【HistGBM 系列①】从决策树到梯度提升 ------ GBDT 原理精讲
文章目录
- [【HistGBM 系列①】从决策树到梯度提升 ------ GBDT 原理精讲](#【HistGBM 系列①】从决策树到梯度提升 —— GBDT 原理精讲)
-
- 前言
- 一、决策树:从直觉到数学
-
- [1.1 为什么需要决策树?](#1.1 为什么需要决策树?)
- [1.2 决策树的三个关键问题](#1.2 决策树的三个关键问题)
- [二、CART 回归树:递归二分法](#二、CART 回归树:递归二分法)
-
- [2.1 CART 的核心抽象](#2.1 CART 的核心抽象)
- [2.2 分裂准则:均方误差最小化](#2.2 分裂准则:均方误差最小化)
- [2.3 增益公式的等价形式(简化计算)](#2.3 增益公式的等价形式(简化计算))
- [2.4 精确贪心搜索算法](#2.4 精确贪心搜索算法)
- [2.5 叶节点的最优预测值](#2.5 叶节点的最优预测值)
- [2.6 停止条件](#2.6 停止条件)
- 三、单棵树的局限与集成学习的动机
-
- [3.1 偏差-方差的两难](#3.1 偏差-方差的两难)
- [3.2 两种集成哲学](#3.2 两种集成哲学)
- [3.3 对比小结](#3.3 对比小结)
- [四、从 Boosting 到 Gradient Boosting:关键一步](#四、从 Boosting 到 Gradient Boosting:关键一步)
-
- [4.1 最朴素的 Boosting 思路](#4.1 最朴素的 Boosting 思路)
- [4.2 换个角度看:残差拟合](#4.2 换个角度看:残差拟合)
- [4.3 一个重要的推广:残差 = 负梯度](#4.3 一个重要的推广:残差 = 负梯度)
- [五、GBDT 完整算法流程(MSE 版本)](#五、GBDT 完整算法流程(MSE 版本))
-
- [5.1 学习率 η 的关键作用](#5.1 学习率 η 的关键作用)
- [5.2 代码演示:传统 GBM 的收敛曲线](#5.2 代码演示:传统 GBM 的收敛曲线)
- [六、传统 GBDT 的性能瓶颈(量化分析)](#六、传统 GBDT 的性能瓶颈(量化分析))
-
- [6.1 精确贪心搜索的时间复杂度](#6.1 精确贪心搜索的时间复杂度)
- [6.2 内存占用](#6.2 内存占用)
- [6.3 问题总结](#6.3 问题总结)
- 七、关键概念总结
系列导航
- 【系列①】从决策树到梯度提升------GBDT 原理精讲(本篇)
- 【系列②】梯度提升的数学框架与二阶优化
- 【系列③】直方图加速------HistGBM 的核心创新
- 【系列④】HistGradientBoostingRegressor 深度解析
- 【系列⑤】调参实战与生产部署
前言
梯度提升决策树(Gradient Boosted Decision Trees,GBDT)是表格数据领域统治级的机器学习算法。从 Kaggle 竞赛到金融风控、从推荐系统到医疗诊断,以 XGBoost、LightGBM 为代表的 GBDT 变种几乎无处不在。
然而,大多数使用者的理解停在"调包+调参"层面------知道设置 n_estimators=500、learning_rate=0.1,却说不清梯度提升究竟在"提升"什么。
scikit-learn 从 0.21 版本起引入了 HistGradientBoostingRegressor------一个借鉴 LightGBM 核心思想的直方图加速实现,效率比传统 GradientBoostingRegressor 高出一个数量级。但要用好它,你必须理解它底层在做什么。
前置知识:监督学习基本概念(特征、标签、训练集/测试集)、损失函数的概念、导数的基本含义。
一、决策树:从直觉到数学
1.1 为什么需要决策树?
想象你要预测北京的房价。已知的信息包括:面积、楼层、到地铁站的距离、房龄。你的思维过程大概是:
- "面积 120 平以上,单价大概 8 万" → 这是一个if-else 判断
- "如果面积不到 120 平,那看看是不是学区房" → 这是条件嵌套
- "既不是大面积也不是学区,那老房子比新房子便宜" → 这是多级条件
决策树就是用数学语言描述这个思维过程:将特征空间递归地划分为互不重叠的矩形区域,每个区域输出一个常数预测值。
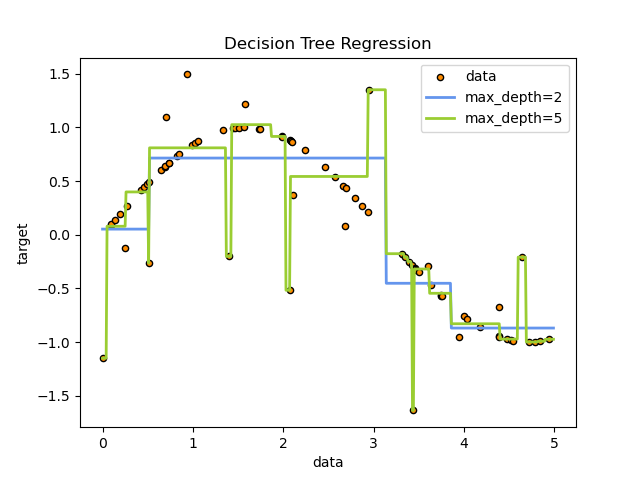
图:决策树通过一系列 if-then-else 规则将特征空间划分为多个区域,每个区域输出一个常数预测值。来源:scikit-learn 官方文档(BSD-3-Clause License)
1.2 决策树的三个关键问题
构建一棵决策树,本质上是在回答三个问题:
| 问题 | 含义 | 举例 |
|---|---|---|
| 在哪里分裂? | 选哪个特征、选哪个阈值来切分数据 | 用"面积 ≤ 100m²"还是"楼层 ≤ 5"? |
| 什么时候停止? | 树长大了该停在哪 | 叶节点样本数 < 20?到达深度上限? |
| 叶节点输出什么值? | 一个叶节点里有一堆样本,预测值取多少 | 取这些样本标签的均值?中位数? |
答案取决于你的目标。对于回归------预测一个连续值------CART 算法给出了最经典的解答。
二、CART 回归树:递归二分法
2.1 CART 的核心抽象
CART(Classification And Regression Tree,分类与回归树)由 Breiman 等人在 1984 年提出,是 GBDT 系列算法的基学习器。
一棵有 J J J 个叶节点的 CART 回归树 h ( x ) h(x) h(x) 可以写作:
h ( x ) = ∑ j = 1 J γ j ⋅ 1 x ∈ R j h(x) = \sum_{j=1}^{J} \gamma_j \cdot \mathbf{1}x \\in R_j h(x)=j=1∑Jγj⋅1x∈Rj
其中:
- R j ⊂ R d R_j \subset \mathbb{R}^d Rj⊂Rd 是第 j j j 个叶节点对应的输入空间区域(一个超矩形)
- γ j ∈ R \gamma_j \in \mathbb{R} γj∈R 是落入该区域的样本的预测值(一个常数)
- 1 ⋅ \mathbf{1}\\cdot 1⋅ 是指示函数,满足条件为 1,否则为 0
- 所有的 R j R_j Rj 互不重叠,且覆盖整个输入空间: ⋃ j = 1 J R j = R d , R i ∩ R j = ∅ ( i ≠ j ) \bigcup_{j=1}^J R_j = \mathbb{R}^d,\quad R_i \cap R_j = \emptyset \ (i \neq j) ⋃j=1JRj=Rd,Ri∩Rj=∅ (i=j)
换句话说:CART 回归树把整个特征空间一刀一刀切成 J J J 块,每块给你一个"均价"。
2.2 分裂准则:均方误差最小化
这是 CART 回归树最核心的数学部分。让我们一步步推导。
给定当前节点包含的样本集合 D = { ( x i , r i ) } i = 1 n \mathcal{D} = \{(x_i, r_i)\}_{i=1}^{n} D={(xi,ri)}i=1n,其中 r i r_i ri 是目标值(在 GBDT 的上下文中是伪残差,后面会讲到)。
定义:节点的均方误差
MSE ( D ) = 1 n ∑ i = 1 n ( r i − r ˉ ) 2 \text{MSE}(\mathcal{D}) = \frac{1}{n} \sum_{i=1}^{n} (r_i - \bar{r})^2 MSE(D)=n1i=1∑n(ri−rˉ)2
其中 r ˉ = 1 n ∑ i = 1 n r i \bar{r} = \frac{1}{n} \sum_{i=1}^{n} r_i rˉ=n1∑i=1nri 是该节点目标值的均值。
分裂操作 :给定特征 k k k 和分裂阈值 s s s,将节点分成左右两个子节点:
D L ( k , s ) = { ( x i , r i ) ∈ D : x i k ≤ s } \mathcal{D}L(k, s) = \{(x_i, r_i) \in \mathcal{D} : x{ik} \leq s\} DL(k,s)={(xi,ri)∈D:xik≤s}
D R ( k , s ) = { ( x i , r i ) ∈ D : x i k > s } \mathcal{D}R(k, s) = \{(x_i, r_i) \in \mathcal{D} : x{ik} > s\} DR(k,s)={(xi,ri)∈D:xik>s}
分裂的效果评估 :我们希望分裂后两个子节点内部的方差(均方误差)尽可能小。用数学表达,就是最大化分裂增益:
2.3 增益公式的等价形式(简化计算)
上面那个公式每次都要计算均值和方差。我们可以把它化成一个更高效的形式。
定义节点中目标值的"平方和分":
Score ( D ) = ( ∑ i ∈ D r i ) 2 ∣ D ∣ \text{Score}(\mathcal{D}) = \frac{(\sum_{i \in \mathcal{D}} r_i)^2}{|\mathcal{D}|} Score(D)=∣D∣(∑i∈Dri)2
那么分裂增益等价于:
Gain ( k , s ) = Score ( D L ) + Score ( D R ) − Score ( D ) \text{Gain}(k, s) = \text{Score}(\mathcal{D}_L) + \text{Score}(\mathcal{D}_R) - \text{Score}(\mathcal{D}) Gain(k,s)=Score(DL)+Score(DR)−Score(D)
推导过程:
展开 MSE ( D ) \text{MSE}(\mathcal{D}) MSE(D):
MSE ( D ) = 1 n ∑ i = 1 n ( r i 2 − 2 r i r ˉ + r ˉ 2 ) = 1 n ∑ i = 1 n r i 2 − ( ∑ r i ) 2 n 2 \text{MSE}(\mathcal{D}) = \frac{1}{n} \sum_{i=1}^n (r_i^2 - 2r_i\bar{r} + \bar{r}^2) = \frac{1}{n} \sum_{i=1}^n r_i^2 - \frac{(\sum r_i)^2}{n^2} MSE(D)=n1i=1∑n(ri2−2rirˉ+rˉ2)=n1i=1∑nri2−n2(∑ri)2
将左右子节点代入增益公式, ∑ r i 2 \sum r_i^2 ∑ri2 这部分在分裂前后不变(所有样本还在),消掉即得上面的等价形式。
**💡: Score ( D ) = ( ∑ r i ) 2 n \text{Score}(\mathcal{D}) = \frac{(\sum r_i)^2}{n} Score(D)=n(∑ri)2 度量的是一个节点"有多纯"------如果所有样本的目标值同号且绝对值大,Score 就大;如果正负混杂、互相抵消,Score 就小。分裂的目标是让两个子节点的 Score 之和尽可能大。
2.4 精确贪心搜索算法
在每个内部节点,我们暴力枚举所有可能的特征 k k k 和分裂阈值 s s s,找到使 Gain 最大的组合。
算法:CART 回归树节点分裂 --- 精确贪心搜索
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
输入:当前节点的样本集合 D = {(x_i, r_i)}_{i=1}^n,特征维度 d
对每个特征 k = 1, 2, ..., d:
1. 按照特征 k 的值对所有样本排序:O(n log n)
2. 遍历排序后的样本,依次尝试每个候选分裂点:
- 将已扫描的样本累积到左子节点
- 右子节点的统计量 = 总量 − 左子节点(一个巧妙的 O(1) 减法)
- 计算 Gain(k, s)
3. 记录该特征上的最优 Gain 和对应分裂点
返回:所有特征中 Gain 最大的 (k*, s*)复杂度分析:
| 操作 | 复杂度 |
|---|---|
| 每个特征排序 | O ( n log n ) O(n \log n) O(nlogn) |
| 每个特征的候选分裂点枚举 | O ( n ) O(n) O(n) |
| 总计(d 个特征) | O ( d ⋅ n log n ) O(d \cdot n \log n) O(d⋅nlogn) |
这就是传统 GBDT 需要预排序的根本原因。 n log n n \log n nlogn 在大数据面前太慢了。
2.5 叶节点的最优预测值
分裂完成后,每个叶节点需要输出一个预测值。对于均方误差损失,最优值是该叶节点内目标值的均值:
γ j ∗ = 1 ∣ R j ∣ ∑ x i ∈ R j r i \gamma_j^* = \frac{1}{|R_j|} \sum_{x_i \in R_j} r_i γj∗=∣Rj∣1xi∈Rj∑ri
推导 :令目标函数 f ( γ ) = ∑ x i ∈ R j ( r i − γ ) 2 f(\gamma) = \sum_{x_i \in R_j} (r_i - \gamma)^2 f(γ)=∑xi∈Rj(ri−γ)2 对 γ \gamma γ 求导:
∂ f ∂ γ = − 2 ∑ x i ∈ R j ( r i − γ ) = 0 \frac{\partial f}{\partial \gamma} = -2 \sum_{x_i \in R_j} (r_i - \gamma) = 0 ∂γ∂f=−2xi∈Rj∑(ri−γ)=0
⇒ ∑ x i ∈ R j r i − ∣ R j ∣ ⋅ γ = 0 ⇒ γ ∗ = 1 ∣ R j ∣ ∑ x i ∈ R j r i \Rightarrow \sum_{x_i \in R_j} r_i - |R_j| \cdot \gamma = 0 \quad\Rightarrow\quad \gamma^* = \frac{1}{|R_j|} \sum_{x_i \in R_j} r_i ⇒xi∈Rj∑ri−∣Rj∣⋅γ=0⇒γ∗=∣Rj∣1xi∈Rj∑ri
这就是为什么传统 GBDT 说"每棵树拟合残差,叶节点取均值"------它不是经验法则,而是 MSE 最优解的必然结论。
2.6 停止条件
以下任一条件满足时,节点不再分裂:
| 条件 | 作用 |
|---|---|
节点样本数 < min_samples_split |
样本太少,统计量不可靠 |
| 所有样本目标值相同 | 无法进一步降低误差 |
到达最大深度 max_depth |
限制模型复杂度 |
节点样本数 < min_samples_leaf × 2 |
分裂后子节点样本太少 |
三、单棵树的局限与集成学习的动机
3.1 偏差-方差的两难
单棵决策树面临一个经典权衡:
- 浅树(max_depth=3):高偏差(bias),低方差(variance)。对训练数据拟合不充分,但预测稳定。
- 深树(max_depth=15):低偏差,高方差。几乎完美记住训练数据,但换一组训练集可能长出完全不同的树------泛化能力差。
用数学表达:
E ( y − f \^ ( x ) ) 2 = ( E f \^ ( x ) − f ( x ) ) 2 ⏟ Bias 2 + Var ( f ^ ( x ) ) ⏟ Variance + σ 2 ⏟ Irreducible Error \mathbb{E}(y - \\hat{f}(x))\^2 = \underbrace{(\mathbb{E}\\hat{f}(x) - f(x))^2}{\text{Bias}^2} + \underbrace{\text{Var}(\hat{f}(x))}{\text{Variance}} + \underbrace{\sigma^2}_{\text{Irreducible Error}} E(y−f\^(x))2=Bias2 (Ef\^(x)−f(x))2+Variance Var(f^(x))+Irreducible Error σ2
单棵树只能在偏差和方差之间做取舍。集成学习的核心思想是:能不能用多棵不同的树来同时降低偏差和方差?
3.2 两种集成哲学
集成学习有两条根本不同的路线。
Bagging(Bootstrap Aggregating):并行降低方差
原始训练集 (n 个样本)
├── Bootstrap 抽样 1 → 训练树 1 ──┐
├── Bootstrap 抽样 2 → 训练树 2 ──┤
├── Bootstrap 抽样 3 → 训练树 3 ──┼── 取平均 → 最终预测
├── ... │
└── Bootstrap 抽样 M → 训练树 M ──┘图:Bagging(如随机森林)通过并行训练多棵树并取平均来降低方差。来源:scikit-learn 官方文档(BSD-3-Clause License)
核心思路:
- 从训练集有放回地抽样,得到 M 个不同的子训练集
- 每个子集独立训练一棵决策树(树之间互不依赖------可并行训练)
- 最终预测取所有树输出的平均值
效果 :每棵树都是独立的随机变量。取平均后,方差降低到原来的 1 / M 1/M 1/M(假设树之间独立),但偏差不变 。代表算法:随机森林。
Boosting:串行降低偏差
F_0(x) = 初始常数(均值)
↓
F_1(x) = F_0(x) + η · h_1(x) ← h_1 专门修正 F_0 的误差
↓
F_2(x) = F_1(x) + η · h_2(x) ← h_2 专门修正 F_1 的误差
↓
F_3(x) = F_2(x) + η · h_3(x) ← h_3 专门修正 F_2 的误差
↓
... ← 持续修正,直到误差不再下降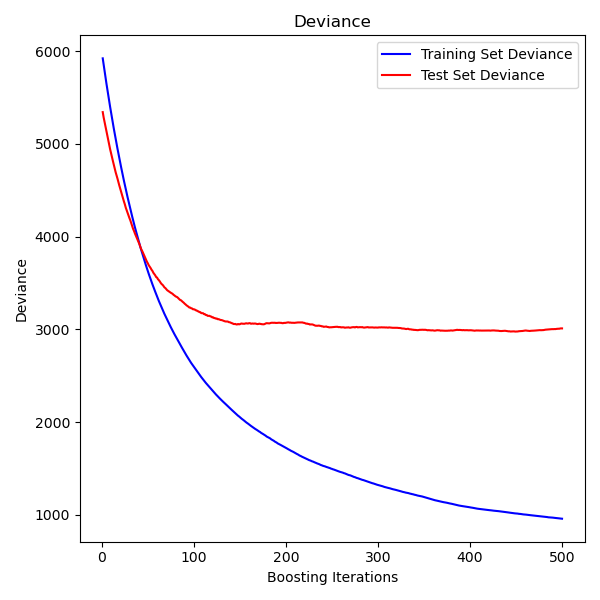
图:Boosting(如 GBDT)通过串行训练,每棵树专门修正前一棵树的误差,逐步降低偏差。来源:scikit-learn 官方文档(BSD-3-Clause License)
核心思路:
- 先训练一个简单的基模型 F 0 F_0 F0(通常就是目标值的均值)
- 分析 F 0 F_0 F0 的误差
- 训练新树 h 1 h_1 h1 专门去修正 F 0 F_0 F0 的误差
- F 1 = F 0 + h 1 F_1 = F_0 + h_1 F1=F0+h1,继续分析 F 1 F_1 F1 的误差,迭代下去
效果 :每次迭代都在降低模型的偏差 (修正之前犯的错误),最终得到一个复杂度高、偏差低的强模型。但方差会增大(树的数量多了,模型变复杂了)。代表算法:GBDT、XGBoost、LightGBM、HistGBM。
3.3 对比小结
| 维度 | Bagging(随机森林) | Boosting(GBDT 家族) |
|---|---|---|
| 训练方式 | 并行、独立训练每棵树 | 串行、每棵树依赖前一棵 |
| 主要改善 | 方差 ↓(取平均平滑掉噪声) | 偏差 ↓(不断修正误差) |
| 基学习器 | 深树(高方差低偏差) | 浅树(弱学习器) |
| 过拟合风险 | 较低(取平均天然防止过拟合) | 较高(需要学习率、正则化等手段控制) |
| 大数据效率 | 天然支持并行,效率高 | 串行限制并行度(但有工程优化) |
🎯 类比打靶:
- Bagging:100 个射手各自独立射击,取弹着点的平均值。每个射手可能偏左或偏右,但平均后弹着点非常稳定。
- Boosting:同一个射手射击,每开一枪后观察偏差,调整瞄准点再开下一枪。每次都在修正上一枪的误差,越来越准,但如果调整过度(过拟合)反而会打偏。
四、从 Boosting 到 Gradient Boosting:关键一步
4.1 最朴素的 Boosting 思路
最早期的 Boosting 算法(如 AdaBoost)对每个样本赋予权重------被当前模型预测错误的样本权重加大,下一轮训练时重点照顾。这虽然直观,但缺乏统一的数学框架。
4.2 换个角度看:残差拟合
假设我们要最小化均方误差 ∑ i = 1 n ( y i − F ( x i ) ) 2 \sum_{i=1}^n (y_i - F(x_i))^2 ∑i=1n(yi−F(xi))2。
当前模型是 F m − 1 ( x ) F_{m-1}(x) Fm−1(x)。它犯了什么错误?很简单------残差:
r i = y i − F m − 1 ( x i ) r_i = y_i - F_{m-1}(x_i) ri=yi−Fm−1(xi)
如果我们训练一棵新树 h m ( x ) h_m(x) hm(x) 去预测这些残差,然后把 h m ( x ) h_m(x) hm(x) 加到模型中:
F m ( x ) = F m − 1 ( x ) + h m ( x ) F_m(x) = F_{m-1}(x) + h_m(x) Fm(x)=Fm−1(x)+hm(x)
那么 F m ( x ) F_m(x) Fm(x) 对第 i 个样本的预测变为 F m − 1 ( x i ) + ( y i − F m − 1 ( x i ) ) ⏟ ≈ h m ( x i ) ≈ y i F_{m-1}(x_i) + \underbrace{(y_i - F_{m-1}(x_i))}_{\approx h_m(x_i)} \approx y_i Fm−1(xi)+≈hm(xi) (yi−Fm−1(xi))≈yi。
这就是"残差拟合"的直觉:每次加一棵拟合残差的树,模型就向正确答案靠近一步。
4.3 一个重要的推广:残差 = 负梯度
注意一个关键事实:对于 MSE 损失 L ( y , F ) = 1 2 ( y − F ) 2 L(y, F) = \frac{1}{2}(y - F)^2 L(y,F)=21(y−F)2:
∂ L ∂ F = F − y \frac{\partial L}{\partial F} = F - y ∂F∂L=F−y
负梯度方向:
− ∂ L ∂ F = y − F (正是残差!) -\frac{\partial L}{\partial F} = y - F \quad \text{(正是残差!)} −∂F∂L=y−F(正是残差!)
也就是说,对于 MSE 损失,拟合残差等价于沿着损失函数负梯度方向走一步。
那如果我们换一个损失函数呢?比如 MAE 损失 L ( y , F ) = ∣ y − F ∣ L(y, F) = |y - F| L(y,F)=∣y−F∣:
∂ L ∂ F = sign ( F − y ) \frac{\partial L}{\partial F} = \text{sign}(F - y) ∂F∂L=sign(F−y)
负梯度不再是残差,而是残差的符号(±1)。但框架不变:训练一棵树去拟合这个"伪梯度",每一步都朝损失函数下降的方向走。
这就是 Friedman(2001)的核心洞见 :把 Boosting 的每次迭代解释为函数空间中的梯度下降------不直接优化模型参数(树没法对参数求导),而是把每个训练样本的预测值当作"参数",在 n 维空间中做梯度下降。
五、GBDT 完整算法流程(MSE 版本)
把上面所有内容串起来,这就是传统 GBDT 的完整流程:
算法:Gradient Boosted Decision Trees(MSE 损失)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
输入:训练集 {(x_i, y_i)}_{i=1}^n
树的数量 M
学习率 η
树的最大深度 D
最小叶节点样本数 L
1. 初始化:F_0(x) = (1/n) Σ y_i ← 从均值开始
(对于 MSE,最优的常数值预测就是取均值)
2. For m = 1 to M: ← 迭代 M 次,每轮加一棵树
a. 计算伪残差(负梯度):
r_{im} = y_i - F_{m-1}(x_i), i = 1,...,n
(对于 MSE,伪残差就是普通残差)
b. 用 CART 算法在 {(x_i, r_{im})} 上训练一棵树 h_m(x)
- 递归二分直到满足停止条件
- 每个叶节点输出该区域内残差的均值
c. 更新模型:
F_m(x) = F_{m-1}(x) + η · h_m(x)
(η 是学习率,控制每步走多远)
3. 输出:最终模型 F_M(x)5.1 学习率 η 的关键作用
学习率(也叫收缩因子 shrinkage)或许是 GBDT 中最重要的超参数。
F m ( x ) = F m − 1 ( x ) + η ⋅ h m ( x ) F_m(x) = F_{m-1}(x) + \eta \cdot h_m(x) Fm(x)=Fm−1(x)+η⋅hm(x)
直观理解:
- η = 1.0 \eta = 1.0 η=1.0:每棵树"全量"修正。收敛快,但容易一步迈过最优解,导致剧烈的震荡和过拟合
- η = 0.01 \eta = 0.01 η=0.01:每棵树只贡献 1% 的修正量。需要更多树( M M M 更大),但每一步都是小心翼翼的微调,泛化能力明显更好
η 和 M 是联动的:
- 小 η + 大 M → 收敛缓慢但泛化好(类似梯度下降中的小步长多次迭代)
- 大 η + 小 M → 收敛快但可能欠拟合或不稳定
典型组合:
| 场景 | η | M | 说明 |
|---|---|---|---|
| 快速实验 | 0.1 | 100 | 快速验证特征和数据质量 |
| 常规任务 | 0.05 | 500 | 标准配置 |
| 追求极致 | 0.01 | 2000+ | 配合早停,自动决定最佳轮数 |
5.2 代码演示:传统 GBM 的收敛曲线
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets, ensemble
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 1. 加载糖尿病数据集(回归任务)
X, y = datasets.load_diabetes(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.1, random_state=42
)
# 2. 训练传统 GradientBoostingRegressor(精确贪心实现)
params = {
"n_estimators": 500, # 树的数量(迭代次数)
"max_depth": 4, # 树的最大深度
"min_samples_split": 5, # 节点最少样本数
"learning_rate": 0.01, # 学习率(收缩因子)
"loss": "squared_error", # MSE 损失
"subsample": 0.8, # 样本采样率
"random_state": 42
}
reg = ensemble.GradientBoostingRegressor(**params)
reg.fit(X_train, y_train)
# 3. 评估
mse = mean_squared_error(y_test, reg.predict(X_test))
print(f"测试集 MSE: {mse:.2f}")
# 4. 绘制训练/测试集损失随迭代次数的变化
test_score = np.array([
mean_squared_error(y_test, y_pred)
for y_pred in reg.staged_predict(X_test)
])
plt.figure(figsize=(10, 5))
plt.plot(reg.train_score_, label="训练集 MSE", color="steelblue", alpha=0.7)
plt.plot(test_score, label="测试集 MSE", color="darkorange", alpha=0.9)
plt.axvline(np.argmin(test_score), color="red", linestyle="--",
label=f"最优迭代次数: {np.argmin(test_score)}")
plt.xlabel("Boosting 迭代次数", fontsize=12)
plt.ylabel("均方误差(MSE)", fontsize=12)
plt.title("GradientBoostingRegressor 收敛曲线", fontsize=14)
plt.legend()
plt.tight_layout()
plt.show()六、传统 GBDT 的性能瓶颈(量化分析)
理解了算法流程,我们来量化它在大数据下的问题。这一分析直接驱动了 HistGBM 的诞生。
6.1 精确贪心搜索的时间复杂度
对于每棵树的每个内部节点:
| 步骤 | 操作 | 复杂度 |
|---|---|---|
| 排序 | 对 d 个特征分别排序 | O ( d ⋅ n log n ) O(d \cdot n \log n) O(d⋅nlogn) |
| 枚举分裂点 | 每个特征扫描所有 n 个候选点 | O ( d ⋅ n ) O(d \cdot n) O(d⋅n) |
| 树级总代价 | 一棵深度 D 的树有 2 D − 1 2^D - 1 2D−1 个节点 | O ( d ⋅ n ⋅ 2 D ) O(d \cdot n \cdot 2^D) O(d⋅n⋅2D) |
具体算一笔账(中等规模数据):
- 样本数 n = 1,000,000 n = 1{,}000{,}000 n=1,000,000
- 特征数 d = 100 d = 100 d=100
- 树深度 D = 6 D = 6 D=6(63 个节点)
单个节点的排序 + 搜索: 100 × 10 6 × log ( 10 6 ) ≈ 2 × 10 9 100 \times 10^6 \times \log(10^6) \approx 2 \times 10^9 100×106×log(106)≈2×109 次比较操作。
整棵树的代价: 100 × 10 6 × 63 ≈ 6.3 × 10 9 100 \times 10^6 \times 63 \approx 6.3 \times 10^9 100×106×63≈6.3×109 次操作。
训练 100 棵树: ≈ 6.3 × 10 11 \approx 6.3 \times 10^{11} ≈6.3×1011 次操作。在单核 CPU 上可能需要数十分钟甚至数小时。
6.2 内存占用
精确贪心需要缓存每个特征的排序索引(XGBoost 的 exact 模式正是如此):
内存 = n × d × 4 bytes \text{内存} = n \times d \times 4 \ \text{bytes} 内存=n×d×4 bytes
当 n = 10 6 n = 10^6 n=106、 d = 100 d = 100 d=100 时:
内存 ≈ 10 6 × 100 × 4 bytes = 400 MB \text{内存} \approx 10^6 \times 100 \times 4 \ \text{bytes} = 400 \ \text{MB} 内存≈106×100×4 bytes=400 MB
400MB 存"排序索引"已经不小,实际加上梯度、原始特征值等常轻松破 1GB。
6.3 问题总结
| 瓶颈 | 根因 | 对大数据的影响 |
|---|---|---|
| 排序代价 | 每个节点都要排序(或缓存排序结果) | O ( d ⋅ n log n ) O(d \cdot n \log n) O(d⋅nlogn) 随 n 超线性增长 |
| 分裂搜索 | 每个节点枚举所有 n 个候选分裂点 | O ( d ⋅ n ⋅ 2 D ) O(d \cdot n \cdot 2^D) O(d⋅n⋅2D) 随 n 线性增长 |
| 内存占用 | 缓存排序索引或存储原始 float 特征 | O ( n ⋅ d ) O(n \cdot d) O(n⋅d),百万样本轻松破 GB |
核心矛盾 :随着数据量增长,精确贪心算法的复杂度以 O ( n log n ) O(n \log n) O(nlogn) 甚至 O ( n ) O(n) O(n) 增长------且常数因子很大。当数据量从 1 万增加到 100 万时,训练时间不是增长 100 倍,而可能是 400-500 倍(因为排序的 log n \log n logn 因子也在变化)。
这就是 HistGBM 要解决的问题 :能不能把分裂搜索的时间复杂度和样本量 n 解耦?
答案是直方图方法------把 n 个样本的信息压缩到 B 个 bin 中,分裂搜索只枚举 B 次,不管 n 多大。下一篇 会先讲梯度提升的完整数学框架(含二阶优化),第三篇将完整展开直方图加速的每一个细节。
七、关键概念总结
在进入下一篇之前,确保这些概念已经清晰:
| 概念 | 一句话解释 |
|---|---|
| CART 回归树 | 递归二分特征空间,叶节点输出区域均值 |
| 分裂增益 | Gain = ( ∑ left r ) 2 n L + ( ∑ right r ) 2 n R − ( ∑ r ) 2 n \text{Gain} = \frac{(\sum_{\text{left}} r)^2}{n_L} + \frac{(\sum_{\text{right}} r)^2}{n_R} - \frac{(\sum r)^2}{n} Gain=nL(∑leftr)2+nR(∑rightr)2−n(∑r)2 |
| Bagging | 并行训练独立树取平均,降低方差 |
| Boosting | 串行训练,每棵树修正前一棵的误差,降低偏差 |
| 残差 = 负梯度(MSE 时) | − ∂ ( 1 2 ( y − F ) 2 ) / ∂ F = y − F -\partial(\frac{1}{2}(y-F)^2)/\partial F = y-F −∂(21(y−F)2)/∂F=y−F |
| 学习率 η | 每棵树只贡献 η 比例的修正,控制步长 |
| 精确贪心瓶颈 | 分裂搜索代价 O ( d ⋅ n ) O(d \cdot n) O(d⋅n),随样本量线性增长 |
参考资料
- Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. Annals of Statistics, 29(5), 1189--1232. --- GBDT 理论的奠基性论文
- Breiman, L., Friedman, J., Olshen, R., & Stone, C. (1984). Classification and Regression Trees. Wadsworth. --- CART 算法的原创著作
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning (2nd ed.), Chapter 9-10 & 15. Springer. --- 统计学习经典教材,第 10 章覆盖 Boosting,第 15 章覆盖随机森林
- Chen, T., & Guestrin, C. (2016). XGBoost: A scalable tree boosting system. KDD 2016. --- XGBoost 论文,引入二阶泰勒展开和正则化
- scikit-learn GradientBoostingRegressor 官方文档
- scikit-learn 梯度提升回归收敛曲线示例