1. Vibe Coding 盛行,质量谁来兜底?
随着 Vibe Coding 逐渐成为常态,产品经理可以用自然语言生成页面,开发也不再从零开始写代码,整体实现速度被成倍放大。甚至没有编程背景的人,也能借助 AI,把想法变成可运行的代码。
效率的提升是实实在在的,但问题也变得更直接:当代码产出越来越快,质量由谁来兜底?
当越来越多代码由大模型参与生成,并不意味着测试可以被弱化。相反,开发节奏被整体拉快,提测更频繁、周期更短,1 周内需求迭代 5 次,测试窗口从 3 天压缩到 1 天,留给测试分析和验证的时间却在减少。原本那套偏慢、依赖人工补位的测试方式,很容易在这个过程中卡住。
LLM 可以高效生产代码,但安全漏洞、逻辑缺陷、边界异常这些问题并不会因此消失。正如《Vibe Testing: How AI is Changing the Way We Test Software》中提到的:
"Just because AI helps you write code doesn't mean the software is automatically reliable. That's where Vibe Testing comes in."
所以问题的核心,不是"还要不要测试",而是:当代码生产速度被拉满之后,测试该如何跟上。
这也正是本文想讨论的两个关键词:Agent Skills 和 Vibe Testing。
前者关注的是如何把资深测试的经验沉淀下来,变成可复用、可传递的能力;后者关注的是如何借助 AI 做探索式测试,把那些规则之外、但真实存在的风险提前挖出来。
2. 什么是 Agent Skills ?
通俗来讲,Agent Skills 是专门为大模型准备的可复用能力包,基于文件系统存储。
过去给模型下任务,往往要一次性提供完整背景。有了 Agent Skills,可以把某个领域的知识提前整理好,打包成一个"技能",模型用到时再按需读取。
简单理解:就是给 AI 配一本随用随查的操作手册。
其核心机制 "渐进式披露(Progressive Disclosure)" 是 Agent Skills 最具魅力的设计,它通过一个精密的三层加载结构来节省 Token 并提高效率:
-
第一层:元数据层 ------ 始终加载。
只加载技能名称和描述,模型据此判断是否匹配当前任务。
-
第二层:指令层 ------ 按需加载。
匹配成功后,才读取 SKILL.md 中的操作指南。就算装了 100 个技能,对话开始时也不会撑爆上下文。
-
第三层:资源层 ------ 深度加载。
包含参考文档(Reference)和执行脚本(Script)。两者有所不同:Reference 是被读取,内容进入上下文供模型参考;Script 是被执行,模型只关心运行结果,不需要读代码本身。
3. 什么是 Vibe Testing ?
简单来说,Vibe Testing 可以理解为:通过 AI 来验证软件是否符合 "预期体验" 的一种测试方式。
它更强调一种 "测试的感觉"------先定义好测试的基调,让 AI 去生成测试场景、模拟用户行为,并关注实际表现是否偏离了预期体验。换句话说,它不只是检查"功能有没有实现",更关注"用起来是不是对"。
相比传统测试更多依赖规则和用例,Vibe Testing 更偏向一种探索式的方式:通过自然语言描述测试意图,让 AI 帮助扩展测试路径,去覆盖那些不容易被事先枚举出来的场景。它关注的,不只是 "有没有做",而是 "是不是应该这样"。
目前,在这个方向上,一些结合 AI 的测试尝试正在逐步出现:
-
自愈测试(Self-Healing Tests)
当 UI 发生变化时,传统测试往往需要人工逐一修复脚本。而在 AI 的帮助下,系统可以自动识别元素变化并进行修复,从而降低维护成本,让测试更稳定地运行下去。
-
AI 生成测试(AI-Generated Tests)生成式 AI 可以结合需求文档、用户故事以及历史缺陷数据,自动生成测试用例。在减少人工投入的同时,也能在一定程度上提升测试覆盖的广度。
-
预测性测试执行(Predictive Test Execution)通过风险分析、历史缺陷数据以及用户行为,AI 可以对测试用例进行优先级排序,让更关键、更高风险的用例优先执行,从而提升测试效率,减少资源浪费。
-
最后,也是我最关注的一点:Agentic Testing
在这种模式下,AI 不再只是执行工具,而是开始参与到测试本身中来。它可以主动提出测试思路、识别潜在风险、标记异常情况,而测试人员则把更多精力放在高价值的探索上。
测试不再只是"执行用例",而是变成了一种人与 AI 协同的探索过程。
4. 测试 Skills 实践
4.1 功能用例生成(manual-case-gen)
基于需求文档、设计说明等输入,自动生成结构化的功能测试用例。
目录结构
manual-case-gen/
├── SKILL.md # 技能入口:工作流程、步骤定义、脚本调用说明
├── references/
│ ├── manual-test-case-gen.md # 用例生成规范:角色定义、JSON 结构、编写规则
│ └── site-repo-mapping.md # 站点 → 仓库映射表(含 Git SSH、数据库名)
└── scripts/
├── fetch_lark_content.py # 拉取飞书文档内容(支持图片下载)
├── read_xmind_draft.py # 读取本地 XMind 草稿(支持 Markdown / JSON 输出)
└── json_to_xmind.py # 将用例 JSON 转换并导出为 XMind 文件用例 JSON 结构
[
{
"module": "功能模块名称",
"id": 1,
"title": "使用非法金额创建订单失败",
"priority": "High/Medium/Low",
"type": "Positive/Negative/Boundary",
"steps": [
"1、操作步骤描述",
"2、下一步"
],
"expected_result": "1、预期结果第一点\n2、预期结果第二点"
}
]用例 XMind 结构

4.2 接口自动化(api-auto-test)
将需求、设计和接口信息转化为接口自动化测试用例,并与具体站点、仓库和分支打通,最终直接写入接口自动化平台并自动执行。
目录结构
api-auto-test/
├── SKILL.md # 技能入口:工作流程、步骤定义、版本检测
├── agents/
│ └── case-reviewer.md # 复核 SubAgent:格式检查 + 覆盖率检查
├── assets/
│ ├── add_template.json # 新增用例的 JSON 模板
│ └── update_template.json # 更新用例的 JSON 模板
├── references/
│ ├── auto-test-case-gen.md # 用例生成规范:JSON 结构、编写规则、断言规范
│ └── site-repo-mapping.md # 站点 → 仓库映射表(含 Git SSH、自动化平台数据库名)
└── scripts/
├── fetch_lark_content.py # 拉取飞书文档内容
└── add_cases.py # 将用例 JSON 写入 接口自动化平台用例 JSON 结构
{
"batch_id": "batch_20260409143022",
"items": [
// 组件定义(可复用的步骤序列)
{
"id": "tmp_comp_001",
"type": "test_comp",
"name": "登录并获取Token",
"inputs": [
{
"name": "username",
"value": "example_user",
"type": "string"
}
],
"outputs": [
{
"name": "token",
"desc": "登录Token,从调用登录接口提取"
}
],
"steps": []
},
// 用例定义
{
"type": "test_suit",
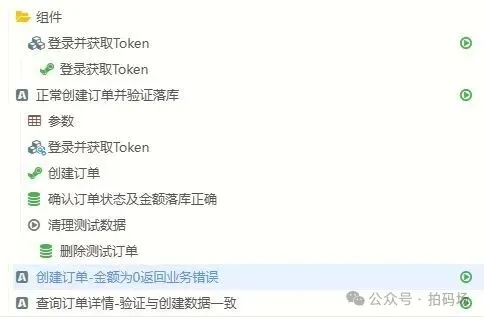
"title": "正常创建订单并验证落库",
"steps": [
{
"type": "parameters",
"parameters": [
{
"name": "amount",
"value": "100",
"type": "number"
}
]
},
{
"type": "comp_ref",
"ref_id": "tmp_comp_001"
},
{
"type": "test_api",
"name": "创建订单",
"url": "http://api.example.com/order/create",
"method": "POST",
"body_type": "json",
"json_body": "{\"amount\":\"$amount\"}",
"assertions": [
{
"path": "data.status",
"logic": "eq",
"value": "SUCCESS",
"part": "body"
}
],
"extractions": [
{
"path": "data.orderId",
"name": "order_id",
"part": "body"
}
]
},
{
"type": "test_sql",
"name": "确认订单状态落库",
"db": "example_db",
"query": "SELECT * FROM tb_order WHERE id = '$order_id'",
"assertions": [
{
"path": "[0].status",
"logic": "eq",
"value": "1"
}
],
"extractions": []
}
],
"post_execute": {
"name": "清理测试数据",
"steps": []
}
}
]
}写入平台
4.3 缺陷定位提交(bug-diagnose-submit)
将零散的排查信息(日志、SQL、复现步骤、代码定位等)整理为结构化的缺陷描述,并直接生成可提交的缺陷报告和修复建议。结合日志平台 MCP 和 MySQL MCP,Agent 可以直接查询日志和数据库,无需人工复制粘贴,实现从"描述问题"到"定位根因"的全程自动化。
目录结构
bug-diagnose-submit/
├── SKILL.md # 技能入口:工作流、字段规范、描述写法要求
└── assets/
└── bug_template.json # 缺陷 JSON 模板(对应禅道/缺陷系统字段)输出格式(bug_template.json)
{
"标题": "充值对账金额比较未统一scale导致无法自动对账",
"优先级": "中",
"经办人": "待设置",
"所属": "待设置",
"缺陷环境": "测试环境",
"严重程度": "严重",
"研发负责人": "待设置",
"测试负责人": "待设置",
"缺陷类型": "功能缺陷",
"描述": "问题现象:...\n复现数据:...\n实际结果:...\n预期结果:...\n根因分析:...\n代码位置:...\n修改建议:...\n参考修改代码:..."
}4.4 测试覆盖率分析(coverage-analysis)
结合覆盖率报告、需求变更和代码差异,识别未覆盖但高风险的改动点。
目录结构
coverage-analysis/
├── SKILL.md # 技能入口:工作流、覆盖率分析规则
└── scripts/
└── get_coverage.py # 拉取差异覆盖率数据(返回各类/方法的 fc/pc/nc 状态)未覆盖点分三类处理
4.5 性能测试(performance-test-jmx)
自动生成或修复可直接运行的 JMeter .jmx 脚本,覆盖线程组、参数化、断言等核心配置。
降低性能测试的使用门槛,让脚本从"需要手写"变成"可以快速生成和复用"。
目录结构
performance-test-jmx/
├── SKILL.md # 技能入口:生成规则、兼容性约束、编辑纪律
├── agents/
│ └── openai.yaml # OpenAI 兼容接口配置(用于 AI 辅助生成)
└── assets/
├── AI Performance Test Plan.jmx # 可参考的 JMX 模板
└── repay_accounts.csv # 参数化数据示例使用 JMeter GUI 打开

流程串联
有了这些 Skills 之后,人机协作可以贯穿提测准备、自动化补齐、缺陷定位到覆盖率分析等环节,把原本零散的动作串成一条更顺畅的测试工作流。
-
提测前:生成功能用例
提供需求文档链接后,Skill 会读取文档内容和原型图,整理出覆盖正常流程、边界条件和异常场景的测试用例,并输出为 XMind 文件,方便评审和执行。
-
提测后:生成自动化用例并执行
提供提测文档和分支名后,Agent 会结合代码 diff 分析接口变更和表结构调整,生成包含接口断言和 SQL 落库校验的用例,确认后可直接写入平台执行。
-
发现缺陷:定位并提交
将报错信息交给 Agent 后,可结合日志 MCP 和数据库 MCP 查询日志、核对数据,进一步定位问题根因,并整理出缺陷现象、相关数据、根因分析、代码位置和修改建议,形成可直接提交的缺陷报告。
-
测试完成:覆盖率分析
结合差异覆盖率报告,Agent 会将未覆盖代码分为三类:正常流程遗漏、可触达的边界场景,以及不可触发的防御性代码。测试重点放在前两类,按需补测,避免无效的全量扫描。
每个环节 Agent 处理信息收集和格式转换,测试同学专注在判断和决策上。
5. 无缝未来
随着 Vibe Coding 逐渐成为常态,软件开发与测试正在被重新定义。开发不再从零开始,测试也不再只是执行与校验,而是逐步演进为一套由 AI 驱动的智能体系。从用自然语言生成代码,到由 Agent 主导端到端的测试生成、执行与反馈,整个研发链路正在被持续压缩与重构。
在这个过程中,Agent Skills + Vibe Testing 不只是工具或方法的升级,更代表了一种新的工作范式------让 AI 进入质量保障的核心环节,使测试从 "被动验证" 走向 "主动进化"。
未来的测试,不再只是发现问题,而是与系统共同演进,持续守护软件质量。
作者简介
