

🎯 博主简介
CSDN 「新星创作者」 ,人工智能技术领域博主,码龄 5 年 ,累计发布
190+ 篇原创文章,博客总访问量30万+浏览。
🚀 持续更新 AI 前沿实战知识,专注于 AI 技术实战、RAG 系统、Agent 应用开发与大模型工程化落地。目前主要更新方向包括:
- 🦞 最新 OpenClaw 教程 ---从入门到精通|AI 智能助手/自动化/Skills 实战(原 Clawdbot/Moltbot)
- ✨ Agent 记忆系统 --- 长期记忆、上下文管理与个性化智能体设计
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥以下系列正在火热更新中🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥- 📘 图解机器学习合集 --- 用图解方式系统梳理机器学习核心概念,持续更新中
同时也会持续分享 AI 编程、Java 后端、Spring 生态、Transformer、大模型基础、计算机视觉 等方向内容,内容会尽量结合自己的学习记录、项目实践和踩坑经验来整理。
📱GZH:安逸Ai(科技前沿新闻,Github热门项目,最新免费资料...)- 网页观看完整系列合集:🌐 Anyi AI 学习资源站
过拟合和欠拟合:为什么训练集很好,测试集很差?
你有没有过这种经历?
模型训练完了,一看准确率99%,心里美滋滋。
上线一跑,准确率掉到65%。
你以为是代码写错了,检查了八百遍。
其实这不是bug,而是每个机器学习工程师都会碰到的经典问题------过拟合和欠拟合。
好消息是,搞懂这两个概念,你就算入门了一半。
上回我们聊了损失函数和梯度下降,知道模型是通过不断优化来"变聪明"的。
但聪明到什么程度算合适?
这就是今天要解决的问题。
拟合是什么?模型在学习还是在背答案?
先说拟合这个概念。
模型训练的目标是什么?
说白了就两件事:第一,在训练数据上表现好;第二,到了新数据上也能行。
第一件事叫拟合训练集。
第二件事叫泛化能力。
你肯定不希望模型只会做课本上的题,换个问法就完蛋。
这就像考试,训练集是教材和习题册,测试集是正式考卷。
你当然得把教材学透,但真正考验你的是那些没见过的题。
训练集负责"学",测试集负责"考"。
两个职责不一样,要求也不一样。
模型在训练集上学到的,不光有真正的规律,还有数据里的噪音和巧合。
到了测试集,如果新数据里的噪音分布变了,模型就可能出错。
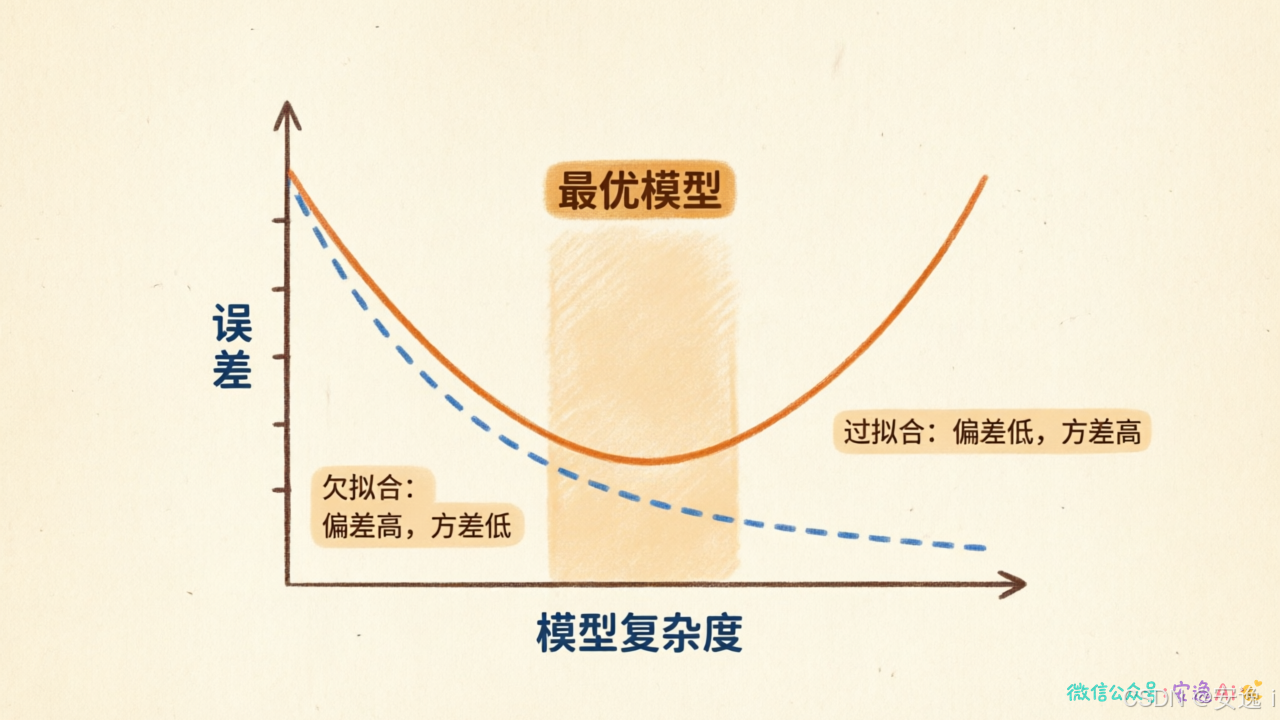
这里有个核心矛盾,叫偏差-方差权衡。
偏差高了,模型太笨,学不到东西。
方差高了,模型太敏感,记住太多不该记的。
找到一个平衡点,是训练模型的关键。
过拟合:模型记性太好,考试就傻眼
先说说过拟合。
你有没有见过那种"学霸"?
教材倒背如流,课后习题全对。
结果一上考场,换了个题型就不会了。
过拟合就是这个问题。
模型在训练集上表现完美,但测试集上一塌糊涂。
为什么会这样?
因为模型不只是学到了规律,还把训练数据的噪音和细节都记住了。
噪音是什么?
举个例子,你想训练一个猫狗分类器。
训练图片里,所有的猫都在同一个摄影棚拍的,背景一模一样。
狗的照片都是在户外拍的。
模型可能根本没用学猫和狗的区别。
它学到的是:背景是室内的是猫,背景是户外的是狗。
到了新测试集,猫的照片在户外拍------完蛋,分错了。
你说这模型傻不傻?
但这种事每天都在发生。
还有个更隐蔽的例子。
医学影像诊断,训练数据里肺部X光片有特定的水印。
模型可能把这个水印当成了诊断依据。
换个医院没有这个水印,准确率直接崩盘。
你说它学的是疾病特征还是水印特征?
本质上,过拟合就是模型"想太多"。
它不光记住了规律,还记住了很多巧合。
这些巧合在新数据里不存在,所以模型就翻车了。
怎么发现过拟合?
看训练损失和测试损失的变化曲线。
一开始两个都下降。
后来训练损失还在降,测试损失开始回升了。
那一刻就是过拟合的开始。
继续训练只会越来越严重。
欠拟合:模型脑子不够用,连教材都看不懂
说完过拟合,再看看另一个极端------欠拟合。
欠拟合正好相反。
训练集上表现不好,测试集上表现也不好。
模型太简单了,连训练数据里的主要规律都没学到。
举个例子。
你想预测房价,只用一个特征:房屋面积(平方英尺)。
这个模型能学到什么?
面积越大价格越高,这是对的。
但它完全忽略了位置、房龄、周边配套这些重要因素。
结果预测出来的价格,跟实际情况差得十万八千里。
这就叫欠拟合------模型脑子不够用,教材都看不懂。
欠拟合的原因通常是模型太简单,或者特征太少。
用一把尺子去测量地球,能量出什么来?
什么也量不出来。
尺子太简单了,需要更精密的工具。
模型也是一样,太简单的模型学不到复杂的关系。
欠拟合的问题更好解决------给它升级装备。
过拟合怎么治?六种方法
好,重点来了。
过拟合这么讨厌,怎么解决?
有六种常用方法,从简单到复杂介绍一遍。
第一种,简化模型。
参数越少,模型能记住的东西就越少。
一棵小树苗长不出参天大树的体型。
减少神经网络的层数,减少决策树的深度,都是这个思路。
第二种,正则化。
给损失函数加个惩罚项。
让模型不能太依赖某一个特征。
L1正则化会让部分权重变成零,相当于自动做了一次特征选择。
L2正则化让所有权重都变小,但不归零。
Dropout是给神经网络用的,训练时随机"关闭"一些神经元。
强制模型不要依赖任何单个节点。
第三种,早停法。
监控验证集上的损失。
如果验证损失不再下降,就停止训练。
不要让模型继续学下去。
见好就收。
第四种,数据增强。
训练数据不够多,就让它变多。
图片可以旋转、缩放、裁剪、加噪声。
文本可以同义词替换、回译。
一个样本变成十个样本,模型见识多了,就不容易过拟合。
第五种,交叉验证。
把数据分成k份,用k-1份训练,1份验证。
轮换着来,得到更可靠的性能评估。
也能更好地发现过拟合问题。
第六种,增加训练数据。
最直接的办法。
数据够多,模型见过的花样够丰富,泛化能力自然就强。
六种方法可以单独用,也可以组合用。
就像考试,规定只能带一张A4纸笔记。
你得筛选最重要的内容,删掉无关的细节。
模型也是一样,要学会提炼精华,而不是囫囵吞枣。

欠拟合怎么治?三种方法
欠拟合的问题正好反过来。
模型太弱了,需要加强。
第一种,增加模型复杂度。
线性回归学不到曲线关系?换成多项式回归。
一次项不够就加二次项,三次项。
神经网络层数不够?加深加宽。
简单模型表达能力有限,得升级。
第二种,特征工程。
也许不是模型太弱,而是喂给它的特征不够好。
去掉跟目标无关的噪音特征。
加入跟目标更相关的新特征。
房价预测里加上"是否学区房",预测能力立刻提升。
第三种,减少正则化。
正则化过度了,模型学不动。
适当放宽限制,给模型更多自由。
就像绑着手脚考试,发挥不出正常水平。
欠拟合和过拟合是一个天平的两端。
解决一个可能让另一个变严重。
需要反复调试,找到最优平衡点。
一分钟诊断:你的模型是记太多还是想太少?
最后来个实战诊断方法。
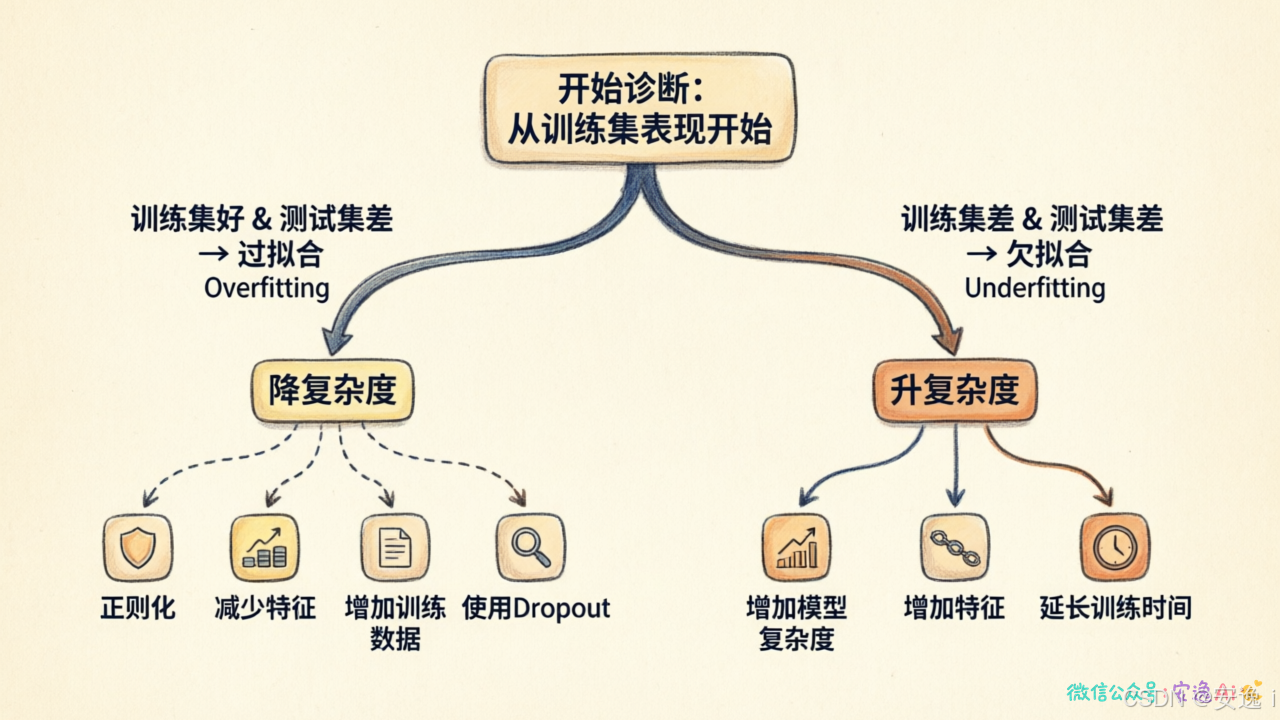
遇到模型表现不好,先判断是哪个问题。
方法很简单,看两个数字:
训练集准确率和测试集准确率。
如果训练集高、测试集低------过拟合。
模型记住了太多,没学到真正的规律。
如果两者都低------欠拟合。
模型太笨了,什么都没学到。
诊断清楚了,方向就对了。
对症下药才能药到病除。
过拟合就降复杂度、加正则、增数据。
欠拟合就升复杂度、加特征、减正则。
方向对了,调参就是细枝末节了。
就像看病,先确诊是发烧还是感冒,才能开药。
模型训练是一个找平衡的过程
过拟合和欠拟合,像是天平的两端。
模型太简单,欠拟合。
太复杂,过拟合。
找到一个合适的复杂度,是训练的核心目标。
这个过程没有标准答案。
数据不同,任务不同,最优复杂度也不同。
只能不断尝试,不断调整。
但好消息是,一旦你理解了这两个问题,遇到模型表现不及预期时,你就有了一套诊断框架。
是"记太多"还是"想太少"?
先想清楚这个问题,再动手调参。
比你瞎试一百遍都管用。
现在你知道模型为什么会在训练集上表现好、测试集上表现差了。
但训练集和测试集上的"好"和"差",具体怎么衡量?
准确率真的够用吗?
有没有更精细的指标?
下回我们就来聊评估指标的那些坑。