
写在前面
前面两篇聊了Feed流的概念和架构选型,这一篇开始落地到具体的数据模型设计。
虽然前文讨论了很多问题和策略,但落到存储层面,其实也就是几张表加上Redis缓存的事情。表设计得好不好,直接影响后面业务逻辑的复杂度和系统的性能。所以这一篇我们会把每张表的设计思路讲清楚------为什么这么设计,每个字段的作用是什么,索引怎么建。
1. 消息表
消息表是整个系统最核心的表,存储所有Feed消息的内容。每条用户发布的动态都是这里的一条记录。
sql
CREATE TABLE message (
msg_id BIGINT PRIMARY KEY COMMENT '消息ID,建议使用雪花算法生成',
sender_id BIGINT NOT NULL COMMENT '发布者ID',
msg_title VARCHAR(255) COMMENT '消息标题',
msg_content TEXT COMMENT '消息内容',
msg_type TINYINT COMMENT '消息类型:1-文字,2-图片,3-视频',
msg_status TINYINT DEFAULT 1 COMMENT '状态:1-正常,0-已删除',
msg_channel VARCHAR(50) COMMENT '消息所属渠道,用于多系统接入',
extra_info JSON COMMENT '扩展信息,存储JSON格式',
ctime TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
utime TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
INDEX idx_sender_time (sender_id, ctime)
);有几个设计点值得说一下。
msg_id用雪花算法。 不要用自增ID。自增ID在分库分表场景下会有冲突问题,而且自增ID本身会暴露业务量信息。雪花算法生成的ID既是递增的(对索引友好),又能保证全局唯一。
msg_status字段很重要。 上一篇提到过,我们采用软删除策略------删除消息的时候不是真的从数据库里删掉,而是把状态标记为0。这个字段就是干这个用的。为什么要软删除?因为收件箱里存的是消息ID的引用,如果真把消息删了,粉丝收件箱里的引用就变成了悬空引用,处理起来非常麻烦。
extra_info用JSON类型。 这个字段是留给未来的扩展空间用的。比如消息可能需要携带一些额外的元数据------地理位置、@了谁、关联的活动ID等等。这些信息不是每条消息都有,而且格式可能各不相同,用JSON存储最灵活。
索引idx_sender_time。 这是一个联合索引,按发布者ID和创建时间排序。这个索引的使用场景是:查询某个用户发布的消息列表(个人页Timeline),以及读扩散场景下从大V的发件箱拉取消息。这两个场景都需要按sender_id过滤,然后按时间排序。
2. 关注关系表
关注关系表存储用户之间的关注/粉丝关系。这张表的设计有几个容易踩坑的地方。
sql
CREATE TABLE follow_relation (
main_uid BIGINT COMMENT '被关注者ID(博主)',
follower_uid BIGINT COMMENT '关注者ID(粉丝)',
status TINYINT DEFAULT 1 COMMENT '状态:1-正常关注,2-特别关注,0-已拉黑',
hot_follower TINYINT DEFAULT 0 COMMENT '是否活跃粉丝:1-是,0-否',
extra_info JSON COMMENT '扩展信息',
ctime TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '关注时间',
utime TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (main_uid, follower_uid),
INDEX idx_follower (follower_uid)
);联合主键的设计。 用(main_uid, follower_uid)作为联合主键,天然保证了同一对关注关系不会重复插入。同时这个主键也能高效支持"查询某用户的所有粉丝"这个操作------因为主键索引本身就是按main_uid排序的。
status字段不只是关注/取关。 很多人设计关注关系表的时候只存"关注"和"取关"两种状态,但实际上status字段可以承载更多语义。比如"特别关注"------微博里你可以把某些人设为特别关注,他们的消息会优先展示。"拉黑"------虽然拉黑和取关的效果类似(都看不到对方消息),但在业务层面是两个不同的操作,分开存储更合理。
hot_follower字段是大V场景的关键。 上一篇提到过,对大V用户采用读写结合策略时,需要区分热粉丝和冷粉丝。热粉丝走写扩散,冷粉丝走读扩散。
这里有个设计选择:hot_follower是存在关注关系表里,还是单独维护一张热粉丝表?
如果单独维护一张热粉丝表,那查询大V的热粉丝列表很简单,但要判断某个用户是不是某个大V的热粉丝,就需要做一次join或者两次查询。而把hot_follower直接放在关注关系表里,查询的时候只需要一个条件过滤就行了,不需要额外的表。代价是每次更新粉丝的冷热状态时,要更新这张表的一个字段。
考虑到粉丝冷热状态的变更频率不高(通常是根据登录频率定期批量更新的),放在关注关系表里是更划算的选择。
idx_follower索引。 这个索引的作用是支持"查询某用户关注了哪些人"这个操作。注意这个查询方向和主键是反的------主键是"被关注者 -> 粉丝列表",而这个索引是"粉丝 -> 关注列表"。两个方向的查询在Feed流系统中都很常见,所以都需要索引支持。
3. 收件箱设计
收件箱是Feed流系统中最有特色的设计。它不存储在数据库里,而是用Redis的Sorted Set(ZSet)来实现。
为什么用ZSet?因为ZSet有两个特性完美匹配收件箱的需求:
- 每个元素有一个score,可以用来排序------我们用消息的发布时间戳作为score
- 支持按score范围查询------翻页的时候就是按时间范围取数据
收件箱的Key-Value设计如下:
Key: user:{userId}:inbox:{channelId}
Value: {senderId}:{messageId}
Score: 消息发布时间戳(毫秒)举个例子,用户123的收件箱可能长这样:
Key: user:123:inbox:default
Members:
456:1001 -> score: 1716000000000
789:1002 -> score: 1716000060000
456:1003 -> score: 1716000120000
...Value存的是"发送者ID:消息ID"而不是只存消息ID,这是有原因的。后面讲取关逻辑的时候会用到------用户取关了某个人之后,需要从收件箱中过滤掉这个人的所有消息。如果Value里没有senderId,就不知道这条消息是谁发的,过滤就没法做。
channelId是消息渠道标识。如果系统只接入了一个业务,那channelId可以固定为"default"。但如果将来要接入多个业务系统(比如社区动态、活动通知、系统消息等),不同的渠道用不同的收件箱,互不干扰。
用图来表示一下Redis ZSet的结构:

收件箱服务的基本实现如下:
java
public class InboxServiceImpl implements InboxService {
private final RedisTemplate<String, String> redisTemplate;
@Override
public void addMessage(long userId, long messageId, long senderId, long timestamp) {
String key = String.format("user:%d:inbox:default", userId);
String value = String.format("%d:%d", senderId, messageId);
redisTemplate.opsForZSet().add(key, value, timestamp);
}
@Override
public List<MessageRef> getMessages(long userId, String lastMessageId, int pageSize) {
String key = String.format("user:%d:inbox:default", userId);
double maxScore = Double.POSITIVE_INFINITY;
if (lastMessageId != null) {
Double lastScore = redisTemplate.opsForZSet().score(key, lastMessageId);
if (lastScore != null) {
maxScore = lastScore - 1;
}
}
Set<ZSetOperations.TypedTuple<String>> results = redisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, maxScore, 0, pageSize);
List<MessageRef> messageRefs = new ArrayList<>();
if (results != null) {
for (ZSetOperations.TypedTuple<String> tuple : results) {
String value = tuple.getValue();
if (value != null) {
String[] parts = value.split(":");
MessageRef ref = new MessageRef();
ref.setSenderId(Long.parseLong(parts[0]));
ref.setMessageId(Long.parseLong(parts[1]));
ref.setTimestamp(tuple.getScore());
messageRefs.add(ref);
}
}
}
return messageRefs;
}
}这里有个细节需要注意:收件箱里存的是消息ID的引用,不是完整的消息内容。这意味着用户读取Feed流的时候,拿到的是一堆消息ID,还需要回查数据库才能拿到完整的消息内容。
为什么要多这一步回查?上一篇已经解释过了------这样消息的修改和删除就不需要扩散了。回查的时候拿到的是最新版本的数据,修改自然就同步了;删除的消息通过msg_status字段过滤掉就行。
虽然多了一次数据库查询,但好处是巨大的:修改和删除操作从O(粉丝数)的扩散成本降到了零。
发布配置表(可选)
这张表不是Feed流系统必须的,但如果你的系统将来要扩展成消息推送平台,那这张表就很有用了。它控制消息的发布行为------什么时候发、发到哪个渠道、触发条件是什么。
sql
CREATE TABLE publish_config (
send_id BIGINT PRIMARY KEY COMMENT '发布配置ID',
send_type TINYINT COMMENT '发布类型:1-立即发布,2-定时发布,3-周期发布',
send_crontab VARCHAR(100) COMMENT '定时/周期发布的规则,存储crontab表达式',
send_msg_channel VARCHAR(50) COMMENT '推送渠道:站内信、邮件、短信等',
channel VARCHAR(50) COMMENT '配置所属渠道',
send_rule VARCHAR(255) COMMENT '触发规则:如审核通过时触发、活动开始时触发',
extra_info JSON COMMENT '扩展信息',
cuid BIGINT COMMENT '创建者',
ctime TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
utime TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间'
);举个例子,你可以配置一条规则:当某篇内容审核通过的时候,自动给所有关注该作者的用户推送一条站内信。这种场景下,publish_config表就派上用场了。
如果你的系统暂时不需要这么复杂的发布控制,可以先不加这张表,等有需求的时候再扩展也不迟。
面向对象的数据抽象
除了数据库层面的设计,在代码层面也需要对Feed流的核心概念进行抽象。一个好的抽象能让业务代码更清晰,也更容易扩展。
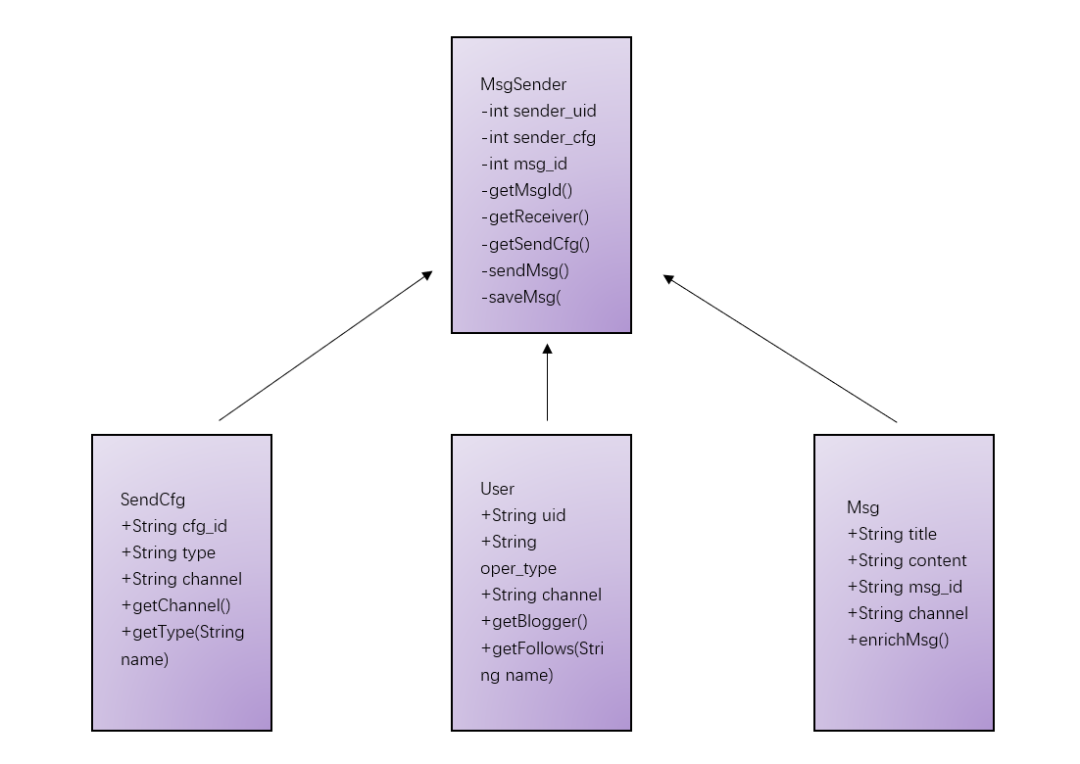
核心的抽象有四个:
消息(Message)。 最基础的数据结构,包含消息标题、内容、附件、类型、渠道等属性。它还需要提供一个"丰富消息内容"的方法------因为收件箱里只存了消息ID,读取的时候需要把消息内容填充完整。
消息发布处理器(MessagePublisher)。 负责消息发布的完整流程。它持有发送用户、发布配置、消息ID等属性,提供获取消息ID、获取接收者、同步消息、保存消息等方法。
用户(User / FeedFetcher)。 在Feed流系统中,用户既是消息的发布者,也是消息的拉取者。作为拉取者,用户需要提供获取关注列表、获取粉丝列表、查询发件箱、查询收件箱等方法。收件箱的查询还包含了过滤逻辑------黑白名单过滤、软删除过滤等。
发布配置(PublishConfig)。 控制消息的发布行为,包括发布渠道和发布方式。
这些抽象不是一成不变的,随着业务的发展可能需要调整。但一开始就把核心概念理清楚,后面扩展的时候会轻松很多。
6. 存储容量规划
最后聊一个实际的问题:存储容量怎么规划。
数据库方面。 消息表是数据量增长最快的表。假设系统有100万日活用户,每人每天平均发布2条消息,那每天新增200万条记录。一年下来就是7亿多条。按每条消息平均1KB计算,大约需要700GB的存储空间。加上索引开销,实际占用可能在1TB左右。这个量级在MySQL里已经需要考虑分库分表了。
Redis方面。 收件箱的容量取决于用户量和关注关系。假设平均每个用户关注50个人,每个被关注者每天发2条消息,那每个用户的收件箱每天新增100条记录。按每条记录50字节计算(senderId:messageId + score),每天新增5KB。100万用户就是每天5GB。Redis的内存成本比较高,所以收件箱数据需要有清理策略------比如只保留最近30天的数据,更早的数据从数据库查询。
这些数字只是估算,实际业务中需要根据用户行为数据来调整。但提前做好容量规划,可以避免上线后手忙脚乱。
7. 小结
这一篇聊了Feed流系统的数据模型和存储设计。核心要点:
- 消息表用雪花算法生成ID,软删除而不是真删除,extra_info预留扩展空间
- 关注关系表用联合主键保证唯一性,hot_follower字段支持大V的冷热粉丝分离
- 收件箱用Redis ZSet实现,Value存"发送者ID:消息ID"而不仅是消息ID,方便后续的取关过滤
- 收件箱只存消息ID引用,完整内容通过回查获取,这样修改和删除就不需要扩散
这些设计决策不是孤立的,它们相互配合,共同支撑起上一篇文章中讨论的读写结合分发策略。
下一篇会进入最核心的部分------发布和读取Feed流的业务流程实现,包括游标分页、软删除与懒删除的具体代码实现。