1. 回顾 :第一期选择了RF随机森林,做完之后效果83.74;
第二期选择了方案中选择了轻量化的 FastText,效果远超预期,从83.74%左右调到字符级别分词的效果是91.65%;虽然提升很大,但还是有很大的优化空间,所以有了第三期项目;
(分类任务算是最简单的任务,对其一般要求都很高,一般都是四个9(9999):即99.99%,工作中91.65%肯定不是最好的,至少要优化到95%以上,尽量减少误差;)
第三期:使用Bert;
2. Transformer理解 :
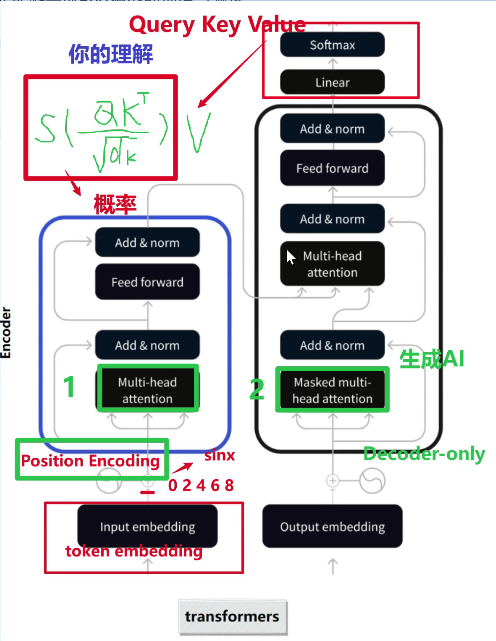
Transformer由四部分构成:输入、输出、编码器、解码器;输入包括:token embedding ➕ PE(Position Encoding位置编码,BERT的3个embedding中有一个是Position embedding位置嵌入 ),这里偶数位(0 2 4 6 8)用正弦、奇数位用余弦;面试时重点介绍:① 带掩码的多头自注意力,它适合做生成任务,因为后面的内容被掩盖掉了,根据前面的预测后面的;如今的大模型叫做 生成式AI,所以现在大模型几乎都使用纯Decoder-only;(面试题:为什么现在大模型都用Decoder-only? :因为如今的大模型叫做 生成式AI,Decoder本身是带有掩码的多头自注意力,后面的内容被掩盖掉了,根据前面的内容预测后面的,适合做生成任务);② 多头自注意力机制(2018年谷歌颠覆性的提出自注意力机制),公式:QKT/根号dk再进行softmax,再乘以V;(面试题:注意力体现在公式中的哪一块? :Softmax后的这一部分;因为softmax后是概率值,V相当于答案,在答案上给定概率值,哪个概率值高,就关注哪个地方、哪个概率值低,默认可以忽视:(对于QKV:Q-Query是问题、V-Value是答案、中间的K-Key是提示信息即 通过Key的提示把Query的问题回答成Value);③ PE (Position Encoding位置编码,BERT的3个embedding中有一个是Position embedding位置嵌入 ),这里偶数位(0 2 4 6 8)用正弦、奇数位用余弦 ?? )
3. BERT理解 :
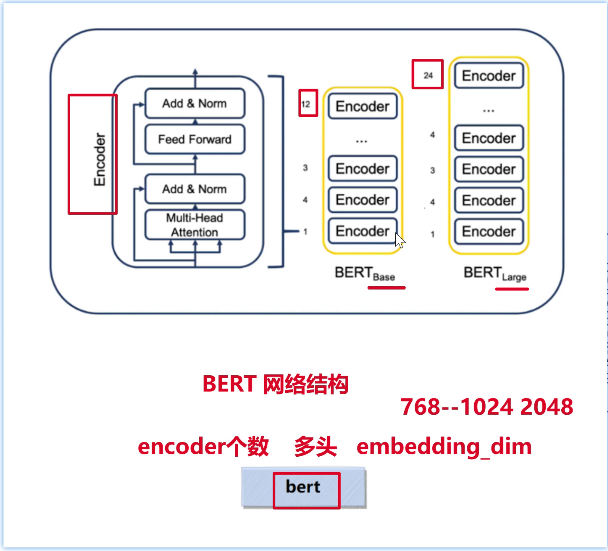
BERT用到Encoder结构,由12个encoder堆叠而成叫base、由24个个encoder堆叠而成叫large。(面试题:主要说出Bert核心是encoder的堆叠,多少个encoder堆叠?多头注意力多少?加上embedding_dim词嵌入维度是多大?这三点。:Bert的网络结构有堆叠了12层encoder、**多头注意力的头数是多少??**embedding_dim 词嵌入维度有768维(现在用的多的1024、2048)
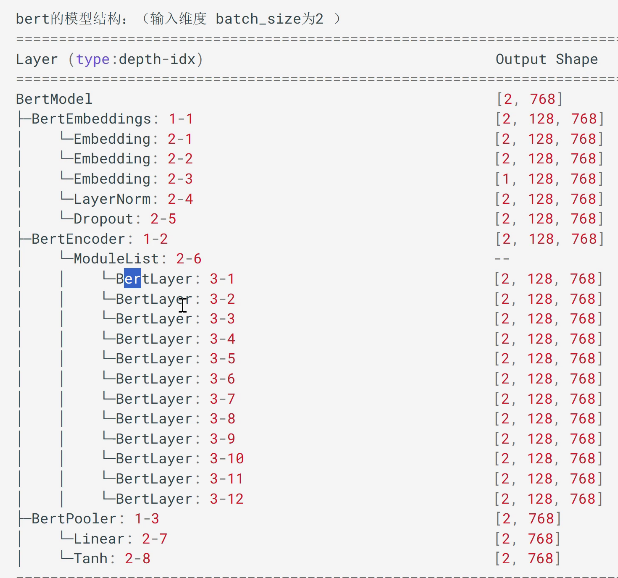
如下Bert架构图:Bert的基础构建块 即通过 BertLayer块进行堆叠,堆叠了12个;