你给项目写了 CLAUDE.md,拆了几条 rule,做了几个 skill,又接了两个 MCP。然后 agent 该犯的错照犯,定下的规矩当没看见。
这时候你会怀疑一件事:它到底有没有读到?
这个问题比看起来值钱。因为「我配了一个文件」和「这个文件的内容真的影响了模型这一步的决策」之间,隔着好几道关,每道关都可能悄悄漏掉。我把它拆成四件常被当成一件的事:
关联 ≠ 加载 ≠ 读到 ≠ 遵守。
你在 .claude/ 里放了文件,是「关联」;它在这次会话里被拼进了上下文窗口,是「加载」;模型在当前这一步真的把它纳入了判断,是「读到」;它照着做了,才是「遵守」。四件事任意一环断掉,结果都是「规矩没生效」,但断在哪一环,排查方式完全不同。
这篇先把接知识库的几种方式过一遍,再讲每种方式到底在什么时机、以什么形式进上下文,最后讲怎么确认它真进去了、真受约束了。还是 Claude Code(下称 CC)和 Codex 两侧对着看,CC 一侧以官方文档为准、措辞保守,Codex 一侧能落到源码行号的我都标了出处。
一、知识库有哪些访问途径
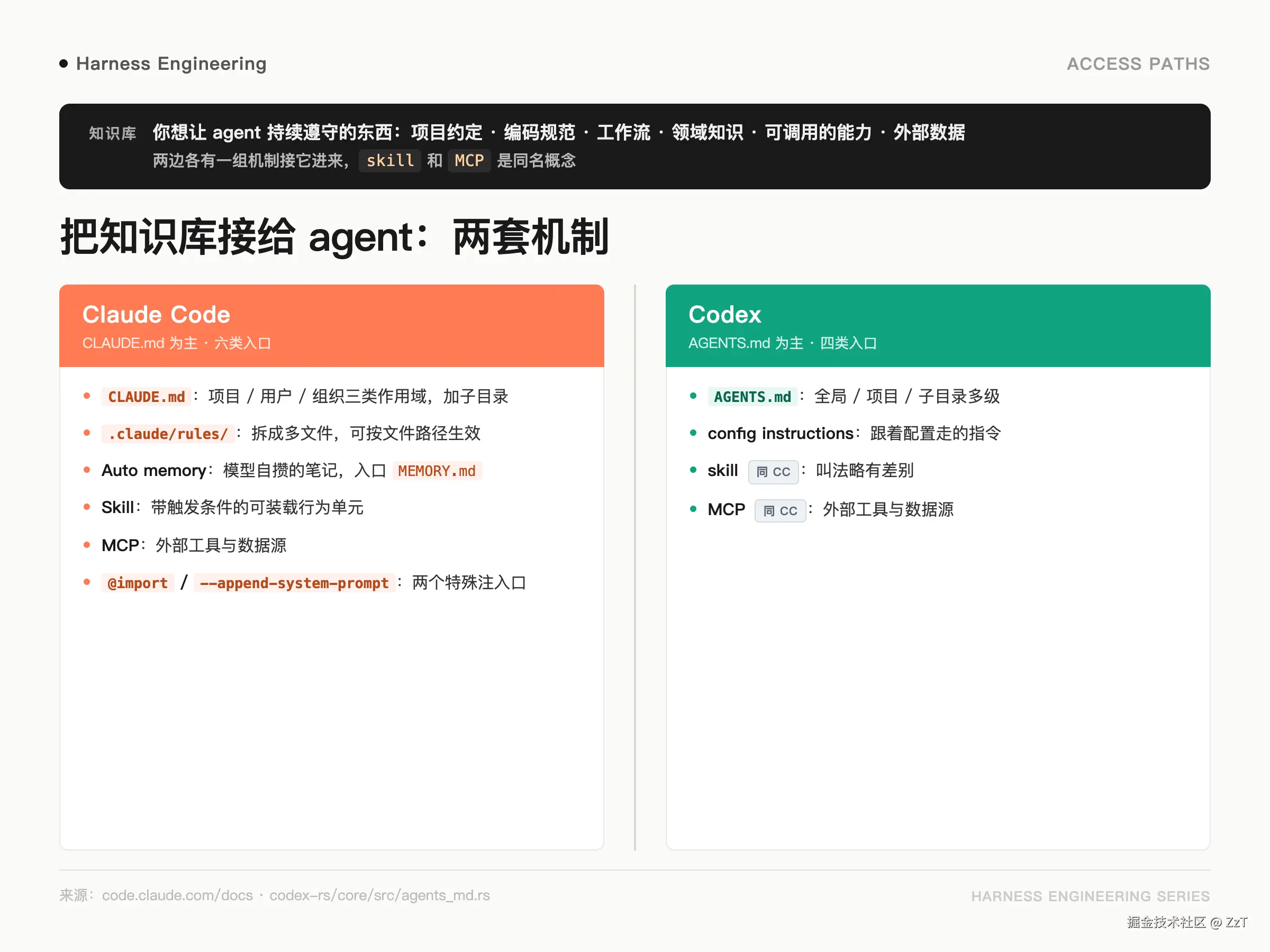
先把「知识库」说清楚:这里指你想让 agent 持续遵守的东西------项目约定、编码规范、工作流、领域知识、可调用的能力、外部数据。把这些接给 agent,CC 和 Codex 各有一组机制,大体能一一对上:
| 机制 | Claude Code | Codex |
|---|---|---|
| 主指令文件 | CLAUDE.md:项目 / 用户 / 组织三类作用域,加上子目录里的 CLAUDE.md | AGENTS.md:全局 / 项目 / 子目录多级 |
| 拆分规则 | .claude/rules/:拆成多个文件,可按文件路径生效 |
config 里的 instructions:跟着配置走的指令 |
| 自动记忆 | Auto memory:模型自己攒的笔记,入口 MEMORY.md |
------ |
| 技能 | Skill:带触发条件的可装载行为单元 | skill:同名概念,叫法略有差别 |
| 外部工具 / 数据 | MCP | MCP |
| 特殊注入口 | @import、--append-system-prompt |
------ |
这几种途径看着差不多,关键差别都在下一节。它们进上下文的时机和形式不一样,正是「我配了它却没生效」的根源。
二、每种途径怎么进上下文

差别藏在三件事里:什么时候进上下文、以什么身份进、哪里会悄悄漏。先用一张表摆清楚骨架,源码出处放在表下:
| 途径 | 什么时候进上下文 | 以什么身份 / 形式 | 最容易栽的点 |
|---|---|---|---|
| CLAUDE.md / AGENTS.md | 开机加载「启动目录往上」那条链;子目录的要等 agent 真去读那个目录的文件才进 | 当作 user 消息注入,不是 system prompt------是 context,不是强制配置 | 子目录规则这次没碰就一直不在;AGENTS.md 默认 32 KiB 上限,超了直接截断(不是没重视,是没进去) |
.claude/rules/ |
带 paths: 的按 glob 路径触发;不带 paths 的才开机全量 |
同 CLAUDE.md,落在 user 侧 | 写了 paths 却没动对应目录 → 规则不生效,这是设计不是 bug |
| skill | 开机只进元数据(名字 + description);正文等被触发才加载 |
progressive disclosure:不用几乎不占 token,一旦加载则后续每轮常驻 | description 没匹配上 → 正文一字不进;「被发现 / 被加载 / 被触发」是三件事 |
| MCP | 工具定义(schema)开机就进上下文 | 占 token 的工具清单 | 挂得多、每个工具又多 → 先交一大笔上下文「租金」 |
| 权限 / hook | 工具真正执行前拦截,不经过模型的意愿 | 客户端硬约束,跳出上面这条「进上下文」的链 | 想「不管模型怎么想都拦住」就别写进 CLAUDE.md,用 deny 规则或 PreToolUse hook |
几个值得记的细节和出处:
- CLAUDE.md :官方定性是 context、不是 enforced configuration,写在里面的「务必 / 绝不」本质是请求不是开关;
@import开机展开、最多 4 跳,块级 HTML 注释注入前被剥掉,可拿来给人留言不占 token。 - AGENTS.md :多级发现见
core/src/agents_md.rs,32 KiB 上限是AGENTS_MD_MAX_BYTES(core/src/config/mod.rs:186);被包成# AGENTS.md instructions .../</INSTRUCTIONS>标签的 user 指令(core/src/context/user_instructions.rs),再和 config instructions 合并。 - skill :元数据在列表里有上限,
description+when_to_use合起来超过 1536 字符会被截断;Codex 侧元数据按预算渲染后拼进 developer 消息(core/src/session/mod.rs的build_available_skills)。 - MCP :工具从连接管理器列出、过滤可访问且启用的再拼进指令(
core/src/connectors.rs)。 - 权限 :CC 是
allow/ask/deny三数组,判定 deny > ask > allow,再叠 permission mode(default / acceptEdits / plan / bypassPermissions);Codex 做进类型系统------SandboxPolicy四种取值(protocol/src/protocol.rs:878)、AskForApproval五种(:784)、细粒度GranularApprovalConfig(:817-854)能分别管 skill / rules / MCP 要不要逐次确认。
一句话收住这节:CLAUDE.md / rule / skill 里的话,是给模型看的建议;权限和 hook,是替你拦动作的闸。想要「一定」,得用后者。
三、怎么确认 agent 真的读到了、真的受限了
🖼 配图位:verify.png ------ 编辑器拖入 verify.png
这是这篇最该解决的问题。把前面那条「关联 ≠ 加载 ≠ 读到 ≠ 遵守」拆开,验证手段也分两层:一层看东西进没进上下文窗口(静态),一层看 agent 实际跑了什么(行为)。
先看:东西到底进没进上下文
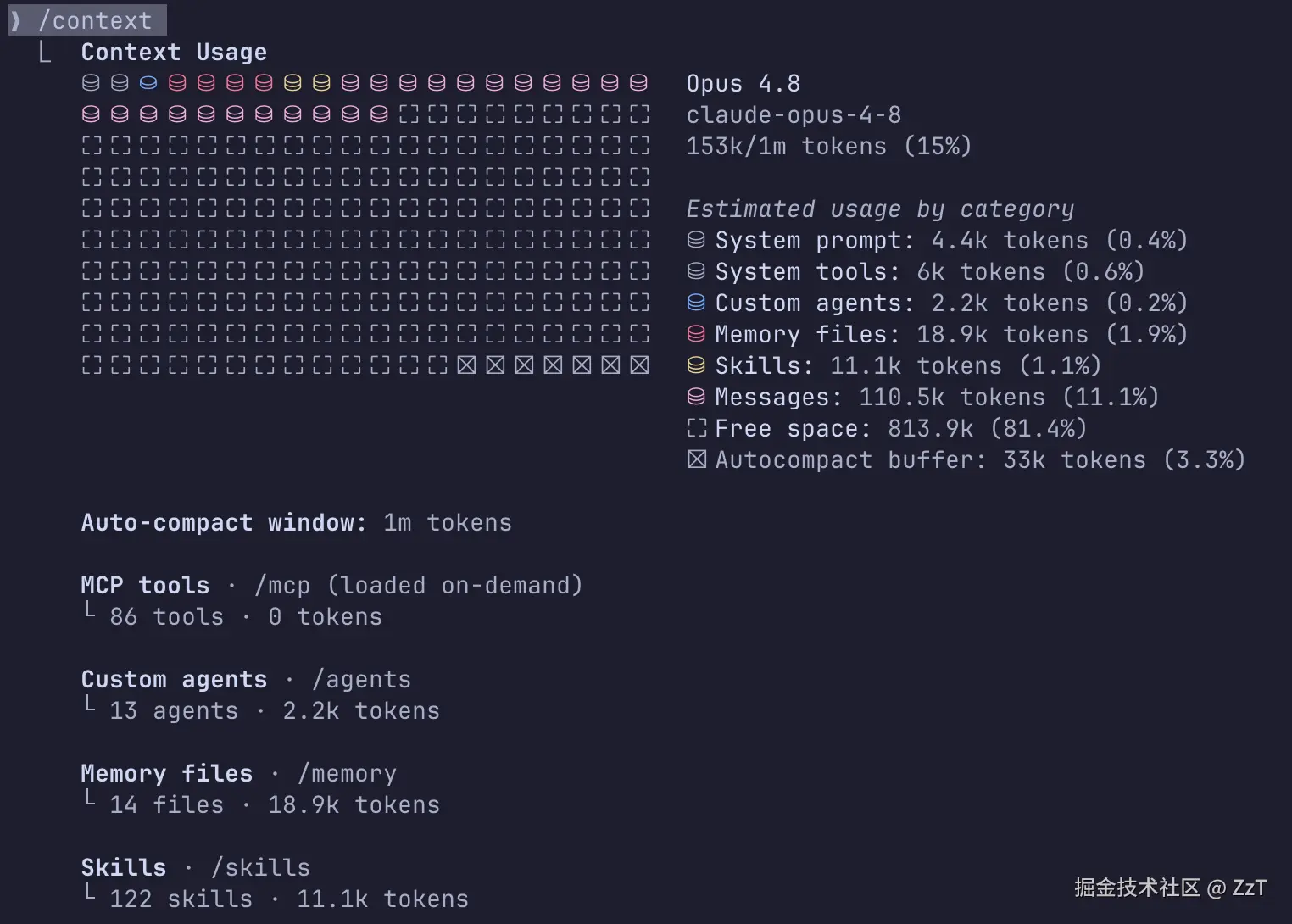
CC 有几个现成的口子。
/context:看当前上下文窗口的 token 分布------system prompt、工具、MCP、记忆文件、消息各占多少。最直接的判断是,你以为加载了的东西,如果这里没有它的份额,那就是没进去。/memory:列出本次会话实际加载了哪些 CLAUDE.md、CLAUDE.local.md 和 rules 文件。不在这个列表里的文件,模型就是看不见。排查「CLAUDE.md 不生效」,第一步就是跑它确认文件在不在列表。InstructionsLoadedhook:想要精确日志,可以用这个 hook 记录到底哪些指令文件、在什么时候、为什么被加载,特别适合排查 path-scoped rule 和子目录里那种懒加载的文件。
还有几个由前面机制直接推出来的检查动作:子目录的 CLAUDE.md、MEMORY.md 200 行以外的内容、topic 文件,开机都不进上下文,要确认它们生效,就看模型有没有真的去 read 对应目录的文件;/compact 之后,项目根的 CLAUDE.md 会被重新读盘注入,子目录的不会,所以压缩后规则「变松」往往是这个原因。
再看:agent 实际跑了什么
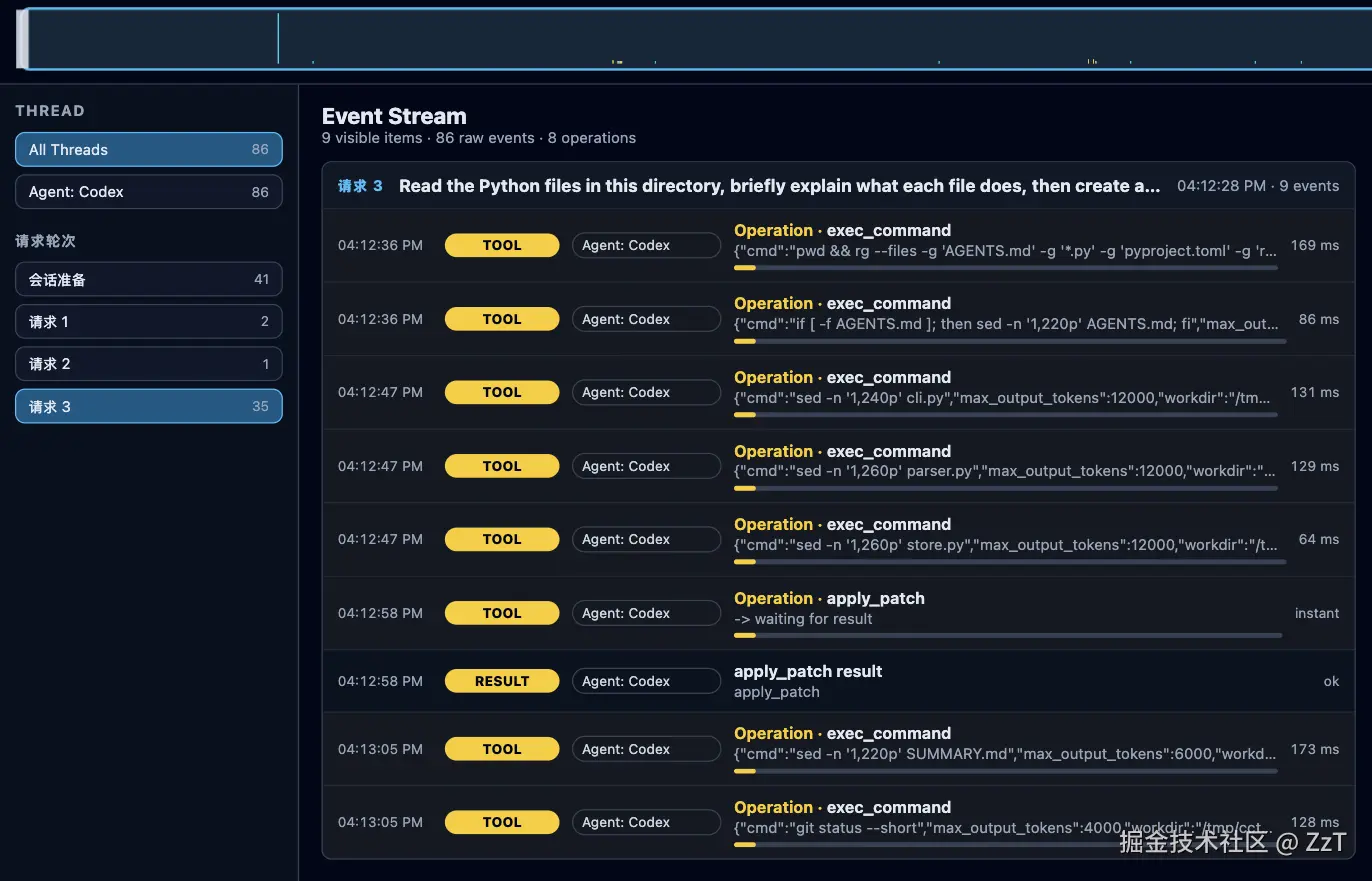
静态检查能告诉你「东西在不在窗口里」,但回答不了「你那个 skill 这次到底触发没触发」「派出去的子 agent 有没有继承你的规则」。这些是行为层的问题,得看一次真实运行的执行轨迹。
这一层可以用一个开源的 profiler,比如 cctrace(Go 写的,MIT,本地跑,不联网)。它的做法是包一层你的 agent(cctrace claude -- claude 或 cctrace codex -- codex),把这次运行的事件铺成一条本地的瀑布流时间线。对应到本文的问题,它有几样东西正好对得上:
- 它在会话启动时会收集「这台机器上发现了哪些 skill,以及它们的 description」,又在时间线上标出「哪个 skill 这次真的触发了」。两相对照,你就能判断:如果某个 skill 在清单里、却整场没 fire,那就是它的
description没让模型路由过来,问题在描述,不在正文。 - 它把子 agent 的 fan out 单独标出来。这点很关键:子 agent 跑在自己独立的上下文里,并不自动继承你主会话里那套 CLAUDE.md。很多「我明明写了规则,子任务却不守」的情况,就是因为活是子 agent 干的,而它从来没读到过那条规则。在时间线上看到 fan out,你才会意识到该把规则下沉到子 agent 能拿到的地方。
- 它把工具调用、模型思考、卡顿、重试都摆在同一条时间轴上,于是「这一步到底调了什么、花在哪」一目了然。
简单说,内置的 /context、/memory 回答「上下文里有什么」,profiler 回答「agent 实际做了什么」。两边对上,才算真的确认了。
Codex 一侧:把发给模型的东西原样落盘
Codex 还提供了一条更彻底的路。设置环境变量 CODEX_ROLLOUT_TRACE_ROOT(rollout-trace/src/thread.rs),它会把每次推理的请求、响应、工具调用这些原始事件和 payload 落盘成一个本地 bundle,事后用离线 reducer 重建出「模型实际看到的那串 conversation items」。这是最硬的 ground truth:不是推断它读没读到,是把真正送进模型的东西原样存下来,逐条核对。会话级的 rollout 持久化在 core/src/session/mod.rs 一带。
想要「一定生效」,只有两条路
绕了一圈,结论很短:context 里的文字不保证被严格执行。你真要某条规则「一定」生效,只有两条路:要么把它提到 system prompt 那一级(CC 的 --append-system-prompt,或组织级的 managed 配置),要么干脆别走「说服模型」这条路,用 hook 和权限规则在客户端把动作直接拦掉。前者提高被遵守的概率,后者根本不给模型选择的机会。
小结
配了,不等于加载了;加载了,不等于读到了;读到了,不等于会遵守。
接知识库的每种方式,都卡在这条链的不同位置:CLAUDE.md 和 rule 卡在「什么时机、以什么身份进上下文」,skill 卡在「description 有没有让它被路由」,MCP 卡在「值不值得占这份上下文」,权限则干脆跳出这条链、在客户端硬拦。
排查的时候,先用 /context、/memory、InstructionsLoaded 确认东西进没进窗口,再用一次真实运行的执行轨迹确认 agent 到底跑了什么、skill 有没有触发、子 agent 有没有继承规则。想要确定性,就别赌上下文里的文字被严格执行,把它提到 system prompt,或者交给 hook 和权限。
下一篇回到长任务那条线:harness 怎么扛住一个跨很多轮的会话------compaction、memory、goal 是怎么配合的。
Harness Engineering 系列
围绕 coding agent 的「平台层(harness)与业务工程」,逐篇拆解:
- Harness 到底指什么 ------ 平台层与业务工程的边界
- 复杂任务的 Spec 怎么写 ------ 多 Agent、编排者入口、rules / docs / skills 组织
- Harness 怎么扩展:skill、配置目录与 hook ------ CC 与 Codex 的两套扩展机制
- Harness 怎么拿捏 agent:权限与 effort ------ CC 与 Codex 的控制面对比
- 费时费力做的 Spec 和知识库,Agent 真受约束了么 ------ 本篇
- Harness 怎么扛住长任务 ------ compact、memory、goal(写作中)