文章目录
-
- 前言
-
- [传统 LLM vs ReAct Agent 对比](#传统 LLM vs ReAct Agent 对比)
- [一、什么是 ReAct ?](#一、什么是 ReAct ?)
- [二、为什么 ReAct 是刚需?](#二、为什么 ReAct 是刚需?)
- [三、ReAct 的核心执行循环(The Loop)](#三、ReAct 的核心执行循环(The Loop))
-
- [底层 Prompt 模版是如何驱动这个循环的?](#底层 Prompt 模版是如何驱动这个循环的?)
- [四、ReAct 的硬伤与改良](#四、ReAct 的硬伤与改良)
- 五、总结与前沿演进
-
- [现代 Agent 架构图](#现代 Agent 架构图)
前言
随着大语言模型(LLM)的爆发,Agent(智能体) 已成为下一代 AI 应用的核心范式。很多人误以为 Agent 只是"更聪明的 Chatbot",但两者的本质区别在于:
传统 LLM vs ReAct Agent 对比
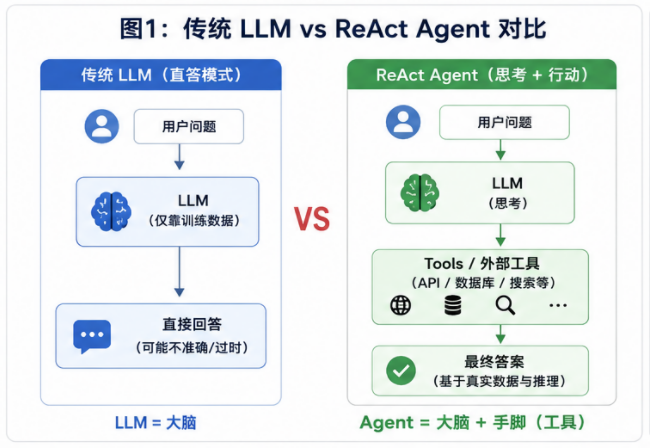
传统 LLM 是"闭卷考试"或"直觉脑暴",只能依靠训练期记忆的权重进行文本生成;
Agent 则拥有了"反思能力(Reasoning)"与"手脚(Tools)",能够自主规划路径并改变物理或数字世界。
在众多 Agent 架构中,由普林斯顿大学与 Google 联合提出的 ReAct(Reason + Act) 拓扑结构,是目前最经典、落地最稳健的基础设计模式。
一、什么是 ReAct ?
ReAct 的核心逻辑是 "协同演进":将大模型的协同推理(Reasoning)与特定任务的行动(Action)紧密结合。
-
Reason(推理): 动态生成、维护和更新行动计划,处理异常,追踪状态。
-
Act(行动): 与外部环境(如 API、数据库、搜索引擎)进行交互,获取新知识。
二、为什么 ReAct 是刚需?
大模型存在三大"先天残疾",ReAct 通过架构设计完美对其进行了"外骨骼补偿":
-
时效性断层(Knowledge Cutoff): 无法获取实时及私域数据(如今日天气、公司昨日财报)。
-
缺乏严谨计算与逻辑确定性: LLM 本质是概率自回归模型,不擅长高精度数学计算和确定性逻辑判断。ReAct 可以通过 Act 调用Tools解决。
-
无法产生"副作用"(Side Effects): 传统 LLM 无法改变外部世界。ReAct 赋予其发送邮件、修改数据库、控制物理硬件(如智能家居、机械臂)的能力。
LLM (脑) + Prompt (神经) + Tools (手脚) = Agent (智能体) \text{LLM (脑)} + \text{Prompt (神经)} + \text{Tools (手脚)} = \text{Agent (智能体)} LLM (脑)+Prompt (神经)+Tools (手脚)=Agent (智能体)
三、ReAct 的核心执行循环(The Loop)
在实际执行中,ReAct 并不是线性的,而是一个严格的闭环状态机(State Machine) 。
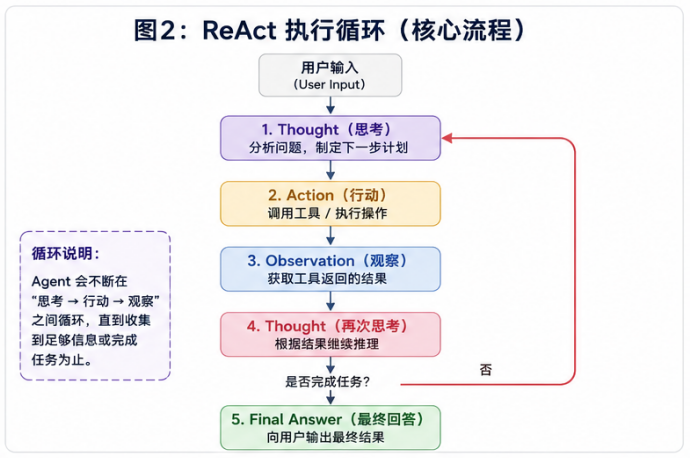
底层 Prompt 模版是如何驱动这个循环的?
为了让大模型严格按照这个流程走,底层的系统提示词(System Prompt)通常被设计为Few-Shot(少样本提示)或ReAct 规范模版:
System Prompt 示例
你是一个具备工具调用能力的 AI 助手。请严格按照以下格式回答问题,不要一次性输出所有内容,每次必须等待 Observation 的结果:
Thought: 思考你当前需要做什么,还需要什么信息。
Action: 工具名称 输入参数(可选工具:WeatherAPI, SQL_Query, Python_Executor)
Observation: 工具返回的真实结果(此步骤由系统输入,你无需自己编造)
... (重复上述 Thought/Action/Observation 步骤)
Final Answer: 给出最终针对用户的完美回答。
四、ReAct 的硬伤与改良
在agent开发中,纯粹的 ReAct 方案面临巨大的挑战,通常需要进行架构改良。
| 致命缺点 | 现象描述 | 解决方案 |
|---|---|---|
| 1. 恐怖的 Token 消耗 | 每一轮 Loop 都要把之前所有的 Thought、Action、Observation 重新作为 Context 喂给模型,Token 消耗呈几何级数增长。 | Prompt 压缩技术 / 状态精简: 仅保留上一步的 Observation 和关键 Plan,利用 Mem0 等长记忆模块提取核心线索。 |
| 2. 延迟高(Latency) | 一次用户交互需要经历 3-5 次 LLM 的串行生成和网络 I/O。用户通常需要等待 10 秒以上。 | Streaming(流式输出)展现思考过程: 让用户实时看到 AI 的 Thought,将"等待焦虑"转化为"看 AI 思考的趣味性"。 |
| 3. 幻觉与"死循环" | 模型可能会生成错误的 Action 参数(Tool Execution Error),或者陷入 Thought -> Action -> Error -> Thought 的无限死循环。 | 强类型约束(Json Mode / Function Calling): 不再依靠纯文本匹配 Action,而是利用大模型的 Function Calling 特性输出标准的 JSON;设置 Max_Loops = 5 的硬性熔断机制。 |
五、总结与前沿演进
ReAct 模式的本质,是让大模型从"单次文本生成器"进化为"图灵完备的自主状态机"。
在 2026 年的今天,单纯的 ReAct 正在向更高级的架构演进:
-
Plan-and-Solve(先规划再执行): 克服 ReAct"走一步看一步"导致的短视,先全局拆解 Task List,再用 ReAct 执行子任务。
-
Reflection / Self-Correction(反思机制): 当 Observation 报错时,引入独立的批评者(Critic)Agent 纠正当前行为,防止死循环。
现代 Agent 架构图
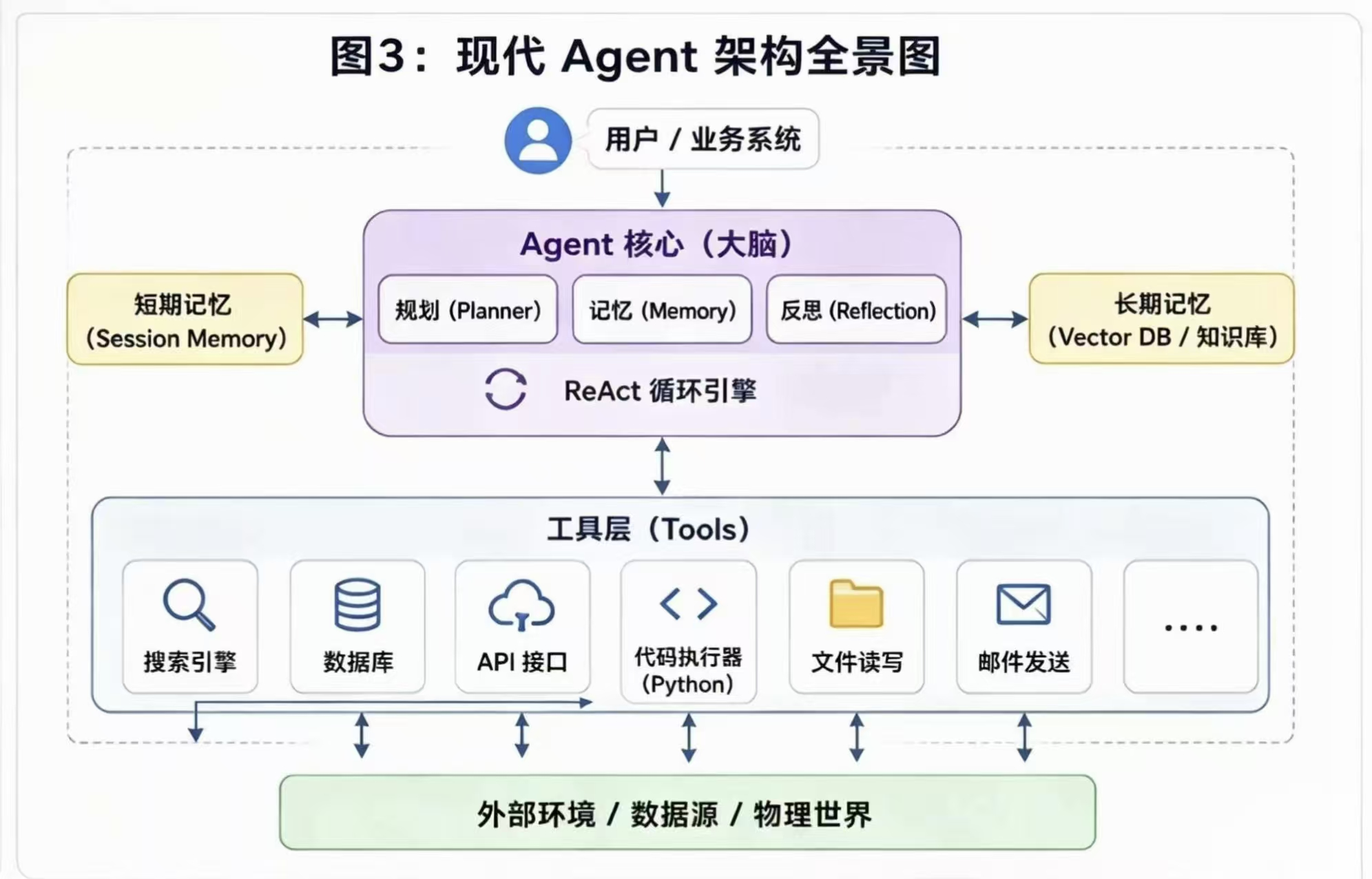
一句话核心:
传统的 LLM 给你答案(Answers) ,而基于 ReAct 架构的 Agent 给你结果(Results)。