建模
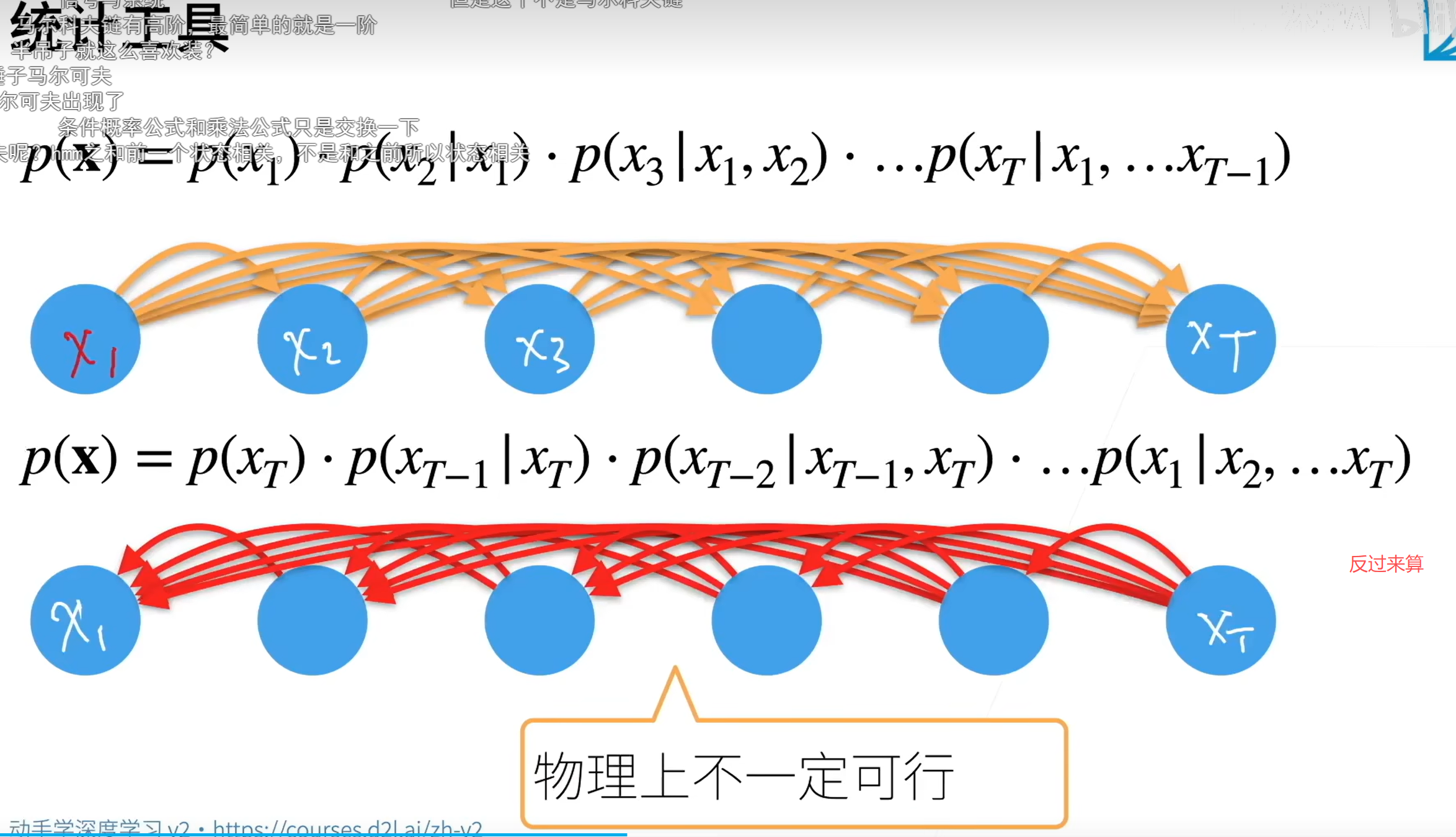
反过来不行是因为可能未来东西是根据之前产生的 过去的是没法改变的
这个不是全概率公式,这个就是一连串先后发生的事件的乘法准则
不是全概率这里就是依次发生并且假定后面发生的和前面所有都有依赖关系
马尔可夫链是当前状态只与前一个状态有关 与历史状态无关

自回归模型: 就是上个状态模型的输出当做下个状态模型的输入,进行迭代
回归模型判断预测对错要引入新的数据集或特征(即label数据),自回归的判断预测对错的数据在这个数据集本身之中
两个方案:
1.不认为与前面所有数据相关 马尔科夫模型

输入是固定长度
2 潜变量模型 用一个变量来表示前面所有时刻数据的信息 rnn就是潜变量模型
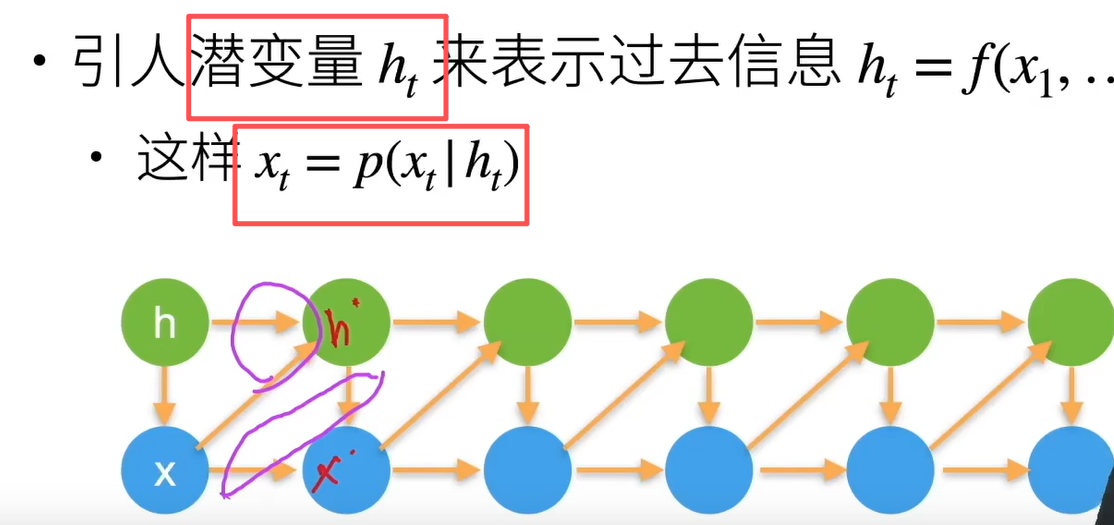
方案A是截断,但是要用到每一个具体的x。而方案B是压缩过去的所有x的信息到h中,不截断。

马尔可夫假设是利用前t个数据来预测下一个数据,而潜变量,是用一个变量来表示前面所有时刻数据的信息 rnn就是潜变量模型
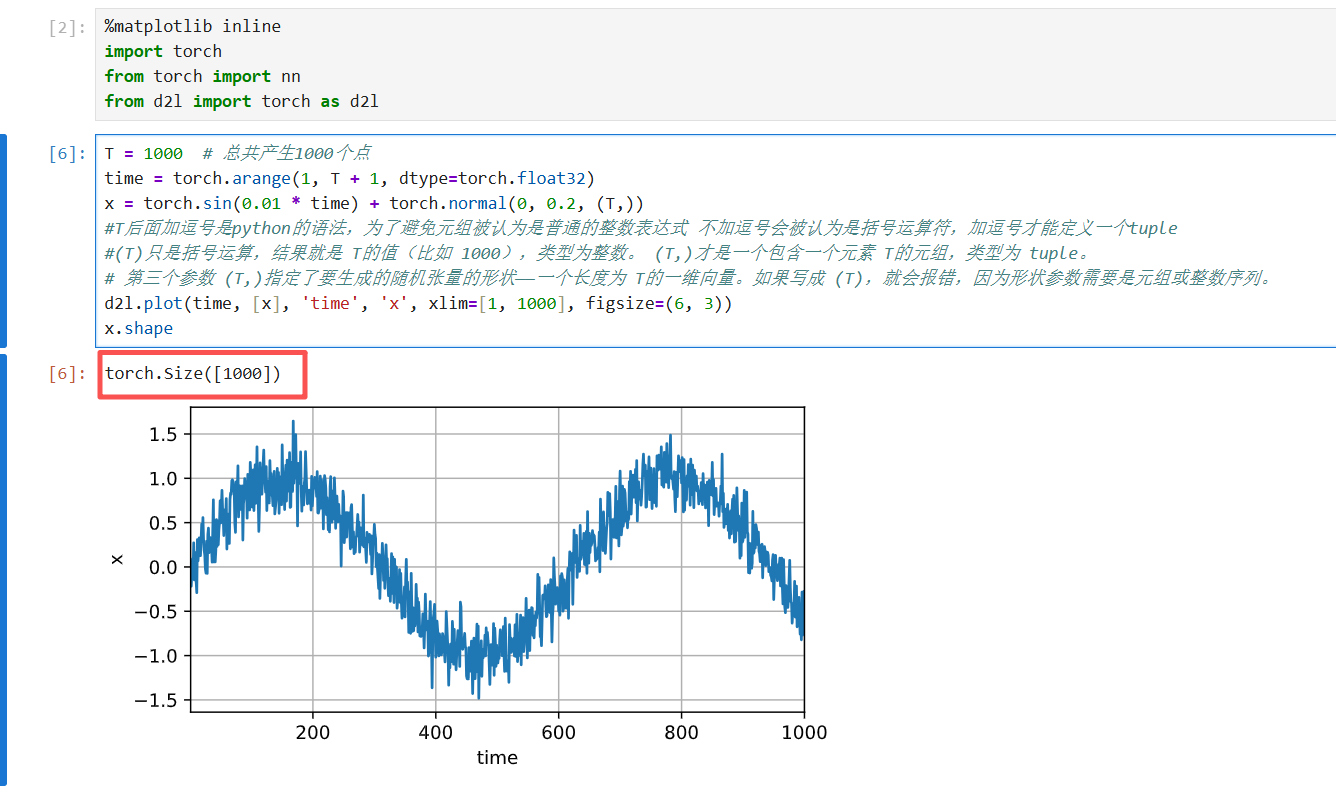
这段代码用于构造一个自回归时间序列预测 的训练数据集。它把前 tau个时间步的值作为特征,下一个时间步的值作为标签。
python
tau = 4 # 滑动窗口大小:用过去 tau 个时间步的值预测下一个值
features = torch.zeros((T - tau, tau)) # 创建特征矩阵,形状:(样本数, 特征数)
# 样本数 = T - tau,每个样本有 tau 个特征
for i in range(tau): # 遍历每个偏移位置 i
features[:, i] = x[i: T - tau + i] # 将 x 中从 i 开始的连续 T-tau 个值赋给第 i 列
# 这样第 t 行的特征就是 x[t], x[t+1], ..., x[t+tau-1]
labels = x[tau:].reshape((-1, 1)) # 标签:从索引 tau 开始到末尾的值,作为列向量
# 第 t 个样本的标签是 x[t+tau]for i in range(tau):
features:, i = xi: T - tau + i
循环填充每一列:
i表示相对偏移(0 到 tau-1)。
xi : T - tau + i是从原始序列 x中取一段连续子序列,长度为 T - tau。
例如:
i=0时,取 x0 : T-tau→ 赋值给 features:, 0,即每个样本的第一个特征(最旧的历史值)。
i=1时,取 x1 : T-tau+1→ 赋值给 features:, 1,即每个样本的第二个特征。
...
i=tau-1时,取 xtau-1 : T-1→ 赋值给 features:, tau-1,即每个样本的最新历史值。
最终,第 t行的特征为:x\[t, xt+1, ..., xt+tau-1]。
labels = xtau:.reshape((-1, 1))
标签是真实的下一个时间步的值:
xtau:从索引 tau开始取到末尾,长度也是 T - tau。
.reshape((-1, 1))将其变为列向量(形状 (T-tau, 1)),与 features的行一一对应。
因此,第 t个样本的标签就是 xt+tau,即紧跟在 featurest最后一个历史值之后的下一个值。

-
T = 10(数据总长度是10,索引从 0 到 9)
-
tau = 3(窗口大小为3,即用3个数预测1个数)
列复制代码:(想不到) 习惯了按行填充反应不过来这里的按列填充
我们来看看代码是如何一步步执行的:
- 准备空间
代码首先执行 features = torch.zeros((T - tau, tau))。
-
计算行数:10−3=7。这意味着我们能做出 7个样本。
-
计算列数:3。每个样本包含 3个特征。
-
此时
features是一个空的 7×3表格。
- 循环填充(核心逻辑)
代码进入 for i in range(tau):也就是 i从 0 跑到 2。
这里的 i代表列的索引 ,同时也代表切片的起始偏移量。
当 i = 0 时(填充第1列)
代码:features[:, 0] = x[i: T - tau + i]
代入数字:features[:, 0] = x[0 : 10 - 3 + 0]→x[0 : 7]
-
操作 :把原序列
x的前7个元素拿出来,填入features的第0列。 -
结果 :这一列是
[x[0], x[1], x[2], x[3], x[4], x[5], x[6]]。 -
含义:这是每个样本里的"最老的那个值"。
当 i = 1 时(填充第2列)
代码:features[:, 1] = x[i: T - tau + i]
代入数字:features[:, 1] = x[1 : 10 - 3 + 1]→x[1 : 8]
-
操作 :把原序列
x从索引1开始的7个元素拿出来,填入features的第1列。 -
结果 :这一列是
[x[1], x[2], x[3], x[4], x[5], x[6], x[7]]。 -
含义:这一列比上一列整体向右滑动了1位,是"中间值"。
当 i = 2 时(填充第3列)
代码:features[:, 2] = x[i: T - tau + i]
代入数字:features[:, 2] = x[2 : 10 - 3 + 2]→x[2 : 9]
-
操作 :把原序列
x从索引2开始的7个元素拿出来,填入features的第2列。 -
结果 :这一列是
[x[2], x[3], x[4], x[5], x[6], x[7], x[8]]。 -
含义:这是每个样本里的"最新值"。
- 纵向拼接的效果
现在我们把这三列拼起来看,就能得到图中的表格:
| 行号 (样本) | 第0列 (i=0) | 第1列 (i=1) | 第2列 (i=2) | 组合后的 Features | Labels (真实值) |
|---|---|---|---|---|---|
| 0 | x0 | x1 | x2 | **x0, x1, x2** | x3 |
| 1 | x1 | x2 | x3 | **x1, x2, x3** | x4 |
| 2 | x2 | x3 | x4 | **x2, x3, x4** | x5 |
| ... | ... | ... | ... | ... | ... |
| 6 | x6 | x7 | x8 | **x6, x7, x8** | x9 |
python
batch_size, n_train = 16, 600
# 只有前n_train个样本用于训练
train_iter = d2l.load_array((features[:n_train], labels[:n_train]),
batch_size, is_train=True)
# 初始化网络权重的函数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
# 一个简单的多层感知机
def get_net():
net = nn.Sequential(nn.Linear(4, 10),
nn.ReLU(),
nn.Linear(10, 1))
net.apply(init_weights)
return net
# 平方损失。注意:MSELoss计算平方误差时不带系数1/2
loss = nn.MSELoss(reduction='none')
def train(net, train_iter, loss, epochs, lr):
trainer = torch.optim.Adam(net.parameters(), lr)
for epoch in range(epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.sum().backward()
trainer.step()
print(f'epoch {epoch + 1}, '
f'loss: {d2l.evaluate_loss(net, train_iter, loss):f}')
net = get_net()
train(net, train_iter, loss, 5, 0.01)
单步预测
onestep_preds = net(features)
d2l.plot([time, time[tau:]],
[x.detach().numpy(), onestep_preds.detach().numpy()], 'time',
'x', legend=['data', '1-step preds'], xlim=[1, 1000],
figsize=(6, 3))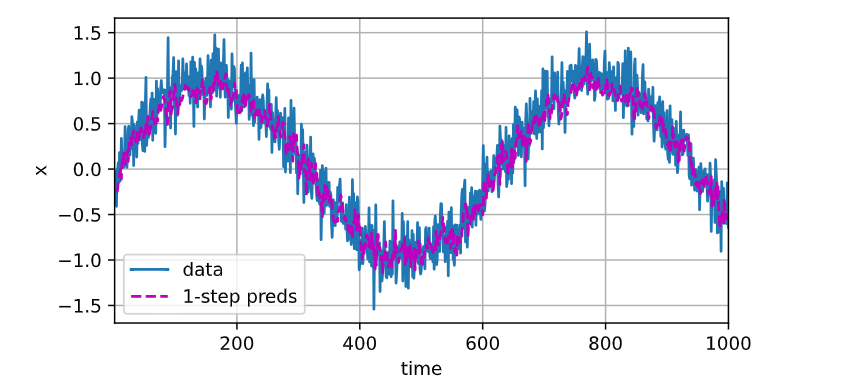
reduction='none'中的 none表示不进行任何聚合操作,直接返回每个样本的单独损失值。
具体来说,nn.MSELoss默认计算的是均方误差(MSE),其 reduction参数有三种取值:
| 参数值 | 行为 | 输出形状 |
|---|---|---|
'mean'(默认) |
对所有样本的损失求平均值 | 标量 |
'sum' |
对所有样本的损失求和 | 标量 |
'none' |
保留每个样本的原始损失,不做聚合 | 与输入形状相同的张量(如 (batch_size,)) |
loss = nn.MSELoss(reduction='none')意味着当你调用 loss(predictions, targets)时,会得到一个与 predictions形状相同的张量,其中每个元素是对应位置的平方误差,而不是一个单一的数值。这样做通常是为了后续对每个时间步的损失进行独立分析或加权平均。
设置 reduction='none'后,loss(net(X), y)返回的是一个与输入形状相同的张量 ,每个元素是单个样本的平方误差。此时必须手动调用 .sum()或 .mean()才能得到一个标量用于反向传播。这里代码与直接用 reduction='sum'效果等价(因为后面加了 .sum())。
onestep_preds.detach().numpy()是什么意思?
这行代码的作用是将 PyTorch 张量转换为 NumPy 数组,同时断开计算图的连接,以便用于绘图。
-
.detach():onestep_preds是网络输出的张量,它仍然连接着计算图(包含梯度信息)。如果直接.numpy()会报错(因为带梯度的张量不能直接转 NumPy),或者在某些版本中虽然能转但会保留不必要的梯度记录。.detach()返回一个新的张量,与当前计算图分离,不再具有梯度信息。 -
.numpy():将 PyTorch 张量转换为 NumPy 数组,因为
d2l.plot底层可能使用 Matplotlib,它只能接受 NumPy 数组或 Python 列表。
多步预测:

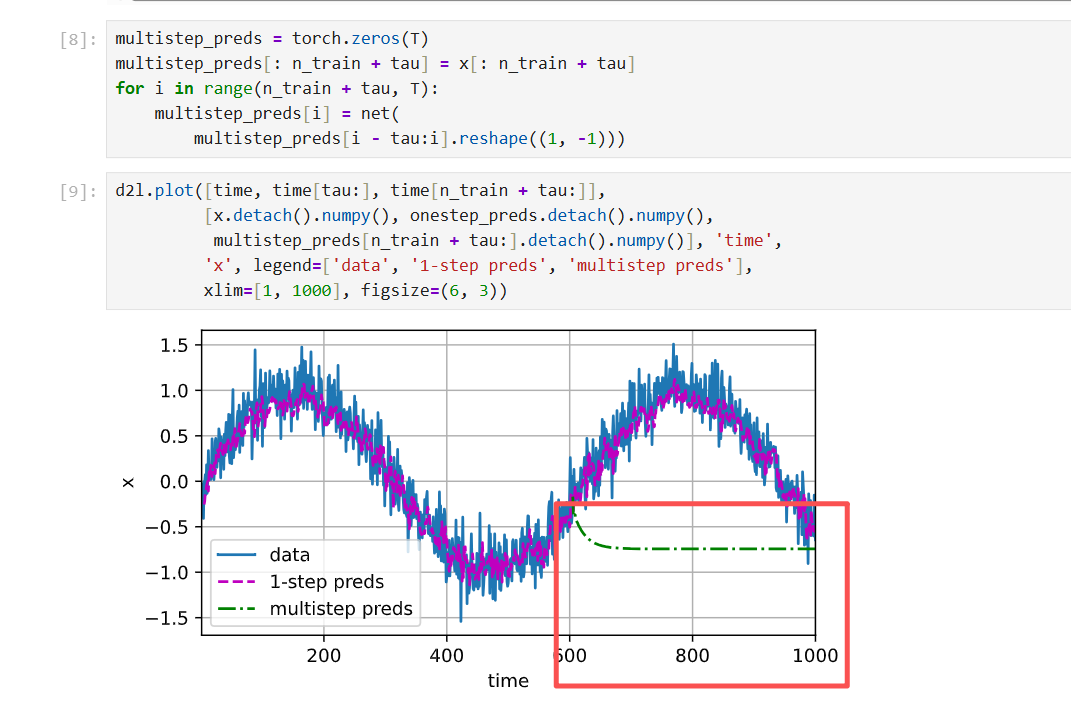
从600开始不给他数据了,自己去预测,结果就g了(就是比如 123 ->4 之后再用4作为自己的输入,234->5 ...逐渐越来越离谱 误差累计) 例如,未来小时的天气预报往往相当准确, 但超过这一点,精度就会迅速下降
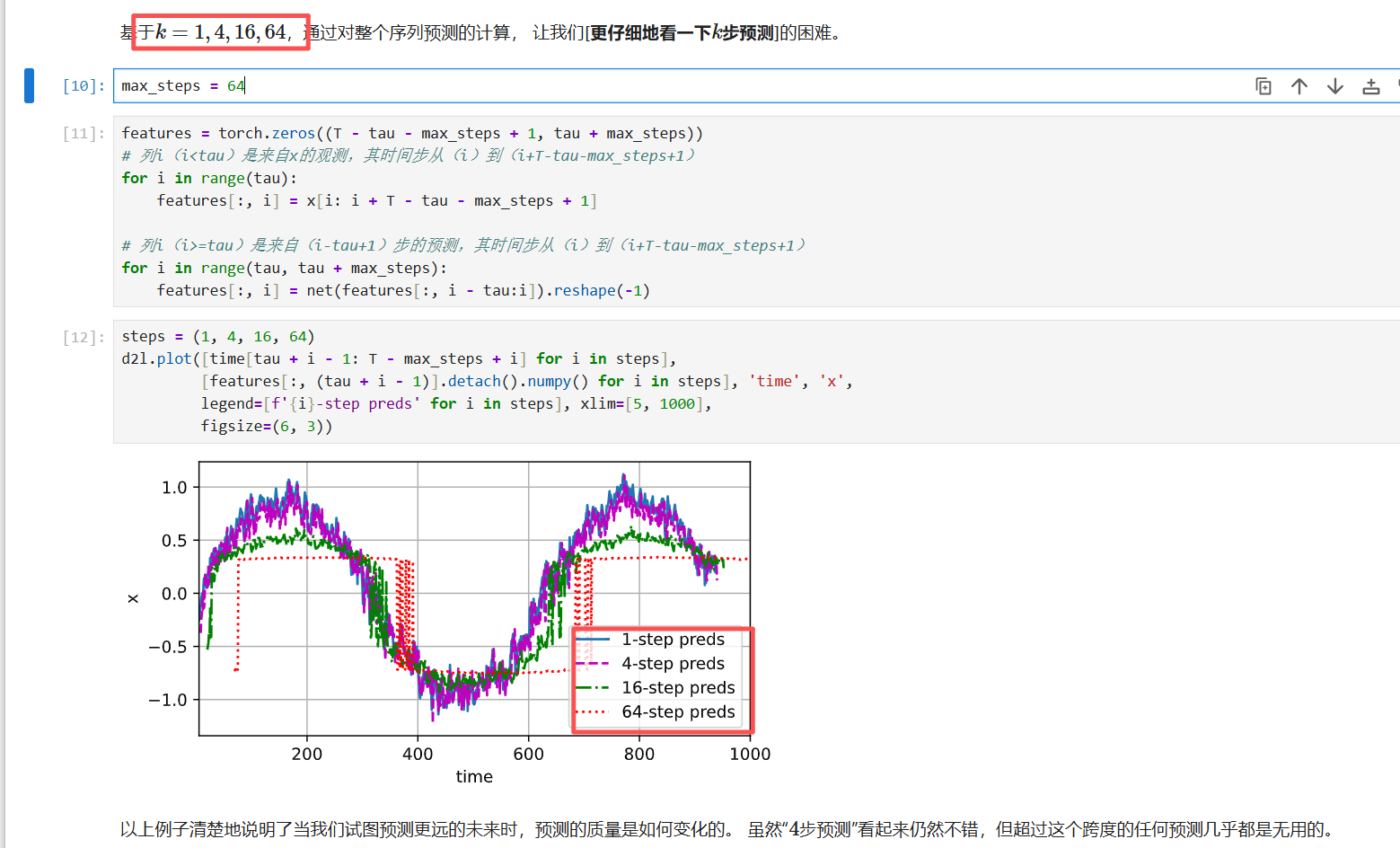
根据每个样本给定4个数据,然后预测未来step步内的数据变化,比如1步的话,预测数据就存在features : , 4 4步的预测值存在features : , 7
意思是1-step:就是最开始的结果,最好的,4step就是给你四个数据,预测接下来四步 16step:给你四个数据,预测接下来16步。。