核心问题:如何评估一个二分类模型的好坏? 尤其是当数据不平衡时,准确率会"骗人",我们需要更可靠的指标------ROC和AUC。
一、为什么要用ROC和AUC?
1.1 准确率的陷阱(不平衡数据问题)
假设我们有一个欺诈检测模型:
-
正常交易:9900笔(负例)
-
欺诈交易:100笔(正例)
如果模型把所有交易都预测为"正常",那么准确率 = 9900/10000 = 99% ------ 看起来很厉害,但实际上一个欺诈都没抓到,模型毫无用处。
准确率在不平衡数据下失效。我们需要一个不受类别比例影响的评估指标。
1.2 ROC与AUC的优势
-
ROC曲线:展示模型在所有可能的分类阈值下的性能,横轴是假正率(FPR),纵轴是真正率(TPR)。
-
AUC值 :ROC曲线下的面积,衡量模型的排序能力------即随机选一个正样本和一个负样本,模型给正样本打分高于负样本的概率。
-
核心优势 :对类别不平衡非常鲁棒,因为TPR只关注正样本,FPR只关注负样本,两者独立计算。
二、核心概念:TPR、FPR与阈值
2.1 混淆矩阵回顾(二分类)
| 预测为正(Positive) | 预测为负(Negative) | |
|---|---|---|
| 真实为正 | TP(真正例) | FN(假负例,漏报) |
| 真实为负 | FP(假正例,误报) | TN(真负例) |
2.2 两个关键比率
-
真正率(TPR,也叫召回率/Sensitivity)
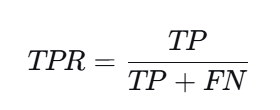
含义:所有真实正例中,被正确预测出来的比例。
-
假正率(FPR)
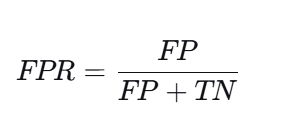
含义:所有真实负例中,被错误预测为正例的比例。
2.3 阈值(Threshold)的作用
分类器通常输出一个"概率"(或得分)。我们需要设定一个阈值,超过阈值为正,否则为负。
| 阈值变化 | 预测倾向 | 对负例的影响 | 对正例的影响 |
|---|---|---|---|
| 提高阈值 | 更严格(只把非常确信的判为正) | FP↓,FPR↓ | TP↓,TPR↓ |
| 降低阈值 | 更宽松(更多样本判为正) | FP↑,FPR↑ | TP↑,TPR↑ |
核心思想 :把阈值从1.0逐渐降到0.0,每改变一次阈值,就得到一个(TPR, FPR)点。将所有点连成曲线,就是ROC曲线。
三、手动计算ROC曲线的四个步骤
步骤1:准备数据
每个测试样本有:真实标签 (1=正例,0=负例)和预测概率(模型输出的属于正例的概率)。
步骤2:按预测概率降序排列
将所有样本按预测概率从高到低排序。概率最高的排在最前面。
步骤3:逐步降低阈值,累计TP/FP,计算(TPR, FPR)
-
初始状态:阈值 > 最高概率 → 没有样本被预测为正 → TP=0, FP=0 → TPR=0, FPR=0 → 点(0,0)
-
然后依次把当前样本的预测概率作为阈值(即该样本及之前的所有样本判为正),累计TP和FP,计算TPR和FPR,得到一个新的点。
-
直到所有样本都被判为正 → TP = 全部正例数,FP = 全部负例数 → TPR=1, FPR=1 → 点(1,1)
步骤4:用梯形法则计算AUC
AUC = ROC曲线下面积。用相邻两点之间的梯形面积累加得到。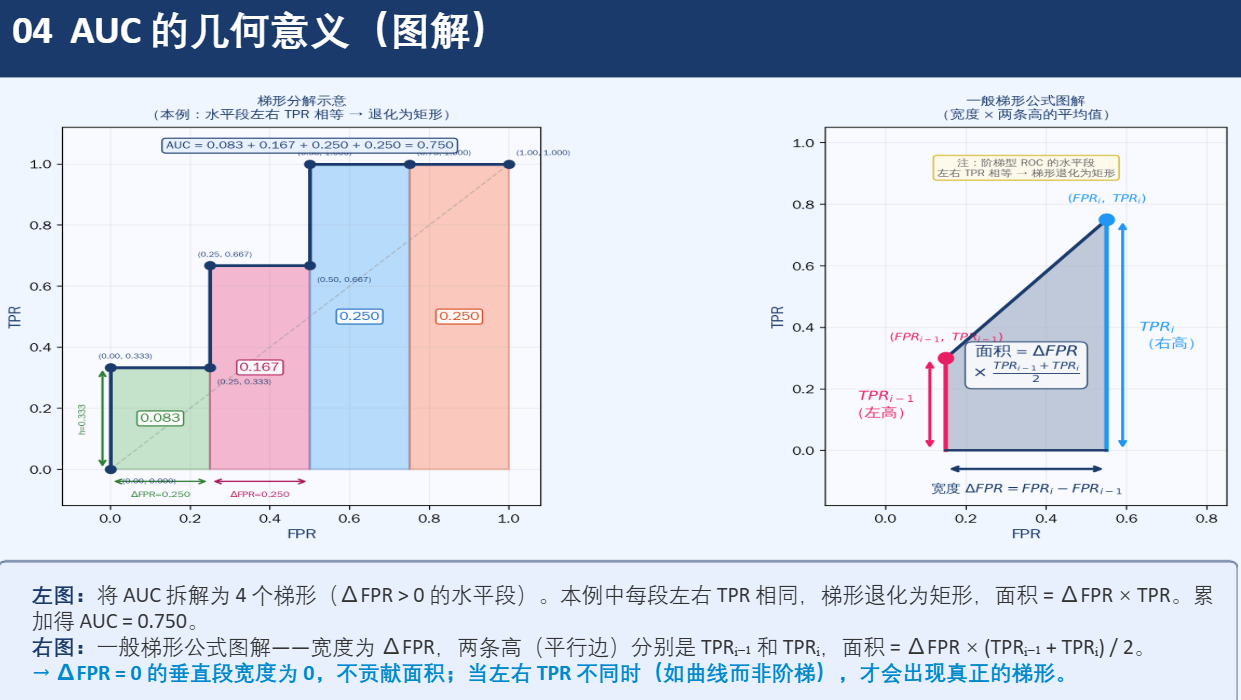
四、完整数值示例(7个样本)
4.1 数据准备(步骤1)
| 样本编号 | 真实标签 | 预测概率 |
|---|---|---|
| S1 | 1(正) | 0.95 |
| S2 | 0(负) | 0.82 |
| S3 | 1(正) | 0.78 |
| S4 | 0(负) | 0.61 |
| S5 | 1(正) | 0.55 |
| S6 | 0(负) | 0.40 |
| S7 | 0(负) | 0.22 |
-
总正例数 P = 3(S1, S3, S5)
-
总负例数 N = 4(S2, S4, S6, S7)
4.2 排序(步骤2)
数据已经按概率降序排列(从上到下递减),无需调整。
4.3 逐步降低阈值,计算(TPR, FPR)(步骤3)
| 步骤 | 当前样本 | 真实标签 | 预测概率 | 累计TP | 累计FP | TPR = TP/3 | FPR = FP/4 | (FPR, TPR) |
|---|---|---|---|---|---|---|---|---|
| 起点 | - | - | - | 0 | 0 | 0.000 | 0.000 | (0.000, 0.000) |
| 1 | S1 | 1(正) | 0.95 | 1 | 0 | 0.333 | 0.000 | (0.000, 0.333) |
| 2 | S2 | 0(负) | 0.82 | 1 | 1 | 0.333 | 0.250 | (0.250, 0.333) |
| 3 | S3 | 1(正) | 0.78 | 2 | 1 | 0.667 | 0.250 | (0.250, 0.667) |
| 4 | S4 | 0(负) | 0.61 | 2 | 2 | 0.667 | 0.500 | (0.500, 0.667) |
| 5 | S5 | 1(正) | 0.55 | 3 | 2 | 1.000 | 0.500 | (0.500, 1.000) |
| 6 | S6 | 0(负) | 0.40 | 3 | 3 | 1.000 | 0.750 | (0.750, 1.000) |
| 7 | S7 | 0(负) | 0.22 | 3 | 4 | 1.000 | 1.000 | (1.000, 1.000) |
💡 理解:每一步都把当前样本的预测概率作为新的阈值,认为"概率≥该值"的为正例。由于已经排序,实际就是累计到当前行。
4.4 梯形法则计算AUC(步骤4)
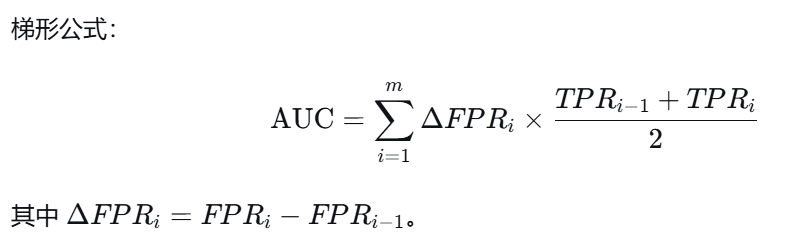
我们逐段计算(从起点到第一个点,再到第二个点......直到最后):
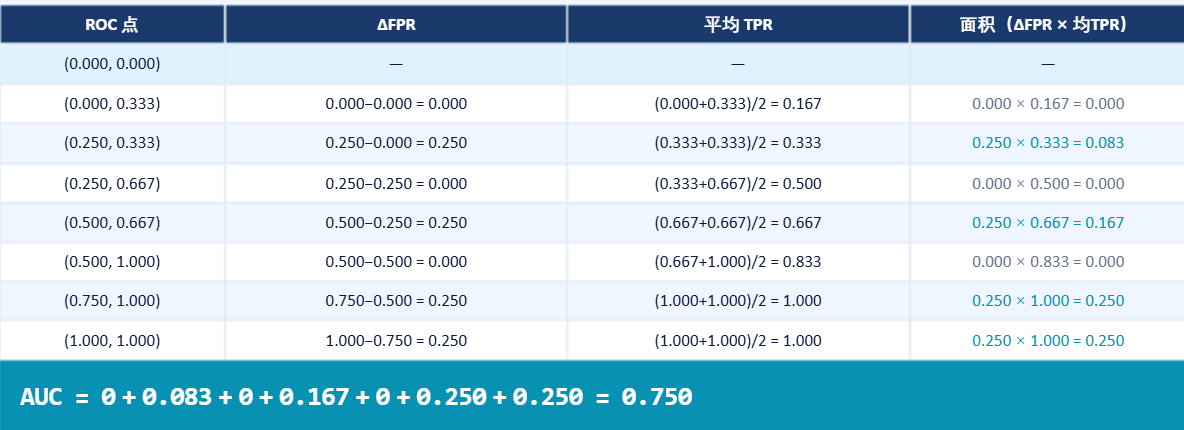
4.5 ROC曲线形状理解
-
垂直段(ΔFPR=0):TPR上升,FPR不变 → 说明模型连续遇到了正例,这是好现象。
-
水平段(ΔTPR=0):FPR上升,TPR不变 → 说明遇到了负例,发生了误报,模型表现变差。
-
本例中AUC=0.75,属于良好模型。
五、第二个示例:更好的模型
5.1 数据与排序
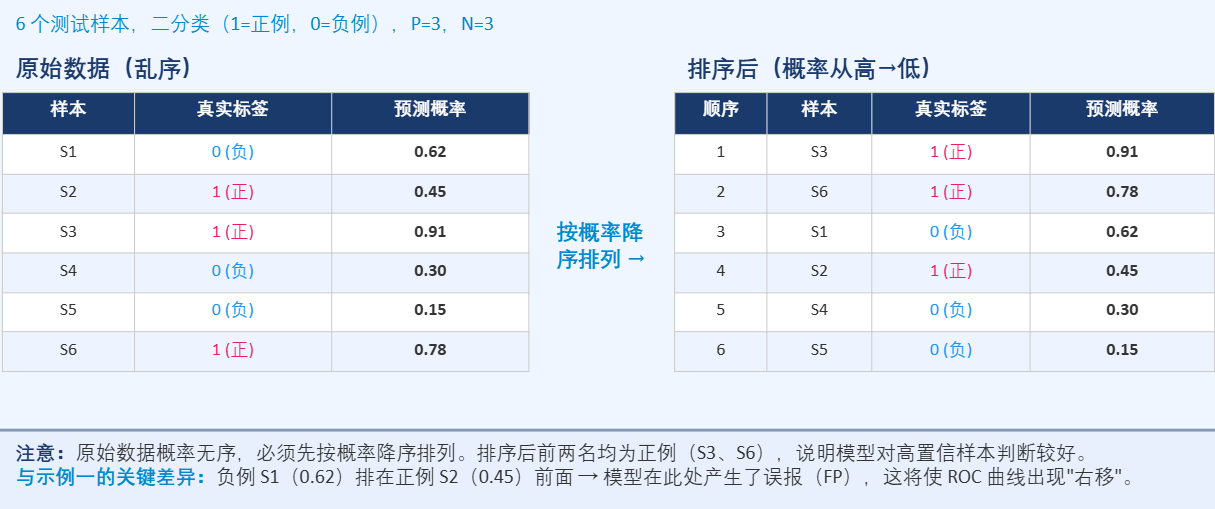
| 样本 | 真实标签 | 预测概率 | 排序后 |
|---|---|---|---|
| S3 | 1 | 0.92 | 第1(正) |
| S6 | 1 | 0.87 | 第2(正) |
| S1 | 0 | 0.62 | 第3(负) |
| S2 | 1 | 0.45 | 第4(正) |
| S4 | 0 | 0.33 | 第5(负) |
| S5 | 0 | 0.21 | 第6(负) |
P=3, N=3。
5.2 逐步计算
| 步骤 | 累计TP | 累计FP | TPR | FPR | 点 |
|---|---|---|---|---|---|
| 起点 | 0 | 0 | 0.000 | 0.000 | (0.000,0.000) |
| S3(正) | 1 | 0 | 0.333 | 0.000 | (0.000,0.333) |
| S6(正) | 2 | 0 | 0.667 | 0.000 | (0.000,0.667) |
| S1(负) | 2 | 1 | 0.667 | 0.333 | (0.333,0.667) |
| S2(正) | 3 | 1 | 1.000 | 0.333 | (0.333,1.000) |
| S4(负) | 3 | 2 | 1.000 | 0.667 | (0.667,1.000) |
| S5(负) | 3 | 3 | 1.000 | 1.000 | (1.000,1.000) |
5.3 梯形法求AUC
重要垂直段:前两步 FPR=0,TPR从0→0.333→0.667,这两段ΔFPR=0,面积0。
后续计算:
-
(0.000→0.333): ΔFPR=0.333, 平均TPR=(0.667+0.667)/2=0.667 → 面积=0.222
-
(0.333→0.333): ΔFPR=0 → 面积0
-
(0.333→0.667): ΔFPR=0.334, 平均TPR=(1.000+1.000)/2=1.000 → 面积≈0.334
-
(0.667→1.000): ΔFPR=0.333, 平均TPR=(1.000+1.000)/2=1.000 → 面积=0.333
AUC = 0.222 + 0.334 + 0.333 = 0.889(四舍五入)
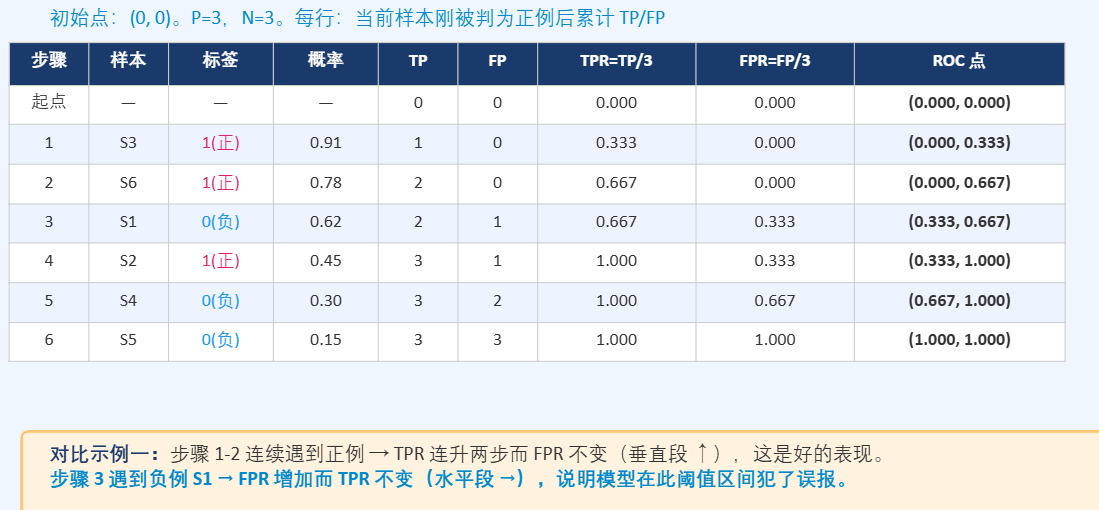
示例二 AUC=0.889 > 示例一 AUC=0.750,因为前两个样本都是正例,模型对高置信样本判断准确,排序能力更强。
六、AUC值的解读(一看就懂)
| AUC值范围 | 含义 | 通俗解释 |
|---|---|---|
| AUC = 1.0 | 完美分类器 | 存在一个阈值,能把所有正负例完全分开(理想情况,现实中极少) |
| 0.9 ≤ AUC < 1.0 | 优秀 | 模型区分能力很强,但需警惕过拟合 |
| 0.7 ≤ AUC < 0.9 | 良好 | 大多数实用模型的范围,可以接受 |
| 0.5 < AUC < 0.7 | 较差 | 比随机好一点,但有明显改进空间 |
| AUC = 0.5 | 随机猜测 | 模型没有区分能力,等于抛硬币 |
| AUC < 0.5 | 比随机还差 | 预测方向反了(比如把正例预测为负的概率更高),可以反转标签使用 |
💡 物理意义 :AUC = 随机选一个正样本和一个负样本,模型给正样本打分高于负样本的概率。
例如 AUC=0.75,意味着有75%的概率正样本的得分高于负样本。
七、常见误区与注意事项
-
AUC只关心排序,不关心校准
即使预测概率整体偏高或偏低,只要排序正确,AUC仍然很高。
-
AUC适合不平衡数据,但不能完全替代PR曲线
当正类非常稀少(如1%),且业务只关注正类时,建议同时看精确率-召回率曲线(PR曲线)。
-
AUC不能跨数据集比较
不同数据集的正负分布不同,AUC值不能直接比较。
-
手动计算时务必先按概率降序排列
乱序会导致ROC曲线错误。
八、核心公式与步骤速记卡
-
TPR = TP/(TP+FN)
-
FPR = FP/(FP+TN)
-
ROC曲线:横轴FPR,纵轴TPR
-
AUC梯形公式 :
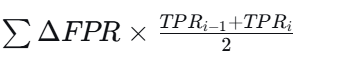
-
手动计算四步:准备数据 → 排序 → 逐步累计 → 梯形法求和