很多团队在做实时通知、任务进度推送、AI 流式输出、监控事件订阅时,都会遇到一个非常实际的问题:一个 Java 服务到底可以支撑多少个 SSE 连接?有人说几千就差不多了,有人说几万没问题,也有人直接把 WebSocket 的经验套过来。但如果不看线程模型、内存占用、连接保持方式、消息频率和网关配置,只给一个固定数字,基本都不可靠。
SSE,全称 Server-Sent Events,是一种基于 HTTP 的服务端单向推送机制。客户端建立连接后,服务端可以持续向客户端写入事件流。它比轮询更省请求,比 WebSocket 更简单,天然兼容 HTTP 语义,适合服务端向浏览器或客户端持续推送文本事件。但它的代价也很明显:每个在线用户都会占用一个长连接,连接越多,对服务端文件描述符、内存、线程调度、网络缓冲区、负载均衡和超时策略的要求越高。
所以,评估一个 Java 服务能支撑多少 SSE 连接,不能只问"Java 能不能扛住",而要拆成几个问题:连接是阻塞模型还是异步模型?每个连接占多少内存?每秒推送多少消息?心跳间隔是多少?是否经过网关和负载均衡?机器的文件描述符、端口、网卡、内核参数是否足够?应用是否做了连接清理和背压控制?只有这些问题回答清楚,容量数字才有意义。
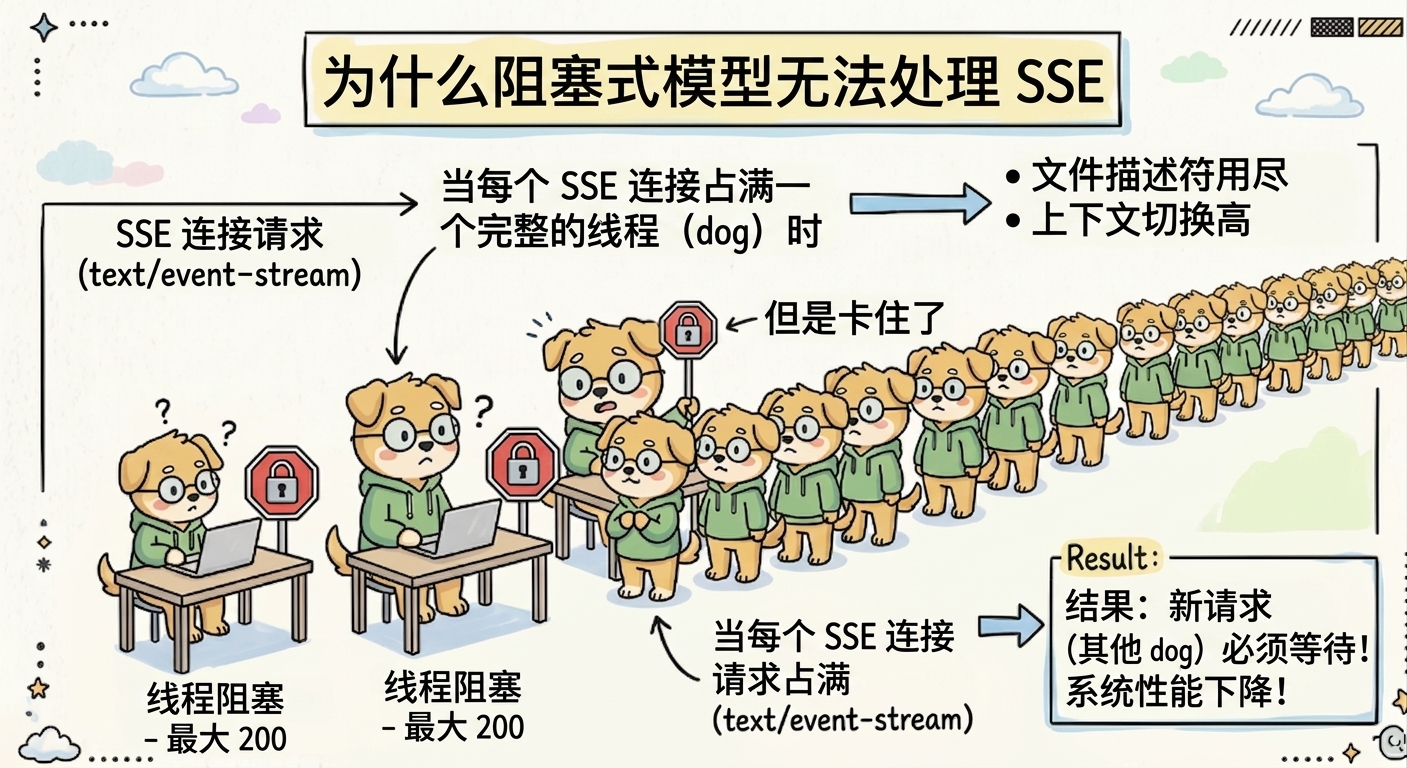
为什么阻塞式模型无法处理 SSE
文章目录
-
- 一、先给结论:没有固定答案,但可以估算
- [二、SSE 连接到底占用什么资源](#二、SSE 连接到底占用什么资源)
- [三、阻塞模型为什么不适合大量 SSE](#三、阻塞模型为什么不适合大量 SSE)
- 四、异步模型下的关键瓶颈
- 五、如何做容量估算
- [六、Tomcat、Jetty、Undertow、Netty 的差异](#六、Tomcat、Jetty、Undertow、Netty 的差异)
- 七、生产环境容易忽略的外部限制
- 八、压测应该怎么做
- [九、Java 服务的调优清单](#九、Java 服务的调优清单)
- 十、一个实用的容量评估示例
- 十一、不要只追求单机连接数
- 十二、结语:用数据回答容量问题
一、先给结论:没有固定答案,但可以估算
如果只是给一个经验范围,可以这样理解:
在传统阻塞 Servlet 写法下,如果每个 SSE 连接长期占用请求线程,一个 Java 实例通常很难稳定支撑大量连接,几百到一两千就可能开始遇到线程数、上下文切换和内存压力。这个模型不适合大规模 SSE。
在 Servlet 3.0 异步、Spring MVC 的 SseEmitter、ResponseBodyEmitter 或类似异步响应模型下,请求线程不会一直被占住,连接主要消耗文件描述符、连接对象、缓冲区和少量调度资源。合理调优后,单实例支撑几千到一两万个空闲或低频 SSE 连接是比较常见的目标。
在 Netty、Spring WebFlux、Undertow 等事件驱动模型下,如果业务逻辑没有阻塞、消息频率较低、内存和系统参数足够,单实例支撑数万级连接是可以设计和压测验证的。但这并不意味着任何 WebFlux 项目都天然能支撑数万连接。只要代码里混入阻塞数据库调用、同步远程接口或大对象缓存,容量就会迅速下降。
因此,更准确的说法是:一个 Java 服务能支撑多少 SSE 连接,主要取决于连接模型、单连接内存、消息频率、网络带宽、系统参数和业务代码阻塞程度,而不是取决于 Java 语言本身。
二、SSE 连接到底占用什么资源
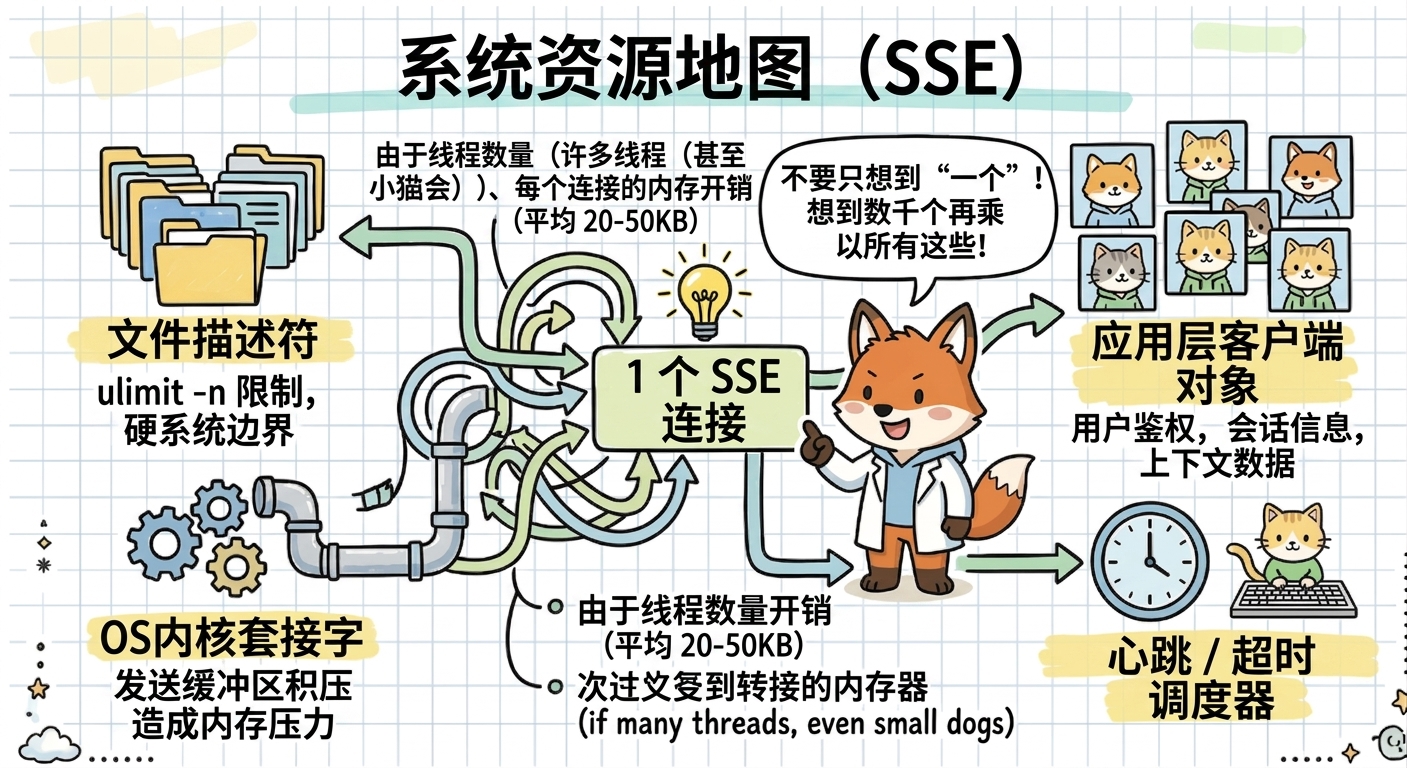
SSE 连接占用的关键资源
一个 SSE 连接本质上是一个保持打开状态的 HTTP 响应。客户端请求一个接口,服务端返回 text/event-stream,然后不立即关闭连接,而是不断写入类似下面的内容:
text
event: progress
data: {"percent":42}从资源角度看,每个连接至少会占用以下几类资源。
第一是文件描述符。Linux 中 socket 是文件描述符,连接数上来后,ulimit -n、进程最大文件数和系统级文件数都会成为硬限制。如果默认值只有 1024 或 4096,应用还没到业务瓶颈就会被系统拦住。
第二是内核 socket 缓冲区。每条 TCP 连接都有发送和接收缓冲区,虽然内核会动态调整,但连接数很大时,这部分内存不能忽略。特别是客户端网络慢、服务端持续写消息时,发送缓冲区可能积压,进一步放大内存压力。
第三是应用层连接对象。Java 框架会为每个连接维护请求、响应、上下文、回调、订阅关系、用户标识、心跳状态等对象。如果业务还把用户权限、会话信息、大量上下文数据挂在连接对象上,单连接内存会明显增大。
第四是线程或事件循环资源。阻塞模型下,连接可能占住工作线程;异步模型下,连接不长期占用请求线程,但写事件、心跳、超时清理仍需要调度线程或事件循环处理。
第五是网络带宽。很多容量评估只看连接数,不看消息频率,这是常见误区。1 万个连接如果每 30 秒发一次心跳,压力很低;如果每秒每个连接推送 1KB 数据,出口带宽和序列化开销会立刻成为瓶颈。
三、阻塞模型为什么不适合大量 SSE
最容易踩坑的写法,是把 SSE 当成普通 HTTP 请求处理,然后在请求线程里循环等待、写数据、睡眠、再写数据。这样的代码逻辑直观,但容量非常差。
传统 Tomcat 工作线程是有限的,比如最大线程数设置为 200。普通短请求处理完就释放线程,而长连接请求如果一直不结束,线程就会被长时间占用。200 个 SSE 连接就可能占满工作线程,新的普通接口请求也会排队,最终表现为整个服务变慢甚至不可用。
即使把最大线程数调到几千,也不是好办法。线程本身有栈内存,线程越多,上下文切换越频繁,调度成本越高。大量线程长期阻塞等待,只是把连接压力转移成线程压力,并没有真正解决问题。
所以,SSE 的第一条工程原则是:不要让每个连接长期占用一个业务线程。要么使用 Servlet 异步能力,要么使用事件驱动框架,要么把连接层和业务计算层拆开。
在 Spring MVC 中,SseEmitter 是常见选择。请求进入后返回一个 emitter,对应响应保持打开,后续由其他线程或消息回调向 emitter 写入事件。请求线程可以释放,连接生命周期由 emitter 管理。这样单实例容量会比阻塞循环好很多。
但 SseEmitter 也不是无限容量。它仍然需要处理超时、异常、连接关闭、发送失败、慢客户端和内存释放。如果 emitter 放进一个全局 Map 后从不清理,连接断开后对象还在,容量迟早被内存泄漏打穿。
四、异步模型下的关键瓶颈
当连接不再占用请求线程后,瓶颈通常会转移到文件描述符、内存、消息分发和慢客户端处理。
文件描述符是最直接的限制。假设一个 Java 进程要支撑 2 万条 SSE 连接,除了这些连接本身,还要考虑日志文件、数据库连接、RPC 连接、配置中心连接、监控采集连接等。进程可打开文件数至少要明显高于目标连接数,不能刚好等于目标值。
内存需要按单连接估算。假设每个连接在应用层平均占 20KB,2 万连接就是约 400MB;如果平均占 50KB,就是约 1GB;如果业务对象设计粗糙,单连接挂了几百 KB 的上下文,连接数上来后很快会触发频繁 GC。
消息分发也很关键。很多系统会维护 userId -> emitter 或 topic -> emitters 的映射。推送时如果遍历大量连接、同步串行发送,单次广播可能拖慢整个服务。更合理的方式是按主题分组、异步投递、限制单次批量大小,并对失败连接及时移除。
慢客户端是 SSE 的隐形杀手。某些客户端网络差、读取慢,服务端写入会变慢或缓冲积压。如果没有超时、队列上限和断开策略,一个慢客户端可能占用过多内存。生产系统通常需要为每个连接设置待发送队列上限,超过阈值就丢弃低优先级事件或断开连接。
五、如何做容量估算
容量估算可以从一个简单公式开始:
text
可支撑连接数 = min(文件描述符上限, 内存可承载连接数, 网络可承载连接数, 框架/线程模型可承载连接数, 业务处理能力)文件描述符上限比较容易计算。假设进程 nofile 设置为 100000,预留 20000 给其他资源和安全余量,那么连接数上限可以先按 80000 估算。但这只是理论上限,不代表业务能承受。
内存估算可以这样做:先压测 1000、5000、10000 条空闲连接,观察堆内存、非堆内存、直接内存和进程 RSS 的增长斜率。比如从 1000 到 10000 连接,RSS 增加了 450MB,则粗略单连接成本约 50KB。再结合机器可用内存和 GC 目标,就能估算合理连接数。
网络估算要看消息频率。假设 2 万连接,每 30 秒一次心跳,每次 20 字节,心跳带宽几乎可以忽略。但如果每个连接每秒推送 1KB 数据,就是约 20MB/s,折合 160Mbps,还没算协议开销、TLS、重传和峰值。若消息是 10KB,压力会放大十倍。
业务处理能力则取决于事件来源和加工逻辑。如果每条推送都要查数据库、调用外部接口、做复杂权限计算,那么瓶颈可能根本不在 SSE 连接,而在后端依赖。SSE 层应该尽量接收已经加工好的事件,避免在发送路径做重计算。
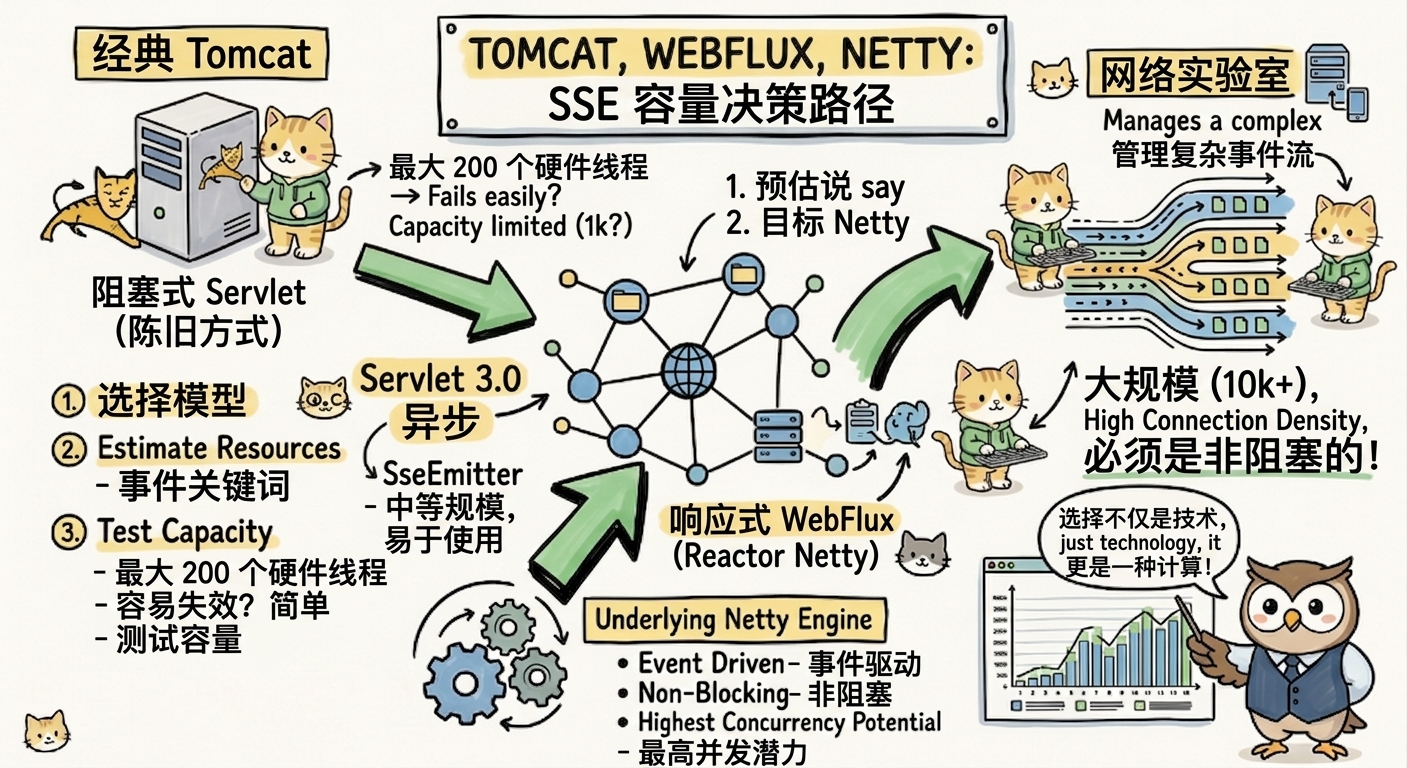
不同 Web 容器处理 SSE 的差异
六、Tomcat、Jetty、Undertow、Netty 的差异
Tomcat 可以支撑 SSE,但要正确使用异步能力,并调好连接数、线程池、超时和系统参数。对于中等规模场景,例如几千到一两万低频连接,Spring MVC + SseEmitter 经过压测和调优是可以落地的。
Jetty 对异步 HTTP 和长连接支持也比较成熟,在一些长连接场景中表现稳定。它的线程策略和连接管理方式适合做细粒度调优,但最终容量仍然取决于应用代码和部署参数。
Undertow 采用基于 XNIO 的架构,适合高并发 I/O 场景。它在连接管理和非阻塞处理上有优势,但如果上层业务阻塞,同样会把优势抵消。
Netty 是事件驱动网络框架,适合高连接数、高并发 I/O 的场景。Spring WebFlux 默认可基于 Reactor Netty 运行,理论上更适合大规模 SSE。但 WebFlux 的前提是整条链路尽量非阻塞。如果 Controller 里调用阻塞 JDBC、同步 HTTP 客户端,事件循环被阻塞后,容量会大幅下降。
因此,框架选择不是唯一答案。小到中等规模可以用 Spring MVC 异步模型,追求更高连接密度和更强背压能力时,可以考虑 WebFlux/Netty。但无论哪种技术栈,都必须通过压测验证。
七、生产环境容易忽略的外部限制
SSE 是 HTTP 长连接,很多外部组件会影响它。
第一是负载均衡超时。Nginx、Ingress、API Gateway、云负载均衡通常都有空闲超时。如果服务端长时间不发送数据,连接可能被中间层断开。因此 SSE 通常需要心跳,例如每 15 到 30 秒发送一次注释行:
text
: ping第二是代理缓冲。有些代理默认会缓冲响应,导致事件不能及时到达客户端。Nginx 场景下经常需要关闭响应缓冲,并配置合适的 proxy_read_timeout。
第三是浏览器连接数限制。浏览器对同域名并发连接数有限制,HTTP/1.1 下尤其明显。如果一个页面同时打开多个 SSE,可能受到浏览器限制。HTTP/2 可以缓解部分问题,但服务端和网关要完整支持。
第四是 TLS 成本。SSE 长连接减少了重复握手,但大量连接建立时仍会带来 TLS 握手压力。突发重连场景下,CPU 可能被握手和认证打满。
第五是重连风暴。服务重启、网络抖动、网关切换后,大量客户端可能同时重连。如果客户端没有随机退避,服务端会瞬间承受连接洪峰。生产客户端应设置指数退避和随机抖动。
八、压测应该怎么做
压测 SSE 不能只测接口 QPS,而要测连接生命周期。
第一阶段测空闲连接容量。逐步建立 1000、5000、10000、20000 条连接,保持心跳,观察 CPU、内存、GC、文件描述符、线程数、网络连接状态和错误率。这个阶段回答"服务能不能挂住这些连接"。
第二阶段测低频推送。比如每个连接每 30 秒、10 秒、5 秒接收一条小消息,观察延迟、失败率、发送队列积压和内存增长。这个阶段回答"服务能不能稳定推送"。
第三阶段测广播和热点主题。很多业务不是均匀推送,而是某个主题下有大量订阅者。压测要模拟热点事件,观察一次广播对 CPU、队列和延迟的影响。
第四阶段测异常场景。包括客户端突然断开、网络慢、服务重启、网关超时、下游消息堆积、客户端集体重连。长连接系统的稳定性往往不是败在正常路径,而是败在异常路径。
压测工具可以使用自研脚本、Gatling、wrk 扩展、k6、JMeter 插件或专门的长连接压测工具。关键是工具本身也要能支撑足够多连接,否则瓶颈可能在压测机而不是服务端。
九、Java 服务的调优清单
系统参数方面,先检查 ulimit -n、进程最大文件数、系统文件数、TCP backlog、端口范围、TIME_WAIT 策略等。目标连接数越高,越不能使用默认参数。
JVM 方面,关注堆大小、直接内存、GC 暂停、线程数和对象分配速率。SSE 连接对象应尽量轻量,不要把大上下文挂在连接上。发送事件时避免频繁创建大字符串和临时对象。
应用设计方面,连接注册和清理必须可靠。onCompletion、onTimeout、onError 都要移除连接。用户多端登录、重复连接、连接替换也要有明确策略。
心跳方面,不要太频繁,也不能超过中间层超时。常见取值是 15 到 30 秒,但最终要根据网关和业务要求确定。
消息队列方面,建议把事件生产和连接发送解耦。事件进入内存队列或消息通道后,由发送层按连接状态投递。队列要有上限,不能无限堆积。
部署方面,不要把所有连接压到单实例。SSE 更适合水平扩展,通过负载均衡分摊连接。若需要按用户定向推送,要解决连接路由问题,例如使用一致性哈希、连接注册中心、消息总线或按实例广播再本地过滤。
十、一个实用的容量评估示例
假设有一台 4 核 8GB 的机器,运行一个 Spring MVC 异步 SSE 服务。业务场景是任务进度和通知推送,平均每个连接 30 秒心跳一次,每分钟收到 1 到 2 条业务事件,事件体小于 1KB。
如果实现正确,连接对象轻量,nofile 调到 100000,网关超时和心跳配置合理,那么单实例先以 5000 到 10000 连接作为压测目标比较稳妥。压测通过后,再尝试 20000 连接,并观察 RSS、GC、发送延迟和断连率。
如果同样机器上每个连接每秒都推送消息,或者每次推送都要查库计算,那么目标就要大幅下调。也许连接数本身还能挂住,但业务处理和网络发送已经无法满足延迟要求。
如果换成 8 核 16GB,并使用 WebFlux/Netty,业务链路完全非阻塞,消息频率较低,单实例挑战数万连接是合理方向。但是否能稳定运行,仍然必须以压测数据为准。
十一、不要只追求单机连接数
很多容量讨论会陷入一个误区:一定要证明单个 Java 服务能支撑多少连接。实际上,生产架构更重要的是整体稳定性。
单机连接数越高,实例故障时影响越大。一个实例挂了,如果上面有 5 万连接,客户端集体重连会给系统造成巨大冲击。适当降低单实例连接密度,通过更多实例分摊,反而更稳。
另外,SSE 通常不是核心业务计算层,而是事件分发层。把连接层独立部署,可以避免长连接影响普通接口。对于规模较大的系统,可以考虑独立的推送服务,业务系统只负责产生事件,推送服务负责连接管理和分发。
最终目标不是把单机连接数压到极限,而是在成本、稳定性、故障半径和运维复杂度之间找到平衡。
十二、结语:用数据回答容量问题
"1 个 Java 服务可以支持多少 SSE 连接"没有万能答案。阻塞模型可能几百到一两千就吃紧;异步 Servlet 模型在合理调优后可以支撑几千到一两万低频连接;事件驱动模型在非阻塞链路和充足资源下可以挑战更高连接数。但这些都只是方向,不是承诺。
真正可靠的做法,是先选对连接模型,再估算文件描述符、内存、带宽和消息频率,然后用贴近真实业务的压测验证。上线后持续监控连接数、断连率、发送延迟、队列积压、GC、RSS 和网关状态。只有这样,容量数字才不是拍脑袋,而是可以解释、可以复现、可以迭代的工程结论。