问题与思考:
1、itertools.chain(),chain的作用
核心功能是将多个可迭代对象(如列表、元组、集合、生成器等)连接起来,形成一个单一的、连续的迭代器
工作机制:它会按顺序从第一个可迭代对象中提取元素,直到该对象被"掏空"(exhausted),然后再无缝移动到下一个可迭代对象,直到所有输入都被处理完毕
代码示例:
python
from itertools import chain<websource>source_group_web_5</websource>
list1 =
tuple1 = ('A', 'B', 'C')
set1 = {7.0, 8.0}<websource>source_group_web_6</websource>
# 将它们连接成一个迭代器并转换为列表查看结果
combined = list(chain(list1, tuple1, set1))
print(combined)
# 输出: [1, 2, 3, 'A', 'B', 'C', 8.0, 7.0] (集合顺序可能不同)
python
test_vocab = set(chain(*map(lambda x: jieba.lcut(x), data_test["sentence"])))一、【了解】自然语言处理介绍
1. 【了解】什么是自然语言处理
自然语言处理(Natural Language Processing, 简称NLP),是**让机器能够理解和生成自然语言。**处理的数据主要就是人类的语言,例如:汉语、英语、法语等,该类型的数据不像我们前面接触过的结构化数据、或者图像数据可以很方便的进行数值化。
自然语言处理的主要任务包括:
-
语音识别:将语音信号转化为文本
-
文本分析:从文本中提取有意义的信息,包括情感分析、主题提取等
-
机器翻译:自动将一种语言的文本翻译为另一种语言
-
语法分析:分析句子的语法结构,识别句子中的各个成分(如主语、谓语、宾语等)
-
命名实体识别(NER):识别文本中的重要实体,如人名、地点名、组织名等
-
对话系统:使计算机能够与人类进行自然流畅的对话,如智能助手、聊天机器人等
-
自动摘要:从大量文本中提取出最关键信息并生成简洁的摘要
2. 【了解】自然语言处理应用场景
搜索与信息检索:
- 搜索引擎: NLP技术是现代搜索引擎的核心。它帮助理解用户查询的意图,并返回最相关的搜索结果
- 企业搜索: 在企业内部的文档、数据库中进行信息检索,提高工作效率
- 学术搜索: 在学术文献库中进行搜索,帮助研究人员查找相关论文
机器翻译:
- 跨语言交流: 帮助不同语言的人们进行交流,例如 Google Translate 等翻译工具
- 文档翻译: 将文档从一种语言翻译成另一种语言,用于商业、法律、科技等领域
- 网站翻译: 实时翻译网页内容,方便用户浏览不同语言的网站
聊天机器人与虚拟助手:
- 客户服务: 自动化处理客户咨询,提供 24/7 的在线服务,降低人力成本
- 智能助手: 如 Siri、Alexa、Google Assistant 等,帮助用户完成各种任务,例如设置提醒、播放音乐、查询信息等
- 医疗助手: 提供健康咨询、预约挂号等服务,方便患者就医
语音识别与语音合成:
- 语音识别: 将语音转换为文本
- 语音合成: 将文本转换为语音
内容生成:
- 文本摘要: 自动生成长文本的摘要
- 文章生成: 自动撰写文章
- 代码生成: 根据自然语言描述生成代码
二、文本处理和向量化
1. 文本预处理介绍
1.1 文本预处理简介
1.1.1 概念:
文本预处理 是指在自然语言处理(NLP)任务中,针对原始文本进行清洗、转换、标准化等一系列处理的过程
1.1.2 目的:
旨在通过去除冗余和无关的部分,提高文本数据的质量和可用性,以便后续的机器学习模型或深度学习模型能够更高效地学习和推理
1.1.3 【了解】作用:
增强文本表示
- 向量化: 将文本转换为数值向量(如TF-IDF、词嵌入)。
- 特征提取: 提取n-gram、词性、句法结构等特征。
- 上下文建模: 通过预处理为上下文相关的模型(如BERT)提供输入。
提高数据质量
- 清洗文本:原始文本可能包含**多余的噪声**(如HTML标签、标点符号、拼写错误等)。这些内容对NLP模型没有实际意义,反而可能会影响模型的学习效果。文本清洗可以去除这些无关的部分。
- 标准化文本格式:例如**统一大小写、统一数字的表示**等,有助于减少模型的复杂度,让模型能够聚焦于重要信息。
降低计算复杂度
- 分词: 将句子拆分为单词或子词单元,便于后续处理。
- 去停用词 :停用词在文本中频繁出现,但对模型的语义贡献较小。去除这些停用词可以
有效减少文本的维度,降低计算复杂度。 - 词形还原与词干提取 :通过将不同形式的词汇(如复数、动词时态等)归一化为基础形式,
减少了模型的词汇量,有助于提高模型的训练效率和准确性。
改进模型性能
-
降低维度: 通过去除冗余信息,减少特征空间的维度,提高计算效率。
-
增强一致性: 统一文本表示(如大小写转换、标点符号处理),避免模型混淆。
-
改善泛化能力: 通过标准化和归一化,使模型更容易捕捉文本中的关键特征。
-
...
1.2 文本预处理环节
1.2.1 文本处理的基本方法
- 分词: NLP中的基础操作,它将连续的文本拆分成词、子词或字符等基本单元,是文本处理的第一步。
- 词性标注: 为文本中的每个词分配一个语法类别,帮助理解文本的语法结构。
- 命名实体识别: 识别文本中的特定实体,如人名、地名、日期等,是信息抽取的核心任务之一。
1.2.2 文本张量表示方法
- one-hot编码: 最简单的词表示方法,但它存在稀疏、维度高和无法捕捉词之间语义关系等缺点。
- Word2Vec: 基于神经网络的词嵌入技术,它能够通过上下文信息学习词的低维稠密向量,能够捕捉语义关系。
- Word Embedding: 将词表示为低维向量的技术,包括Word2Vec、GloVe、FastText等方法。它们能够捕捉词语之间的语义和句法关系,是现代自然语言处理的基础。
1.2.3 文本语料的数据分析
- 标签数量分布: 在一个分类任务中,每个类别(标签)的样本数量分布,检查是否存在标签不平衡。
- 句子长度分布: 对文本数据集中句子长度(通常是单词数量或字符数量)的统计分析。通过分析句子长度分布,可以了解文本数据的基本结构和特点。
- 词频统计: 对文本中各个词汇出现频率的计算和分析。通过统计每个词在文本中出现的次数,可以找出数据集中最常见的词汇。
- 关键词词云: 常用的文本数据可视化方法,通过图形化展示词汇的频率,其中出现频率较高的词汇显示得更大。词云图可以帮助快速查看文本数据中的关键词。
1.2.4 文本特征处理
- 添加n-gram特征: 文本中连续出现的n个词(或字符)的组合。
- 文本长度规范: 对文本长度进行标准化或限制,以确保每个文本的长度在一个合理的范围内。
2. 文本预处理基本方法
2.1 分词
2.1.1 分词介绍
概念:
分词就是将连续的句子、段落,按照一定的规范重新拆分为一个个词的过程。
在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符。
作用:
-
预处理:分词是文本处理的第一步,能够将文本分解成有意义的单元,为后续的分析提供基础。
-
理解结构:分词有助于理解句子的基本构成和含义,尤其是在做文本分类、情感分析等任务时,分词是不可缺少的一步。
-
常用的中文分词工具包括Jieba、HanLP等。
2.1.2 Jieba分词工具
Jieba("结巴")是一个开源的Python中文分词组件,可以将中文句子拆分为一个个单独含义的词语,它支持精确模式、全模式和搜索引擎模式三种分词模式。
特点 【了解】:
- 支持多种分词模式: 精确模式、全模式和搜索引擎模式,满足不同场景的需求。
- 支持自定义词典: 用户可以添加自定义的词语,提高分词准确率。
- 支持词性标注: 可以为每个词语标注词性,例如名词、动词等。
- 支持关键词提取: 可以提取文本中的关键词。
- 支持并行分词: 可以利用多核处理器加速分词。
- 简单易用: API 简单明了,易于上手。
- 开源免费: 任何人都可以免费使用。
基本使用:
精确模式分词【默认使用】: 试图将句子最精确地切分开,适合文本分析。
python
import jieba
content = "这道题目可以说在面试中出现频率较高的题目,本题并不涉及到什么算法,就是模拟过程,但却十分考察对代码的掌控能力"
# 精确模式
w1 = jieba.cut(content) # 输出是一个生成器
w2 = list(jieba.cut(content)) # 进行列表转换
w3 = jieba.lcut(content) # 输出是一个列表
print("w1:", w1)
print("w2:", w2)
print("w3:", w3)
'''
输出:
w1: <generator object Tokenizer.cut at 0x0000021E18B1FCC0>
w2: ['这道', '题目', '可以', '说', '在', '面试', '中', '出现', '频率', '较', '高', '的', '题目', ',', '本题', '并', '不', '涉及', '到', '什么', '算法', ',', '就是', '模拟', '过程', ',', '但', '却', '十分', '考察', '对', '代码', '的', '掌控', '能力']
w3: ['这道', '题目', '可以', '说', '在', '面试', '中', '出现', '频率', '较', '高', '的', '题目', ',', '本题', '并', '不', '涉及', '到', '什么', '算法', ',', '就是', '模拟', '过程', ',', '但', '却', '十分', '考察', '对', '代码', '的', '掌控', '能力']
'''全模式分词: 将句子中所有可以成词的词语都扫描出来,速度非常快,但是不能消除歧义
需要添加参数: cut_all=True
python
import jieba
content = "这道题目可以说在面试中出现频率较高的题目,本题并不涉及到什么算法,就是模拟过程,但却十分考察对代码的掌控能力"
# 全模式
w4 = jieba.lcut(content, cut_all=True)
print("w4:", w4)
# 输出: w4: ['这', '道', '题目', '可以', '说', '在', '面试', '中出', '出现', '频率', '较', '高', '的', '题目', ',', '本题', '并', '不', '涉及', '到', '什么', '算法', ',', '就是', '模拟', '过程', ',', '但', '却', '十分', '考察', '对', '代码', '的', '掌控', '能力']搜索引擎模式分词: 在精确模式的基础上,对长词再次切分,进行细粒度分词,适合用于搜索引擎分词。
python
import jieba
# 搜索引擎
w_s = jieba.cut_for_search(sentence=content)
print(list(w_s))
w_sl = jieba.lcut_for_search(content)
print(w_sl)中文繁体分词: 针对中国香港, 台湾地区的繁体文本进行分词。和上边使用的API是一样的
使用用户自定义词典: 添加自定义词典后, jieba能够准确识别词典中出现的词汇,提升整体的识别准确率。
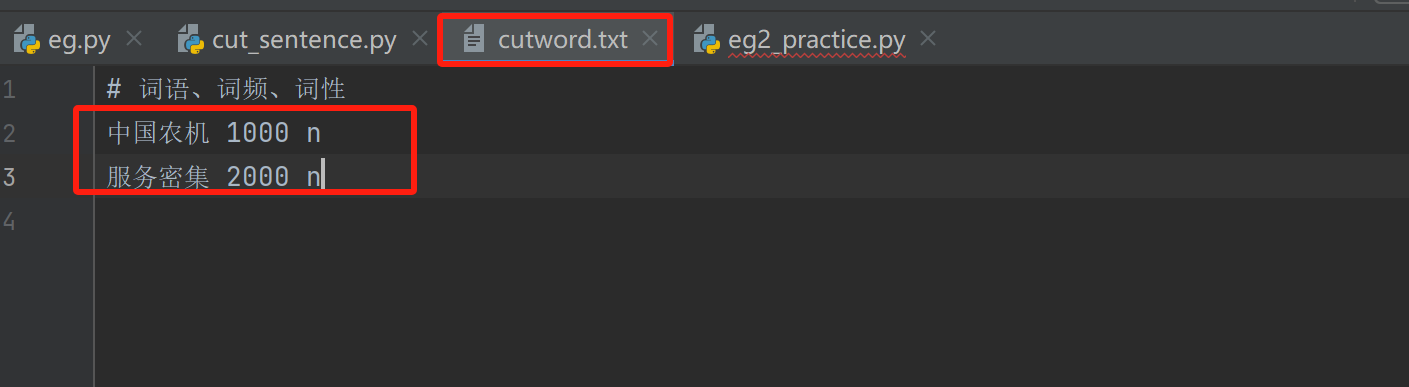
自定义词典文件格式必须是txt文件
自定义词典格式:词语、词频、词性
python
import jieba
content = "我们期待,中国农机加速迈向高附加值、技术密集、服务密集的转型之路,以更加硬核的实力深耕全球田野。"
w1 = jieba.lcut(content)
print("w1:", w1)
jieba.load_userdict(r"./data/cutword.txt")
w2 = jieba.lcut(content)
print("w2:", w2)
'''
输出:
w1: ['我们', '期待', ',', '中国', '农机', '加速', '迈向', '高附加值', '、', '技术密集', '、', '服务', '密集', '的', '转型', '之', '路', ',', '以', '更加', '硬核', '的', '实力', '深耕', '全球', '田野', '。']
w2: ['我们', '期待', ',', '中国农机', '加速', '迈向', '高附加值', '、', '技术密集', '、', '服务密集', '的', '转型', '之', '路', ',', '以', '更加', '硬核', '的', '实力', '深耕', '全球', '田野', '。']
'''自定义词典示例:
2.2 命名实体识别
命名实体识别(NER---Named Entity Recognition)是自然语言处理中的一个任务,旨在从文本中识别出特定类别的实体(如人名、地名、机构名、日期、时间等)。NER是信息抽取的一部分,帮助计算机识别出与任务相关的实体信息。
命名实体识别作用
- 信息抽取:NER帮助从海量的文本中自动抽取出结构化的实体信息,为数据分析、问答系统等提供有价值的内容。
- 问答系统:在智能问答系统中,NER能够帮助系统准确理解用户的提问,并提取相关的实体信息以便生成更准确的回答。
- 文本理解:NER对于文本理解至关重要,它帮助系统识别出文本中的关键信息,例如人物、地点、组织等,进而为语义分析和事件抽取提供支持。
处理工具
- SpaCy 、NLTK 、Stanford NER 、BERT(通过微调) 、LTP、**HanLP**等都可以用于命名实体识别任务。
举个例子
python
from hanlp_restful import HanLPClient
HanLP = HanLPClient(url="https://www.hanlp.com/api",
auth=None,
language='zh',
verify=False)
# 进行命名实体识别
# 只选择一个任务,包含了分词和命名实体识别
print(HanLP.parse("鲁迅, 浙江绍兴人, 五四新文化运动的重要参与者, 代表作朝花夕拾.",
tasks=['ner/msra']))
# tasks=['ner/msra'] 使用对应的文本库
'''
输出:
{
"tok/fine": [
["鲁迅", ",", "浙江", "绍兴人", ",", "五四", "新", "文化", "运动", "的", "重要", "参与者", ",", "代表作", "朝花夕拾", "."]
],
"ner/msra": [
[["鲁迅", "PERSON", 0, 1], ["浙江", "LOCATION", 2, 3], ["五四", "DATE", 5, 6], ["文化", "ORGANIZATION", 7, 8]]
]
}
'''2.3 【了解】词性标注
词性标注(Part-Of-Speech tagging, 简称POS)就是为文本中的每个词分配一个语法类别(即词性),例如名词、动词、形容词等。
词性标注能够帮助模型理解词汇在句子中的语法功能,并为进一步的句法分析和语义分析提供支持
类型
- 名词n :表示人、事物、地方等,例如
"中国","鲁迅"。 - 动词v :表示动作、存在等,例如
"跑","吃"。 - 形容词a :描述事物的性质或状态,例如
"大","美丽"。 - 副词d :修饰动词、形容词或其他副词,例如
"马上","非常"。 - 代词r :代替名词的词,例如
"我","他们"。
作用
为文本中的每个词分配一个语法类别,例如名词、动词、形容词等。可以用于之后单独筛选、使用对应的词语。
处理工具
- Jieba 、NLTK 、SpaCy、**Stanford POS Tagger**等是常用的词性标注工具。
举个例子
python
from jieba import posseg
content = "北京的金山上光芒照四方"
pairs = posseg.lcut(sentence=content)
# print(poss)
for word, pos in pairs:
if pos in ["n"]:
print(word, "n")
'''
# 输出:
光芒 n
照 n
'''3. 文本的张量表示
3.1 什么是文本张量表示及其作用
**概念:**将一段文本使用张量进行表示,先进行分词,再将词汇表示成向量,称作词向量,由各个词向量按顺序组成矩阵形成文本表示。
"人生", "该", "如何", "起头"
==>
每个词对应矩阵中的一个向量
\[1.32, 4,32, 0,32, 5.2,
3.1, 5.43, 0.34, 3.2,
3.21, 5.32, 2, 4.32,
2.54, 7.32, 5.12, 9.54\]
张量表示的作用
将文本表示成张量(矩阵)形式,能够使语言文本可以作为计算机处理程序的输入,使得含义相近的词 在向量中的欧式距离相近,进行接下来一系列的解析工作。
3.2 【掌握】文本张量表示的几种方法及其实现
3.2.1 【了解】热编码( 0ne-Hot )
**概念:**一种将离散的分类变量转化为二进制向量的方法。
在自然语言处理中,one-hot编码常用于表示单词。每个单词都被表示为一个稀疏向量,该向量的长度等于词汇表的大小,其中只有一个位置为1,其他位置为0。
**稀疏向量:**每个词对应一个n列的行向量,只有词对应的有意义的才为1,其它位置为0.
例如:
假设有一个简单的词汇表:"cat", "dog", "fish"。
我们将每个单词用一个固定长度的向量表示:
"cat" → 1, 0, 0
"dog" → 0, 1, 0
"fish" → 0, 0, 1
优缺点:
- 优点:实现简单,容易理解。
- 缺点:高维稀疏向量,无法捕捉词之间的语义相似性。而且在大语料集下,每个向量的长度过大,占据大量内存。
one-hot编码器代码实现:
语料、分词
去重、构建词表(id_to_word)
one-hot
3.1 构建全零向量
3.2 构建词表(word_to_id)
3.3 根据id对应索引位置为1
3.4 保存
python
import joblib
class BuildVocab(object):
def __init__(self):
self.id_to_word = {}
self.word_to_id = {}
def fit_ont_text(self, text):
sort_text = sorted(text)
for id, word in enumerate(sort_text, start=1):
self.id_to_word[id] = word
self.word_to_id[word] = id
return self.id_to_word, self.word_to_id
def dm_onehot_gen(vocabs):
build_vocab = BuildVocab()
id_to_word, word_to_id = build_vocab.fit_ont_text(vocabs)
# print(id_to_word)
# print(word_to_id)
for word in vocabs:
zero_list = [0] * len(vocabs)
idx = word_to_id[word] - 1
zero_list[idx] = 1
print(word, ":", zero_list)
# 保存
joblib.dump(build_vocab, r"./data/vocabs")
print("\nword_index (单词->索引):", build_vocab.word_to_id)
print("index_word (索引->单词):", build_vocab.id_to_word)
def dm_onehot_use(token):
my_token = joblib.load(r'./data/vocabs')
vocab_size = len(my_token.word_to_id)
zero_list = [0] * vocab_size
idx = my_token.word_to_id[token]
zero_list[idx] = 1
print(f'{token}:{zero_list}')
if __name__ == '__main__':
# vocabs = {"周杰伦", "陈奕迅", "王力宏", "李宗盛", "吴亦凡", "鹿晗"}
# dm_onehot_gen(vocabs)
dm_onehot_use("李宗盛")
# token不存在会出现异常
# dm_onehot_use("海伦")3.2.2 Word2Vec模型
**目标:**将每个词转换为一个固定长度的向量,这些向量能够捕捉词与词之间的语义关系。
与onehot比较:
这些向量能够捕捉词与词之间的语义关系
Word2Vec通过训练得到的词向量通常是稠密的,即大部分值不为零,每个向量的维度较小(通常几十到几百维),计算效率高。
缺点:
需要大量的语料来训练;可能不适用于某些特定任务(例如:词语的多义性)
1. CBOW(Continuous bag of words)模式
给定一段用于训练的上下文词汇(周围词汇),预测目标词汇。
**窗口大小:**上文或下文 大小
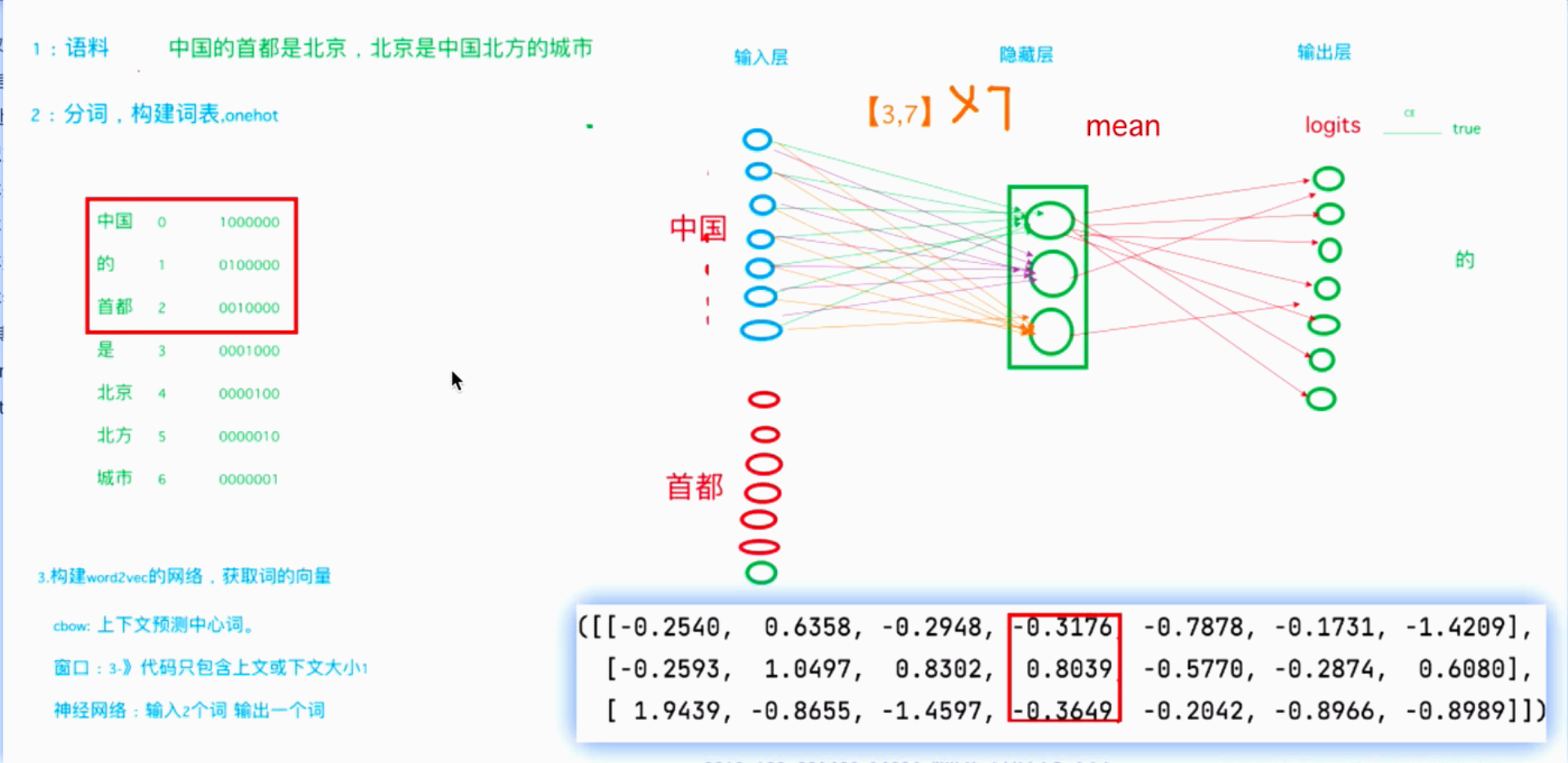
实现步骤:
① 确认滑动窗口,特征(上下文)、目标值(中心词)
② 将上下文、中心词进行onehot编码
③ 构建Word2Vec神经网络,获取词向量
④ 通过上下文预测目标词
输入层->隐藏层
输入层"中国"对应的 X = x0,x1,x2,x3,x4,x5,x6,x7 = 1,0,0,0,0,0,0, Y = W*X
对应,
输入层"首都"对应的 X = x0,x1,x2,x3,x4,x5,x6,x7 = 0,0,1,0,0,0,0, Y = W*X
对应,
⑤ 隐藏层->输出层
取平均值,得到一个3,1的矩阵
得 ,y.shape=7,1
⑥ 计算Y与"的"对应onehot编码的损失值,更新网络参数完成一次模型迭代。
⑦ 最后窗口按顺序向后移动,重新更新参数,直到所有语料被遍历完成,得到最终的变换矩阵(3x7),这个变换矩阵与每个词汇的one-hot编码(7x1)相乘,得到的3x1的矩阵就是该词汇的word2vec张量表示
2. Skip-gram模式
给定一个目标词,预测其上下文词汇
实现步骤与cbow类似,输入层输入为目标层,输出层结果为上下文词汇
3.word2vec的训练和使用
fasttext作用?分类、词向量
训练步骤:
第一步: 获取训练数据
第二步: 训练词向量
第三步: 模型超参数设定
第四步: 模型效果检验
第五步: 模型的保存与重加载
获取训练数据:
fasttext只支持英文数据,非英文需要特殊处理,下边步骤中使用维基百科数据,放置在data/fil9
工具安装:
fasttext是facebook开源的一个词向量与文本分类工具。下面是该工具包的安装方法:
- 官网(fasttext-wheel)下载对应操作系统对应python解析器版本的fasttext模块的whl文件
- 进入到base虚拟环境,然后在whl文件目录下通过以下命令安装
在下载好的whl文件目录下执行
pip install asttext_wheel-0.9.2-cp311-cp311-win_amd64.whl
模型超参数设定:
在训练词向量过程中, 我们可以设定很多常用超参数来调节我们的模型效果, 如:
无监督训练模式:model默认为'skipgram', 在实践中,skipgram模式在利用子词方面比cbow更好.
词嵌入维度dim: 默认为100, 但随着语料库的增大, 词嵌入的维度往往也要更大.
数据循环次数epoch: 默认为5, 但当你的数据集足够大, 可能不需要那么多次.
学习率lr: 默认为0.05, 根据经验, 建议选择0.01,1范围内.
使用的线程数thread: 默认为12个线程, 一般建议和你的cpu核数相同.
model = fasttext.train_unsupervised(input='data/fil9', model="cbow", dim=300, epoch=1, lr=0.1, thread=4)
代码实现:
python
import fasttext
# 词向量的训练保存加载
def train_model_save():
model = fasttext.train_unsupervised(input=r'./data/fil9',
model="skipgram",
dim=100,
epoch=1,
ws=2)
model.save_model(r'./data/word_to_vect.bin')
# 查看单词对应的词向量
def get_word_vector():
mymodel = fasttext.load_model(r'./data/word_to_vect.bin')
myvector = mymodel.get_word_vector(word="the")
print(type(myvector), myvector.shape, myvector)
# 获取词义相近的词
print("car:",mymodel.get_nearest_neighbors(word="car", k=10))
if __name__ == '__main__':
get_word_vector()
'''
输出:
<class 'numpy.ndarray'> (100,) [ 4.18672226e-02 4.62766327e-02 5.70637872e-04 -2.12754868e-02
-1.82987943e-01 -3.42566848e-01 -8.67610991e-01 -2.65146792e-01
-8.75629485e-01 -4.07558709e-01 1.89817056e-01 3.86929542e-01
-1.55139476e-01 1.71416357e-01 -1.31946132e-01 -2.42667228e-01
-1.70112953e-01 2.46678740e-01 1.18591890e-01 -5.76239407e-01
4.04453799e-02 -2.68159300e-01 5.20325541e-01 -1.39237195e-01
-2.29602337e-01 1.95318125e-02 1.54153258e-01 -7.17301667e-02
6.02285452e-02 1.56152844e-01 3.29819530e-01 -3.06362361e-01
1.71186864e-01 1.43164843e-01 -1.59120768e-01 -1.09350719e-01
9.44681242e-02 3.91500980e-01 -3.59377086e-01 1.79823935e-01
3.46986443e-01 2.66780168e-01 1.76452070e-01 1.16695292e-01
5.25159873e-02 -5.70445418e-01 -2.98287094e-01 -1.94418579e-01
-1.14174411e-01 -3.54996949e-01 -1.75185859e-01 -4.92802709e-02
1.88400850e-01 -4.54358727e-01 -2.02580601e-01 -6.95897713e-02
-1.22147739e-01 1.26475185e-01 1.73797265e-01 1.98543966e-01
-1.63118169e-02 5.84476769e-01 1.27587155e-01 1.79365538e-02
-2.11599767e-01 4.84536409e-01 2.64206171e-01 7.48719508e-03
-2.72169173e-01 -3.03729951e-01 -9.51248929e-02 -3.50620091e-01
3.40196013e-01 -3.34886998e-01 -5.26830107e-02 3.25369924e-01
-3.10484469e-01 9.82736871e-02 -3.22383106e-01 3.46053749e-01
-8.01684409e-02 1.25729024e-01 4.47198540e-01 3.03867042e-01
2.74949998e-01 6.90502077e-02 -1.02765545e-01 -1.21493079e-01
-4.34350044e-01 1.46982834e-01 1.39929503e-01 3.28707904e-01
-2.24144831e-01 -1.74008861e-01 -1.52936533e-01 -5.55022120e-01
-5.18302098e-02 1.40422150e-01 5.01559019e-01 6.08061068e-02]
car: [(0.8506630659103394, 'cars'), (0.8432316780090332, 'motorcar'), (0.8403528928756714, 'automobile'), (0.8329198360443115, 'motorcyle'), (0.830048680305481, 'motorcycle'), (0.8298582434654236, 'motorcars'), (0.8273360133171082, 'motorbike'), (0.821898877620697, 'motorboat'), (0.8212409019470215, 'truck'), (0.8169911503791809, 'automobiles')]
'''3.2.3 词嵌入Word Embedding
Word Embedding 与 Word2Vec 的关系:
-
Word2Vec是一种Word Embedding方法,专门用于生成词的稠密向量表示。Word2Vec通过神经网络训练,利用上下文信息将每个词表示为一个低维稠密向量。
-
Word Embedding是一个更广泛的概念,指任何将词汇映射到低维空间的表示方法,不仅限于Word2Vec。GloVe和FastText等方法同样属于词嵌入。
概念:
一种通过一定的方式将单词映射为向量,转换为计算机可以处理的语言的技术
特点:
词嵌入将每个词映射为低维稠密的向量,通常维度为50、100、200或300
词嵌入能够捕捉词语之间的关系,例如语法上的相似性(如复数形式)和语义上的相似性(如"man"与"woman")。
词嵌入能够在不同任务之间共享词向量,提高模型的泛化能力。
优缺点:
- 优点:能够有效捕捉词的语义和句法信息,且训练出来的词向量可以在多个任务中使用。
- 缺点:对于一些低频词和未见过的词处理可能较差。
Word Embedding的代码实践:
语料-> 分词 -> 去重 -> 词表 -> nn.embedding -> 获取词的向量
python
import jieba,torch
class SimpleTokenizer(object):
# 构建词表
def __init__(self):
self.id_to_word = {}
self.word_to_id = {}
self.embedding_dim = 5
# 词表填充
def fit_to_text(self, word_list):
# 去重
self.vocab_uniq = set(word_list)
self.sort_vocab = sorted(self.vocab_uniq)
# 构建词表
for id, word in enumerate(self.sort_vocab, start=1):
self.id_to_word[id] = word
self.word_to_id[word] = id
return len(self.id_to_word)
# 将语料转换为向量
def corpus2id(self, words_list):
self.emb = torch.nn.Embedding(num_embeddings=len(self.id_to_word), embedding_dim=self.embedding_dim)
self.idx_list = [self.word_to_id[word] - 1 for word in words_list if word in self.word_to_id]
if __name__ == '__main__':
# 准备语料
text1 = "明月别枝惊鹊,清风半夜鸣蝉"
text2 = "稻花香里说丰年,听取蛙声一片"
text_list = [text1, text2]
# 分词
vocab = []
for i in text_list:
content = jieba.lcut(i)
vocab.extend(content)
# print(vocab)
# 构建词表:id2word,word2id
simpletokenizer = SimpleTokenizer()
print(simpletokenizer.fit_to_text(vocab))
# nn.embedding、将语料转换为向量
print(simpletokenizer.corpus2id(words_list=vocab))
'''
输出:
tensor([[-1.1450e-01, 1.2088e+00, -9.4051e-01, 1.8691e+00, -1.9103e-01],
[-8.3853e-01, 2.0364e-01, -2.5151e-01, -8.4897e-01, -5.6467e-01],
[ 1.6336e-01, -1.4972e-03, 1.6723e+00, -6.8816e-01, -6.8300e-01],
[-2.6995e-01, 1.7414e+00, -6.0668e-01, 1.4826e+00, 2.7362e-01],
[-4.3352e-02, -2.6302e-01, 1.3160e+00, -3.7131e-02, -3.0329e-01],
[-5.3816e-02, -2.1601e+00, -2.5578e-01, -2.9828e-01, -9.6168e-02],
[-1.3576e+00, -1.4366e-01, 2.8796e-01, 1.5117e+00, 8.3077e-01],
[-7.3763e-01, -8.1732e-01, 2.3481e-01, -5.9262e-01, -1.1383e+00],
[-2.1493e+00, -3.1500e-01, 4.4446e-01, 2.6473e-01, 5.3921e-01],
[-8.5790e-01, 2.4494e-01, -5.0341e-01, 1.5175e+00, -7.0211e-01],
[-7.1657e-01, -5.8821e-02, -6.1985e-01, 7.7105e-01, 1.1907e-01],
[ 6.5331e-01, -1.1482e+00, -3.7885e-01, -8.8140e-01, -9.0716e-01],
[-2.6995e-01, 1.7414e+00, -6.0668e-01, 1.4826e+00, 2.7362e-01],
[-3.5049e-01, 2.1535e+00, -3.3688e-01, -8.3146e-01, -1.9835e-01],
[ 4.5430e-01, 1.4338e+00, 8.7068e-01, -1.5256e-01, -5.5994e-01],
[ 2.7393e-02, 1.2252e-01, 1.1776e-01, -2.5576e-01, -9.0140e-01]],
grad_fn=<EmbeddingBackward0>)
'''4. 文本的数据分析
4.1 文本数据分析介绍
4.1.1 概念:
也称为文本挖掘或文本分析,从非结构化的文本数据中提取有价值的信息、分类、主旨等
4.1.2 作用:
能够有效帮助我们理解数据语料,快速检查出语料可能存在的问题,并指导之后模型训练过程中一些超参数的选择。
4.1.3主要方法:
**标签数量分布:**在分类问题中,各个类别标签所对应的样本数量的分布情况。训练集中各个标签的样本数据量应该均衡。
**句子长度分布:**指数据集中各个句子的长度(通常以词语数量来衡量)的分布情况。数据处理时要去除过长、过短的句子,这种一般是脏数据。
词频统计: 指统计文本数据集中每个词语出现的频率。 可以更好理解句意,或删除高频的停用词。
**关键词词云:**一种可视化技术,以图形化的方式展示文本中词语的频率,通常频率越高的词语显示得越大。
4.2 数据集说明
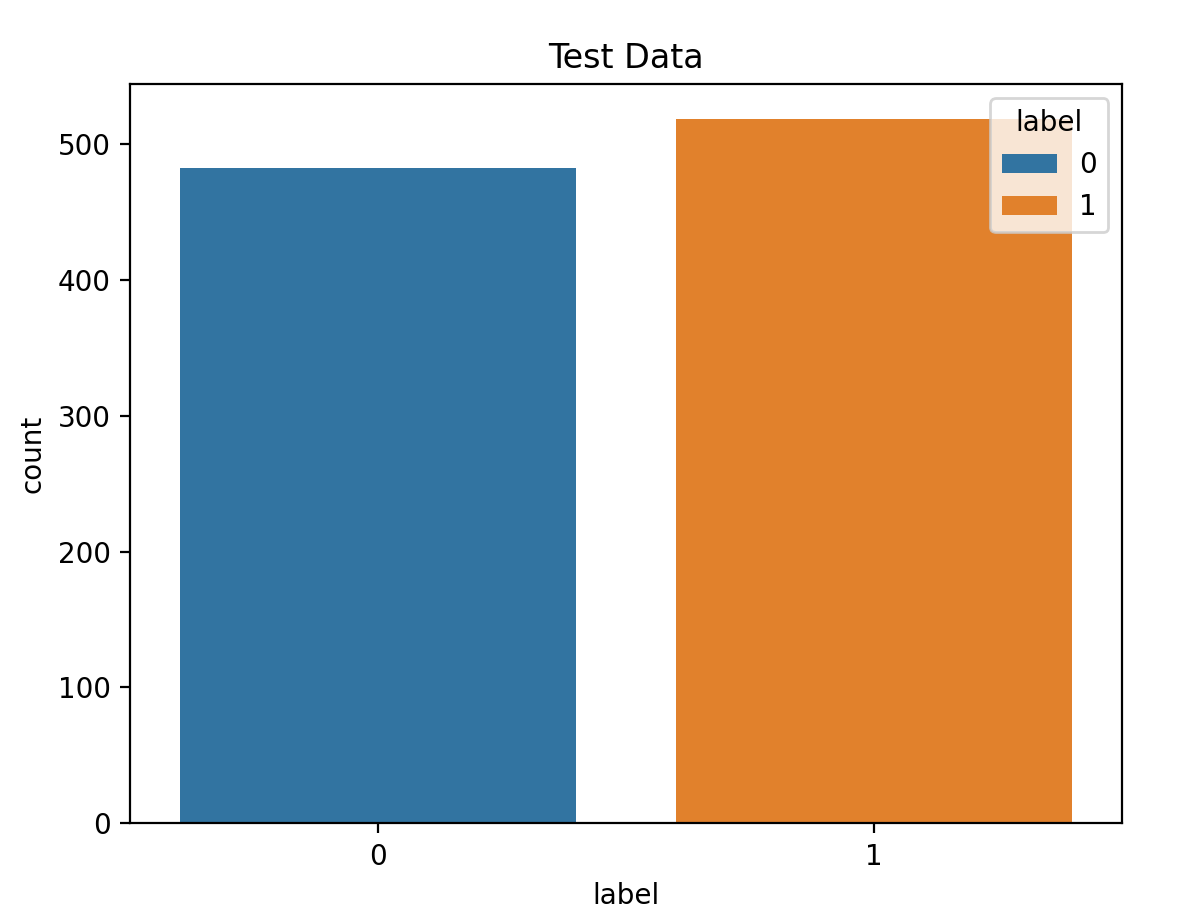
4.3 获取标签数量分布
python
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
matplotlib.use("TkAgg")
data_train = pd.read_csv(r'./data/train.tsv', sep="\t")
data_test = pd.read_csv(r'./data/dev.tsv', sep="\t")
# print(data_train.head(5))
sns.countplot(data=data_train, x="label", hue="label")
plt.title("Train Data")
plt.show()
sns.countplot(data=data_test, x="label", hue="label")
plt.title("Test Data")
plt.show()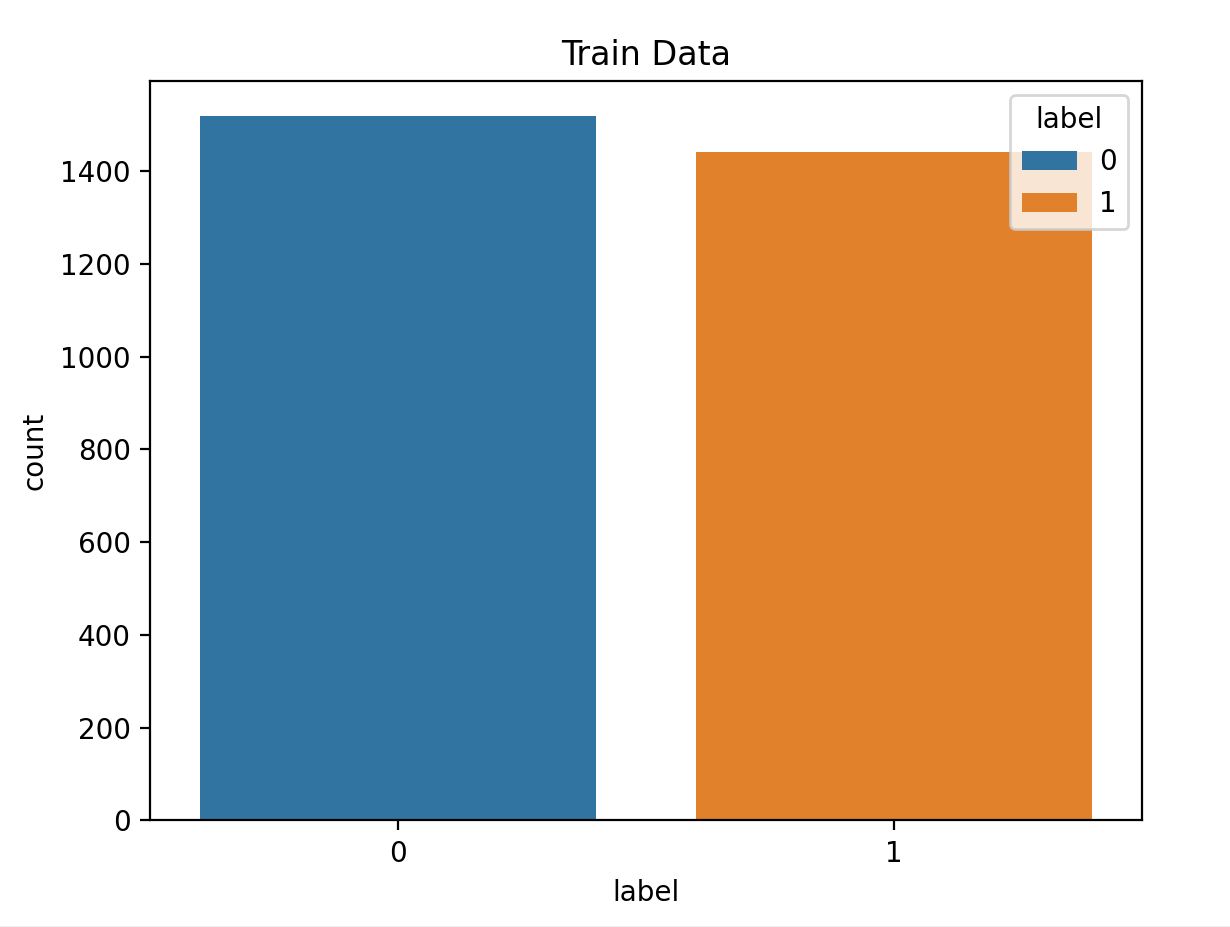
4.4 获取句子长度分布
python
import matplotlib, jieba
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
matplotlib.use("TkAgg")
# 读取训练集数据,以"\t"为分隔符
data_train = pd.read_csv(r'./data/train.tsv', sep="\t")
# 读取测试集数据,以"\t"为分隔符
data_test = pd.read_csv(r'./data/dev.tsv', sep="\t")
# 可视化字符长度
data_train["sentence_len"] = list(map(lambda x: len(x), data_train["sentence"]))
data_test["sentence_len"] = list(map(lambda x: len(x), data_test["sentence"]))
# print(data_train.head())
# sns.countplot(data=data_train, x="sentence_len", hue="label")
# plt.title("Train Data")
# plt.show()
# sns.countplot(data=data_test, x="sentence_len", hue="label")
# plt.title("Test Data")
# plt.show()
#
sns.displot(data=data_train, x="sentence_len", kde=True)
plt.title("Train Data")
plt.show()
sns.displot(data=data_test, x="sentence_len", kde=True)
plt.title("Test Data")
plt.show()
# 可视化词的长度
data_train["word_len"] = list(map(lambda x: len(jieba.lcut(x)), data_train["sentence"]))
data_test["word_len"] = list(map(lambda x: len(jieba.lcut(x)), data_test["sentence"]))
# print(data_train.head())
# sns.countplot(data=data_train, x="sentence_len", hue="label")
# plt.title("Train Data")
# plt.show()
# sns.countplot(data=data_test, x="sentence_len", hue="label")
# plt.title("Test Data")
# plt.show()
#
sns.displot(data=data_train, x="word_len", kde=True)
plt.title("Train Data")
plt.show()
sns.displot(data=data_test, x="word_len", kde=True)
plt.title("Test Data")
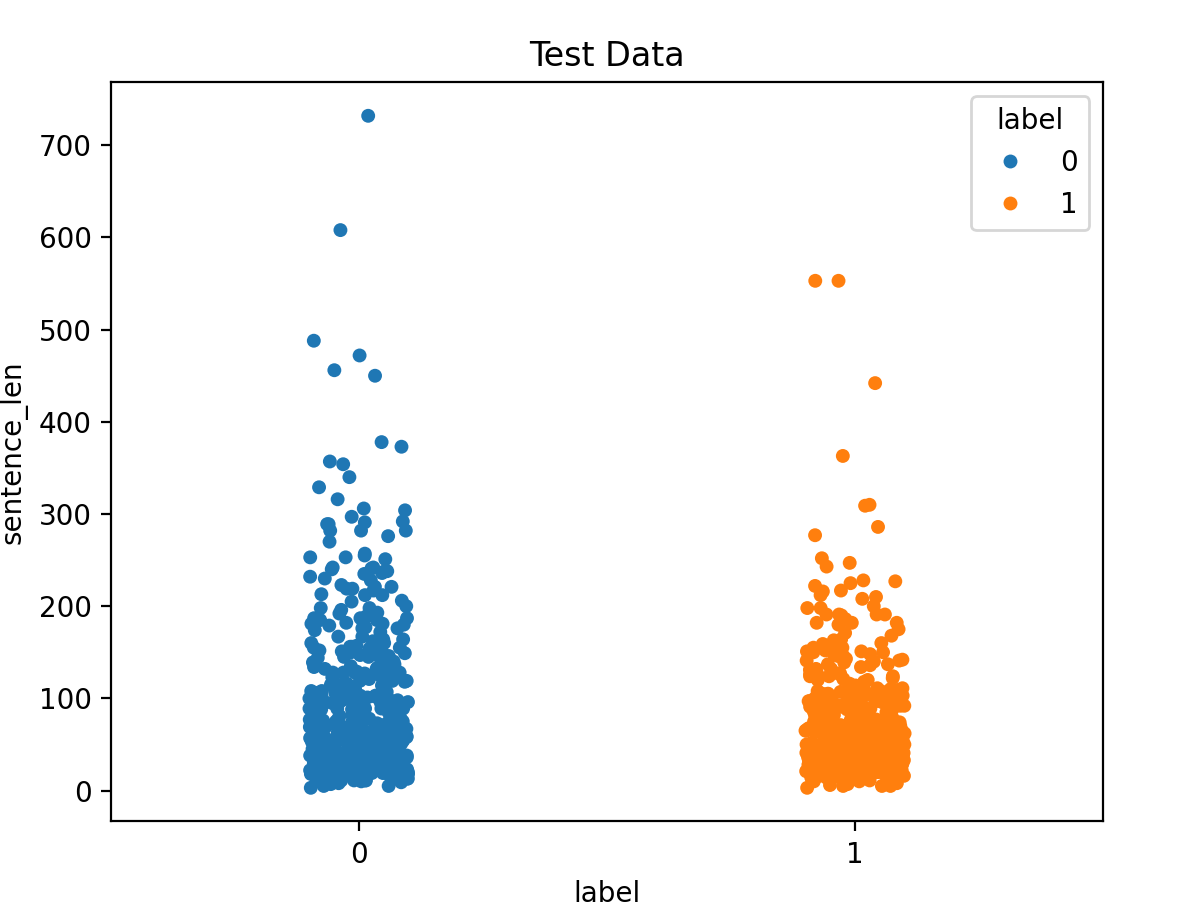
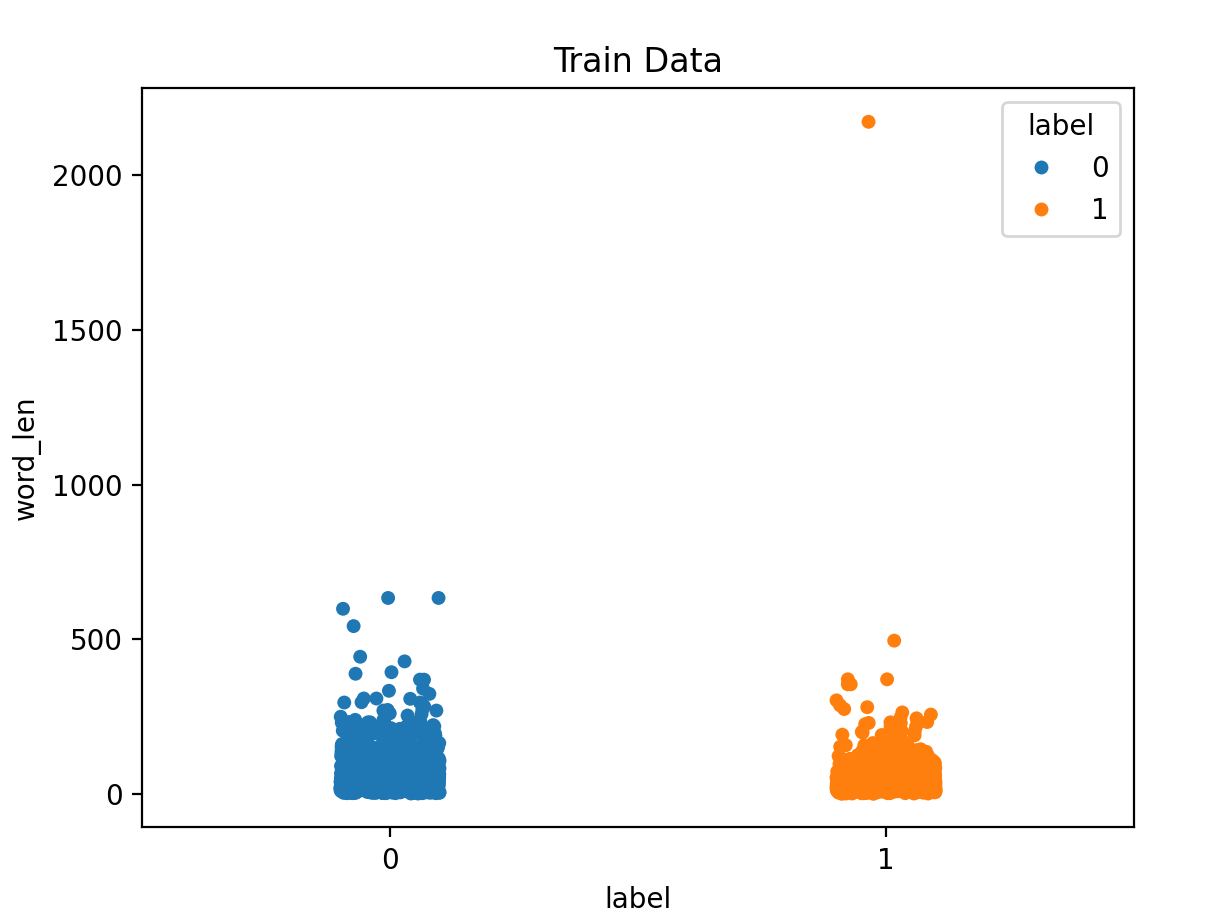
plt.show()4.5 获取正负样本长度散点分布
python
import matplotlib, jieba
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
matplotlib.use("TkAgg")
# 读取训练集数据,以"\t"为分隔符
data_train = pd.read_csv(r'./data/train.tsv', sep="\t")
# 读取测试集数据,以"\t"为分隔符
data_test = pd.read_csv(r'./data/dev.tsv', sep="\t")
# print(data_train.head(5))
# 字符长度
data_train["sentence_len"] = list(map(lambda x: len(x), data_train["sentence"]))
data_test["sentence_len"] = list(map(lambda x: len(x), data_test["sentence"]))
sns.stripplot(data=data_train, y="sentence_len", x="label", hue="label")
plt.title("Train Data")
plt.show()
sns.stripplot(data=data_test, y="sentence_len", x="label", hue="label")
plt.title("Test Data")
plt.show()
# 词的长度
data_train["word_len"] = list(map(lambda x: len(jieba.lcut(x)), data_train["sentence"]))
data_test["word_len"] = list(map(lambda x: len(jieba.lcut(x)), data_test["sentence"]))
sns.stripplot(data=data_train, y="word_len", x="label", hue="label")
plt.title("Train Data")
plt.show()
sns.stripplot(data=data_test, y="word_len", x="label", hue="label")
plt.title("Test Data")
plt.show()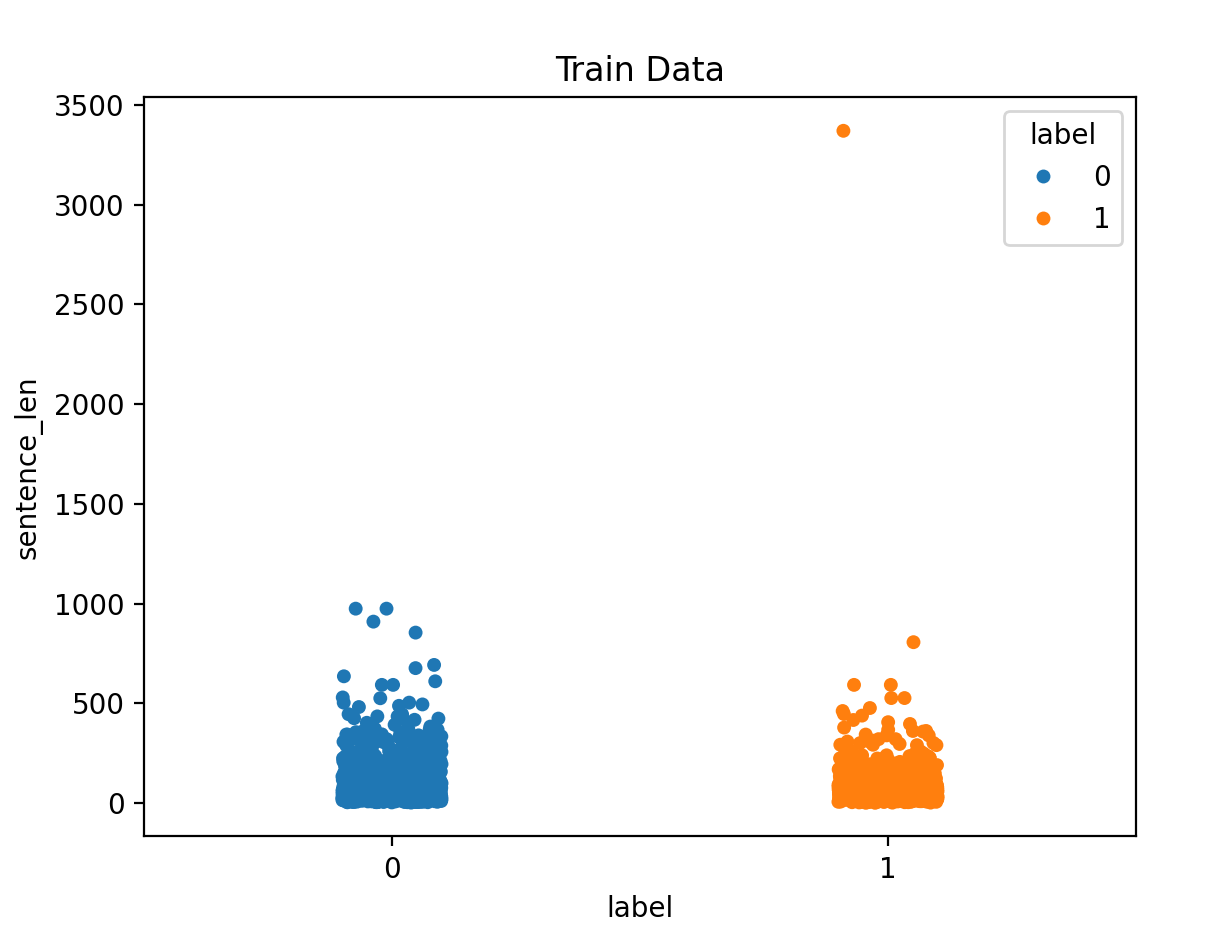
4.6 获取不同词汇总数统计
chain的作用:将各个可迭代对象串联起来
python
from itertools import chain
import matplotlib, jieba
import pandas as pd
# 读取训练集数据,以"\t"为分隔符
data_train = pd.read_csv(r'./data/train.tsv', sep="\t")
# 读取测试集数据,以"\t"为分隔符
data_test = pd.read_csv(r'./data/dev.tsv', sep="\t")
train_vocab = set(chain(*map(lambda x : jieba.lcut(x),data_train["sentence"])))
test_vocab = set(chain(*map(lambda x: jieba.lcut(x), data_test["sentence"])))
print(train_vocab)
print(test_vocab)
'''
输出:
{'号楼', '布局', '摆设', '心中', '赫赫', '派', '嬉笑', '平心'}
{'号楼', '布局', '摆设', '心中', '赫赫', '派', '嬉笑', '平心'}
'''4.7 获取训练集、验证集高频形容词词云
python
from itertools import chain
import pandas as pd
from jieba import posseg
from wordcloud import WordCloud
import matplotlib
import matplotlib.pyplot as plt
matplotlib.use("TKAgg")
# 2.分词获取形容词
def get_adj_word(sentence):
word_list = []
for word, flag in posseg.lcut(sentence=sentence):
if flag == "a":
word_list.append(word)
return word_list
# 3.绘制词云
def wordcloud_plt(keyword_list):
word_cloud = WordCloud(font_path=r'./data/SimHei.ttf', max_words=50, background_color="white")
keyword_string = " ".join(keyword_list)
word_cloud.generate(keyword_string)
plt.imshow(word_cloud)
plt.axis("off")
plt.show()
if __name__ == '__main__':
# 1.获取数据
# 读取训练集数据,以"\t"为分隔符
data_train = pd.read_csv(r'./data/train.tsv', sep="\t")
# 读取测试集数据,以"\t"为分隔符
data_test = pd.read_csv(r'./data/dev.tsv', sep="\t")
# 1.1 获取正样本数据
train_positive_data = data_train[data_train["label"] == 1]["sentence"]
test_positive_data = data_test[data_test["label"] == 1]["sentence"]
# print(train_positive_data.head())
# 1.2 获取负样本数据
train_negative_data = data_train[data_train["label"] == 0]["sentence"]
test_negative_data = data_test[data_test["label"] == 0]["sentence"]
# 1.3 分词,提取形容词
adj_train_positive = list(chain(*map(lambda x: get_adj_word(x), train_positive_data)))
adj_train_negative = list(chain(*map(lambda x: get_adj_word(x), test_positive_data)))
adj_test_positive = list(chain(*map(lambda x: get_adj_word(x), train_positive_data)))
adj_test_negative = list(chain(*map(lambda x: get_adj_word(x), test_negative_data)))
# print(adj_train_positive)
wordcloud_plt(adj_train_negative)
wordcloud_plt(adj_train_positive)
wordcloud_plt(adj_test_positive)
wordcloud_plt(adj_test_negative)输出示例:
差评:

好评:

**分析:**上图中的正样本大多数是褒义词, 而负样本大多数是贬义词, 基本符合要求, 但是负样本词云中也存在"不错"、"好"这样的褒义词。
可能原因:① 训练集数据不准确;② 分词时将 "不好" 分为了 "不" 和 "好"。
解决方案:
第一种可以通过人为再次处理数据解决。
第二种,可以使用特征预处理,让分词结合上下文或相邻n个词,从而使语义更加饱满、明确。
5. 文本的特征处理
5.1 n-gram特征
概念:
它通过将文本中的相邻n个词(或字符)组合起来,形成新的特征表示,可以用于很多任务,如文本分类、语言建模、机器翻译,使数据根据意义
常用的n-gram特征是bi-gram和tri-gram特征, 分别对应n为2和3
作用:
捕捉文本中词语之间的局部上下文信息,可以有效的减少分词过小或分类错误导致的脏数据的影响。
例如: "i" ,"am" ,"not" ,"happy" 中将 "not"与"happy" 组合起来,而不是将happy单独来分析,使得含义更加准确
实现方式:
**zip方法:**将两个可迭代对应中的数据遍历、滑动窗口的方式,转换为一个(n1,n2)的上下文组合
python
input_list = [1, 3, 2, 1, 5, 3]
n = 2
print(set(zip(*[input_list[i:] for i in range(n)])))
# 输出:{(2, 1), (1, 5), (5, 3), (3, 2), (1, 3)}sklearn实现:
python
# sklearn实现
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
"I love NLP.",
"NLP is fun!",
"I study natural language processing."]
transform = CountVectorizer(ngram_range=(2, 2))
x = transform.fit_transform(corpus)
print(transform.get_feature_names_out())
print(x.toarray())
'''
输出:
['is fun' 'language processing' 'love nlp' 'natural language' 'nlp is'
'study natural']
[[0 0 1 0 0 0]
[1 0 0 0 1 0]
[0 1 0 1 0 1]]
'''5.2 文本长度规范
为什么要进行文本长度规范?
① 防止过长、过短的数据的影响,文本过长可能会有很多无效数据
② 一般模型的输入需要等尺寸大小的矩阵
③ 数据一致,方便后续进行的统计分析和可视化
如何进行文本长度规范?
一般使用截断+填充的方式,指定最大长度 过长的进行截断、过短的进行填充,从而统一文本长度。
也可根据实际情况只选择 截断或填充。
如何选择是在前边截断(填充) 还是后边截断(填充)?
NLU:后边截断、填充
NLG: 前面截断、填充
代码示例------实现文本的截断、填充
python
def pad_truncation(sequence, max_len, truncation="pre",padding="pre",value=0):
'''
:param sequence: 待处理语料
:param max_len: 词表允许最大长度
:param truncation: 截断位置,从头或者从尾
:param padding: 填充位置,从头或者从尾
:param value: 填充的数据
:return: 处理后统一长度的数据
'''
# truncation
# 从头截断
if len(sequence) > max_len:
if truncation == "pre":
sequence = sequence[:max_len]
else:
sequence = sequence[-max_len:]
# pading
if len(sequence) < max_len:
# 从头添加
length = max_len - len(sequence)
if padding == "pre":
sequence = [0]*length + sequence
else:
sequence = sequence + [0]*length
return sequence
x_train = [[1, 23, 5, 32, 55, 63, 2, 21, 78, 32, 23, 1],
[2, 32, 1, 23, 1]]
new_list = []
for word in x_train:
result = pad_truncation(word, max_len=8)
new_list.append(result)
print(new_list)
# 输出:[[1, 23, 5, 32, 55, 63, 2, 21], [0, 0, 0, 2, 32, 1, 23, 1]]