软件开发时,写出能够正常运行的代码只是基础。当面对高并发、低延迟以及云原生 AOT 编译部署等严苛的生产环境要求时,初级开发与资深开发在编码设计上的差距便会显现。
本文将从底层原理出发,对比初级实现与资深优化的差异,深入剖析八个实用的 C# 13 与 .NET 10 高级开发技巧。

内存管理优化
在高吞吐量的服务中,垃圾回收(GC)的压力通常是导致系统响应时间出现长尾(P99 延迟高)的主要因素。减少堆内存分配是提升系统吞吐性能的有效手段。
初级做法 --- 频繁分配堆内存
初级编写的代码通常不关注临时对象的分配,频繁使用 new 关键字在堆上开辟空间。
c#
// 每次调用都会创建新的列表和 Task 对象,产生垃圾回收开销
public async Task<List<double>> ParseSensorDataAsync(byte[] rawData)
{
var results = new List<double>();
using var stream = new MemoryStream(rawData);
using var reader = new StreamReader(stream);
while (!reader.EndOfStream)
{
var line = await reader.ReadLineAsync();
if (double.TryParse(line, out var value))
{
results.Add(value);
}
}
return results;
}资深做法 --- 零分配与对象池复用
资深开发者会避免在高频热点路径上分配临时数组与对象,通过对象池复用内存,并利用 ValueTask 优化同步完成的路径。
c#
using System.Buffers;
public readonly record struct SensorReading(int DeviceId, double Value);
public class DataParser(ArrayPool<SensorReading> pool)
{
private readonly ArrayPool<SensorReading> _pool = pool;
// 使用 ValueTask 减少 Task 对象分配,使用 ReadOnlyMemory 避免复制
public async ValueTask<ReadOnlyMemory<SensorReading>> ParseOptimizedAsync(
ReadOnlyMemory<byte> rawData,
CancellationToken ct = default)
{
// 从对象池租用缓冲区,避免在堆上分配新数组
var buffer = _pool.Rent(100);
var count = 0;
try
{
// 此处省略复杂的 Span 解析逻辑,直接将解析数据存入 buffer
buffer[count++] = new SensorReading(1, 45.2);
// 模拟异步等待,但在同步完成时 ValueTask 不会产生堆分配
await Task.Yield();
return new ReadOnlyMemory<SensorReading>(buffer, 0, count);
}
catch
{
_pool.Return(buffer, clearArray: true);
throw;
}
}
}通过将 Task 替换为 ValueTask,以及利用 ArrayPool 复用临时数组,能够有效降低高并发环境下的 GC 触发频率,提升系统的稳定运行能力。
异步编程与结构化并发
异步编程不仅仅是叠加 async 和 await,还需要合理控制并发执行顺序并管理线程上下文。
初级做法 --- 顺序等待与不必要的上下文捕获
初级开发在处理多个异步操作时,通常采用循环等待的方式,导致原本可以并行的操作变成了串行执行。
c#
// 串行执行,没有并行优势,且未传递 CancellationToken
public async Task<double[]> GetDevicesDataSlowAsync(int[] deviceIds)
{
var results = new List<double>();
foreach (var id in deviceIds)
{
var data = await FetchFromRemoteAsync(id); // 依次等待,效率低下
results.Add(data);
}
return [.. results];
}资深做法 --- 并行处理、上下文忽略与 C# 13 局部引用
高级做法会启动并行任务,合理运用 ConfigureAwait(false) 释放上下文,并结合 C# 13 的局部引用(ref locals)在不跨越等待边界的前提下直接修改缓冲区。
c#
public async ValueTask<double[]> GetDevicesDataFastAsync(
int[] deviceIds,
CancellationToken ct)
{
if (deviceIds.Length == 0) return [];
// 并行触发所有异步任务
var tasks = deviceIds
.Select(id => FetchFromRemoteAsync(id, ct))
.ToArray();
// 在类库和非 UI 环境中,通过 ConfigureAwait(false) 避免强制返回原同步上下文
var results = await Task.WhenAll(tasks).ConfigureAwait(false);
// C# 13 允许在异步方法中声明 ref 局部变量,只要其不跨越 await 语句即可
ref double firstElement = ref results[0];
if (firstElement < 0)
{
firstElement = 0.0; // 直接通过引用修改,免去寻址开销
}
return results;
}现代 C# 13 语法实践
C# 13 引入了诸多编译期的语法糖与底层优化,合理运用这些新特性能够让代码在保持高性能的同时更加简洁。
初级做法 --- 繁琐的初始化与参数可变风险
在早期版本中,初始化集合通常需要编写大量样板代码,且主构造函数的参数容易被意外修改。
c#
public class UserConfiguration
{
private readonly string _role;
public UserConfiguration(string role)
{
_role = role;
}
public List<string> GetDefaultPermissions()
{
var list = new List<string>();
list.Add("Read");
list.Add("Write");
return list;
}
}资深做法 --- 集合表达式、主构造函数安全赋值与 field 关键字
在 C# 13 中,推荐使用集合表达式、将主构造函数参数锁定为只读字段,并配合预览版的 field 关键字来编写更安全的属性。
c#
// 使用主构造函数,并将其显式赋予只读成员以防止后续被篡改
public class UserConfigurationOptimized(string role)
{
private readonly string _role = role;
// C# 13 使用集合表达式,编译器在底层会优化数组或集合的创建过程
public ReadOnlySpan<string> DefaultPermissions => ["Read", "Write"];
// C# 13 的 field 关键字(预览功能)允许直接访问自动属性的后备字段,避免编写样板代码
public required string SystemStatus
{
get => field;
set
{
if (value is not ("Online" or "Offline"))
throw new ArgumentException("状态不合法");
field = value;
}
}
}读多写少场景的极致优化 ------ FrozenCollections
在很多业务系统中,存在大量只在启动时加载、运行期间仅用于查询的数据,例如国家代码映射、错误码表或业务策略配置。
初级做法 --- 使用标准的 Dictionary
普通字典在设计上为了兼顾添加、删除操作,保留了较为复杂的冲突处理链。
c#
private static readonly IReadOnlyDictionary<int, string> _errorCodes =
new Dictionary<int, string>
{
{ 404, "未找到资源" },
{ 500, "服务器内部错误" }
}; // 只读包装器并没有改变底层的哈希查找机制资深做法 --- 转换为 FrozenDictionary
在 .NET 8 及以上版本中,针对此类静态数据,可以使用 System.Collections.Frozen 命名空间下的固化集合。
c#
using System.Collections.Frozen;
private static readonly FrozenDictionary<int, string> _optimizedErrorCodes =
new Dictionary<int, string>
{
{ 404, "未找到资源" },
{ 500, "服务器内部错误" }
}.ToFrozenDictionary(); // 编译或构建时重新对键进行无冲突哈希映射FrozenDictionary 会在创建时彻底分析键的集合,计算出一种近乎零冲突的哈希表结构。这使得在后续运行过程中的读取操作性能达到极致,空间占用也更为紧凑。
硬件加速的字符串/字符查找 ------ SearchValues<T>
对输入文本进行特定字符或敏感词的扫描是常见的业务需求。
初级做法 --- 循环匹配或低效的正则表达式
频繁使用 LINQ 或正则表达式来匹配特定字符组会带来大量的 CPU 时钟周期消耗。
c#
public bool HasInvalidSymbols(string text)
{
char[] targets = ['<', '>', '"', '''];
return text.Any(c => targets.Contains(c)); // 产生了多次迭代与无谓的内存分配
}资深做法 --- 使用编译期硬件加速的 SearchValues
利用 .NET 8 引入、并在 .NET 10 中继续强化的 SearchValues<T>,可以将匹配工作交给向量化(SIMD)底层指令。
c#
using System.Buffers;
public class SecurityValidator
{
// 预先创建搜索值集合
private static readonly SearchValues<char> _invalidPayload =
SearchValues.Create(['<', '>', '"', ''']);
public bool HasInvalidSymbolsFast(ReadOnlySpan<char> text)
{
// 自动利用当前 CPU 支持的最优指令集(如 AVX2 或 ARM NEON)进行高速扫描
return text.ContainsAny(_invalidPayload);
}
}SearchValues 底层会根据当前运行机器的 CPU 架构选择最佳的并行计算方式,以极高的速度扫描字符,避免了手动编写指针带来的安全隐患。
应对缓存击穿的官方标准方案 ------ HybridCache
当高并发请求同时穿透到数据库,而缓存中正好没有该项数据时,系统很容易出现缓存击穿,甚至导致后端服务瘫痪。
初级做法 --- 双重检查锁与手动并发控制
为了解决并发打满数据库的问题,开发人员经常手写复杂的锁逻辑,极易引发死锁或处理不周。
c#
public async Task<string> FetchCatalogDataAsync(string key)
{
var data = await _cache.GetStringAsync(key);
if (data == null)
{
lock (_syncLock) // 进程内锁,在分布式环境下依然无法完全阻断对数据库的冲击
{
data = GetFromDatabase(key);
_cache.SetString(key, data);
}
}
return data;
}资深做法 --- 采用 .NET 官方内置的 HybridCache
.NET 9 及 .NET 10 引入了全新的 HybridCache。它无缝融合了内存缓存(L1)与分布式缓存(L2),且默认具备防击穿机制。
c#
using Microsoft.Extensions.Caching.Hybrid;
public class CatalogService(HybridCache cache)
{
private readonly HybridCache _cache = cache;
public async ValueTask<string> GetCatalogDataOptimizedAsync(string key, CancellationToken ct)
{
// GetOrCreateAsync 保证在缓存失效时,只有一个线程会执行底层的数据库查询操作
return await _cache.GetOrCreateAsync(
$"catalog:{key}",
async token => await FetchFromDbAsync(key, token),
cancellationToken: ct);
}
private Task<string> FetchFromDbAsync(string key, CancellationToken ct)
{
return Task.FromResult("数据库中的商品信息数据");
}
}HybridCache 的底层防击穿机制会自动阻断重复的穿透请求。同时,它还支持通过标记(Tag)进行大范围缓存的级联失效,大大降低了维护复杂缓存同步系统的难度。
用 Source Generators 代替运行时反射
为了让 C# 编写的服务在云原生(如 AWS Lambda、K8s 容器)中获得更快的启动速度和更低的内存消耗,Native AOT 编译部署正逐渐成为主流。然而,运行时反射无法与 Native AOT 兼容,且执行性能较差。
初级做法 --- 依赖反射的 JSON 序列化
普通开发习惯于直接调用各种反射库,这在运行时会带来巨大的开销,且在 AOT 裁剪时会导致关键代码丢失。
c#
// 运行时需要利用反射剖析 SensorReading 的成员,性能较差,且不支持 Native AOT
var jsonText = JsonSerializer.Serialize(new SensorReading(12, 98.6));资深做法 --- 使用编译期源生成器
通过 Source Generators,编译器在编译阶段就能够把序列化所需要的元数据直接生成好,彻底摆脱运行时的反射机制。
c#
using System.Text.Json.Serialization;
// 通过特性指示编译器在编译期生成序列化逻辑
[JsonSerializable(typeof(SensorReading))]
internal partial class SensorJsonContext : JsonSerializerContext
{
}
public class SerializerHelper
{
public string SerializePayload(SensorReading reading)
{
// 传入编译期生成的上下文对象,实现零反射序列化,完全兼容 Native AOT
return JsonSerializer.Serialize(reading, SensorJsonContext.Default.SensorReading);
}
}在高性能场景中,配合源生成日志([LoggerMessage])等其他源生成技术,能够显著提升应用的启动效率,并让运行期内存保持在极低水平。
异常与错误处理的性能考量
在 C# 中,创建和抛出异常(Exception)需要收集调用堆栈(Stack Trace),其开销高昂。因此,绝不应将异常作为日常业务流程控制的手段。
初级做法 --- 用抛异常来做普通的业务校验
初级做法习惯在遇到非预期输入时通过抛出异常来中断流程。
c#
public double CalculateRate(double value)
{
if (value <= 0)
{
// 仅仅是数据输入不合法,抛出异常会导致 CPU 开销暴涨数倍
throw new ArgumentException("值必须大于零");
}
return 100.0 / value;
}资深做法 --- 使用结果模式与统一问题细节(Problem Details)
高级写法提倡使用"结果模式"(Result Pattern)表达业务错误,并通过标准的 Problem Details(RFC 7807)返回给调用端。
c#
// 使用记录类型定义轻量级的结果对象
public abstract record OperationResult<T>
{
public sealed record Success(T Data) : OperationResult<T>;
public sealed record Failure(string ErrorCode, string Message) : OperationResult<T>;
}
public class BusinessCalculator
{
public OperationResult<double> CalculateRateOptimized(double value)
{
if (value <= 0)
{
// 作为普通数据返回,免去收集调用堆栈的巨大代价
return new OperationResult<double>.Failure("INVALID_VALUE", "计算值不能小于或等于零");
}
return new OperationResult<double>.Success(100.0 / value);
}
}在 API 接口层,利用匹配表达式将 Failure 直接转化为 ASP.NET Core 的问题细节格式输出,既维护了标准的错误响应格式,又保护了高频接口的响应性能。
在进行高性能开发与新语法尝试时,高效的本地开发环境配置同样是拉开开发效能差距的关键。本节将为您拓展介绍如何高效管理本地多版本环境。
高效多版本 .NET 本地环境管理
许多开发者在管理本地多版本 SDK、数据库和服务器组件时,一不小心环境就冲突了。传统做法普遍通过复杂的容器化配置或手动下载多个 SDK 压缩包来回修改环境变量。当需要同时维护经典的遗留项目(如基于 Mono 运行的代码)与最新的 .NET 10 现代项目时,极易因版本切换产生各种编译冲突。
针对本地环境管理的痛点,使用 ServBay 这一现代化本地集成开发环境管理工具及一体化AI 基础设施,能够极大地提升本地开发的灵活性与效率。
ServBay 在环境部署与维护上带来了便捷的特性:
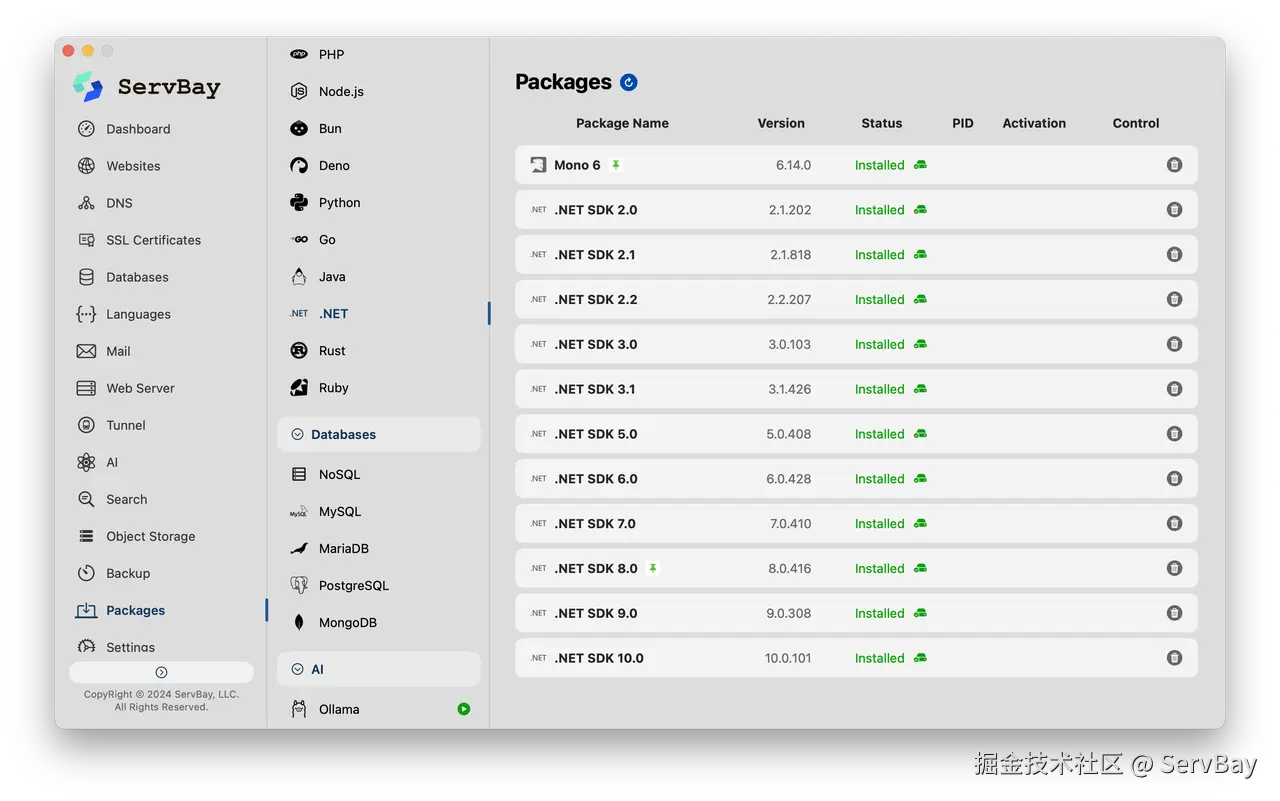
-
一键安装 .NET 环境:无需手动配置复杂的 Path 变量或依赖繁琐的命令行包管理工具,通过直观的图形界面即可秒级部署所需的 .NET SDK。
-
多版本 .NET 环境并存:原生支持从早期版本到最新 .NET 10.0 的广泛版本区间,甚至包含经典的 Mono 框架。不同版本可以在本地干净、独立地共存,无需担心彼此产生版本冲突或相互覆盖。
这使得开发者得以在干净的本地系统中,轻松切换并同时运行多个不同技术栈的后端服务,将更多的精力专注于代码本身的逻辑优化。
总结:资深开发的演进方向
编写具备生产级生存能力的高性能代码,核心在于转变编码思维:
- 运营思维 --- 关注系统在高并发运行状况下的真实表现。
- 经济思维 --- 精打细算每一字节的内存分配和每一个 CPU 时钟周期。
- 工程思维 --- 利用现代 C# 13 特性与 .NET 10 的源生成器、固化集合等基础架构,再配合 ServBay 等高效率的本地多版本管理工具,让整个开发与运行流程保持高效与纯净。