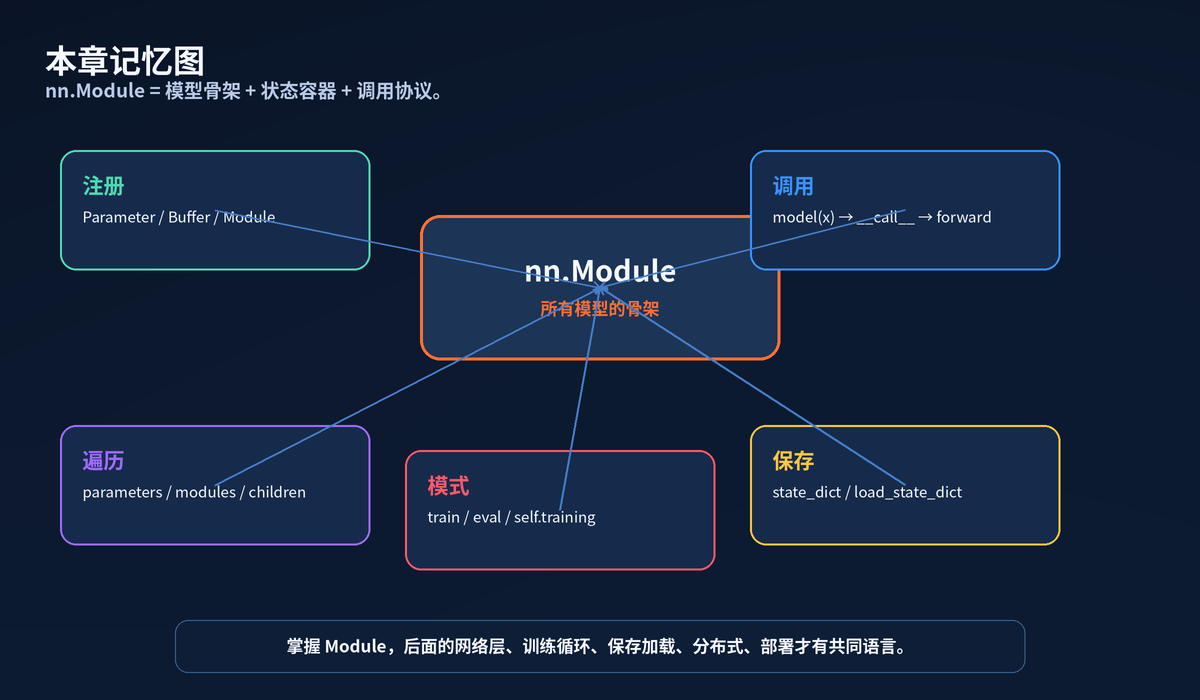
开篇:Module 不是"普通父类"
写 PyTorch 模型,最终都会回到 nn.Module。
它不是一个空壳父类。它是模型的总管:管参数、管子模块、管状态、管调用、管保存加载。
你写的 forward 只是计算逻辑。真正让模型"像模型一样工作"的,是 nn.Module 背后的注册和调用机制。
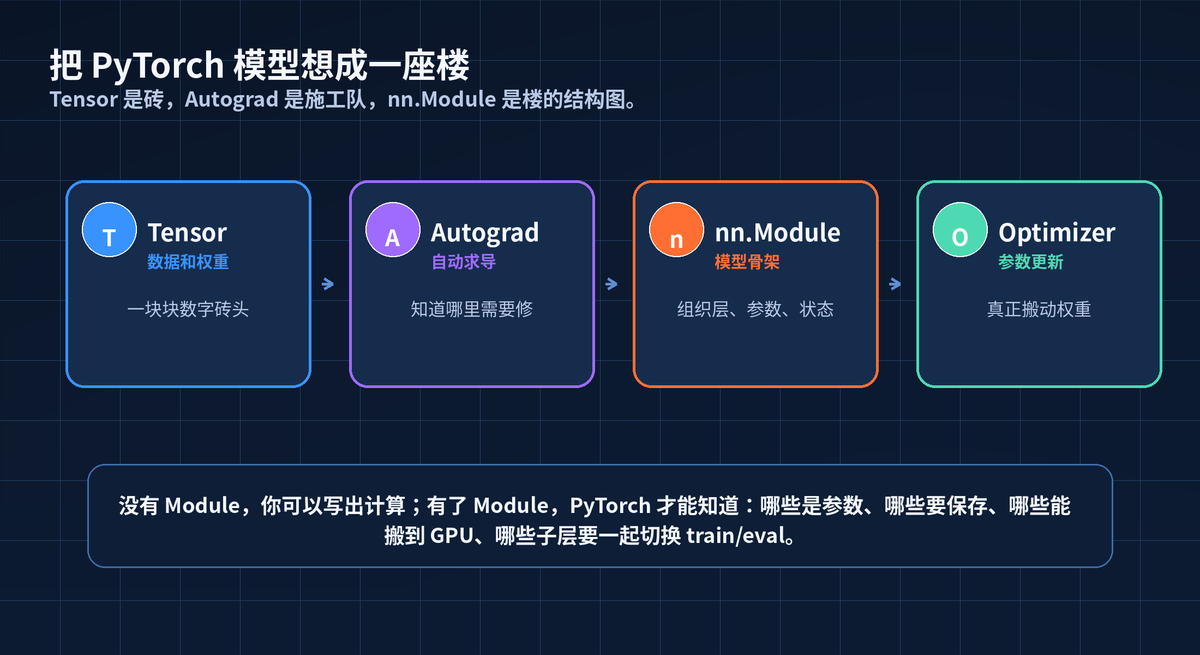
把 Module 放到 PyTorch 体系里看
1. 官方定位:Module 是神经网络模块的基类
PyTorch 官方文档说得很直接:torch.nn.Module 是所有神经网络模块的基类,自己的模型也应该继承它。
更关键的是:Module 可以包含其他 Module。也就是说,模型天然是一棵树。
这棵树的价值很大。只要树建好了,PyTorch 就能递归找参数、迁移设备、切换模式、保存状态。
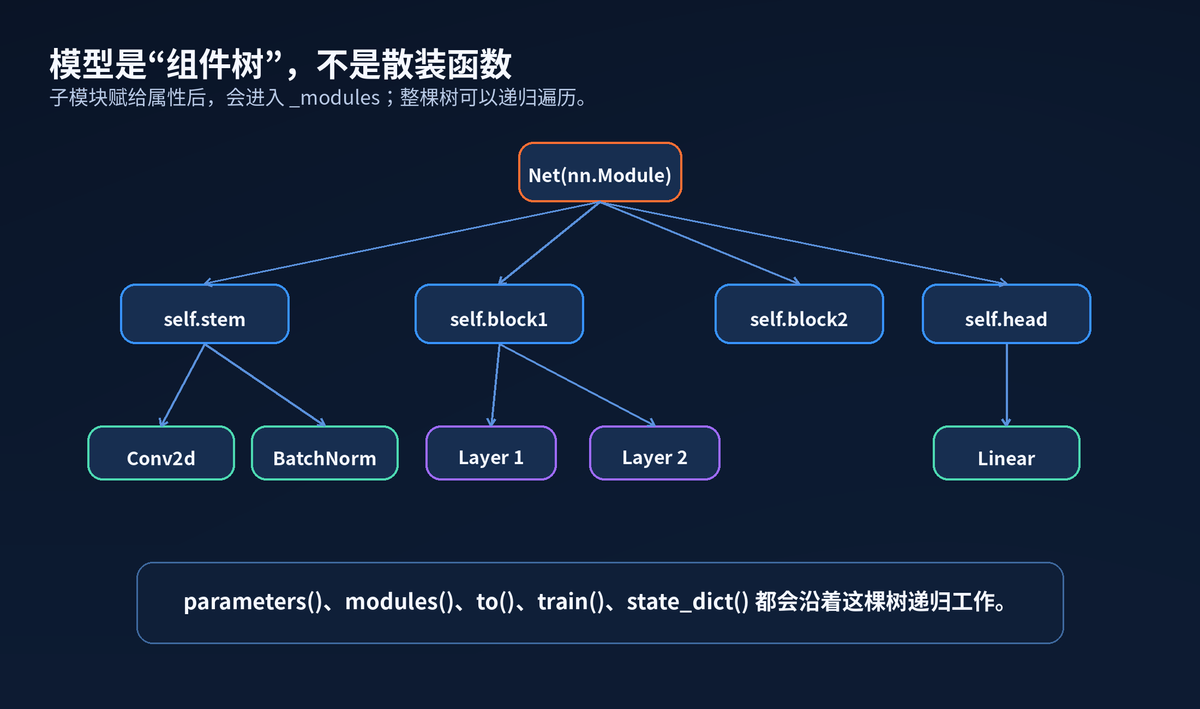
模型是 Module 组件树
2. 写 Module,只记住两个函数
init:放结构,放状态,放需要被 PyTorch 管理的对象。
forward:放计算,描述输入如何一步步变成输出。
简单说:init 管"有什么",forward 管"怎么走"。

init 与 forward 的分工
import torch
import torch.nn as nn
class TinyNet(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(10, 32)
self.act = nn.ReLU()
self.fc2 = nn.Linear(32, 2)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
return self.fc2(x)
model = TinyNet()
y = model(torch.randn(4, 10))这段代码很短,但已经触发了 Module 的核心能力:fc1、act、fc2 都被注册成子模块;Linear 里的 weight 和 bias 会被递归找到。
3. 自动注册:不是魔法,是 setattr
为什么 self.fc = nn.Linear(...) 之后,model.parameters() 能找到里面的权重?
因为 nn.Module 重写了 setattr。你给属性赋值时,它会看 value 的类型。
如果是 nn.Parameter,放进 _parameters;如果是 nn.Module,放进 _modules;如果是 Buffer 或 register_buffer,放进 _buffers;其他对象才只是普通属性。
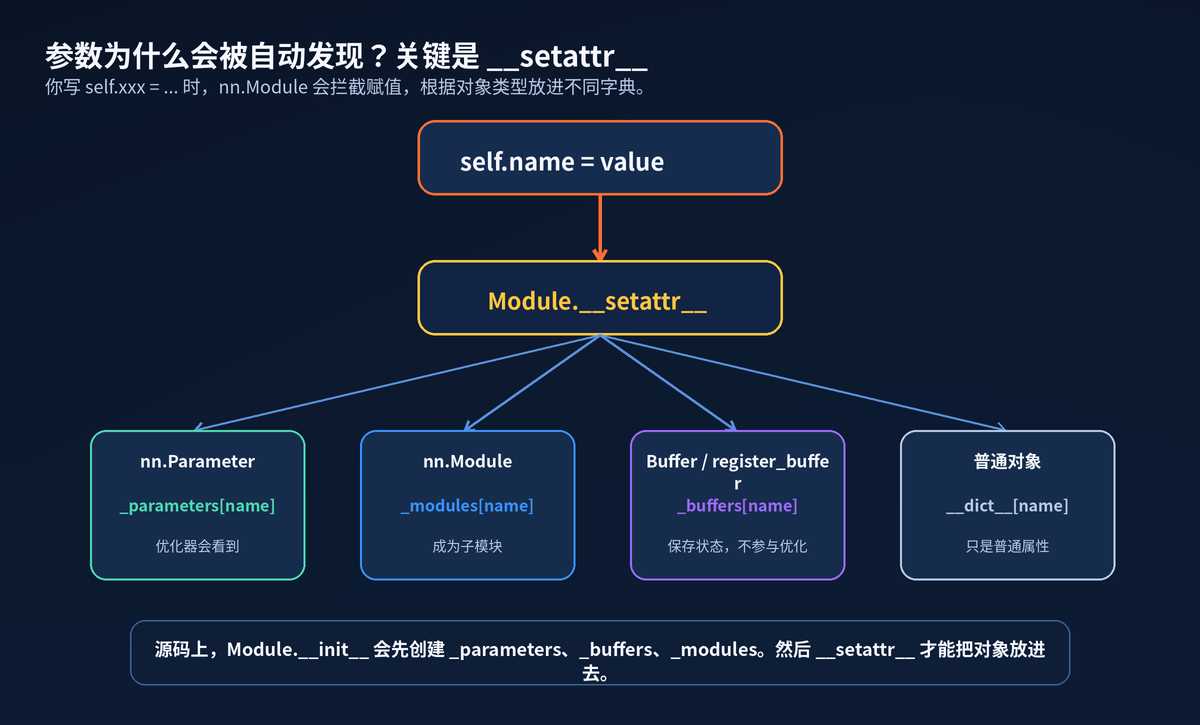
setattr 如何把对象分流到不同注册表
4. 四类成员:命运完全不同
很多 PyTorch Bug,本质是对象放错了地方。
想让优化器更新,必须是 Parameter。想随模型保存但不被优化,应该是 Buffer。想嵌套层,必须是 Module 或容器 Module。

Parameter、Buffer、Module、普通属性对比
5. 源码入口一:Module.init 先准备内部字典
源码里,Module.init 会先创建几个关键容器:_parameters、_buffers、_modules,以及 hooks 相关字典。
这就是为什么自定义模型第一行通常要写 super().init()。没有这一步,后续注册没有地方可放。
# torch/nn/modules/module.py 的核心思路
super().__setattr__("training", True)
super().__setattr__("_parameters", {})
super().__setattr__("_buffers", {})
super().__setattr__("_modules", {})注意:这里源码用的是 super().setattr,不是 self.xxx = xxx。这样可以绕开 Module.setattr 的注册逻辑,避免初始化时自己拦截自己。
6. 源码入口二:model(x) 会走 call
官方文档提醒:虽然计算配方写在 forward 里,但应该调用 Module 实例本身,而不是直接调用 forward。
原因很简单:model(x) 会进入 call 和 _call_impl,那里会处理 forward hooks、pre hooks、编译调用等逻辑。直接 model.forward(x) 会绕开这些能力。
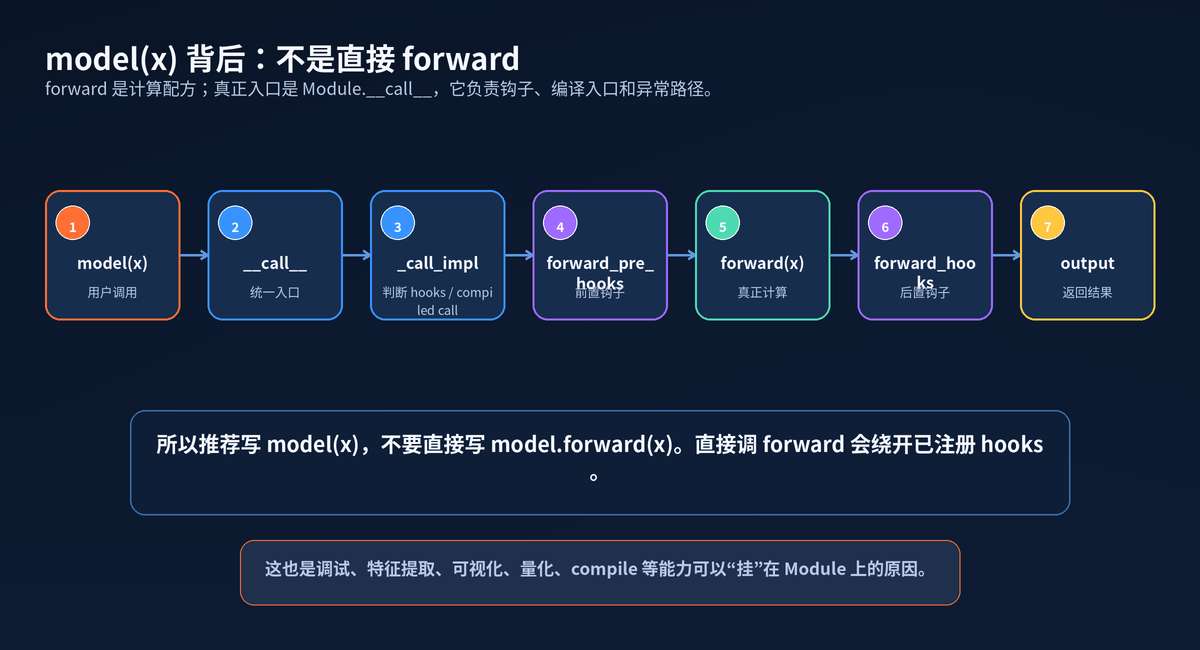
model(x) 的真实调用路径
这条链路也解释了很多高级能力:特征提取可以靠 hook,调试可以靠 hook,torch.compile 也可以挂在 Module 调用入口上。
7. parameters():优化器为什么能拿到所有权重
parameters() 返回的是 Module 参数迭代器,通常直接交给优化器。
它默认 recurse=True,会递归进入所有子模块。所以你只需要写 optimizer = torch.optim.Adam(model.parameters()),不需要手动收集每一层权重。
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
for name, p in model.named_parameters():
print(name, p.shape)关键点:被注册的参数才会出现。普通 Python list 里的层不会自动注册。需要用 nn.ModuleList 或 nn.Sequential。
8. Buffer:不学习,但要跟着模型走
Buffer 是模型状态,但不是可学习参数。
典型例子是 BatchNorm 的 running_mean。它会影响计算,也需要保存和加载,但不应该交给优化器更新。
class RunningStat(nn.Module):
def __init__(self):
super().__init__()
self.register_buffer("running_mean", torch.zeros(10))
def forward(self, x):
return x - self.running_meanpersistent=True 的 Buffer 会进 state_dict。persistent=False 的 Buffer 会跟着 to()/cuda() 迁移,但不会被保存。
9. state_dict:模型保存的核心
PyTorch 推荐保存 state_dict,而不是把整个模型对象直接打包。
state_dict 里包含参数和持久 Buffer。key 是名字,value 是 Tensor。名字来自 Module 树的路径。
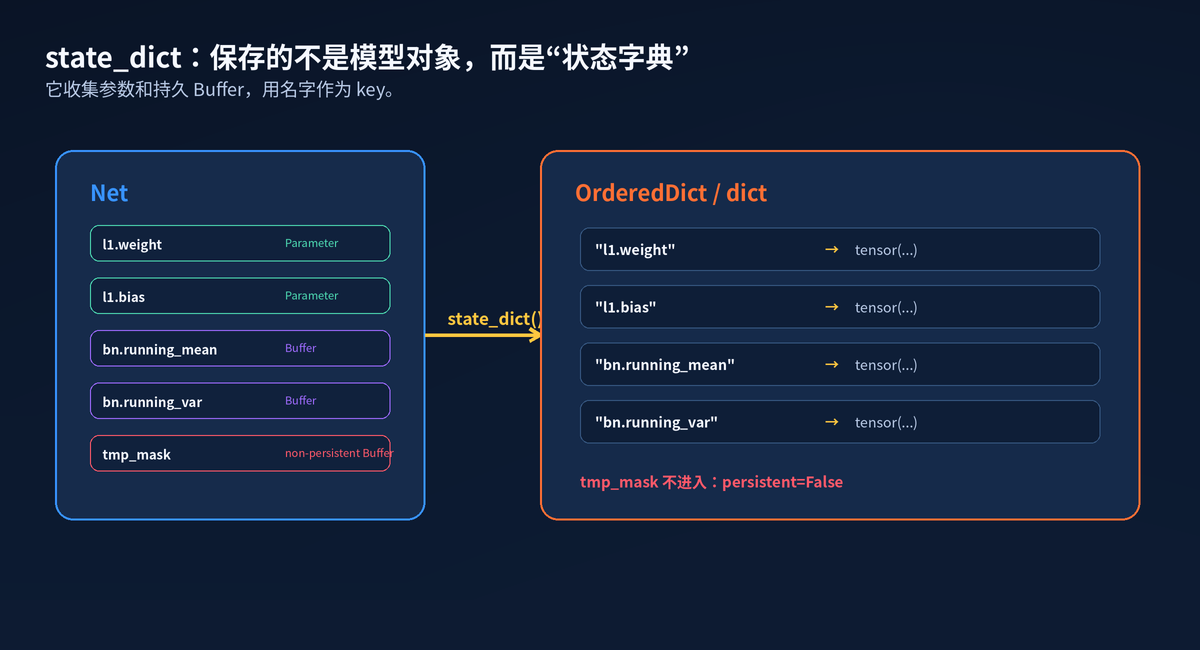
state_dict 如何收集模型状态
torch.save(model.state_dict(), "model.pt")
new_model = TinyNet()
new_model.load_state_dict(torch.load("model.pt"))理解 state_dict,后面学断点续训、迁移学习、分布式保存、部署导出都会轻松很多。
10. train() 和 eval():只切模式,不跑训练
model.train() 不会自动开始训练。model.eval() 也不会自动开始推理。
它们只是递归设置每个 Module 的 training 标志。某些层会读这个标志,比如 Dropout 和 BatchNorm。

train/eval 的真实作用
一个常见误解:eval() 不等于 no_grad()。eval() 只影响层行为;no_grad() 才影响 Autograd 是否记录梯度。
11. to():为什么整棵模型能搬到 GPU
model.to(device) 能生效,是因为 Module 会递归处理自己的参数、Buffer 和子模块。
普通属性不会自动被迁移。普通 Tensor 如果没注册成 Buffer,也不会被 Module 管。
device = "cuda" if torch.cuda.is_available() else "cpu"
model = TinyNet().to(device)
x = torch.randn(4, 10, device=device)
y = model(x)记住:需要跟着模型走的 Tensor,要么是 Parameter,要么注册成 Buffer。
12. 源码级主线:六个动作串起来
读 Module 源码,不要从头到尾硬啃。按动作读:初始化、注册、调用、遍历、状态、模式/迁移。
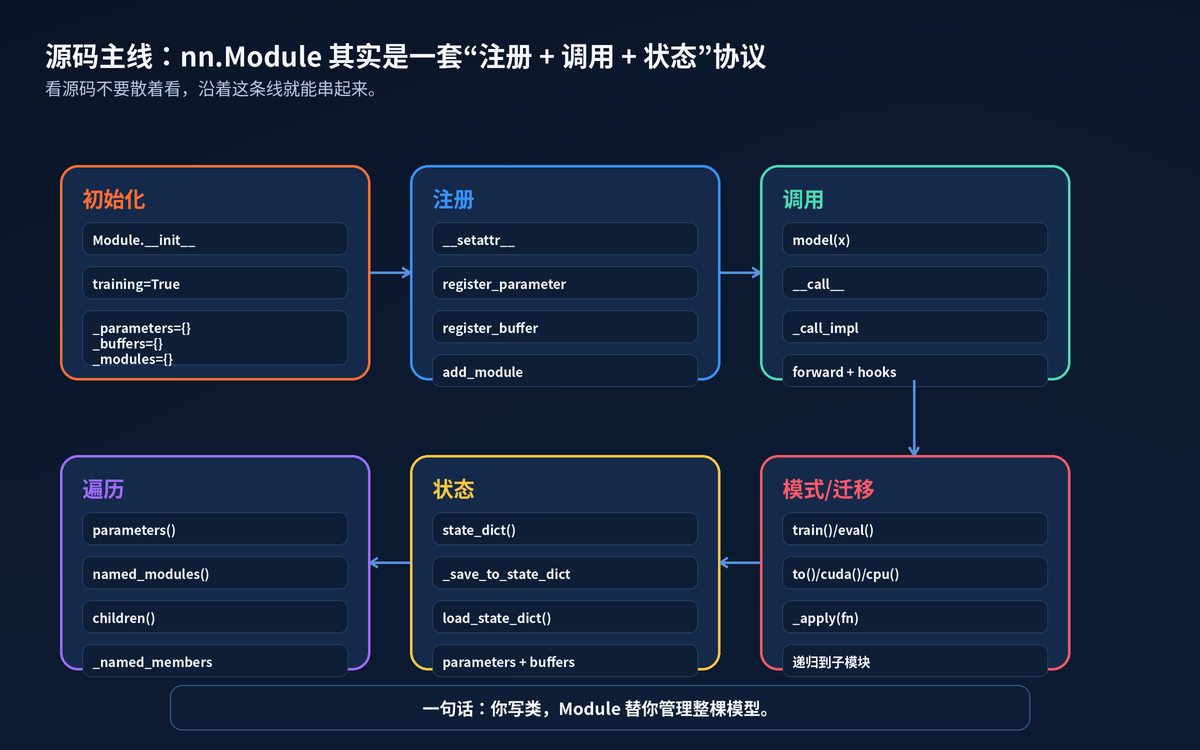
最重要的三个问题:
对象赋值后,去了 _parameters、_buffers、_modules,还是普通 dict?
模型调用时,是走 model(x),还是绕过了 call?
保存加载时,这个对象会不会出现在 state_dict 里?
13. 常见坑:先看有没有被注册
当参数没有更新、模型保存后丢东西、to(cuda) 后设备不一致,先不要怀疑玄学。
先检查注册。

print(model)
print(dict(model.named_parameters()).keys())
print(dict(model.named_buffers()).keys())
print(model.state_dict().keys())总结
nn.Module 是 PyTorch 模型的骨架。
它把散落的层、参数、状态组织成一棵可训练、可迁移、可保存、可调试的树。
掌握 Module,后面讲 Linear、Conv、Transformer、训练循环、模型保存、分布式训练,都会有同一套底层语言。