欢迎加入鸿蒙PC开发者社区,共同打造开发者工具生态:鸿蒙PC开发者社区:https://harmonypc.csdn.net/
项目开源地址:https://atomgit.com/OpenHarmonyPCDeveloper/ohos_Tesseract
欢迎在PC社区平台申请新建项目:https://atomgit.com/OpenHarmonyPCDeveloper
这篇文章记录的是一次把 C++ 光学字符识别(OCR)引擎 Tesseract 接入鸿蒙 / HarmonyOS 应用的完整过程。
和 kiwi 那种 header-only 的 C++ 库不一样,Tesseract 不是"把头文件 include 进来就能用"的轻量库。它是一个有几百个 .cpp 源文件、还依赖一整条第三方库链(图像编解码 + Leptonica)的完整引擎。也就是说,这次适配要回答的问题,比 header-only 库更现实一层:
当一个 C++ 库不仅自身要编译、还拖着 zlib / libpng / libjpeg / Leptonica 一长串依赖时,怎么把它整条交叉编译到鸿蒙,再做成用户能用的 OCR 应用?
最终我们在仓库里新增了一个 ohos/ 目录:里面有一套交叉编译脚本,把 Tesseract 和它的依赖链全部编成鸿蒙 arm64 的静态库;还有一个 ohos/demo/TessOcrDemo 鸿蒙示例工程,通过 NAPI 把 OCR 能力暴露给 ArkTS 页面。用户可以用内置示例图,也可以从相册选择任意图片去识别,应用自包含、安装即用。
一、项目背景:Tesseract 是什么,难点为什么在"依赖链"
Tesseract 是目前最常用的开源 OCR 引擎之一,最早由惠普实验室开发,后来由 Google 维护,现在的稳定版是 5.x。它支持 100 多种语言、UTF-8,能把图片里的文字识别成纯文本、hOCR、PDF、TSV 等多种格式。本次适配用的是 5.5.2。
它的能力很直接:给一张图,识别出里面的文字。但它的工程结构决定了适配难点不在"算法",而在"依赖":
- Tesseract 本体是几百个
.cpp,要真正交叉编译,不是加个头文件路径就行; - 它必须 依赖 Leptonica 来读图片;
- Leptonica 又依赖 zlib、libpng、libjpeg 这些图像编解码库;
- 训练工具那部分还会牵扯 ICU、Pango、Cairo(这次端侧用不到,全部关掉)。
所以这条依赖链长这样,必须自底向上一层层交叉编译,前一层是后一层的输入:
text
zlib ──► libpng ─┐
libjpeg-turbo ───┼─► leptonica ──► libtesseract
┘这也是和 kiwi 那篇最本质的区别:kiwi 是 header-only,CMake 里加一行 include 路径就完事;Tesseract 是"引擎 + 一长串依赖",真正的工作量全在把这条链稳定地交叉编译出来。
二、路线选择:交叉编译成静态库 + NAPI,不绕 Python
适配前对比了两条路线。
第一条是"绕 Python":在鸿蒙上装 HNP Python,再 pip install pytesseract 之类。但这条路对 Tesseract 很别扭------pytesseract 只是个命令行封装,底层还是要有 tesseract 可执行文件和 Leptonica 动态库,等于既要装 Python、又要装原生引擎,门槛叠加,得不偿失。
第二条是"顺着它的本性来":既然 Tesseract 本身就是 C++,那就把它和依赖链整条交叉编译成鸿蒙 arm64 的静态库,再用 NAPI 把 OCR 能力直接暴露给 ArkTS。应用自包含,不依赖设备上任何运行时。
最终采用第二条:
text
鸿蒙 ArkTS 页面
-> 选图 / 准备 traineddata 到沙箱
-> libtessocr.so (NAPI) ← 静态链接 libtesseract + leptonica + png/jpeg/z
-> C++ 里 TessBaseAPI::Init + SetImage(pixRead) + GetUTF8Text
-> 返回识别文字
-> ArkTS 渲染结果这条路线的好处很明确:
- 不改 Tesseract 一行 C++ 源码,适配全部落在
ohos/目录; - 应用自包含,用户安装即用,不需要装 Python 或任何运行时;
- 原生性能,识别在 C++ 里直接完成;
- 几个静态库最后合并进一个
libtessocr.so,打包干净。
值得一提的是:Tesseract 本来就支持 Android NDK 交叉编译,而鸿蒙 NDK 同样是 Clang + musl + CMake 工具链,和 Android NDK 高度相似。这意味着"Android 能编"基本等价于"鸿蒙也能编",这给了第二条路线很大的信心。
三、交叉编译引擎:把整条依赖链编成鸿蒙 arm64 静态库
这是整个适配的核心。我在 ohos/scripts/ 下写了一组脚本:
env.sh:定位鸿蒙 Native NDK,设好OHOS_ARCH=arm64-v8a、目标三元组aarch64-linux-ohos、clang、sysroot;fetch-sources.sh:下载 zlib / libjpeg-turbo / libpng / leptonica 源码;build-deps.sh:自底向上交叉编译这四个依赖(全部静态 + PIC);build-tesseract.sh:编libtesseract.a并安装头文件;build-all.sh:一键串起来。
整条链一条命令搞定:
sh
cd ohos
bash scripts/build-all.sh
# 默认 arm64-v8a;模拟器可 OHOS_ARCH=x86_64 bash scripts/build-all.sh编完产物都在 ohos/prebuilt/arm64-v8a/:
| 库 | 作用 |
|---|---|
libtesseract.a |
OCR 引擎 |
libleptonica.a |
Tesseract 用来读图片 |
libpng16.a / libjpeg.a / libz.a |
图像编解码 |
可以用 llvm-readelf 确认编出来的确实是鸿蒙 arm64(AArch64 / ELF64),而不是 macOS 的本机产物。
四、移植中真正要解决的几个问题
Tesseract 的 C++ 代码本身是可移植的 C++17,鸿蒙这套 clang + musl + CMake 跟它已经支持的 Android NDK 很接近,所以摩擦全在构建配置,而不在源码。具体踩到这么几个点:
1)CMAKE_SYSTEM_NAME=OHOS 下要走通用 Unix 分支。 鸿蒙工具链里设了 UNIX=TRUE,所以 Tesseract 的 CMake 会自动走通用 Unix 路径;同时它只有在 ANDROID 时才会去找 CpuFeaturesNdkCompat,鸿蒙不是 Android,这个依赖被自然跳过。
2)aarch64 的 SIMD 不需要运行时探测。 在 __aarch64__ 上,NEON 是编译期常开的,simddetect.cpp 不会去调 getauxval / android_getCpuFamily,省掉了一类平台探测代码。
3)libpng 的 pnglibconf 生成步骤丢了 target。 libpng 交叉编译时会单独调用 clang 去预处理一个配置文件,但这一步没带上工具链的 --target,导致找不到鸿蒙按架构分目录的 musl 头 bits/alltypes.h。解决办法是在 png 的 CMake 参数里把 --target=aarch64-linux-ohos 和对应 include 目录重新补回去。
4)Tesseract 探测 Leptonica 的 TIFF 支持用了 try_run。 交叉编译时根本没法在主机上运行目标二进制,try_run 直接报错。解决办法是预置一个缓存变量 -DLEPT_TIFF_RESULT=1,跳过这次运行探测(我们本来也没编 TIFF)。
这几个点解决后,libtesseract.a 就顺利编出来了,Tesseract 自身源码一行没改。
五、新增的鸿蒙示例工程长什么样
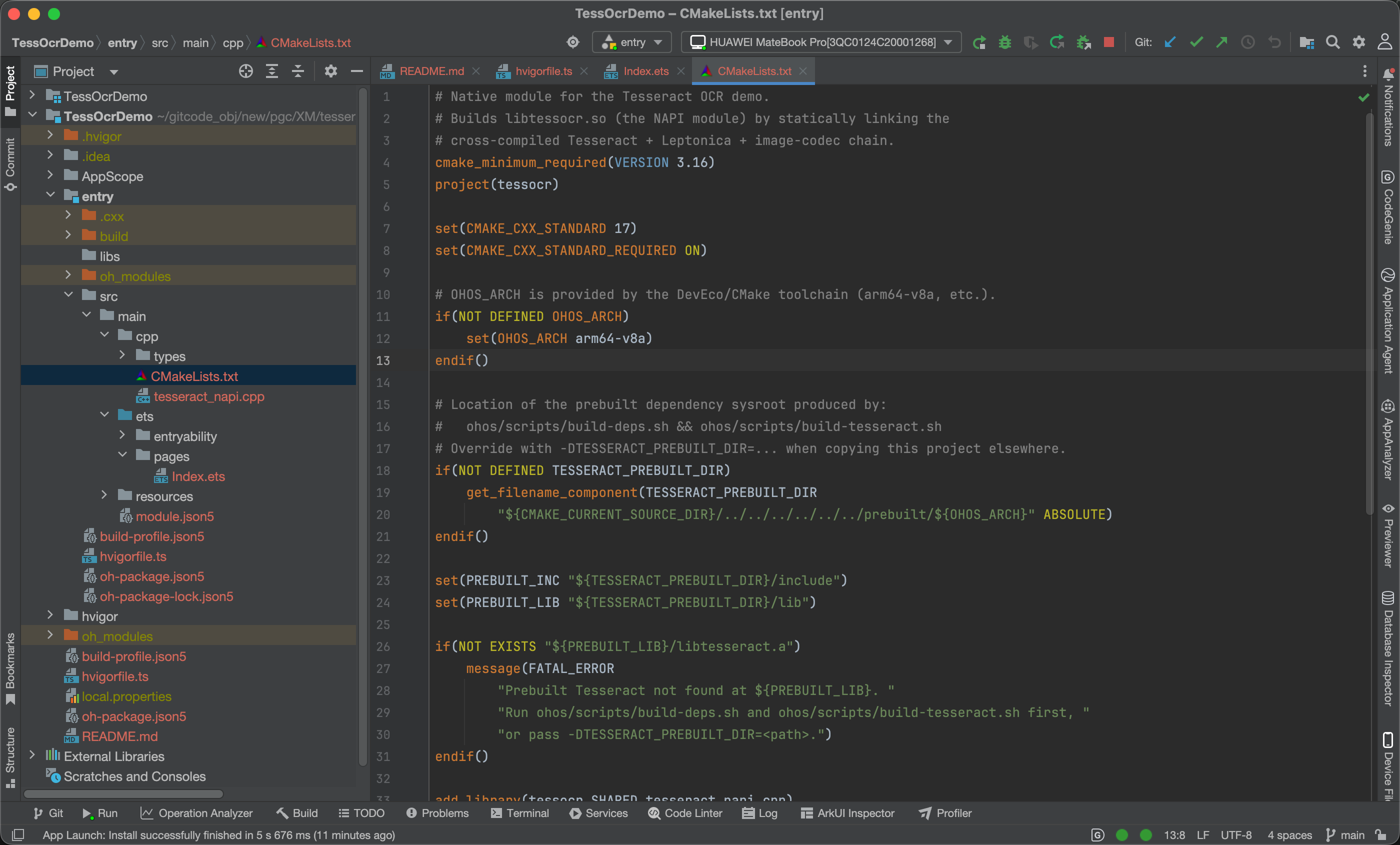
引擎编好后,ohos/demo/TessOcrDemo 是一个标准的 DevEco / Stage 模型工程,重点是 cpp/ 目录:
text
ohos/demo/TessOcrDemo/
├── AppScope/app.json5
├── build-profile.json5 / oh-package.json5
└── entry/
├── build-profile.json5 ← externalNativeOptions 指向 cpp/CMakeLists.txt
└── src/main/
├── module.json5
├── cpp/
│ ├── CMakeLists.txt 链接预编译的 Tesseract 静态库,编出 libtessocr.so
│ ├── tesseract_napi.cpp NAPI 入口:version() + 异步 recognize()
│ └── types/libtessocr/ .so 的 TS 声明 index.d.ts
├── ets/pages/Index.ets 演示页:选图 / 识别 / 结果展示
└── resources/rawfile/
├── sample.png 内置示例图
└── tessdata/eng.traineddata 英文识别模型各文件职责很清楚:
CMakeLists.txt:把libtesseract.a + libleptonica.a + libpng16.a + libjpeg.a + libz.a静态链接成一个libtessocr.so;tesseract_napi.cpp:NAPI 桥接,只暴露两个方法;Index.ets:页面,处理选图、识别和结果显示;rawfile/:内置示例图和英文模型eng.traineddata。
这里同样没有改写上游 Tesseract ,所有鸿蒙适配逻辑都集中在 ohos/ 里,边界清晰。
六、NAPI 桥接:把 OCR 暴露给 ArkTS
ArkTS 不能直接用 C++ 的 Tesseract,中间需要 NAPI 做桥接。tesseract_napi.cpp 只暴露两个方法:
text
version(): string // 返回 libtesseract 版本
recognize(imagePath, dataPath, lang): Promise<string> // 异步识别,返回文字recognize 是异步的------OCR 可能比较慢,所以放到 libuv 工作线程里跑,不卡 UI。工作线程里就是 Tesseract 最标准的用法:
cpp
tesseract::TessBaseAPI api;
api.Init(dataPath, lang); // dataPath 下要有 <lang>.traineddata
Pix* image = pixRead(imagePath); // Leptonica 按文件内容判格式
api.SetImage(image);
char* text = api.GetUTF8Text(); // 识别结果CMake 这边的关键是静态链接顺序 :tesseract → leptonica → png/jpeg → z,最后再带上 NAPI 库:
cmake
target_link_libraries(tessocr PRIVATE
"${PREBUILT_LIB}/libtesseract.a"
"${PREBUILT_LIB}/libleptonica.a"
"${PREBUILT_LIB}/libpng16.a"
"${PREBUILT_LIB}/libjpeg.a"
"${PREBUILT_LIB}/libz.a"
m
libace_napi.z.so)由于鸿蒙链接默认带 -Wl,--no-undefined,只要这一步链接通过,就说明整条静态库的符号都解析干净了------这本身就是一次很强的集成验证。
七、ArkTS 页面:选图 + 识别
页面 Index.ets 做成了真正能上手的小工具,而不是一个验证按钮:
- 识别:对当前图片跑 OCR,结果显示在下方;
- 选择图片:调系统相册选择器,选任意图片去识别;
- 恢复示例图:选过图后一键切回内置样图。
这里有一个和文件处理相关的关键点:相册选择器返回的是 URI(如 file://media/...),而 Leptonica 的 pixRead 需要真实文件路径。所以选图后要先把内容拷进应用沙箱,再把沙箱路径交给识别:
ts
const uri = (await picker.select(options)).photoUris[0];
const dst = `${ctx.filesDir}/picked_image`;
const src = fs.openSync(uri, fs.OpenMode.READ_ONLY);
fs.copyFileSync(src.fd, dst); // URI -> 沙箱真实路径
fs.closeSync(src);
this.currentImagePath = dst; // 交给 recognize()补充两个细节:一是 Leptonica 按文件内容 (magic bytes)判断格式,所以沙箱副本叫 picked_image、没有扩展名也能正确识别 PNG/JPEG;二是用系统选择器不需要声明相册权限,它只对用户选中的那张图临时授读权,符合最小权限。
同样,内置的 eng.traineddata 和示例图也是开机时从 rawfile 拷到沙箱,因为 Tesseract 的 Init(dataPath, ...) 需要一个真实目录。
八、构建:用 hvigor 把引擎、NAPI、ArkTS 一起打成 HAP
工程可以在 DevEco Studio 里直接构建,也可以用命令行 hvigor。先装依赖再 assembleHap:
sh
cd ohos/demo/TessOcrDemo
ohpm install
hvigorw assembleHap -p product=default --no-daemon这里要注意一个很典型的 SDK 版本与归属 问题。本机命令行 SDK 实际是 HarmonyOS 6.0.1 / API 21 (看 sdk/default/sdk-pkg.json 写的是 "HarmonyOS 6.0.1"),所以 build-profile.json5 要配成 HarmonyOS、版本写 6.0.1(21),而不是 OpenHarmony 的整数写法:
json5
"compileSdkVersion": "6.0.1(21)",
"compatibleSdkVersion": "6.0.1(21)",
"targetSdkVersion": "6.0.1(21)",
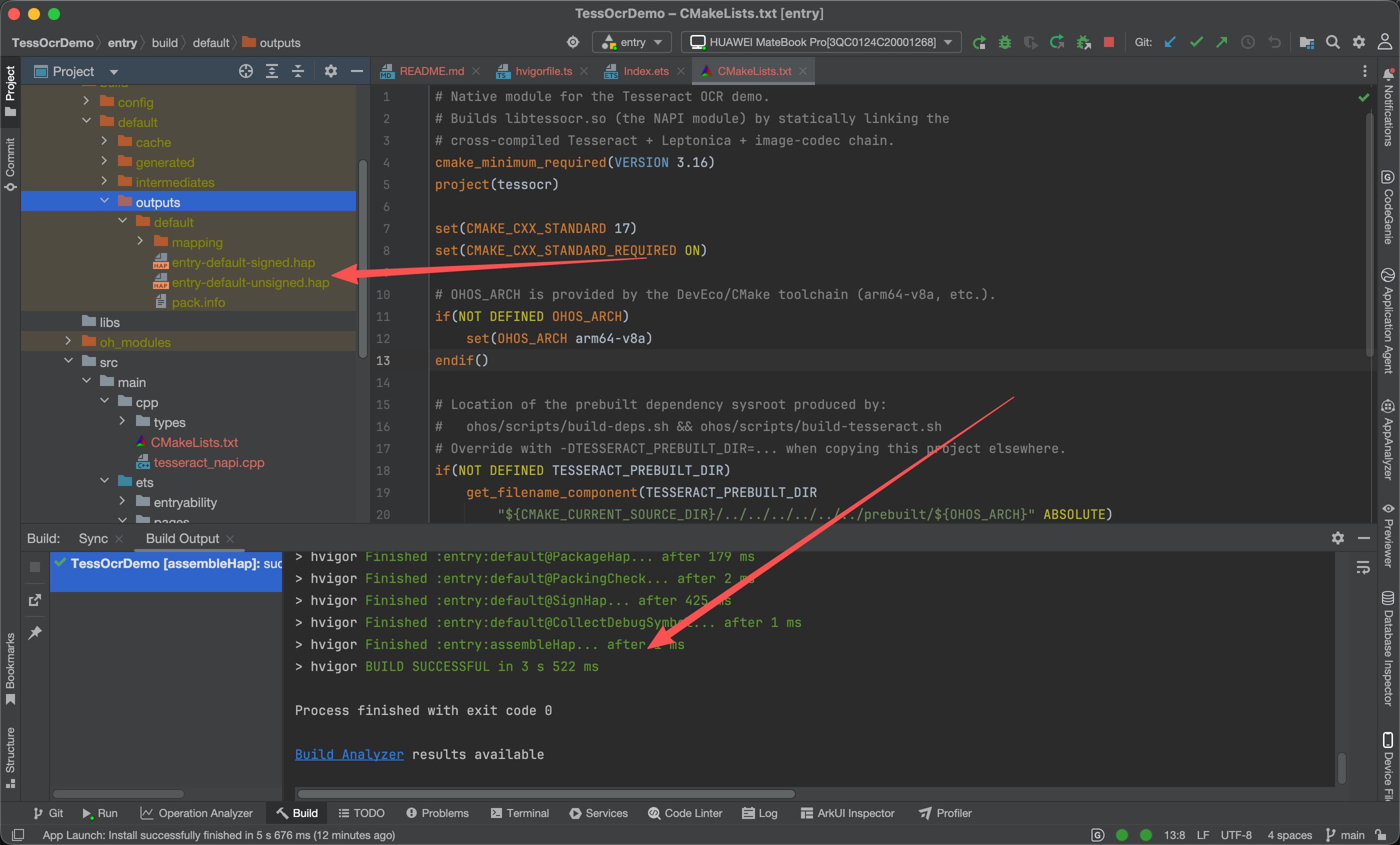
"runtimeOS": "HarmonyOS"local.properties 里 sdk.dir 要指到 .../sdk/default/openharmony。配对后构建日志能清楚看到 Native 和 ArkTS 两条线都编了:BuildNativeWithCmake / BuildNativeWithNinja 把 libtessocr.so 编出来,CompileArkTS 编页面,最后签名打包:
text
Finished :entry:default@BuildNativeWithCmake
Finished :entry:default@BuildNativeWithNinja
Finished :entry:default@CompileArkTS
Finished :entry:default@PackageHap
Finished :entry:default@SignHap
Finished :entry:assembleHap
BUILD SUCCESSFUL签名后的 HAP 在 entry/build/default/outputs/default/entry-default-signed.hap,解包能看到 libs/arm64-v8a/libtessocr.so、自动带上的 libc++_shared.so,以及 resources/rawfile 里的 eng.traineddata 和 sample.png 都打进去了。
九、装到真机 / 模拟器,实测选图识别
构建出签名 HAP 后,用 hdc 装到连着的鸿蒙设备 / 模拟器并启动:
sh
HDC=~/ohos/command-line-tools/sdk/default/openharmony/toolchains/hdc
$HDC install -r entry/build/default/outputs/default/entry-default-signed.hap
$HDC shell aa start -a EntryAbility -b com.tesseract.ocrdemo -m entry(也可以直接在 DevEco Studio 里选好设备点 ▶ Run,省去手动 install。)
应用起来后,先用内置示例图点 识别 ,确认整条链路通;再点 选择图片,从相册挑一张带文字的图来识别。
选中图片后,应用会把它拷进沙箱并显示在预览区,这时点 识别,稍等片刻,下方结果区就会出现这张图里识别出来的文字。
十、适配过程中踩到的关键问题(小结)
- 依赖链必须自底向上编。 Leptonica 找不到 png/jpeg/z 就编不过,Tesseract 找不到 Leptonica 也编不过,顺序不能乱。脚本里固定为
zlib → libpng/libjpeg → leptonica → tesseract。 - libpng 交叉编译丢 target。
pnglibconf生成步骤要手动补--target和按架构的 musl include,否则报bits/alltypes.h not found。 try_run在交叉编译下非法。 Tesseract 探测 Leptonica TIFF 支持要预置-DLEPT_TIFF_RESULT=1跳过。- SDK 归属要对。 本机是 HarmonyOS 6.0.1(21) 而非 OpenHarmony,
build-profile.json5要写runtimeOS: "HarmonyOS"+"6.0.1(21)",sdk.dir指到.../sdk/default/openharmony,否则 hvigor 报 "Unable to find components"。 - 选择器 URI ≠ 文件路径。 Leptonica 要真实路径,所以相册返回的 URI 必须先拷进沙箱再识别;沙箱副本无需扩展名,Leptonica 按内容判格式。
十一、总结:这套思路怎么迁到其他"带依赖链"的 C++ 库
这次 Tesseract 适配最有价值的,不只是做了一个 OCR 应用,而是跑通了一条**"引擎 + 一长串依赖"的 C++ 库整体交叉编译到鸿蒙**的完整路径,并形成了可复用的脚手架:
ohos/scripts/一套脚本:定位 NDK → 拉源码 → 自底向上编依赖 → 编主库 → 装产物;- 几个静态库合并进一个
libtessocr.so,NAPI 只做"路径进、文字出"的桥接; - ArkTS 负责选图、沙箱中转、结果展示;
- 上游 Tesseract 源码一行未改,适配全部集中在
ohos/。
和 header-only 的 kiwi 相比,Tesseract 这类库的难点全在"依赖链"。但只要把链拆清楚、自底向上一层层用同一套工具链编,再用 imported target 把传递依赖(png/jpeg/z)自动带上,整条链就能稳定落地:
text
先用 NDK 工具链把依赖自底向上编成静态库(PIC)
-> 主库 CMake 用 find_package 拿到依赖的 imported target(自动带传递依赖)
-> NAPI 把静态库合并链接成一个 .so,只做字符串/路径进出
-> ArkTS 负责选图、URI→沙箱、结果展示
-> rawfile 内置模型/示例,开机拷到沙箱
-> 最后 hvigor 构建 + 真机/模拟器验证闭环这条路线可以直接套到其他带依赖链的 C/C++ 库 上------比如 OpenCV、FFmpeg、各类图像 / 音视频 / 解析库。后续如果继续扩展,可以加多语言模型(中文 chi_sim 等)、支持从相机 / PixelMap 原始像素直接识别(免落盘),把这个 OCR demo 做成真正可用的鸿蒙工具。