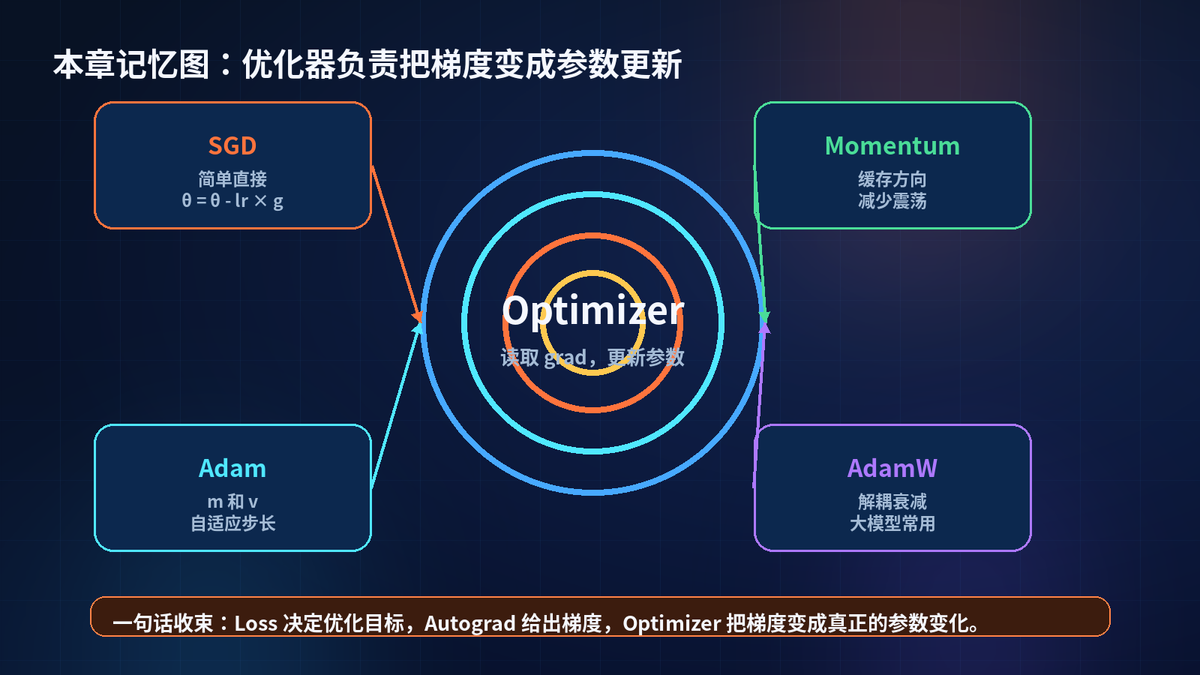
梯度不是参数更新。梯度只是方向,优化器才是真正踩油门的人。
1. 模型参数不会自己变好
模型训练不是"算出 loss 就结束"。loss 只是告诉我们错了多少。
backward 会把错误沿计算图传回去,写到每个参数的 grad 里。
但 grad 还不是更新。grad 只是一个方向提示。真正修改 weight 和 bias 的,是 optimizer.step()。
Autograd 负责算梯度,Optimizer 负责改参数。
2. Optimizer 在训练循环中的位置
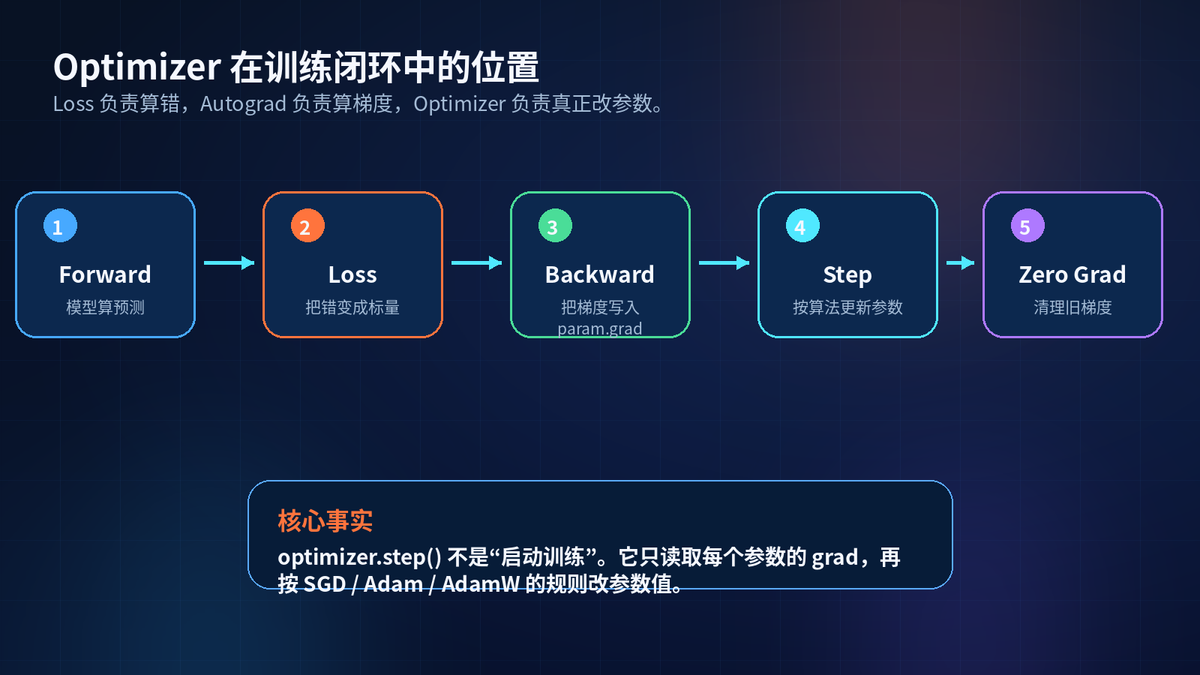
一轮训练可以拆成五步:forward、loss、backward、step、zero_grad。
forward 负责预测。loss 负责衡量错误。backward 负责计算梯度。step 负责更新参数。zero_grad 负责清理旧梯度。
这里最容易误解的是 step。step 不会重新计算 loss,也不会自动 backward。它只读取已有的 param.grad,再按算法更新参数。
3. 梯度给方向,学习率给步长
参数更新的最小动作,就是从当前参数出发,沿着让 Loss 下降的方向挪一点。
梯度告诉你坡往哪边陡。学习率告诉你每步走多远。
学习率太小,训练慢。学习率太大,容易震荡,甚至 loss 爆炸。
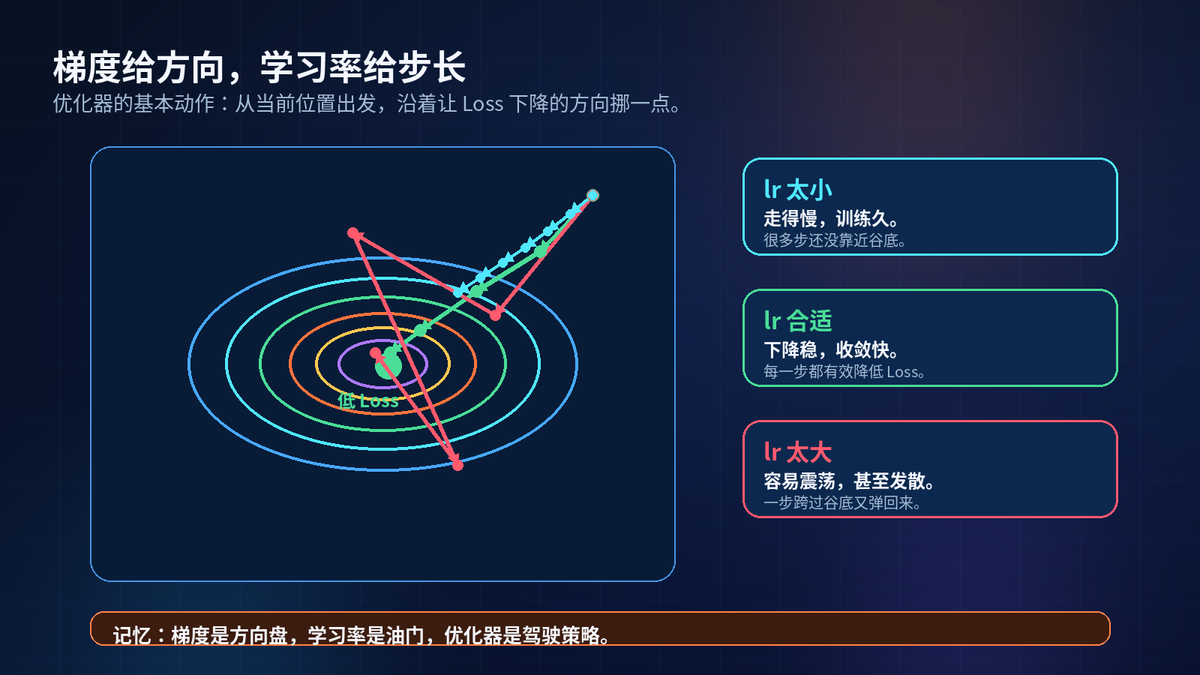
记忆:梯度是方向盘,学习率是油门,优化器是驾驶策略。
4. SGD:最朴素的更新规则
SGD 的直觉很简单:当前参数减去学习率乘以梯度。
梯度指向 Loss 上升最快的方向。要让 Loss 下降,就反方向走。
SGD 的优点是简单、透明、泛化能力经常不错。缺点是调参比较敏感,训练可能抖。

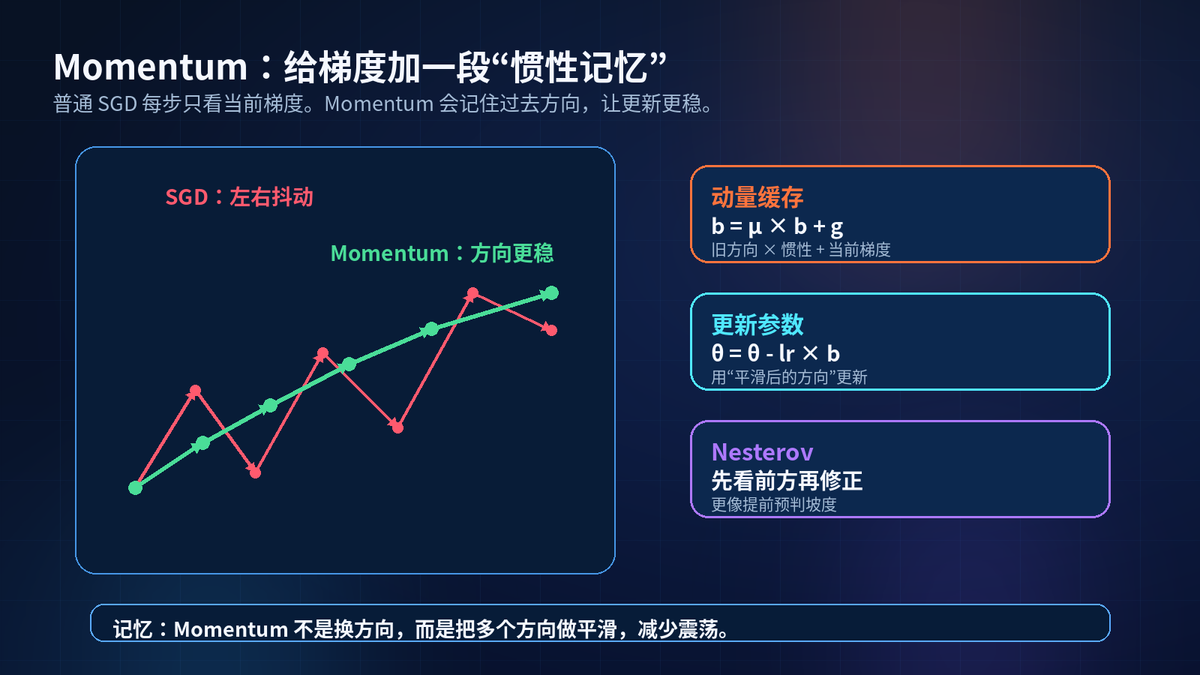
5. Momentum:让更新带一点惯性
普通 SGD 每一步只看当前梯度。当前梯度有噪声,方向就会左右晃。
Momentum 会维护一个 momentum_buffer。它把历史梯度方向和当前梯度混合起来。
这样可以减少无意义抖动,在长期正确的方向上走得更快。
Nesterov Momentum 更进一步:它像是先看一步前方的坡度,再做修正。
6. Adam:每个参数都有自己的步长
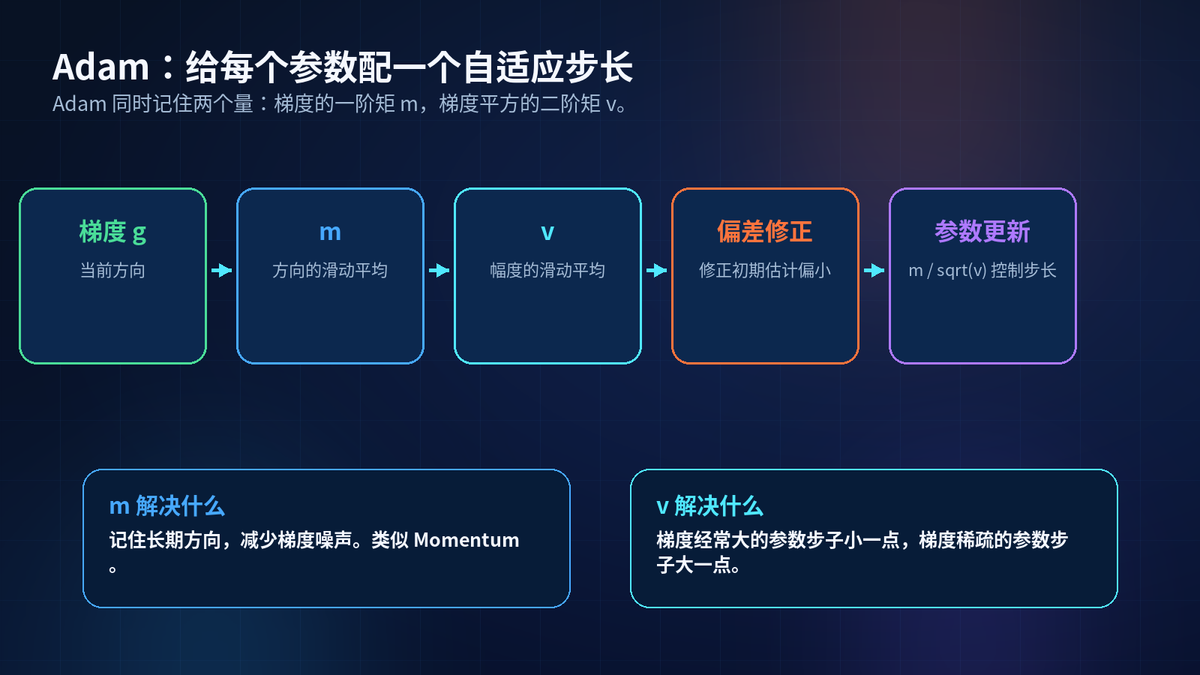
Adam 可以理解成 Momentum 的升级版。
它同时维护两个状态:exp_avg 和 exp_avg_sq。
exp_avg 记录梯度方向的滑动平均,类似动量。exp_avg_sq 记录梯度平方的滑动平均,用来衡量这个参数的梯度尺度。
梯度经常大的参数,步子自动变小。梯度稀疏或较小的参数,步子可以相对变大。
这就是 Adam 在 NLP、Transformer、稀疏梯度场景里常用的原因。
7. AdamW:大模型时代的默认选择之一
Adam 里如果直接把 weight_decay 加进梯度,会被 Adam 的自适应缩放影响。
AdamW 的关键是解耦。它把权重衰减从梯度更新里拆出来。
先让参数按 weight_decay 轻微衰减,再执行 Adam 的自适应更新。
这让 weight_decay 更像真正的正则化,而不是混在梯度里的另一个项。

大模型经验:AdamW 常作为默认起点,但 bias 和 norm 参数通常不做 weight decay。
8. 怎么选优化器
不要把优化器当玄学。先看任务,再看模型,再看训练稳定性。
传统 CNN 可以从 SGD + Momentum 开始,尤其追求最终泛化时。
Transformer、NLP、大模型微调,通常优先 AdamW。
快速验证想法时,Adam 或 AdamW 往往更省心。

9. param_groups:不是所有参数都该一样更新
优化器可以把参数分成多组。每一组可以有自己的 lr、weight_decay、betas 或 momentum。
这在微调里很常见:预训练 backbone 用小学习率,新加分类头用大学习率。
这在 AdamW 里也很常见:weight 参数做 weight_decay,bias 和 norm 参数不做。
参数分组不是技巧,而是工程基本功。
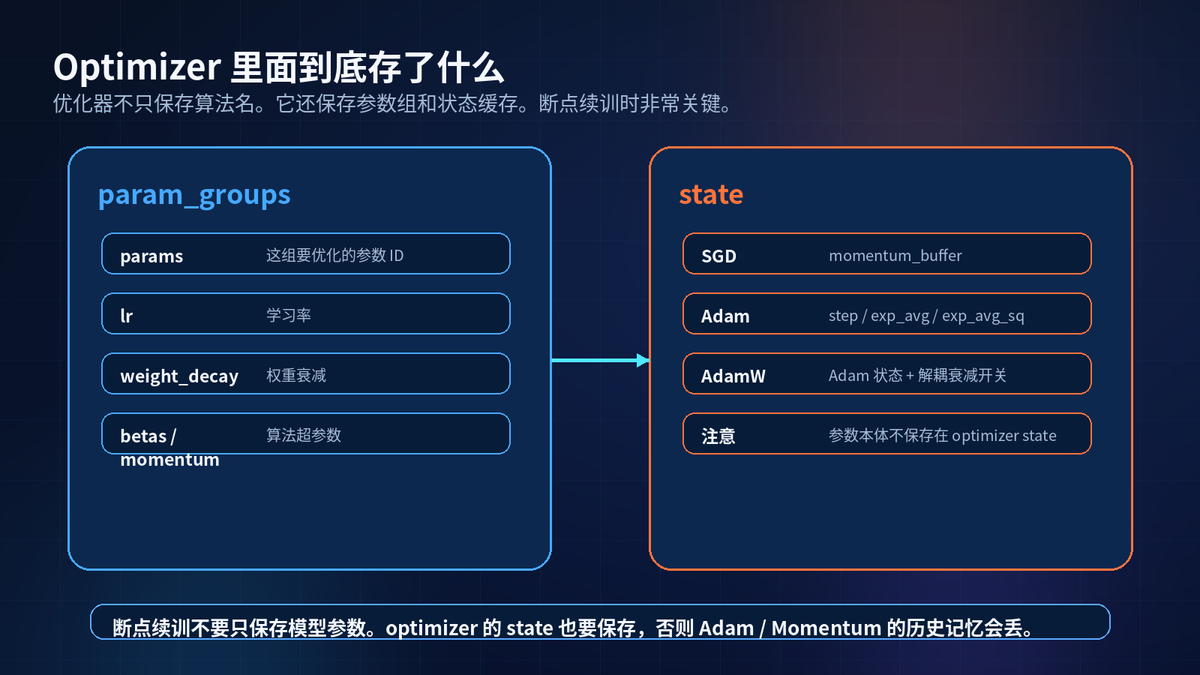
10. optimizer.state_dict:优化器也有记忆
模型的 state_dict 保存 weight 和 bias。优化器的 state_dict 保存更新过程中的历史状态。
SGD with Momentum 会保存 momentum_buffer。
Adam 和 AdamW 会保存 step、exp_avg、exp_avg_sq。
如果断点续训只保存模型,不保存优化器,恢复后参数虽然在,但优化器的历史记忆没了,训练曲线可能突然变差。
断点续训:model.state_dict 和 optimizer.state_dict 要一起保存。
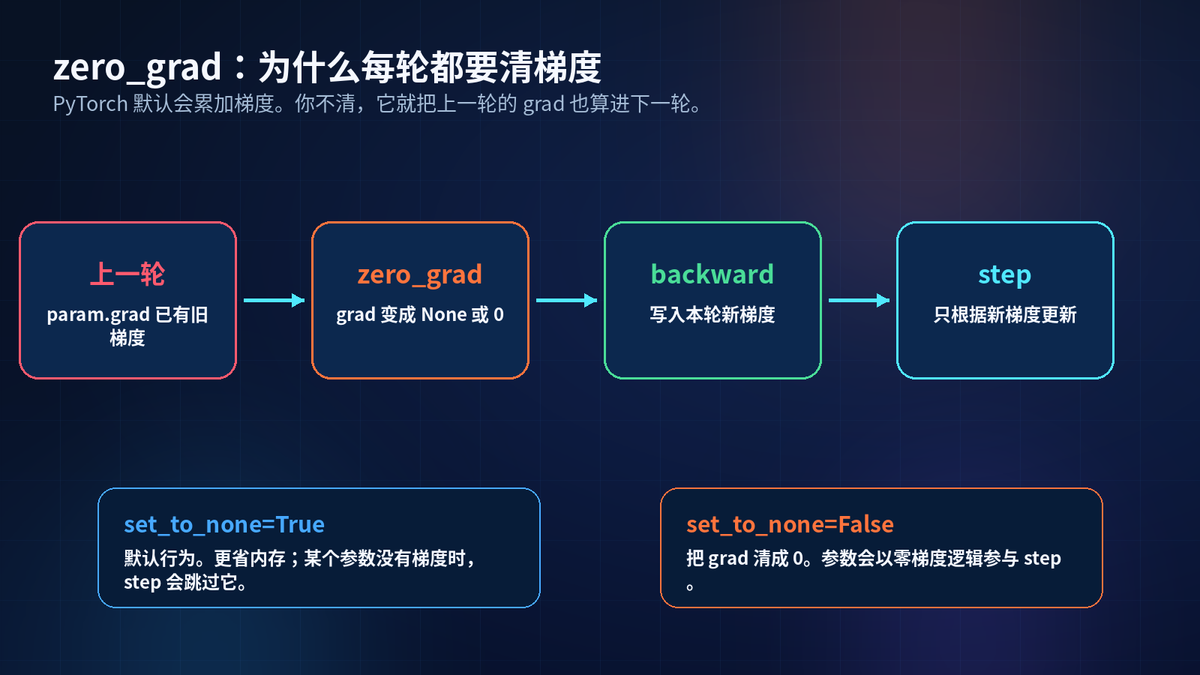
11. zero_grad:为什么每轮都要清梯度
PyTorch 的梯度默认是累加的。
这很有用,因为它支持梯度累积。但普通训练里,如果不清空上一轮梯度,下一轮 backward 会把新旧梯度加在一起。
所以标准顺序是:清梯度、算 loss、backward、step。
zero_grad 默认 set_to_none=True。它会把 grad 设成 None。这样更省内存,也让没有收到梯度的参数在 step 时被跳过。
12. 源码级讲解:step 背后的主线
Optimizer 基类在初始化时,会把传入的 model.parameters() 包装成 param_groups。
每个优化器都有自己的 step 方法。SGD.step 会遍历 param_groups,收集 params、grads、momentum_buffer,然后调用 functional sgd。
Adam.step 会收集 params、grads、exp_avg、exp_avg_sq、state_steps,然后调用 functional adam。
AdamW 继承自 Adam。它在初始化时把 decoupled_weight_decay 固定为 True。
functional 层会根据设备、dtype、foreach、fused 等条件选择实现路径。最后底层算子对参数做原地更新。
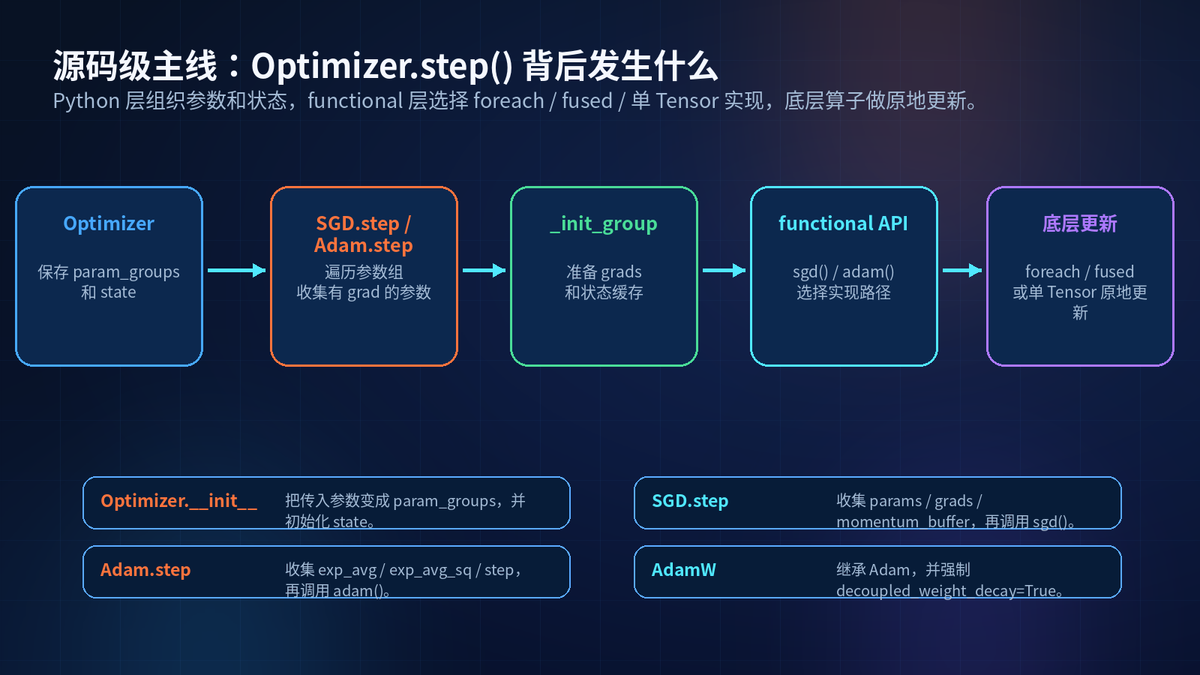
源码主线:Optimizer 管参数组和状态,step 收集梯度,functional 选择实现,底层算子原地改参数。
13. 实战常见坑
第一个坑:忘记 zero_grad。表现是梯度越来越怪,loss 抖动。
第二个坑:学习率太大。表现是 loss 爆炸、NaN、指标突然崩。
第三个坑:weight_decay 误伤 bias 和 norm。大模型微调里尤其常见。
第四个坑:断点续训只保存 model,不保存 optimizer。Adam 的历史状态会丢。
第五个坑:grad 是 None。说明这个参数没有参与计算,或者 requires_grad 被关掉。

14. 总结
优化器是训练闭环里真正修改参数的组件。
SGD 简单直接,适合追求可控和泛化。
Momentum 用历史方向减少震荡。
Adam 用一阶矩和二阶矩给每个参数自适应步长。
AdamW 把 weight_decay 从梯度更新里解耦出来,是 Transformer 和大模型训练里的常见默认选择。
源码上,Optimizer 管理 param_groups 和 state;具体 step 收集 grad 和状态,再下沉到 functional 与底层算子。