一、自然语言处理概述
自然语言处理(Nature language Processing, NLP)
什么是自然语言?
人类日常交流使用的语言,例如:汉语、英语、法语等
自然语言处理做了什么?
主要是通过计算机算法来理解自然语言,处理自然语言对应的文本信息。处理流程:输入自然语言文本->分词->词嵌入-> 模型处理->输出结果。
文本预处理:脏数据、缺失值、分词(工具:jieba)
词嵌入(Dense Embedding)/词向量:将自然语言的分词 转换为 数值
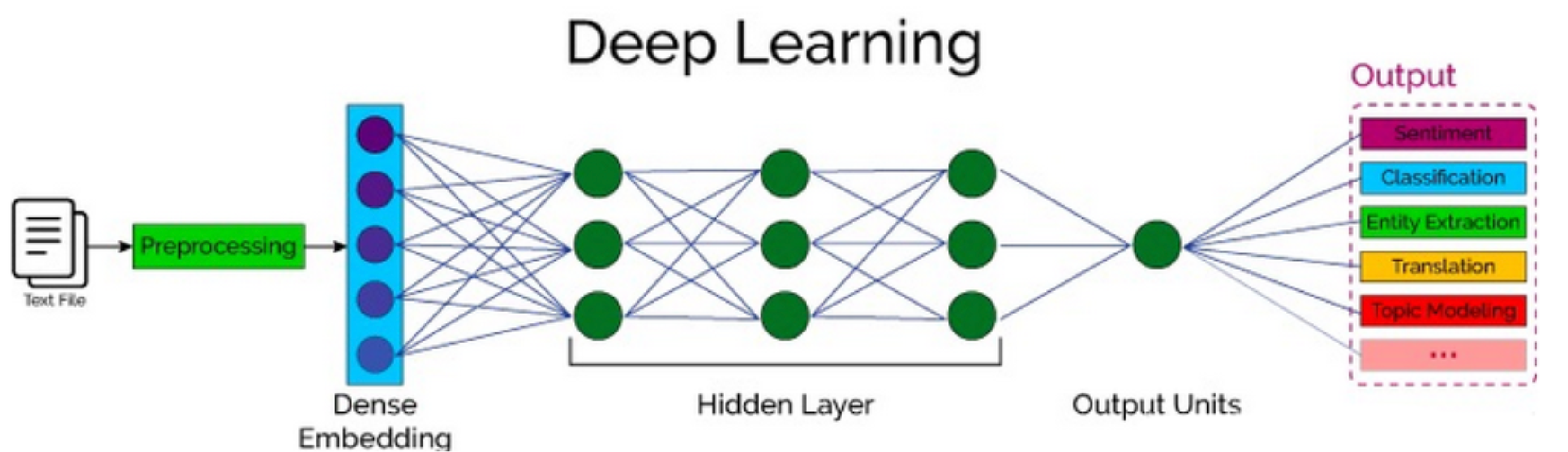
自然语言处理分类:
文本理解(NLU): 文本分类、摘要抽取、实体识别
文本生成(NLG): 文本翻译、文本生成
二、词嵌入层
1. 词嵌入概念(Dense Embedding)
作用: 将文本转换为向量
实现步骤:
① 先将语料进行分词,构建词与索引的映射,我们可以把这个映射叫做词表,词表中每个词都对应了一个唯一的索引 ------ 语料(数据集) -> 句子分词-> token(词语)去重 ->词表 (词:id)-> 生成索引对应每一个 词:id
② 使用 nn.embedding 构成词嵌入矩阵,词索引对应的向量即为该词对应的数值化后的向量表示。
2.【掌握】PyTorch词嵌入API
nn.Embedding(num_embeddings=10, embedding_dim=4)
参数:
num_embeddings 表示词的数量
embedding_dim 表示用多少维的向量来表示每个词
python
import jieba, torch
# 1、语料
text = '在Python开发中,经常需要使用pip(Python的包管理工具)来安装第三方库。为了加速安装过程,通常会选择使用镜像源,比如阿里云提供的镜像源。下面是如何配置pip使用阿里云镜像源的步骤'
# 2、分词
words = jieba.lcut(text)
# 3、去重
unique_words = set(words)
# 4、词表
words_list = list(unique_words)
# 5、词嵌入
emb = torch.nn.Embedding(num_embeddings=len(words_list), embedding_dim=5)
print(emb)
# # 6、观察
for id, word in enumerate(words_list):
print(word)
print(emb(torch.tensor(id)))
print("-"*50)
'''
输出示例:
安装
tensor([-0.3809, -0.2814, -0.7770, 0.1734, -0.8781],
grad_fn=<EmbeddingBackward0>)
--------------------------------------------------
(
tensor([ 0.8479, -0.5507, 0.4455, -0.1631, 1.2829],
grad_fn=<EmbeddingBackward0>)
'''如何实现语义相近的词,向量相似?
词向量不断从数据进行学习,将之放到神经网络中,去不断更新
三、循环网络RNN
1、【掌握】RNN网络原理
作用:处理具有序列特性的数据,并捕捉数据中的上下文与时间依赖关系
RNN 层具备"记忆"功能,能够记住先前的输入,从而在时间推移中理解上下文
例如: "我爱你", 这串文本就是具有序列关系的,"爱" 需要在 "我" 之后,"你" 需要在 "爱" 之后, 如果颠倒了顺序,那么可能就会表达不同的意思。
常见使用场景:因文本数据是具有序列特性,一般用来处理文本数据
RNN 是如何计算,过程是什么样的呢?
RNN 层通过逐步接收当前输入和前一时刻的隐状态,逐步捕捉序列中的依赖关系
RNN 层的核心在于其隐藏状态(Hidden State):当新的输入进入网络时,当前的隐藏状态会结合新输入来生成新的隐藏状态,这使得网络能够处理变长的序列数据,并保留历史上下文
实现步骤:
示例输入文本:"我爱你"
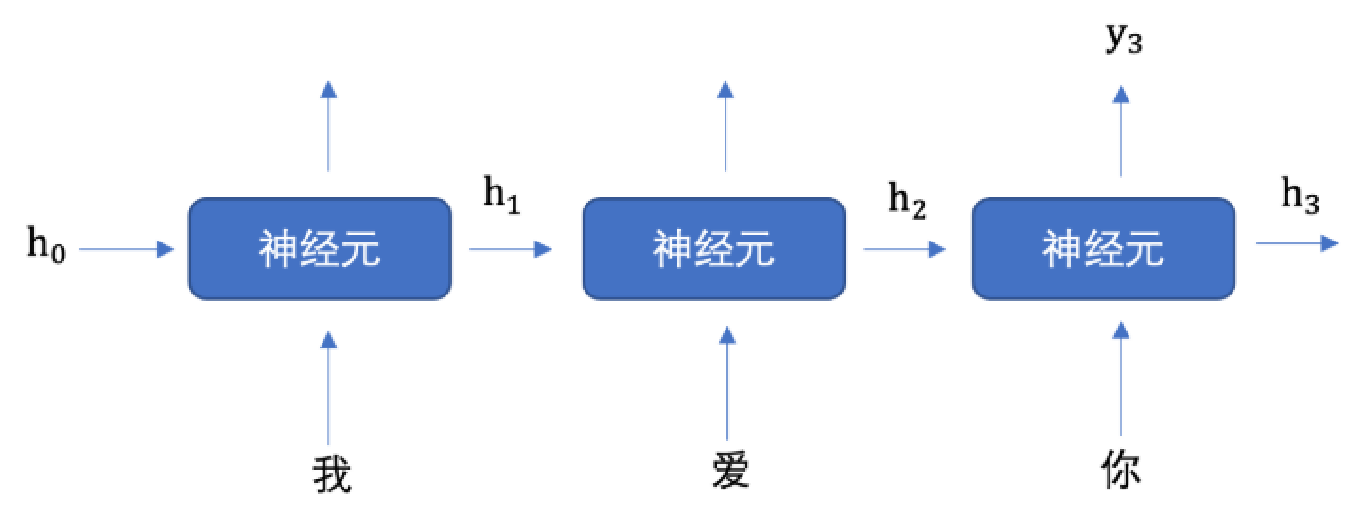
① 首先初始化出第一个隐藏状态h0,一般都是全0的一个向量
② 将 "我" 进行词嵌入,转换为向量的表示形式。送入到第一个时间步,结合上一步隐藏状态h0,然后输出隐藏状态 h1
③ 然后将 h1 和 "爱" 输入到第二个时间步,得到隐藏状态 h2
④ 将 h2 送入到全连接网络,得到 "你" 的预测概率。
每个神经元内部是如何计算的呢?
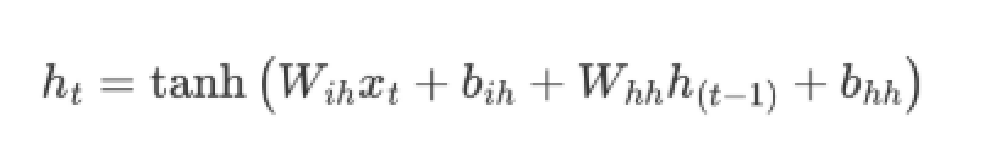
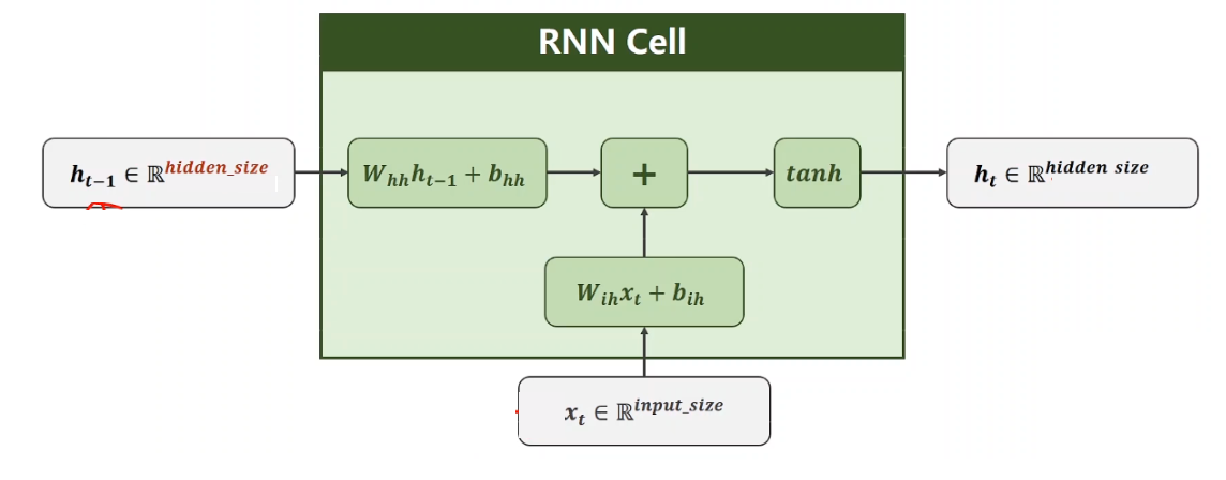
上述公式中:
表示输入数据的权重
表示输入数据的偏置
表示输入隐藏状态的权重
表示输入隐藏状态的偏置
最后对输出的结果使用 tanh 激活函数进行计算,得到该神经元你的输出。
2、【掌握】PyTorch RNN API
RNN = torch.nn.RNN(input_size,hidden_size,num_layer)
参数意义是:
input_size:输入数据的维度,一般设为词向量的维度;
hidden_size:隐藏层h的维数,也是当前层神经元的输出维度;
num_layer: 隐藏层h的层数,默认为1.
output, hn = RNN(x, h0)
**输入数据:**输入主要包括词嵌入的x 、初始的隐藏层h0
x的表示形式为seq_len, batch, input_size,即句子的长度,batch的大小,词向量的维度
h0的表示形式为num_layers, batch, hidden_size,即隐藏层的层数,batch的大,隐藏层h的维数
输出结果:主要包括输出结果output,最后一层的hn
output的表示形式与输入x类似,为seq_len, batch, hidden_size,即句子的长度,batch的大小,输出向量的维度
hn的表示形式与输入h0一样,为num_layers, batch, hidden_size,即隐藏层的层数,batch的大,隐藏层h的维度
python
from torch import nn
import torch
# 构建层
layer_rnn = nn.RNN(input_size=108, hidden_size=256, num_layers=1)
# 构建数据
inputs = torch.randn(5, 32, 108)
h0 = torch.zeros([1, 32, 256])
# 获取输出
y, hn = layer_rnn(inputs, h0)
print("输出向量的维度:\n", y.shape)
print("隐含层输出的维度:\n", hn.shape)
'''
输出:
输出向量的维度:
torch.Size([5, 32, 256])
隐含层输出的维度:
torch.Size([1, 32, 256])
'''3、【了解】使用场景
- 语言建模与文本生成: 通过理解先前词汇的上下文来预测句子中的下一个词,或根据初始词语逐步生成文本。
- 机器翻译: 分析输入句子的序列和结构,正确用另一种语言组织词句(多对多架构)。
- 语音识别: 处理连续的音频数据流,理解口语语言的细微差别和时间依赖关系,将语音转换为文本。
- 时间序列预测: 识别并记住随时间变化的模式(如股票价格、天气模式),用于趋势分析和异常检测。
- 情感分析: 考虑词汇序列来确定文本的情感倾向(多对一架构)
四、文本生成案例
① emb 嵌入层的输出为什么是 batch_size,seq_len,input_size
嵌入层输入的数据是x,对应的维度是 batch_size, seq_len
对每个元素向量化,得到的结果维度是 batch_size, seq_len, embedding_dim
② rnn层的输入为什么是 seq_len,batch_size,input_size(输入特征维度)?
在初始化rnn是,默认是seq_len first模式,模型输入在内存中是**先存储所有序列的第一个时间步单元,然后存储第二个时间步单元。**rnn处理时会按照时间步取遍历处理输出的x
输出为seq_len,batch_size,隐藏状态维度
③ 全连接层的输入为什么是batch_size\*seq_len, 隐藏状态维度?
全连接层接收的数据是 样本个数,特征数(或上一层输出)
样本个数等于:batch_size*seq_len
全连接层的输出为:分类个数(所有可能的字符个数)
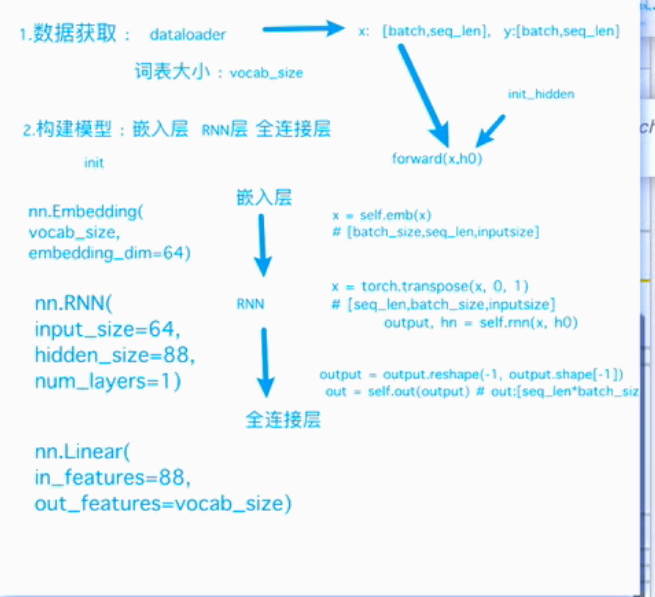
实现步骤:
1、数据处理
1.1 分词(jieba)
1.2 分词结果去重,生成列表
1.3 id_to_word: 本质是一个列表,可以根据输入的id得到对应的word
1.4 word_to_id: 本质是一个字典{word:id},可以根据输入的word得到id
words_to_id = {words: id for id, words in enumerate(id_to_words)} #enumerate 枚举,会生成对应id,word
1.5 将去重后的 word列表,转换为id存储
2、创建dataset
1.1 需继承torch.utils.data.Dataset,包含三个方法: init、getitem、len(分组个数)
1.2 init(self, vocal_dict, seq_len): 初始化构成x、y值的相关参数
1.3 getitem(self, idx): 规定x、y范围,返回x,y值
1.4 def len(self): 规定句子总数,创建模型会自动读取
注:x = self.vocal_dictstart: start + self.sentence_len, y = self.vocal_dictstart + 1: start + 1 + self.sentence_len
self.word_count - self.word_count - 1 > start
- 模型构建
3.1 继承 torch.nn.Module
3.2 init(self, word_count):定义每一层的上一层、本层有多少神经元
3.3 forward(self, x, h0):数据传入、添加激活函数
3.4 初始化 h0
- 模型训练
4.1 数据加载:Dataset、Dataloader
4.2 模型定义
4.3 损失函数、优化器
4.4 循环eopces、批次
4.5 模型预测
4.6 计算损失
4.7 反向传播:梯度清零、计算梯度(loss.backward())、更新梯度
4.8 模型保存
- 模型预测
5.1 模型加载:加载已经训练权重参数
5.2 预测
5.3 预测结果转译为文字
代码实现:
python
import time
import jieba
import torch
from torch.utils.data import DataLoader
from torch.nn import Embedding, RNN, Linear, CrossEntropyLoss
# 数据处理
def build_vocab():
# 数据读取
with open(file=r'./data/jaychou_lyrics.txt', mode="r", encoding="UTF-8") as f:
text = f.readlines()
# print(text)
all_words = []
for line in text:
words = jieba.lcut(line)
all_words.extend(words)
words_set = set(all_words)
# print(len(words_set))
# print(words_set)
id_to_words = list(words_set)
words_to_id = {words: id for id, words in enumerate(id_to_words)}
# print(words2id)
# 将为去重的数据转换id
vocal_dict = []
for word in all_words:
vocal_dict.append(words_to_id[word])
return vocal_dict, len(words_set), id_to_words, words_to_id
# 构建训练数据集对象,dataset
class CreateDataset(torch.utils.data.Dataset):
def __init__(self, vocal_dict, seq_len):
# 语料
self.vocal_dict = vocal_dict
# 句子长度
self.sentence_len = seq_len
# 语料中分词个数
self.word_count = len(self.vocal_dict)
# 句子个数
self.sentence_num = self.word_count // self.sentence_len
def __getitem__(self, idx):
# idx指词的索引,并将其修正索引值到文档的范围里面
start = min(max(idx, 0), self.word_count - self.sentence_num - 2)
# 输入值
x = self.vocal_dict[start: start + self.sentence_len]
# 网络预测结果(目标值)
y = self.vocal_dict[start + 1: start + 1 + self.sentence_len]
# 返回结果
return torch.tensor(x), torch.tensor(y)
def __len__(self):
return self.sentence_num
# 模型构建
class BuildModel(torch.nn.Module):
def __init__(self, word_count):
super().__init__()
# 嵌入层
self.emb = Embedding(num_embeddings=word_count, embedding_dim=128)
# rnn层
self.rnn = RNN(input_size=128, hidden_size=64)
# 全连接层
self.out = Linear(in_features=64, out_features=word_count)
def forward(self, x, h0):
# 嵌入层,输入是 ((batch_size, seq_len)
emb_out = self.emb(x) # 输出(batch_size, seq_len,embedding_dim=128)
# rnn: 输入维度: (seq_len, batch,词向量维度 128)
output, hn = self.rnn(emb_out.permute(1, 0, 2), h0)
# print("output:", output.shape)
# Linear :输入维度: (seq_len*batch,隐藏状态维度 ) 输出维度: (seq_len*batch,wordcount)
out = self.out(output.reshape(-1, output.shape[-1]))
return out, hn
def init_hidden(self, batch_size):
# [num_layer,batch_size,hidden_size]
return torch.zeros([1, batch_size, 64])
def train_model():
# 数据
vocal_dict, word_count, id_to_words, words_to_id = build_vocab()
dataset = CreateDataset(vocal_dict=vocal_dict, seq_len=5)
dataloader = DataLoader(dataset=dataset, batch_size=3, shuffle=True)
# 模型
model = BuildModel(word_count)
# 损失函数、优化器
error = CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001, betas=(0.9, 0.95))
# 遍历
epochs = 3
for epoch in range(epochs):
loss_sum = 0
iter_num = 0.01
start_time = time.time()
for x, y in dataloader:
# 预测
h0 = model.init_hidden(batch_size=y.shape[0])
y_pred, hn = model(x, h0)
# 计算损失
y = torch.permute(y, (1, 0)).reshape(-1)
loss = error(y_pred, y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
break
print(f"epoch:{epoch},loss:{loss/iter_num},time:{time.time()-start_time}")
# 保存模型
torch.save(model.state_dict(),r'./data/model.pth')
def predict(start_word, word_num):
vocal_dict, word_count, id_to_words, words_to_id = build_vocab()
# print(words_to_id)
# 模型加载
weight = torch.load(r'./data/model.pth')
model = BuildModel(word_count)
model.load_state_dict(weight)
# 预测
idx = words_to_id[start_word]
hidden = model.init_hidden(batch_size=1)
get_idx = [idx]
for i in range(word_num):
output, hidden = model(torch.tensor([[idx]]), hidden)
idx = torch.argmax(output)
get_idx.append(idx)
for idx in get_idx:
print(id_to_words[idx], end='')
if __name__ == '__main__':
train_model()
predict(start_word='另一端', word_num=20)
# 输出: 另一端雨刷脸颊微热楼第七所谓无人雾茫茫面向你加三分球驾驭淘汰夜色烟味难过沦落三对森林雾茫茫