给 AI 装上大脑,不如给它接上手。
这几天的工作,集中在一件事上:让 Agent 不只是能说,还能真正接过来、改完、还给你。
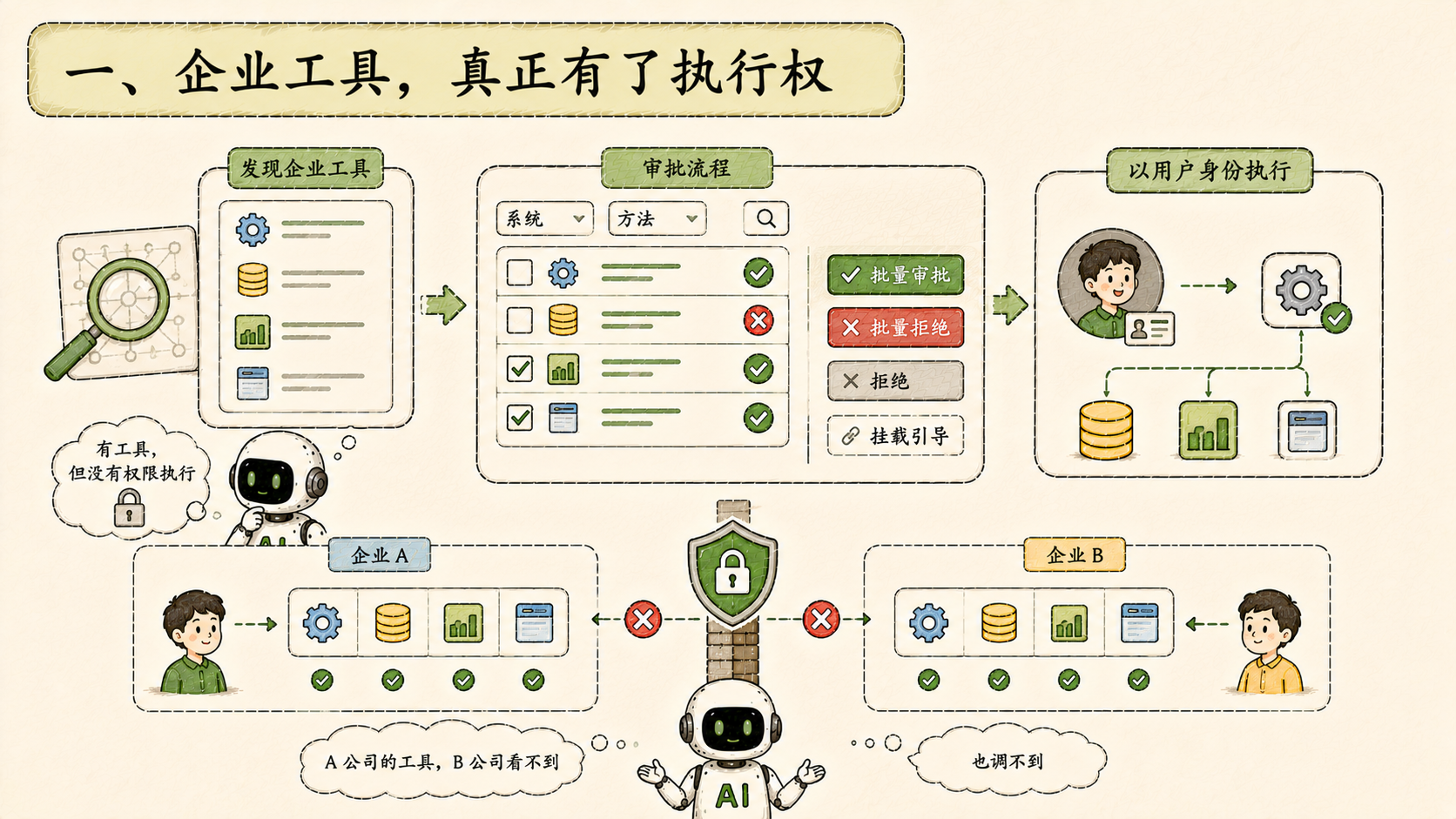
一、企业工具,真正有了执行权
之前系统已经能发现企业内部的工具和系统,列出来、让用户审批。但审批完之后,工具执行时拿不到真实的用户身份------它知道该做什么,但没有权限真正去做。
这次把这个环节打通了:审批通过的工具在运行时能拿到调用者的真实身份,以用户自身的权限去执行操作,而不是用一个共享的系统账号。
审批流程也完善了。原来是全量审批或拒绝,现在支持单条拒绝、批量审批、批量拒绝,前端加了系统和方法的筛选,审批后有挂载引导,已审批工具的名称可见。流程细化之后,工具管理才真正可操作,而不是一个摆设。
租户隔离也同步跟上:A 公司的工具,B 公司看不到,也调不到。
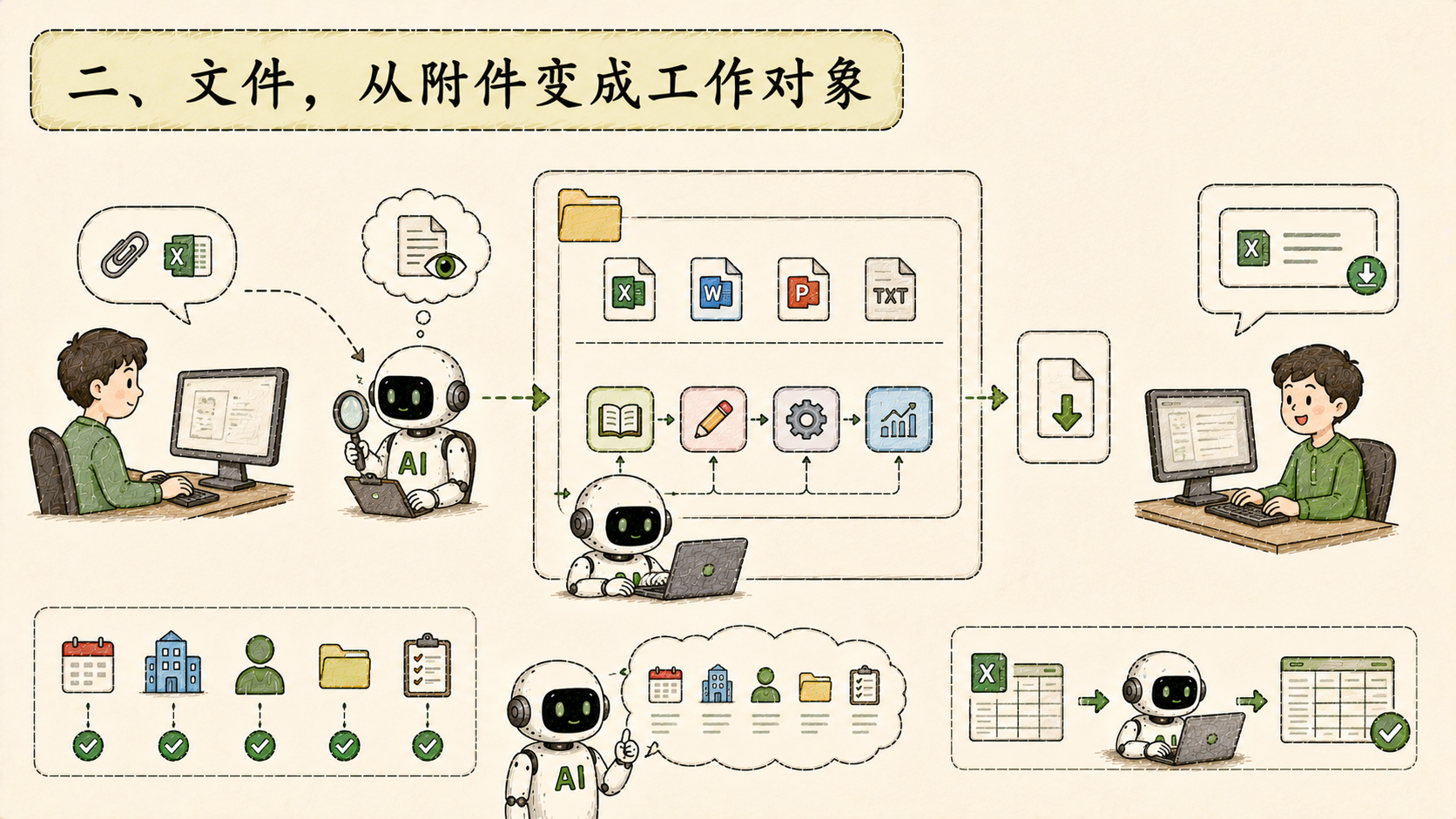
二、文件,从附件变成工作对象
以前用户上传文件,Agent 最多能"看"一眼------读一读内容,回答问题。文件本身还是文件,Agent 碰不到。
这次把文件落到了 Agent 的工作区里。Agent 现在可以直接对文件进行操作:读、改、处理,完了之后通过新增的导出工具把结果回传,用户在聊天窗口直接看到下载卡片,点一下拿走。
同时给 Agent 注入了当前的工作上下文------日期、所在企业、当前用户、工作区的文件情况、文件处理的操作规范。Agent 在处理任务时有了更完整的背景,不用用户每次解释"我是谁、现在几号、文件在哪"。
具体到 Excel 这类场景:上传表格、说清楚要做什么,Agent 处理完直接发回来。这是"数字员工"最朴实的样子。
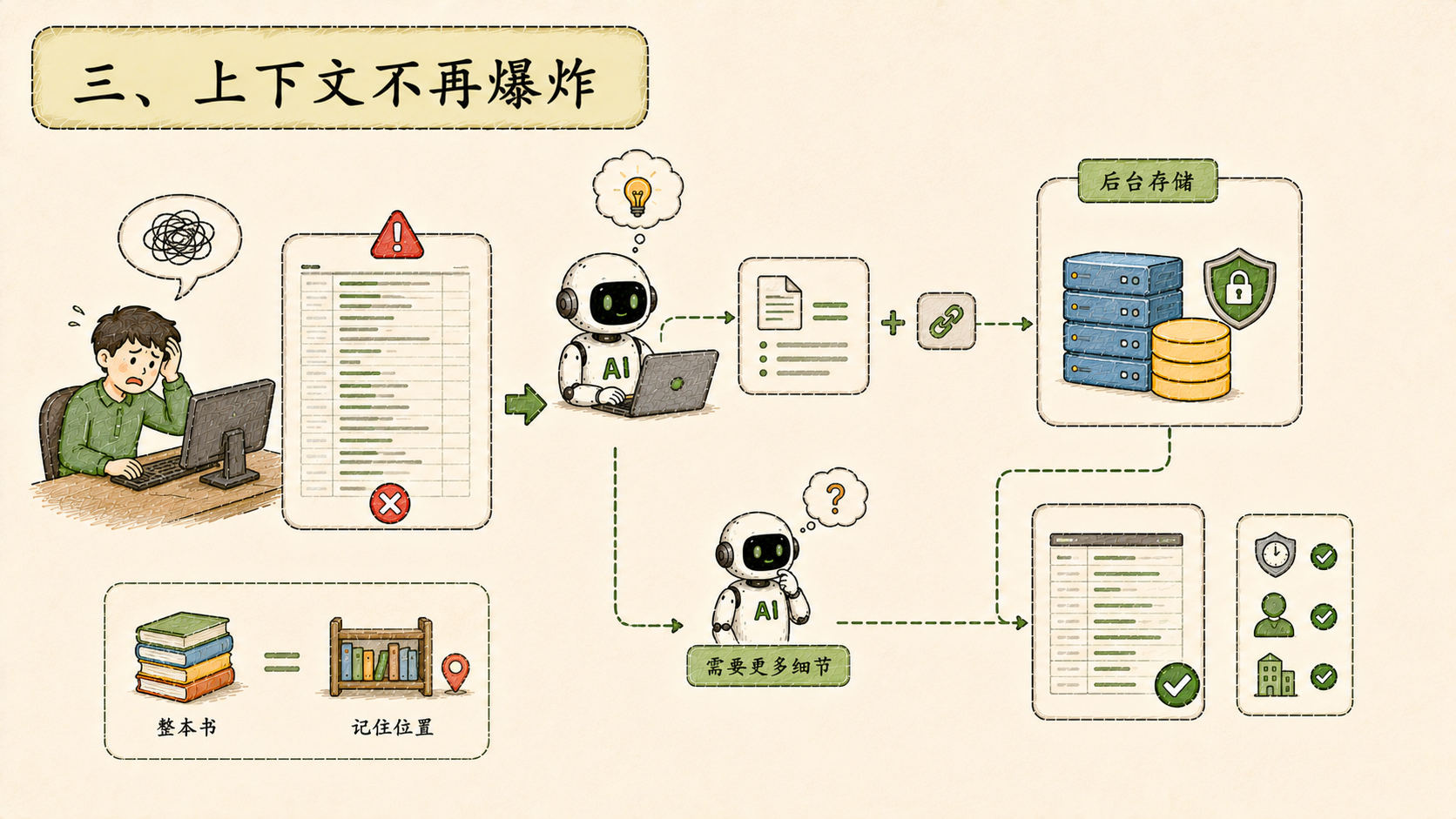
三、上下文不再爆炸
有一类问题一直存在:当工具返回的结果很大------几千行数据、完整的系统日志、长篇检索结果------直接塞进对话上下文,很快就超出了模型能处理的范围,要么截断,要么报错。
这次的解法是句柄化:超大的工具输出不再直接留在上下文里,而是存到后台,上下文只保留一个摘要和一个取回地址。Agent 在推理时如果判断需要更多细节,可以主动去取原始数据,不需要的时候就不取。
类比起来就是:不是把整本书背进脑子,而是记住书在哪个书架,需要的时候再翻。
数据有过期清理,有脱敏处理,有租户归属校验,不是简单存一下了事。
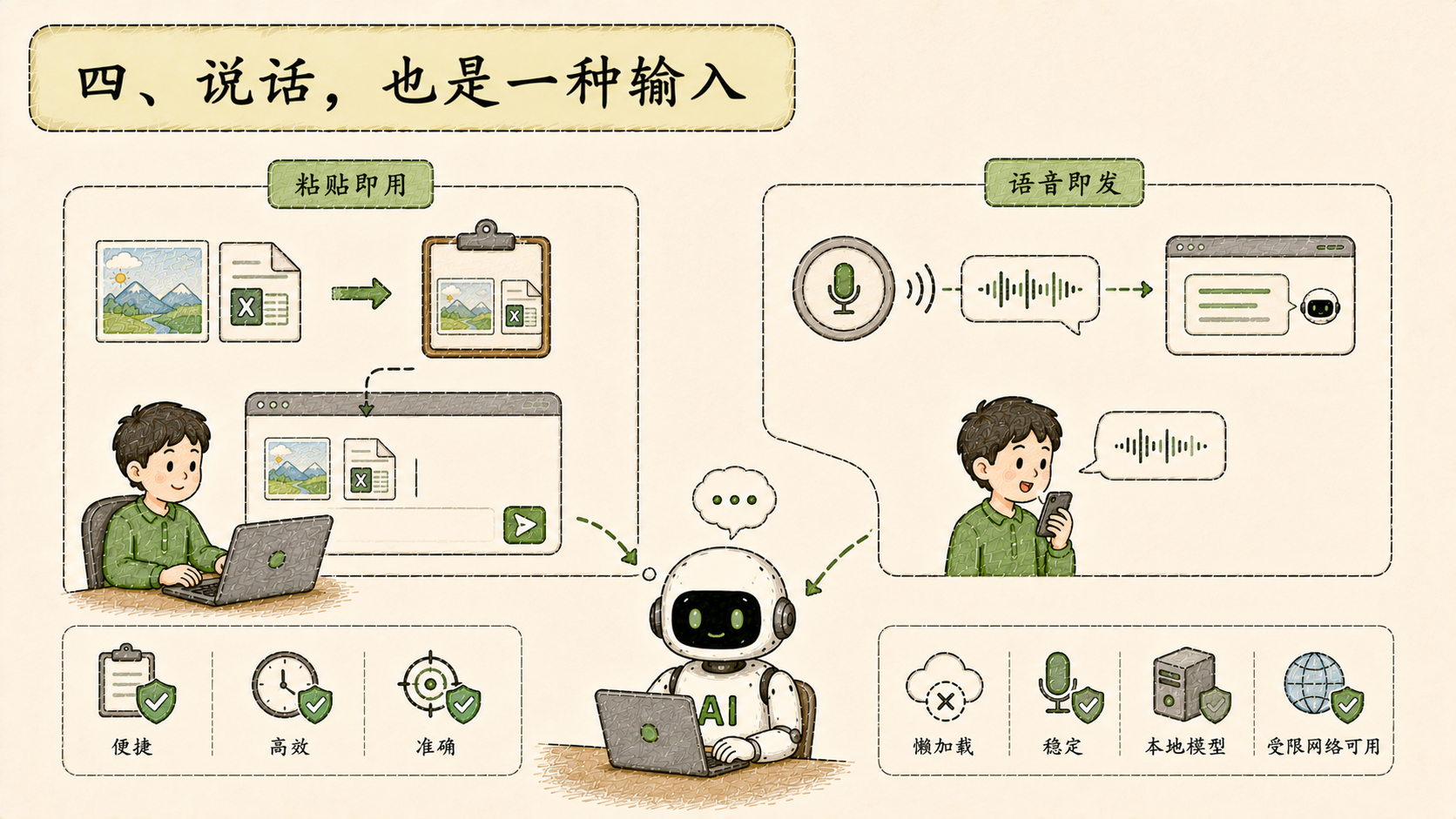
四、说话,也是一种输入
今天还加了两个输入方式的改动。
第一个是剪贴板粘贴:复制图片或文件后,直接在对话框里粘贴,不需要点上传按钮再找文件。
第二个是语音听写:点开麦克风说话,转成文字发给 Agent。后端接了语音转写服务,前端做了懒加载,避免没用到时占资源。修了一个隐蔽的问题------录音过程中如果界面重渲染,会静默丢失音频内容,用户以为在录,其实已经断了。还有另一个问题:服务在受限网络环境里启动时会尝试联网下载模型,卡住超过两分钟才超时,改成强制使用本地模型之后启动恢复正常。
这两个改动加在一起,对话的输入方式从"必须打字"变成了**"所见即粘,所说即发"**。
另外这几天做了一轮比较彻底的死代码清理,前后端加各子服务共移除了 52 项无效代码,不会产生新功能,但维护负担实实在在轻了一截。
这,是第四十七天。
**《从0到1:企业级AI项目迭代日记》**记录一个企业级 AI 项目从创意、架构到落地的真实过程。不讲神话,只记录进化。
如果你也在做企业 AI 落地,欢迎留言来聊。或者,把这篇转发给一个正在踩同样坑的朋友