AI 学习路线 04:机器学习到底在学什么?从分类、回归到模型评估
前言
前面几篇我们已经建立了 AI 的整体认知,补了 Python、数据处理和数学基础。
这一篇开始进入很多人印象中最"正统"的 AI 主题:机器学习。
但机器学习并不是一上来就背算法名字:
text
线性回归、逻辑回归、决策树、随机森林、SVM、K-Means......更重要的是先搞懂这几个问题:
- 机器学习到底在学什么?
- 监督学习、无监督学习、强化学习有什么区别?
- 为什么要划分训练集、验证集、测试集?
- 什么是过拟合、欠拟合、泛化能力?
- 回归、分类、聚类分别解决什么问题?
- 怎么选择常见算法?
- 为什么不能只看准确率?
这篇文章会尽量用图、例子和实战代码,把机器学习的基础框架讲清楚。
一、机器学习到底在学什么?
机器学习的核心可以概括成一句话:
text
从数据中学习规律,然后用到新数据上。比如:
| 历史数据 | 学到的规律 | 用于预测 |
|---|---|---|
| 历史房屋数据 | 面积、城市、楼层、房龄和价格的关系 | 新房子的价格 |
| 历史邮件样本 | 垃圾邮件常见特征 | 新邮件是否垃圾 |
| 用户行为记录 | 哪些用户容易流失 | 新用户是否会流失 |
先看机器学习的整体流程:
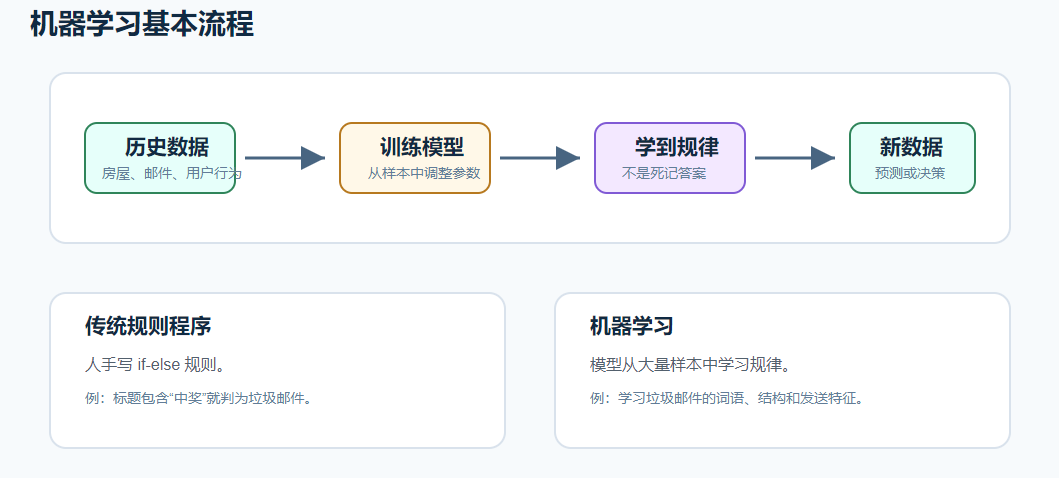
传统程序更像是人写规则:
text
如果标题包含"中奖""免费领取",就判断为垃圾邮件。机器学习则更像是:
text
给模型很多历史邮件,并告诉它哪些是垃圾邮件、哪些不是。
模型自己从数据里学习垃圾邮件的特征。
以后来了新邮件,模型自己判断。所以机器学习不是简单"背数据",而是希望学到能迁移到新样本上的规律。
这就引出了一个重要词:
text
泛化能力:模型在没见过的新数据上的表现能力。二、三种学习范式:监督、无监督、强化学习
机器学习常见的三种学习范式是:

| 学习方式 | 数据特点 | 目标 | 例子 |
|---|---|---|---|
| 监督学习 | 有输入和正确答案 | 学会从输入预测答案 | 房价预测、垃圾邮件识别 |
| 无监督学习 | 只有输入,没有标签 | 从数据中发现结构 | 用户分群、主题聚类 |
| 强化学习 | 行动后有奖励反馈 | 学会更好的策略 | 游戏 AI、机器人控制 |
1. 监督学习
监督学习的数据通常长这样:
text
输入 X -> 正确答案 y比如房价预测:
| 面积 | 城市 | 楼层 | 房价 |
|---|---|---|---|
| 100 平 | 北京 | 10 层 | 500 万 |
| 80 平 | 上海 | 6 层 | 400 万 |
| 120 平 | 杭州 | 15 层 | 450 万 |
这里:
text
输入 X:面积、城市、楼层
答案 y:房价一句话记忆:
text
有标准答案,就是监督学习。2. 无监督学习
无监督学习没有提前给好的标签。
它不是问:
text
这个样本的标准答案是什么?而是问:
text
这些数据内部有没有自然形成的结构?
哪些样本彼此更相似?比如用户分群:
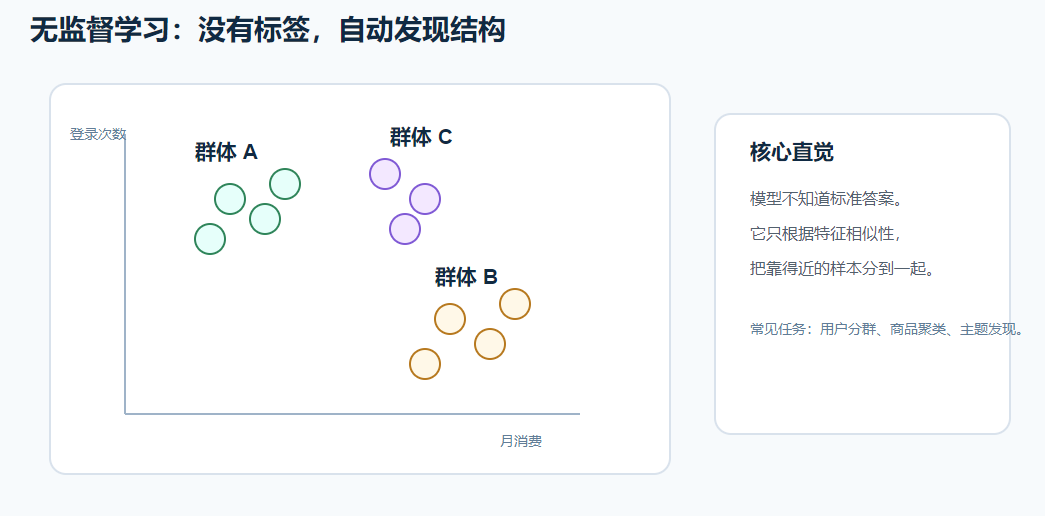
模型可能会自动发现:
text
高消费、高登录频率用户是一类。
低消费、低登录频率用户是一类。一句话记忆:
text
没有标签,让模型自己找结构,就是无监督学习。3. 强化学习
强化学习关注的是:
text
智能体采取行动 -> 环境给奖励或惩罚 -> 智能体改进策略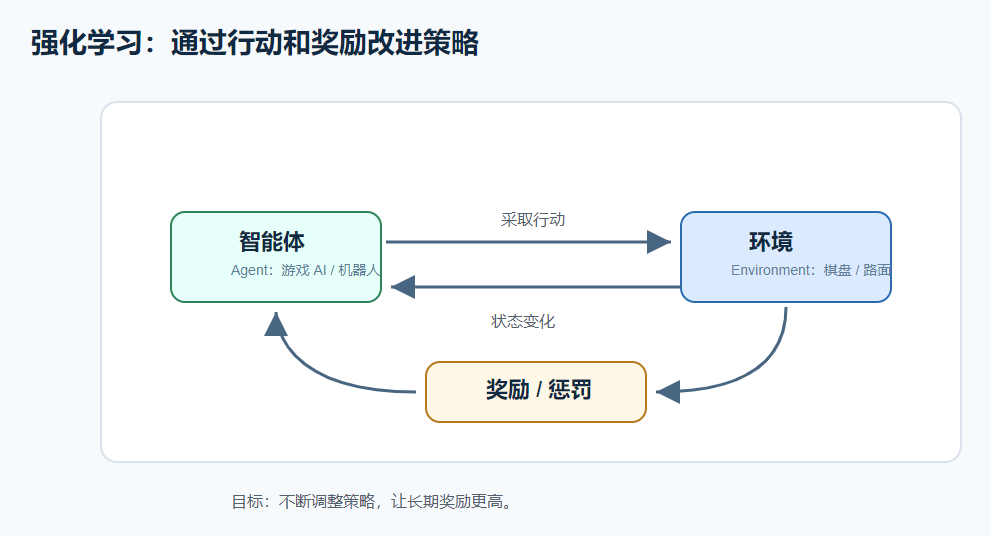
比如游戏 AI:
text
赢了:奖励高
输了:奖励低它不是每一步都有人告诉它标准答案,而是通过不断尝试,学会哪些动作更容易带来长期收益。
三、为什么要划分训练集、验证集、测试集?
机器学习真正关心的不是模型在"见过的数据"上表现多好,而是:
text
模型遇到没见过的新数据时,还能不能表现好。所以我们通常会把数据分成:
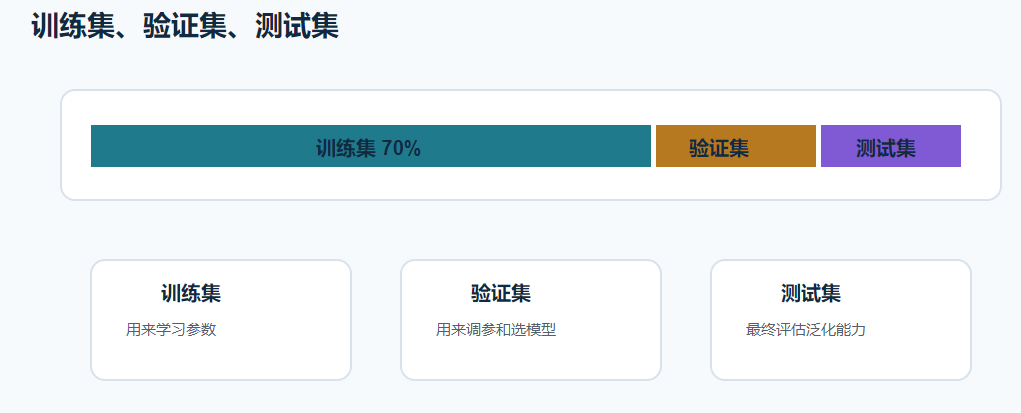
| 数据集 | 作用 | 类比 |
|---|---|---|
| 训练集 | 让模型学习参数和规律 | 平时刷题 |
| 验证集 | 调参、选模型 | 模拟考试 |
| 测试集 | 最终评估泛化能力 | 正式考试 |
如果你把全部数据都拿来训练,然后又用同一批数据测试,就会出现一个问题:
text
模型可能只是记住了训练数据。这就像学生把练习题答案背下来了:
text
练习册原题:100 分
换一套新题:40 分看起来学得很好,其实没有真正掌握规律。
四、过拟合、欠拟合、泛化能力
模型学习状态大致可以分成三种:
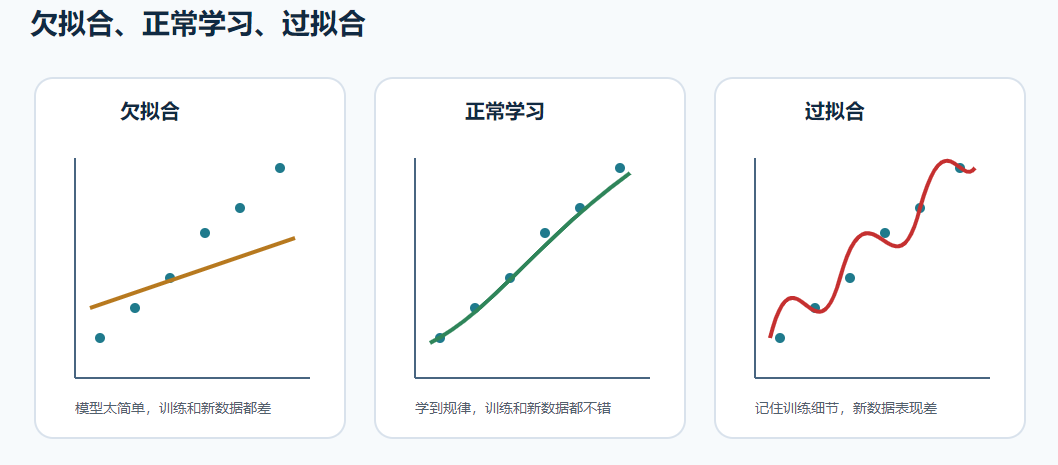
| 状态 | 训练集表现 | 新数据表现 | 问题 |
|---|---|---|---|
| 欠拟合 | 差 | 差 | 没学明白 |
| 正常学习 | 好 | 好 | 学到规律 |
| 过拟合 | 很好 | 差 | 背得太死 |
欠拟合
欠拟合是模型太弱,或者训练不充分,连训练数据里的规律都没学好。
常见表现:
text
训练集表现差
测试集表现也差常见原因:
- 模型太简单
- 特征太少
- 训练不充分
- 数据质量太差
过拟合
过拟合是模型在训练集上表现很好,但在新数据上表现差。
常见表现:
text
训练集准确率 99%
测试集准确率 70%这说明模型可能把训练数据中的细节、噪声、偶然规律都记住了。
缓解过拟合的常见方式:
| 方法 | 直觉 |
|---|---|
| 增加训练数据 | 让模型看到更多变化 |
| 简化模型 | 降低死记细节的能力 |
| 正则化 | 惩罚过度复杂的模型 |
| 早停 | 验证集变差时停止训练 |
| 数据增强 | 让模型看到更多变体 |
一句话总结:
text
欠拟合:旧题新题都不会。
正常学习:旧题新题都还行。
过拟合:旧题很会,新题不会。五、回归、分类、聚类:先看任务类型
很多机器学习问题,先不要急着问"用什么算法",要先问:
text
我要预测的结果是什么?
| 任务 | 目标 | 例子 |
|---|---|---|
| 回归 | 预测连续数值 | 房价、销量、温度 |
| 分类 | 预测离散类别 | 是否欺诈、是否流失、图片类别 |
| 聚类 | 把相似样本分组 | 用户分群、商品分组 |
| 降维 | 压缩特征维度 | 可视化、特征压缩 |
判断口诀:
text
数值预测是回归。
类别预测是分类。
无标签分组是聚类。举几个例子:
| 场景 | 输出结果 | 任务类型 |
|---|---|---|
| 预测房价 500 万 | 连续数值 | 回归 |
| 判断邮件是否垃圾邮件 | 离散类别 | 分类 |
| 预测用户消费等级高 / 中 / 低 | 离散类别 | 分类 |
| 预测用户下月消费金额 | 连续数值 | 回归 |
| 把用户自动分成 5 组 | 无标签分组 | 聚类 |
面试中如果问"分类和回归有什么区别",可以这样答:
text
分类是预测离散类别,比如是否欺诈、是否流失。
回归是预测连续数值,比如房价、销量、温度。
判断时主要看目标变量是类别还是连续值。六、常见算法怎么选?
机器学习算法很多,但初学阶段先建立一个选择地图:
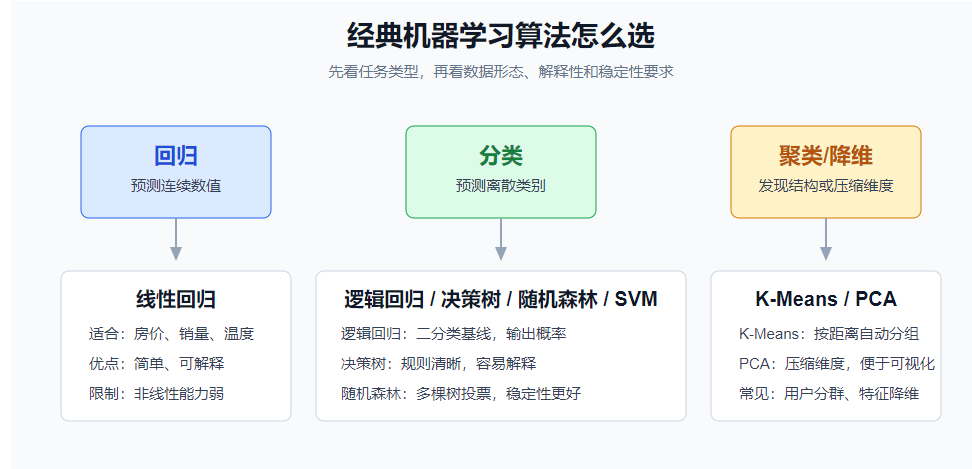
| 算法 | 直觉 | 常见场景 |
|---|---|---|
| 线性回归 | 用一条线拟合数据 | 预测连续值 |
| 逻辑回归 | 输出类别概率 | 二分类基线 |
| 决策树 | 像一组 if-else 判断 | 可解释分类 / 回归 |
| 随机森林 | 多棵树投票 | 稳定性更好 |
| SVM | 找到分类边界 | 中小数据分类 |
| K-Means | 按距离聚类 | 用户分群 |
| PCA | 压缩维度 | 降维、可视化 |
1. 线性回归
线性回归主要用于预测连续数值。
可以粗略理解成:
text
房价 = w1 * 面积 + w2 * 房龄 + w3 * 地段 + b优点是简单、快、容易解释,适合作为回归任务的第一个基线模型。
2. 逻辑回归
逻辑回归名字里有"回归",但常用于分类,尤其是二分类。
比如:
text
用户流失概率 = 0.82然后根据阈值判断:
text
概率 >= 0.5 -> 会流失
概率 < 0.5 -> 不会流失3. 决策树和随机森林
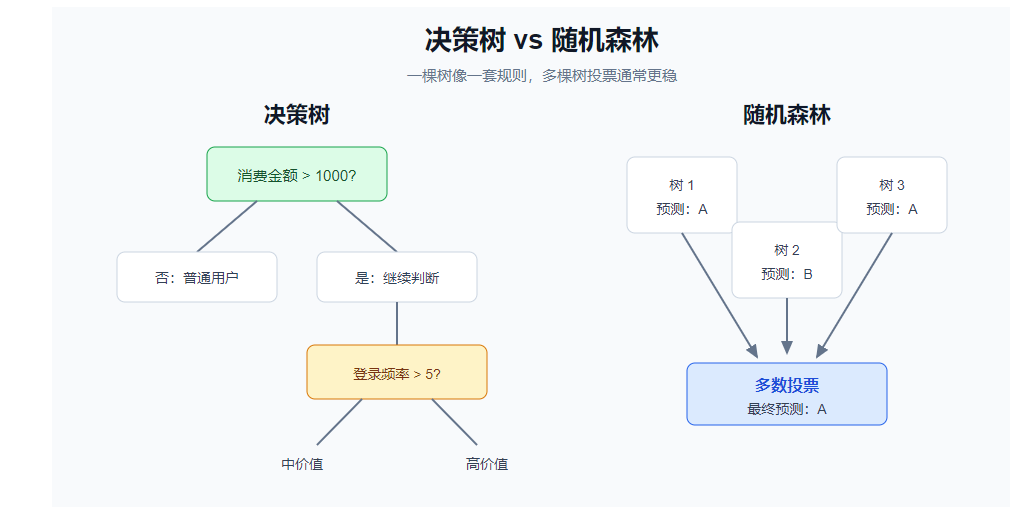
决策树像一组 if-else 规则:
text
如果消费金额 > 1000
再看登录频率是否 > 5
如果是:高价值用户
如果否:中价值用户
否则:普通用户单棵树容易过拟合,所以随机森林让很多棵树一起投票,通常更稳定。
4. K-Means
K-Means 用于没有标签时的自动分组。
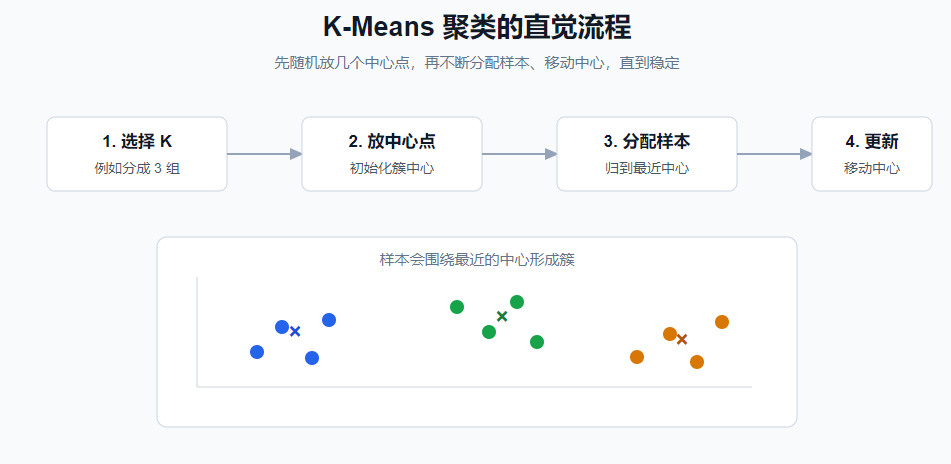
它的大致流程:
text
1. 先指定 K,比如分成 3 组。
2. 随机放 3 个中心点。
3. 每个样本归到最近中心点。
4. 重新计算每组中心点。
5. 重复,直到分组稳定。注意:
text
K-Means 需要提前指定 K。5. PCA
PCA 用于降维,不是直接做预测。
它可以把很多特征压缩成更少的特征,用于:
- 高维数据可视化
- 降低特征维度
- 去除一部分冗余信息
七、模型评估指标:别只看准确率
模型评估指标要和业务目标一致。
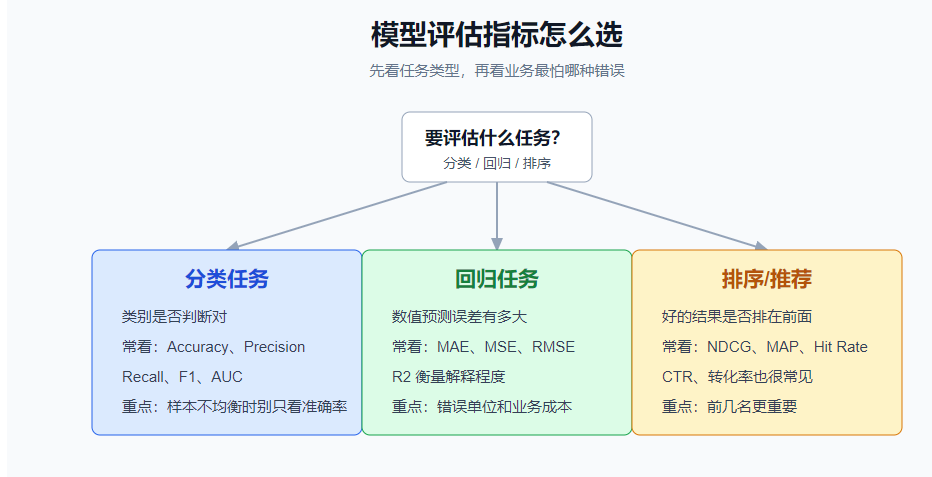
分类任务常看:
text
Accuracy、Precision、Recall、F1、AUC回归任务常看:
text
MAE、MSE、RMSE、R2推荐排序常看:
text
NDCG、MAP、Hit Rate1. 混淆矩阵
分类指标的基础是混淆矩阵。

以欺诈检测为例:
| 名称 | 含义 | 例子 |
|---|---|---|
| TP | 真实是正类,预测也是正类 | 欺诈被抓到 |
| FP | 真实是负类,预测成正类 | 正常交易被误伤 |
| FN | 真实是正类,预测成负类 | 欺诈被漏掉 |
| TN | 真实是负类,预测也是负类 | 正常交易被放行 |
2. Precision 和 Recall
Precision 关注:
text
模型预测为正类的样本里,有多少是真的正类?如果 Precision 低,说明误伤多。
Recall 关注:
text
真实正类里,模型抓出来了多少?如果 Recall 低,说明漏掉多。
可以这样记:
text
怕误伤,看 Precision。
怕漏掉,看 Recall。3. 为什么准确率可能误导?
比如欺诈检测:
text
10000 笔交易里,只有 10 笔欺诈。如果模型全部预测为"正常":
text
准确率 = 9990 / 10000 = 99.9%看起来很高,但一个欺诈都没抓到。
这说明:
text
样本极度不均衡时,只看 Accuracy 很危险。4. 回归指标
回归任务关心预测值离真实值有多远。
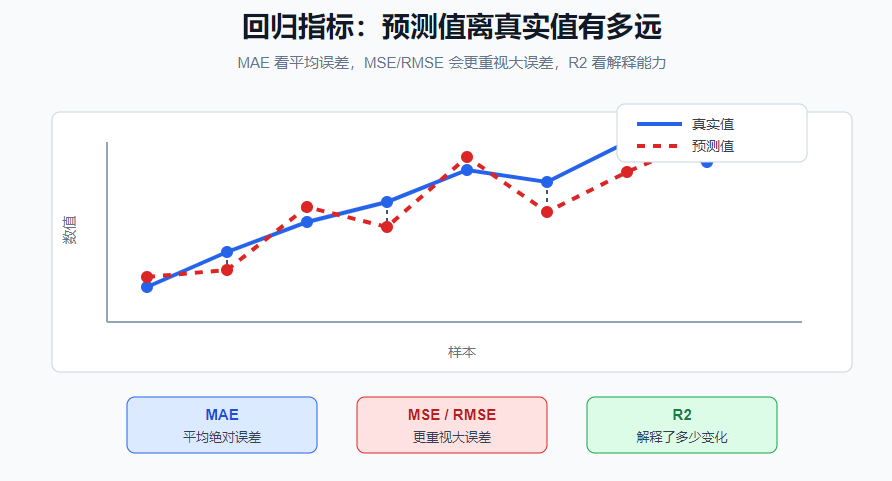
| 指标 | 直觉 |
|---|---|
| MAE | 平均每次预测差多少 |
| MSE | 平方误差,更重视大误差 |
| RMSE | MSE 开方,单位回到原始目标单位 |
| R2 | 模型解释了目标变化的多少 |
如果预测房价,MAE = 20 万,业务方很容易理解:
text
平均预测误差约 20 万。八、一个最小 scikit-learn 实战
下面用鸢尾花数据集做一个分类任务。
重点不是背 API,而是理解机器学习流程:
python
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
data = load_iris()
X = data.data
y = data.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
models = {
"逻辑回归": LogisticRegression(max_iter=200),
"决策树": DecisionTreeClassifier(max_depth=3, random_state=42),
"随机森林": RandomForestClassifier(n_estimators=100, random_state=42),
}
for name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print("模型:", name)
print("准确率:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))这段代码对应:
text
加载数据
-> 划分训练集和测试集
-> 选择多个算法
-> 分别训练
-> 在测试集上预测
-> 用指标评估真实项目里也类似,只是数据准备、特征工程和评估会更复杂。
九、面试中可以怎么回答?
1. 监督学习、无监督学习、强化学习有什么区别?
text
监督学习有输入和标签,目标是学习从输入到答案的映射,比如分类和回归。
无监督学习没有标签,目标是从数据中发现结构,比如聚类和降维。
强化学习通过行动和奖励学习策略,常见于游戏 AI、机器人控制等场景。2. 为什么要划分训练集、验证集、测试集?
text
训练集用于学习参数,验证集用于调参和选择模型,测试集用于最终评估模型在未见过数据上的泛化能力。
如果只看训练集效果,可能无法发现过拟合。3. 什么是过拟合?
text
过拟合是指模型在训练集上表现很好,但在未见过的新数据上表现差。
它说明模型可能记住了训练数据中的细节和噪声,而没有真正学到可泛化的规律。4. 如何选择机器学习算法?
text
我会先看任务类型。
如果是连续数值预测,可以先用线性回归做基线,再尝试树模型或集成模型。
如果是分类任务,可以先用逻辑回归做可解释基线,再尝试决策树、随机森林等模型处理非线性关系。
如果没有标签、目标是用户分群或发现结构,可以考虑 K-Means。
如果特征维度很高,可以用 PCA 做降维或可视化。
实际项目里还要结合数据规模、特征类型、解释性要求、评估指标和上线成本。5. 如何选择评估指标?
text
我会先看任务类型和业务代价。
分类任务中,如果类别均衡,可以看 Accuracy;如果样本不均衡,不能只看准确率,还要结合 Precision、Recall、F1、AUC。
如果业务更怕误伤,比如正常用户被错误拦截,就重点看 Precision。
如果业务更怕漏掉,比如欺诈、疾病筛查、安全风险,就重点看 Recall。
回归任务会看 MAE、MSE、RMSE、R2。
推荐或排序任务会看 NDCG、MAP、Hit Rate。
核心是让评估指标和业务目标一致。十、常见误区
| 误区 | 更准确的理解 |
|---|---|
| 机器学习就是选算法 | 数据、特征、评估同样重要 |
| 训练集效果好就代表模型好 | 还要看测试集和泛化能力 |
| 准确率越高一定越好 | 样本不均衡时准确率可能误导 |
| 逻辑回归只能做回归 | 逻辑回归常用于分类,尤其是二分类 |
| 聚类就是分类 | 聚类通常没有标签,分类通常有标签 |
| 随机森林一定比决策树好 | 效果可能更稳,但解释性通常弱于单棵树 |
| R2 高就一定业务可用 | 还要看实际误差能不能接受 |
十一、本篇小结
这篇文章我们完成了机器学习入门的核心框架:
- 机器学习是从数据中学习规律,并用到新数据上。
- 监督学习有标签,无监督学习没标签,强化学习通过奖励学习策略。
- 训练集用于学习,验证集用于调参,测试集用于最终评估泛化能力。
- 欠拟合是没学明白,过拟合是背得太死,泛化能力是新数据表现。
- 回归预测连续值,分类预测离散类别,聚类做无标签分组。
- 线性回归、逻辑回归、决策树、随机森林、K-Means、PCA 各有适用场景。
- 评估指标要和业务目标一致,不能只看 Accuracy。
- 怕误伤看 Precision,怕漏掉看 Recall,回归看误差,推荐看排序质量。
学到这里,你已经具备了理解传统机器学习项目的基本地图。
十二、下一篇预告
下一篇进入 深度学习。
我们会继续讨论:
- 神经网络基本结构是什么?
- 激活函数、损失函数、优化器分别做什么?
- 反向传播到底在传播什么?
- CNN、RNN、LSTM、GRU 这些网络结构怎么理解?
机器学习像是在学习数据规律,深度学习则进一步让模型拥有更强的特征表达能力。