&comm, nranks, id, myrank);一句话 :所有 rank 必须拿到完全相同的 ncclUniqueId,才能建立起同一个 communicator。
3. 在 NCCL_UID_STAGGER_THRESHOLD 里为什么提到它?
这就是变量的核心背景:
- 当所有 rank 都用同一个 ncclUniqueId 时(最常见的情况),初始化阶段的 allgather 操作 会让几百上千个 rank 同时去连同一个 uid。
- 这会导致内部连接队列 / 缓冲区瞬间溢出(文档里叫 "ncclUniqueId 溢出")。
NCCL 从 2.23 版本开始引入 stagger(交错)机制 来解决这个问题:
- NCCL_UID_STAGGER_THRESHOLD 默认 256
- 如果单个 ncclUniqueId 上挂的 rank 数 > 阈值(比如 128 个 rank 只用 1 个 uid),NCCL 就会按 rank 号错开时间去连接(stagger),避免同时冲上去。
- 如果你用了多个 ncclUniqueId(比如把 128 个 rank 分成 2 组,每组用一个 uid),就不需要 stagger 了。
官方例子(文档原文):
- 128 个 rank + 1 个 ncclUniqueId + 阈值 64 → 触发交错
- 128 个 rank + 2 个 ncclUniqueId + 阈值 64 → 不触发交错
4. 实战
-
大多数情况:只用 1 个 ncclUniqueId(最简单),让 NCCL 自动 stagger(默认就够)。
-
超大规模 (>1024 rank):建议手动拆成多个 uid(用 ncclCommInitRank + ncclCommSplit),性能更好。
-
查看当前是否触发 stagger:
NCCL_DEBUG=INFO NCCL_DEBUG_SUBSYS=INIT,BOOTSTRAP ...日志里会出现 "staggering UID connections" 字样。
NCCL_UID_STAGGER_RATE(从 2.23 起)
NCCL_UID_STAGGER_RATE 变量用于定义当交错 NCCL 等级与 ncclUniqueId 之间的通信时目标消息速率。
如果使用交错(见上面的 NCCL_UID_STAGGER_THRESHOLD),则使用消息速率计算给定 NCCL 等级的等待时间。
接受的值
NCCL_UID_STAGGER_RATE 的值必须是严格正整数,以消息/秒表示。
如果未指定,默认值为 7000。
测试Tips:交错速率调优,设置5000测试初始化延迟。
NCCL_NET(从 2.10 起)
NCCL_NET 是 NCCL 中用于强制指定网络传输模块的环境变量(从 NCCL 2.10 版本开始引入),它的主要作用是:
- 确保 NCCL 使用你想要的特定网络实现(尤其是外部插件),
- 防止 NCCL 自动回退到内置的 IB(InfiniBand)或 Socket(TCP/IP)实现。
在默认情况下,NCCL 会根据硬件和拓扑自动选择 最合适的网络模块(优先 IB → RoCE → Socket)。但很多场景下(比如使用第三方插件、AWS EFA、特定云厂商优化、调试强制用 Socket),你需要手动锁定网络类型,这时就靠 NCCL_NET。
可接受的值(Accepted Values)
值必须精确匹配 NCCL 网络模块的名称(不区分大小写 ,从 2.23+ 版本开始不区分大小写,早版需区分)。
常见值列表(内置 + 外部插件):
| 值示例 | 含义 | 典型使用场景 |
|---|---|---|
| IB | 强制使用内置 InfiniBand Verbs(包括 RoCE) | 想禁用插件、强制 IB/RoCE 时用 |
| Socket | 强制使用内置 TCP/IP Socket 传输 | 调试、禁用 IB、测试 fallback、网络无 RDMA 时 |
| AWS Libfabric | AWS EFA 的官方插件(aws-ofi-nccl) | AWS p4d/p5 实例,强制用 EFA 高性能网络 |
| AWS OFI 或类似 | 旧版 AWS Libfabric 插件名称 | 老 AWS 环境 |
| UCX | UCX 插件(某些集群用) | Cray/HPE 系统、Slingshot 网络 |
| gni 或 cxi | 特定厂商插件(如 Cray) | 高性能计算集群 |
| 自定义插件名称 | 外部 NCCL Net 插件自己定义的名称 | 自定义/第三方插件时必须匹配插件的 name 字段 |
默认:未定义(undefined),NCCL 自动选择。
3. 如何使用(实战示例)
示例 1:强制用内置 IB/RoCE(禁用任何插件)
export NCCL_NET=IB
# 常用于:验证插件是否导致问题、强制 RDMA示例 2:强制用 Socket(纯 TCP 回退)
export NCCL_NET=Socket
# 常用于:IB 链路故障时测试、模拟无 RDMA 环境、排查网络问题示例 3:AWS EFA 实例强制用官方插件(最常见云场景)
export NCCL_NET="AWS Libfabric"
# 或旧版写法:NCCL_NET="AWS OFI"
# 常用于:AWS p5.48xlarge 等 H100 实例,确保用 EFA 而非 Socket fallback示例 4:结合 OOB(带外)使用(初始化优化)
NCCL_NET="IB" \
NCCL_OOB_NET_ENABLE=1 \
NCCL_OOB_NET_IFNAME="ens1f0" # 用管理网做带外初始化示例 5:查看当前用了哪个网络(调试必备)
NCCL_DEBUG=INFO NCCL_DEBUG_SUBSYS=NET,INIT mpirun -np 8 ./all_reduce_perf ...日志开头会打印:
NCCL INFO NET/Plugin: Using AWS Libfabric或
NCCL INFO NET/Socket: Using interface ens1f04. 注意事项 & 常见坑(交付经验总结)
- 必须精确匹配插件的 name:插件加载后会报告自己的名字(NCCL_DEBUG=INFO 可见),必须用这个名字设置 NCCL_NET,否则加载失败。
- 和 NCCL_NET_PLUGIN 的区别 (很多人混淆):
- NCCL_NET:强制网络模块名称(如 "AWS Libfabric")
- NCCL_NET_PLUGIN:指定库文件后缀(如 "aws" → 加载 libnccl-net-aws.so)
- 先加载插件(用 NCCL_NET_PLUGIN),再用 NCCL_NET 选具体实现。
- 不设置时:NCCL 自动选(优先 IB → 插件 → Socket),生产环境最稳。
- 强制 Socket 调试:当 IB 报错时,先设 NCCL_NET=Socket 确认是否网络问题。
NCCL_IGNORE_CPU_AFFINITY(从 2.4.6 起)
NCCL_IGNORE_CPU_AFFINITY 变量可导致 NCCL 忽略作业提供的 CPU 亲和性,而是仅使用 GPU 亲和性。
接受的值
默认值为 0,设置为 1 以导致 NCCL 忽略作业提供的 CPU 亲和性。
测试Tips:亲和性测试,启用忽略CPU绑定,验证GPU-only优化。
NCCL_CONF_FILE(从 2.23 起)
NCCL_CONF_FILE 变量允许用户指定静态配置文件。
此路径不接受 ~ 字符;请先转换为相对或绝对路径。
接受的值
如果未设置或版本早于 2.23,则如果可用,使用主目录中的 .nccl.conf。
测试Tips:静态配置测试,设置自定义文件批量部署变量。
罕见变量
NCCL_IB_ROCE_VERSION_NUM(从 2.21 起)
NCCL_IB_ROCE_VERSION_NUM 变量定义 RoCE 版本,与 InfiniBand GID 关联,当 NCCL_IB_GID_INDEX 未设置时由 NCCL 动态选择。
接受的值
默认值为 2。
测试Tips:RoCE v1/v2切换测试,设置1验证兼容性。
NCCL_NET_PLUGIN(从 2.11 起)
设置为后缀字符串或库名称,以在多个 NCCL net 插件中选择。此设置将导致 NCCL 使用以下策略查找 net 插件库:
如果 NCCL_NET_PLUGIN 已设置,尝试加载 NCCL_NET_PLUGIN 指定的库名称;
如果 NCCL_NET_PLUGIN 已设置且之前失败,尝试加载 libnccl-net-<NCCL_NET_PLUGIN>.so;
如果 NCCL_NET_PLUGIN 未设置,尝试加载 libnccl-net.so;
如果未找到插件(既非用户定义也非默认),则使用内部网络插件。
例如,设置 NCCL_NET_PLUGIN=foo 将导致 NCCL 尝试加载 foo,如果 foo 未找到,则加载 libnccl-net-foo.so(前提是它存在于系统上)。
接受的值
插件后缀、插件文件名或 "none"。
测试Tips:插件加载测试,设置自定义插件诊断加载失败。
NCCL_TUNER_PLUGIN
设置为后缀字符串或库名称,以在多个 NCCL tuner 插件中选择。此设置将导致 NCCL 使用以下策略查找 tuner 插件库:
如果 NCCL_TUNER_PLUGIN 已设置,尝试加载 NCCL_TUNER_PLUGIN 指定的库名称;
如果 NCCL_TUNER_PLUGIN 已设置且之前失败,尝试加载 libnccl-tuner-<NCCL_TUNER_PLUGIN>.so;
如果 NCCL_TUNER_PLUGIN 未设置,尝试加载 libnccl-tuner.so;
如果未找到插件,则在 net 插件中查找 tuner 符号(参阅 NCCL_NET_PLUGIN);
如果未找到插件(既非通过 NCCL_TUNER_PLUGIN 也非 NCCL_NET_PLUGIN),则使用内部 tuner 插件。
例如,设置 NCCL_TUNER_PLUGIN=foo 将导致 NCCL 尝试加载 foo,如果 foo 未找到,则加载 libnccl-tuner-foo.so(前提是它存在于系统上)。
接受的值
插件后缀、插件文件名或 "none"。
测试Tips:算法调优插件测试,设置自定义tuner优化AllReduce。
NCCL_PROFILER_PLUGIN
设置为后缀字符串或库名称,以在多个 NCCL profiler 插件中选择。此设置将导致 NCCL 使用以下策略查找 profiler 插件库:
如果 NCCL_PROFILER_PLUGIN 已设置,尝试加载 NCCL_PROFILER_PLUGIN 指定的库名称;
如果 NCCL_PROFILER_PLUGIN 已设置且之前失败,尝试加载 libnccl-profiler-<NCCL_PROFILER_PLUGIN>.so;
如果 NCCL_PROFILER_PLUGIN 未设置,尝试加载 libnccl-profiler.so;
如果未找到插件(既非用户定义也非默认),则不启用分析。
如果 NCCL_PROFILER_PLUGIN 设置为 STATIC_PLUGIN,则在程序二进制文件中搜索插件符号。
例如,设置 NCCL_PROFILER_PLUGIN=foo 将导致 NCCL 尝试加载 foo,如果 foo 未找到,则加载 libnccl-profiler-foo.so(前提是它存在于系统上)。
接受的值
插件后缀、插件文件名或 "none"。
测试Tips:性能分析插件,设置启用详细profiling。
NCCL_ENV_PLUGIN(从 2.28 起)
NCCL_ENV_PLUGIN 变量可用于让 NCCL 加载外部环境插件。设置为库名称或后缀字符串,以在多个 NCCL 环境插件中选择。此设置将导致 NCCL 使用以下策略查找环境插件库:
如果 NCCL_ENV_PLUGIN 设置为库名称,尝试加载该库(例如 NCCL_ENV_PLUGIN=/path/to/library/libfoo.so 将导致 NCCL 尝试加载 /path/to/library/libfoo.so);
如果 NCCL_ENV_PLUGIN 设置为后缀字符串,尝试加载 libnccl-env-<NCCL_ENV_PLUGIN>.so(例如 NCCL_ENV_PLUGIN=foo 将导致 NCCL 从系统库路径加载 libnccl-env-foo.so);
如果 NCCL_ENV_PLUGIN 未设置,尝试从系统库路径加载默认 libnccl-env.so 库;
如果 NCCL_ENV_PLUGIN 设置为 "none",显式禁用外部插件并使用内部插件;
如果未找到插件(既非用户定义也非默认)或变量设置为 "none",则使用内部环境插件。
接受的值
插件库名称(例如 /path/to/library/libfoo.so)、后缀(例如 foo)或 "none"。
测试Tips:环境插件自定义测试,用于扩展配置。
NCCL_SET_THREAD_NAME(从 2.12 起)
为 NCCL CPU 线程赋予更有意义的名称,以调试和分析。
接受的值
0 或 1。默认值为 0(禁用)。
测试Tips:线程命名,启用便于gdb调试。
环境变量(调试)
这些环境变量应谨慎使用。新版本 NCCL 可能不同工作,强制它们为特定值将阻止 NCCL 自动选择最佳设置。因此,它们可能导致长期性能问题,甚至破坏某些功能。
它们适合用于实验或调试问题,但通常不应在生产代码中设置。
常用变量(很实用)
NCCL_P2P_DISABLE
NCCL_P2P_DISABLE 变量禁用点对点 (P2P) 传输,使用 NVLink 或 PCI 的 GPU 之间 CUDA 直接访问。
P2P详解
1. P2P 是什么?
在 NCCL 里,P2P = GPU 直接访问另一个 GPU 的显存。
- 技术实现:CUDA Peer-to-Peer + NVLink / PCIe P2P(使用 cudaDeviceEnablePeerAccess)
- 优势 :零拷贝、最低延迟、最高带宽(节点内最优路径)
- 适用场景:同一进程内多 GPU 通信(节点内 AllReduce、AlltoAll 等)
- 拓扑要求:GPU 必须在同一 NUMA 节点或通过 NVLink/PCIe Switch 直连
NCCL 默认行为:
- 检测到 P2P 可行 → 优先使用 P2P(最快)
- 检测不到 → 回退到 SHM(共享内存)或网络代理
2. 设置 NCCL_P2P_DISABLE=1 后,内部原理变化
当你设置 export NCCL_P2P_DISABLE=1 时,NCCL 在拓扑构建阶段 (Graph 构建)会直接把所有 P2P 路径标记为不可用 。
内部流程变化如下:
- 拓扑检测阶段 (GRAPH 子系统):
- 正常:发现 P2P 路径 → 标记为 "P2P" 类型
- 禁用后:所有 P2P 路径被强制删除,改为 "Proxy" 或 "SHM" 类型
- 通信通道建立阶段 :
- 节点内 GPU 通信不再走 CUDA P2P 直接读写
- 改为两种回退路径:
- 首选:Shared Memory (SHM) + Proxy 线程(数据先拷贝到主机内存,再通过 Proxy 线程转发)
- 次选:如果 SHM 也被禁用,则走完整网络路径(IB / Socket)
- 内核执行阶段 :
- 正常 P2P:通信内核直接访问对端 GPU 显存(一个内核完成)
- 禁用后:需要额外 Proxy 内核 + 内存拷贝,多了一层数据搬运
本质:把"GPU 直连"变成了"GPU → 主机内存 → GPU"的间接路径。
3. 在 nccl-tests 中的实际影响(对比表格)
| 项目 | P2P 开启(默认) | NCCL_P2P_DISABLE=1(禁用后) |
|---|---|---|
| 节点内带宽 | 最高(NVLink 可达 600GB/s+) | 明显下降(SHM 限制在 ~200-300GB/s) |
| 延迟 | 最低 | 增加 2~5 倍 |
| GPU SM 占用 | 较低(直接访问) | 更高(Proxy 线程占用 SM) |
| 调试价值 | --- | 极高:快速验证"是否 P2P 导致的问题" |
| 典型测试场景 | 正常性能测试 | 隔离 P2P 故障、对比 SHM vs P2P 性能 |
4. 内部原理更深层细节(NCCL 源码层面)
- NCCL 在 ncclTopoGetPaths 中构建路径图时,会调用 ncclP2PIsSupported 检查 P2P 可行性。
- 设置 NCCL_P2P_DISABLE=1 后,ncclP2PIsSupported 直接返回 false。
- 后续 ncclCommBuild 会把所有 intra-node 连接类型改为 NCCL_CONN_TYPE_PROXY 或 NCCL_CONN_TYPE_SHM。
- Proxy 线程(CPU 辅助线程)会负责把数据从一个 GPU 拷贝到主机,再从主机拷贝到另一个 GPU。
注意 :这不是禁用 CUDA P2P 功能,只是 NCCL 不再使用它。其他 CUDA 程序仍可正常 P2P。
5. 什么时候必须用这个变量?(交付经验)
- 怀疑 P2P 路径有问题(NVLink 断链、驱动 bug、PCIe 宽度不足)
- 想对比 P2P vs SHM 性能差异
- 调试 节点内带宽达不到预期 时,先禁用 P2P 看是否恢复
- 配合 NCCL_SHM_DISABLE=1 使用 → 强制所有通信走网络(最慢路径,用于极端隔离)
- 测试 Proxy 线程性能(多线程套接字相关)
P2P使用方式
1. P2P 的最底层依赖:NUMA 节点(PCIe 域)
- 最基础的 P2P :基于 PCIe P2P(Peer-to-Peer over PCIe)
- 硬件要求 :两个 GPU 必须在同一个 NUMA 节点 (同一个 CPU socket)内,或者通过 PCIe Switch 连接,且驱动支持 cudaDeviceEnablePeerAccess
- NUMA 节点的角色 :
- 如果两个 GPU 在不同 NUMA 节点 (跨 CPU socket),即使有 PCIe 链路,P2P 通常无法直接启用(因为跨 NUMA 的 PCIe 访问会走 QPI/UPI 互连,带宽低、延迟高,CUDA 默认禁用这种跨 NUMA P2P)
- 所以在纯 PCIe 系统 (无 NVLink 的服务器,如很多 A100 PCIe 版或消费级多卡机),P2P 只在同一个 NUMA 节点内有效。
- 典型性能(PCIe Gen5 双向):~64--128 GB/s(视 PCIe 宽度)
结论 :在没有 NVLink 的情况下,P2P 高度依赖 NUMA 节点边界。
2. NVLink + NVSwitch 下的 P2P(高端实现,当前主流)
- NVLink P2P:NVIDIA 的专有高速互连(NVLink 3.0 / 4.0 / 5.0)
- NVSwitch 的角色 :
- NVSwitch 是一个全连接交换芯片 ,把节点内所有 GPU 通过 NVLink 连成一个扁平域(flat domain)
- 在 NVSwitch 系统(DGX H100、HGX H200、GB200 NVL72 等)中:
- 所有 GPU 之间都是全互联 (all-to-all),不再受 NUMA 节点限制
- 即使 GPU 物理上挂在不同 CPU socket、不同 PCIe 根复杂(root complex),只要通过 NVSwitch 相连,P2P 就能直接工作,且带宽极高
- 带宽对比 :
- NVLink 4.0(H100 SXM):单链路 100 GB/s 双向,8-GPU 全互联聚合后可达 ~900 GB/s(实际 NCCL 节点内 AllReduce 常测到 500--700 GB/s)
- NVSwitch 让 P2P 跨越 NUMA 边界,变成真正的节点内全域高速 P2P
结论 :在现代高端系统(有 NVSwitch)中,P2P 主要依赖 NVLink + NVSwitch ,而不再严格依赖 NUMA 节点。
3. 总结对比表(不同硬件下的 P2P 依赖)
| 硬件类型 | P2P 是否可用 | 主要依赖什么 | 是否受 NUMA 节点限制 | 典型节点内带宽(8 GPU AllReduce) | 代表系统 |
|---|---|---|---|---|---|
| 纯 PCIe(无 NVLink) | 是(但有限) | PCIe Switch + 同 NUMA | 是(严格) | ~100--200 GB/s | A100 PCIe、RTX 4090 多卡 |
| NVLink 桥接(无 NVSwitch) | 是 | NVLink 桥 + 同 NUMA 或桥接 | 部分限制 | ~300--500 GB/s | DGX A100(老版) |
| NVLink + NVSwitch | 是(最强) | NVLink + NVSwitch | 几乎不受限制 | 500--900 GB/s | DGX H100、HGX H200、GB200 |
P2P & NVLS
P2P 和 NVLS 的区别(NCCL 内部通信路径层面,详细对比)
在 NCCL(尤其是 AllReduce 等集体操作)中,P2P 和 NVLS 都是节点内(intra-node) GPU 间高效通信的技术,但它们本质完全不同:
- P2P (Peer-to-Peer)是点对点直接内存访问 ,属于传统 GPU-GPU 直连方式。
- NVLS (NVLink SHARP)是网络内计算(in-network computing) 的升级版,把归约计算卸载到 NVSwitch 上做。
下面用表格 + 逐项详细对比,让你彻底搞清楚两者的区别、适用场景、性能差异和内部原理。
核心对比表格
| 维度 | P2P (Peer-to-Peer) | NVLS (NVLink SHARP) |
|---|---|---|
| 全称 / 技术本质 | GPU 直接通过 NVLink / PCIe 访问对端显存 | NVLink + SHARP:在 NVSwitch 上做 in-network 归约 |
| 引入版本 | NCCL 早期就支持(NCCLP2P* 系列从 2.3.4 精细化) | 从 NCCL 2.17 开始(NCCL_NVLS_ENABLE) |
| 硬件依赖 | NVLink(最佳)或 PCIe P2P(较慢) | 第三代+ NVSwitch(NVLink4,Hopper/Blackwell 架构) |
| 支持的集体操作 | 所有(AllReduce、AlltoAll、Broadcast 等) | 主要 AllReduce(ReduceScatter / AllGather 部分支持) |
| 计算位置 | GPU SM 上做归约(每个 GPU 都要计算) | NVSwitch 上做归约(GPU 只发数据,不计算) |
| 节点内带宽 | 极高(H100 NVLink4 可达 ~900 GB/s 双向) | 更高(NVSwitch 聚合后可超单链路极限) |
| 延迟 | 低(直接访问) | 更低(减少 GPU 计算 + 交换机加速) |
| 跨节点结合 | 可与 IB/RoCE 结合(节点内 P2P + 节点间 RDMA) | 可与 CollNet / IB SHARP 结合(节点内 NVLS + 节点间 SHARP) |
| 资源占用(SM) | 中等(需要 SM 跑通信内核) | 更低(GPU SM 只负责发/收,计算在 NVSwitch) |
| 控制变量 | NCCL_P2P_DISABLE=1(禁用) NCCL_P2P_LEVEL(精细控制) | NCCL_NVLS_ENABLE=1(启用,默认 1) |
| 典型系统 | 所有多 GPU 系统(DGX、HGX、单机 8 卡) | GB200 NVL72、DGX H100/H200 + NVSwitch 系统 |
| 禁用后影响 | 节点内通信 fallback 到 SHM / Proxy(带宽下降 30-70%) | fallback 到 Ring/Tree/P2P(性能下降,但仍可用) |
内部原理对比(更深层拆解)
- P2P 的工作流程 (传统方式)
- GPU A 想发数据给 GPU B → 通过 NVLink/PCIe 直接写进 B 的显存(cudaMemcpyPeer 或内核内直接 load/store)。
- AllReduce 时:
- 每个 GPU 都要把自己的数据分块发给邻居。
- 邻居收到后在自己的 SM 上做 reduce(sum/max)。
- 再把结果发给下一个。
- 瓶颈:归约计算全在 GPU SM 上,占用 SM 资源,计算与通信竞争。
- NVLS 的工作流程 (in-network computing)
- GPU 只负责把部分数据发到 NVSwitch。
- NVSwitch 本身做 reduce(硬件加速 sum/max 等操作)。
- 结果直接从 NVSwitch 广播/发回给目标 GPU。
- 关键 :GPU SM 几乎不参与计算,只做发/收 → SM 空闲率更高,计算重叠更好。
- 支持的拓扑:NVL72(72 GPU 单域)或更小 NVSwitch 域。
NCCL_P2P_LEVEL(从 2.3.4 起)
NCCL_P2P_LEVEL 变量允许用户精细控制何时使用 GPU 之间点对点 (P2P) 传输。
级别定义 GPU 之间最大距离,在此距离内 NCCL 将使用 P2P 传输。使用表示路径类型的短字符串指定使用 P2P 传输的拓扑截止点。
如果未指定,NCCL 将尝试基于架构和运行环境优化选择值。
#接受的值
LOC :从不使用 P2P(始终禁用)
NVL :当 GPU 通过 NVLink 连接时使用 P2P
PIX :当 GPU 在同一 PCI 交换机上时使用 P2P。
PXB :当 GPU 通过 PCI 交换机连接(可能多跳)时使用 P2P。
PHB :当 GPU 在同一 NUMA 节点上时使用 P2P。流量将通过 CPU。
SYS :在 NUMA 节点之间使用 P2P,可能跨越 SMP 互连(例如 QPI/UPI)。
整数值(遗留)
也可以将 NCCL_P2P_LEVEL 声明为对应路径类型的整数。这些数字值保留用于 retro-兼容性,对于在字符串允许前使用数字值的用户。
由于路径类型变更,整数值不鼓励使用 - 字面值可能随时间变化。为了避免调试配置头疼,使用字符串标识符。
LOC :0
PIX :1
PXB :2
PHB :3
SYS :4
大于 4 的值将被解释为 SYS。遗留整数值不支持 NVL。
测试Tips:P2P距离测试,设置PIX限制到PCI交换机,检查拓扑性能。
NCCL_P2P_DIRECT_DISABLE
NCCL_P2P_DIRECT_DISABLE 变量禁止 NCCL 通过 P2P 在同一进程的 GPU 之间直接访问用户缓冲区。这在用户缓冲区使用不自动访问,使它们可由同一进程管理的其他 GPU P2P 访问的 API 分配时有用。
#接受的值
定义并设置为 1 以禁用跨 GPU 的直接用户缓冲区访问。
测试Tips:缓冲区访问测试,启用避免隐式同步挂起。
NCCL_SHM_DISABLE
来强制禁用节点内 GPU 之间的共享内存(Shared Memory,简称 SHM)传输路径 。
下面给你从概念、原理、默认行为、实际影响、测试场景到推荐用法,完整详细地讲一遍。
1. 基本概念与作用
- 变量全称:NCCL_SHM_DISABLE(Shared Memory Disable)
- 默认值:0(启用 SHM)
- 接受值:0 = 允许使用 SHM 1 = 完全禁用 SHM
- 核心作用 : 当节点内 GPU 之间无法使用 P2P (或 P2P 被手动禁用)时,NCCL 会尝试使用共享内存 + Proxy 线程 作为回退路径。 设置 NCCL_SHM_DISABLE=1 后,这个回退路径也被彻底封死 ,节点内所有通信都会被迫走完整网络路径(RoCE / IB / Socket)。
一句话: NCCL_SHM_DISABLE=1 就是把节点内"最后一根救命稻草"也拔掉,强制所有节点内通信都走外网。
2. SHM 路径的内部工作原理(重点)
当 NCCL 需要节点内 GPU 间通信时,路径选择优先级如下(从高到低):
- P2P(GPU 直接访问对端显存) → 最快、最优 (依赖 NVLink / PCIe P2P)
- SHM + Proxy (共享内存 + CPU 代理线程) → 次优
- 流程:
- 发送 GPU 把数据拷贝到主机内存(cudaMemcpy 到 pinned memory)
- CPU Proxy 线程读取主机内存,再通过 cudaMemcpy 把数据拷贝到接收 GPU
- 带宽:通常 100--300 GB/s(视主机内存带宽、CPU 拷贝效率)
- 延迟:比 P2P 高 2--5 倍(多了一次 CPU 介入)
- 流程:
- 网络路径 (RoCE / IB / Socket) → 最慢
- 数据从 GPU → 主机 → NIC → 网络 → 对端 NIC → 主机 → 对端 GPU
NCCL_SHM_DISABLE=1 的效果:
- 把第 2 步直接砍掉
- 节点内通信直接跳到第 3 步(走网络)
3. 在实际测试中的表现对比(8卡节点内 AllReduce 为例)
| 配置 | 节点内通信路径 | 典型带宽(H100 SXM 8卡) | 延迟影响 | SM 占用 | 典型场景 / 用途 |
|---|---|---|---|---|---|
| 默认(P2P + SHM 都启用) | 优先 P2P | 500--900 GB/s | 最低 | 中等 | 正常性能测试 |
| NCCL_P2P_DISABLE=1 | 走 SHM + Proxy | 150--300 GB/s | 增加 2--5 倍 | 较高 | 隔离 P2P 问题、对比 SHM 性能 |
| NCCL_SHM_DISABLE=1 | 强制走网络(RoCE) | 受限于 RoCE 单节点带宽(~100--200 GB/s) | 极高(网络往返) | 较低 | 极端调试、验证网络路径是否正常 |
| NCCL_P2P_DISABLE=1 + SHM_DISABLE=1 | 强制走网络 | 同上 | 极高 | 最低 | 完全隔离节点内路径,只看跨节点性能 |
RoCE 64 节点背景下:
- 如果节点内有 NVLink + NVSwitch,P2P 带宽很高,SHM 几乎不会被触发。
- 但一旦 P2P 被禁用或链路有问题,SHM 就成了"救命稻草"。
- 设 NCCL_SHM_DISABLE=1 会让节点内 AllReduce 变成"本地 GPU 发 RoCE 包到自己再收回来",带宽暴跌,延迟爆炸。
4. 什么时候用 NCCL_SHM_DISABLE=1?
- 彻底隔离节点内路径,只看跨节点 RoCE 性能 → 排除一切节点内加速(P2P + SHM),让 AllReduce 完全依赖网络。
- 怀疑 SHM 路径有 bug
- 比如共享内存拷贝卡死、Proxy 线程崩溃、内存注册失败等。
- 设 1 后如果问题消失 → 说明 SHM 出问题。
- 极端稳定性测试
- 模拟"节点内所有高速路径都失效"的场景,看 NCCL 是否能优雅 fallback 到网络。
- 配合其他变量做路径对比(经典三连杀):
5. 注意事项与风险
- 性能代价极大:节点内带宽可能下降 70%+,延迟增加数倍。
- 不适合生产:只用于调试/基准对比,生产环境千万别开。
- 和 NCCL_P2P_DISABLE 的区别 :
- P2P_DISABLE:只禁用最优路径(P2P),还有 SHM 兜底。
- SHM_DISABLE:把兜底也拔掉,彻底走网络。
- 日志体现 (设 NCCL_DEBUG=INFO):
- 启用 SHM:日志会出现 NCCL INFO Channel ... via SHM
- 禁用后:强制 via NET/IB 或 via NET/RoCE,即使是节点内。
NCCL_BUFFSIZE
NCCL_BUFFSIZE 变量控制 NCCL 在 GPU 对之间通信数据时使用的缓冲区大小。
当使用 NCCL 时遇到内存约束问题,或认为不同缓冲区大小会改善性能时,使用此变量。
#接受的值
默认值为 4194304 (4 MiB)。
值为整数,以字节为单位。推荐使用 2 的幂。例如,1024 将给出 1KiB 缓冲区。
测试Tips:缓冲大小调优,设置8MB测试大消息性能。
1. NCCL_BUFFSIZE 的核心作用回顾
- 控制 NCCL 内部缓冲区大小(per-channel FIFO buffer)
- 主要影响:
- 大消息(>几百 MB)的流水线效率(pipeline depth)
- 协议切换点(LL → LL128 → Simple 的阈值受其影响)
- 内存占用 vs 性能 的权衡(每个 channel 都会分配这个大小的缓冲,rank 数多时显存压力大)
- 默认值:4194304(4 MiB),从 Hopper 时代沿用至今
2. Blackwell / GB200 上的调优经验
根据 NVIDIA 官方 GB200 MNNVL 调优指南、社区基准(MLPerf、HPC-AI 报告)、以及大量 DGX GB200 / HGX B200 用户反馈,最常见的经验总结如下:
| 系统类型 | 推荐 NCCL_BUFFSIZE 值 | 为什么这个值更好?(相比默认 4 MiB) | 典型收益(AllReduce 节点内/跨节点) | 注意事项 / 风险 |
|---|---|---|---|---|
| 单节点 DGX/HGX B200 | 16 MiB -- 32 MiB (16777216 -- 33554432) | NVLink 5.0 + NVSwitch 聚合带宽极高,流水线深度需要更大缓冲才能饱和链路;减少协议切换抖动 | 节点内 +10% ~ +30% | 显存占用增加(8 GPU × 32 MiB × channel 数) |
| GB200 NVL36 / NVL72 | 32 MiB -- 64 MiB (33554432 -- 67108864) | 超大规模 NVLink 域(72 GPU 单域),大消息 AllReduce 需要更深流水线;NVLS 路径对大缓冲更敏感 | 节点内 +20% ~ +50%,跨 tray +15% | 显存压力极大,建议监控 nvidia-smi |
| 多节点 HGX B200 + RoCE | 8 MiB -- 16 MiB (8388608 -- 16777216) | 跨节点瓶颈在 RoCE(800 Gb/s NIC),过大缓冲反而增加延迟;8--16 MiB 是平衡点 | 跨节点 +5% ~ +15% | 太大可能导致 RoCE 拥塞,建议结合 NCCL_PROTO |
| 纯 Hopper H200 对比 | 默认 4 MiB 或 8 MiB | Hopper NVLink 4.0 带宽较低,4 MiB 已接近饱和 | --- | Blackwell 普遍需要更大值 |
最常见生产推荐值(2026 年主流):
- B200 单节点 / 小规模 :16 MiB(16777216)------ 性价比最高,显存开销可控
- GB200 NVL72 / 大规模 NVLink 域 :32 MiB (33554432)或 64 MiB(67108864)------ 最大化 NVLink 饱和度
- 混合 RoCE 集群 :8 MiB(8388608)------ 避免跨节点延迟恶化
3. 为什么 Blackwell 需要更大 BUFFSIZE?
- NVLink 5.0 + NVSwitch 带宽爆炸 单 GPU 1.8 TB/s 双向,NVL72 整体 130 TB/s 规模。默认 4 MiB 缓冲导致流水线深度不足,无法充分利用链路。
- NVLS / NVLSTree 路径更依赖大缓冲 in-network reduce 需要更多数据在 flight(飞行中),小缓冲会频繁 stall。
- 更大 HBM3e 带宽和容量 B200 8 TB/s 内存带宽 + 192 GB 显存,对缓冲区大小的容忍度更高,显存压力相对可控。
- NCCL 内部算法演进 从 2.20+ 开始,NCCL 对大缓冲的调度更友好,尤其在 NVLink 域内。
NCCL_IB_DISABLE
NCCL_IB_DISABLE 告诉 NCCL:"别用 InfiniBand / RoCE 了,全部改用普通的 TCP/IP 网络(Socket)来通信"
- 默认情况下(=0 或不设置),NCCL 会优先使用 InfiniBand Verbs (简称 IB)或 RoCE(RDMA over Converged Ethernet)来进行高速 GPU 间通信。
- 一旦你设置 NCCL_IB_DISABLE=1,NCCL 就会完全放弃 IB/RoCE ,强制回退到最慢、最基础的 IP 套接字(TCP/IP Socket) 方式。
接受的值
定义并设置为 1 以禁用 InfiniBand Verbs 用于通信(并强制另一种方法,例如 IP 套接字)。
测试Tips:IB fallback测试,启用验证Socket性能。
NCCL_IB_AR_THRESHOLD(从 2.6 起)
阈值,超过该阈值我们将 InfiniBand 数据发送到单独消息中,可以利用自适应路由。
接受的值
大小以字节为单位,默认值为 8192。
设置为高于 NCCL_BUFFSIZE 将完全禁用自适应路由的使用。
测试Tips:AR阈值调优,设置16384测试路由优化。
NCHANNELS & QPS
1. NCHANNELS
功能与内部原理
- Channel(通道) 是 NCCL 最基本的并行传输单元。
- 每个 Channel 对应一个独立的 CUDA 线程块(CTA) + 一组独立的发送/接收缓冲区。
- NCCL 会把一个大 AllReduce 操作切分成多个 Channel 并行传输(类似多车道高速路)。
- NCCL_MAX_NCHANNELS:限制最多能开多少个 Channel(上限)
- NCCL_MIN_NCHANNELS :强制至少开多少个 Channel(下限)
默认值(不同架构不同): - Hopper(H100/H200):默认 16~32
- Blackwell(B200/GB200):默认 32(更高)
NCHANNELS 越大: - 流水线深度越深 → 大消息带宽越高
- 并行度越高 → 能更好地利用 NVLink 5.0 / NVSwitch 的超高带宽
2. NCCL_IB_QPS_PER_CONNECTION 中的 QP(Queue Pair)
什么是 QP?
QP(Queue Pair)是 InfiniBand / RoCE 的基本通信单元,相当于"一条独立的 RDMA 连接"。
- 每个 QP 包含:
- 一个 Send Queue(发送队列)
- 一个 Receive Queue(接收队列)
- NCCL 在每个节点间建立连接时,默认只创建一个 QP。
- NCCL_IB_QPS_PER_CONNECTION 就是控制每个节点间连接(connection)创建几个 QP。
功能:
- 增加 QP 数量 = 让同一个逻辑连接产生多条物理队列。
- 每条 QP 可以走不同的物理路径 (不同网卡、不同交换机链路),极大提高路由熵(routing entropy)。
- 尤其在多轨 RoCE (每个节点多张网卡 + 多交换机)环境中,能避免单条路径拥塞。
默认值:1(单 QP)
3. 两个变量的详细对比
| 维度 | NCHANNELS(MAX/MIN) | NCCL_IB_QPS_PER_CONNECTION(QP) |
|---|---|---|
| 作用层面 | GPU 侧(CUDA 内核、CTA) | 网络侧(InfiniBand/RoCE 队列) |
| 控制什么 | CUDA 线程块数量 + 缓冲区并行度 | 每个连接创建的 QP(队列对)数量 |
| 主要影响 | 节点内 + 跨节点通用(所有协议) | 仅 IB/RoCE(Socket 无效) |
| 带宽提升方式 | 增加流水线深度、并行发送 | 增加路由多样性、避免单路径热点 |
| 默认值(Blackwell) | MAX ≈ 32 | 1 |
| 推荐值(64 节点 RoCE) | MAX=32~64 | 4~8 |
| 显存/资源开销 | 高(每个 Channel 都要分配缓冲区) | 中等(每个 QP 占用少量内存 + QP 上下文) |
| 适用消息大小 | 大消息收益更明显 | 所有消息都受益(尤其多轨网络) |
| 日志体现 | "Channel 00/01/02..." | "QP 0, QP 1, QP 2..."(DEBUG=INFO 时可见) |
**核心区别
- NCHANNELS 是"我要开多少条 GPU 并行车道"(GPU 侧并行)
- QP 是"我要每条车道上开多少辆车走不同路"(网络侧多路径)
4. 经验注意事项(血泪总结)
- NCHANNELS 上限不要超过 64 (Blackwell 实际极限)
- 再高会占用过多 SM 和寄存器,反而导致性能下降。
- 建议先从 32 开始,逐步测试到 64,看 bus bandwidth 是否继续上升。
- QP 数量与 NCCL_IB_SPLIT_DATA_ON_QPS 必须配合
- 默认 NCCL_IB_SPLIT_DATA_ON_QPS=0(轮询模式)
- 如果 QP 设为 4~8,建议同时设 NCCL_IB_SPLIT_DATA_ON_QPS=1(分割模式),否则可能出现延迟抖动。
- 显存占用风险
- NCHANNELS 每增加 1 个,显存增加 ≈ BUFFSIZE × rank数 × 2
- QP 每增加 1 个,显存增加 ≈ 几百 KB ~ 1 MB(较小)
- 多轨 RoCE 环境必须调 QP
- 如果你的集群是多轨(每节点 4 张以上 NIC),QP=1 会导致严重单路径热点,带宽浪费 30%+。
- QP=4~8 是当前 Blackwell RoCE 集群的黄金值。
NCCL_MAX_NCHANNELS
(从 2.0.5 起 NCCL_MAX_NRINGS,从 2.5.0 起 NCCL_MAX_NCHANNELS)
NCCL_MAX_NCHANNELS 变量限制 NCCL 可以使用的通道数。减少通道数也会减少用于通信的 CUDA 块数,因此减少对 GPU 计算资源的影响。
较旧的 NCCL_MAX_NRINGS 变量(直到 2.4 使用)在新版本中仍作为别名工作,但如果设置 NCCL_MAX_NCHANNELS 则忽略。
此环境变量已被 NCCL_MAX_CTAS 取代,后者也可以使用 编程设置。
接受的值
任何大于或等于 1 的值。
测试Tips:通道上限测试,设置8减少资源使用。
NCCL_MIN_NCHANNELS
(从 2.2.0 起 NCCL_MIN_NRINGS,从 2.5.0 起 NCCL_MIN_NCHANNELS)
NCCL_MIN_NCHANNELS 变量控制您希望 NCCL 使用的最小通道数。
增加通道数也会增加 NCCL 使用的 CUDA 块数,这可能有助于改善性能;但是,它使用更多 CUDA 计算资源。
这在 NCCL 通常只创建一个通道的平台上使用聚合集体时特别有用。
较旧的 NCCL_MIN_NRINGS 变量(直到 2.4 使用)在新版本中仍作为别名工作,但如果设置 NCCL_MIN_NCHANNELS 则忽略。
此环境变量已被 NCCL_MIN_CTAS 取代,后者也可以使用 编程设置。
接受的值
默认值为平台依赖。设置为整数值,最高 12(最高 2.2)、16(2.3 和 2.4)或 32(2.5 及以后)。
测试Tips:最小通道测试,设置16增加并行度。
NCCL_IB_QPS_PER_CONNECTION(从 2.10 起)
每个连接之间两个等级使用的 IB 队列对数。这在需要多个队列对以具有良好路由熵的多级结构上有用。
请参阅 NCCL_IB_SPLIT_DATA_ON_QPS 以了解在多个 QP 上分割数据的不同方式,因为它会影响性能
接受的值
1 到 128 之间的数,默认值为 1。
测试Tips:QP数测试,设置4增加熵。
NCCL_IB_SPLIT_DATA_ON_QPS(从 2.18 起)
此参数控制当我们创建多个队列对时如何使用它们。
设置为 1(分割模式),每个消息将均匀分割到每个队列对。这可能导致可见延迟退化如果使用许多 QP。
设置为 0(轮询模式),队列对将为我们发送的每个消息使用轮询模式。不发送多个消息的操作将不使用所有 QP。
接受的值
0 或 1。默认值为 0(从 NCCL 2.20 起)。设置为 1 将启用分割模式(2.18 和 2.19 中的默认)。
测试Tips:数据分割模式测试,设置1观察延迟。
NCCL_NET_GDR_LEVEL (formerly NCCL_IB_GDR_LEVEL)
(从 2.3.4 起。在 2.4.0 中,NCCL_IB_GDR_LEVEL 重命名为 NCCL_NET_GDR_LEVEL)
NCCL_NET_GDR_LEVEL 变量允许用户精细控制何时在 NIC 和 GPU 之间使用 GPU Direct RDMA。
级别定义 NIC 和 GPU 之间的最大距离。使用表示路径类型的字符串指定 GpuDirect 的拓扑截止点。
如果未指定,NCCL 将尝试基于架构和运行环境优化选择值。
接受的值
LOC :从不使用 GPU Direct RDMA(始终禁用)。
PIX :当 GPU 和 NIC 在同一 PCI 交换机上时使用 GPU Direct RDMA。
PXB :当 GPU 和 NIC 通过 PCI 交换机连接(可能多跳)时使用 GPU Direct RDMA。
PHB :当 GPU 和 NIC 在同一 NUMA 节点上时使用 GPU Direct RDMA。流量将通过 CPU。
SYS :甚至跨越 NUMA 节点之间的 SMP 互连(例如 QPI/UPI)使用 GPU Direct RDMA(始终启用)。
整数值(遗留)
也可以将 NCCL_NET_GDR_LEVEL 声明为对应路径类型的整数。这些数字值保留用于 retro-兼容性,对于在字符串允许前使用数字值的用户。
由于路径类型变更,整数值不鼓励使用 - 字面值可能随时间变化。为了避免调试配置头疼,使用字符串标识符。
LOC :0
PIX :1
PXB :2
PHB :3
SYS :4
大于 4 的值将被解释为 SYS。
测试Tips:GDR距离测试,设置PHB限制到NUMA。
NCCL_NET_GDR_C2C(2.27+ 默认 1)
作用 允许 GPU 通过 C2C(CPU ↔ CPU 互连) + PCIe 直接 RDMA 到对端 NIC(即距离 PHB 的 NIC),绕过本地 NIC。
典型拓扑
-
每个 CPU socket 挂几张 NIC,但 GPU 是跨 socket 分布的
-
GPU 离自己直连 NIC 较远,但可以通过 C2C + PCIe 访问另一个 CPU 上的 NIC
开启后效果 -
原本只能用本地 NIC 的 GPU,现在可以"借用"对端 CPU 的 NIC
-
聚合带宽提升,减少单 NIC 热点
推荐配置 -
有 C2C + 多 NIC 的系统(如某些 HGX B200 / GB200 设计) → 保持默认 1
-
想强制本地 NIC 优先(避免跨 C2C 延迟) → 设 0
开启(默认已开)
NCCL_NET_GDR_C2C=1
关闭对比
NCCL_NET_GDR_C2C=0 NCCL_DEBUG=INFO ./all_reduce_perf ...
日志会显示是否使用了 C2C 路径("via C2C" 或类似字样)。
注意事项
- 只对 PHB 距离的 NIC 有效(即 GPU 和 NIC 不在同一个 PCIe 根复杂下)
- 跨 C2C 有额外延迟,某些对延迟敏感的 AlltoAll 可能反而下降
- 推荐先跑开启 vs 关闭对比,尤其是 8 GPU + 8 NIC 的节点
NCCL_NET_GDR_READ(NVLink 系统默认 1)
作用 发送数据时,允许 NIC 直接从 GPU 显存 RDMA Read 数据(绕过主机内存拷贝)。
开启前 :GPU → cudaMemcpy → 主机 pinned memory → NIC RDMA Write 开启后 :GPU 显存 ← NIC RDMA Read ← 对端
典型收益场景
-
大消息 AllReduce / AlltoAll 发送阶段
-
NVLink 系统(Hopper/Blackwell),因为 GPU 内存访问速度极快
推荐配置 -
Hopper/Blackwell NVLink 系统 → 保持默认 1
-
纯 PCIe 系统 → 默认 0(因为 PCIe 读性能较差,开启反而慢)
-
想测试影响 → 对比开关
实战例子开启(推荐)
NCCL_NET_GDR_READ=1
关闭对比
NCCL_NET_GDR_READ=0 ./all_reduce_perf -b 512M -e 8G -f 2
注意事项
- 在某些 PCIe 系统上开启反而会降低性能(已知问题)
- 需要 GPU 和 NIC 在同一 NUMA 节点或通过高带宽路径相连
- 配合 NCCL_NET_GDR_LEVEL=PIX 或 PXB 效果更好
接受的值
0 或 1。定义并设置为 1 以使用 GPU Direct RDMA 直接发送数据到 NIC(绕过 CPU)。
在 2.4.2 之前,所有平台的默认值为 0。从 2.4.2 起,对于基于 NVLink 的平台默认值为 1,否则为 0。
NCCL_NET_SHARED_BUFFERS(从 2.8 起)
作用 节点间点对点通信(Send/Recv)使用单个共享大缓冲池 ,而不是为每个远程 rank 分配独立缓冲。
开启前 :每个远程 rank 一个缓冲 → 内存占用随 rank 数线性增长 开启后 :所有远程 rank 共享一个大池 → 内存占用恒定
典型收益场景
- rank 数很多(64 节点 × 8 GPU = 512 rank)
- 内存紧张(显存吃紧时)
- 大量小消息点对点通信
推荐配置 - 绝大多数场景 → 保持默认 1
- 极少数特殊情况(发现共享池竞争导致延迟抖动) → 设 0
注意事项 - 开启后内存占用大幅降低(尤其是 AlltoAllv 场景)
- 关闭后内存占用暴增,但可能减少竞争
NCCL_NET_SHARED_COMMS(从 2.12 起)
作用 在 PXN (Peer to eXternal NIC)场景下,重用相同的连接 ,允许消息聚合,但会降低路由多样性。
开启前 :每个 PXN 路径可能建立独立连接 → 路由熵高,但开销大 开启后 :复用连接 → 消息聚合效率高,但所有消息可能走同一条物理路径
典型收益场景
- PXN 开启(NCCL_PXN_DISABLE=0)
- 节点内 GPU 通过 NVLink 共享少量 NIC
- 希望减少连接建立开销
推荐配置 - 默认 1 通常更好(聚合效率高)
- 如果发现单条路径严重拥塞 → 设 0(强制更多独立连接,提高路由均衡)
注意事项 - 设 0 后连接数增加,初始化时间可能变长
- 在多轨 RoCE + PXN 场景下,设 0 有时能缓解热点
NCCL_ALGO
1. NCCL_ALGO 的核心作用和使用方式
NCCL_ALGO 告诉你 NCCL:"我只允许你用这些算法,其他的全部禁用!"
两种写法 :
简单写法(2.5~2.23 主流):
NCCL_ALGO=Ring,Tree,NVLS # 只允许这三种
NCCL_ALGO=^Tree # 排除 Tree(其他都允许)高级写法(2.24+ 推荐,函数级精确控制):
# 为不同集体操作指定不同算法
NCCL_ALGO="allreduce:NVLS,Ring;alltoall:CollnetDirect;broadcast:ring"
# 排除某个操作的某个算法
NCCL_ALGO="allreduce:^Tree"默认行为(未设置): NCCL 根据拓扑自动选择(优先 NVLS → CollnetDirect → Ring → Tree)
2. NCCL 当前所有算法完整解析(按出现顺序)
| 算法名称 | 首次支持版本 | 核心原理 | 适用规模 | 带宽表现 | 延迟表现 | 典型使用场景 | 硬件依赖 |
|---|---|---|---|---|---|---|---|
| Ring | 2.5+ | 经典环形流水线,每个 GPU 只和左右邻居通信 | 所有规模 | 中等(稳定) | 中等 | 通用基准测试、最稳路径 | 无 |
| Tree | 2.5+ | 二叉树/多叉树结构,根节点汇总再广播 | 中小规模 | 小消息快 | 低 | 小消息 AllReduce、广播型操作 | 无 |
| Collnet | 2.5~2.13 | 早期 CollNet(已废弃) | --- | --- | --- | 已废弃 | SHARP |
| CollnetChain | 2.14+ | CollNet 的链式版本 | 大规模 | 高 | 中 | 早期 SHARP 集群 | SHARP |
| CollnetDirect | 2.14+ | CollNet 的直连版本(当前主流) | 大规模 | 极高 | 低 | 多节点 SHARP 集群 | SHARP + 多轨网络 |
| NVLS | 2.17+ | NVLink SHARP(节点内用 NVSwitch 做归约) | 节点内 | 极高 | 极低 | 单节点/双节点 NVLink 系统 | NVSwitch(Hopper+) |
| NVLSTree | 2.18+ | NVLink SHARP 的树形版本 | 节点内 | 极高(小消息更优) | 极低 | GB200 NVL72 等超大规模 NVLink 域 | NVSwitch |
| PAT | 2.23+ | Path-Aware Tree(路径感知树) | 大规模混合拓扑 | 高 | 中 | 异构拓扑(NVLink+RoCE 混合) | 无(智能拓扑感知) |
3. 每个算法的内部工作原理(深度版)
Ring(最经典、最稳)
- 所有 GPU 排成一个环(或多个环)
- 数据分块流水线传输 + 归约
- 优点:实现最简单、带宽利用率高、支持所有操作
- 缺点:大消息时延迟随节点数线性增长
- 推荐:作为保底算法,几乎所有测试都要留 Ring
Tree(二叉/多叉树)
- 构建一棵树,根节点先做 Reduce,再 Broadcast 结果
- 优点:小消息延迟最低
- 缺点:根节点压力大,容易成为瓶颈
- 推荐:小消息(<1MB)AllReduce,或 Broadcast 操作
CollnetDirect / CollnetChain(SHARP 时代)
- 把归约计算卸载到交换机上做(in-network computing)
- CollnetDirect 是当前主力(更灵活)
- 推荐:64 节点以上 + 支持 SHARP 的 RoCE 集群
NVLS / NVLSTree(Blackwell 时代王牌)
- 节点内用 NVSwitch 做硬件归约
- NVLS = 平行归约,NVLSTree = 树形归约
- 推荐:任何有 NVSwitch 的系统(H100 SXM / GB200)都应该优先开启
PAT(Path-Aware Tree,2.23+ 新星)
- NCCL 最智能的算法
- 会根据实际拓扑动态构建最优树(感知 NVLink、RoCE、PXN 等路径)
- 推荐:异构拓扑(NVLink + 多轨 RoCE)时设为默认
5. 测试Tips(直接复制)
# 1. 查看当前实际用了哪个算法
NCCL_DEBUG=INFO NCCL_DEBUG_SUBSYS=GRAPH,TUNING ./all_reduce_perf ...
# 2. 对比不同算法(推荐脚本)
for algo in Ring Tree CollnetDirect NVLS PAT; do
echo "=== Testing $algo ==="
NCCL_ALGO=$algo ./all_reduce_perf -b 1G -e 4G -f 2 -g 1 -n 50
done总结口诀(记住了就能用):
- 节点内 → 优先 NVLS / NVLSTree
- 跨节点多机 → 优先 CollnetDirect / PAT
- 保底稳定 → Ring
- 小消息 → Tree
- 调试 → 先强制 NCCL_ALGO=Ring 做基准,再逐个开启高级算法对比
NCCL_PROTO(从 2.5 起)
NCCL_PROTO 变量定义 NCCL 将允许使用哪些协议。
不鼓励用户设置此变量,除了在怀疑 NCCL 错误时禁用特定协议。特别是,在不支持的平台上启用 LL128 可能导致数据损坏。
接受的值
(从 2.5 起)逗号分隔的协议列表(不区分大小写),其中:LL、LL128 和 Simple。要指定排除的协议(而不是包括),以 ^ 开始列表。
默认行为启用所有支持的算法:在支持 LL128 的平台上相当于 LL,LL128,Simple,否则 LL,Simple。
(从 2.24 起)接受的值扩展以允许更多灵活性,正如 NCCL_ALGO 中描述,允许用户为每个函数指定协议。
测试Tips:协议选择,设置Simple禁用LL诊断。
NCCL_NVB_DISABLE(从 2.11 起)
通过中间 GPU 禁用通过 NVLink 的节点内通信。
接受的值
默认值为 0,设置为 1 以禁用此机制。
测试Tips:NVB禁用测试,验证备用路径。
PXN_Series
1. PXN 到底是什么?(核心概念)
PXN 全称 :Peer to eXternal NIC 中文:对端到外部 NIC (借道机制)
一句话定义 : 当一个 GPU 没有直连高速 NIC 时,它可以通过 NVLink 把数据"借道"给节点内另一个有直连 NIC 的 GPU,由后者帮它把数据发出去。
为什么需要 PXN?
在很多服务器设计中(尤其是 8 GPU + 8 NIC 的 RoCE 节点):
- GPU0、GPU1、GPU2、GPU3 可能只直连前 4 张 NIC
- GPU4、GPU5、GPU6、GPU7 只直连后 4 张 NIC
- 或者 GPU 分布在不同 CPU socket,导致部分 GPU 离最近的 NIC 很远
如果不启用 PXN,这些"远端 GPU"就只能用自己直连的慢路径或走低带宽链路。 PXN 的作用就是让所有 GPU 都能"借用"节点内所有 NIC,最大化聚合带宽。
2. PXN 的实现原理(内部数据流详解)
PXN 的核心是 "节点内 NVLink 中转 + 外部 NIC 发送",整个过程完全由 NCCL 自动完成,不需要应用层修改代码。
详细数据流(以 GPU0 想发数据到远端节点为例):
- GPU0(无直连高速 NIC)产生数据
- NCCL 判断目标 NIC 不在本地 → 启用 PXN
- 数据通过 NVLink 快速发送给中间 GPU(比如 GPU4,它直连高速 NIC)
- 中间 GPU(GPU4)收到数据后:
- 不做任何计算
- 直接把数据通过自己的 本地 NIC 发出(RDMA Send)
- 对端节点收到数据
关键点:
- 整个过程只多了一次 NVLink 跳(延迟极低)
- 中间 GPU 只负责转发,不占用 SM 计算资源(几乎零开销)
- NCCL 会自动选择最佳中间 GPU (离目标 NIC 最近的那个)
PXN 的本质 : 用节点内最快的 NVLink,把数据"搬运"到离出口最近的 GPU,再让它发出去。
3. 三个参数的详细作用与实战用法
(1)NCCL_PXN_DISABLE(从 2.12 起)
- 默认值:0(启用 PXN)
- 设为 1 :完全禁用 PXN 机制
实战用法: - 默认保持 0(推荐),让 NCCL 自动借道
- 只有在以下情况才设 1:
- 想强制每个 GPU 只用自己直连的 NIC(避免跨 NVLink 延迟)
- 发现 PXN 导致单条路径严重拥塞
(2)NCCL_P2P_PXN_LEVEL(从 2.12 起)------ 最重要参数
这是控制 PXN 使用力度 的核心开关,有三个级别:
| 值 | 含义 | 推荐场景 | 聚合效果 |
|---|---|---|---|
| 0 | 完全禁用发送/接收的 PXN | 极少数极致低延迟场景 | 无 |
| 1 | 仅在目标首选 NIC 通过 PCIe 不可访问时 才启用 PXN | 大多数生产环境(推荐) | 中等 |
| 2 | 始终使用 PXN(即使 NIC 通过 PCIe 可达),强制把数据存到中间 GPU | 多 NIC 不对称拓扑、想最大化聚合带宽 | 最强 |
推荐 :默认值 2(最大聚合),尤其在 8 GPU + 8 NIC 的 RoCE 节点上,设 2 通常能多榨 10--25% 跨节点带宽。
(3)NCCL_PXN_C2C(从 2.27 起,默认 1)
- 作用 :允许 GPU 通过 C2C(CPU-to-CPU 互连) + PCIe 借用对端 CPU 上的 NIC
- 默认值:2.28+ 为 1(开启)
适用场景:
- GPU 和 NIC 分布在不同 CPU socket 的服务器(常见于 GB200、部分 B200 设计)
- 开启后可以进一步扩大"借道"范围
推荐 :保持默认 1(开启),除非你明确想限制跨 C2C。
5. 总结 + 一句话口诀
- PXN 原理:用 NVLink 把数据"搬"到离出口最近的 GPU,再由它发出 → 实现节点内所有 GPU 共享所有 NIC
- 核心控制参数:NCCL_P2P_PXN_LEVEL=2(最大聚合)
- NCCL_PXN_DISABLE=1:彻底关闭借道(仅调试用)
- NCCL_PXN_C2C=1:允许跨 C2C 借道(现代多 socket 系统必开)
不常用变量
NCCL_NTHREADS
NCCL_NTHREADS 变量设置每个 CUDA 块的 CUDA 线程数。NCCL 将为每个通信通道启动一个 CUDA 块。
如果您认为 GPU 时钟低并希望增加线程数,请使用此变量。
您也可以使用此变量减少线程数以降低 GPU 工作负载。
接受的值
对于最近一代 GPU,默认值为 512,对于一些旧世代为 256。
允许的值为 64、128、256 和 512。
测试Tips:线程数优化,设置256降低负载测试。
NCCL_CHECKS_DISABLE(从 2.0.5 起,2.2.12 中弃用)
NCCL_CHECKS_DISABLE 变量可用于禁用每个集体调用的参数检查。
检查在开发期间有用,但会增加延迟。可以禁用它们以改善生产性能。
接受的值
默认值为 0,设置为 1 以禁用检查。
测试Tips:生产优化,禁用减少延迟。
NCCL_CHECK_POINTERS(从 2.2.12 起)
NCCL_CHECK_POINTERS 变量启用每个集体调用上的 CUDA 内存指针检查。
检查在开发期间有用,但会增加延迟。
接受的值
默认值为 0,设置为 1 以启用检查。
设置为 1 恢复 NCCL 2.2.12 之前的原始行为。
测试Tips:指针验证,启用开发调试。
NCCL_LAUNCH_MODE(从 2.1.0 起)
NCCL_LAUNCH_MODE 变量控制 NCCL 如何启动 CUDA 内核。
接受的值
默认值为 PARALLEL。
设置为 GROUP 将使用协作组(CUDA 9.0 及以后)用于管理多个 GPU 的进程。
这在 2.9 中弃用,可能在未来版本中移除。
测试Tips:启动模式测试,设置GROUP验证协作组。
NCCL_IB_CUDA_SUPPORT(2.4.0 中移除,见 NCCL_NET_GDR_LEVEL)
接受的值 CUDA_SUPPORT` 变量用于强制或禁用 GPU Direct RDMA 的使用。
默认情况下,NCCL 如果拓扑允许则启用 GPU Direct RDMA。此变量可以禁用此行为或在所有情况下强制使用 GPU Direct RDMA。
接受的值
定义并设置为 0 以禁用 GPU Direct RDMA。
定义并设置为 1 以强制使用 GPU Direct RDMA。
测试Tips:遗留GDR测试,已取代。
NCCL_IB_PCI_RELAXED_ORDERING(从 2.12 起)
启用 IB Verbs 传输的 Relaxed Ordering。Relaxed Ordering 可以极大帮助虚拟化环境中的 InfiniBand 网络性能。
接受的值
设置为 2 以如果可用自动使用 Relaxed Ordering。设置为 1 以强制使用 Relaxed Ordering 并在不可用时失败。设置为 0 以禁用 Relaxed Ordering 的使用。默认值为 2。
测试Tips:Relaxed Ordering测试,启用虚拟化优化。
NCCL_IB_ADAPTIVE_ROUTING(从 2.16 起)
启用 IB Verbs 传输的自适应路由能力数据传输。自适应路由可以改善大规模通信性能。必须相应选择系统定义的自适应路由启用 SL(参阅 NCCL_IB_SL)。
接受的值
默认在 IB 网络上启用 (1)。在 RoCE 网络上默认禁用 (0)。设置为 1 以强制使用自适应路由能力数据传输。
测试Tips:AR启用测试,结合SL优化大规模。
NCCL_IB_ECE_ENABLE(从 2.23 起)
启用 IB/RoCE Verbs 网络上的增强连接建立 (ECE)。ECE 可用于启用高级网络功能,如拥塞控制、自适应路由和选择性重复。注意:这些参数不由 NCCL 解释或控制,而是通过 ECE 机制直接传递到 HCA。
接受的值
默认启用 (1)(从 2.19 起)。设置为 0 以禁用 ECE 网络能力的使用。
注意:系统上 ECE 参数的错误配置可能会不利影响 NCCL 性能。如果在系统级别启用,管理员应确保 ECE 配置正确。
测试Tips:ECE功能测试,启用验证高级网络。
NCCL_MEM_SYNC_DOMAIN
(从 2.16 起)
设置 NCCL 内核的默认内存同步域(CUDA 12.0 & sm90 及以后)。内存同步域可以帮助消除 NCCL 内核和应用计算内核之间的干扰,当它们使用不同域时。
接受的值
默认值为 cudaLaunchMemSyncDomainRemote (1)。当前支持的值为 0 和 1。
测试Tips:同步域测试,设置1减少干扰。
NCCL_CUMEM_ENABLE(从 2.18 起)
在 NCCL 中使用 CUDA cuMem* 函数分配内存。
接受的值
0 或 1。2.18 中的默认值为 0(禁用);从 2.19 起,如果系统支持,此功能默认自动启用(NCCL_CUMEM_ENABLE 仍可用于覆盖自动检测)。
测试Tips:cuMem分配测试,启用验证现代内存管理。
NCCL_CUMEM_HOST_ENABLE(从 2.23 起)
在 NCCL 中使用 CUDA cuMem* 函数分配主机内存。请参阅以获取更多信息。
接受的值
0 或 1。
2.23 中的默认值为 0;从 2.24 起,如果 CUDA 驱动 >= 12.6、CUDA 运行时 >= 12.2 且支持 cuMem 主机分配,则默认值为 1。
测试Tips:主机cuMem测试,启用优化主机缓冲。
NCCL_SINGLE_RING_THRESHOLD(从 2.1 起,2.3 中移除)
NCCL_SINGLE_RING_THRESHOLD 变量设置 NCCL 仅使用一个环的限制。
这将限制带宽但改善延迟。
接受的值
对于计算能力 7 及以上的 GPU,默认值为 262144 (256kB)。否则,默认值为 131072 (128kB)。
值为整数,以字节为单位。
测试Tips:遗留单环阈值,已移除。
NCCL_LL_THRESHOLD(从 2.1 起,2.5 中移除)
NCCL_LL_THRESHOLD 变量设置 NCCL 使用低延迟算法的大小限制。
接受的值
默认值为 16384(最高 2.2)或依赖于等级数(2.3 及以后)。
值为整数,以字节为单位。
测试Tips:遗留LL阈值,已移除。
NCCL_TREE_THRESHOLD(从 2.4 起,2.5 中移除)
NCCL_TREE_THRESHOLD 变量设置 NCCL 使用树算法而不是环的大小限制。
接受的值
默认值依赖于等级数。
值为整数,以字节为单位。
测试Tips:遗留树阈值,已移除。
NCCL_RUNTIME_CONNECT(从 2.22 起)
在运行时动态连接对端(例如调用 ncclAllreduce())而不是初始化阶段。
接受的值
默认值为 1,设置为 0 以在初始化阶段连接对端。
测试Tips:动态连接测试,禁用回退初始化连接。
NCCL_GRAPH_REGISTER(从 2.11 起)
当 NCCL 调用被 CUDA 图捕获时启用用户缓冲区注册。
仅在以下情况下有效:
(i) 使用 CollNet 算法;
(ii) 节点内所有 GPU 彼此有 P2P 访问;
(iii) 每个进程最多一个 GPU。
用户缓冲区注册可能减少用户缓冲区和 NCCL 内部缓冲区之间的数据拷贝数。
当 CUDA 图被破坏时,用户缓冲区将自动注销。
接受的值
0 或 1。默认值为 1(启用)。
测试Tips:图注册测试,启用减少拷贝。
NCCL_LOCAL_REGISTER(从 2.19 起)
当用户显式调用 ncclCommRegister 时启用用户本地缓冲区注册。
接受的值
0 或 1。默认值为 1(启用)。
测试Tips:本地注册测试,启用自定义缓冲。
NCCL_LEGACY_CUDA_REGISTER(从 2.24 起)
通过 cudaMalloc (和相关内存分配器)分配的 Cuda 缓冲区是遗留缓冲区。注册遗留缓冲区可能导致隐式同步,这是不安全的,并可能导致 NCCL 挂起。NCCL 默认禁用遗留缓冲区注册,用户应移动到基于 cuMem 的内存分配。
接受的值 (未完整,但基于文档,默认禁用)
测试Tips:遗留注册测试,注意挂起风险。