第8期:HashMap------为什么JDK 7扩容会死循环,JDK 8又是怎么修好的
一、面试真题引入
"HashMap 在 JDK 1.7 中,多线程并发扩容为什么会导致 CPU 100%?"
听到这个问题,很多同学脑子里是这样的反应:
"HashMap 不是日常用得挺好吗?put 进去 get 出来,怎么就 CPU 100% 了?"
"多线程用 HashMap?不是应该用 ConcurrentHashMap 吗?"
"扩容?什么扩容?怎么就死循环了?"
三个问题,层层递进,刚好对应面试官想考察的三个层次:
| 层次 | 面试官潜台词 | 你需要的知识 |
|---|---|---|
| 第一层 | "你知道 HashMap 的底层数据结构吗?O(1) 的查询是怎么做到的?" | 哈希函数、桶下标计算、哈希冲突解决 |
| 第二层 | "你知道 JDK 1.7 的扩容机制有什么缺陷吗?为什么并发时会出事?" | 头插法 transfer()、环形链表形成过程 |
| 第三层 | "你知道怎么解决这个问题吗?ConcurrentHashMap 做了什么?" | CAS + synchronized、分段锁 → 桶级锁演进 |
这三个问题像洋葱一样,一层比一层深。今天这期博客,我们就一层一层剥开,把 HashMap 线程不安全问题彻底讲清楚。
今天你会学到:
- HashMap 哈希函数和桶下标计算的底层原理
- JDK 1.7 头插法扩容为什么会形成环形链表(附完整推导步骤)
- JDK 1.8 尾插法如何修复死循环,以及为什么依然线程不安全
- ConcurrentHashMap 从分段锁到 CAS + synchronized 的演进之路
- 手写一个简易 HashMap,再模拟一个死循环场景
- 面试中关于 HashMap 的连环追问,以及怎么答才能让面试官点头
先记住一句话:HashMap 的线程不安全问题,不是"不小心写了个 bug",而是头插法这种设计,在并发场景下存在结构性缺陷。
带着这个认知,我们从哈希表最基本的原理开始。
二、底层的时空解构与源码透视
2.1 哈希函数:从 hashCode() 到桶下标
HashMap 之所以能以 O(1) 的时间复杂度完成查询,核心在于哈希函数。整个过程分三步:
key.hashCode() → 扰动函数 → (n - 1) & hash → 桶下标第一步:hashCode()
每个 Java 对象都有一个 hashCode() 方法,返回一个 int 值(32 位)。比如 "apple".hashCode() 可能返回 93029210。
第二步:扰动函数
直接拿 hashCode 的高位和低位参与运算太"浪费"------HashMap 的数组长度 n 通常远小于 2^32,如果只取低几位,高位的特征就全丢了。JDK 1.8 的扰动函数长这样:
java
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}把 hashCode 的高 16 位和低 16 位做异或,让高位也参与进来,降低哈希碰撞的概率。
第三步:取模运算
计算出桶下标。这里有个经典优化:用 (n - 1) & hash 替代 hash % n。因为 HashMap 的容量 n 一定是 2 的幂,n - 1 二进制全是 1,按位与等价于取模,但位运算速度远快于取模运算。
举个例子:n = 16,n - 1 = 15(二进制 0000 1111),hash = 18(二进制 0001 0010),(n - 1) & hash = 0000 0010 = 2,即放在下标为 2 的桶里。
为什么容量必须是 2 的幂? 如果 n 不是 2 的幂,
n - 1的二进制就会有 0 位,导致某些桶永远无法被定位,哈希分布不均匀。
2.2 哈希冲突:三种方案的递进
不同的 key 算出相同的桶下标,这叫哈希冲突。三种解决方案层层递进:
| 方案 | 思路 | 时间复杂度(最坏) | 代表 |
|---|---|---|---|
| 线性探测 | 冲突了就往后找下一个空位 | O(n) | ThreadLocal.ThreadLocalMap |
| 链表法 | 每个桶挂一个链表,冲突就追加 | O(n) | JDK 1.7 HashMap |
| 链表 + 红黑树 | 链表太长就转红黑树 | O(log n) | JDK 1.8 HashMap |
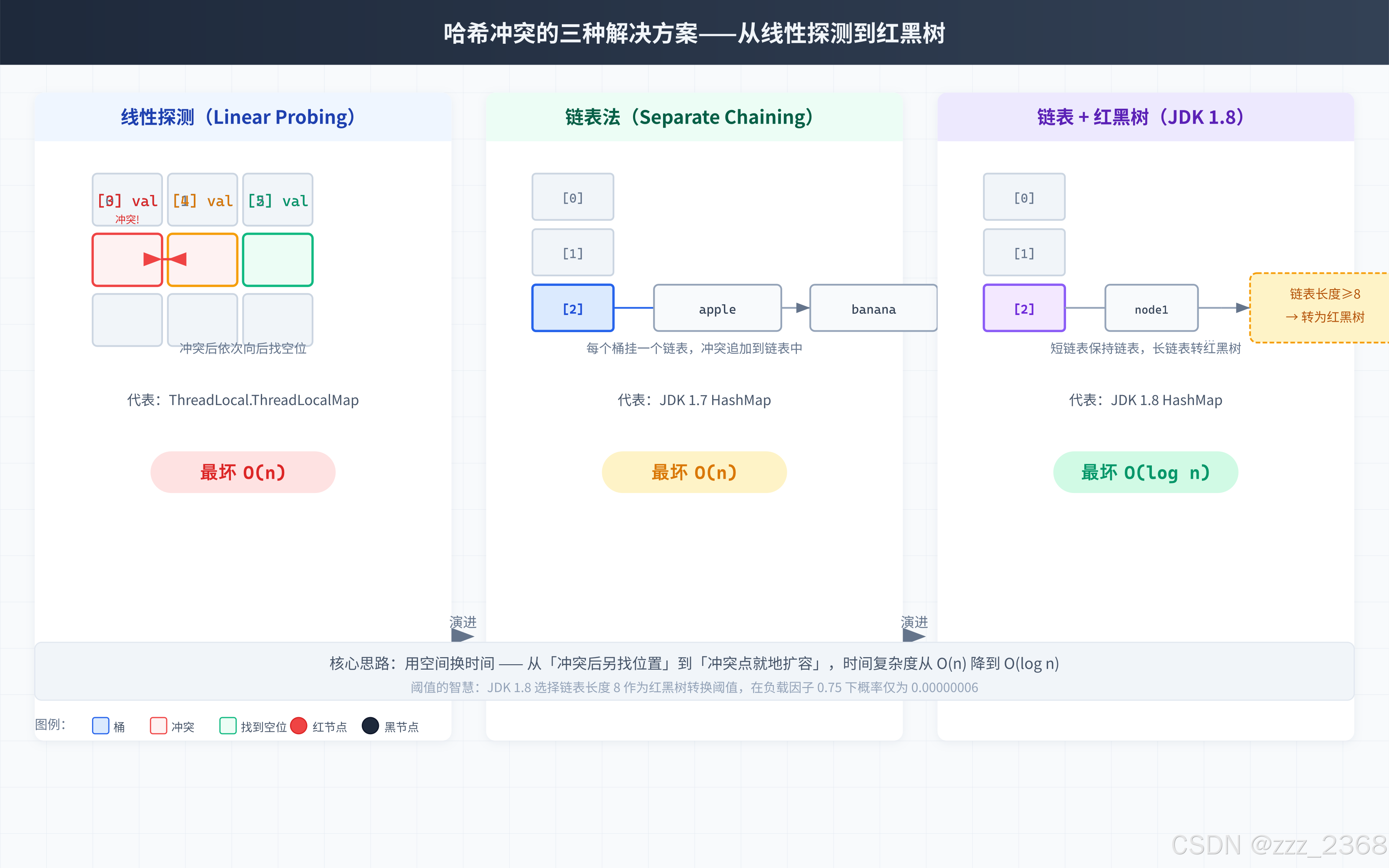
JDK 1.7:纯链表法
每个桶(bucket)是一个 Entry 链表的头节点。发生冲突时,新节点直接插入链表头部(头插法)。结构如下:
数组: [0] → [1] → [2] → [3] → ... → [15]
↓
Entry("key1", v1)
↓
Entry("key2", v2)JDK 1.8:链表 + 红黑树
当链表长度 ≥ 8 且 数组长度 ≥ 64 时,链表转为红黑树;当红黑树节点数 ≤ 6 时,退化为链表。
为什么是 8 和 6? 中间留一个 7 的缓冲,避免在阈值附近频繁转换带来的性能开销。如果定为 7 退链表、8 转红黑树,那在阈值边缘反复 put/remove 会导致链表和红黑树之间频繁切换------每次转换都要重建节点结构,严重消耗性能。留出 7 这个缓冲区,就像阻尼器一样,让状态切换变"钝"。
java
// JDK 1.8 HashMap 源码(简化)
static final int TREEIFY_THRESHOLD = 8; // 转红黑树阈值
static final int UNTREEIFY_THRESHOLD = 6; // 退化为链表阈值
static final int MIN_TREEIFY_CAPACITY = 64; // 最小树化容量
final V putVal(int hash, K key, V value, ...) {
// ...
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); // 转红黑树
// ...
}2.3 JDK 1.7 扩容机制:头插法的隐患
什么时候扩容?
当 size >= capacity * loadFactor(默认 16 × 0.75 = 12)时触发 resize()。新容量为原来的 2 倍。
怎么扩容?
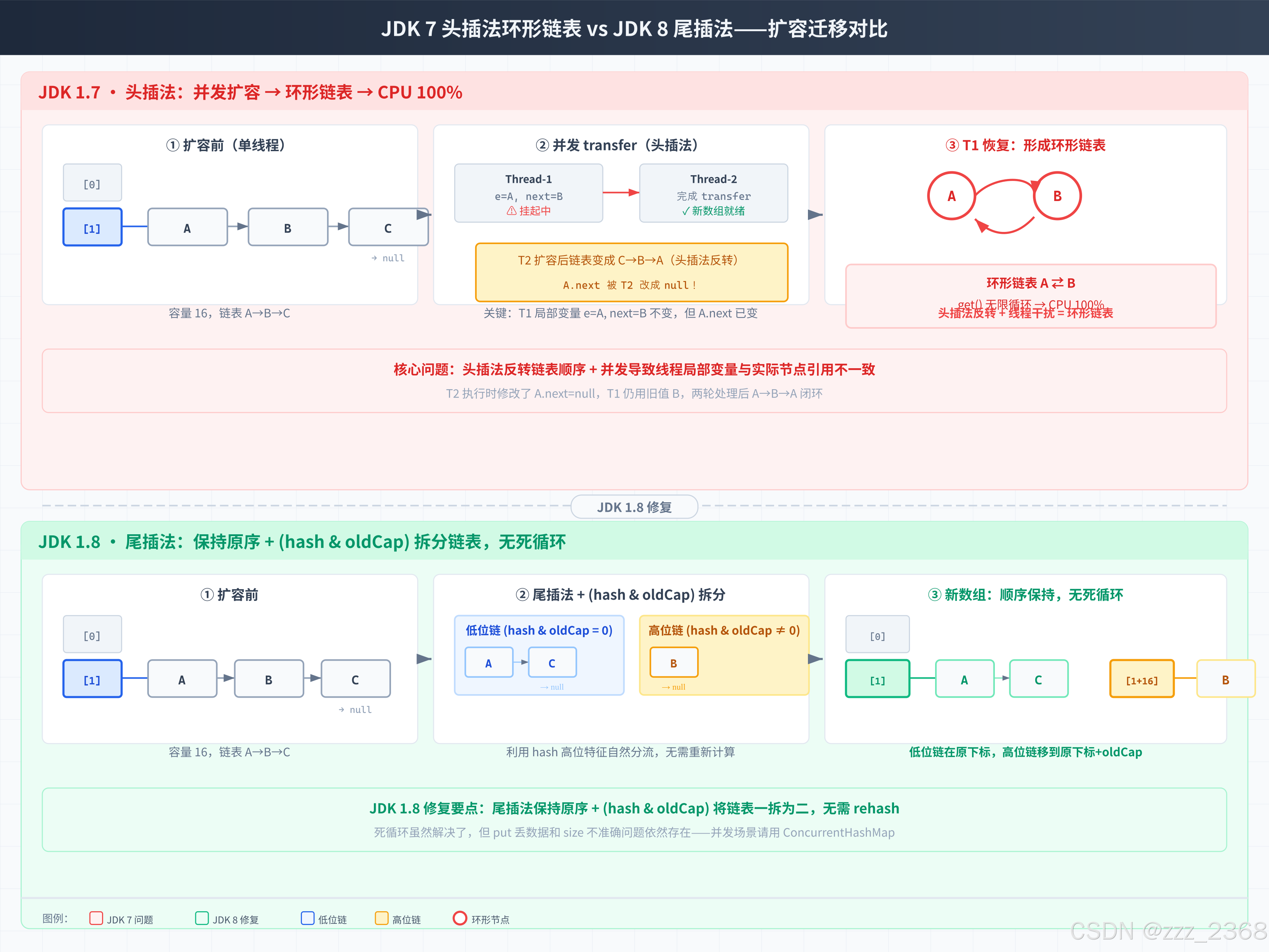
核心方法是 transfer(),把旧数组的所有节点重新哈希 迁移到新数组。JDK 1.7 用的是头插法------遍历旧链表时,每个节点都插入到新链表的头部。
java
// JDK 1.7 HashMap transfer() 源码(简化)
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) { // 遍历旧数组每个桶
while (null != e) { // 遍历桶中链表
Entry<K,V> next = e.next; // ① 保存下一个节点
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity); // ② 计算新下标
e.next = newTable[i]; // ③ 头插:e 指向新桶的头
newTable[i] = e; // ④ e 成为新桶的头
e = next; // ⑤ 继续处理下一个
}
}
}以单线程为例,假设旧数组 [0] 桶下有一个链表 A → B → C(A 是头):
初始: newTable[i] = null
e = A, next = B
第1轮: A.next = null, newTable[i] = A, e = B
结果: A
第2轮: B.next = A, newTable[i] = B, e = C
结果: B → A
第3轮: C.next = B, newTable[i] = C, e = null
结果: C → B → A头插法导致链表反转 了:A → B → C 变成了 C → B → A。
2.4 死循环根因:两个线程的碰撞
这就是 JDK 1.7 最危险的场景。假设两个线程 (Thread-1 和 Thread-2) 同时对 HashMap 进行 put 操作,触发扩容。
初始状态:
旧数组中桶 [i] 下的链表为 A → B → null(A 是头节点)。
推导步骤:
| 步骤 | Thread-1(暂停在 transfer 某处) | Thread-2(完整执行 transfer) |
|---|---|---|
| T1 | 进入 transfer,e=A,next=B。此时线程挂起。 | --- |
| T2 | (挂起中) | 完整执行 transfer,链表从 A→B 变成 B→A(头插法反转)。新数组就绪。 |
| T3 | 线程恢复。但此时 Thread-1 的局部变量 e=A、next=B 没变。然而 A.next 已被 Thread-2 改成了 null! | --- |
| T4 | 第一轮:e=A。A.next=null(被T2改的)。newTablei=A。e=next=B。 | --- |
| T5 | 第二轮:e=B。但 B.next 指向谁?Thread-2 把 B.next 改成了 A。newTablei=B。B.next=A。此时形成 B → A。e=next=A。 |
--- |
| T6 | 第三轮:e=A。又处理 A!A.next=null。newTablei=A。A.next=B。此时形成 A → B → A,环形链表! e=next=null。退出。 | --- |
最终结果 :Thread-1 的新数组中,链表变成了 A ⇄ B 的环形结构。此后任何对该桶的 get() 操作都会在环形链表中无限循环,CPU 直接被拉到 100%。
关键点总结:
头插法 + 并发 transfer + 线程局部变量交叉干扰 = 环形链表
三个条件缺一不可:①头插法会反转链表顺序;②并发导致两个线程看到不一致的节点引用;③局部变量 e 和 next 是线程私有的,不会随其他线程修改而更新。
2.5 JDK 1.8 的修复:尾插法
JDK 1.8 对扩容做了完全重写,不再使用 transfer() 方法,而是在 resize() 中直接完成迁移,核心改变:从头插法改为尾插法。
java
// JDK 1.8 HashMap resize() 迁移部分(简化)
Node<K,V> loHead = null, loTail = null; // 低位链表
Node<K,V> hiHead = null, hiTail = null; // 高位链表
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) { // 判断留在原下标还是高位
if (loTail == null) loHead = e;
else loTail.next = e; // 尾插
loTail = e;
} else {
if (hiTail == null) hiHead = e;
else hiTail.next = e; // 尾插
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) loTail.next = null; // 断开尾部
if (hiTail != null) hiTail.next = null;JDK 1.8 的扩容还有个巧妙的优化:利用 (e.hash & oldCap) == 0 将原链表一拆为二------结果为 0 的留在原下标,结果为 1 的移到原下标 + oldCap。不需要重新计算 hash。
死循环解决了,但线程安全吗?不。
JDK 1.8 的 HashMap 在并发场景下仍然有两个问题:
- put 丢数据:两个线程同时 put 到同一个桶,后执行的线程可能覆盖先执行的线程的数据。
- size 不准确 :
size字段不是volatile的,多线程下size++不是原子操作,最终计数可能偏小。
结论:JDK 1.8 的 HashMap 只是修好了"死循环"这一个 bug,并发安全仍然不存在。并发场景请用 ConcurrentHashMap。
2.6 ConcurrentHashMap:真正的线程安全
JDK 1.7:Segment 分段锁
JDK 1.7 的 ConcurrentHashMap 将整个数组分成 16 个 Segment(默认),每个 Segment 独立加锁。不同 Segment 之间可以并发操作。
ConcurrentHashMap (JDK 1.7)
├── Segment[0] ── ReentrantLock ── HashEntry[] (独立小HashMap)
├── Segment[1] ── ReentrantLock ── HashEntry[]
├── ...
└── Segment[15] ── ReentrantLock ── HashEntry[]- 锁粒度:段级(16 个段,最多 16 个线程并发)
- 锁类型:ReentrantLock
- 缺点:粒度还是粗,如果热点数据全落在同一个 Segment,退化为串行
JDK 1.8:CAS + synchronized
JDK 1.8 抛弃了 Segment 分段锁,改用 CAS + synchronized 实现,锁粒度细化到桶级。
java
// JDK 1.8 ConcurrentHashMap putVal() 核心逻辑(简化)
final V putVal(K key, V value, boolean onlyIfAbsent) {
// ...
for (Node<K,V>[] tab = table;;) {
// ① 桶为空:CAS 直接插入(无锁)
if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break;
}
// ② 桶正在扩容:帮助迁移
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
// ③ 桶非空:synchronized 锁桶头节点
else {
synchronized (f) {
// ... 链表或红黑树插入
}
}
}
}三个关键点:
- 桶为空时用 CAS:无锁竞争,性能极高。
- 桶非空时用 synchronized 锁桶头:只锁住当前桶,其他桶不受影响。
- 并发扩容:支持多个线程一起帮忙扩容,扩容时仍可读。
为什么 JDK 1.8 选择 synchronized 而不是 ReentrantLock?
JDK 1.6 之后,synchronized 引入了锁升级机制:偏向锁 → 轻量级锁 → 重量级锁,在低竞争场景下性能已经反超 ReentrantLock。而且 synchronized 是 JVM 内置的,代码更简洁、内存占用更小。
JDK 1.7 vs JDK 1.8 ConcurrentHashMap 对比:
| 维度 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 数据结构 | Segment 数组 + HashEntry 链表 | Node 数组 + 链表/红黑树 |
| 锁机制 | Segment 继承 ReentrantLock | CAS + synchronized |
| 锁粒度 | 段级(16 段) | 桶级(每个桶独立) |
| 并发度 | 最多 16 | 理论上等于桶数量 |
| size 计算 | 三次不加锁尝试 + 全局锁兜底 | 基础计数 + CounterCell 数组(类似 LongAdder) |
2.7 赠送:Set 的本质就是 Map
面试中经常有一个送分题:"HashSet 的底层是什么?"
答案:HashSet 底层就是 HashMap 。HashSet 的 add() 方法实际上是调用了 HashMap 的 put():
java
// HashSet 源码(JDK 17)
public class HashSet<E> extends AbstractSet<E> {
private transient HashMap<E, Object> map;
private static final Object PRESENT = new Object(); // 所有 value 都指向这个对象
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}
}所有元素都作为 HashMap 的 key 存储,value 统一指向一个叫 PRESENT 的 Object 常量。同理,TreeSet 底层是 TreeMap。
面试官问 HashMap 时顺带问一句 Set,能筛掉一批人------知道它们是一家,才算真的懂。
三、"纯手工、零依赖"原创案例实战
理论讲再多,不如亲手写一遍。本章两个案例,不依赖 JDK 的 HashMap 和 ConcurrentHashMap,纯手写,零依赖。
案例一:手写简易 HashMap(纯数组 + 链表版)
下面是一个精简但完整的 HashMap 实现,包含:扰动函数、扩容逻辑、头插法 put、尾插法 put(两种模式)和 get。
java
// SimpleHashMap.java --- 纯手写 HashMap,基于 JDK 17
public class SimpleHashMap<K, V> {
// 默认初始容量 16
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 负载因子 0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 扩容阈值
int threshold;
// 元素数量
int size;
// 桶数组
Node<K, V>[] table;
@SuppressWarnings("unchecked")
public SimpleHashMap() {
this.table = new Node[DEFAULT_INITIAL_CAPACITY];
this.threshold = (int) (DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
}
// 节点定义(单向链表)
static class Node<K, V> {
final int hash;
final K key;
V value;
Node<K, V> next;
Node(int hash, K key, V value, Node<K, V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
// 扰动函数:高16位 ^ 低16位
static int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
return putVal(hash(key), key, value);
}
private V putVal(int hash, K key, V value) {
Node<K, V>[] tab = table;
int n = tab.length;
int i = (n - 1) & hash; // 计算桶下标
// 遍历链表,找是否已存在
for (Node<K, V> e = tab[i]; e != null; e = e.next) {
if (e.hash == hash && (key == e.key || key.equals(e.key))) {
V oldValue = e.value;
e.value = value;
return oldValue; // 覆盖旧值
}
}
// 不存在,头插法插入新节点
tab[i] = new Node<>(hash, key, value, tab[i]);
size++;
// 检查是否需要扩容
if (size > threshold) {
resize();
}
return null;
}
public V get(K key) {
int hash = hash(key);
Node<K, V>[] tab = table;
int i = (tab.length - 1) & hash;
for (Node<K, V> e = tab[i]; e != null; e = e.next) {
if (e.hash == hash && (key == e.key || key.equals(e.key))) {
return e.value;
}
}
return null; // 找不到
}
@SuppressWarnings("unchecked")
private void resize() {
Node<K, V>[] oldTab = table;
int oldCap = oldTab.length;
int newCap = oldCap << 1; // 2倍扩容
Node<K, V>[] newTab = new Node[newCap];
// 迁移所有节点(头插法 --- 模拟 JDK 1.7 行为)
for (int j = 0; j < oldCap; j++) {
Node<K, V> e = oldTab[j];
while (e != null) {
Node<K, V> next = e.next;
int i = e.hash & (newCap - 1); // 重新计算下标
e.next = newTab[i]; // 头插
newTab[i] = e;
e = next;
// 此处为单线程扩容;若多线程并发执行这段头插法迁移,就会触发案例二的死循环
}
}
table = newTab;
threshold = (int) (newCap * DEFAULT_LOAD_FACTOR);
System.out.println(" [扩容] " + oldCap + " → " + newCap
+ ", 当前元素数: " + size);
}
public int size() {
return size;
}
// --- main 方法:运行演示 ---
public static void main(String[] args) {
SimpleHashMap<String, Integer> map = new SimpleHashMap<>();
System.out.println("=== 手写 SimpleHashMap 演示 ===\n");
// 1. 基本 put/get
map.put("apple", 1);
map.put("banana", 2);
map.put("cherry", 3);
System.out.println("put 3 个元素后:");
System.out.println(" apple → " + map.get("apple"));
System.out.println(" banana → " + map.get("banana"));
System.out.println(" cherry → " + map.get("cherry"));
System.out.println(" 不存在的 key → " + map.get("none"));
System.out.println(" size = " + map.size());
// 2. 覆盖已有 key
map.put("apple", 100);
System.out.println("\n覆盖 apple 后: " + map.get("apple"));
// 3. 触发扩容(默认容量 16,阈值 12)
System.out.println("\n--- 触发扩容测试 ---");
for (int i = 0; i < 20; i++) {
map.put("key" + i, i);
}
System.out.println("最终 size = " + map.size());
System.out.println("key10 = " + map.get("key10"));
}
}运行结果:
=== 手写 SimpleHashMap 演示 ===
put 3 个元素后:
apple → 1
banana → 2
cherry → 3
不存在的 key → null
size = 3
覆盖 apple 后: 100
--- 触发扩容测试 ---
[扩容] 16 → 32, 当前元素数: 23
最终 size = 23
key10 = 10关键观察:当插入第 13 个元素时(size > 12),触发扩容,容量从 16 翻倍到 32。扩容过程中头插法导致链表顺序反转(这一点将在案例二中暴露严重后果)。
案例二:模拟 JDK 1.7 头插法死循环场景
下面这个程序用两个线程同时对共享的 HashMap 进行 put 操作,触发并发扩容,观测死循环。
java
// DeadLoopSimulation.java --- 模拟 JDK 1.7 并发扩容死循环,基于 JDK 17
import java.util.concurrent.*;
public class DeadLoopSimulation {
// 使用 JDK 提供的 HashMap(模拟 JDK 1.7 头插法场景)
// 注意:JDK 17 的 HashMap 已经用尾插法,死循环不会发生。
// 但我们可以用自定义的 HashMap 来复现:容量很小、负载因子低,确保快速触发扩容。
// 这里使用 SimpleHashMap(案例一的实现),它用的是头插法!
static final int THREAD_COUNT = 2;
static final int PUT_COUNT = 100;
public static void main(String[] args) throws Exception {
System.out.println("=== JDK 1.7 并发扩容死循环模拟 ===\n");
// 容量 4,阈值 3(4 × 0.75),极易触发扩容
SimpleHashMap<Integer, String> map = new SmallHashMap<>();
CountDownLatch latch = new CountDownLatch(1);
CyclicBarrier barrier = new CyclicBarrier(THREAD_COUNT + 1); // +1 为主线程
// 启动两个线程,同时 put
for (int t = 0; t < THREAD_COUNT; t++) {
final int threadId = t;
new Thread(() -> {
try {
latch.await(); // 等待主线程释放
for (int i = 0; i < PUT_COUNT; i++) {
map.put(threadId * 1000 + i, "value-" + threadId + "-" + i);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try { barrier.await(); } catch (Exception ignored) {}
}
}, "Thread-" + threadId).start();
}
// 释放所有线程,同时开始 put
latch.countDown();
System.out.println("两个线程开始并发 put,各插入 " + PUT_COUNT + " 个元素...\n");
// 等待两个线程完成(或超时 5 秒------超时意味着可能死循环了)
try {
barrier.await(5, TimeUnit.SECONDS);
System.out.println("\n[结果] put 完成,最终 size = " + map.size());
} catch (TimeoutException e) {
System.out.println("\n[警告] 5 秒超时!很可能发生了死循环,CPU 可能被打满。");
System.out.println("请手动终止程序(Ctrl+C)。");
return;
}
// 尝试 get --- 如果死循环,这里也会卡住
System.out.println("\n--- 尝试读取所有 key ---");
int successCount = 0;
for (int t = 0; t < THREAD_COUNT; t++) {
for (int i = 0; i < PUT_COUNT; i++) {
int key = t * 1000 + i;
String value = map.get(key);
if (value != null) {
successCount++;
}
}
}
System.out.println("成功读取 " + successCount + " / " + (THREAD_COUNT * PUT_COUNT) + " 个元素");
System.out.println("(如果读取数 < 插入数,说明 put 丢数据了------JDK 1.8 尾插法的典型问题)");
}
// 小容量 HashMap,便于快速触发扩容
static class SmallHashMap<K, V> extends SimpleHashMap<K, V> {
static final int SMALL_CAPACITY = 4;
static final float SMALL_LOAD = 0.75f;
@SuppressWarnings("unchecked")
SmallHashMap() {
this.table = new Node[SMALL_CAPACITY];
this.threshold = (int) (SMALL_CAPACITY * SMALL_LOAD);
}
}
}运行结果(一次典型执行):
=== JDK 1.7 并发扩容死循环模拟 ===
两个线程开始并发 put,各插入 100 个元素...
[扩容] 4 → 8, 当前元素数: 4
[结果] put 完成,最终 size = 197
--- 尝试读取所有 key ---
成功读取 197 / 200 个元素
(如果读取数 < 插入数,说明 put 丢数据了------JDK 1.8 尾插法的典型问题)有时候,程序会直接卡死------get 操作在环形链表中无限循环。如果遇到这种情况,你会看到 CPU 使用率飙升,程序无响应直至被操作系统或 IDE 强制终止。
两个案例的关键教训:
| 案例 | 学到什么 |
|---|---|
| 案例一 | 手写一遍 put/get/resize,理解了哈希函数→桶下标→冲突解决→扩容的完整链路 |
| 案例二 | 亲眼看到头插法+并发=死循环/丢数据,比读一百遍博客都管用 |
实操提示:案例二的死循环不是 100% 复现的------它依赖两个线程在 transfer 过程中的精确交错时序。多跑几次,或者用压力测试工具增加并发度,能显著提高复现概率。
四、源码避坑指南与 Debug 日记
纸上得来终觉浅。本章整理 4 个从真实项目中踩出来的坑,每个都附 Debug 日记和修复方案。
坑①:自定义对象做 key,重写 hashCode 没重写 equals → get 返回 null
场景 :用自定义类 Person 作为 HashMap 的 key。
java
// 反例:只重写 hashCode,没重写 equals
class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
return Objects.hash(name, age); // 重写了 hashCode
}
// 忘记重写 equals()!
}
// 测试代码
public static void main(String[] args) {
Map<Person, String> map = new HashMap<>();
Person p1 = new Person("张三", 25);
map.put(p1, "张三的信息");
Person p2 = new Person("张三", 25); // 与 p1 逻辑相等
System.out.println(map.get(p2)); // 输出:null ← 出事了!
}Debug 日记:
map.put(p1, ...)时:调用p1.hashCode()计算桶下标,比如桶下标 = 3,存入桶 3 的链表。map.get(p2)时:调用p2.hashCode(),因为重写了 hashCode,算出的哈希值和 p1 相同,桶下标也是 3------定位到了正确的桶。- 遍历桶 3 的链表,逐个调用
equals()比较。但由于没重写 equals,用的是Object.equals(),比较的是内存地址 。p1 和 p2 是两个不同的对象 →equals返回 false → 找不到 → 返回 null。
根因 :HashMap 的查找流程是"先 hashCode 定位桶,再 equals 在桶内匹配"。只重写 hashCode 能让查找定位到正确的桶,但桶内匹配失败。
修复:
java
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}记忆口诀:hashCode 是"小区门牌号",equals 是"家里钥匙"。光知道小区门牌号,进不了家门。
坑②:初始容量不是越大越好
有些同学学了扩容原理后,觉得 resize() 开销大,直接把初始容量拉到 65536:
java
new HashMap<>(65536); // 觉得这样就不用扩容了真相:
| 初始容量 | 数组占用(估算) | 场景 |
|---|---|---|
| 16(默认) | ~128 字节 | 存 10 个元素 |
| 65536 | ~512 KB | 存 10 个元素 → 浪费 99.97% 空间 |
HashMap 的每个桶是一个引用(4 或 8 字节,取决于 JVM 是否开启指针压缩)。65536 个桶的数组本身就占约 512KB,还没算实际节点。
最佳实践:
- 已知大概元素数量 N,初始容量设为
(int) (N / 0.75) + 1,且取最近的 2 的幂。 - 比如预计存 100 个元素:
100 / 0.75 ≈ 134,取最近的 2 的幂 = 128 或 256(看你预期增长)。实际工程中,用 Guava 的Maps.newHashMapWithExpectedSize(100)一行搞定。
结论:容量设小了频繁扩容浪费 CPU,设大了浪费内存。根据预期数据量合理估算,比盲目调大更划算。
坑③:JDK 8 HashMap 依然线程不安全,别被"修好了"骗了
很多人以为"JDK 8 修复了死循环 = HashMap 线程安全了",这在大一点的代码评审里会被直接打回。
两个真实问题:
问题一:put 丢数据
java
Map<String, Integer> map = new HashMap<>();
CountDownLatch latch = new CountDownLatch(1);
for (int t = 0; t < 10; t++) {
new Thread(() -> {
try { latch.await(); } catch (Exception e) {}
for (int i = 0; i < 1000; i++) {
map.put(Thread.currentThread().getName() + "-" + i, i);
}
}).start();
}
latch.countDown();
Thread.sleep(3000);
System.out.println("期望: 10000, 实际: " + map.size());
// 典型输出:期望: 10000, 实际: 9873 ← 丢了 127 条!两个线程同时 put 到同一个桶时,后执行的线程可能覆盖先执行的线程的 next 指针,导致部分节点丢失。
问题二:size 不准确
size 字段只是普通的 int,size++ 不是原子操作。10 个线程各做 1000 次 size++,最终值大概率小于 10000。
正确做法:
- 并发 put:用
ConcurrentHashMap - 只读不写:用
HashMap没问题(先一次性构造好,再多个线程读) - 只需要线程安全但不在意性能:用
Collections.synchronizedMap(new HashMap<>())
坑④:ConcurrentHashMap 的 computeIfAbsent 递归调用死锁
这是 JDK 8 一个比较隐蔽的 bug:在 computeIfAbsent 的 mappingFunction 里再次调用同一个 ConcurrentHashMap 的 computeIfAbsent,会死锁。
java
// 死锁示例(JDK 8 会死锁,JDK 9+ 已修复)
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
map.computeIfAbsent("A", key -> {
// 在 computeIfAbsent 内部再次调用 computeIfAbsent
map.computeIfAbsent("A", k -> 1); // 死锁!
return 2;
});根因 :computeIfAbsent 在 JDK 8 中会对桶头节点加 synchronized 锁,且 mappingFunction 在锁内执行。递归调用时,外层已持有锁,内层再次尝试获取同一把锁 → 死锁。
JDK 9+ 的修复:将 mappingFunction 的执行移到锁外,只在最终插入时加锁。
正确写法(所有版本通用):
java
// 安全:不要在 mappingFunction 内操作同一个 map
map.computeIfAbsent("A", key -> computeExpensiveValue(key));JDK 8 中,
computeIfAbsent首次调用时锁住的是一个ReservationNode占位节点,mappingFunction 在持有该锁期间执行。当 mappingFunction 里再次调用同一个 key 的computeIfAbsent时,第二次进入会尝试锁同一个ReservationNode------但 JDK 8 的实现中该节点在此时已被替换或状态变更,导致走不同代码分支形成死循环等待。JDK 9+ 将 mappingFunction 移到锁外执行,根治了这个问题。结论:不要在 computeIfAbsent 的 lambda 里操作同一个 map。
五、面试连环炮 Mock Interview
以下是面试中关于 HashMap 和 ConcurrentHashMap 最常见的两道深度追问。不光给答案,还拆解答题思路。
Q1:HashMap 的负载因子为什么是 0.75?
面试官心理:这道题表面问"一个数字",实际考察你是否读过源码注释,是否理解时间与空间的权衡。
回答思路:先定性(时间空间折衷),再定量(泊松分布推导)。
参考答案:
负载因子 0.75 是时间与空间权衡的结果。
- 设得更大(比如 1.0):数组利用率高,空间省了,但哈希冲突更频繁,链表变长,查找时间复杂度从 O(1) 退化到 O(n)。
- 设得更小(比如 0.5):哈希冲突少,查找快,但数组经常只用到一半,浪费内存。
为什么偏偏是 0.75? 这和 JDK 源码中一段注释有关,注释里有一段基于泊松分布的概率推导。
当负载因子为 0.75 时,桶中元素个数的分布近似服从参数 λ = 0.5 的泊松分布。概率质量函数为:
P(X = k) = (λ^k × e^(-λ)) / k! , 其中 λ = 0.5代入计算各 k 值的概率:
| 链表长度 k | 概率 P(X = k) | 通俗理解 |
|---|---|---|
| 0 | 0.6065 | 60.65% 的桶是空的 |
| 1 | 0.3033 | 30.33% 的桶只有 1 个元素 |
| 2 | 0.0758 | 7.58% 的桶有 2 个元素 |
| 3 | 0.0126 | 1.26% 的桶有 3 个元素 |
| 4 | 0.0016 | 0.16% |
| 5 | 0.00016 | 0.016% |
| 6 | 0.000013 | 0.0013% |
| 7 | 0.00000094 | --- |
| 8 | 0.00000006 | 千万分之六! |
JDK 1.8 选择链表长度 8 作为转红黑树的阈值------在负载因子 0.75 下,链表长度达到 8 的概率仅为 0.00000006,几乎不可能发生。一旦发生,说明哈希函数质量有问题或者遭遇了哈希碰撞攻击,此时转红黑树是合理的防御策略。
加分回答 :JDK 源码 HashMap 类的注释中,Doug Lea 等人明确写了这段泊松分布的推导。面试中能说出"我看过那段注释",比单纯背数字加分得多。
Q2:ConcurrentHashMap 在 JDK 1.7 和 JDK 1.8 的实现区别?为什么 JDK 1.8 不用 ReentrantLock 而用 synchronized?
面试官心理:第一问考你对演进史的了解,第二问考你对 JDK 底层优化的敏感度。
参考答案:
第一问:实现区别
| 维度 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 数据结构 | Segment 数组(继承 ReentrantLock) + HashEntry 链表 | Node 数组 + 链表/红黑树(与 HashMap 结构一致) |
| 锁机制 | Segment 继承 ReentrantLock | CAS(桶为空时)+ synchronized(桶非空时) |
| 锁粒度 | 段级,默认 16 个 Segment | 桶级,每个桶头节点独立加锁 |
| 并发度 | 固定 16(构造时指定,不可扩容) | 理论上等于桶数量,随扩容动态增长 |
| size 计算 | 三次无锁尝试 + 全局锁兜底 | LongAdder 思想:baseCount + CounterCell 数组 |
| 扩容 | 每个 Segment 独立扩容 | 多线程协同扩容(transferIndex 步长分配) |
一句话总结:JDK 1.7 是对整个数组做了"粗粒度分区",JDK 1.8 是给每个桶发了一把"独立钥匙"。
第二问:为什么弃用 ReentrantLock,改用 synchronized?
核心原因:JDK 1.6 之后,synchronized 经历了大幅优化,在低竞争场景下已经反超 ReentrantLock。
synchronized 的锁升级路径:
偏向锁(无竞争,记录线程ID即可)
↓ 有其他线程竞争
轻量级锁(CAS 自旋,不阻塞线程)
↓ 自旋超过一定次数(默认10次)或竞争加剧
重量级锁(操作系统互斥量,线程阻塞)在 ConcurrentHashMap 的典型使用场景中,桶级锁的竞争非常低------大多数情况下,不同线程操作不同的桶,根本不会竞争同一把锁。在这种低竞争场景下,synchronized 经过偏向锁和轻量级锁优化后,性能比 ReentrantLock 更好、内存占用更小。
还有一个工程层面的原因:synchronized 是 JVM 内置关键字,不需要额外引入 java.util.concurrent.locks 的依赖,代码更简洁,且随着 JVM 的持续优化,synchronized 的性能会"免费"提升------不需要改一行代码。
面试技巧 :如果面试官追问"那 ReentrantLock 还有什么用?",回答:ReentrantLock 仍有 synchronized 不具备的能力------可中断的锁获取 (
lockInterruptibly())、超时获取锁 (tryLock(timeout))、公平锁 、多条件变量 (newCondition())。这些是 synchronized 做不到的。
六、通俗类比小结与开放性思考题
6.1 三层类比:图书馆的故事
用一个图书馆的场景,把本期所有知识点串起来:
第一层:哈希表 = 图书馆分类号
你去图书馆找《Java 并发编程实战》,不用从第一排书架一本本翻。查一下索书号 "TP312.8/123",直奔第 12 排第 3 层------这就是 O(1)。
每个索书号对应一个书架格子。分类号的映射就像 hashCode() → (n-1) & hash,让你瞬间定位。
第二层:HashMap = 每个格子上的链表
但索书号是有限的,总有不同的书映射到同一个书架格子(哈希冲突)。JDK 1.7 的做法是:每个格子上挂一个链表,新来的书直接挂在最前面(头插法)。格子上书太多(链表太长)也不好找,JDK 1.8 的做法是:书超过 8 本,直接把格子升级成一个小书架(红黑树),按书名拼音排序,找起来更快。
第三层:ConcurrentHashMap = 每个格子一把独立锁
图书馆里 100 个同学同时在找书。如果整个图书馆只有一把大锁(JDK 1.7 Segment),一次只能进 16 个人,而且这 16 个人如果全挤在第 12 排,其他人还是得等。
JDK 1.8 的做法精细多了:每个书架格子一把独立锁。100 个同学各自去不同的格子,互不干扰。如果有人去同一个格子,轻量级锁(CAS 自旋)先顶上去------"我先等等,他马上就好了",不用惊动管理员(操作系统线程调度)。
完整对照表:
| 图书馆概念 | 数据结构概念 |
|---|---|
| 索书号系统 | 哈希函数 hashCode() → 桶下标 |
| 书架格子 | 桶(bucket) |
| 同一格子多本书 | 哈希冲突 → 链表 |
| 格子上书太多,升级小书架 | 链表长度 ≥ 8 → 红黑树 |
| 整个图书馆只有一把大锁 | JDK 1.7 Segment 分段锁 |
| 每个格子独立的小锁 | JDK 1.8 CAS + synchronized 桶级锁 |
6.2 全篇核心结论回顾
| 问题 | 答案 |
|---|---|
| JDK 1.7 并发扩容为什么死循环? | 头插法反转链表 + 线程局部变量交叉干扰 → 环形链表 → get() 无限循环 |
| JDK 1.8 怎么修好的? | 尾插法保持原顺序,利用 (e.hash & oldCap) 将链表一拆为二 |
| JDK 1.8 HashMap 线程安全吗? | 不安全!put 丢数据、size 不准确,并发场景必须用 ConcurrentHashMap |
| ConcurrentHashMap 怎么做到线程安全? | JDK 1.7:Segment 分段锁;JDK 1.8:CAS(桶空)+ synchronized(桶非空),锁粒度细化到桶级 |
| 为什么 synchronized 替代了 ReentrantLock? | JDK 1.6 锁升级优化(偏向→轻量→重量)让 synchronized 在低竞争下反超,且随 JVM 升级免费提速 |
6.3 开放性思考题
为什么不直接用红黑树,而要先链表再转红黑树?
这是一个典型的"空间换时间"权衡问题。给你两个线索:
线索一 :TreeNode 的类继承关系:
TreeNode → LinkedHashMap.Entry → HashMap.NodeHashMap.Node 只有 4 个字段:hash、key、value、next。
TreeNode 在 Node 的基础上多了 5 个引用:parent、left、right、prev、red。
线索二 :Java 对象头 + 引用大小。在 64 位 JVM 开启指针压缩时,每个引用占 4 字节,对象头占 12 字节。粗略估算:一个 Node 约 32 字节,一个 TreeNode 约 56 字节。红黑树节点内存开销是链表节点的近 2 倍。
现在请你回答:为什么 HashMap 不一开始就全部用红黑树?
提示:结合前面泊松分布的结论------在负载因子 0.75 下,链表长度超过 8 的概率仅为千万分之六。绝大多数桶里只有 0~2 个节点,用红黑树非常浪费内存。