AudioX-Turbo:面向通用音频生成的高效多模态统一框架
作者 :田泽越、柯磊、刘昭洋、袁瑞彬、薛刘梦、杨巨九、陈伟嘉、谭旭、陈启峰、薛巍、郭毅可
单位 :香港科技大学、清华大学、Noiz AI、独立研究者
(* 同等贡献;† 通讯作者)
摘要
依托灵活多模态控制信号的音频与音乐生成技术具备广泛应用价值,但该领域目前存在三大核心难题:1)缺乏通用的多模态建模框架;2)缺少大规模高质量训练数据;3)多步扩散采样带来极高的推理成本 。针对以上问题,本文提出 AudioX-Turbo ------ 一套可实现任意输入转音频的统一高效生成框架,支持文本、视频、音频等多种模态作为控制条件。
本框架采用师生模型架构 :教师模型 AudioX-Base 基于多模态扩散变换器 搭建,并搭配多模态自适应融合模块 ,实现不同多模态输入的特征对齐,保障高保真音频合成效果。随后本文结合适配流匹配的分布匹配蒸馏算法,将教师模型蒸馏为仅需少量采样步的学生模型 AudioX-Turbo;同时引入基于扩散的判别器,进一步提升少步生成的音质表现。
为支撑模型训练,团队搭建了IF-caps-Pro 大规模高质量数据集。该数据集通过两阶段数据采集与标注流程构建,总计包含约 920 万条样本。本文在多项主流基准测试集上开展全面实验,结果表明:AudioX-Turbo 在文本转音频、文本转音乐等任务中均取得顶尖性能;模型仅需4 步采样 即可完成生成,相比传统多步基线模型,函数评估次数最多可减少约 25 倍。实验证明,该框架不仅能基于各类多模态指令完成音频生成,同时具备出色的指令跟随能力与推理效率。
关键词:音频生成;扩散模型;高效推理
一、引言
近年来,音效与音乐生成技术成为多媒体内容创作的核心分支,在社交媒体、影视制作、电子游戏等场景中发挥重要作用,能够强化内容感染力、提升观众沉浸感。高质量音频创作不仅丰富了多媒体内容形态,也拓展了创意表达的边界。
但传统人工音频制作耗时费力,且对专业技能要求极高,因此音频生成自动化成为重要研究方向。现有相关研究虽取得一定进展,但仍存在明显局限:当前主流模型大多为单任务专用模型,输入、输出模态受限,仅支持文本转音频、视频转音频等单一条件生成,且往往只能单独制作音效或音乐。
尽管业内已出现部分支持多输入的统一模型,但这类模型普遍存在模态组合灵活性不足、指令跟随能力薄弱 的问题。造成该现状的首要原因是高质量多模态训练数据稀缺:现有数据集大多面向单一任务设计,仅适配某一种控制模态,难以支撑通用模型训练。
除模型结构与数据瓶颈外,推理效率低下 也是易被忽视的痛点。当前顶尖音频生成模型普遍基于扩散模型或流匹配技术,求解常微分方程需要数十至上百次连续函数运算,采样成本高、推理延迟大,无法适配交互式内容创作、实时视频配音等低延迟场景。图像领域的分步蒸馏技术已大幅提升生成速度,但该方案在多模态条件音频生成中的应用仍处于空白阶段。此外,激进的少步采样策略,还容易破坏跨模态对齐效果与指令跟随能力,而这两点正是可控音频生成的核心。
基于上述背景,本文提出 AudioX-Turbo ------ 面向任意输入转音频的统一高效生成框架。研究思路如下:
-
先训练多步多模态教师模型 AudioX-Base,实现高保真音频合成;再将其蒸馏为轻量少步学生模型 AudioX-Turbo,二者共享变换器主干网络。本文选用多模态扩散变换器(MMDiT) 作为基础架构,在统一多模态控制信号的同时,保留音频高保真生成能力。
-
新增轻量化多模态自适应融合模块,对不同模态特征进行权重调节与对齐,削弱模态间干扰,进一步提升音频质量与跨模态控制效果。
-
针对少步高效推理,将分布匹配蒸馏适配至流匹配范式,并搭配扩散判别器。该方案可在大幅提速的同时,保障激进少步采样下的跨模态对齐效果,让学生模型在推理提速的前提下,生成音质比肩教师模型。
-
为解决数据短缺问题,设计两阶段数据构建流程:第一阶段采集大规模视频 - 音频、视频 - 音乐原始数据;第二阶段依托 Gemini 2.5 Pro 与 Qwen2-Audio 串联模型,完成细粒度多模态标注。最终构建出 IF-caps-Pro 数据集,包含约 130 万条通用音频样本与 790 万条音乐样本,为通用型 "任意输入转音频" 模型提供充足训练数据。
依托大规模数据集与统一架构,本模型展现出优异的综合性能与指令跟随能力。为此,本文还专门构建了 T2A-bench 基准集,用于量化评估文本转音频任务的指令跟随效果。大量实验证明:AudioX-Turbo 在各类任务与基准测试中达到或超越当前顶尖模型;仅 4 步采样即可实现与多步教师模型持平的音质,函数评估次数最多缩减 25 倍。
同时本文还发现一个有趣现象:统一训练会带来跨模态正则化效应------ 优化文本监督信息的质量与细粒度,能够提升整体模态对齐效果,进而同步增强所有控制模态下的模型性能,该结论也为后续多模态音频生成研究提供了实践参考。
本文主要创新点总结如下:
-
提出 AudioX-Turbo 统一框架,支持文本、视频、音频等多类输入,可同时完成音效与音乐生成,打破传统专用模型的输入输出限制;结合适配流匹配的分布匹配蒸馏技术,实现高效少步推理,为通用型音频生成模型的工程落地提供可行方案。
-
设计两阶段数据采集与标注流程,整合多类视频 - 音频、视频 - 音乐数据源,规模化生成细粒度多模态标注,构建总计 920 万样本的 IF-caps-Pro 数据集,填补了通用多模态音频生成的训练数据缺口。
-
在海量任务与主流基准集上开展系统性对比实验。结果证实,AudioX-Turbo 具备强大的多任务能力与顶尖的指令跟随能力;仅 4 步采样即可媲美多步教师模型,推理成本大幅降低。
二、相关研究
2.1 音频与音乐生成
深度生成模型极大推动了音频、音乐合成技术的发展,但现有方法大多仅支持单一模态或有限的控制条件:文本转音频模型专注于根据文本描述生成各类环境音;文本转音乐模型擅长创作结构完整的乐曲;视频转音频模型主要生成与画面同步的现场音效,部分模型会结合文本补充语义信息;视频转音乐则侧重为画面搭配适配曲风的配乐,强化影视叙事感。
现有框架功能单一,跨任务迁移与泛化能力较弱。与之不同,本文提出的统一框架可在同一套模型内,基于文本、视频、音频等各类输入,完成音效与音乐的全品类生成。
2.2 音频数据集
目前业内已针对文本转音频、文本转音乐、视频转音频等细分任务构建了专用数据集,但通用型统一模型的配套数据集仍十分匮乏。现有数据大多局限于单一控制模态与单一输出类型(仅音效或仅音乐),制约了通用音频生成模型的发展。本文构建的大规模多模态数据集,专门为统一音频、音乐生成任务设计,补充了该领域的数据短板。
2.3 扩散模型
去噪扩散模型是当前生成建模的主流技术,在图像、视频、音频合成领域均取得顶尖效果。但现有音频领域的扩散模型多聚焦于文本转音频等单一条件任务,无法适配 "任意输入转音频" 的通用场景。本文将扩散模型拓展至多条件生成场景,搭建更灵活、通用的技术范式。
2.4 扩散模型加速
分步蒸馏是降低扩散模型采样成本的主流方案。现有技术路线分为两类:一类是轨迹保留法 (渐进式蒸馏、一致性蒸馏、整流流等),用更少步数复刻教师模型的生成轨迹;另一类是分布匹配法(分布匹配蒸馏 DMD),放宽轨迹约束,直接对齐师生模型的输出分布,在少步生成场景下音质表现更优。
上述加速技术在图像领域已十分成熟,但在多模态音频生成中鲜有应用。本文将分布匹配思想结合流匹配技术,实现音频生成模型的高效蒸馏。
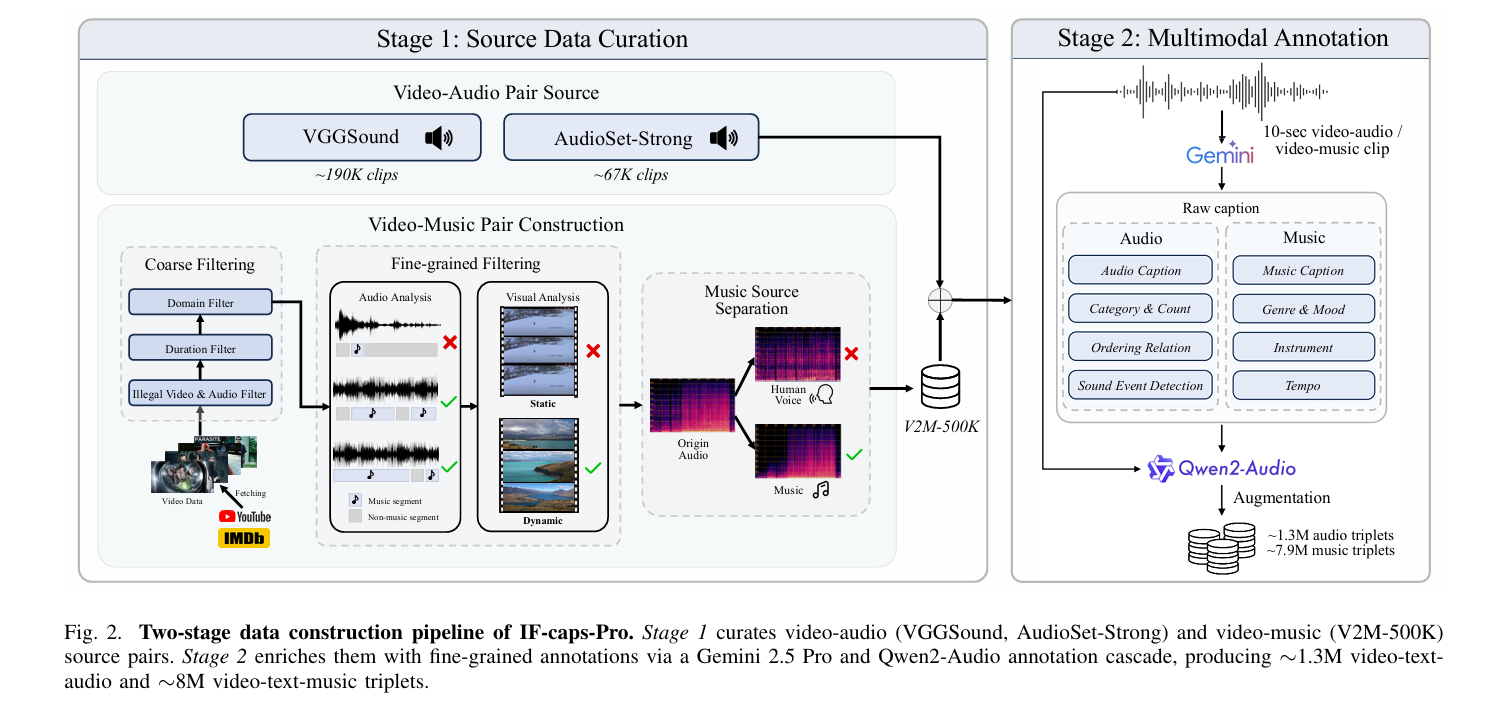
三、数据集构建
训练通用型 "任意输入转音频" 模型主要存在两大数据难题:其一,视频 - 音频公开数据集较为丰富,但大规模、高质量的视频 - 音乐数据集稀缺 ,现有数据存在体量小、曲风单一、质量参差不齐等问题;其二,即便拥有原始配对数据,也缺少支撑通用模型训练的细粒度多模态标注信息。
针对以上问题,本文设计两阶段数据构建流程,打造 IF-caps-Pro 数据集。
3.1 第一阶段:原始数据采集
-
视频 - 音频数据:直接采用业内主流公开数据集 VGGSound 与 AudioSet-Strong,两类数据经过严格筛选,包含可靠的事件类别标签,可为后续大模型标注提供基础关键词。
-
视频 - 音乐数据 :自主构建 V2M-500K 数据集。通过关键词检索 YouTube、IMDb 平台中画面与音乐高度绑定的视频(影视预告、广告、纪录片、日常短视频等),再经过两轮过滤:粗筛剔除音画损坏、时长异常、内容无关的视频;细筛借助预训练音频分类器与画质评估模型,保留音乐内容饱满、画面动态性强的片段;最后通过人声 / 环境音分离技术,提取纯净音乐轨道,最终得到高质量视频 - 音乐配对数据。
3.2 第二阶段:多模态标注流程
原始配对数据缺少丰富的文本描述,因此本文搭建双模型串联标注流水线,为每一段 10 秒音视频片段生成全局描述与结构化标签:
-
主标注:使用 Gemini 2.5 Pro 多模态大模型,生成全局描述文本,同时输出结构化字段(通用音频:事件类别、数量;音乐:曲风、乐器、节奏等)。
-
数据增广:由于 Gemini 推理成本较高,依托开源模型 Qwen2-Audio,结合原始标注与原始音频生成多样化描述文本,在控制成本的同时提升数据多样性。
最终产出约130 万条视频 - 文本 - 音频三元组 、790 万条视频 - 文本 - 音乐三元组。数据集涵盖海量音效、音乐类型与乐器,标注内容丰富多样,可支撑多任务统一模型训练。
四、通用 "任意输入转音频" 预训练框架
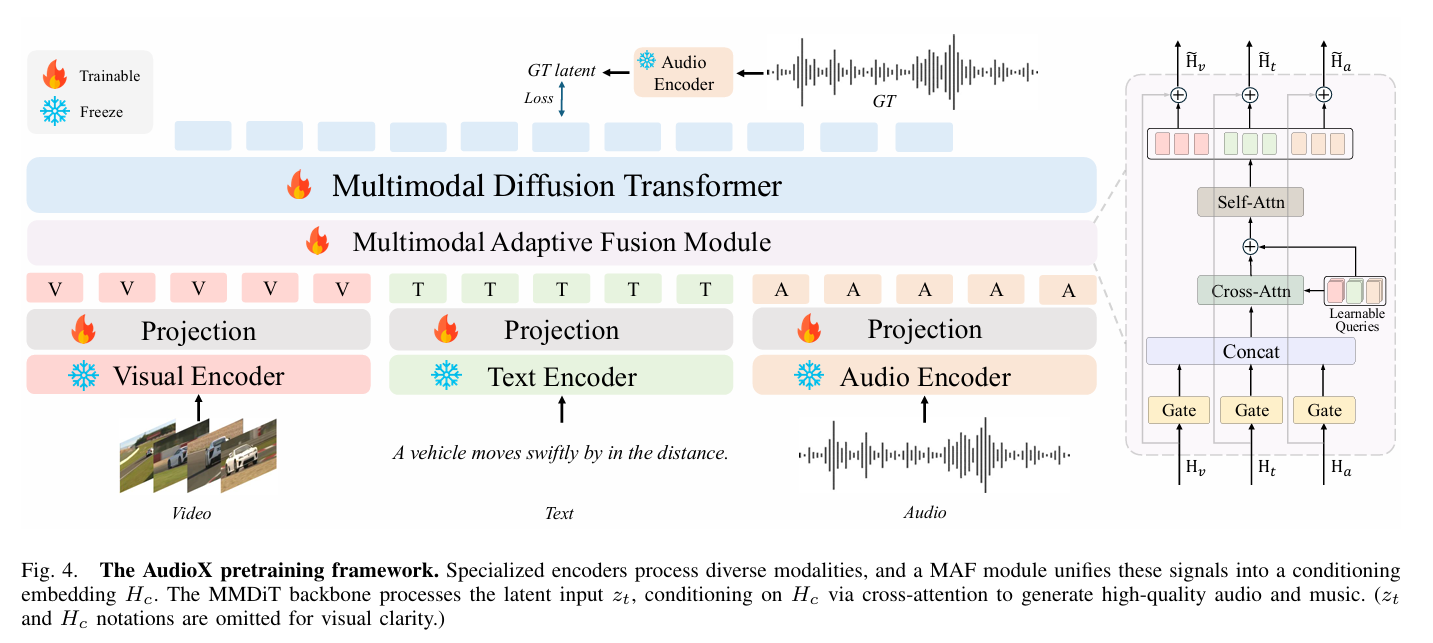
4.1 模型整体结构
模型主干为多模态扩散变换器(MMDiT),整体流程如下:
-
视频、文本、音频三类输入分别经过专属编码器提取特征;针对视频与音频的时序特性,额外使用时序变换器建模动态信息。
-
各类模态特征通过投影层,得到模态专属嵌入特征。
-
引入轻量化多模态自适应融合模块(MAF) 完成特征融合:该模块通过门控机制过滤噪声、重加权有效特征;再通过可学习查询向量与交叉注意力机制聚合多模态信息;最后借助自注意力整合全局上下文,输出校准后的多模态融合嵌入特征。
-
融合特征结合连续时间步,输入 MMDiT 主干网络,引导音频生成。
MAF 模块是解决多模态特征相互干扰的核心设计,能够有效提升多模态任务的生成质量与指令跟随能力。
4.2 模型训练
预训练阶段目标是基于流匹配框架,训练多模态教师模型 AudioX-Base,实现多条件下的高保真音频 / 音乐生成。
-
数据补全:若样本缺少某类模态输入,使用零填充处理;若无文本输入,则补充通用描述语句(如 "为该视频生成配乐")。针对音频补全、音乐续写任务,保留原始音频片段作为条件输入。
-
流匹配机制:将真实音频通过编码器映射至隐空间,定义噪声分布与数据分布之间的连续时间常微分方程(ODE),构建线性插值路径。模型学习预测路径对应的速度向量场,通过最小化预测值与真实向量场的均方误差完成训练。该机制可将各类多模态输入统一至隐空间,保障生成音频与控制条件高度契合。
五、分步蒸馏加速
本文通过模型蒸馏 ,将多步教师模型压缩为仅 4 步推理的学生模型 AudioX-Turbo,在保留音质的同时大幅降低推理开销。整体方案结合分布匹配蒸馏(DMD) 与基于扩散的判别器。
5.1 适配流匹配的分布匹配蒸馏
分布匹配蒸馏的核心目标:最小化学生模型输出分布与真实数据分布之间的 KL 散度。
-
模型推理时,学生模型从高斯噪声出发,按照 "去噪 - 重加噪" 逻辑逐步推演,在指定时间步完成去噪并输出预测结果。
-
由于无法直接求解学生分布的分数函数,本文引入辅助伪模型拟合学生输出分布,而冻结的教师模型提供真实数据分布的分数。
-
结合流匹配的数学特性,对损失函数进行推导适配,最终通过教师模型与伪模型的向量场差异构建损失,引导学生模型学习。
-
伪模型单独训练,持续追踪学生模型的输出分布变化;教师模型全程冻结,仅作为参考标准。
5.2 基于扩散的判别器
分布匹配损失可实现全局分布对齐,但难以捕捉音频高频细节与听觉质感。为此本文新增对抗训练目标:
-
复用冻结教师模型的前若干层变换器模块作为特征提取骨干,仅训练轻量化判别器头部,避免从零训练判别器带来的巨额成本。
-
不在纯净输出上做判别,而是对添加轻微噪声的隐向量进行真伪分类,防止判别器过拟合细微噪声,输出更有效的梯度信号。
-
采用铰链对抗损失训练判别器,学生模型(生成器)以欺骗判别器为目标,进一步提升音频的听觉真实感。
最终学生模型的总损失为分布匹配损失 + 对抗损失,平衡分布对齐与听觉质感。
5.3 蒸馏训练细节
-
学生模型与伪模型均使用训练完成的教师模型权重初始化;将连续 ODE 轨迹压缩为4 步离散采样。
-
推理阶段将无分类器引导(CFG) 内置至学生模型,消除推理时的二次前向计算开销。
-
采用非对称更新策略:伪模型每更新 1 次,学生模型更新 5 次,避免伪模型过快过拟合。
六、实验
6.1 实验配置
-
编码器:视频特征使用 CLIP-ViT-B/32 + Synchformer 提取;文本使用 T5-base;音频采用专用音频自编码器。
-
模型规模:总参数量 27 亿,其中可训练参数 24 亿,MAF 模块仅 6000 万参数(轻量化);MMDiT 共 24 层,从零开始训练。
-
训练硬件:三集群 NVIDIA H800 80GB 显卡,总批次大小 240,训练约 10 万步;优化器选用 AdamW。
-
蒸馏配置:对抗损失权重设为 1,判别器复用教师模型前 6 层结构;采用逆学习率调度,并持续维护模型权重的指数移动平均值(EMA)保证稳定性。
6.2 评估指标
(1)客观指标
-
通用音质指标:KL 散度、 inception 得分 (IS)、PANNs 特征弗雷歇距离 (FD)、VGGish 特征音频弗雷歇距离 (FAD)、制作复杂度 (PC)、制作质量 (PQ)。
-
对齐指标:文本 - 音频对齐使用 CLAP 得分;视频 - 音频对齐使用 ImageBind 视听得分;额外新增视听对齐准确率、音画同步指标。
-
指令跟随指标(T2A-bench):类别准确率、数量准确率、顺序准确率、时间戳准确率。
-
效率指标:函数评估次数 (NFE)、推理延迟、实时因子 (RTF)。
(2)主观评估
邀请 10 名专业音频从业者,从整体音质 、与指令匹配度两个维度,对匿名样本进行 1~100 分打分。
6.3 核心实验结果
-
多任务生成性能
在文本转音频、视频转音频、文本 + 视频转音频、文本转音乐、视频转音乐等全品类任务中,AudioX-Base 与 AudioX-Turbo 均达到业内顶尖水平。即便作为通用模型,性能也不输各类单任务专用模型。
-
推理效率
AudioX-Turbo 仅需4 次函数评估(NFE=4),而传统多步模型最多需要 400 次评估,算力开销缩减约 25 倍;在单张 RTX 4090 显卡上,10 秒音频推理延迟仅 0.24 秒,实时因子远小于 1,可满足实时生成需求。同时,4 步采样下的音质与多步教师模型基本持平,而其他基线模型在少步采样下音质严重崩坏。
-
指令跟随能力
在自建 T2A-bench 基准集上,本模型的类别、数量、顺序准确率远超所有基线模型;在 AudioTime 时序基准集上,时序控制能力同样排名第一。且蒸馏后的 AudioX-Turbo 指令跟随能力未出现明显衰减。
-
拓展任务
在音频补全、音乐续写、图像转音频等拓展任务中,模型依旧保持优异性能,泛化能力突出。
6.4 消融实验
-
数据流水线 :本文两阶段标注方案产出的数据集,效果显著优于单一模型标注、公开第三方数据集;同时验证了高质量文本标注可带来跨模态正则化------ 优化文本监督,能同步提升视频转音频等其他任务的性能。
-
MAF 模块:门控机制、可学习查询注意力均为核心组件,移除任意一部分都会造成音质与对齐效果下降,完整模块是多模态融合的关键。
-
蒸馏策略:均匀时间步采样、搭配对抗损失的方案效果最优;复用教师模型浅层结构作为判别器,性价比与效果最佳。
-
训练目标:流匹配与传统扩散目标的生成质量接近,但流匹配更适配本文蒸馏架构。
-
数据集规模:扩大视频 - 音乐数据集体量后,音乐生成性能持续提升,证明数据规模对模型效果有正向增益。
七、总结与展望
7.1 工作总结
本文提出 AudioX-Turbo ,一套支持文本、视频、音频多类输入的统一高效音频 / 音乐生成框架:
-
结合多模态扩散变换器与多模态自适应融合模块,实现多模态条件下的高保真生成;
-
构建 IF-caps-Pro 大规模多模态标注数据集,解决通用模型训练的数据难题;
-
基于适配流匹配的分布匹配蒸馏与扩散判别器,实现极致少步推理,兼顾音质与效率;
-
自建 T2A-bench 基准集,系统验证模型顶尖的指令跟随能力。
大量实验证明,该框架集通用性、可控性、高效性于一体,具备极高的实际落地价值。
7.2 局限性与未来方向
-
现有模型仅支持10 秒短片段生成,无法满足完整影视配乐、长篇乐曲等长时序场景需求;
-
模型目前仅覆盖音效与音乐,暂不支持语音生成;
-
面对超复杂指令(大量叠加音效、严苛时间戳要求),指令跟随精度仍有提升空间。
未来研究方向:拓展长上下文建模、将语音纳入统一生成框架、强化时序监督提升精细控制能力、设计自适应步数推理方案。