Loop Engineering描述的问题非常真实:很多 AI Agent 不是输在"模型不会回答",而是输在只会回答一次,做错了不知道怎么继续;工具调用失败了只会重试;任务没有停止条件,越跑越乱。
如果说 Prompt Engineering 关注"怎么问模型",Context Engineering 关注"给模型什么上下文",那么 Loop Engineering 关注的是:如何把 AI Agent 设计成一个可以规划、执行、观察、评估、修正并安全停止的闭环系统。
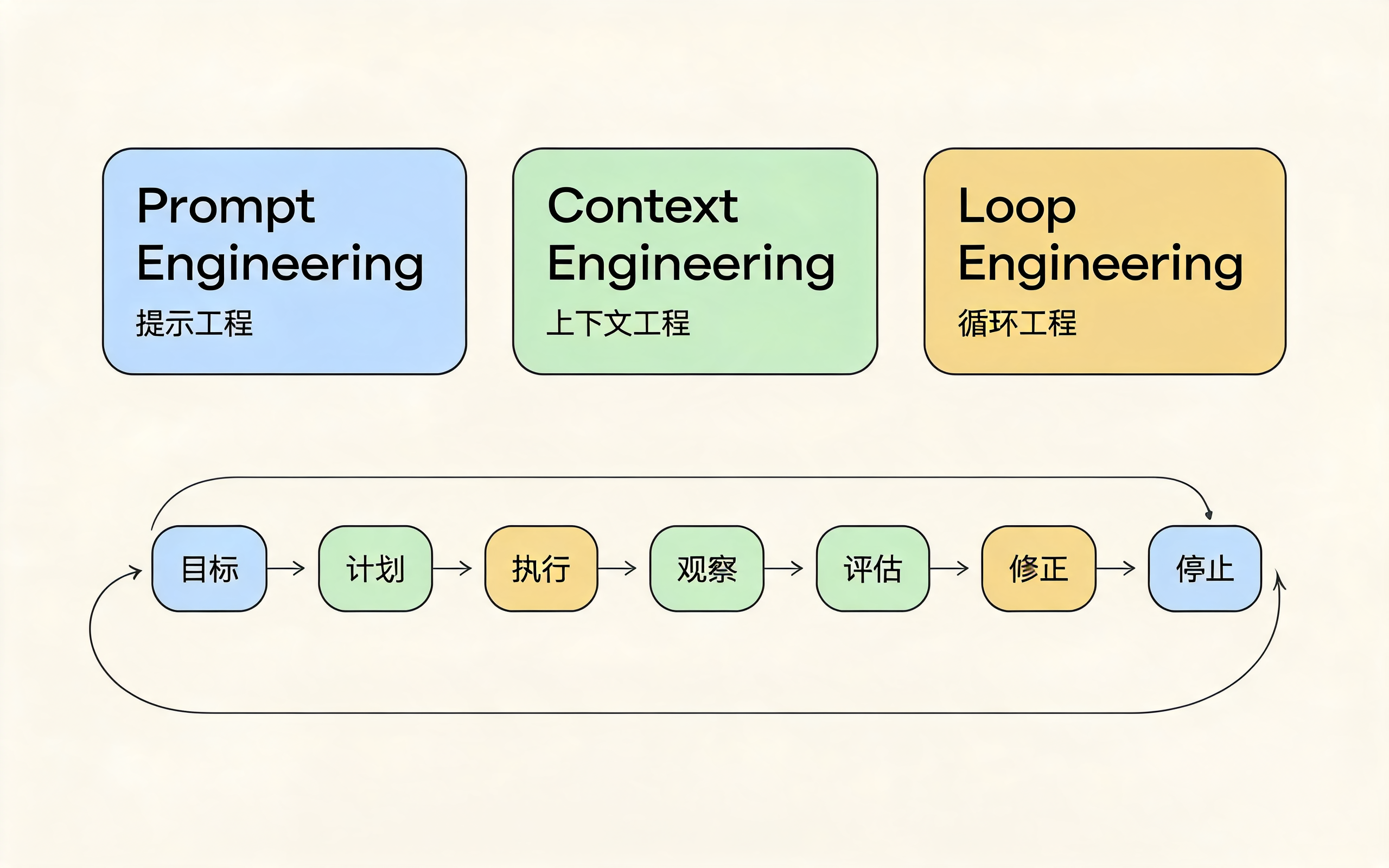
Loop Engineering 视觉摘要:从一次性回答到反馈闭环
文章目录
-
- [一、为什么需要 Loop Engineering](#一、为什么需要 Loop Engineering)
- [二、Loop Engineering 的一句话定义](#二、Loop Engineering 的一句话定义)
- [三、别把 Loop Engineering 等同于"多试几次"](#三、别把 Loop Engineering 等同于“多试几次”)
- [四、一个最小可用的 Agent Loop 模板](#四、一个最小可用的 Agent Loop 模板)
- [五、Loop State:没有状态,就没有真正的闭环](#五、Loop State:没有状态,就没有真正的闭环)
- 六、Observe:工具返回值不是结果,解释后的信息才是观察
- 七、Evaluate:不要让模型自己宣布自己成功
- 八、Repair:失败后不是重试,而是分类纠错
- [九、Stop Condition:Loop 最大的风险是停不下来](#九、Stop Condition:Loop 最大的风险是停不下来)
- [十、三个真实场景下的 Loop 设计](#十、三个真实场景下的 Loop 设计)
-
- [1. 写代码 Loop](#1. 写代码 Loop)
- [2. RAG 幻觉治理 Loop](#2. RAG 幻觉治理 Loop)
- [3. 内容质量优化 Loop](#3. 内容质量优化 Loop)
- [十一、Loop Engineering 和 Prompt Engineering 的区别](#十一、Loop Engineering 和 Prompt Engineering 的区别)
- 十二、落地检查清单
- [十三、最容易踩的 5 个坑](#十三、最容易踩的 5 个坑)
- 一句话结论
一、为什么需要 Loop Engineering
很多人第一次做 Agent,会把流程写成这样:
text
用户输入 → 大模型生成答案 → 返回结果这适合问答,但不适合执行任务。真实业务里的 Agent 经常遇到这些情况:
| 场景 | 一次性回答的问题 | 需要 Loop 的原因 |
|---|---|---|
| 写代码 | 代码看起来对,但测试失败 | 要读取报错、定位原因、修改、再测试 |
| RAG 问答 | 答案流畅,但证据不支持 | 要重新检索、交叉验证、拒答或追问 |
| 工具调用 | API 返回 500 或字段缺失 | 要区分临时错误、参数错误、权限错误 |
| 自动运维 | 指标异常,但原因不确定 | 要观察日志、指标、变更记录并逐步收敛 |
| 内容生成 | 初稿完整,但质量分不高 | 要根据结构、深度、可读性反馈迭代 |
所以 Agent 工程的关键,不是让模型"想得更多",而是让它做完一步后知道下一步该干什么。
这就是 Loop Engineering 的价值。
二、Loop Engineering 的一句话定义
可以把 Loop Engineering 定义为:
面向 AI Agent 和自动化系统的反馈闭环设计方法,通过状态管理、工具执行、外部观察、评估信号、纠错策略和停止条件,让模型从"一次性生成"升级为"可迭代完成任务"。
它解决的不是"模型会不会说",而是:
- 任务怎么拆成多轮步骤;
- 每一轮执行后如何判断结果;
- 失败后应该重试、换策略、降级,还是问人;
- 什么情况下必须停止;
- 如何避免 Agent 自己陷入无限循环。
一个典型 Loop 长这样:
text
Goal → Plan → Act → Observe → Evaluate → Reflect/Fix → Stop or Continue中文可以理解为:
text
目标 → 计划 → 执行 → 观察 → 评估 → 修正 → 停止或继续三、别把 Loop Engineering 等同于"多试几次"
很多项目里的所谓 Agent Loop,本质上只是:
python
for i in range(5):
answer = llm(prompt)
if looks_good(answer):
break这不是 Loop Engineering,只是重复调用。
真正的 Loop 至少要回答四个问题:
| 问题 | 错误做法 | 工程化做法 |
|---|---|---|
| 为什么继续? | 因为还没满意 | 因为某个评估指标未通过 |
| 下一步做什么? | 让模型自己猜 | 根据失败类型选择动作 |
| 记住什么? | 什么都不记 | 保存状态、尝试历史、证据和错误 |
| 何时停止? | 跑到次数耗尽 | 成功、失败、风险升级、人工接管 |
Loop Engineering 的重点不是"循环",而是有反馈、有状态、有边界的循环。
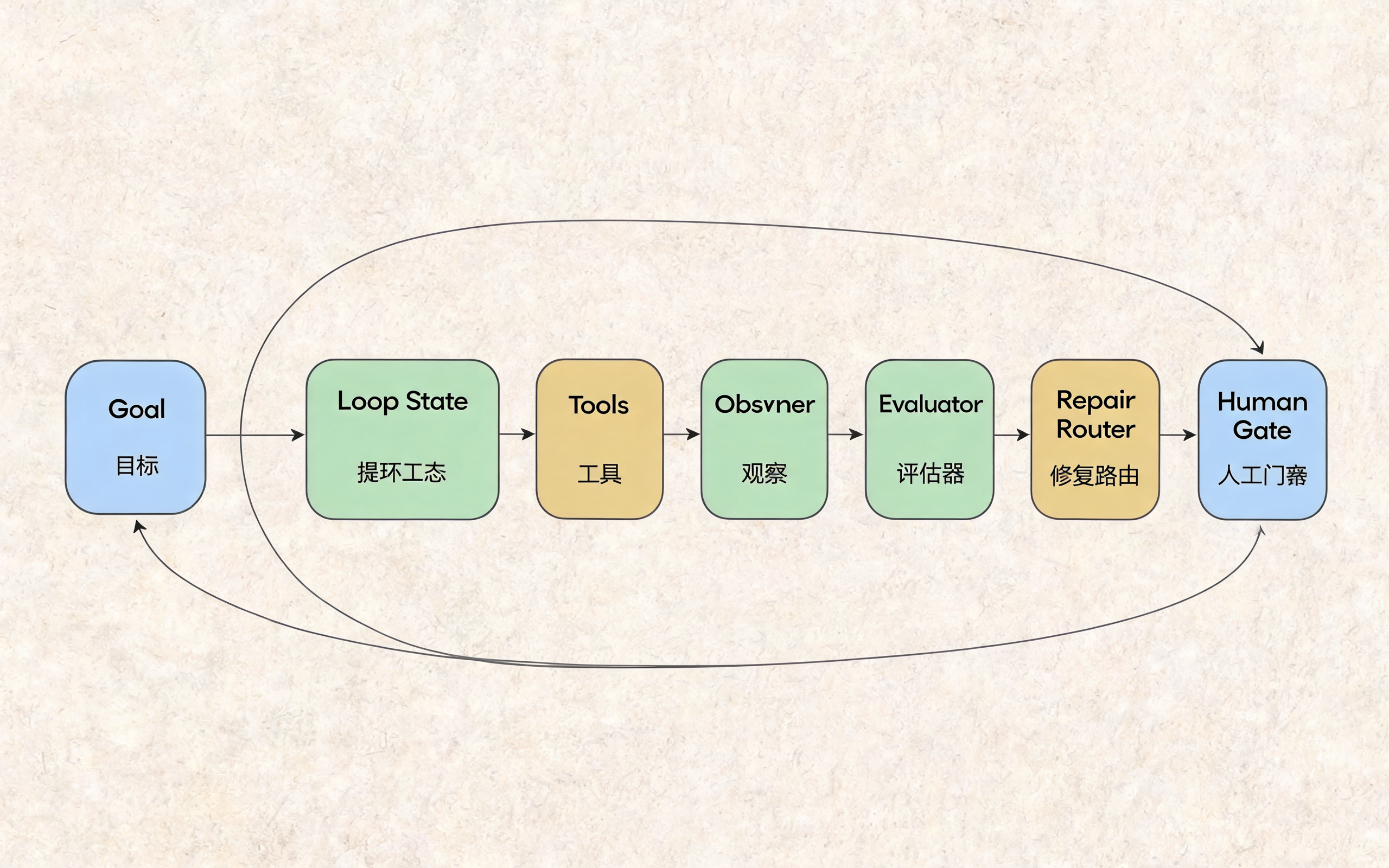
Loop 架构图:状态、工具、观察、评估和人工门禁
四、一个最小可用的 Agent Loop 模板
下面是一个工程上更容易落地的最小 Loop 模板:
python
from dataclasses import dataclass, field
from typing import Any
@dataclass
class LoopState:
goal: str
plan: list[str] = field(default_factory=list)
evidence: list[dict] = field(default_factory=list)
actions: list[dict] = field(default_factory=list)
errors: list[str] = field(default_factory=list)
iteration: int = 0
status: str = "running" # running / success / failed / need_human
MAX_ITERATIONS = 6
def agent_loop(state: LoopState):
while state.status == "running":
state.iteration += 1
if state.iteration > MAX_ITERATIONS:
state.status = "need_human"
state.errors.append("超过最大循环次数,停止自动执行")
break
step = plan_next_step(state)
result = execute_step(step, state)
state.actions.append({"step": step, "result": result})
observation = observe_result(result)
evaluation = evaluate_observation(observation, state)
if evaluation["passed"]:
state.status = "success"
break
if evaluation["risk"] == "high":
state.status = "need_human"
break
state = repair_state(state, evaluation)
return state这个模板里有几个关键点:
LoopState保存当前任务状态;MAX_ITERATIONS限制循环次数;evaluate_observation提供外部评估;- 高风险情况进入
need_human,而不是继续自动执行; - 每一轮行动都记录下来,方便复盘。
五、Loop State:没有状态,就没有真正的闭环
很多 Agent 失败,是因为每一轮都像重新开始。
Loop State 至少要保存这些内容:
| 状态字段 | 作用 |
|---|---|
| goal | 当前任务目标,防止跑偏 |
| plan | 任务拆解和当前步骤 |
| evidence | 已找到的证据、日志、检索结果 |
| actions | 已执行过的工具调用和参数 |
| errors | 已出现的错误和失败原因 |
| constraints | 用户约束、安全边界、禁止动作 |
| iteration | 当前循环次数 |
| status | running / success / failed / need_human |
如果没有状态,Agent 很容易出现三类问题:
- 重复尝试:同一个错误方案反复执行;
- 证据丢失:前一轮查到的信息后一轮不用;
- 目标漂移:修 A 问题时顺手改了 B 模块。
一个更完整的状态可以这样设计:
json
{
"goal": "修复订单退款接口的单测失败",
"constraints": ["不能改数据库结构", "不能跳过测试"],
"current_step": "分析失败日志",
"tried_actions": [
{"action": "run_test", "result": "failed", "error": "status_code expected 200 got 409"}
],
"hypotheses": ["退款状态机缺少处理中分支"],
"evidence": ["test_refund_pending_case", "refund_state_machine.py"],
"iteration": 2,
"status": "running"
}六、Observe:工具返回值不是结果,解释后的信息才是观察
Agent 调用工具后,不能只把原始输出塞回模型。比如运行测试后,工具返回的是一大段日志,但 Loop 需要的是结构化观察:
json
{
"tool": "pytest",
"passed": false,
"failed_cases": ["test_refund_pending_order"],
"error_type": "assertion_error",
"key_message": "expected 200 but got 409",
"suspected_module": "refund_state_machine"
}观察层的作用是把原始结果变成可决策信息。
常见观察类型包括:
| 工具/场景 | 原始输出 | 观察结果 |
|---|---|---|
| 测试工具 | 日志、堆栈 | 哪个 case 失败、错误类型、可能模块 |
| RAG 检索 | 文档片段 | 是否覆盖关键事实、是否冲突 |
| API 调用 | 状态码、响应体 | 参数错、权限错、服务错还是限流 |
| 监控系统 | 指标曲线 | 是否异常、异常窗口、关联变更 |
| 内容评分 | 分数和规则 | 哪些维度弱、是否需要重写 |
没有 Observe 层,Agent 很容易把"看见了输出"误当成"理解了结果"。
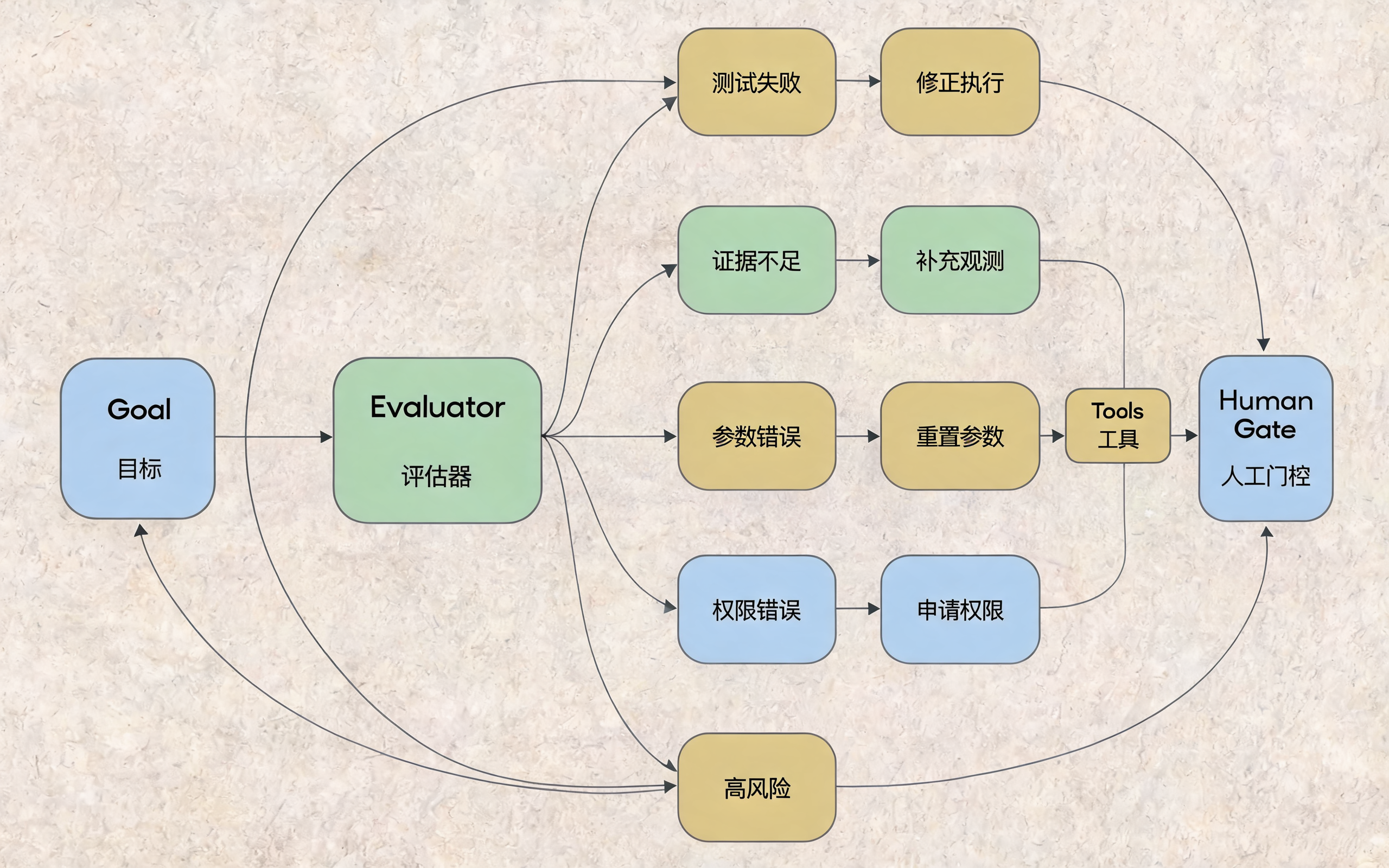
评估与纠错闭环:失败不是重试,而是分类处理
七、Evaluate:不要让模型自己宣布自己成功
Loop Engineering 里最重要的一点是:评估信号要尽量外部化。
比如写代码不能只问模型:
text
你觉得代码修好了吗?而应该运行:
bash
pytest tests/test_refund.py -qRAG 问答不能只看答案是否流畅,而要检查:
- 是否引用了证据;
- 证据是否真的支持结论;
- 是否出现无证据断言;
- 证据之间是否冲突;
- 高风险问题是否触发确认。
一个评估结果可以设计成:
json
{
"passed": false,
"score": 0.72,
"failed_rules": [
"missing_evidence_for_refund_policy",
"tool_call_without_confirmation"
],
"risk": "high",
"next_action": "ask_human"
}评估层决定 Loop 是继续、修正、失败还是人工接管。
八、Repair:失败后不是重试,而是分类纠错
失败后的处理策略,决定了 Loop 是工程系统还是随机游走。
推荐把失败分成几类:
| 失败类型 | 例子 | 推荐策略 |
|---|---|---|
| 临时错误 | 网络超时、502 | 有上限地重试 |
| 参数错误 | API 字段缺失 | 修参数,不重试原请求 |
| 权限错误 | 403、无 token | 停止并请求授权 |
| 证据不足 | RAG 没召回关键规则 | 换查询、扩展检索或追问 |
| 目标冲突 | 用户要求和系统规则冲突 | 停止并解释 |
| 高风险动作 | 删除、付款、重启、发消息 | 必须人工确认 |
可以写成一个简单的修复路由器:
python
def choose_repair_strategy(evaluation):
error_type = evaluation.get("error_type")
risk = evaluation.get("risk")
if risk == "high":
return "ask_human"
if error_type in ["timeout", "rate_limit"]:
return "retry_with_backoff"
if error_type == "bad_argument":
return "fix_arguments"
if error_type == "missing_evidence":
return "retrieve_more"
if error_type == "permission_denied":
return "stop_and_request_auth"
return "stop_with_reason"这比"失败就再来一次"可靠得多。
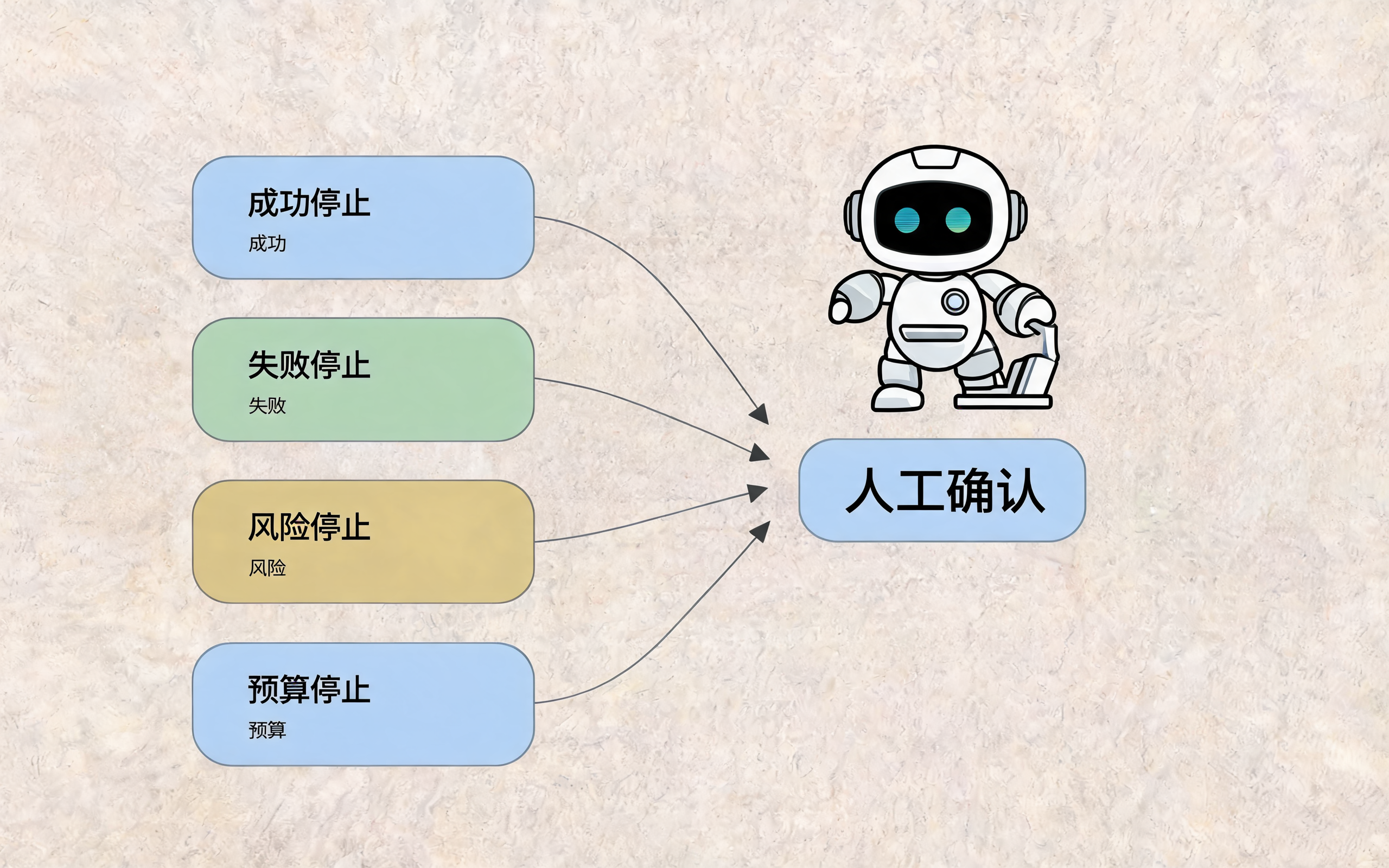
停止条件检查卡:成功、失败、风险和预算
九、Stop Condition:Loop 最大的风险是停不下来
Loop Engineering 一定要把停止条件写清楚。
常见停止条件有四类:
| 停止类型 | 触发条件 | 结果 |
|---|---|---|
| 成功停止 | 测试通过、评估达标、用户确认 | 输出结果 |
| 失败停止 | 明确不可完成、依赖缺失 | 给出失败原因 |
| 风险停止 | 涉及高风险动作或权限不足 | 请求人工确认 |
| 预算停止 | 次数、时间、成本达到上限 | 汇报当前进展 |
建议每个 Agent Loop 至少配置:
yaml
loop_policy:
max_iterations: 6
max_tool_calls: 20
max_minutes: 15
stop_on_high_risk: true
require_human_for:
- payment
- deletion
- publish
- restart_service
- external_message如果没有停止条件,Agent 可能会:
- 一直重试同一个错误;
- 为了完成任务越权调用工具;
- 把小问题扩大成大范围改动;
- 消耗大量 token 和 API 费用。
十、三个真实场景下的 Loop 设计
1. 写代码 Loop
text
读取需求
→ 定位相关文件
→ 修改代码
→ 运行测试
→ 分析失败日志
→ 修复
→ 再测试
→ 通过后总结变更关键评估信号:测试结果、lint、类型检查、代码 diff。
停止条件:测试通过;超过次数;改动范围超出预期;需要产品确认。
2. RAG 幻觉治理 Loop
text
用户问题
→ 风险识别
→ 检索证据
→ 生成带引用答案
→ 校验证据是否支持结论
→ 不支持则重新检索/拒答/追问关键评估信号:证据召回率、引用准确率、无证据断言比例。
停止条件:证据足够;证据冲突;问题超出知识库;高风险动作需要确认。
3. 内容质量优化 Loop
text
生成初稿
→ 检查标题、结构、案例、代码、图表
→ 找出薄弱项
→ 局部重写
→ 再评分
→ 达标后保存草稿关键评估信号:结构完整度、原创洞察、工程可复现、读者收益、平台质量分。
停止条件:达到目标分;多轮无提升;主题本身平台识别弱;需要人工反馈。
十一、Loop Engineering 和 Prompt Engineering 的区别
| 维度 | Prompt Engineering | Loop Engineering |
|---|---|---|
| 关注点 | 单次输入怎么写 | 多轮任务怎么闭环 |
| 核心对象 | Prompt | 状态、工具、评估、停止条件 |
| 成功标准 | 回答更好 | 任务完成且可验证 |
| 主要风险 | 提示词不清楚 | 无限循环、越权、错误重试 |
| 典型产物 | Prompt 模板 | Loop Policy、State、Evaluator、Repair Router |
Prompt Engineering 仍然重要,但它只是 Loop 里的一个组件。
一个成熟 Agent 往往需要:
text
Prompt Engineering + Context Engineering + Tool Engineering + Loop Engineering + Evaluation Engineering其中 Loop Engineering 负责把这些能力串成可执行闭环。
十二、落地检查清单
如果你正在做一个 Agent,可以用下面这张清单自检:
| 检查项 | 是否具备 |
|---|---|
| 任务目标是否结构化保存 | ✅ / ❌ |
| 每一轮是否记录执行动作和结果 | ✅ / ❌ |
| 工具输出是否被解析成观察对象 | ✅ / ❌ |
| 是否有外部评估信号,而不是模型自评 | ✅ / ❌ |
| 失败是否按类型选择修复策略 | ✅ / ❌ |
| 是否限制最大循环次数和工具调用次数 | ✅ / ❌ |
| 高风险动作是否必须人工确认 | ✅ / ❌ |
| 是否能解释为什么停止 | ✅ / ❌ |
| 是否把失败样本沉淀到评估集 | ✅ / ❌ |
如果这些问题大部分是"否",那这个 Agent 还只是一个会调用工具的聊天机器人。
十三、最容易踩的 5 个坑
- 把 Loop 写成无限 while:没有次数、时间和成本上限,迟早会失控。
- 失败只会重试:参数错、权限错、证据不足,不能用同一种策略处理。
- 让模型自己判断成功:没有测试、评分、证据校验,成功只是幻觉。
- 不保存尝试历史:Agent 会忘记自己刚刚失败过,又走回老路。
- 高风险动作不设门禁:Loop 一旦能调用真实工具,安全边界比回答质量更重要。
一句话结论
Loop Engineering 的核心不是"让 Agent 多跑几轮",而是设计一套有目标、有状态、有观察、有评估、有纠错、有停止条件的反馈闭环。只有这样,AI Agent 才能从一次性回答问题,走向可验证、可复盘、可安全交付的任务执行系统。