开篇介绍:
hello 大家,那么我们又见面了哈哈,那么在上篇博客中,我们一起学习了进程控制的相关知识,知道了关于pthread一系列的函数接口,那么接下来在本篇博客中,我们就将一起学习线程中的局部存储的知识以及对线程的一系列接口进行一个封装,使其形成一个类。
OK那么我们话不多说,直接开始。
线程局部存储(TLS):
一、先从 "宿舍共享吹风机" 的烦恼 ------ 理解没有 TLS 的坑
咱们先抛开代码,用生活场景把 "线程共享全局变量" 的问题说透:
假设你们宿舍有一个公共吹风机(相当于全局变量count),4 个室友(相当于 4 个线程)共用。室友 A 刚用了一半没电了(把count改成 5),室友 B 接着用,看到的就是 "只剩一半电"(读到count=5);室友 B 充满电(把count改成 10),室友 C 再用,看到的就是满电 ------ 这就是 "共享" 的本质:所有使用者共用同一个东西,一个人的修改会直接影响其他人。
放到程序里,一个进程里的线程就像室友,全局变量就是公共吹风机。如果线程 A 要统计自己处理的任务数,用全局变量task_count,结果线程 B 也用这个变量统计自己的任务,最后task_count里的数字根本分不清是谁的 ------ 这就是 "共享变量的线程安全问题",也是为什么需要线程局部存储(TLS) 的核心原因。
二、TLS 就是给每个 "室友" 发专属吹风机 ------ 它到底是什么?
线程局部存储(Thread-Local Storage,简称 TLS),说白了就是系统给每个线程发一个 "专属副本":
原本是 "全进程共用" 的变量(比如加了__thread的count),系统会为每一个访问它的线程单独分配一块内存空间,相当于给每个线程都定制了一个 "一模一样的变量"------ 变量名还叫count,但线程 A 用的是count_A,线程 B 用的是count_B,线程 C 用的是count_C...... 它们的名字看起来一样,但底层是完全独立的 "私有财产"。
再回到宿舍例子:
- 没有 TLS:全宿舍 1 个吹风机,谁用都得接着上一个人的状态;
- 有 TLS:宿管给每个室友发了专属吹风机,都叫 "宿舍吹风机",但 A 用 A 的、B 用 B 的,A 把自己的吹风机用没电了,B 的还是满电 ------ 彼此完全不干扰。
这就是 TLS 的核心:"同名不同体",变量名相同,但每个线程拥有独立的实例。
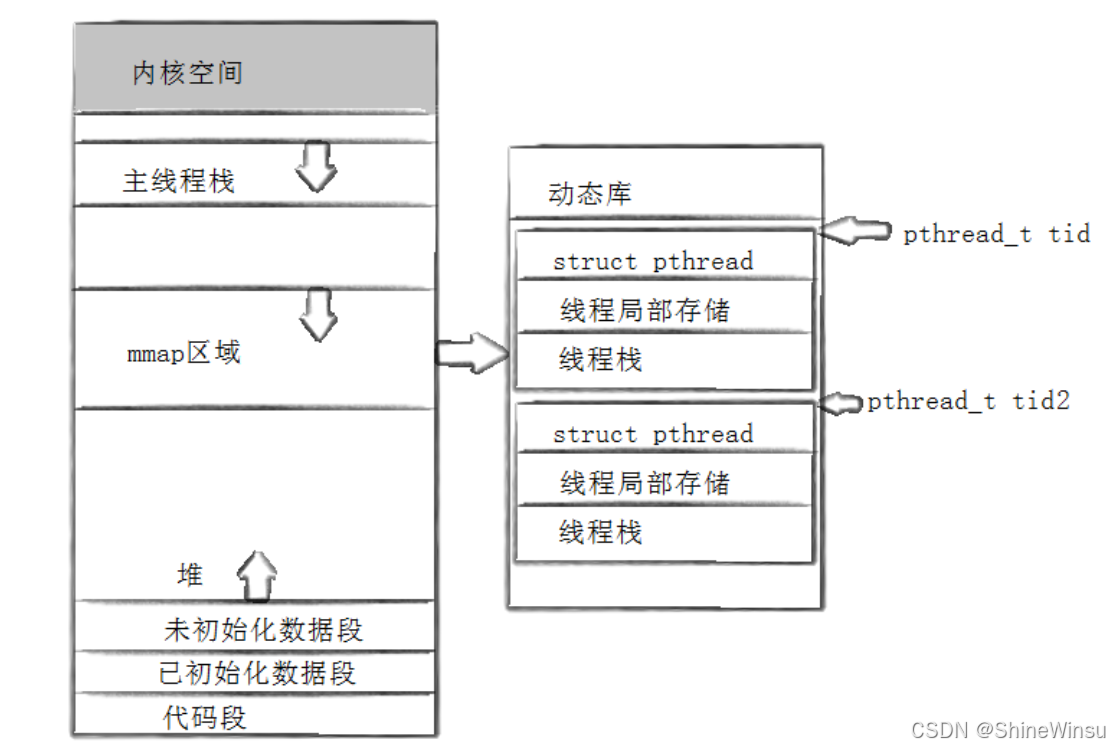
三、TLS 的 "魔法" 是怎么实现的?------ 系统偷偷做了这些事
你可能会好奇:为什么加个__thread,变量就从 "共享" 变 "私有" 了?其实系统在背后做了 3 件关键事:
1. 给每个线程建一个 "TLS 专属抽屉"
操作系统管理线程时,会给每个线程维护一块专门的内存区域,叫 "TLS 存储区"------ 相当于每个线程都有一个带锁的 "私人抽屉",专门放自己的 TLS 变量。
当你定义__thread int count=0时,系统会记住:"这个count是 TLS 变量,每个线程用的时候都要去自己的'抽屉'里拿"。
2. 线程创建时,自动 "填充抽屉"
当你用pthread_create创建新线程时,系统会:
- 先检查有没有 TLS 变量(比如
count); - 如果有,就在这个新线程的 "TLS 抽屉" 里,为
count分配一块内存,初始化值为 0(就是你定义的初始值); - 这个
count只属于这个新线程,和其他线程的count没关系。
就像新生入学,宿管会自动给每个新室友的 "抽屉" 里放好专属吹风机,不用自己申请。
3. 访问变量时,自动 "找对抽屉"
当线程里的代码访问count时,系统会偷偷做一个 "地址转换":
- 不是直接去全局内存找
count,而是先查 "当前线程是谁"(比如线程 A); - 然后去线程 A 的 "TLS 抽屉" 里,找到 A 专属的
count副本; - 你以为自己访问的是 "全局变量
count",其实系统已经帮你换成了 "线程 A 的私有count"。
这就像你喊 "我要拿吹风机",宿管会根据你的学生证(线程 ID),把你自己的吹风机递给你,而不是拿公共的那个 ------ 你完全没察觉,但拿到的是专属的。
四、TLS 的核心特性 ------ 为什么它能 "隔离" 线程?
1. 线程内 "全局可见",线程间 "完全隔离"
在同一个线程 里,不管是主线程、子线程,还是线程里调用的函数,访问 TLS 变量都是同一个 "副本"------ 比如线程 A 里的函数func1()改了count,函数func2()里看到的就是改后的值,因为它们用的是 A 的专属副本(线程内全局)。
但在不同线程 间,TLS 变量完全看不到对方的修改 ------ 线程 A 把count改成 100,线程 B 的count还是 0,因为它们用的是不同的副本(线程间隔离)。
2. 生命周期和线程 "绑定"
TLS 变量的副本是 "跟着线程走" 的:
- 线程创建时,副本诞生;
- 线程运行时,副本一直存在;
- 线程结束时,副本自动销毁,内存被系统回收。
就像室友毕业(线程结束),他的专属吹风机(TLS 副本)会被宿管收回 ------ 不会占用公共空间,也不会残留数据。
3. 初始化是 "独立的",不会继承
如果你定义__thread int count=10,每个线程的count初始值都是 10,不是 "主线程的count是 10,子线程继承这个 10"------ 它们是各自独立初始化的,起点相同,但后续修改互不影响。
五、TLS 能解决哪些实际问题?------ 这些场景离不了它
TLS 不是 "花架子",实际开发中很多场景都要靠它:
1. 线程专属的计数器 / 状态
比如每个线程要统计自己处理的请求数,用 TLS 变量thread_request_count,线程 A 统计 A 的、线程 B 统计 B 的,最后汇总时直接加起来就行 ------ 不用加锁,也不会乱。
2. 简化线程内的数据传递
比如线程要调用 10 个函数,每个函数都需要用 "线程 ID + 任务参数",不用把这些参数一层层传(函数 1 传给函数 2,函数 2 传给函数 3......),直接存在 TLS 变量里,线程内所有函数都能直接取 ------ 像线程的 "全局背包"。
3. 避免 "线程安全的单例" 冲突
比如日志系统里,每个线程需要一个专属的日志对象(避免多个线程写日志时互相覆盖),用 TLS 存储日志对象,每个线程拿自己的,安全又高效。
4. 存储线程私有的资源句柄
比如数据库连接池里,每个线程从池里拿一个连接后,存在 TLS 里,线程内的所有操作都用这个连接 ------ 不用每次操作都去池里拿,也不会和其他线程的连接冲突。
六、TLS 不是 "万能钥匙"------ 这些坑要避开
TLS 好用,但也有局限性,不能随便用:
1. 类型有限制
不是所有变量都能加__thread:
- 只能用于内置类型(int、char、指针等)或简单的 POD 类型(比如没有自定义构造 / 析构函数的结构体
struct Data { int a; char b; }); - 像
std::string、std::vector这种复杂对象,很多系统不支持直接用__thread修饰 ------ 因为复杂对象需要调用构造函数初始化,TLS 默认的 "简单内存分配" 搞不定。
2. 内存开销会变大
每个线程都有一份 TLS 副本,如果 TLS 变量很大(比如一个 1MB 的数组),创建 1000 个线程就会占用 1GB 内存 ------ 比共用一个全局变量费内存多了,所以不能把大变量随便设为 TLS。
3. 不能跨线程访问
TLS 变量是 "线程私有" 的,主线程想读子线程的 TLS 变量?没门 ------ 系统根本不让你访问其他线程的 "TLS 抽屉",这既是优点也是限制。
4. 初始化只能用常量
TLS 变量的初始值必须是 "编译期就能确定的常量",比如__thread int count=10可以,但__thread int count=get_random()不行 ------ 因为线程创建时,系统没法调用函数初始化 TLS 副本。
七、最后总结:TLS 的本质是 "线程的私有全局变量"
线程局部存储既保留了 "全局变量" 的方便性(线程内随处可访问),又解决了 "共享变量" 的冲突问题(线程间完全隔离)。它就像给每个线程发了一本 "专属笔记本",本子封面都写着 "工作记录",但你写你的、我写我的,永远不会互相蹭掉内容 ------ 这就是 TLS 最核心的价值:用 "同名副本" 实现线程私有,兼顾方便性和安全性。
简单说:没有 TLS,全局变量是 "全进程的公共财产";有了 TLS,全局变量变成 "每个线程的私有财产"------ 名字没变,但归属权彻底变了。
示例代码:
cpp
#include <unistd.h>
#include <iostream>
#include <pthread.h>
#include <string>
#include <cstdlib>
//OK,那么在这里我们主要是来了解一下线程局部存储的问题
//那么我们知道,由于线程本质上就是轻量级进程,所以在总的一个进程内
//其里面的所有线程是指向同一块空间,也就是资源的
//所以,一个线程的资源,另一个线程也可以轻易访问,那么这个不重要,后面会讲到互斥锁来解决
//这里主要是讨论全局变量的问题,那么我们知道,要是我们在一个进程里面创建了一个全局变量
//那么这个进程里面的所有线程都可以去对这个全局变量进行访问、改变
//因为它们能获取到同一个指向该全局变量的地址
// int count=0;
// std::string Addr(int &c)
// {
// char addr[64];
// snprintf(addr, sizeof(addr), "%p", &c);//获取地址
// return addr;//隐式转换
// }
// void *routine1(void *args)
// {
// (void)args;
// while (true)
// {
// std::cout << "thread - 1, count = " << count << "[我来修改count], "
// << "&count: " << Addr(count) << std::endl;
// count++;
// sleep(1);
// }
// }
// void *routine2(void *args)
// {
// (void)args;
// while (true)
// {
// std::cout << "thread - 2, count = " << count
// << ", &count: " << Addr(count) << std::endl;
// sleep(1);
// }
// }
// int main()
// {
// pthread_t tid1, tid2;
// pthread_create(&tid1, nullptr, routine1, nullptr);
// pthread_create(&tid2, nullptr, routine2, nullptr);
// pthread_join(tid1, nullptr);
// pthread_join(tid2, nullptr);
// return 0;
// }
//就如上面的代码所示,两个线程都能对count这个全局变量进行改变,
//因为它们获取到的地址是一模一样的。
//那么提到的线程局部存储是什么呢?
//其实就是针对类似上面的全局变量
//即将该全局变量私有化为某个线程自己的
//换句话来说,对于一个全局变量,不再是可以多个线程都进行访问
//然后一个线程更改该全局变量,另一个线程再去访问该全局变量就得到的是被更改过的
//当我们对某个全局变量进行线程局部存储之后
//那么在每个访问到该全局变量的线程内,都会为该全局变量创建一个空间
//换句话来说就是每个线程将该全局变量私有化,那么此时多个线程访问到的该全局变量就是不一样的
//也就是线程内部自己的,所以获取到的地址也是不一样的哦,具体看下面代码
__thread int count=0;
//在全局变量前面加__thread,那么就代表这个变量是会被线程局部存储
//这里需要注意的是,其只支持内置类型和某些指针类型哦
std::string Addr(int &c)
{
char addr[64];
snprintf(addr, sizeof(addr), "%p", &c);//获取地址
return addr;//隐式转换
}
void *routine1(void *args)
{
(void)args;
while (true)
{
std::cout << "thread - 1, count = " << count << "[我来修改count], "
<< "&count: " << Addr(count) << std::endl;
count++;
sleep(1);
}
}
void *routine2(void *args)
{
(void)args;
while (true)
{
std::cout << "thread - 2, count = " << count
<< ", &count: " << Addr(count) << std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid1, tid2;
pthread_create(&tid1, nullptr, routine1, nullptr);
pthread_create(&tid2, nullptr, routine2, nullptr);
pthread_join(tid1, nullptr);
pthread_join(tid2, nullptr);
return 0;
}还是很简单的大家,那么既然说到了线程局部存储,那么我就再给大家扩展一下pthread库里面的两个函数:pthread_setname_nd和pthread_getname_nd函数:
扩展:
一、函数概述
pthread_setname_np 和 pthread_getname_np 是 Linux 系统下的非标准扩展函数(np 即 non-portable,表示不属于 POSIX 标准),用于设置和获取线程的名称。它们的核心作用是给线程 "贴标签",方便调试时通过工具(如 ps、top、gdb)区分不同线程,尤其在多线程程序中,能快速定位线程的功能和状态。
二、函数原型与参数说明
1. pthread_setname_np(设置线程名)
#include <pthread.h>
int pthread_setname_np(pthread_t thread, const char *name);- 参数 :
thread:目标线程的 ID(通过pthread_create返回或pthread_self()获取当前线程 ID);name:要设置的线程名称(Linux 下长度限制为 15 个字符 ,因为系统会自动添加字符串结束符\0,超过会被截断)。
- 返回值 :
- 成功:返回
0; - 失败:返回非零错误码(如
EINVAL表示名称无效、EPERM表示权限不足、ESRCH表示线程不存在)。
- 成功:返回
2. pthread_getname_np(获取线程名)
#include <pthread.h>
int pthread_getname_np(pthread_t thread, char *name, size_t len);- 参数 :
thread:目标线程的 ID;name:用于存储线程名称的字符缓冲区(需提前分配内存);len:缓冲区的长度(需至少为 16 字节,以容纳 15 个字符 +\0)。
- 返回值 :
- 成功:返回
0,线程名会被写入name缓冲区; - 失败:返回非零错误码(如
EINVAL表示缓冲区长度不足、ESRCH表示线程不存在)。
- 成功:返回
三、使用示例
1. 设置并获取当前线程的名称
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
int main() {
// 获取当前线程 ID
pthread_t self = pthread_self();
// 设置线程名:"main-thread"(11个字符,符合15字符限制)
int ret = pthread_setname_np(self, "main-thread");
if (ret != 0) {
std::cerr << "设置线程名失败,错误码:" << ret << std::endl;
return 1;
}
std::cout << "线程名设置成功!" << std::endl;
// 获取线程名(缓冲区长度设为16)
char name[16];
ret = pthread_getname_np(self, name, sizeof(name));
if (ret != 0) {
std::cerr << "获取线程名失败,错误码:" << ret << std::endl;
return 1;
}
std::cout << "当前线程名:" << name << std::endl;
return 0;
}2. 设置子线程的名称
cpp
#include <iostream>
#include <pthread.h>
#include <unistd.h>
void* WorkerThread(void* arg) {
// 设置子线程名:"worker-1"
pthread_setname_np(pthread_self(), "worker-1");
// 模拟线程工作
while (true) {
sleep(1);
}
return nullptr;
}
int main() {
pthread_t tid;
pthread_create(&tid, nullptr, WorkerThread, nullptr);
// 获取子线程名
char name[16];
pthread_getname_np(tid, name, sizeof(name));
std::cout << "子线程名:" << name << std::endl;
// 等待子线程(防止主线程退出)
pthread_join(tid, nullptr);
return 0;
}四、关键注意事项
-
非标准性 :这两个函数是 Linux/glibc 的扩展,不保证在其他系统(如 FreeBSD、macOS)上兼容 (比如 macOS 也有
pthread_setname_np,但参数格式不同)。 -
名称长度限制 :Linux 内核限制线程名长度为 15 个字符 (含字母、数字、下划线),超过部分会被自动截断,且必须以
\0结尾。若传入空字符串或超长字符串,会返回EINVAL错误。 -
权限限制 :只能设置当前进程内的线程名称 ,无法修改其他进程的线程名(否则返回
EPERM)。 -
调试工具支持:设置线程名后,可通过以下命令查看:
ps -Lp <进程ID>:显示进程内所有线程的 ID 和名称;top -H -p <进程ID>:实时查看线程名称和资源占用;gdb调试时,用info threads可看到线程名。
五、常见错误码说明
| 错误码 | 含义 |
|---|---|
EINVAL |
名称无效(如超长、空字符串)或缓冲区长度不足 |
ESRCH |
指定的线程 ID 不存在 |
EPERM |
权限不足(如修改其他进程的线程名) |
总结
pthread_setname_np/pthread_getname_np是 Linux 下调试多线程的实用工具,核心价值是给线程 "命名" 以区分功能;- 使用时需注意名称长度(≤15 字符)和系统兼容性;
- 常用于日志输出、调试工具定位线程,提升多线程程序的可维护性。
线程封装:
一、为什么要封装线程?------ 从 "手动操作" 到 "管家式管理"
原生的 POSIX 线程(pthread)是 C 语言风格的 API,用起来像 "手动搬砖":
- 要记住
pthread_create、pthread_detach、pthread_join等一堆函数,参数多且类型严格; - 线程的 ID、运行状态、分离状态需要手动记录,容易记混或遗漏;
- 入口函数只能是固定格式的
void*(void*),传参和回调都很麻烦。
而封装成 C++ 的Thread类,就像给线程请了个 "专属管家":
- 把线程的 "属性"(ID、名称、运行状态)和 "行为"(创建、终止、等待)打包在一起,用户不用关心底层细节;
- 用面向对象的方式调用(比如
t.CreateThread()),更符合 C++ 的使用习惯; - 支持传入任意可调用对象(lambda、成员函数等),比原生函数指针灵活 10 倍。
二、线程封装的核心思路 ------"把零散的零件拼成完整的机器"
封装的本质是 **"数据抽象 + 行为封装"**:把线程相关的零散数据(ID、状态)藏在类里,把零散的操作(创建、分离)变成类的成员函数,最终给用户一个 "开箱即用" 的线程对象。
我们一步步拆解代码里的封装逻辑:
第一步:定义 "可调用对象类型"------ 让用户传什么都能接
using func_t = std::function<void()>;这是封装的 "灵活性基石":
-
原生 pthread 只能接收
void*(void*)的函数指针,用户要传参数得绕弯(比如打包成结构体再转 void*); -
用
std::function<void()>就不一样了:用户可以传普通函数、lambda 表达式、绑定的类成员函数,甚至函数对象 ------ 只要能 "无参数调用",都行。比如用户想传带参数的函数?用 lambda 捕获参数就行:
这一步把 "僵硬的函数指针" 变成了 "灵活的可调用对象容器"。
第二步:设计类的 "属性"------ 记录线程的 "身份信息"
类的私有成员变量就是线程的 "身份证" 和 "状态卡":
pthread_t _tid; // 线程ID:唯一标识线程
bool _isrunning; // 运行状态:是否正在跑
bool _isdetach; // 分离状态:是否是分离线程
std::string _name; // 线程名称:方便调试
void* _ret; // 返回值:线程结束后的返回结果
func_t _func; // 核心逻辑:用户要线程执行的任务这些变量都是 "线程的私有数据",对外隐藏(private),避免用户误操作(比如随便改_tid导致线程失控)。
第三步:解决 "入口函数不匹配" 的问题 ------ 静态函数当 "桥梁"
这是封装的最关键难点:pthread_create 要求的入口函数必须是:
void* (*start_routine)(void*); // 无类属、只有一个void*参数但类的非静态成员函数有个 "隐藏参数"------this指针(代表当前对象),所以非静态成员函数的实际参数列表是:
void* Thread::routine(Thread* this, void* arg); // 编译器偷偷加的这和 pthread 要求的格式完全不匹配,直接用会编译报错。
所以代码里用了静态成员函数当 "桥梁":
static void* routine(void* arg);静态成员函数没有this指针,参数列表正好符合 pthread 的要求!
但新问题来了:静态函数不能访问类的非静态成员(比如_func、_isrunning),怎么执行用户的任务?
答案是:把this指针传给静态函数!
pthread_create 的第四个参数是 "传给入口函数的参数",我们传this:
pthread_create(&_tid, nullptr, routine, static_cast<void*>(this));静态函数里再把void*转成Thread*:
Thread* self = static_cast<Thread*>(arg);这样静态函数就拿到了当前对象的指针,能像普通成员函数一样访问self->_func()、self->_isrunning了 ------ 这一步就像给静态函数递了一把 "钥匙",打开了访问对象成员的大门。
第四步:封装线程的核心操作 ------ 把 pthread 函数 "包起来"
原生 pthread 函数是 "裸奔" 的,封装成成员函数后,会加 "安全检查" 和 "状态更新",避免用户犯低级错误。
1. 创建线程:CreateThread()
封装pthread_create,做了三件事:
- 检查状态 :如果线程已经在运行(
_isrunning==true),直接返回 false,避免重复创建; - 调用底层函数 :
pthread_create(&_tid, nullptr, routine, this),把this传给静态入口; - 错误处理 :如果
pthread_create返回非 0(失败),打印错误信息,返回 false;成功则打印提示,返回 true。
相当于给pthread_create加了 "安全锁",防止无效操作。
2. 分离线程:DetachThread()
封装pthread_detach,核心逻辑是 "先检查,再操作":
- 先看是否已经分离(
_isdetach==true):如果是,直接返回,避免重复分离; - 再看是否在运行(
_isrunning==true):没运行的线程分离也没用,返回 false; - 调用
pthread_detach,成功后把_isdetach设为 true,标记状态。
3. 终止线程:StopThread()
封装pthread_cancel,逻辑类似:
- 检查是否在运行:没运行的线程不用终止;
- 调用
pthread_cancel终止线程,成功后把_isrunning设为 false,更新状态。
4. 等待线程:JoinThread()
封装pthread_join:
- 先检查是否分离:分离的线程不能 join(pthread 规定),直接返回;
- 调用
pthread_join等待线程结束,获取返回值存在_ret里; - 处理错误,返回结果。
第五步:线程的 "善后工作"------ 析构函数的安全设计
如果线程还在运行时,Thread对象被析构(比如超出作用域),会导致:
- 线程还在访问已经销毁的对象成员(比如
_func),引发野指针; - 线程变成 "孤儿线程",资源无法回收。
所以析构函数里做了 "兜底处理":
~Thread() {
if(_isrunning==true) { // 如果线程还在跑
StopThread(); // 先终止线程
if (_isdetach==false) { // 如果没分离
JoinThread(); // 等待线程结束,回收资源
}
}
}相当于 "管家" 在离职前,先把线程的烂摊子收拾干净,避免内存泄漏或崩溃。
第六步:线程命名 ------ 给线程贴 "标签",方便调试
代码里自动给线程生成名称:
_name = "thread-" + std::to_string(number);
++number;然后用pthread_setname_np(self->_tid, self->_name.c_str())设置线程名 ------ 这样用ps -Lp <进程ID>或gdb调试时,能一眼认出哪个线程是哪个,比默认的 "pthread-xxx" 友好多了。
三、封装里的 "小坑"------ 代码里的 bug 和改进点
虽然封装思路很对,但代码里有几个容易踩的坑,也能帮我们理解封装的细节:
1. 线程名重复的 bug:number是 "非静态成员"
代码里int number = 1;是类的非静态成员 ------每个Thread对象都会有一个自己的number!
比如创建两个线程:
- 第一个 Thread 对象的
number是 1,生成thread-1,然后number变成 2; - 第二个 Thread 对象的
number还是 1,生成thread-1,然后number变成 2;结果两个线程重名了!
解决方法:把number改成静态成员 (static int number = 1;),这样所有 Thread 对象共享一个number,就能生成thread-1、thread-2... 的唯一名称了。
2. 线程名设置的时机问题:_tid什么时候有效?
pthread_setname_np(self->_tid, ...)里的_tid是在pthread_create成功后才赋值的 ------ 而静态函数routine是线程启动后才执行的,这时候_tid已经有效了,所以没问题。但如果pthread_create失败,_tid还是 0,不过这种情况线程不会启动,也不会执行到这行代码,所以安全。
3. 状态变量的 "线程安全" 问题
_isrunning和_isdetach是普通 bool 变量 ------ 如果主线程在改_isrunning,子线程同时在读,可能出现 "竞态条件"(比如主线程刚把_isrunning设为 true,子线程没看到,还以为没运行)。
改进方法:用std::atomic<bool>代替普通 bool,让状态的读写变成 "原子操作",避免多线程下的状态错乱。
四、封装的核心价值
总结一下线程封装的妙处:
- 易用性 :用户不用记 pthread 的复杂函数,只要创建
Thread对象,调用CreateThread()就行,像用 "黑盒" 一样简单; - 安全性:内置状态检查和析构兜底,避免用户犯 "重复创建线程""join 分离线程" 等低级错误;
- 灵活性 :用
std::function支持任意可调用对象,用户传 lambda、成员函数都可以,适配各种场景。
这就是面向对象封装的魅力 ------ 把复杂的底层逻辑藏起来,给用户一个简洁、安全、好用的接口。
最后:封装的本质是 "抽象"
线程封装的核心不是 "把函数包起来",而是 **"抽象出线程的本质属性和行为"**:
- 线程的本质是 "一段可执行的任务 + 执行状态";
- 我们把 "任务" 抽象成
func_t,把 "状态" 抽象成_isrunning/_isdetach,把 "执行" 抽象成CreateThread()/StopThread();最终让用户只需要关心 "我要让线程做什么",而不用关心 "线程是怎么创建、怎么运行的"------ 这就是 "授人以渔" 的封装思想。
完整代码:
下面我就给出完整代码:
Thread.hpp:
cpp
#pragma once
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cstdlib>
#include <unistd.h>
#include <pthread.h>
#include <functional>
#include <vector>
#include <string>
//那么在本文件中,主要是对线程进行一个封装
//因为在外面我们老是pthread_create等等很麻烦
//那么我们就可以自己封装出一个线程类
//然后用户在外面就可以直接创建一个线程类变量
//然后我们再在该线程类内部去将各个pthread系列的函数都封装起来,使它们成为线程类的成员函数
//这个就非常舒服了,用户用起来也会舒服很多,所以,接下来
//我们就来简单封装一下线程类
//难度并不是很大,还挺简单的说实话
//但是需要我们对C++有高度的了解
namespace thread
{
class Thread
{
using func_t=std::function<void()>;//重命名函数指针类型,用户在外界可以直接传入函数指针
int number = 1; //TODO is bug
private:
//新线程的入口函数
//这里我们要知道,系统是要求说,新线程的入口函数是只能有一个形参的
//而由于我们是在进程类里面创建的,所以会自动在该函数内部void* routine(void* arg)加上this指针这个形参
//那么这就违反了系统的要求
//所以为了解决这个问题,我们就得将该函数设置为全局函数,那么其实就是直接设置为静态函数即可
//那么此时该函数形参就不会自动加上this指针了
static void* routine(void* arg)
{
//那么问题就是,该函数是设置为静态函数了,可是这也就代表着它不能访问进程类型的成员变量了、
//而我们还要在这里面调用用户传过来的实际的新线程的入口函数啊哇
//这可怎么办,那么我们可以设置为友元函数,不过在这里,我们用另一个方法
//那就是直接给该函数形参传入this指针不就行了哈哈哈
//那么此时在该函数内部不就可以访问this的所有成员变量了吗
//那么因为系统要求线程函数入口的形参必须是void*类型的,所以我们是把this强制转换为了void*的
//所以在该函数内部,我们就得转换回去
//那么我们可以用一个新Thread*去接收
Thread* self=static_cast<Thread*>(arg);//不需要std::,嗯,我还没学到呢哈哈哈
//非常方便
self->_isrunning=true;//将线程运行状态设置为true
//那么要是用户是在线程内部再去分离线程的话
//那么我们在线程入口函数内部也得进行处理
if(self->_isdetach==true)
{
self->DetachThread();//调用this的分离函数
}
//我们对该线程进行一个命名,本质上是使用线程局部存储
pthread_setname_np(self->_tid,self->_name.c_str());
//然后我们就调用用户传过来的实际的新线程的入口函数,也就是函数回调
self->_func();
return nullptr;//返回空指针
}
public:
//构造函数
Thread(func_t func)
:_func(func)
,_isrunning(false)
,_isdetach(false)
,_tid(0)
,_ret(nullptr)//将线程类的成员变量都初始化
{
//对名字也初始化一下
_name="thread-"+std::to_string(number);
++number;
}
//析构函数
~Thread()
{
//其实该析构函数是不需要处理什么的
//但是为了以防万一,比如线程还在运行中就析构的话
//所以我们也加入终止线程和等待线程的函数
if(_isrunning==true)
{
StopThread();
if (_isdetach==false)
{
JoinThread();
}
}
}
//创建线程的函数
bool CreateThread()
{
//那么这个就有说法了,怎么说呢,其实就是有点难度在
//在本函数内,我们就是简单的调用pthread_create函数即可,主要的是在新线程实际的入口函数进行
int ret_pthread_create=pthread_create(&_tid,nullptr,routine,static_cast<void*>(this));
if(ret_pthread_create!=0)
{
std::cout<<"pthread_create failed: "<<strerror(ret_pthread_create)<<std::endl;
return false;
}
else
{
//打印表示创建进程成功
std::cout<<"Create Thread Success!"<<std::endl;
return true;
}
}
//分离线程的函数
bool DetachThread()
{
//如果用户调用了这个函数,那么就代表要进行线程分离
if(_isdetach==true)//如果线程已经分离了,那直接返回就完了,不需要去分离线程
{
//打印说明
std::cout<<"Thread Is Already Detach!"<<std::endl;
return true;
}
if(_isrunning==true)//线程在运行了分离线程
{
int ret_pthread_detach=pthread_detach(_tid);
if(ret_pthread_detach!=0)
{
std::cout<<"pthread_detach failed: "<<strerror(ret_pthread_detach)<<std::endl;
return false;
}
else
{
//打印表示分离进程成功
std::cout<<"Detach Thread Success!"<<std::endl;
_isdetach=true;
return true;
}
}
return false;
}
//终止线程的函数
bool StopThread()
{
if(_isrunning==false)//如果线程都没在运行,那直接返回就完了,不需要去终止线程
{
//打印说明
std::cout<<"Thread Not Running!"<<std::endl;
return true;
}
//因为是在外部对线程进行终止的,所以我们就得使用pthread_cancel函数
int ret_pthread_cancel=pthread_cancel(_tid);
if(ret_pthread_cancel!=0)
{
std::cout<<"pthread_cancel failed: "<<strerror(ret_pthread_cancel)<<std::endl;
return false;
}
else
{
//打印表示终止进程成功
std::cout<<"Stop Thread Success!"<<std::endl;
_isrunning=false;//将线程运行状态修改为false
return true;
}
}
//等待线程的函数
bool JoinThread()
{
if(_isdetach==true)//如果线程是分离的,那直接返回就完了,不需要去等待线程
{
//打印说明
std::cout<<"Thread Is Detach!"<<std::endl;
return true;
}
//对线程进程等待,使用pthread_join函数
int ret_pthread_join=pthread_join(_tid,&_ret);//void* _ret;//线程等待函数(pthread_join)的返回值
if(ret_pthread_join!=0)
{
std::cout<<"pthread_join failed: "<<strerror(ret_pthread_join)<<std::endl;
return false;
}
else
{
//打印表示终止进程成功
std::cout<<"Join Thread Success!"<<std::endl;
return true;
}
}
private:
//成员变量
pthread_t _tid;//线程id
bool _isrunning;//判断线程是否在运行
bool _isdetach;//判断线程是不是分离的,默认是没有分离的
std::string _name;//线程名字
void* _ret;//线程等待函数(pthread_join)的返回值
func_t _func;//线程入口函数中的回调函数
//额,其实本质上是用户在外界要传入这个函数,然后我们在类里面的pthread_create里面的第三个参数
//也就是新线程实际的入口函数中,要调用用户所传入的函数
//怎么说,其实就是一个狸猫换太子,偷天换日
//因为我们是要封装一个进程类,所以在进程类里面肯定得有新线程实际的入口函数
//但是由于实际上新线程要进行的函数得是用户在外界传入的,
//所以,我们就要在进程类内部的新线程实际的入口函数里面调用用户在外界传入的函数的哇
//所以这个还是很重要的
};
}Main.cc:
cpp
//测试文件
#include "Thread.hpp"
using namespace thread;
int main()
{
Thread t([](){
while(true)
{
char name[128];
pthread_getname_np(pthread_self(), name, sizeof(name));
std::cout << "我是一个新线程: " << name << std::endl; // 我的线程的名字是什么呀?debug
sleep(1);
}
});
t.CreateThread();
// t.DetachThread();
sleep(5);
t.StopThread();
sleep(5);
t.JoinThread();
return 0;
}线程封装------template版:
一、模板版线程封装的核心目标:让线程函数能 "接收参数"
普通版的线程类只能执行无参函数 (std::function<void()>),但实际开发中,我们经常需要让线程函数接收参数(比如让线程处理一个数字、一个字符串,或者一个自定义的任务对象)。
模板版的核心改进就是:通过C++ 模板 适配任意类型的参数 ,让用户可以给线程函数传参 ------ 你想传int就传int,想传std::string就传std::string,想传自己定义的Task结构体也可以,不用改类的代码,模板会自动适配。
在已封装完成的线程类基础上,我们专门为其增添模板相关功能,核心目的在于打破线程实际入口函数只能无参的限制,让外界能够灵活地向这个入口函数传入参数。
此前未对线程类进行封装时,我们没办法给线程的实际入口函数传入多个参数,这并非技术上的疏漏,而是受系统规则约束 ------ 系统明确要求线程的入口函数只能包含一个 void * 类型的形参,所以我们自然无法突破这个限制实现多参传入。
而封装后的线程类之所以能支持参数传入,关键在于我们采用了函数回调的设计思路:具体来说,就是在线程类内部定义的线程入口函数里,去调用由外界传入的、真正需要新线程执行的目标函数。这里有个重要的细节 ------ 系统仅仅规定传入 pthread_create 函数的那个线程入口函数必须只有一个 void * 类型形参,却并没有限制这个入口函数内部所调用的其他函数的形参类型。正是利用这一规则空间,我们得以让用户传入带有多个形参的函数,交由新线程去运行。
但新的问题随之而来:我们无法预先知晓用户传入的函数究竟会带有何种类型的形参,所以必须借助模板机制来解决这个适配问题。具体做法就是将函数类型别名 func_t 定义为 std::function<void (type1)>,其中 type1 作为模板参数,这样用户传入的函数就能携带参数了,只是需要用户根据实际需求指定对应的参数类型。
除此之外,我们还必须在线程类内部新增一个成员变量,专门用于存储用户传给目标函数的实际参数。试想如果缺少这个成员变量来存放实参,后续调用目标函数时就会因没有参数传入而导致程序出错。
综合来看,整个实现思路其实并不复杂,核心就是利用模板适配参数类型、借助函数回调突破系统对入口函数的参数限制,再配合成员变量存储实参,最终实现线程函数的灵活传参。
二、模板参数的作用:"万能适配" 用户的参数类型
代码里的template <typename type1>是类模板参数 ,type1就像一个 "占位符":
- 你创建线程对象时指定
type1是什么类型(比如Thread<int>),类里所有用到type1的地方就会变成这个类型; - 我们不知道用户要传什么类型的参数(可能是
int、string、自定义结构体),所以用模板参数 "留位置",让编译器根据用户的实际使用自动填类型。
比如用户想传int参数,就写Thread<int>;想传std::string,就写Thread<std::string>------ 模板帮我们实现了 "一套代码适配所有参数类型",不用为每种参数类型写一个单独的线程类。
三、类的关键变化:为 "传参" 新增的设计
对比普通版,模板版主要改了 3 处核心地方,都是为了支持 "传参":
1. func_t的定义:从 "无参函数" 变成 "带参函数"
普通版:
using func_t = std::function<void()>; // 只能接收无参函数模板版:
using func_t = std::function<void(type1)>; // 能接收"参数类型为type1"的函数这样用户传入的线程函数就可以有一个参数了 ------ 比如void TaskFunc(int num)(参数是int),或者void PrintFunc(std::string msg)(参数是string),只要参数类型和模板参数type1匹配就行。
2. 新增_data成员:存储用户传入的 "实参"
模板版新增了私有成员:
type1 _data; // 专门存用户传给线程函数的参数(实参)比如用户想让线程函数处理数字100,_data就存100;想处理字符串"hello",_data就存"hello"------ 它是 "用户参数的中转站",把用户在主线程传入的参数,传递给子线程的函数。
3. 构造函数:接收 "函数 + 参数",初始化_data
模板版的构造函数需要同时接收两个东西:
- 用户的线程函数(
func_t func); - 用户传给函数的参数(
type1 data)。
然后通过初始化列表把参数存到_data里:
Thread(func_t func, type1 data)
: _func(func)
, _data(data) // 把用户传入的参数存起来
// 其他成员初始化...
{
// 生成线程名...
}这样主线程创建线程对象时,就能把 "要执行的函数" 和 "函数需要的参数" 一起传给线程类了。
四、核心逻辑:参数怎么从 "主线程" 传到 "子线程函数"?
模板版的关键是:把用户传入的参数存到_data里,然后在子线程的routine函数里,把_data传给用户的线程函数。
具体流程像 "快递中转":
- 主线程发货 :用户创建
Thread<int>对象,传入函数TaskFunc(int)和参数100,构造函数把100存到_data里(相当于把快递放到中转站); - 子线程取件 :
routine函数里拿到self指针(指向线程对象),然后调用self->_func(self->_data)------ 把中转站的_data(100)传给用户的TaskFunc(相当于快递员把快递送到收件人手里); - 函数执行 :用户的
TaskFunc拿到参数100,开始处理(比如计算、打印)。
代码里的关键一行就是:
self->_func(self->_data); // 把存储的参数传给用户函数这行解决了 "子线程函数怎么拿到主线程参数" 的问题 ------ 普通版做不到,模板版通过_data和模板参数实现了。
五、模板版的优势:灵活性直接拉满
对比普通版,模板版的优势一眼就能看出来:
1. 支持任意类型的参数
你可以给线程函数传:
- 基础类型:
int、double、std::string; - 自定义类型:自己写的
Student结构体、Task类对象; - 指针 / 引用:比如
int*(注意引用的生命周期问题,后面会说)。
比如让线程处理自定义结构体:
// 自定义任务结构体
struct Task {
int id;
std::string name;
};
// 线程函数:处理Task对象
void DealTask(Task task) {
std::cout << "处理任务:id=" << task.id << ", name=" << task.name << std::endl;
}
// 创建模板线程对象,参数类型是Task
thread::Thread<Task> t(DealTask, Task{1, "支付任务"});
t.CreateThread();
t.JoinThread();不用改线程类的代码,直接用就行 ------ 这就是模板的 "万能适配" 能力。
2. 代码复用性高
一套模板类可以应对所有传参场景,不用为 "传 int" 写一个线程类,"传 string" 又写一个 ------ 减少重复代码,也降低出错概率。
六、模板版的注意点
1. number的 bug 依然存在(非静态导致重名)
模板版里的int number = 1;还是非静态成员变量 ,每个Thread对象都有自己的number,创建多个对象时会生成重复的线程名(比如两个Thread<int>对象都生成thread-1)。
解决方法:把number改成模板类的静态成员:
template <typename type1>
class Thread {
static int number; // 模板类的静态成员,所有同类型的Thread对象共享
// ...
};
// 模板类静态成员需要在类外初始化
template <typename type1>
int thread::Thread<type1>::number = 1;这样Thread<int>的所有对象共享一个number,Thread<string>的所有对象共享另一个number,名字就不会重复了。
2. 参数的 "拷贝" 问题
模板版里的_data是值拷贝 用户传入的参数 ------ 如果用户传的是大对象(比如一个 10MB 的结构体),拷贝会消耗内存和时间;如果用户传的是 "临时对象"(比如Task{1, "test"}),要注意临时对象的生命周期(临时对象在构造函数结束后就销毁,但_data已经拷贝了一份,所以没问题)。
如果想避免拷贝,可以用引用或指针:
// 用引用传参(注意:引用的对象必须比线程活得久!)
thread::Thread<Task&> t(DealTask, task_obj);但要注意:如果引用的对象(比如task_obj)在主线程里提前销毁了,子线程访问时会触发野指针,导致崩溃。
3. 模板类的编译特点
模板类是 "按需编译" 的 ------ 只有你创建Thread<int>对象时,编译器才会生成Thread<int>的代码;创建Thread<string>时,才生成Thread<string>的代码。这意味着:如果模板代码有语法错误,只有用到对应的类型时才会报错(比如Thread<int>没问题,但Thread<string>因为线程名太长报错)。
七、模板版 vs 普通版:核心差异总结
| 特性 | 普通版线程类 | 模板版线程类 |
|---|---|---|
| 线程函数参数 | 只能无参(void()) |
支持任意类型单参数(void(type1)) |
| 灵活性 | 低(只能处理固定无参逻辑) | 高(适配任意传参场景) |
| 代码复用性 | 低(换参数要改类) | 高(一套代码适配所有类型) |
| 核心改进点 | 无参数传递设计 | 模板参数 +_data 存储参数 |
八、总结:模板版的本质是 "参数的通用化"
模板版线程封装并没有改变线程类的核心逻辑(静态routine当桥梁、封装 pthread 函数、状态管理),只是在 "参数传递" 这个环节做了通用化改造 ------ 用模板参数适配任意参数类型,用_data存储参数,最终让线程函数从 "只能无参" 变成 "能接收任意类型参数"。
简单说:普通版是 "固定套餐"(只能吃白米饭),模板版是 "自助套餐"(想吃什么菜自己选)------ 这就是模板给 C++ 带来的灵活性,也是模板版线程类的核心价值。
完整代码:
Thread_Template.hpp:
cpp
#pragma once
#include <iostream>
#include <cstdio>
#include <cstring>
#include <cstdlib>
#include <unistd.h>
#include <pthread.h>
#include <functional>
#include <vector>
#include <string>
//那么在本文件中,我们其实是在已经封装了的线程类中去添加模版的功能
//就是说我们可以让线程的实际入口函数里面不是啥形参都没有,外界是可以对该函数进行传入参数的
//那么为什么我们没有封装线程类的时候就没有对线程的实际入口函数进行传入多的参数呢
//因为系统要求线程的入口函数只能有一个void*类型的形参,所以我们自然就不能了
//那么为什么进程类就有可以了呢,哈哈哈,那自然是因为我们在线程类中其实是进行了函数回调
//也就是说我们是在进程类内的线程的入口函数内调用用户在外界传入的实际要新线程进行的函数
//那么系统要求传入pthread_create内的函数只能有一个void*类型的形参
//可没要求说该函数内调用的函数也只能有一个void*类型的形参哦
//所以我们就可以借助这一点去让用户传入有多个形参的要让新线程运行的函数
//那么我们又不知道用户所传入的函数的形参类型是什么
//所以我们就得用到模版,而其实该模版也是用到using func_t=std::function<void()>里的
//using func_t=std::function<void(type1)>;,那么用户传入的函数就可以有形参了,只不过需要用户指定
//还有就是我们也要在线程类内部增加一个成员变量去代表该函数的实参
//不然我们调用函数的时候没有实参传入,那就BBQ了
//综上所述,还是很简单的
namespace thread
{
template <typename type1>
class Thread
{
using func_t=std::function<void(type1)>;//重命名函数指针类型,用户在外界可以直接传入函数指针
int number = 1; // bug
private:
//新线程的入口函数
//这里我们要知道,系统是要求说,新线程的入口函数是只能有一个形参的
//而由于我们是在进程类里面创建的,所以会自动在该函数内部void* routine(void* arg)加上this指针这个形参
//那么这就违反了系统的要求
//所以为了解决这个问题,我们就得将该函数设置为全局函数,那么其实就是直接设置为静态函数即可
//那么此时该函数形参就不会自动加上this指针了
static void* routine(void* arg)
{
//那么问题就是,该函数是设置为静态函数了,可是这也就代表着它不能访问进程类型的成员变量了、
//而我们还要在这里面调用用户传过来的实际的新线程的入口函数啊哇
//这可怎么办,那么我们可以设置为友元函数,不过在这里,我们用另一个方法
//那就是直接给该函数形参传入this指针不就行了哈哈哈
//那么此时在该函数内部不就可以访问this的所有成员变量了吗
//那么因为系统要求线程函数入口的形参必须是void*类型的,所以我们是把this强制转换为了void*的
//所以在该函数内部,我们就得转换回去
//那么我们可以用一个新Thread*去接收
Thread* self=static_cast<Thread*>(arg);//不需要std::,嗯,我还没学到呢哈哈哈
//非常方便
self->_isrunning=true;//将线程运行状态设置为true
//那么要是用户是在线程内部再去分离线程的话
//那么我们在线程入口函数内部也得进行处理
if(self->_isdetach==true)
{
self->DetachThread();//调用this的分离函数
}
//我们对该线程进行一个命名,本质上是使用线程局部存储
pthread_setname_np(self->_tid,self->_name.c_str());
//然后我们就调用用户传过来的实际的新线程的入口函数,也就是函数回调
self->_func(self->_data);//这里也要改一下,将实参传入
return nullptr;//返回空指针
}
public:
//构造函数
Thread(func_t func,type1 data)//用户在创建线程类对象的时候,就得把要给新线程所运行函数的实参传过来
:_func(func)
,_isrunning(false)
,_isdetach(false)
,_tid(0)
,_ret(nullptr)//将线程类的成员变量都初始化
,_data(data)
{
//对名字也初始化一下
_name="thread-"+std::to_string(number);
++number;
}
//析构函数
~Thread()
{
//其实该析构函数是不需要处理什么的
//但是为了以防万一,比如线程还在运行中就析构的话
//所以我们也加入终止线程和等待线程的函数
if(_isrunning==true)
{
StopThread();
if (_isdetach==false)
{
JoinThread();
}
}
}
//创建线程的函数
bool CreateThread()
{
//那么这个就有说法了,怎么说呢,其实就是有点难度在
//在本函数内,我们就是简单的调用pthread_create函数即可,主要的是在新线程实际的入口函数进行
int ret_pthread_create=pthread_create(&_tid,nullptr,routine,static_cast<void*>(this));
if(ret_pthread_create!=0)
{
std::cout<<"pthread_create failed: "<<strerror(ret_pthread_create)<<std::endl;
return false;
}
else
{
//打印表示创建进程成功
std::cout<<"Create Thread Success!"<<std::endl;
return true;
}
}
//分离线程的函数
bool DetachThread()
{
//如果用户调用了这个函数,那么就代表要进行线程分离
if(_isdetach==true)//如果线程已经分离了,那直接返回就完了,不需要去分离线程
{
//打印说明
std::cout<<"Thread Is Already Detach!"<<std::endl;
return true;
}
if(_isrunning==true)//线程在运行了分离线程
{
int ret_pthread_detach=pthread_detach(_tid);
if(ret_pthread_detach!=0)
{
std::cout<<"pthread_detach failed: "<<strerror(ret_pthread_detach)<<std::endl;
return false;
}
else
{
//打印表示分离进程成功
std::cout<<"Detach Thread Success!"<<std::endl;
_isdetach=true;
return true;
}
}
return false;
}
//终止线程的函数
bool StopThread()
{
if(_isrunning==false)//如果线程都没在运行,那直接返回就完了,不需要去终止线程
{
//打印说明
std::cout<<"Thread Not Running!"<<std::endl;
return true;
}
//因为是在外部对线程进行终止的,所以我们就得使用pthread_cancel函数
int ret_pthread_cancel=pthread_cancel(_tid);
if(ret_pthread_cancel!=0)
{
std::cout<<"pthread_cancel failed: "<<strerror(ret_pthread_cancel)<<std::endl;
return false;
}
else
{
//打印表示终止进程成功
std::cout<<"Stop Thread Success!"<<std::endl;
_isrunning=false;//将线程运行状态修改为false
return true;
}
}
//等待线程的函数
bool JoinThread()
{
if(_isdetach==true)//如果线程是分离的,那直接返回就完了,不需要去等待线程
{
//打印说明
std::cout<<"Thread Is Detach!"<<std::endl;
return true;
}
//对线程进程等待,使用pthread_join函数
int ret_pthread_join=pthread_join(_tid,&_ret);//void* _ret;//线程等待函数(pthread_join)的返回值
if(ret_pthread_join!=0)
{
std::cout<<"pthread_join failed: "<<strerror(ret_pthread_join)<<std::endl;
return false;
}
else
{
//打印表示终止进程成功
std::cout<<"Join Thread Success!"<<std::endl;
return true;
}
}
private:
//成员变量
pthread_t _tid;//线程id
bool _isrunning;//判断线程是否在运行
bool _isdetach;//判断线程是不是分离的,默认是没有分离的
std::string _name;//线程名字
void* _ret;//线程等待函数(pthread_join)的返回值
func_t _func;//线程入口函数中的回调函数
//额,其实本质上是用户在外界要传入这个函数,然后我们在类里面的pthread_create里面的第三个参数
//也就是新线程实际的入口函数中,要调用用户所传入的函数
//怎么说,其实就是一个狸猫换太子,偷天换日
//因为我们是要封装一个进程类,所以在进程类里面肯定得有新线程实际的入口函数
//但是由于实际上新线程要进行的函数得是用户在外界传入的,
//所以,我们就要在进程类内部的新线程实际的入口函数里面调用用户在外界传入的函数的哇
//所以这个还是很重要的
type1 _data;//要传入给回调函数的实参
};
}Main_Thread_Template.cc:
cpp
#include "Thread_Template.hpp"
#include <unistd.h>
using namespace thread;
// 我们可以传递对象吗???
class ThreadData
{
public:
pthread_t tid;
std::string name;
};
void Count(ThreadData td)
{
while (true)
{
std::cout << "我是一个新线程" << std::endl;
sleep(1);
}
}
int main()
{
ThreadData td;
Thread<ThreadData> t(Count, td);
t.CreateThread();
t.JoinThread();
return 0;
}结语:于细节处见真章,于封装中悟本质
敲完最后一行代码,看着终端里线程按预期输出 "我是一个新线程: thread-1",再回头翻看从 TLS 到线程封装的整个笔记,忽然觉得技术学习就像拼拼图 ------ 从 "宿舍吹风机" 的比喻理解 TLS 的隔离本质,到对着 pthread_create 的参数表犯愁,再到把零散的 API 封装成整洁的 Thread 类,每一块碎片慢慢合拢,终于看到了 "线程编程" 这幅图景的全貌。
我们总说 "线程难",难的从来不是记住 pthread_create 的参数顺序,而是理解 "为什么系统要限制入口函数的格式""为什么全局变量会引发线程安全问题""为什么封装能让复杂逻辑变简单"。就像 TLS 的学习,起初以为只是加个__thread 关键字的小技巧,直到用 "每个线程的专属抽屉" 去类比,才明白它解决的是 "共享与私有" 的核心矛盾 ------ 计算机世界的规则,说到底都是对现实问题的抽象映射,而我们要做的,就是把这些抽象再还原成能触摸到的逻辑。
线程封装的过程更是如此。一开始觉得 "直接用 pthread 函数就行,何必多此一举封装类",可当尝试给线程传参时,才发现原生 API 的僵硬:函数指针的限制、参数传递的绕弯、状态管理的混乱...... 直到把 "线程 ID、运行状态、任务逻辑" 打包成类的属性,把 "创建、分离、等待" 封装成类的方法,才突然懂了面向对象的意义 ------ 不是为了写 "看起来高级" 的代码,而是为了让程序更贴近人的思维:我们关心的是 "让线程做什么",而不是 "线程是怎么被创建的"。模板版的改造则更进了一步,从 "只能处理无参任务" 到 "适配任意参数类型",泛型编程的 "万能适配" 让我们看到:好的代码不仅能解决当下的问题,更能容纳未来的变化。
当然,这个过程里也踩了不少坑:非静态的 number 导致线程名重复,传参时的拷贝开销,引用传递的生命周期陷阱...... 可这些 "坑" 恰恰是最珍贵的收获。就像调试时盯着终端里重复的 "thread-1" 百思不得其解,最后发现是 static 关键字的缺失 ------ 那一刻突然明白,"细节" 从来不是 "细枝末节",而是决定程序能否正确运行的关键。技术的进阶,从来不是 "写更多代码",而是 "在错误里沉淀出对规则的敬畏"。
我常想,我们学的到底是 "线程",还是 "解决问题的思维"?答案或许是后者。TLS 教会我们 "用隔离解决冲突",封装教会我们 "用抽象简化复杂",模板教会我们 "用泛型实现复用"------ 这些思想,早已超越了 "线程编程" 的范畴,适用于任何领域的开发。就像当你理解了 Thread 类里 "静态函数做桥梁" 的设计,再去看其他库的封装时,会突然有种 "原来如此" 的通透:所有优秀的代码,都藏着对 "简洁" 与 "通用" 的追求。
或许你现在还会对着模板参数的推导犯迷糊,还会忘记给分离线程调用 join 的禁忌,但这都没关系。技术学习从来不是 "一蹴而就的顿悟",而是 "日复一日的积累"。今天搞懂了 TLS 的 "专属副本",明天吃透了封装的 "数据抽象",后天摸透了模板的 "类型适配"------ 每一个小小的 "懂了",都会在未来的某一刻串联起来,让你突然站到更高的台阶上。
编程的世界很大,从线程到进程,从同步到异步,从单机到分布式,还有无数的知识等着我们去探索。但请记住:再复杂的技术,拆解开来都是一个个简单的逻辑;再庞大的框架,底层都是我们今天学过的这些 "基础"。就像我们用几十行代码封装出的 Thread 类,虽然简陋,却藏着和 std::thread 一样的设计内核 ------ 所谓 "高手",不过是把基础的逻辑嚼碎了、揉烂了,再重新组合成自己的武器。
最后,想把写代码时的一点感悟分享给你:别害怕 "重复造轮子"。我们封装 Thread 类,不是为了替代标准库,而是为了亲手触摸 "封装" 的温度 ------ 当你从 0 到 1 实现一个功能,才会真正理解它的痛点、亮点和改进点。这种 "亲手造轮子" 的过程,比背一百遍 API 文档更能让你成长。
好了,关于线程的故事暂时讲到这里。但编程的旅程永远没有终点,下一篇博客,我们或许会聊聊线程安全里的互斥锁,或许会探索线程池的实现 ------ 无论哪里,愿你永远保持对 "为什么" 的好奇,永远在拆解问题、解决问题的过程里,找到属于自己的乐趣。
毕竟,技术的浪漫,就在于把抽象的逻辑,变成能运行的代码;把模糊的困惑,变成清晰的答案。而你我,都是在代码里追光的人。