1 引言
论文链接:https://arxiv.org/pdf/2106.09685v1/1000
大模型下游迁移微调是行业落地的关键环节,传统全参数微调存在参数量大、算力消耗高、权重分发不便、易发生原有知识覆盖等缺陷。Adapter、Prefix Tuning、Prompt Tuning 等一系列参数高效微调(Parameter-Efficient Fine-Tuning,PEFT)方案被陆续提出,其中低秩自适应( Low-Rank Adaptation,LoRA)1方案凭借收敛速度快、推理无额外延迟、兼容性强等综合优势,在大模型微调、多模态适配、领域定制等场景中被大规模应用。LoRA 1 核心思路是冻结预训练模型主体权重,仅对注意力权重矩阵分解训练两个小维度低秩矩阵,以极低的参数增量实现下游任务适配。本文围绕 LoRA1 设计动机、数学原理、结构细节、优缺点及实操要点展开系统性讲解,同时梳理该技术的实际工程应用价值。
2 为什么需要 LoRA
相较于成本高昂的大模型全量微调,LoRA1 凭借多项核心优势,成为当下主流的 PEFT 方案,核心优势如下:
算力门槛极低,适配消费级硬件:LoRA1 仅训练模型极小部分参数,大幅缩减显存占用与算力消耗,有效降低微调成本,训练迭代速度更快,普通消费级显卡即可完成模型微调训练,大幅降低开发者使用门槛。
微调效果对标全量微调:依托插入的低秩矩阵,LoRA1 可精准挖掘下游任务专属特征。在绝大多数 NLP、文本生成任务中,LoRA1 微调效果能够比肩传统全量参数微调,性能损耗极低。
轻量化模块化设计,部署灵活可插拔:LoRA1 微调产出的权重文件体量极小,大小仅几十至数百兆,方便存储、开源分享与版本管理。同时 LoRA1 模块与底座预训练模型完全解耦,推理阶段按需加载对应任务 LoRA1 权重即可,无需修改、替换原始底座模型,实现不同任务模型的快速切换,具备极佳的即插即用特性。
3 设计思想
现有预训练大模型普遍具备过参数化特性,模型整体参数量庞大,但仅依靠极低维度的内在特征空间,即可完成下游任务适配。LoRA1 基于核心假设提出设计思路:大模型进行下游任务微调时,原有预训练参数的增量更新具备低秩特性。基于该假设,LoRA1 借助低秩矩阵分解,拟合模型微调过程中的参数变化量,无需更新冻结底座大模型主干权重,仅训练少量低秩参数,即可低成本完成大模型的下游任务适配。
4 LoRA
LoRA1 的具体实现方式为:在基础模型各类线性变换权重矩阵 (全连接、Embedding、卷积)旁增加一个旁路低秩分支矩阵
,其中
、
和
,秩
。则 LoRA1 的完整计算公式为:
其中 为输入向量,
为线性变换结果。
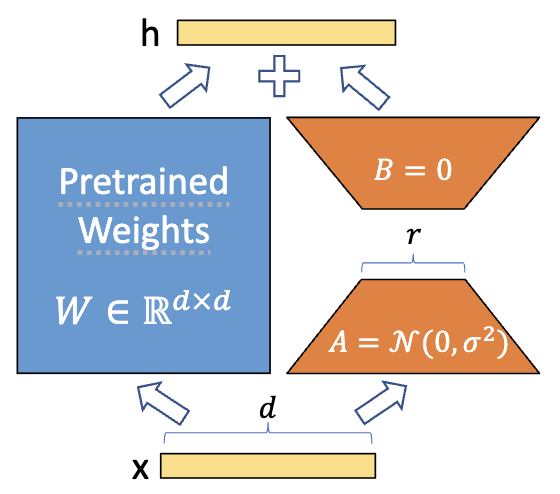
图2-1 LoRA1
若满足输入输出维度相等,即 d=k,LoRA1 整体原理如图 2-1 所示。对于模型原有预训练权重矩阵 ,微调阶段仅更新旁路低秩矩阵 A、B,主干预训练权重全程冻结;参数初始化有固定规范,矩阵 A 采用高斯分布初始化,矩阵 B 采用零值初始化。大模型注意力层权重矩阵维度庞大,直接对其全量微调,不仅算力成本极高,还极易破坏模型原生通用能力。而低秩矩阵分解方案,能够以极少量可学习参数,近似拟合下游任务所需的特征变换,矩阵计算量由
降至 2dr,大幅降低运算开销。
推理阶段只需叠加 LoRA1 旁路模块,模型主干结构与原生预训练参数保持不变,LoRA1 模块以外接分支形式,微调特征输出结果、适配下游任务,不会干扰主干模型原有能力。通俗而言,LoRA1 相当于给大模型加装轻量化外接调节器,在保留底座模型能力的基础上,引导模型输出贴合专属任务需求。
5 LoRA 的典型应用场景
依托低成本、高性能、可插拔的核心优势,LoRA1 目前已成为大模型落地适配的主流方案,覆盖文本、多模态、行业定制等多个主流场景,典型应用分类如下:
垂直领域大模型定制:针对医疗、法律、金融、学术等专业领域,使用领域专属数据集微调 LoRA1 模块,无需改动通用底座大模型,即可快速赋予模型行业专业知识、专业话术与合规表达能力,兼顾通用能力与领域专业性。
个性化对话风格调教:面向聊天机器人、智能客服、虚拟人设场景,通过 LoRA1 微调定制模型语气、行文风格、应答逻辑,可快速打造严谨专业、活泼口语、文艺书面等差异化人设,且多套风格 LoRA1 权重可按需切换,适配不同交互场景。
多模态模型轻量化适配:适配图文大模型,仅微调注意力层 LoRA1 分支,低成本完成图文对齐、图像问答、图文生成微调,相比全量微调大幅降低多模态模型训练门槛。
模型安全对齐与指令微调:用于大模型指令遵循、价值观对齐、违禁内容规避等安全优化工作,以极小参数成本完成模型对齐微调,避免全量微调破坏模型原生生成能力。
硬件受限下的本地微调:适配个人开发者、小型实验室硬件条件,依托消费级显卡即可完成模型微调,快速验证微调方案、制作轻量化私有模型,降低大模型二次开发门槛。
6 总结
本文系统性梳理了 LoRA1 核心理论与落地价值。作为经典 PEFT 算法,LoRA1 依托大模型过参数化、任务参数增量低秩的核心假设,通过旁路增设低秩矩阵 A、B,仅微调少量参数即可拟合任务特征变换,兼顾极低算力开销与媲美全量微调的模型效果。其主干权重冻结、模块可插拔、推理无额外开销的特性,完美解决了传统全量微调成本高、易遗忘、部署不便的痛点。目前 LoRA1 已广泛落地于行业模型定制、人设风格调教、多模态适配、模型对齐等场景,适配个人开发者与企业级研发全流程,也是当下大模型轻量化二次开发最主流、实用性最强的微调方案。
参考文献
1 Hu E J, Shen Y, Wallis P, et al. Lora: Low-rank adaptation of large language modelsJ. Iclr, 2022, 1(2): 3.