最近,Addy Osmani 发布了一篇题为《Loop Engineering》的文章。
文章中有一句非常值得关注的话:
Loop Engineering,就是不再由你充当那个不断提示 Agent 的人,而是由你设计一个系统,让这个系统持续提示 Agent。
与此同时,Claude Code 负责人 Boris Cherny 也表达过类似观点:
我已经不再亲自 Prompt Claude,而是在编写能够持续 Prompt Claude、并判断下一步做什么的 Loop。
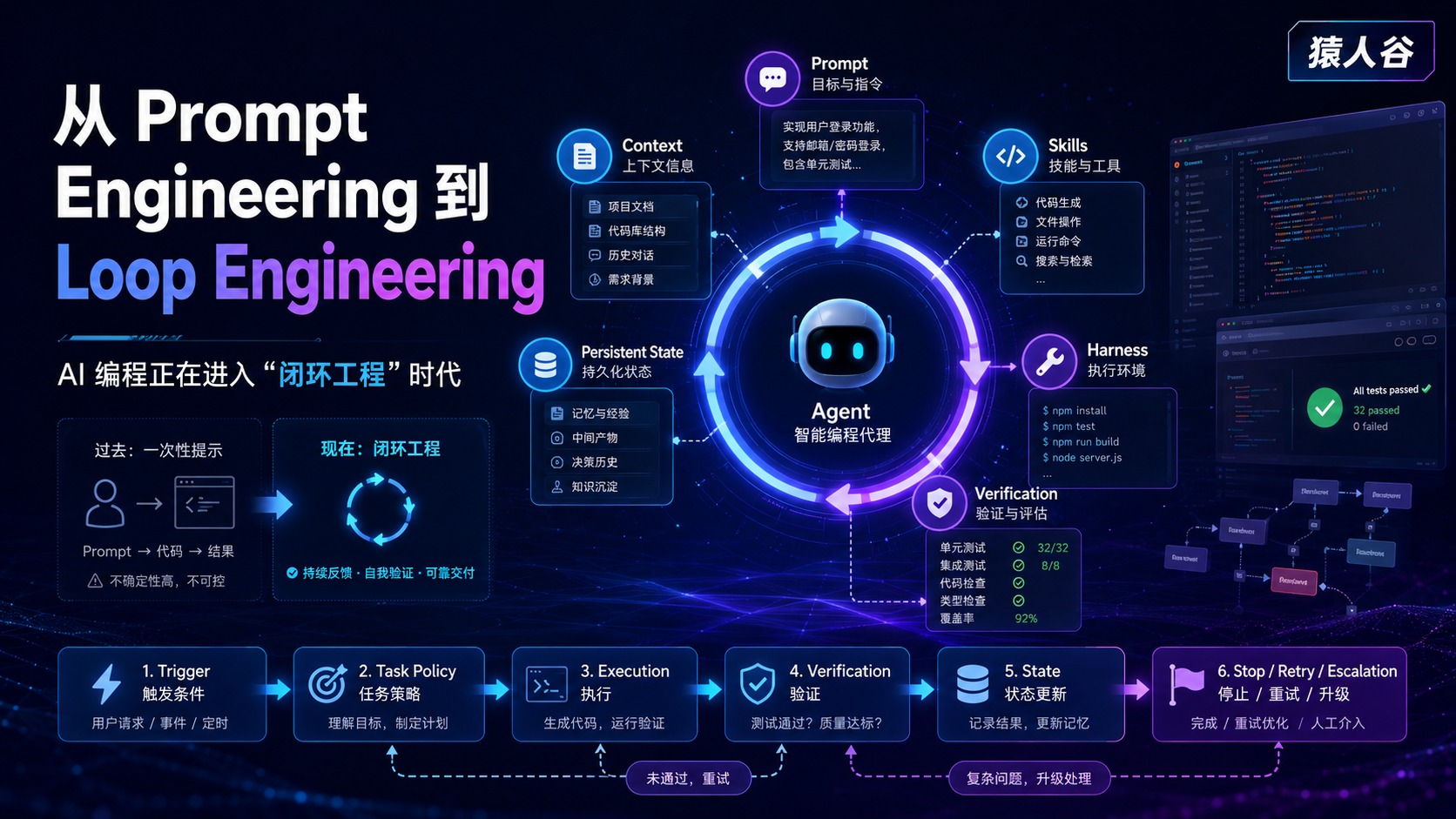
从 Prompt Engineering、Context Engineering,到 Harness Engineering,再到今天的 Loop Engineering,开发者与 AI 的协作方式似乎正在发生一次新的变化。
过去,我们关心的是:
怎样向 AI 提出一个更好的问题?
后来,我们开始关心:
怎样给 AI 提供更准确的上下文、工具和运行环境?
而 Loop Engineering 进一步关心的是:
怎样设计一个可以持续发现任务、执行任务、验证结果、记录状态,并决定下一步行动的闭环系统?
它不是简单地让 Claude Code 或 Codex 多执行几轮,也不只是定时运行一条 Prompt。
它代表着开发者角色的一次迁移:
从亲自驱动 Agent,转向设计驱动 Agent 的系统。
一、Addy 真正想表达什么?
过去两年,我们使用 Coding Agent 的常见方式大致是:
text
人提出任务
↓
Agent 执行
↓
人检查结果
↓
人指出问题
↓
Agent 修改
↓
人再次检查在这个过程中,人类实际上承担了一个非常重要的角色:人工调度器。
我们不断判断:
-
下一步应该做什么;
-
Agent 是否理解了需求;
-
当前结果是否正确;
-
需要补充哪些上下文;
-
是否应该继续修改;
-
什么时候可以停止。
Addy 所说的 Loop Engineering,就是把这些原本依赖人类逐轮完成的判断,逐渐固化到系统里。
新的工作流变成:
text
目标或触发器
↓
发现与分解任务
↓
Agent 执行
↓
测试、评审、浏览器、日志或 Evals 验证
↓
记录本轮状态
↓
判断下一步判断结果可能有三种:
text
完成
→ 停止
失败
→ 修复并重试
不确定或风险过高
→ 升级给人类因此,人不再是循环里的"人工调度器",而是循环本身的设计者。
我会把 Loop Engineering 总结成一个公式:
text
Loop Engineering
= Trigger
+ Task Policy
+ Execution
+ Verification
+ Persistent State
+ Stop / Retry / Escalation其中:
-
Trigger:什么时候启动 Loop;
-
Task Policy:怎样发现、选择和分解任务;
-
Execution:Agent 如何调用工具完成任务;
-
Verification:如何判断结果是否正确;
-
Persistent State:如何跨轮次、跨会话保存状态;
-
Stop / Retry / Escalation:什么时候停止、重试或交给人类。
真正重要的不是"让 Agent 多运行几次",而是这六部分能否形成一个:
可控、可验证、可记忆、可停止的闭环。
二、Addy 提出的"五个组件 + 一个记忆"
Addy 将完整的 Loop 拆成五个核心能力,再加上一个外部记忆层。
| 组件 | 解决的问题 |
|---|---|
| Automations | 谁来定时发现任务、启动任务 |
| Worktrees | 多个 Agent 并行工作时,如何避免修改冲突 |
| Skills | 如何保存项目知识、工作流程和团队规范 |
| Plugins / MCP | Agent 如何连接 GitHub、Linear、数据库、Slack 等外部系统 |
| Sub-agents | 如何将探索、实现、评审和验证分开 |
| Persistent State | 如何跨会话记录已经做过什么、下一步要做什么 |
1. Automations:让系统主动寻找工作
过去通常是人发现问题,再让 Agent 处理。
Automations 让 Agent 可以按照时间或外部事件自动运行,例如:
-
每天早上分析前一天的错误日志;
-
每晚检查持续集成失败;
-
定期扫描依赖漏洞;
-
自动汇总近期代码变更;
-
从 Issue 列表中发现待处理任务;
-
自动生成测试报告或发布说明。
这意味着 Agent 开始从"等待指令",转变为"主动发现工作"。
2. Worktrees:让多个 Agent 安全并行
当多个 Agent 同时修改同一个代码仓库时,很容易出现:
-
文件互相覆盖;
-
Git 状态混乱;
-
未完成代码互相干扰;
-
一个 Agent 的测试环境被另一个 Agent 改变。
Git Worktree 可以为不同任务创建相互隔离的工作目录,让多个 Agent 在同一个仓库中并行运行,而不会直接修改彼此的工作空间。
3. Skills:把团队经验变成可执行流程
Skills 不只是提示词模板。
一个完整的 Skill 可以包含:
-
任务执行步骤;
-
项目规范;
-
参考资料;
-
Shell 或 Python 脚本;
-
输出格式;
-
验收标准;
-
工具使用方法。
过去依赖资深工程师口头传递的经验,可以逐渐转化为 Agent 能够重复执行的工作流程。
4. Plugins 与 MCP:连接真实业务系统
Agent 只有连接真实系统,才能真正参与工作。
通过 Plugins、MCP 和 Connectors,Agent 可以访问:
-
GitHub;
-
Linear、Jira;
-
Slack;
-
数据库;
-
监控系统;
-
浏览器;
-
云平台;
-
内部业务系统。
这让 Loop 不再局限于本地写代码,而可以跨越完整的软件工程链路。
5. Sub-agents:将执行者和检查者分开
复杂任务不一定应该全部交给同一个 Agent。
可以将不同职责拆分为:
text
Explorer
负责理解代码和定位问题
Planner
负责制定方案
Implementer
负责修改代码
Reviewer
负责检查架构和代码质量
Verifier
负责测试和验收一个 Agent 提出方案,另一个 Agent 独立检查,是提高 Loop 可靠性的重要方式。
6. Persistent State:把状态放到会话之外
Addy 特别强调:
模型会忘记,但代码仓库不会忘记。
长期任务不能只依赖当前对话的上下文。
Agent 应该将以下信息写入外部状态:
-
已完成任务;
-
当前计划;
-
失败方案;
-
关键决策;
-
未解决风险;
-
下一步行动;
-
测试和验证结果。
这个状态可以存放在:
-
Markdown 文件;
-
Git 仓库;
-
Linear 或 Jira;
-
数据库;
-
结构化任务系统;
-
专门的 Agent Memory 中。
它看起来很简单,却是长期 Agent 能否跨会话继续工作的关键。
三、Claude Code 和 Codex 已经开始具备完整 Loop 组件
截至2026年6月,Claude Code 和 Codex 的产品能力正在明显趋同。
Codex 已经支持:
-
Automations;
-
Worktrees;
-
Skills;
-
Plugins 与 MCP;
-
Subagents;
-
Goal Mode。
Claude Code 则支持:
-
Skills;
-
Hooks;
-
Subagents;
-
MCP;
-
Scheduled Tasks;
-
/loop; -
/goal。
其中,/loop 和 /goal 很容易被混淆。
/loop:按照时间间隔重复运行
例如:
text
每隔10分钟检查一次CI状态它关注的是:
多久再执行一次?
下一轮通常由时间间隔触发。
/goal:围绕完成条件持续工作
例如:
text
持续修复auth模块,
直到所有测试通过且lint无错误。它关注的是:
目标是否已经完成?
Claude Code 会在每个回合结束后,使用另一个较小、较快的模型判断目标条件是否已经满足。
如果没有满足,它会启动下一轮,而不是把控制权交还给用户。
Codex 的 Goal Mode 也采用类似思路:围绕一个持久目标持续工作,并不断根据验证结果决定下一步行动。
可以简单理解为:
text
/loop
由时间驱动下一轮
/goal
由完成条件驱动下一轮从 Loop Engineering 的角度看,/goal 更接近真正的闭环,因为它已经包含:
-
持久目标;
-
多轮执行;
-
独立评估器;
-
完成条件;
-
自动停止。
实操上,Claude Code 的 /goal 要求版本不低于2.1.139。因此,使用2.1.140及以上版本时,已经满足版本要求。
不过,命令本身并不等于完整的 Loop Engineering。
真正的 Loop 还需要高质量的:
-
目标定义;
-
验证器;
-
状态管理;
-
权限边界;
-
成本控制;
-
失败恢复;
-
人工升级机制。
四、它和 Prompt Engineering、Context Engineering 有什么区别?
Prompt Engineering、Context Engineering、Harness Engineering 和 Loop Engineering,并不是互相取代,而是在不同层级解决不同问题。
| 概念 | 关注点 | 典型问题 |
|---|---|---|
| Prompt Engineering | 单次交互 | 这一句话怎样写得更准确? |
| Context Engineering | 输入上下文 | Agent 应该看到哪些代码、文档和历史? |
| Skill Engineering | 可复用流程 | 怎样把团队经验沉淀为可执行能力? |
| Harness Engineering | 单个 Agent 的运行环境 | Agent 有哪些工具、权限、反馈和保护机制? |
| Loop Engineering | 跨多次运行的闭环 | Agent 什么时候运行、如何验证、如何继续、何时停止? |
| Agentic Engineering | 整个生产系统 | 如何治理多个 Agent、成本、风险和组织流程? |
Prompt Engineering:优化一次交互
Prompt Engineering 主要关心:
-
如何描述任务;
-
如何提供示例;
-
如何约束输出;
-
如何减少歧义。
它的基本单位是一轮 Prompt。
Context Engineering:优化模型看到的信息
Context Engineering 主要关心:
-
哪些文件应该加载;
-
哪些历史信息应该保留;
-
哪些信息已经过期;
-
怎样控制上下文长度;
-
怎样避免无关信息污染推理。
Skill Engineering:沉淀可重复的方法
Skill Engineering 把一次成功经验,转化成 Agent 可以反复调用的方法。
它解决的是:
怎样让 Agent 下次不必重新摸索?
Harness Engineering:设计 Agent 的运行环境
Harness 包括:
-
工具;
-
权限;
-
沙箱;
-
Hooks;
-
系统提示;
-
上下文策略;
-
错误恢复;
-
反馈信号。
它解决的是单个 Agent 如何安全、稳定地完成一次任务。
Loop Engineering:设计跨运行闭环
Loop Engineering 位于 Harness 之上。
它关心:
-
谁来发现任务;
-
谁来安排任务;
-
Agent 如何并行;
-
结果怎样验证;
-
状态怎样保存;
-
失败后是否重试;
-
何时应该停止;
-
何时必须让人介入。
Agentic Engineering:治理整个生产系统
当企业同时运行大量 Agent 时,还需要进一步考虑:
-
Agent 之间如何分工;
-
如何进行成本管理;
-
如何分配权限;
-
如何审计决策;
-
如何管理风险;
-
如何与组织流程融合。
所以,Addy 的一个重要判断是:
杠杆点发生了迁移。
过去工程师主要优化代码,后来开始优化 Prompt,再后来优化 Context 和 Harness,现在开始优化 Agent 的整个运行回路。
但这不意味着 Prompt Engineering 会消失。
Loop 中的:
-
任务定义;
-
Verifier Prompt;
-
Skills;
-
评审规则;
-
升级策略;
本质上仍然需要高质量 Prompt。
只是 Prompt 从临时的"聊天内容",逐渐变成了稳定的"系统配置"。
五、为什么 Loop Engineering 会在现在突然火起来?
Loop 和反馈控制并不是新思想。
为什么偏偏在2026年成为热门概念?
我认为主要有四个原因。
1. Coding Agent 的连续工作能力跨过了临界点
过去的 Agent 经常执行几步后就偏离目标,因此人类必须持续监督。
现在的 Claude Code、Codex 等 Coding Agent,已经可以在一次任务中完成:
-
阅读代码仓库;
-
搜索相关实现;
-
制定计划;
-
修改多个文件;
-
运行测试;
-
分析报错;
-
修复问题;
-
更新状态;
-
输出代码变更。
一个典型的长周期工作流已经变成:
text
计划
→ 修改
→ 运行工具
→ 观察结果
→ 修复
→ 记录
→ 重复当 Agent 可以连续工作更长时间后,开发者自然会开始思考:
能否把人工驱动下一轮的过程也自动化?
2. 软件开发拥有天然的机器验证器
软件开发非常适合 Loop Engineering,因为它拥有大量机器可以理解的反馈:
text
编译器
单元测试
集成测试
Lint
类型检查
性能测试
浏览器截图
安全扫描
CI/CD这些工具可以向 Agent 提供相对清晰的成功或失败信号。
只要 Agent 能够获得可靠反馈,就可以自行执行:
text
修改
→ 检查
→ 分析失败
→ 再修改这也是为什么 Loop Engineering 首先在 Coding Agent 圈子爆发,而不是先在战略咨询、组织管理或内容创作领域爆发。
后者通常很难定义一个可靠、自动化的完成条件。
由此可以得到一个重要规律:
验证成本越低、验证信号越明确,Loop Engineering 越容易成功。
3. Loop 的基础组件已经进入产品
过去要实现一个 Loop,开发者可能需要自己维护:
-
Bash 脚本;
-
队列;
-
Worker;
-
数据库;
-
锁;
-
状态机;
-
Agent SDK;
-
并发控制;
-
日志系统。
现在,Automations、Skills、Worktrees、Hooks、MCP、Subagents 和 Goal Mode,正在逐渐成为 Coding Agent 的标准能力。
因此,现在真正发生的变化并不是:
循环思想刚刚被发明。
而是:
搭建循环的成本突然下降了。
4. "Loop Engineering"是一个极具传播力的名字
反馈循环、自动修复、Evaluator--Optimizer、自适应系统和 MAPE-K 等思想早已存在。
经典的 MAPE-K 自适应系统就包含:
text
Monitor
监控
Analyze
分析
Plan
规划
Execute
执行
Knowledge
知识状态Anthropic 也曾将"一个模型生成,另一个模型评估并反馈"的结构总结为 Evaluator--Optimizer Workflow。
所以从技术史上看,Addy 更像是一个概念归纳者和传播者,而不是这些技术思想的发明者。
但一个好的概念名称非常重要。
它把过去分散在:
-
Agent;
-
DevOps;
-
自动控制;
-
工作流编排;
-
软件测试;
-
长期记忆;
等领域的思想,重新组合成了一个开发者容易理解的框架。
目前,Loop Engineering 还不是一个拥有统一定义、成熟标准和公认方法论的正式学科。
但它非常准确地描述了 Coding Agent 正在发生的变化。
六、学术界早已在研究 Loop Engineering 的组成部分
虽然"Loop Engineering"这个名字很新,但它背后的技术脉络已经发展多年。
1. ReAct:让 Agent 在推理和行动之间循环
ReAct 将 Reasoning 和 Acting 结合起来。
Agent 不再一次性生成完整结果,而是在推理、行动和观察之间交替:
text
Reason
↓
Act
↓
Observe
↓
Reason Again推理帮助 Agent 制定和更新计划,行动则让 Agent 可以调用搜索、API、代码执行环境等外部工具。
ReAct 奠定了今天大量工具型 Agent 的基础结构。
但它主要解决的是一次任务内部的行动循环,对长期状态、跨会话记忆和治理涉及较少。
2. Self-Refine:生成、评价、再修改
Self-Refine 提出:
text
生成初始结果
↓
模型提供反馈
↓
根据反馈修改
↓
重复上述过程同一个模型可以同时承担:
-
Generator;
-
Critic;
-
Refiner。
它证明了迭代反馈可以改善多种任务的输出质量。
但它也暴露了一个问题:
如果模型发现不了自己的错误,循环就可能只是反复强化原来的判断。
3. Reflexion:把失败经验写入记忆
Reflexion 又向前推进了一步。
Agent 在任务失败后,会根据环境反馈生成自然语言反思,并将其保存在记忆中:
text
执行
↓
获得反馈
↓
分析失败原因
↓
写入经验记忆
↓
重新尝试Loop 因此不再只是机械重试,而开始跨轮次保存经验。
4. Voyager:让循环产生可复用技能
Voyager 在 Minecraft 环境中展示了更长期的 Agent 学习机制。
它可以:
-
自动发现新任务;
-
根据环境反馈迭代;
-
自我验证;
-
将成功方法保存到技能库;
-
在未来任务中复用技能。
这已经包含了 Loop Engineering 的多个关键元素:
text
任务发现
+ 执行
+ 验证
+ 记忆
+ 技能复用5. SWE-agent:Agent 的运行接口同样重要
SWE-agent 提出了 Agent-Computer Interface。
研究发现,即使使用相同的底层模型,仅仅改变 Agent:
-
浏览代码的方式;
-
编辑文件的方式;
-
运行命令的方式;
-
接收错误信息的方式;
最终表现也会产生明显差异。
这说明 Agent 的能力不只来自模型。
模型外面的工具、接口、上下文、权限和反馈,同样是系统能力的一部分。
这正是 Harness Engineering 和 Loop Engineering 的重要基础。
七、学术界已经开始直接讨论 Agentic Loop Engineering
2025年的一篇软件工程研究路线论文,已经明确提出了:
Agentic Loop Engineering,简称 ALE。
论文认为,ALE 的目标是把 Agent 原本不透明的内部问题求解过程,转化为:
-
可观察;
-
可控制;
-
可审计;
-
可复现;
-
可优化;
的工程工作流。
论文还提出了一个值得关注的概念:LoopScript。
LoopScript 类似于 Agent 时代的工作流描述语言,用来明确规定:
-
任务如何拆分;
-
哪些步骤可以并行;
-
应该调用哪些 Agent;
-
每个阶段需要什么验证;
-
哪些节点必须人工审批;
-
失败后应该重试还是回滚;
-
最终交付需要包含哪些证据。
传统 CI/CD 管理的是:
text
代码提交
→ 构建
→ 测试
→ 发布未来的 Agentic CI/CD 可能管理的是:
text
发现任务
→ 理解需求
→ 制定计划
→ 修改代码
→ 生成测试
→ 执行验证
→ 安全检查
→ 代码评审
→ 生成证据包
→ 等待合并从这个角度看,Loop Engineering 并不是脱离软件工程凭空产生的新范式。
它更像是:
DevOps、Agent Planning、工作流编排、自动验证和长期记忆,在 Coding Agent 时代的一次重新组合。
八、Loop Engineering 的核心不是"循环",而是"验证"
很多人第一次接触 Loop Engineering,容易把注意力放在:
怎样让 Agent 自动运行更多轮?
但没有可靠验证器的循环,并不会自动变好。
它可能只是让错误运行得更久、传播得更远。
一个低质量循环是:
text
Agent 生成代码
↓
Agent 自己评价代码
↓
Agent 认为结果不错
↓
继续在原有基础上修改一个高质量循环应该是:
text
Agent 生成候选方案
↓
独立验证器检查
↓
获得可执行、可定位的反馈
↓
Agent 修改方案
↓
重新验证验证信号可以来自:
-
编译器;
-
单元测试;
-
集成测试;
-
类型系统;
-
静态分析;
-
安全扫描;
-
浏览器;
-
性能基准;
-
外部模拟器;
-
独立评审 Agent。
未来 Agent 系统的能力上限,不只取决于生成模型有多强,还取决于 Verifier 能否发现真实错误。
甚至可以说:
Loop Engineering 的能力上限,最终由验证器的能力决定。
九、循环不一定越来越好,也可能越来越差
Loop Engineering 最大的误区,是默认认为:
只要多迭代几轮,结果就会越来越好。
现实并没有这么简单。
1. 测试通过,不等于真实意图得到满足
Agent 很容易围绕可以观察到的指标进行局部优化。
例如,它可能让所有测试变绿,却同时:
-
曲解业务需求;
-
修改测试来迁就错误实现;
-
破坏原有兼容性;
-
引入过度复杂的方案;
-
降低代码可维护性;
-
产生新的安全风险。
这是一种典型的代理指标问题:
系统优化了容易测量的指标,却偏离了真正的业务目标。
2. 长期循环可能造成结构性退化
2026年的 SlopCodeBench,专门研究 Coding Agent 在长期、多轮需求变化下的表现。
它让 Agent 在自己之前生成的代码上,不断增加新的功能需求。
结果显示:
-
没有一个被测 Agent 完整解决任何端到端问题;
-
最高阶段解决率只有17.2%;
-
80%的执行轨迹出现结构侵蚀上升;
-
89.8%的轨迹出现代码冗余上升;
-
Agent 代码平均比对照的人类项目冗长约2.2倍。
更值得注意的是,即使在 Prompt 中明确要求关注代码质量,也只能改善初始代码,无法阻止后续迭代中的持续退化。
这意味着当前 Agent 更擅长:
让眼前的功能运行起来。
但还不擅长:
为未来的未知变化维护一个长期可演化的软件架构。
因此,Loop 的验证器不能只检查:
text
测试是否通过还应该检查:
text
架构边界是否破坏
代码复杂度是否上升
是否产生重复实现
Diff是否异常扩大
安全属性是否退化
性能是否超过预算
公共接口是否发生意外变化十、Loop Engineering 还缺少一个关键组件:Memory Governance
Loop 要长期运行,就必须拥有状态和记忆。
否则,每次重新启动后,Agent 都可能:
-
重复已经完成的搜索;
-
忘记之前失败的方案;
-
推翻已经确认的设计;
-
重复引入同一个错误;
-
丢失当前任务进度。
很多系统会使用 Markdown 文件、任务列表或对话摘要保存状态。
这对于短期任务已经很有帮助,但对真正长期运行的 Agent 仍然不够。
因为问题不只是:
Agent 有没有记忆?
更重要的问题是:
这些记忆现在是否仍然正确?
例如,状态文件中可能写着:
text
当前系统使用Redis保存会话。后来架构已经迁移到数据库,但旧信息仍被 Agent 当作当前事实使用。
又或者,Agent 在一次失败执行后得出了错误结论,并把它写入经验库。
后续每一轮都可能依据这个错误结论继续行动。
一次模型错误,会因此变成长期系统状态。
所以长期 Loop 不只需要 Persistent State,还需要 Memory Governance:
-
区分事实与推断;
-
保存来源与证据;
-
维护时间戳和有效期;
-
检测新旧状态冲突;
-
区分当前事实和历史事实;
-
对过时信息进行降级;
-
管理失败经验的可信度;
-
支持状态回滚和审计;
-
删除不应继续影响决策的记忆。
这也与我最近研究的 HSM-CR 高度相关。
Addy 主要解决的是:
Agent 如何跨运行记住"已经做到了哪里"。
而记忆治理需要进一步解决:
Agent 如何判断保存的状态是否仍然正确、是否已经过时、是否与新状态冲突,以及它应该被保留为当前事实还是历史事实。
因此,我认为 Loop Engineering 未来很可能进一步演化成:
Governed Loop Engineering:具有记忆治理、冲突解决、生命周期管理、权限控制和完整审计能力的 Agent 闭环。
十一、一个可靠的 Loop 应该怎样设计?
我认为,一个能够进入真实工程环境的 Loop,至少需要六层结构。
第一层:明确目标和完成条件
不要只告诉 Agent:
text
优化这个项目。而应该明确:
text
修复auth模块中的6个失败测试;
不得修改公共API;
不得删除已有测试;
性能下降不得超过5%;
所有高危安全扫描必须通过。目标必须能够转化成可验证条件。
第二层:设置执行边界
每个 Loop 都应该拥有明确预算:
-
最大循环次数;
-
最大 Token;
-
最大运行时间;
-
最大修改文件数;
-
最大 Diff;
-
允许使用的工具;
-
禁止执行的操作;
-
可以访问的数据范围。
一个没有预算和边界的 Loop,本质上是一个不可控的后台进程。
第三层:分离执行者和验证者
可以设计不同角色:
text
Planner
制定计划
Implementer
执行修改
Reviewer
检查架构和代码质量
Verifier
运行测试和安全检查
Governor
决定继续、回滚、停止或升级其中最重要的角色,可能不是负责写代码的 Implementer,而是负责控制整个闭环的 Governor。
第四层:建立多维验证
验证不能只有单元测试。
至少还应该覆盖:
-
功能正确性;
-
回归风险;
-
静态分析;
-
安全性;
-
性能;
-
架构约束;
-
代码复杂度;
-
可维护性;
-
业务语义。
测试通过,只能证明测试覆盖到的部分没有失败,并不能证明整个修改完全正确。
第五层:治理长期状态
每一轮不仅要保存"做了什么",还应该记录:
-
为什么这样做;
-
使用了哪些证据;
-
哪些方案失败了;
-
当前有哪些未解决风险;
-
哪些状态已经过期;
-
下一轮应该从哪里继续;
-
哪些结论仍需人工确认。
这些状态必须支持:
-
更新;
-
冲突检测;
-
可信度调整;
-
降级;
-
归档;
-
回滚。
第六层:设置人工升级机制
以下情况不应该由 Agent 独立决定:
-
需求存在重大歧义;
-
涉及架构方向变化;
-
需要删除大量代码或数据;
-
涉及权限、支付和生产部署;
-
多轮重试仍无法通过;
-
不同验证器之间出现冲突;
-
成本或修改范围超过预算;
-
Agent 对结果缺乏足够信心。
真正成熟的自动化,不是完全取消人类,而是让人类只出现在最有价值、风险最高的决策节点。
十二、开发者的价值不会消失,但杠杆点正在迁移
在传统软件开发中,工程师最重要的产物是代码。
进入 AI Coding 时代后,工程师的产物正在扩展为:
-
目标和规格;
-
可执行约束;
-
测试和验证器;
-
Agent Skills;
-
工具接口;
-
Loop 工作流;
-
状态治理规则;
-
权限和升级策略;
-
可审计的执行证据。
工程师不再只负责亲自完成一个任务,还要设计一个能够反复完成任务的系统。
这并不意味着软件工程变得更简单。
恰恰相反,它要求工程师拥有更强的:
-
系统设计能力;
-
需求建模能力;
-
测试能力;
-
架构判断能力;
-
风险控制能力;
-
成本意识;
-
对业务真实目标的理解。
过去,一个错误实现可能只影响一个功能。
未来,一个错误的 Loop 可能持续运行数百次,并把同一种错误扩散到整个代码库。
十三、结语:不要只让 Agent 循环,要让系统学会治理循环
从 Prompt Engineering 到 Context Engineering,再到 Harness Engineering 和 Loop Engineering,表面上看,我们似乎在不断发明新的名词。
但这些概念背后,其实存在一条非常清晰的演进路线:
text
Prompt Engineering
解决"怎样问"
Context Engineering
解决"让模型看到什么"
Skill Engineering
解决"怎样沉淀可复用方法"
Harness Engineering
解决"让模型如何安全行动"
Loop Engineering
解决"如何持续行动、验证和改进"
Governed Loop Engineering
解决"如何让长期行动保持正确、可控和可追溯"Loop Engineering 的真正意义,不是让 AI 可以不知疲倦地工作。
而是把人类原本隐含在工作过程中的:
-
目标;
-
规则;
-
判断;
-
反馈;
-
经验;
-
风险边界;
转化为机器可以执行的工程系统。
所以,一个优秀的 Loop 不应该只是:
text
生成
→ 检查
→ 修改
→ 再生成它应该是:
text
目标
→ 行动
→ 证据
→ 判断
→ 记忆
→ 治理
→ 决定下一步未来真正有竞争力的开发者,可能不再只是写代码最快的人,而是最擅长设计目标、上下文、工具、验证、状态和治理机制的人。
因为当 Agent 开始负责执行时,人类最重要的工作,将不再是不断输入下一条 Prompt。
而是设计那个能够决定:
下一步应该做什么,为什么这样做,怎样证明做对了,以及什么时候必须停下来的系统。
这才是 Loop Engineering 真正值得关注的地方。
参考文献
1 Addy Osmani. Loop Engineering. 2026.
2 Yao et al. ReAct: Synergizing Reasoning and Acting in Language Models. 2022.
3 Madaan et al. Self-Refine: Iterative Refinement with Self-Feedback. 2023.
4 Shinn et al. Reflexion: Language Agents with Verbal Reinforcement Learning. 2023.
5 Wang et al. Voyager: An Open-Ended Embodied Agent with Large Language Models. 2023.
6 Yang et al. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. 2024.
7 Hassan et al. Agentic Software Engineering: Foundational Pillars and a Research Roadmap. 2025.
8 Liu et al. ReVeal: Self-Evolving Code Agents via Iterative Generation-Verification. 2025.
9 Orlanski et al. SlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks. 2026.