UniPat AI 推出 30B 参数量开源科研大模型 UniScientist,突破科研大模型 "只写报告不做研究" 的行业痛点,以统一范式搭建通用科研智能,实现 "提出假设 - 收集证据 - 可复现推导 - 迭代验证" 的全流程科研闭环,性能匹敌甚至超越参数量大一个数量级的顶尖闭源模型,为 AI 科研落地提供关键参考。
UniScientist核心价值在于将 AI 建模为动态系统,通过自主数据引擎将开放式科研难题转化为可验证 "单元测试",让科研智能实现可训练、可评估、可迭代,真正具备自主科学研究能力。
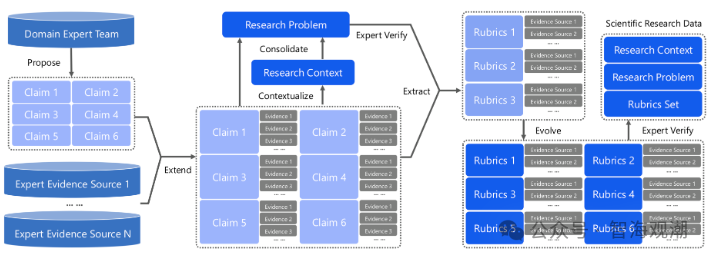
在训练数据构建上,模型破解人工标注成本高、纯合成数据质量低的双重瓶颈。创新采用 "大模型生成 + 人类专家验证" 分工模式,由模型跨学科批量生成研究问题与解法草案,人类专家负责高精度核验,打造进化式多学科合成数据引擎。目前已产出超 4700 个研究级实例,覆盖 50 + 学科、400 + 研究方向,每个实例配套 20 + 项评测标准,专家单样本标注仅需 1-2 小时,兼顾数据广度与精度。
在技术架构上,UniScientist 聚焦主动证据整合与模型溯因两大核心操作,构建三大核心组件实现科研智能化:一是人智协同的进化式多学科合成,规模化生成多学科研究问题及多维校验评测标准;二是智能体研究循环,集成学术检索、代码解释器等工具,完成 "获取证据 - 推导结论 - 更新假说" 迭代;三是报告聚合,融合多份研究报告优势,实现研究质量自我进化。同时模型建立 "证据状态" 体系,将证据分为可核验、可推导两类,通过循环迭代形成严谨成果,并用原子化检查项保障研究可复现性。
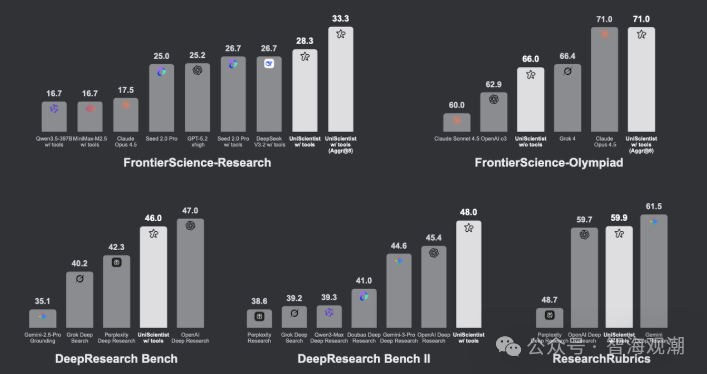
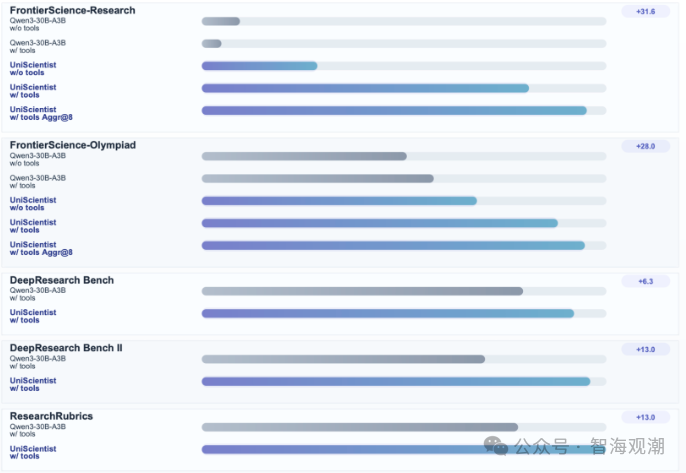
评测数据验证了模型硬核实力:UniScientist-30B-A3B 在 FrontierScience-Research 榜单斩获 28.3 分,超越 Claude Opus 4.5、GPT-5.2 xhigh 等模型,成果聚合模式下得分升至 33.3;FrontierScience-Olympiad 工具启用后得分 71.0,与 Claude Opus 4.5 持平,在 DeepResearch Bench 等基准中与顶级闭源模型实力相当。即便无工具辅助,模型推理能力仍显著提升,实现检索、推导、验证、写作全流程协同。
目前该模型已完全开源,支持本地部署、推理及结果聚合,需搭配 Serper 等 API 密钥使用,同时发布了权威基准的完整推理轨迹。现阶段其核心能力聚焦可复现推理与仿真计算,暂未覆盖真实世界研究资源调度;未来将拓展至开放真实实验场景,实现对真实实验、计算基础设施的受控执行,持续推动 AI 加速科学发现。作为轻量化开源科研模型,UniScientist 既为科研领域提供高效工具,也为大模型从 "文本生成" 向 "实际问题解决" 转型提供重要路径。