
LDPC码入门
原文:An Introduction to LDPC Codes
日期:2003年8月19日
译者注:本文为LDPC码领域的经典综述教程
摘要
低密度奇偶校验(LDPC)码是一类线性分组码,在大量数据传输和存储信道上都能提供接近信道容量的性能。本文提供了LDPC码学习和实践的基础,涵盖基本表示方法(奇偶校验矩阵和Tanner图)、LDPC码集合分类、设计方法、编码问题以及迭代消息传递译码算法。
1. 引言
低密度奇偶校验(LDPC)码是一类线性分组码,在大量数据传输和存储信道上都能提供接近信道容量的性能,同时还具有可实现的译码器。LDPC码最早由Gallager在其1960年的博士论文1中提出,但在此后的35年间几乎无人问津。一个值得注意的例外是Tanner在1981年的重要工作2,其中Tanner推广了LDPC码,并引入了一种称为Tanner图的LDPC码图形表示方法。LDPC码的研究在20世纪90年代中期得以复兴,MacKay、Luby等人的工作345重新发现了(显然独立于Gallager的工作)具有稀疏(低密度)奇偶校验矩阵的线性分组码的优势。
本教程章节为LDPC码的学习和实践奠定基础。我们将从LDPC码的基本表示方法开始,包括奇偶校验矩阵和Tanner图。将介绍通过Tanner图度分布对LDPC码集合进行分类的方法,但我们将仅浅层次地介绍通过约束伪随机矩阵构造来设计具有最优度分布的LDPC码。我们还将回顾文献中出现的其他一些LDPC码构造技术。将介绍此类LDPC码的编码问题,并引入解决该编码问题的某些特殊类别的LDPC码。最后,将介绍迭代消息传递译码算法(及其某些简化形式),该算法能够提供接近最优的性能。
本工作由NSF基金CCR-9814472和CCR-9979310、NASA基金NAG5-10643以及INSIC EHDR项目的资助完成。
2. LDPC码的表示
2.1. 矩阵表示
尽管LDPC码可以推广到非二进制字母表,但为简单起见,我们仅考虑二进制LDPC码。由于LDPC码构成一类线性分组码,它们可以被描述为在二进制域 F2\mathbb{F}2F2 上的二元 nnn 元组向量空间 F2n\mathbb{F}2^nF2n 的某个 kkk 维子空间 CCC。基于此,我们可以找到一个张成 CCC 的基 B={g0,g1,...,gk−1}B = \{g_0, g_1, \ldots, g{k-1}\}B={g0,g1,...,gk−1},使得每个 c∈Cc \in Cc∈C 可以写成 c=u0g0+u1g1+⋯+uk−1gk−1c = u_0g_0 + u_1g_1 + \cdots + u{k-1}g_{k-1}c=u0g0+u1g1+⋯+uk−1gk−1,其中 {ui}\{u_i\}{ui} 为某些取值;更紧凑地,c=uGc = uGc=uG,其中 u=u0 u1 ... uk−1u = u_0\\; u_1\\; \\ldots\\; u_{k-1}u=u0u1...uk−1,GGG 是所谓的 k×nk \times nk×n 生成矩阵 ,其行向量为 {gi}\{g_i\}{gi}(按照编码中的惯例,所有向量均为行向量)。GGG 的 (n−k)(n-k)(n−k) 维零空间 C⊥C^\perpC⊥ 由所有满足 xGT=0xG^T = 0xGT=0 的向量 x∈F2nx \in \mathbb{F}2^nx∈F2n 组成,并由基 B⊥={h0,h1,...,hn−k−1}B^\perp = \{h_0, h_1, \ldots, h{n-k-1}\}B⊥={h0,h1,...,hn−k−1} 张成。因此,对于每个 c∈Cc \in Cc∈C,chiT=0ch_i^T = 0chiT=0 对所有 iii 成立,或更紧凑地,cHT=0cH^T = 0cHT=0,其中 HHH 是所谓的 (n−k)×n(n-k) \times n(n−k)×n 奇偶校验矩阵 ,其行向量为 {hi}\{h_i\}{hi},是零空间 C⊥C^\perpC⊥ 的生成矩阵。HHH 之所以被称为奇偶校验矩阵,是因为它对接收到的码字执行 m=n−km = n-km=n−k 个独立的奇偶校验。
低密度奇偶校验码是一种线性分组码,其奇偶校验矩阵 HHH 中 1 的密度很低。规则LDPC码 是一种线性分组码,其奇偶校验矩阵 HHH 中每列恰好包含 wcw_cwc 个 1,每行恰好包含 wr=wc(n/m)w_r = w_c(n/m)wr=wc(n/m) 个 1,其中 wc≪mw_c \ll mwc≪m(等价地,wr≪nw_r \ll nwr≪n)。码率 R=k/nR = k/nR=k/n 通过这些参数相关联:
R=1−wcwrR = 1 - \frac{w_c}{w_r}R=1−wrwc
(这里假设 HHH 是满秩的)。如果 HHH 是低密度的,但每列或每行中 1 的数量不恒定,则该码为非规则LDPC码。通过其图形表示,最容易看出LDPC码是规则的还是非规则的。
2.2. 图形表示
Tanner研究了LDPC码(及其推广形式),并展示了如何通过所谓的二分图 有效地表示它们,现在称为 Tanner图 2。LDPC码的Tanner图类似于卷积码的网格图,因为它提供了码的完整表示,并有助于描述译码算法。二分图是一种图(由边连接的节点),其节点可以分为两种类型,边只能连接不同类型的两个节点。Tanner图中的两种节点类型是变量节点 和校验节点 (我们分别称之为 v-node 和 c-node )。Tanner图按照以下规则绘制:当 HHH 中的元素 hji=1h_{ji} = 1hji=1 时,校验节点 fjf_jfj 与变量节点 iii 相连。由此可以推断,有 m=n−km = n-km=n−k 个校验节点(每个校验方程对应一个),nnn 个变量节点(每个码位 cic_ici 对应一个)。此外,HHH 的 mmm 行指定了 mmm 个 c-node 的连接,HHH 的 nnn 列指定了 nnn 个 v-node 的连接。
文献中的术语有所不同:变量节点也称为比特节点 或符号节点 ,校验节点也称为函数节点。
示例。 考虑一个 (10,5)(10, 5)(10,5) 线性分组码,wc=2w_c = 2wc=2,wr=wc(n/m)=4w_r = w_c(n/m) = 4wr=wc(n/m)=4,其 HHH 矩阵如下:
[1 1 1 1 0 0 0 0 0 0]
[1 0 0 0 1 1 1 0 0 0]
H = [0 1 0 0 1 0 0 1 1 0]
[0 0 1 0 0 1 0 1 0 1]
[0 0 0 1 0 0 1 0 1 1]HHH 对应的Tanner图如图1所示。可以观察到,v-node c0,c1,c2,c3c_0, c_1, c_2, c_3c0,c1,c2,c3 与 c-node f0f_0f0 相连,这是因为 HHH 的第 0 行中 h00=h01=h02=h03=1h_{00} = h_{01} = h_{02} = h_{03} = 1h00=h01=h02=h03=1(其余为零)。类似地,c-node f1,f2,f3,f4f_1, f_2, f_3, f_4f1,f2,f3,f4 分别对应 HHH 的第 1、2、3、4 行。注意,由于 cHT=0cH^T = 0cHT=0,连接到同一校验节点的比特值之和(模 2)必须为零。我们也可以沿列方向构造Tanner图。例如,v-node c0c_0c0 与 c-node f0f_0f0 和 f1f_1f1 相连,这是因为 HHH 的第 0 列中 h00=h10=1h_{00} = h_{10} = 1h00=h10=1。
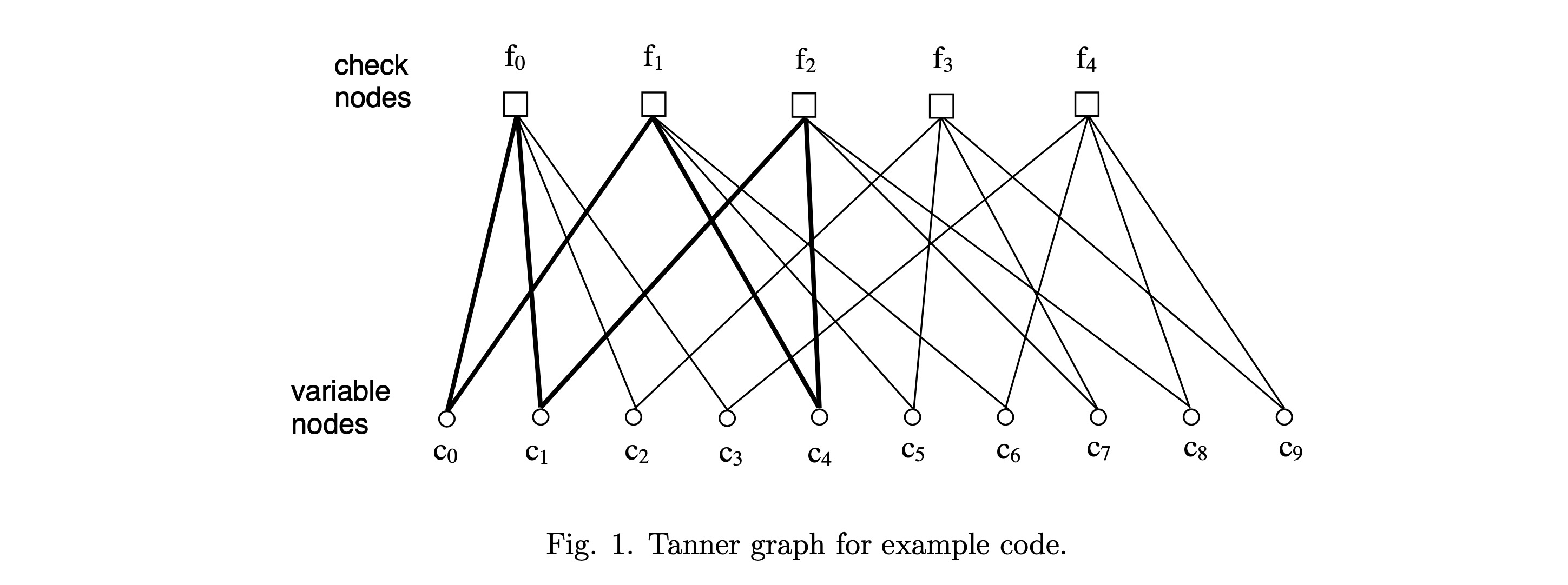
图1. 示例码的Tanner图
注意,此示例中的Tanner图是规则 的:每个 v-node 有 2 条边连接,每个 c-node 有 4 条边连接(即每个 v-node 的度为 2,每个 c-node 的度为 4)。这与 wc=2w_c = 2wc=2 和 wr=4w_r = 4wr=4 的事实一致。从这个例子也可以清楚地看出 mwr=nwcmw_r = nw_cmwr=nwc。
对于非规则LDPC码,参数 wcw_cwc 和 wrw_rwr 是列号和行号的函数,因此在这种情况下通常不采用这种表示方法。相反,文献中(按照7的做法)通常指定 v-node 和 c-node 的度分布多项式 ,分别记为 λ(x)\lambda(x)λ(x) 和 ρ(x)\rho(x)ρ(x)。在多项式
λ(x)=∑d=1dvλdxd−1\lambda(x) = \sum_{d=1}^{d_v} \lambda_d x^{d-1}λ(x)=d=1∑dvλdxd−1
中,λd\lambda_dλd 表示连接到度为 ddd 的 v-node 的所有边的比例,dvd_vdv 表示最大的 v-node 度。类似地,在多项式
ρ(x)=∑d=1dcρdxd−1\rho(x) = \sum_{d=1}^{d_c} \rho_d x^{d-1}ρ(x)=d=1∑dcρdxd−1
中,ρd\rho_dρd 表示连接到度为 ddd 的 c-node 的所有边的比例,dcd_cdc 表示最大的 c-node 度。注意,对于上述规则码,wc=dv=2w_c = d_v = 2wc=dv=2 且 wr=dc=4w_r = d_c = 4wr=dc=4,我们有 λ(x)=x\lambda(x) = xλ(x)=x(因为 λ2=1\lambda_2 = 1λ2=1)和 ρ(x)=x3\rho(x) = x^3ρ(x)=x3(因为 ρ4=1\rho_4 = 1ρ4=1)。
Tanner图中的环 (或回路)是由 lll 条边组成并自身闭合的路径。上述示例中的Tanner图具有长度为 6 的环。Tanner图的围长 ggg 是图中最短环的长度。二分图中最短的可能环显然是长度为 4 的环,这类环在 HHH 矩阵中表现为四个 1 位于 HHH 的某个子矩阵的角上。我们关注环,特别是短环,因为它们会降低用于LDPC码的迭代译码算法的性能。
3. LDPC码设计方法
3.1. Gallager码
Gallager提出的原始LDPC码1是规则LDPC码,其 HHH 矩阵由 jjj 个子矩阵垂直堆叠而成:
H=H1H2⋮HjH = \begin{bmatrix} H_1 \\ H_2 \\ \vdots \\ H_j \end{bmatrix}H= H1H2⋮Hj
其中每个子矩阵 HiH_iHi 具有以下结构。对于任意大于 1 的整数 jjj 和 wcw_cwc,每个子矩阵 HiH_iHi 是 p×(p⋅wr)p \times (p \cdot w_r)p×(p⋅wr) 的,行权重为 wrw_rwr,列权重为 1。子矩阵 H1H_1H1 具有以下特定形式:对于 i=1,2,...,pi = 1, 2, \ldots, pi=1,2,...,p,第 iii 行的 wrw_rwr 个 1 全部位于列 (i−1)wr+1(i-1)w_r + 1(i−1)wr+1 到 iwriw_riwr 中。其他子矩阵只是 H1H_1H1 的列置换。显然,HHH 是规则的,维度为 jp×pwrjp \times pw_rjp×pwr,行权重和列权重分别为 wrw_rwr 和 wcw_cwc(=j=j=j)。HHH 中不存在长度为 4 的环并不能得到保证,但可以通过计算机设计来避免。Gallager证明,这类码的集合具有优异的距离特性,前提是 wc≥3w_c \geq 3wc≥3 且 wr>wcw_r > w_cwr>wc。此外,这类码具有低复杂度的编码器,因为校验位可以作为用户位的函数通过奇偶校验矩阵求解1。
3.2. MacKay码
MacKay独立发现了设计具有稀疏 HHH 矩阵的二进制码的优势,并提出了一系列半随机生成稀疏 HHH 矩阵的算法34,按复杂度递增排序如下:
- 随机生成权重为 wcw_cwc 的列,并(尽可能)使行权重均匀。
- 随机生成权重为 wcw_cwc 的列,同时确保行权重为 wrw_rwr,且任意两列的重叠不超过 1。
- 在第 2 类的基础上,避免短环。
- 在第 3 类的基础上,约束 H=H1∣H2H = H_1 \| H_2H=H1∣H2 使得 H2H_2H2 可逆(或至少 HHH 满秩)。
MacKay码的一个缺点是它们缺乏足够的结构来实现低复杂度编码。编码需要通过高斯消元将 HHH 化为 PT∣IP\^T \| IPT∣I 的形式,从而将生成矩阵化为系统形式 G=I∣PG = I \| PG=I∣P。问题在于通过 GGG 进行编码时,子矩阵 PPP 通常不是稀疏的,因此当码长 n≥1000n \geq 1000n≥1000 时,编码复杂度较高。
3.3. 基于密度进化的非规则码设计
Richardson等人7和Luby等人8定义了由度分布多项式 λ(x)\lambda(x)λ(x) 和 ρ(x)\rho(x)ρ(x) 参数化的非规则LDPC码集合,并展示了如何针对各种信道优化这些多项式。最优性 的含义是:假设采用消息传递译码(见下文),集合中的典型码能够在比集合外码更恶劣的信道条件下实现可靠通信。最恶劣的信道条件称为译码门限 ,而 λ(x)\lambda(x)λ(x) 和 ρ(x)\rho(x)ρ(x) 的优化通过所谓的密度进化 算法和优化算法的组合来实现。密度进化 指的是跟踪译码器Tanner图中传递的各种量的概率密度函数(pdf)的演变。给定一对 λ(x)\lambda(x)λ(x)-ρ(x)\rho(x)ρ(x),其译码门限通过计算码比特的对数似然比(见下一节)的pdf来确定。分离优化算法在 λ(x)\lambda(x)λ(x)-ρ(x)\rho(x)ρ(x) 对上优化。使用这种方法,已设计出性能距离二进制输入AWGN信道的容量限仅 0.045 dB 的非规则LDPC码11。该码长度 n=107n = 10^7n=107,码率 R=1/2R = 1/2R=1/2。
通常,通过密度进化设计的方法最适用于码率不太高(R<3/4R < 3/4R<3/4)且长度不太短(n≥5000n \geq 5000n≥5000)的码。原因是密度进化设计算法假设 n→∞n \to \inftyn→∞(因此 m→∞m \to \inftym→∞),因此对于非常长的码最优的 λ(x)\lambda(x)λ(x)-ρ(x)\rho(x)ρ(x) 对,对于中等长度和短码将不是最优的。如12131415所讨论的,将这些 λ(x)\lambda(x)λ(x)-ρ(x)\rho(x)ρ(x) 对应用于中等长度和短码会导致较高的误码率平台。最后,与MacKay码一样,这些非规则码在本质上不便于高效编码。然而,Richardson和Urbanke6已提出了实现这些码线性时间编码的算法。
3.4. 有限几何码
在1617中,使用基于有限几何的经典代数技术18设计了规则LDPC码。所得的LDPC码属于分组码的循环和准循环类别,可通过移位寄存器电路实现简单的编码器。循环有限几何码往往具有相对较大的最小距离,但准循环码的最小距离往往较小。循环有限几何码的一个缺点是,用于译码的奇偶校验矩阵是 n×nn \times nn×n 而非 (n−k)×n(n-k) \times n(n−k)×n。另一个缺点是 wcw_cwc 和 wrw_rwr 的值相对较大,这是不理想的,因为迭代消息传递译码器的复杂度与这些值成正比。
3.5. RA、IRA和eIRA码
重复累积(RA)码 20具有串行turbo码和LDPC码的双重特性。RA码的编码器中,用户比特被重复(通常重复 2 或 3 次),然后经过置换,最后送入累加器(差分编码器)。这些码能够接近容量限工作,但自然码率较低(码率 1/21/21/2 或更低)。
非规则重复累积(IRA)码21是RA码的推广,其中某些比特比其他比特重复更多次。IRA编码器包含一个低密度生成矩阵、一个置换器和一个累加器。这类码允许更高的码率,但名义上是非系统码。
扩展IRA(eIRA)码 13141522是一类可高效编码的非规则LDPC码。eIRA编码器是系统的,允许低码率和高码率。编码可以直接从 HHH 矩阵高效地进行,HHH 矩阵具有一个 m×mm \times mm×m 子矩阵,便于从用户比特计算校验位。
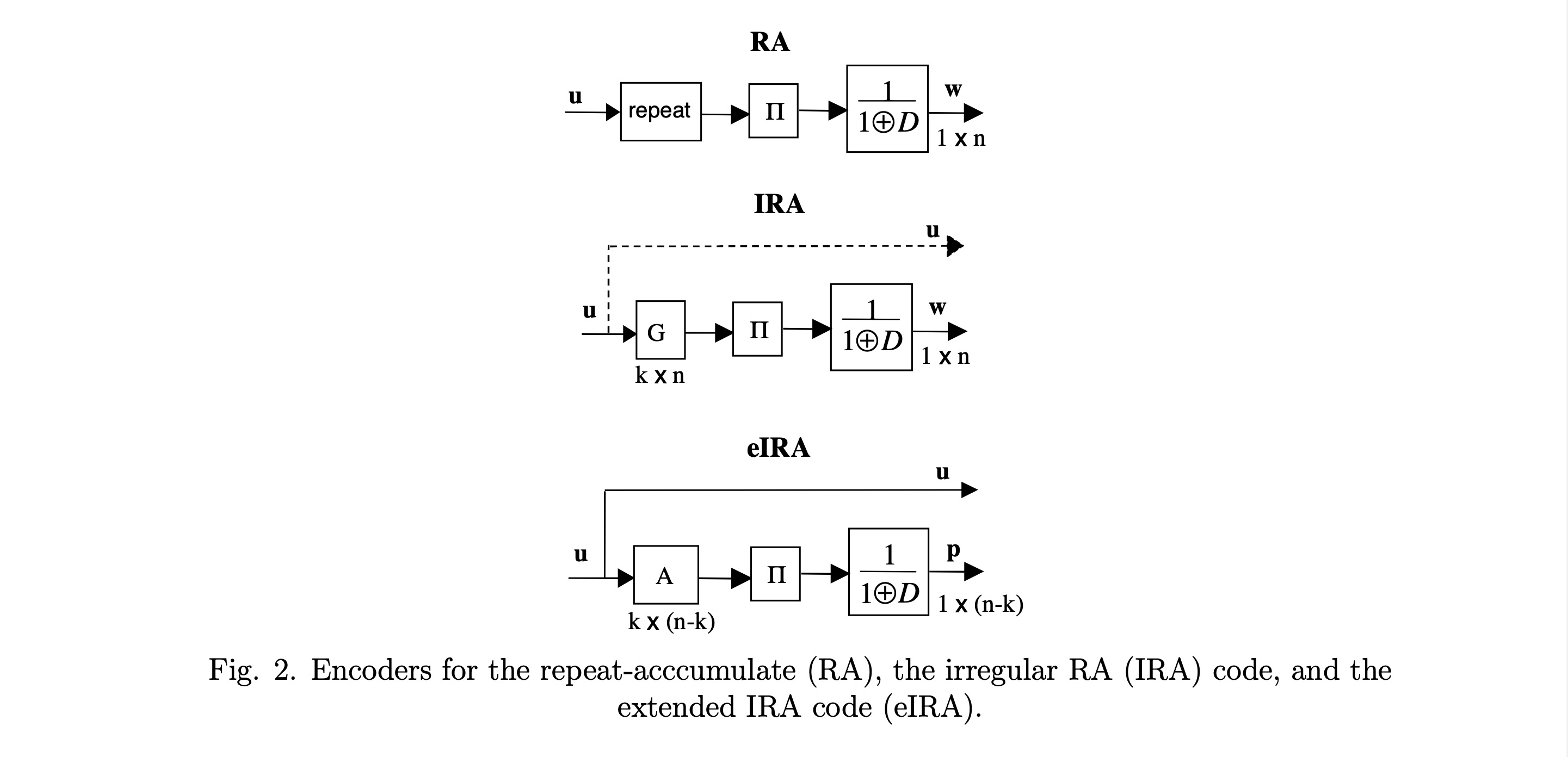
图2. 重复累积(RA)码、非规则RA(IRA)码和扩展IRA码(eIRA)的编码器。
3.6. 阵列码
某类称为阵列码 的码可以被视为LDPC码2324。改进阵列码采用以下 HHH 矩阵格式25:
H=III⋯I0αα2⋯αk−1⋮⋮⋮⋱⋮0αj−1α2(j−1)⋯α(k−1)(j−1)H = \begin{bmatrix} I & I & I & \cdots & I \\ 0 & \alpha & \alpha^2 & \cdots & \alpha^{k-1} \\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & \alpha^{j-1} & \alpha^{2(j-1)} & \cdots & \alpha^{(k-1)(j-1)} \end{bmatrix}H= I0⋮0Iα⋮αj−1Iα2⋮α2(j−1)⋯⋯⋱⋯Iαk−1⋮α(k−1)(j−1)
其中 kkk 和 jjj 是两个整数,满足 k,j≤pk, j \leq pk,j≤p,ppp 表示一个素数。III 是 p×pp \times pp×p 单位矩阵,000 是 p×pp \times pp×p 零矩阵,α\alphaα 是表示单次左移或右移循环置换的 p×pp \times pp×p 置换矩阵。HHH 的上三角性质保证了编码在码字长度上是线性的。
3.7. 组合LDPC码
好的LDPC码可以通过组合数学的应用来设计。设计约束(如没有长度为 4 的环)应用于 (n−k)×n(n-k) \times n(n−k)×n 的 HHH 矩阵可以被表述为一个组合问题。几位研究人员已经通过Steiner系统、Kirkman系统和平衡不完全区组设计(BIBD)等组合对象成功解决了这个问题2627282916。
图3. H矩阵第0列为{1 1 1 0 0...0}ᵀ的Tanner图的子图。箭头表示从节点c₀到节点f₀的消息传递。
4. 迭代译码算法
4.1. 概述
Gallager除了在其开创性工作1中引入LDPC码外,还提供了一种通常接近最优的译码算法。该算法迭代计算基于图的模型中变量的分布,根据上下文有不同的名称,包括:和积算法(SPA) 、置信传播算法(BPA) 和 消息传递算法(MPA)。术语"消息传递"通常指所有这类迭代算法。
与网格码的最优(最大后验概率,MAP)逐符号译码类似,我们感兴趣的是计算给定比特在发送码字 c=c0 c1 ... cn−1c = c_0\\; c_1\\; \\ldots\\; c_{n-1}c=c0c1...cn−1 中等于 1 的后验概率(APP),给定接收到的字 y=y0 y1 ... yn−1y = y_0\\; y_1\\; \\ldots\\; y_{n-1}y=y0y1...yn−1。不失一般性,让我们关注比特 cic_ici 的译码:
Pr(ci=1∣y)\Pr(c_i = 1 \mid y)Pr(ci=1∣y)
或 APP 比(也称为似然比,LR):
l(ci)=Pr(ci=0∣y)Pr(ci=1∣y)l(c_i) = \frac{\Pr(c_i = 0 \mid y)}{\Pr(c_i = 1 \mid y)}l(ci)=Pr(ci=1∣y)Pr(ci=0∣y)
稍后我们将扩展到更数值稳定的对数APP比的计算,也称为对数似然比(LLR):
L(ci)=logl(ci)L(c_i) = \log l(c_i)L(ci)=logl(ci)
其中假设使用自然对数。
用于计算 Pr(ci=1∣y)\Pr(c_i = 1 \mid y)Pr(ci=1∣y)、l(ci)l(c_i)l(ci) 或 L(ci)L(c_i)L(ci) 的MPA是一种基于码的Tanner图的迭代算法。具体来说,v-node 代表一类处理器,c-node 代表另一类处理器,边代表消息路径。在半次迭代中,每个 v-node 处理其输入消息,并将结果输出消息传递给相邻的 c-node。在另一次半迭代中,每个 c-node 处理其输入消息,并将结果输出消息传递给相邻的 v-node。关键原则是只传递外信息(extrinsic information),即不包含来自接收节点的信息。
在规定的最大迭代次数之后,或者在满足某个停止准则(如 c^HT=0\hat{c}H^T = 0c^HT=0)之后,译码器根据计算出的APP、LR或LLR做出硬判决。
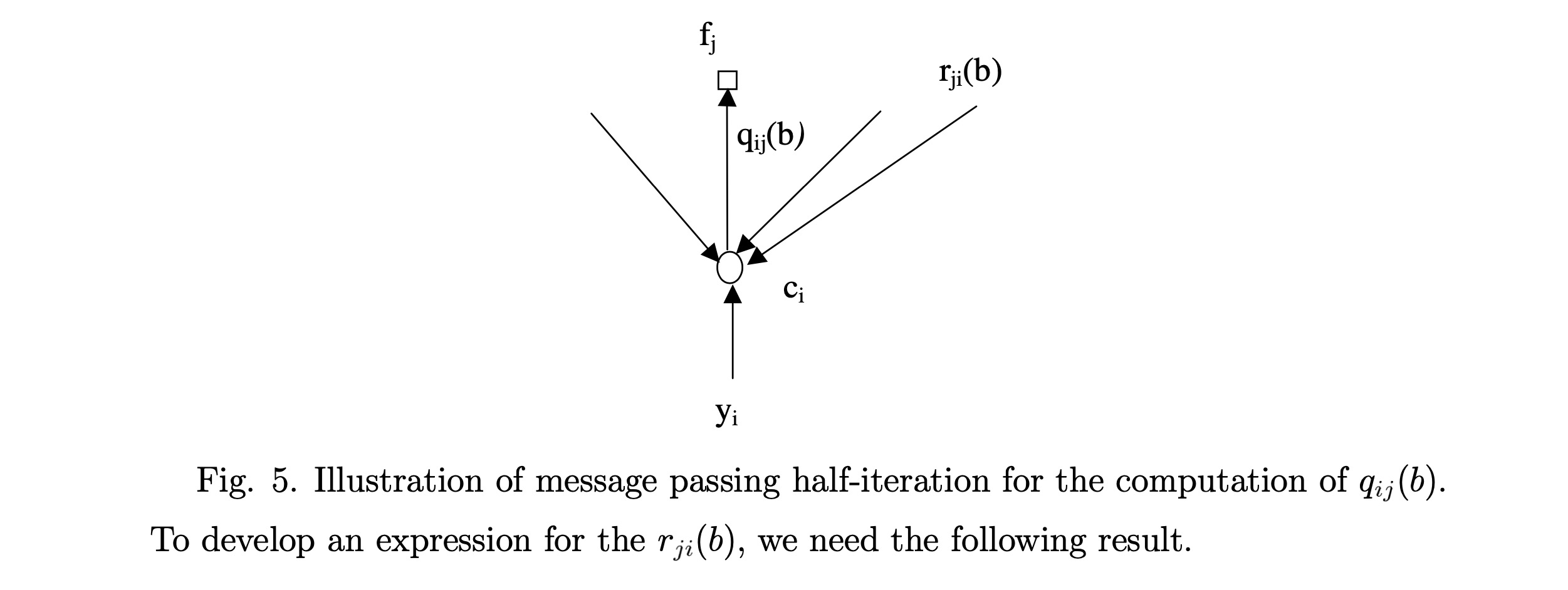
图5. 对应于H矩阵第0列为{1 1 1 0 0...0}ᵀ的Tanner图的子图。箭头表示消息从c-node传递到v-node。
4.2. 概率域SPA译码器
现在我们介绍概率域SPA译码器。令 ViV_iVi 表示连接到 v-node cic_ici 的 c-node 索引集合,CjC_jCj 表示连接到 c-node fjf_jfj 的 v-node 索引集合。Vi∖jV_i \setminus jVi∖j 表示 ViV_iVi 去掉元素 jjj,Cj∖iC_j \setminus iCj∖i 表示 CjC_jCj 去掉元素 iii。
初始化: 对于所有满足 hji=1h_{ji} = 1hji=1 的 i,ji, ji,j:
qij(1)=Pi=Pr(ci=1∣yi),qij(0)=1−Piq_{ij}(1) = P_i = \Pr(c_i = 1 \mid y_i), \quad q_{ij}(0) = 1 - P_iqij(1)=Pi=Pr(ci=1∣yi),qij(0)=1−Pi
Step 1(校验节点更新)。 利用以下结果(Gallager1):
结果 1. 考虑 MMM 个独立二进制数字 aia_iai,满足 Pr(ai=1)=pi\Pr(a_i = 1) = p_iPr(ai=1)=pi。则 {ai}i=1M\{a_i\}_{i=1}^M{ai}i=1M 中包含偶数个 1 的概率为:
12+12∏i=1M(1−2pi)\frac{1}{2} + \frac{1}{2} \prod_{i=1}^{M} (1 - 2p_i)21+21i=1∏M(1−2pi)
结合 pi↔qij(1)p_i \leftrightarrow q_{ij}(1)pi↔qij(1) 的对应关系,我们有:
rji(0)=12+12∏i′∈Cj∖i(1−2qi′j(1))(4.4)r_{ji}(0) = \frac{1}{2} + \frac{1}{2} \prod_{i' \in C_j \setminus i} \bigl(1 - 2q_{i'j}(1)\bigr) \tag{4.4}rji(0)=21+21i′∈Cj∖i∏(1−2qi′j(1))(4.4)
rji(1)=1−rji(0)(4.5)r_{ji}(1) = 1 - r_{ji}(0) \tag{4.5}rji(1)=1−rji(0)(4.5)
Step 2(变量节点更新)。 对于每个 v-node cic_ici 和每个 j∈Vij \in V_ij∈Vi:
qij(0)=Kij (1−Pi)∏j′∈Vi∖jrj′i(0)(4.1)q_{ij}(0) = K_{ij}\,(1-P_i) \prod_{j' \in V_i \setminus j} r_{j'i}(0) \tag{4.1}qij(0)=Kij(1−Pi)j′∈Vi∖j∏rj′i(0)(4.1)
qij(1)=Kij Pi∏j′∈Vi∖jrj′i(1)(4.2)q_{ij}(1) = K_{ij}\,P_i \prod_{j' \in V_i \setminus j} r_{j'i}(1) \tag{4.2}qij(1)=KijPij′∈Vi∖j∏rj′i(1)(4.2)
其中常数 KijK_{ij}Kij 确保 qij(0)+qij(1)=1q_{ij}(0) + q_{ij}(1) = 1qij(0)+qij(1)=1。
Step 3(后验概率更新)。
Qi(0)=Ki (1−Pi)∏j∈Virji(0),Qi(1)=Ki Pi∏j∈Virji(1)Q_i(0) = K_i\,(1-P_i) \prod_{j \in V_i} r_{ji}(0), \quad Q_i(1) = K_i\,P_i \prod_{j \in V_i} r_{ji}(1)Qi(0)=Ki(1−Pi)j∈Vi∏rji(0),Qi(1)=KiPij∈Vi∏rji(1)
Step 4(判决)。 对于 i=0,1,...,n−1i = 0, 1, \ldots, n-1i=0,1,...,n−1:
c^i={1若 Qi(1)>Qi(0)0否则\hat{c}_i = \begin{cases} 1 & \text{若 } Q_i(1) > Q_i(0) \\ 0 & \text{否则} \end{cases}c^i={10若 Qi(1)>Qi(0)否则
若 c^HT=0\hat{c}H^T = 0c^HT=0 或迭代次数达到最大限制,则停止;否则返回 Step 1。
备注。 Step 3 可以用除法 qij(b)=Kij′ Qi(b)/rji(b)q_{ij}(b) = K'{ij}\,Q_i(b) / r{ji}(b)qij(b)=Kij′Qi(b)/rji(b) 代替,以减少计算量。
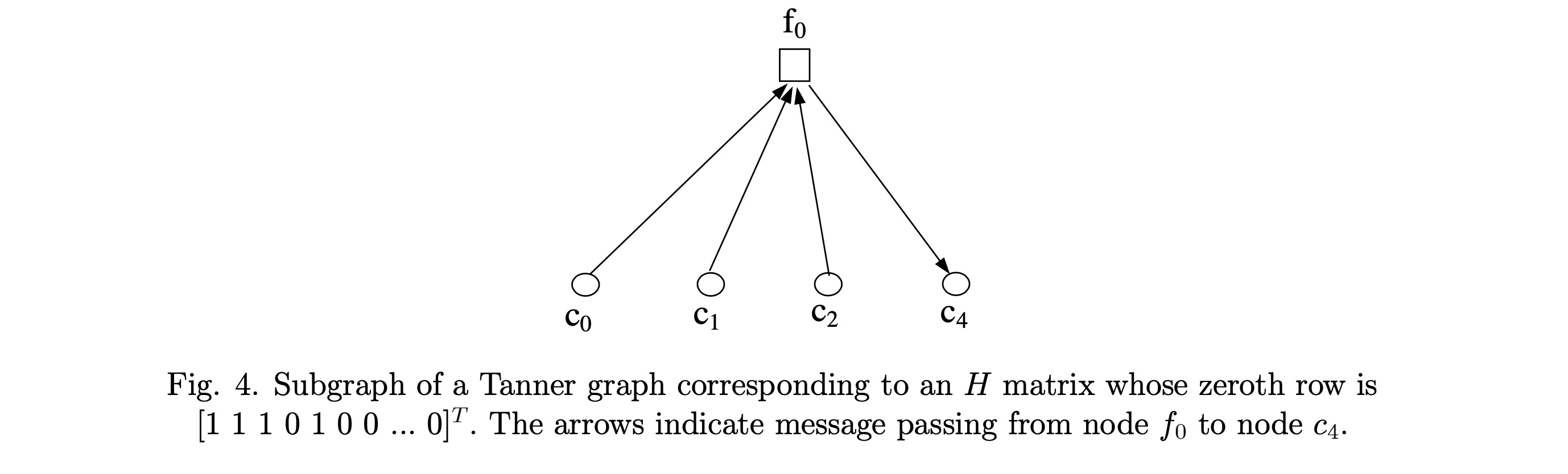
图4. H矩阵第0行为{1 1 1 0 0...0}的Tanner图的子图。箭头表示从节点f₀到节点c₀的消息传递。
4.3. 对数域SPA译码器
由于概率域SPA涉及大量乘法运算,实现起来较为繁琐且可能出现数值不稳定。因此,我们推导一种在对数域中运算的版本131。首先定义以下LLR:
L(qij)=logqij(0)qij(1),L(rji)=logrji(0)rji(1)L(q_{ij}) = \log\frac{q_{ij}(0)}{q_{ij}(1)}, \quad L(r_{ji}) = \log\frac{r_{ji}(0)}{r_{ji}(1)}L(qij)=logqij(1)qij(0),L(rji)=logrji(1)rji(0)
L(Qi)=logQi(0)Qi(1),L(ci)=logPr(ci=0∣yi)Pr(ci=1∣yi)L(Q_i) = \log\frac{Q_i(0)}{Q_i(1)}, \quad L(c_i) = \log\frac{\Pr(c_i=0 \mid y_i)}{\Pr(c_i=1 \mid y_i)}L(Qi)=logQi(1)Qi(0),L(ci)=logPr(ci=1∣yi)Pr(ci=0∣yi)
三种信道下的初始化:
| 信道 | L(ci)L(c_i)L(ci) |
|---|---|
| BEC(擦除概率 δ\deltaδ) | +∞+\infty+∞(yi=0y_i=0yi=0),−∞-\infty−∞(yi=1y_i=1yi=1),000(yi=Ey_i=\mathsf{E}yi=E) |
| BSC( crossover probability ϵ\epsilonϵ) | (−1)yilog1−ϵϵ(-1)^{y_i} \log\frac{1-\epsilon}{\epsilon}(−1)yilogϵ1−ϵ |
| BI-AWGNC(噪声方差 σ2\sigma^2σ2) | 2yi/σ22y_i / \sigma^22yi/σ2 |
Step 1(校验节点更新)。 首先利用 (4.5) 将 rji(0)=1−rji(1)r_{ji}(0) = 1 - r_{ji}(1)rji(0)=1−rji(1) 代入并重排得到:
1−2rji(1)=∏i′∈Cj∖i(1−2qi′j(1))1 - 2r_{ji}(1) = \prod_{i' \in C_j \setminus i} \bigl(1 - 2q_{i'j}(1)\bigr)1−2rji(1)=i′∈Cj∖i∏(1−2qi′j(1))
利用恒等式 tanh 12log(p0/p1)=p0−p1=1−2p1\tanh\!\bigl\\frac{1}{2}\\log(p_0/p_1)\\bigr = p_0 - p_1 = 1 - 2p_1tanh21log(p0/p1)=p0−p1=1−2p1,上式可写为:
tanh (12L(rji))=∏i′∈Cj∖itanh (12L(qi′j))(4.9)\tanh\!\left(\frac{1}{2}L(r_{ji})\right) = \prod_{i' \in C_j \setminus i} \tanh\!\left(\frac{1}{2}L(q_{i'j})\right) \tag{4.9}tanh(21L(rji))=i′∈Cj∖i∏tanh(21L(qi′j))(4.9)
为消除乘积和复杂的 tanh\tanhtanh 函数,将 L(qij)L(q_{ij})L(qij) 分解为符号和幅度1:
L(qij)=αij βij,αij=signL(qij),βij=∣L(qij)∣L(q_{ij}) = \alpha_{ij}\,\beta_{ij}, \quad \alpha_{ij} = \mathrm{sign}\biglL(q_{ij})\\bigr, \quad \beta_{ij} = \bigl|L(q_{ij})\bigr|L(qij)=αijβij,αij=signL(qij),βij= L(qij)
则 (4.9) 变为:
tanh (12L(rji))=∏i′∈Cj∖iαi′j⏟αji⋅tanh (12∑i′∈Cj∖iϕ(βi′j)⏟βji)\tanh\!\left(\frac{1}{2}L(r_{ji})\right) = \underbrace{\prod_{i' \in C_j \setminus i} \alpha_{i'j}}{\displaystyle\alpha{ji}} \cdot \tanh\!\left(\frac{1}{2}\underbrace{\sum_{i' \in C_j \setminus i} \phi(\beta_{i'j})}{\displaystyle\beta{ji}}\right)tanh(21L(rji))=αji i′∈Cj∖i∏αi′j⋅tanh 21βji i′∈Cj∖i∑ϕ(βi′j)
其中定义了函数:
ϕ(x)=−log tanh(x/2)=log ex+1ex−1\phi(x) = -\log\!\bigl\\tanh(x/2)\\bigr = \log\!\frac{e^x + 1}{e^x - 1}ϕ(x)=−logtanh(x/2)=logex−1ex+1
并利用了关键性质 ϕ−1(x)=ϕ(x)\phi^{-1}(x) = \phi(x)ϕ−1(x)=ϕ(x)(当 x>0x > 0x>0 时,ϕ\phiϕ 是它自己的反函数)。由此得到校验节点LLR更新公式:
L(rji)=∏i′∈Cj∖iαi′j⏟符号乘积⋅ ϕ (∑i′∈Cj∖iϕ(βi′j)⏟幅度和)(4.10)L(r_{ji}) = \underbrace{\prod_{i' \in C_j \setminus i} \alpha_{i'j}}{\text{符号乘积}} \cdot \; \phi\!\Bigl(\underbrace{\sum{i' \in C_j \setminus i} \phi(\beta_{i'j})}_{\text{幅度和}}\Bigr) \tag{4.10}L(rji)=符号乘积 i′∈Cj∖i∏αi′j⋅ϕ(幅度和 i′∈Cj∖i∑ϕ(βi′j))(4.10)
函数 ϕ(x)\phi(x)ϕ(x) 如图7所示,可以通过查找表实现。
Step 2(变量节点更新)。 将方程 (4.1) 除以 (4.2) 并取对数:
L(qij)=L(ci)+∑j′∈Vi∖jL(rj′i)(4.11)L(q_{ij}) = L(c_i) + \sum_{j' \in V_i \setminus j} L(r_{j'i}) \tag{4.11}L(qij)=L(ci)+j′∈Vi∖j∑L(rj′i)(4.11)
Step 3(后验LLR更新)。
L(Qi)=L(ci)+∑j∈ViL(rji)(4.12)L(Q_i) = L(c_i) + \sum_{j \in V_i} L(r_{ji}) \tag{4.12}L(Qi)=L(ci)+j∈Vi∑L(rji)(4.12)
Step 4(判决)。 c^i=1\hat{c}_i = 1c^i=1 若 L(Qi)<0L(Q_i) < 0L(Qi)<0,否则 c^i=0\hat{c}_i = 0c^i=0。
备注。 对于BEC和BSC信道,该算法可以进一步简化,因为初始LLR分别是三值的和二值的。
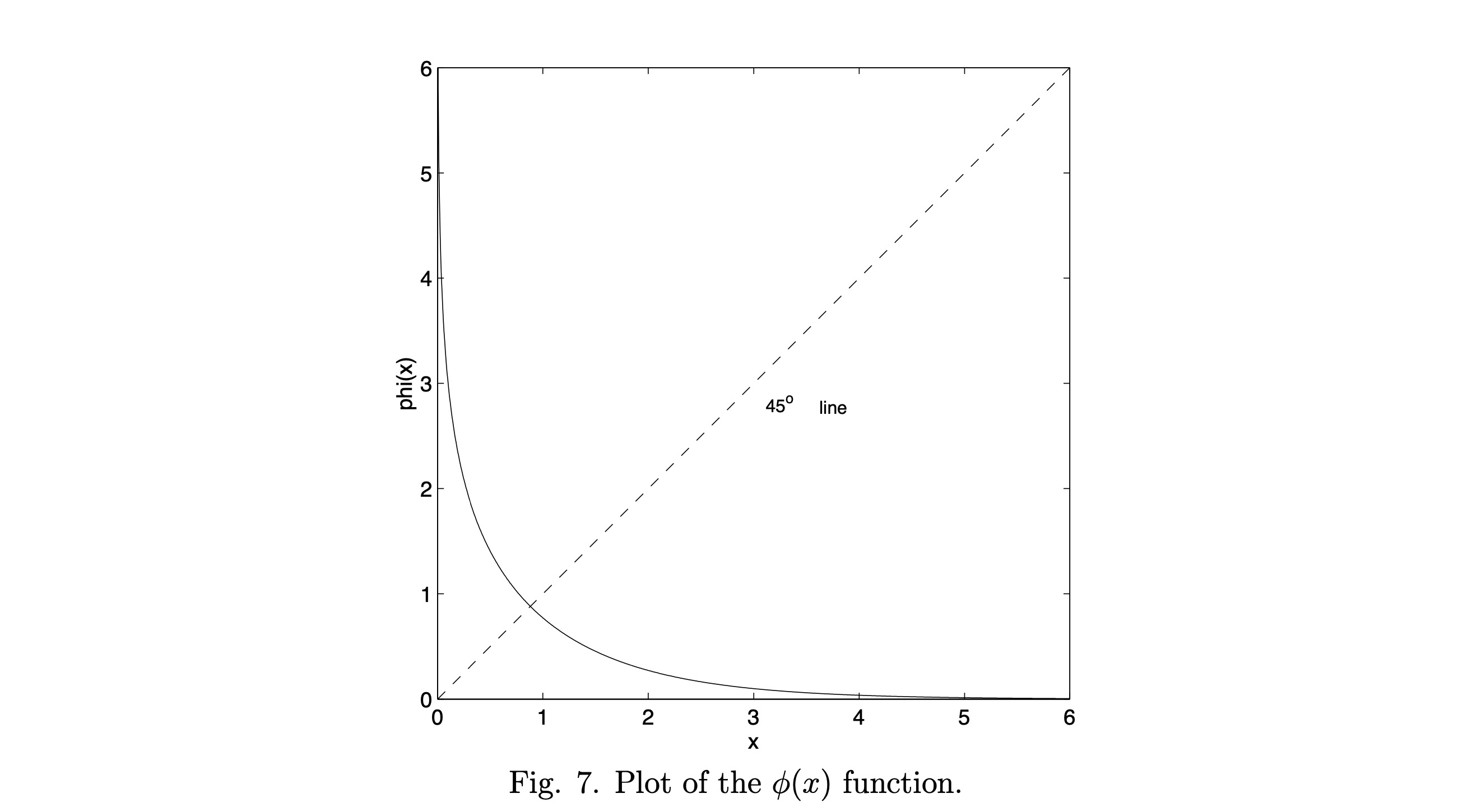
图7. φ(x)函数的图像。
4.4. 简化复杂度译码器
4.4.1. 最小和(Min-Sum)译码器32
考虑对数域译码中 L(rji)L(r_{ji})L(rji) 的更新方程 (4.10)。注意从 ϕ(x)\phi(x)ϕ(x) 的形状可以看出,求和式中最小的 βi′j\beta_{i'j}βi′j 对应的项占主导地位,因此:
ϕ (∑i′∈Cj∖iϕ(βi′j)) ≈ ϕ (ϕ(mini′∈Cj∖iβi′j)) = mini′∈Cj∖iβi′j\phi\!\Bigl(\sum_{i' \in C_j \setminus i} \phi(\beta_{i'j})\Bigr) \;\approx\; \phi\!\bigl(\phi(\min_{i' \in C_j \setminus i} \beta_{i'j})\bigr) \;=\; \min_{i' \in C_j \setminus i} \beta_{i'j}ϕ(i′∈Cj∖i∑ϕ(βi′j))≈ϕ(ϕ(i′∈Cj∖iminβi′j))=i′∈Cj∖iminβi′j
这里利用了 ϕ=ϕ−1\phi = \phi^{-1}ϕ=ϕ−1 的自反性质。因此,最小和算法将Step 1替换为:
L(rji)=∏i′∈Cj∖isign(L(qi′j))⏟所有输入符号的乘积⋅mini′∈Cj∖i∣L(qi′j)∣⏟最小输入幅度(4.13)L(r_{ji}) = \underbrace{\prod_{i' \in C_j \setminus i} \mathrm{sign}\bigl(L(q_{i'j})\bigr)}{\text{所有输入符号的乘积}} \cdot \underbrace{\min{i' \in C_j \setminus i} \bigl|L(q_{i'j})\bigr|}_{\text{最小输入幅度}} \tag{4.13}L(rji)=所有输入符号的乘积 i′∈Cj∖i∏sign(L(qi′j))⋅最小输入幅度 i′∈Cj∖imin L(qi′j) (4.13)
该算法无需计算 ϕ\phiϕ 函数,仅需符号和最小值操作。在BI-AWGNC情况下,初始化 L(qij)=2yi/σ2L(q_{ij}) = 2y_i/\sigma^2L(qij)=2yi/σ2 也可以替换为 L(qij)=yiL(q_{ij}) = y_iL(qij)=yi,此时甚至不需要知道噪声功率 σ2\sigma^2σ2。
4.4.2. 带校正因子的最小和译码器34
注意 L(rji)L(r_{ji})L(rji) 对应于二进制随机变量之和的(条件)LLR。考虑以下一般结果(Hagenauer等33):
结果 2. 考虑两个独立二进制随机变量 a1a_1a1 和 a2a_2a2,满足 Pr(ai=b)=pb(i)\Pr(a_i = b) = p_b^{(i)}Pr(ai=b)=pb(i),b∈{0,1}b \in \{0,1\}b∈{0,1},LLR为 Li=L(ai)=log(p0(i)/p1(i))L_i = L(a_i) = \log(p_0^{(i)}/p_1^{(i)})Li=L(ai)=log(p0(i)/p1(i))。则二进制和 A2=a1⊕a2A_2 = a_1 \oplus a_2A2=a1⊕a2 的LLR为:
L(A2)=log1+eL1+L2eL1+eL2(4.13)L(A_2) = \log\frac{1 + e^{L_1 + L_2}}{e^{L_1} + e^{L_2}} \tag{4.13}L(A2)=logeL1+eL21+eL1+L2(4.13)
若涉及多于两个独立二进制随机变量(如 rji(b)r_{ji}(b)rji(b) 的情况),则这些随机变量之和的LLR可通过重复应用此结果来计算。记 L1⊞L2L_1 \boxplus L_2L1⊞L2 表示由 L1L_1L1 和 L2L_2L2 计算 L(A2)=L(a1⊕a2)L(A_2) = L(a_1 \oplus a_2)L(A2)=L(a1⊕a2) 的运算。
定义对于任意实数 x,yx, yx,y:
max∗(x,y)=log(ex+ey)(4.14)\max^*(x, y) = \log(e^x + e^y) \tag{4.14}max∗(x,y)=log(ex+ey)(4.14)
可以证明35:
max∗(x,y)=max(x,y)+log(1+e−∣x−y∣)(4.15)\max^*(x, y) = \max(x, y) + \log\bigl(1 + e^{-|x-y|}\bigr) \tag{4.15}max∗(x,y)=max(x,y)+log(1+e−∣x−y∣)(4.15)
由 (4.13) 和 (4.14) 可写出:
L1⊞L2=max∗(0,L1+L2)−max∗(L1,L2)(4.16)L_1 \boxplus L_2 = \max^*(0, L_1 + L_2) - \max^*(L_1, L_2) \tag{4.16}L1⊞L2=max∗(0,L1+L2)−max∗(L1,L2)(4.16)
进而:
L1⊞L2=max(0,L1+L2)−max(L1,L2)⏟= sign(L1) sign(L2) min(∣L1∣,∣L2∣)+s(L1,L2)⏟校正项(4.17)L_1 \boxplus L_2 = \underbrace{\max(0, L_1 + L_2) - \max(L_1, L_2)}{=\;\mathrm{sign}(L_1)\,\mathrm{sign}(L_2)\,\min(|L_1|,|L_2|)} + \underbrace{s(L_1, L_2)}{\text{校正项}} \tag{4.17}L1⊞L2==sign(L1)sign(L2)min(∣L1∣,∣L2∣) max(0,L1+L2)−max(L1,L2)+校正项 s(L1,L2)(4.17)
其中校正项 s(x,y)s(x, y)s(x,y) 为:
s(x,y)=log(1+e−∣x+y∣)−log(1+e−∣x−y∣)s(x, y) = \log\bigl(1 + e^{-|x+y|}\bigr) - \log\bigl(1 + e^{-|x-y|}\bigr)s(x,y)=log(1+e−∣x+y∣)−log(1+e−∣x−y∣)
可以证明34:
max(0,L1+L2)−max(L1,L2)=sign(L1) sign(L2) min(∣L1∣,∣L2∣)\max(0, L_1 + L_2) - \max(L_1, L_2) = \mathrm{sign}(L_1)\,\mathrm{sign}(L_2)\,\min(|L_1|, |L_2|)max(0,L1+L2)−max(L1,L2)=sign(L1)sign(L2)min(∣L1∣,∣L2∣)
因此:
L1⊞L2=sign(L1) sign(L2) min(∣L1∣,∣L2∣)+s(L1,L2)(4.18)L_1 \boxplus L_2 = \mathrm{sign}(L_1)\,\mathrm{sign}(L_2)\,\min(|L_1|, |L_2|) + s(L_1, L_2) \tag{4.18}L1⊞L2=sign(L1)sign(L2)min(∣L1∣,∣L2∣)+s(L1,L2)(4.18)
若忽略校正项 s(L1,L2)s(L_1, L_2)s(L1,L2)(因为 ∣s(x,y)∣≤log2≈0.693|s(x,y)| \leq \log 2 \approx 0.693∣s(x,y)∣≤log2≈0.693),得到近似式:
L1⊞L2 ≈ sign(L1) sign(L2) min(∣L1∣,∣L2∣)(4.19)L_1 \boxplus L_2 \;\approx\; \mathrm{sign}(L_1)\,\mathrm{sign}(L_2)\,\min(|L_1|, |L_2|) \tag{4.19}L1⊞L2≈sign(L1)sign(L2)min(∣L1∣,∣L2∣)(4.19)
回到 L(rji)L(r_{ji})L(rji) 的计算,在独立性假设下可以写:
L(rji)=L(q1j)⊞⋯⊞L(qi−1,j)⊞L(qi+1,j)⊞⋯⊞L(qnj)L(r_{ji}) = L(q_{1j}) \boxplus \cdots \boxplus L(q_{i-1,j}) \boxplus L(q_{i+1,j}) \boxplus \cdots \boxplus L(q_{nj})L(rji)=L(q1j)⊞⋯⊞L(qi−1,j)⊞L(qi+1,j)⊞⋯⊞L(qnj)
此表达式可通过重复应用结果 2 以及 (4.17) 来计算34。若采用近似 (4.19),即得到最小和算法 。若采用稍紧的近似,用 S(x,y)\mathcal{S}(x,y)S(x,y) 代替 (4.18) 中的 s(x,y)s(x,y)s(x,y)34:
S(x,y)={c若 ∣x+y∣<2 且 ∣x−y∣>2∣x+y∣−c若 ∣x−y∣<2 且 ∣x+y∣>2∣x−y∣0其他\mathcal{S}(x, y) = \begin{cases} c & \text{若 } |x+y| < 2 \text{ 且 } |x-y| > 2|x+y| \\ -c & \text{若 } |x-y| < 2 \text{ 且 } |x+y| > 2|x-y| \\ 0 & \text{其他} \end{cases}S(x,y)=⎩ ⎨ ⎧c−c0若 ∣x+y∣<2 且 ∣x−y∣>2∣x+y∣若 ∣x−y∣<2 且 ∣x+y∣>2∣x−y∣其他
其中 c≈0.5c \approx 0.5c≈0.5 是典型值,可获得比最小和算法更好的性能。
4.5. 性能比较
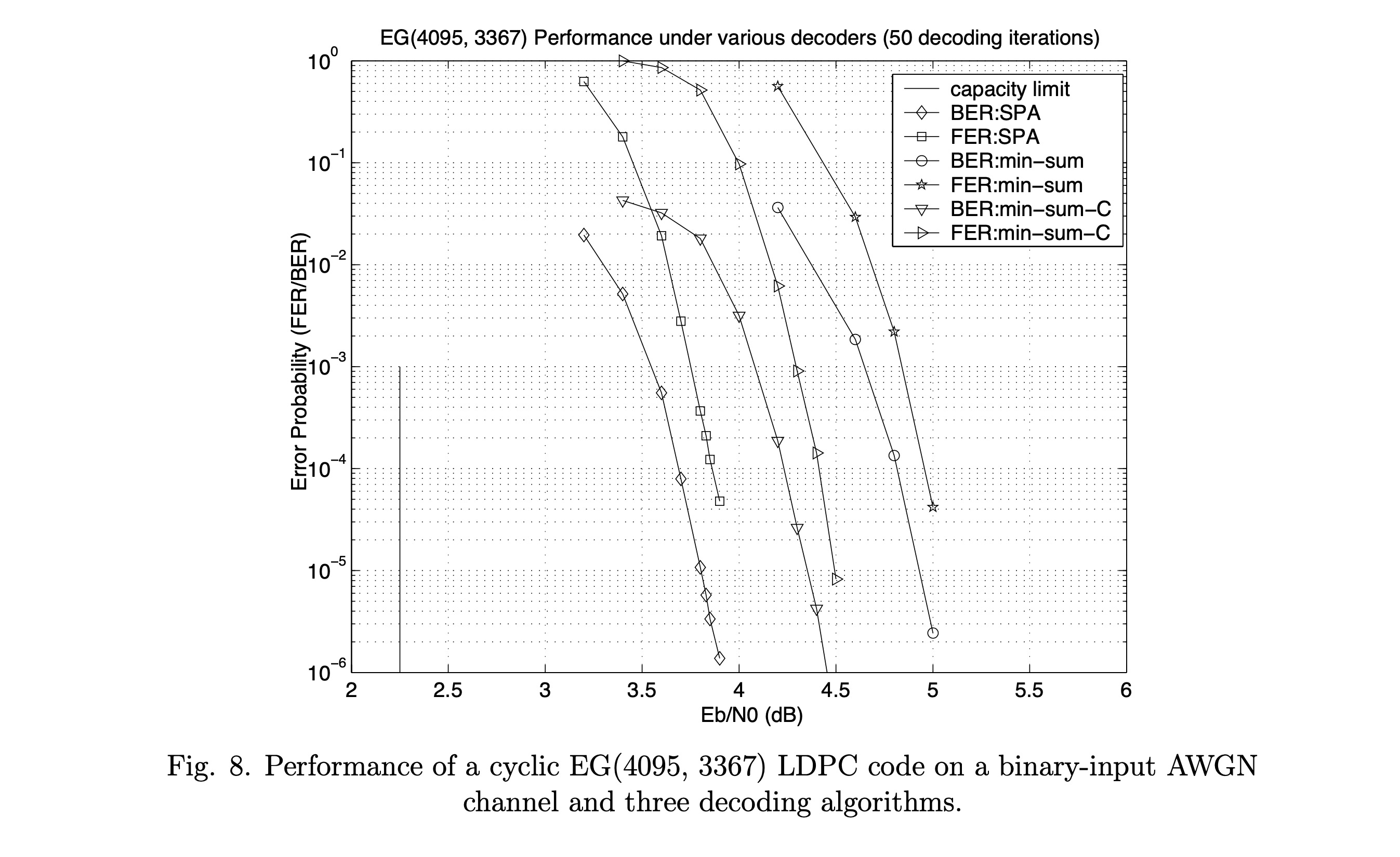
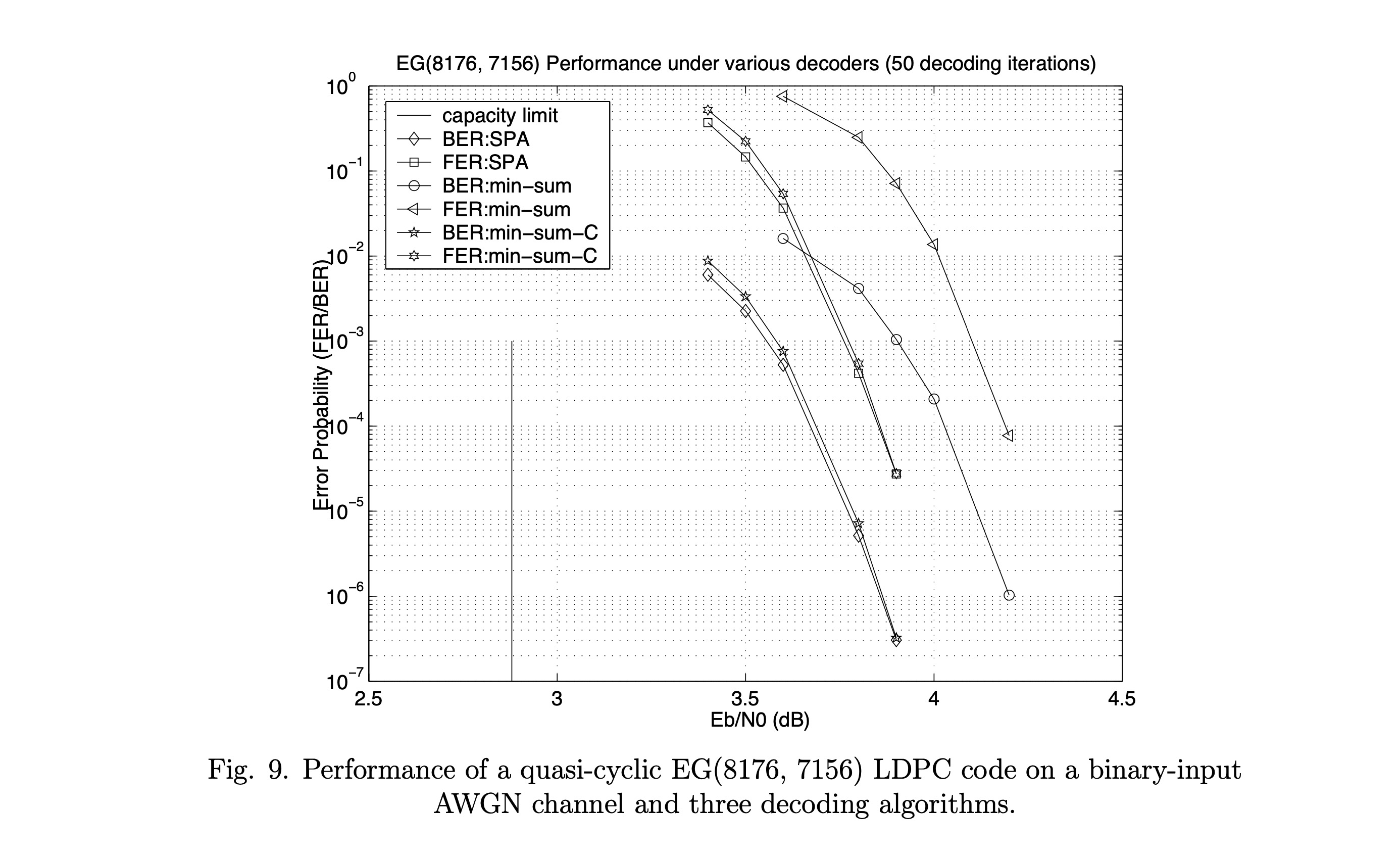
图8和图9展示了两个规则欧几里得几何(EG)LDPC码在二进制输入AWGN信道上使用三种译码算法的性能:对数域SPA、最小和(min-sum)、以及带校正因子的最小和(min-sum-c,c=0.5c = 0.5c=0.5)。
码1: 循环码,码率 R=0.82R = 0.82R=0.82,(4095,3367)(4095, 3367)(4095,3367),最小距离下界 dmin≥65d_{\min} \geq 65dmin≥65。HHH 是 4095×40954095 \times 40954095×4095 循环矩阵,行权重和列权重均为 64。
码2: 准循环码,码率 R=0.875R = 0.875R=0.875,(8176,7156)(8176, 7156)(8176,7156)。HHH 是 1022×81761022 \times 81761022×8176,列权重 4,行权重 32,由八个 511×2044511 \times 2044511×2044 循环子矩阵组成。
仿真结果(BER =10−5= 10^{-5}=10−5 处测量):
- 长度4095码距离容量限 1.6 dB;长度8176码仅距离容量限 0.9 dB。
- 对于长度4095码:min-sum相对于SPA损失 1.1 dB,min-sum-c损失 0.5 dB。
- 对于长度8176码:上述损失分别为 0.3 dB 和 0.01 dB。
- 长度4095码损失较大的原因是其译码器依赖行权重为 64 的 HHH 矩阵,在校验节点处取 64 个小非负数的最小值,通常产生接近零的值。
5. 结论性评论
低密度奇偶校验码与turbo码、网格码一样正在被大量应用研究。与turbo码不同,LDPC码具有相对低复杂度的译码算法,并且其性能可以通过密度进化等分析工具准确预测。LDPC码的灵活结构允许通过多种方法进行设计,包括随机构造、代数构造和组合构造。
本教程介绍了LDPC码的基础知识,包括其表示方法、设计技术和迭代译码算法。还讨论了降低译码复杂度的简化算法,这些算法在性能上仅有很小的损失。未来的研究方向包括短码和中长码的优化设计、低误码率平台的设计技术、硬件高效的译码器实现,以及LDPC码在新应用中的推广。
LDPC码代表了信道编码领域最重要的进展之一,其实际应用正在不断扩大,从深空通信到无线网络和数字存储系统。
参考文献
-
R. Gallager, "Low-density parity-check codes," IRE Trans. Information Theory, pp. 21-28, Jan. 1962.
-
R. M. Tanner, "A recursive approach to low complexity codes," IEEE Trans. Information Theory, pp. 533-547, Sept. 1981.
-
D. MacKay and R. Neal, "Good codes based on very sparse matrices," in Cryptography and Coding, 5th IMA Conf., C. Boyd, Ed., Lecture Notes in Computer Science, pp. 100-111, Berlin, Germany: Springer, 1995.
-
D. MacKay, "Good error correcting codes based on very sparse matrices," IEEE Trans. Information Theory, pp. 399-431, March 1999.
-
M. Luby, M. Mitzenmacher, M. Shokrollahi, and D. Spielman, "Improved low-density parity-check codes using irregular graphs and belief propagation," in Proc. 1998 IEEE Intl. Symp. Inform. Theory, Cambridge, MA, Aug. 1998, p. 117.
-
T. Richardson and R. Urbanke, "Efficient encoding of low-density parity-check codes," IEEE Trans. Inform. Theory, pp. 638-656, Feb. 2001.
-
T. Richardson, A. Shokrollahi, and R. Urbanke, "Design of capacity-approaching low-density parity-check codes," IEEE Trans. Inform. Theory, pp. 619-637, Feb. 2001.
-
M. Luby, M. Mitzenmacher, A. Shokrollahi, D. Spielman, and V. Stemann, "Practical loss-resilient codes," in Proc. 29th Annual ACM Symp. Theory of Computing, 1997, pp. 150-159.
-
R. Lucas, M. Fossorier, Y. Kou, and S. Lin, "Iterative decoding of one-step majority-logic decodable codes based on belief propagation," IEEE Trans. Commun., pp. 931-937, June 2000.
-
D. MacKay, "Encyclopedia of sparse graph codes," available at http://www.inference.phy.cam.ac.uk/mackay/codes/data.html.
-
S.-Y. Chung, G. D. Forney, T. J. Richardson, and R. Urbanke, "On the design of low-density parity-check codes within 0.0045 dB of the Shannon limit," IEEE Commun. Lett., vol. 5, pp. 58-60, Feb. 2001.
-
T. Richardson and R. Urbanke, "The capacity of low-density parity-check codes under message-passing decoding," IEEE Trans. Inform. Theory, pp. 599-618, Feb. 2001.
-
M. Yang, W. E. Ryan, and Y. Li, "Design of efficiently encodable moderate-length high-rate LDPC codes," IEEE Trans. Commun., 2003.
-
Y. Kou, S. Lin, and M. Fossorier, "Low-density parity-check codes based on finite geometries: a rediscovery and new results," IEEE Trans. Information Theory, vol. 47, pp. 2711-2736, Nov. 2001.
-
M. Yang, W. E. Ryan, and Y. Li, "Design of efficiently encodable moderate-length high-rate irregular LDPC codes," IEEE Trans. Commun., 2003.
-
Y. Kou, S. Lin, and M. Fossorier, "Low-density parity-check codes based on finite geometries: a rediscovery and new results," IEEE Trans. Information Theory, vol. 47, pp. 2711-2736, Nov. 2001.
-
S. Lin and D. J. Costello, Error Control Coding: Fundamentals and Applications, 2nd ed., Prentice Hall, 2004.
-
R. Lucas, M. Fossorier, Y. Kou, and S. Lin, "Iterative decoding of one-step majority-logic decodable codes based on belief propagation," IEEE Trans. Commun., pp. 931-937, June 2000.
-
H. Jin, A. Khandekar, and R. McEliece, "Irregular repeat-accumulate codes," in Proc. 2nd International Symposium on Turbo Codes and Related Topics, Brest, France, Sept. 2000, pp. 1-8.
-
H. Jin, A. Khandekar, and R. McEliece, "Irregular repeat-accumulate codes," in Proc. 2nd International Symposium on Turbo Codes, pp. 1-8, 2000.
-
A. Abbasfar, D. Divsalar, and Y. Kung, "Accumulate-repeat-accumulate codes," in Proc. IEEE Globecom, San Francisco, CA, Dec. 2003.
-
M. Yang, W. E. Ryan, and Y. Li, "Design of efficiently encodable moderate-length high-rate irregular LDPC codes," IEEE Trans. Commun., 2003.
-
J. L. Fan, "Array codes as low-density parity-check codes," in Proc. 2nd Int. Symp. Turbo Codes and Related Topics, Brest, France, Sept. 2000, pp. 543-546.
-
J. L. Fan, "Constrained coding and soft iterative decoding for storage," Ph.D. dissertation, Stanford Univ., Stanford, CA, Dec. 1999.
-
E. Eleftheriou and S. Ölçer, "Low-density parity-check codes for digital subscriber lines," in Proc. IEEE Int. Conf. Commun., New York, NY, April 2002, pp. 1752-1757.
-
I. B. Djordjevic and B. Vasic, "Projective plane iteratively decodable block codes for WDM high-speed long-haul transmission systems," J. Lightwave Technol., vol. 22, pp. 695-702, March 2004.
-
B. Ammar, B. Honary, Y. Kou, J. Xu, and S. Lin, "Construction of low-density parity-check codes based on balanced incomplete block designs," IEEE Trans. Information Theory, vol. 50, pp. 1257-1268, June 2004.
-
B. Vasic and O. Milenkovic, "Combinatorial constructions of low-density parity-check codes for iterative decoding," IEEE Trans. Information Theory, vol. 50, pp. 1156-1176, June 2004.
-
C. J. Colbourn and J. H. Dinitz, The CRC Handbook of Combinatorial Designs, CRC Press, 1996.
-
F. R. Kschischang, B. J. Frey, and H.-A. Loeliger, "Factor graphs and the sum-product algorithm," IEEE Trans. Inform. Theory, pp. 498-519, Feb. 2001.
-
M. Fossorier, M. Mihaljevic, and H. Imai, "Reduced complexity iterative decoding of low-density parity-check codes based on belief propagation," IEEE Trans. Commun., pp. 673-680, May 1999.
-
J. Hagenauer, E. Offer, and L. Papke, "Iterative decoding of binary block and convolutional codes," IEEE Trans. Inform. Theory, pp. 429-445, March 1996.
-
J. Hagenauer, E. Offer, and L. Papke, "A comparison between the sum-product and the min-sum iterative detection algorithms based on density evolution," in Proc. IEEE Globecom, San Antonio, TX, Nov. 2001.
-
M. Fossorier, "Iterative reliability-based decoding of low-density parity-check codes," IEEE Trans. Inform. Theory, pp. 1700-1712, Sept. 2001.
-
S. Lin and D. J. Costello, Error Control Coding: Fundamentals and Applications, 2nd ed., Prentice Hall, 2004.
-
R. E. Blahut, Algebraic Codes for Data Transmission, Cambridge University Press, 2003.
-
J. Pearl, Probabilistic Reasoning in Intelligent Systems, San Mateo, CA: Morgan Kaufmann, 1988.