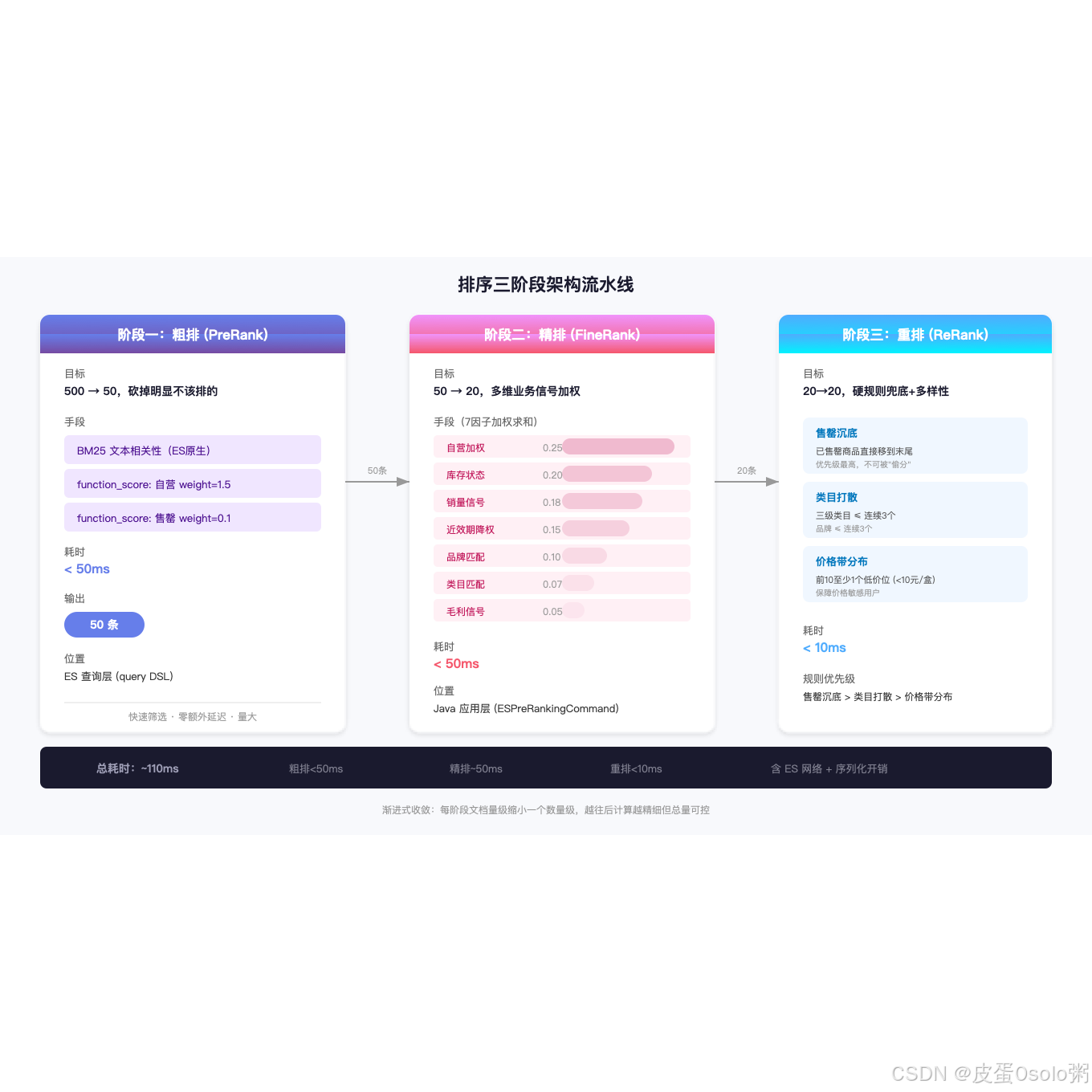
排序三阶段:粗排→精排→重排,把业务信号灌进 ES 排序管道
医药搜索系列第8篇。前面我们聊了怎么把商品"找出来"(倒排索引、分词、BM25、bool query、filter 缓存、相关性调优、多路召回),这篇聊怎么把它们排出你想要的顺序。
一、背景:BM25 排出来的结果,运营不认
先说个真实场景。
用户搜"布洛芬缓释胶囊",BM25 算出来 Top3 是这样的:
| 排名 | 商品 | BM25 分 | 库存 | 毛利 | 自营 |
|---|---|---|---|---|---|
| 1 | 某小厂布洛芬缓释胶囊 0.3g×24粒 | 15.2 | 3 | 低 | 否 |
| 2 | 芬必得布洛芬缓释胶囊 0.3g×20粒 | 14.8 | 500 | 高 | 是 |
| 3 | 某B厂布洛芬缓释胶囊 0.4g×12粒 | 13.5 | 0 | 中 | 否 |
运营一看就炸了:第一个库存只有3盒,第三个直接没货,你们搜索引擎是有毛病?
BM25 只看文本相关性,它不知道哪个商品该多卖、哪个商品快过期了、哪个商品利润高。搜索不是图书馆检索------搜索结果必须承载商业意图。
排序问题拆开来看,就三件事:
- 召回决定上限------没召回的商品永远排不到前面(上篇解决了)
- 排序决定下限------同样的召回集,不同排序策略天差地别
- 重排兜底------硬规则不能被打分"漂移"掉
这就是我们做三阶段排序的根本原因。
二、整体架构:为什么是三阶段,不是一锅炖?
为什么不是一阶段全搞?
如果把所有业务信号都用 function_score 的 script_score 塞进 ES 查询里:
- 500 个文档每个都要跑 Painless 脚本 → 500 次脚本执行 → 至少 200ms+
- 脚本里 if-else 分支多 → JIT 编译开销大
- 排序逻辑和查询逻辑耦合 → 改一个加权系数要动查询 DSL
三阶段的核心思想是渐进式收敛:
- 每阶段文档量级缩小一个数量级
- 越往后计算越精细,但文档越少所以总耗时可控
- 阶段之间解耦,改精排逻辑不动粗排
三、粗排:用 ES 原生能力做第一刀
粗排的目标只有一个:在不增加太多延迟的前提下,把候选集从 500 收敛到 50。
3.1 什么时候需要粗排?
不是所有搜索都要粗排。判断标准:
- 搜索结果 < 200 条:精排直接扛得住,不需要粗排
- 搜索结果 > 200 条:粗排性价比高
医药搜索里,"阿莫西林"这类大词会召回 500+ 商品,必须有粗排。
3.2 粗排用什么?
BM25 + function_score 轻量加权:
json
{
"query": {
"function_score": {
"query": { "bool": { ... } },
"functions": [
{
"filter": { "term": { "is_self_operated": true } },
"weight": 1.5
},
{
"filter": { "term": { "is_out_of_stock": true } },
"weight": 0.1
}
],
"boost_mode": "multiply",
"score_mode": "multiply"
}
},
"size": 50
}粗排阶段只做两件事:
- BM25 算文本相关性(ES 原生,几乎零额外开销)
- 两个硬 filter + weight:自营加权 1.5 倍、售罄压到 0.1 倍
不用 script_score,不用 field_value_factor,不用 decay------这些留给精排。
粗排选 50 条而不是更少的原因:给精排留足够候选空间。如果粗排砍到 20,可能某些低 BM25 分但高毛利的商品被误杀。
四、精排:ESPreRankingCommand------把业务信号做成可配置的排序管道
精排是核心。我们做了 ESPreRankingCommand------一个 Java 侧的自定义排序组件。
4.1 为什么不在 ES 里做精排?
ES 的 script_score 本质上不擅长复杂业务排序:
- Painless 是解释执行,不是编译执行,50 个文档每个跑 10 个 if-else 分支,50ms 起步
- DSL 膨胀------加权因子硬编码在查询里,A/B 测试要改查询 DSL
- 无法复用业务上下文------排序需要实时库存、用户标签、促销信息,这些数据在 ES 里不一定有
所以我们在 ES 返回 top50 之后,把 50 个文档拉到 Java 侧,用 ESPreRankingCommand 做精排。
4.2 ESPreRankingCommand 设计
java
public class ESPreRankingCommand implements RankingCommand {
// 配置化的排序因子
private List<RankingFactor> factors;
@Override
public List<SearchItem> rank(List<SearchItem> items, SearchContext ctx) {
for (SearchItem item : items) {
double score = 0.0;
for (RankingFactor factor : factors) {
// 每个因子返回 [0, 1] 的贡献分,乘以权重
score += factor.weight() * factor.score(item, ctx);
}
item.setRankScore(score);
}
// 按 rankScore 降序排列
items.sort(Comparator.comparing(SearchItem::getRankScore).reversed());
return items;
}
}核心设计:
每个因子实现 RankingFactor 接口,输出 [0, 1] 归一化分数,乘以配置化权重:
java
public interface RankingFactor {
// 权重,如 0.3 表示该因子最高贡献 30% 的排序分
double weight();
// 对单个商品打分,返回 [0, 1]
double score(SearchItem item, SearchContext ctx);
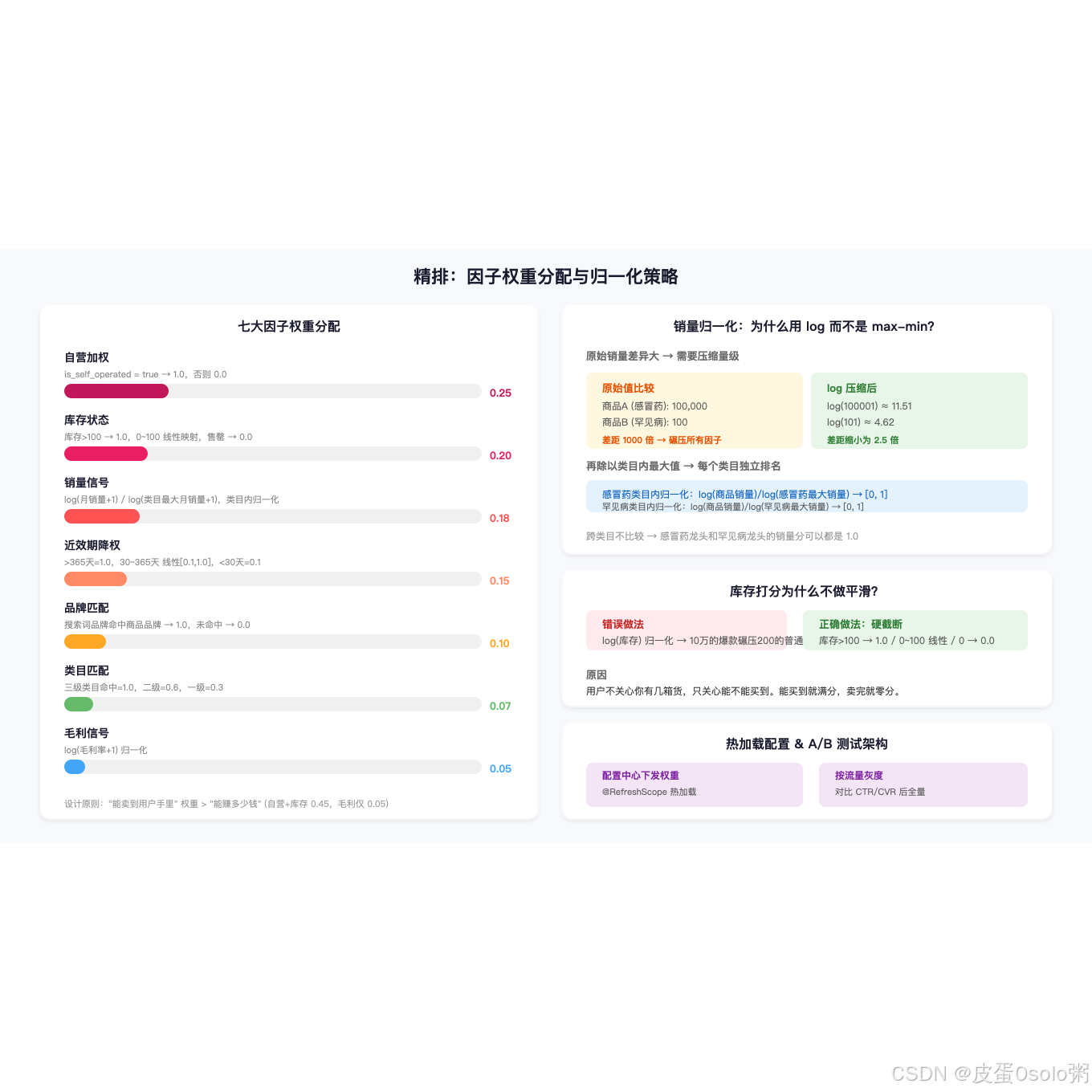
}因子列表(医药搜索实际使用):
| 因子 | 权重 | 逻辑 | 打分规则 |
|---|---|---|---|
| 自营加权 | 0.25 | 自营打满分 | 自营=1.0,非自营=0.0 |
| 库存状态 | 0.20 | 有货优先 | 库存>100=1.0,库存>0 线性映射,售罄=0.0 |
| 销量信号 | 0.18 | 卖得好的排前面 | log(月销量+1)/log(最大月销量+1) 归一化 |
| 近效期降权 | 0.15 | 快过期的往下降 | 剩余天数>365=1.0,<30天=0.1,中间线性 |
| 品牌匹配 | 0.10 | 搜"芬必得"时芬必得加分 | 品牌命中=1.0,未命中=0.0 |
| 类目匹配 | 0.07 | 搜"感冒"时感冒用药加分 | 三级类目命中=1.0,二级=0.6,一级=0.3 |
| 毛利信号 | 0.05 | 高毛利稍微提权 | log(毛利率+1) 归一化 |
注意权重的设计逻辑:
- 自营和库存合计 0.45------"这个药能卖到用户手里"比"这个药赚多少钱"重要
- 销量 0.18------销量是用户投票,但不能替代自营/库存
- 近效期 0.15------合规刚需,过期药不能卖
- 毛利只有 0.05------搜索不是推荐,不能为了利润牺牲相关性
4.3 销量信号的归一化
销量是最容易出问题的因子。不同类目的销量量级差异巨大(感冒药月销几十万,罕见病药月销个位数),直接拿原始销量会碾压其他因子。
我们用 对数归一化 + 类目内标准化:
java
public double score(SearchItem item, SearchContext ctx) {
long monthlySales = item.getMonthlySales();
long categoryMax = ctx.getCategoryMaxSales(item.getCategoryId());
double logSales = Math.log(monthlySales + 1);
double logMax = Math.log(categoryMax + 1);
return logMax == 0 ? 0 : logSales / logMax;
}为什么是 log(销量) 而不是原始销量?
假设 A 商品月销 10 万,B 商品月销 1 万。原始值差距 10 倍,绝大部分因子都会淹没。取 log 后 log(100001) ≈ 11.5,log(10001) ≈ 9.2,差距缩小为 1.25 倍,不会碾压其他因子。
类目内标准化:感冒药和罕见病药各比各的 max,不跨类目比较。这样每个类目内部销量排名是准确的。
4.4 近效期降权的线性分段
java
public double score(SearchItem item, SearchContext ctx) {
long remainingDays = item.getRemainingDays();
if (remainingDays > 365) return 1.0; // 一年以上:不降权
if (remainingDays <= 30) return 0.1; // 一个月以内:压到底
// 30~365 天之间线性映射到 [0.1, 1.0]
return 0.1 + 0.9 * (remainingDays - 30) / (365 - 30);
}为什么不用 function_score 的 gauss decay?因为 gauss 曲线的拐点不好控制------我们需要的是一条确定的、可解释的线,而不是"经验调参"的曲线。运营要的是"剩余 90 天打几分",不是"σ 等于多少"。
4.5 排序因子热加载
ESPreRankingCommand 的因子权重通过配置中心下发,支持运行时热加载:
java
@RefreshScope // Spring Cloud 配置刷新
public class RankingFactorConfig {
private Map<String, Double> weights = Map.of(
"self_operated", 0.25,
"stock", 0.20,
"sales", 0.18,
"expiry", 0.15,
"brand_match", 0.10,
"category_match",0.07,
"profit", 0.05
);
}这意味着我们可以做到:
- A/B 测试:新因子先在 5% 流量上跑,对比 CTR/CVR
- 活动期间临时调权:双11 期间毛利+自营权重大幅提升
- 灰度发布:新排序策略逐步放量
五、重排:硬规则兜底 + 多样性保障
精排完拿到 top20 后,重排做最后一层兜底。精排是打分制的,再精细的公式也可能让不合理的商品"偷分"排到前面。重排不记分,用硬规则直接干预位置。
5.1 售罄沉底
精排的库存因子权重只有 0.20,极端情况下(一个售罄商品的自营+品牌+类目三项全满分 = 0.25+0.10+0.07 = 0.42 > 0.20),售罄商品可能还排在前面。
重排硬规则:已售罄商品直接位移到结果列表末尾,不给任何"抢救"机会。
5.2 类目打散
用户搜"感冒",精排可能排出来全是"感冒灵颗粒"的不同规格。搜索结果页前 20 个里面 18 个都是同一个通用名------即使搜索相关性很高,用户体验极差。
重排做类目打散:
text
规则:同一三级类目最多连续出现 3 个
同一二级类目最多连续出现 5 个
同一品牌最多连续出现 3 个打散不是随机插------保留精排的 rankScore 作为主序,只在违反打散规则时向后位移。
5.3 价格带分布
医药搜索里,用户对价格不敏感的情况很少。搜"感冒药",如果前 20 全是 30 元以上的,价格敏感用户可能直接关页面。
重排保证前 10 至少有一个低价位选项(< 10 元/盒):
java
// 检查前10是否包含低价位商品
boolean hasLowPrice = items.subList(0, 10).stream()
.anyMatch(item -> item.getPrice() < 10.0);
if (!hasLowPrice) {
// 从11~20中找最低价的,插入到第10位
SearchItem cheapest = findCheapest(items.subList(10, items.size()));
items.remove(cheapest);
items.add(9, cheapest); // 插入到第9位(index=9,即第10个)
}六、完整排序链路回顾
把三个阶段串起来看:
text
ES返回500条(BM25粗排+自营/库存快速过滤,50ms)
│
▼
精排50条 → ESPreRankingCommand
自营加权(0.25) + 库存(0.20) + 销量(0.18)
+ 近效期(0.15) + 品牌(0.10) + 类目(0.07) + 毛利(0.05)
→ 排序按 rankScore 降序,取 top20
耗时:~50ms
│
▼
重排20条 → 硬规则
售罄沉底 + 类目打散 + 价格带分布
耗时:~10ms
│
▼
返回给前端
总耗时:~110ms(含ES网络+序列化)七、面试得分点
7.1 你为什么做三阶段而不是单阶段?
三个阶段的职责不同:
- 粗排解决量级问题(500→50),用 ES 原生能力不增加延迟
- 精排解决精度问题(50→20),用 Java 侧定制化计算,避免 Painless 脚本的性能损耗
- 重排解决公平性问题(20→20),硬规则兜底,防止打分公式被钻空子
每阶段文档量级缩小一个数量级,越往后计算越贵但文档越少,整体耗时可控。
7.2 ESPreRankingCommand 的设计理念?
- 因子归一化到 0, 1:所有因子输出统一区间,权重才是最终排序的决定因素
- 因子可插拔 :新增因子只需实现
RankingFactor接口,不改主逻辑 - 配置化权重:权重通过配置中心下发,支持 A/B 测试和热加载
- 对数归一化销量:避免量级差异淹没其他因子
7.3 销量归一化为什么用 log 而不是 max-min?
max-min 归一化受极端值影响大。如果某个 SKU 月销 100 万,max-min 归一化后大部分商品的销量分接近 0,销量因子形同虚设。log 压缩了量级差距,但没有抹平差距------高销量商品仍然得分更高,只是不会碾压。
7.4 如果不做重排会有什么问题?
- 售罄商品可能靠其他因子"偷分"排到前面(库存权重 0.20,其他因子可以凑出 0.42)
- 搜索结果同质化,全是同一通用名的不同规格,用户找不到想要的形式(颗粒 vs 胶囊 vs 口服液)
- 搜索结果全部高价,价格敏感用户流失
八、三个坑
坑1:精排因子权重之和到底要不要等于 1?
不需要。 rankScore 是多个因子加权求和的结果,每个文档的 rankScore 只在相互比较时有意义------绝对值不重要,相对排序才重要。A.rankScore=3.5 vs B.rankScore=2.1,和 A.rankScore=0.87 vs B.rankScore=0.53,排序结果一样。
权重之和为 1 只是为了让分数"看起来像概率",实际排序不需要。而且一旦因子列表调整(新增/删除因子),强制权重和为 1 会导致所有已有权重需要重新分配。
正确做法:权重只表示因子之间的相对重要性,不要求之和为特定值。
坑2:库存状态要不要做平滑?
不要。 库存 1000 和库存 500 对排序的影响应该几乎没有区别------用户不关心你仓库里有几箱货,只关心能不能买到。
我们的做法:库存 > 100 → 得满分 1.0。超过 100 就等同于"有货",不多给分。从 0 到 100 之间线性映射。
如果做平滑(比如 log(库存)),库存 10 万的爆款会比库存 200 的正常商品得分高一大截,库存因子会不正常地主导排序。
坑3:重排规则冲突怎么办?
售罄沉底和价格带分布可能冲突:如果前 10 不包含低价商品,需要从 11~20 中找最便宜的插入到第 9 位,但 11~20 全是售罄商品。
规则优先级:售罄沉底 > 类目打散 > 价格带分布。价格带分布只在非售罄商品中找候选。如果找不到(即前 20 全售罄),说明搜索结果本身有问题,回退到原始顺序。