大家好,我是子昕。
这次测完 Kimi K2.7 Code,我最想说的不是"它很快"。
快是真的快。
高速版刷代码、读文件、跑命令、写总结的时候,等待感明显少很多。
但对个人开发者和团队负责人来说,更关键的问题是:它到底能不能进真实工程工作流?
我的结论是:可以进,但位置要摆对。
我现在对它的定位也更清楚:速度很快、多模态可用、整体发挥稳定,适合程序员拿来做第一轮工程任务。
比如前端复刻、截图/录屏反馈后修 UI、内部工具、本地 CRUD / CLI、第一轮代码审查,这些场景里,它都可以作为一个很实际的选择。
它适合做第一轮实现、前端/脚本的快速成型、局部修复和代码审查;涉及架构边界、业务状态机、高风险业务链路、权限和数据变更的地方,还是要人来拍板。
所以这次我没有只看 benchmark,而是直接给 Kimi K2.7 Code 安排了 4 个任务:
| 测试项目 | 为什么测它 | 主要看什么能力 |
|---|---|---|
从零实现 logq 日志查询 CLI |
小而完整,接近日常开发工具 | 需求理解、代码组织、测试、命令行输出 |
| 根据录屏实现 LogQ Viewer 前端 | 模拟"看设计/录屏做页面" | 多模态理解、前端实现、交互还原 |
| SQLite 工单管理系统 | 本地完整 Agent 工具链 | 文件修改、数据库、服务启动、浏览器验证 CRUD |
| 大型 Java 项目代码审查 | 真实复杂业务仓库 | 长上下文代码阅读、跨模块对比、业务边界判断 |
如果你是个人开发者,这篇可以帮你判断哪些任务可以放心先丢给它跑一版。
如果你是团队负责人,更适合关注它怎么接进试点流程,以及哪些环节必须保留人工 review。
先说结论。
Kimi K2.7 Code 高速版给我的第一印象,是快、稳,而且能把不少真实工程任务跑完整。
小型端到端任务,它完成得不错。
前端录屏复刻,它能做出可用版本。
本地工具链任务,它能把数据库、服务、浏览器验证串起来。
到了真实大型业务项目,它也能发现问题。更适合的用法,是先让它做第一轮审查和局部修复,再由人来做最终取舍。
Kimi K2.7 Code 是什么
这段简单过一下。
Kimi K2.7 Code 是月之暗面新发布并开源的 coding 模型,也是 Kimi 现在主打编程和 Agent 任务的模型。
几个和开发者最相关的点:
- 面向 coding 和 agent 任务
- 支持 256K 上下文
- K2.7 Code 必须开启 Thinking 模式
- 相比 K2.6,reasoning token 使用量降低 30%
- 目标是提高端到端编码任务成功率
如果你已经用过 Codex、Claude Code、GLM、MiniMax 这些工具,应该知道现在真正拉开差距的不是"能不能写代码"。
重点是它进项目之后,能不能读懂上下文、改对文件、跑完验证,并且中途出错时继续收敛。
我这次主要用的是 Kimi Code。
这张图基本说明了 Kimi Code 最省心的地方:登录授权很简单。
我这里基本就是打开网页,一键授权,然后终端里就能用了。不需要自己先去创建 API Key,再到处配置环境变量。
如果你习惯 Claude Code、Roo Code、Cline、OpenCode 这些第三方 CLI,也可以走 API Key 的方式接入。
高速版怎么获取
这里补一个实际使用信息:我这次用到的高速版,是通过 Kimi Code 的「抢先体验计划」申请拿到的。
申请成功后,可以在 Kimi Code 页面里切换 K2.7 Code 和 K2.7 Code 高速版;切到高速版后,下次调用 Kimi-For-Code 模型时会自动生效,不需要再去工具里手动改配置。
页面里也写得很清楚,高速版是 6x 速度、3x 消耗;抢先体验版本可能包含未完全验证的功能,如果遇到不稳定,也可以切回稳定版本。
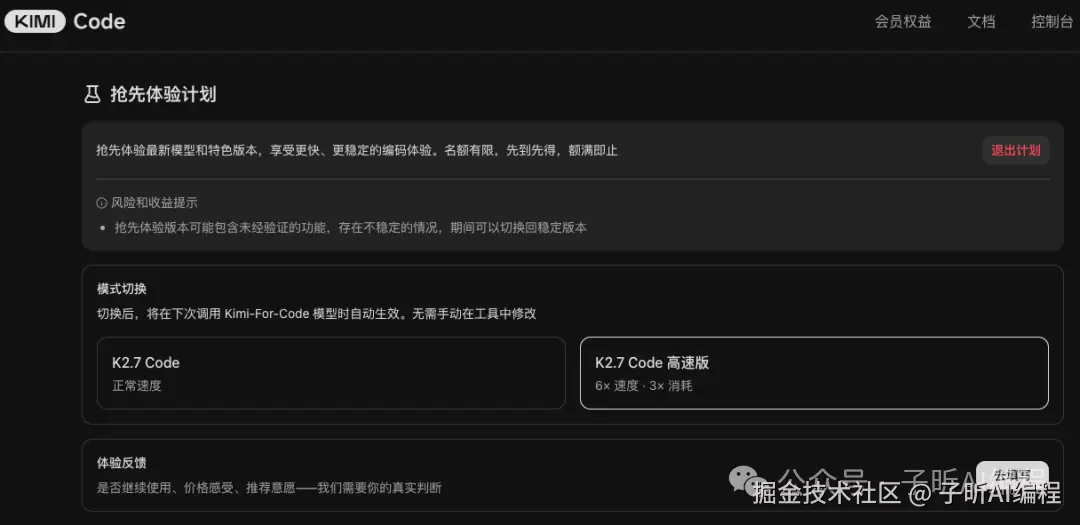
这张图是 Kimi Code 的抢先体验计划页面,可以在这里切换 K2.7 Code 和 K2.7 Code 高速版。
价格不展开讲太细,主要讲怎么选。
Kimi K2.7 Code 普通版 API,标准输入是 6.5 元 / 百万 token,输出是 27 元 / 百万 token,命中缓存的输入是 1.3 元 / 百万 token。
高速版和普通版是同一个模型,输出速度约 5-6 倍,常规编程场景大约 180 token/s,短上下文场景可到 260 token/s。
高速版 API 价格是普通版的 2 倍;在 Kimi Code Plan 里,高速版用量消耗是普通版的 3 倍。
我的理解是:
- 小脚本、一次性任务,不一定非要高速版
- 连续交互、前端调试、长任务闭环,高速版更有价值
- 团队试点要算成本,尤其是多人长时间跑 Agent 的场景
我这次主要是在高速版里测的。
实际体感上,这个速度对 coding agent 影响很大。
以前你让模型改一个项目,经常是"等它想、等它写、等它跑",中间很容易走神。
高速版更像是你刚把需求说完,它就已经开始连续刷代码了。
当然,速度只是体验的一部分。
所以后面还是要看它在真实任务里的表现。
第一关:从零实现一个日志查询 CLI
这关翻译成人话,就是测它能不能把一个小型内部工具从 0 到 1 做完整。
第一个任务,我没有让它写 Todo App。
我让它从零实现一个叫 logq 的日志查询 CLI。
要求不算复杂,但很完整:
- 支持三种日志格式解析
- 支持按时间、级别、关键词过滤
- 支持 JSON 和表格输出
- 支持多个日志文件
- 无法解析的行要保留成
UNKNOWN - 要写 README、sample.log 和自动化测试
这个任务适合测什么?
我想看的是它能不能把一个小工具做完整,而不是只写一段能跑的脚本。
最后它交付出来的结构是这样的:
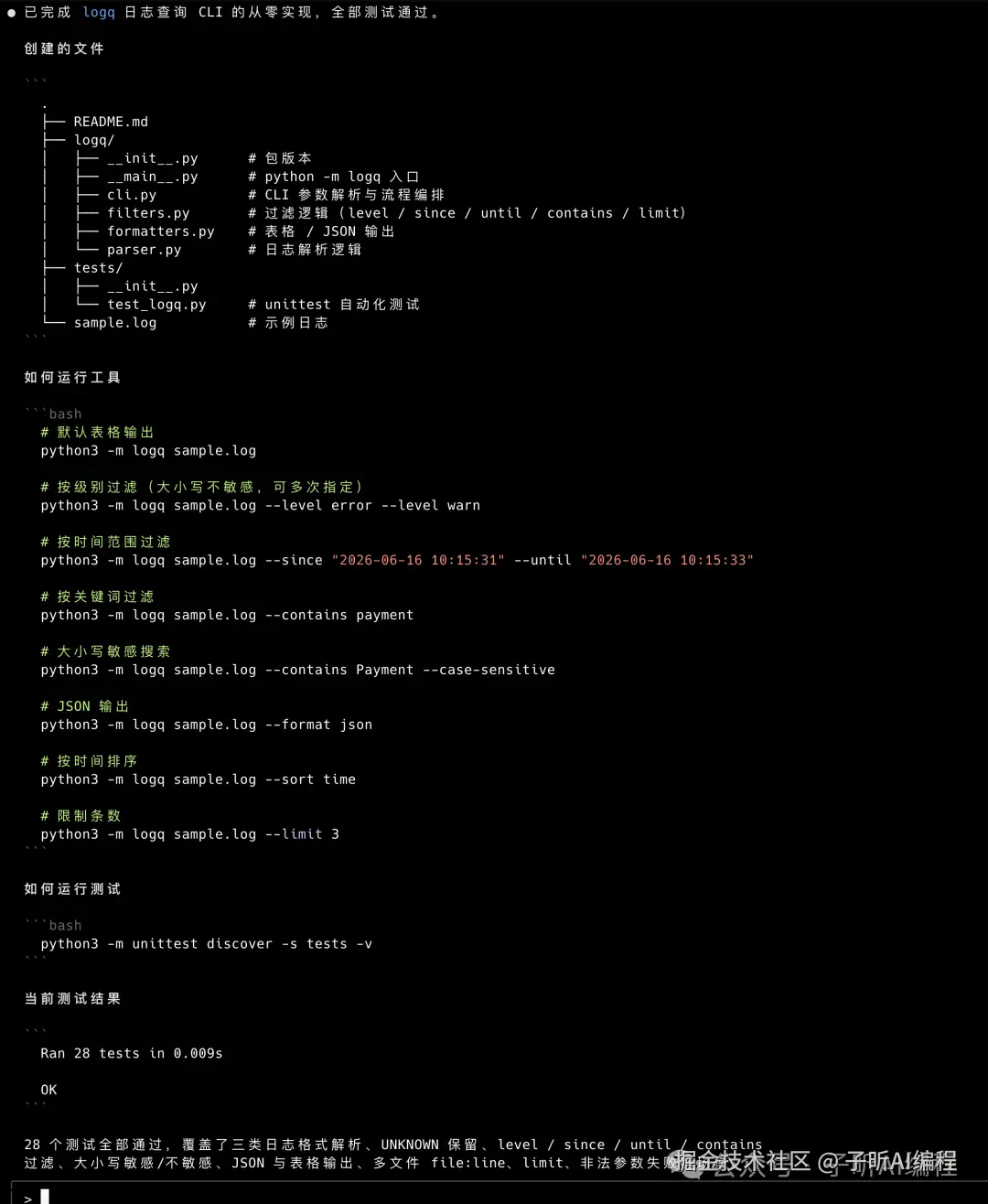
这张图看的是项目结构,不是看"代码多不多"。
我更关心它有没有把解析、过滤、输出、CLI 入口拆开,而不是一股脑塞进一个脚本里。
这个结果我觉得是不错的。
它没有把所有逻辑塞进一个文件,而是拆成了 parser、filters、formatters、cli 几个模块。
测试也补了。
一共 28 个 unittest,覆盖了三种日志格式、UNKNOWN 保留、level 过滤、since/until、contains、JSON 输出、表格输出、多文件、limit、非法参数这些场景。
为了不是只看它自己给的 sample.log,我又生成了一批大日志文件来测。
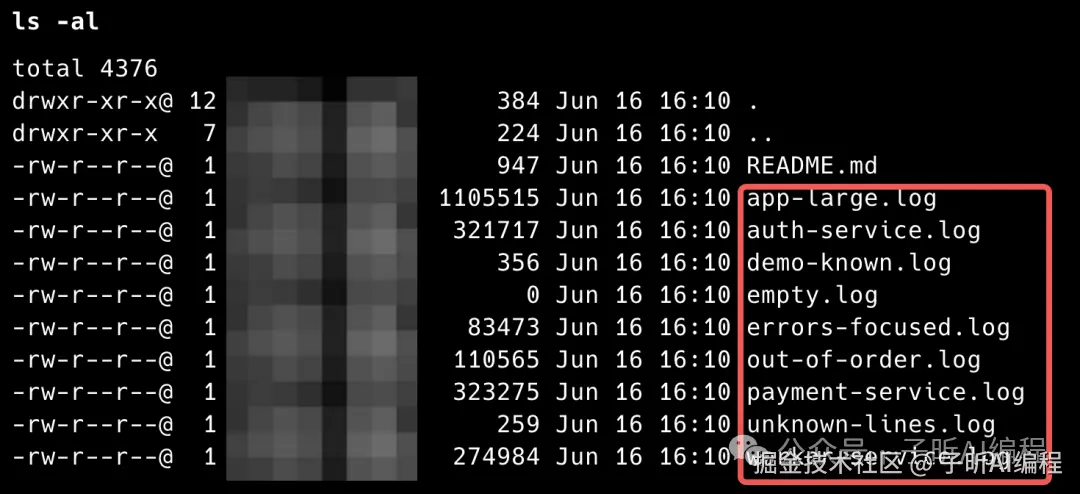
然后跑了几组命令。
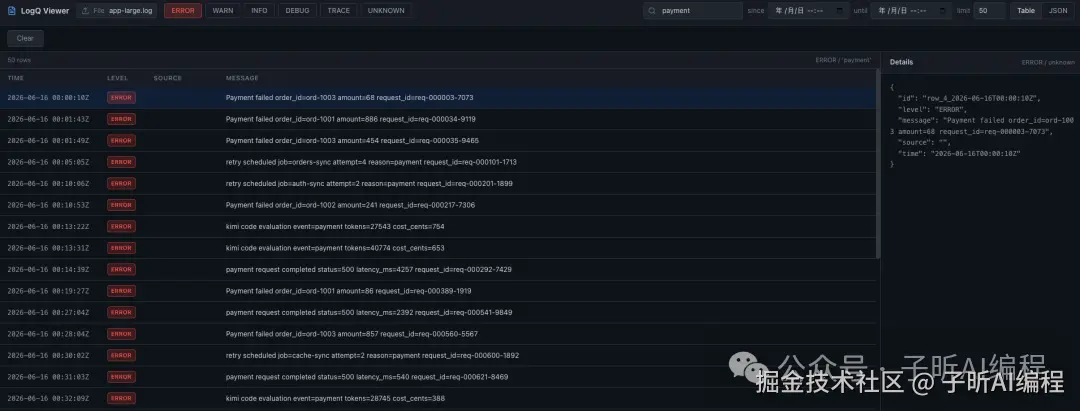
第一组,按 ERROR 过滤,并限制输出 10 条。
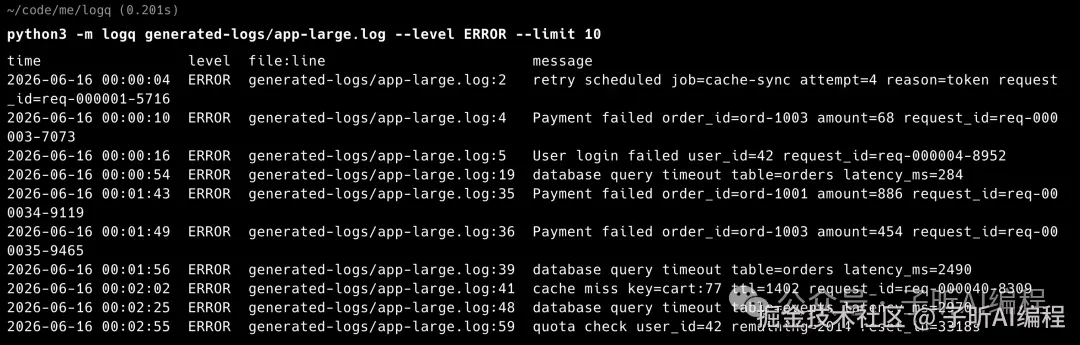
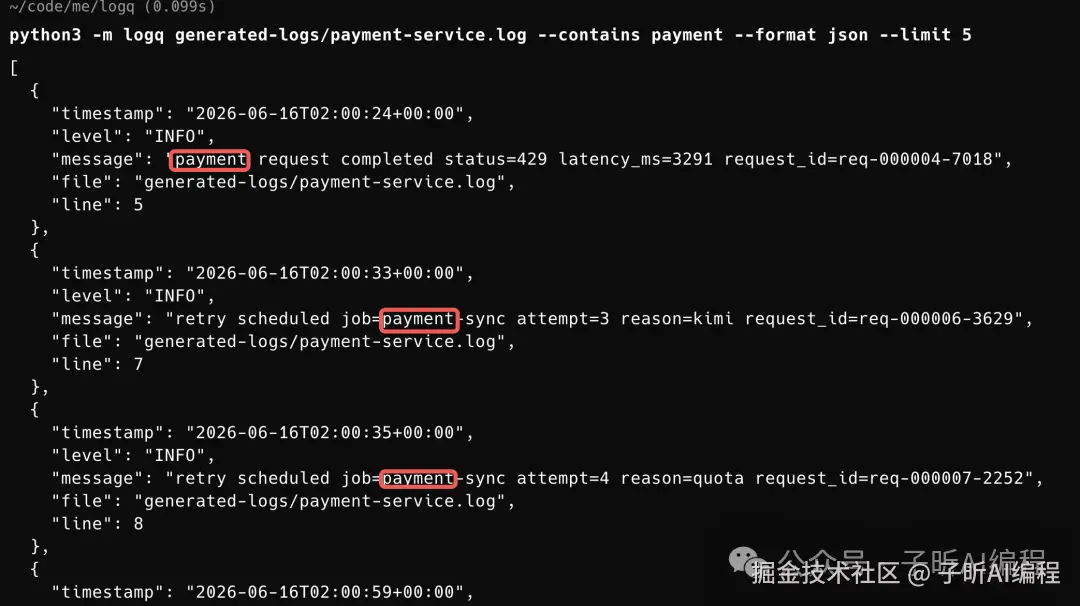
第二组,按关键词 payment 过滤,并输出 JSON。
第三组,多文件输入,再加时间范围过滤。
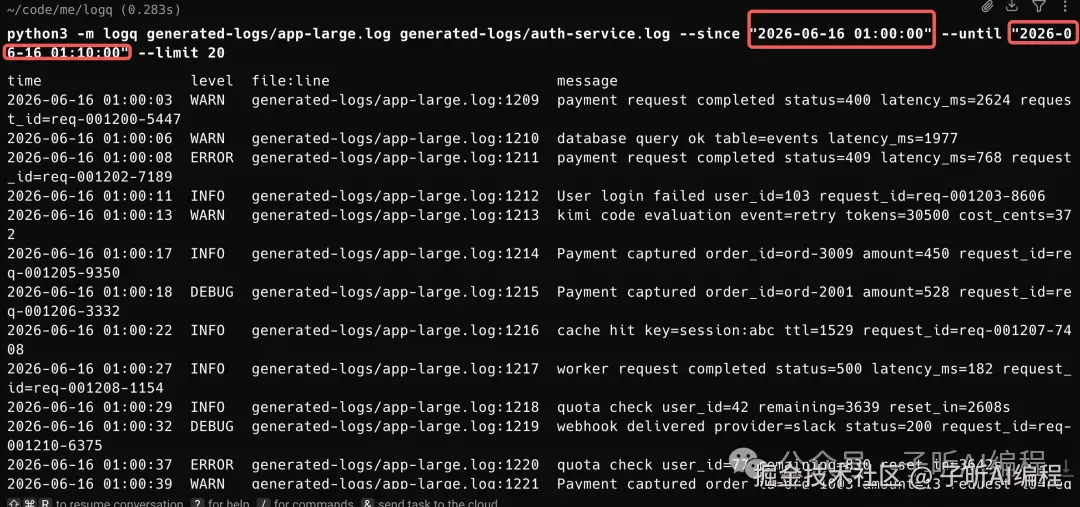
这几张命令行截图主要说明一件事:它不是只在自己准备的 demo 数据里能跑,换成更大的日志文件、多条件组合过滤,也能走通。
这关我的评价比较明确:
Kimi K2.7 Code 做这种小型端到端工具,完成度是可以的。
它能从需求拆到文件结构、实现、测试和 README,而不是只停在"写出主要逻辑"这一步。
这种任务放在真实工作里,其实很常见。
比如写一个内部脚本、做一个日志分析工具、补一个命令行小工具。
以前可能要你自己花半小时到一小时,现在可以先让它跑一版,然后人来验收和调整。
我原本担心它会把功能写散,最后只交一个"能跑但不好维护"的脚本。实际结果还行,至少第一版已经有工程结构了。
第二关:看录屏做前端
这关翻译成人话,就是测它能不能看懂一个已有交互,再把它复刻成可用页面。
第二个任务,我想测多模态和前端能力。
但我不想让它凭空设计一个页面,因为那样很容易变成"审美玄学"。
所以我先做了一个用于录屏的目标页面。
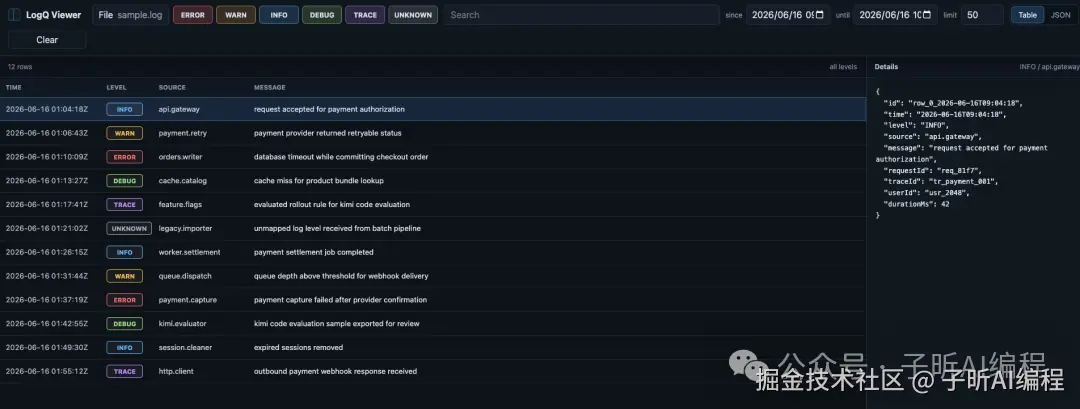
然后录了一段操作视频。
视频里大概展示这些内容:
- 顶部筛选栏
- level 多选
- 日志表格
- 右侧详情面板
- 搜索
payment - Table / JSON 视图切换
- 无结果状态
- Clear 恢复默认
然后我让 Kimi Code 根据这个录屏实现一个 LogQ Viewer。
它拿到任务后,先做了计划。
这个过程我觉得比结果更值得看。
因为前端任务不是"写一个页面"这么简单。它要先看懂录屏里的信息结构,再落到组件、状态、交互、样式。
最后它做出来的页面是这样的:
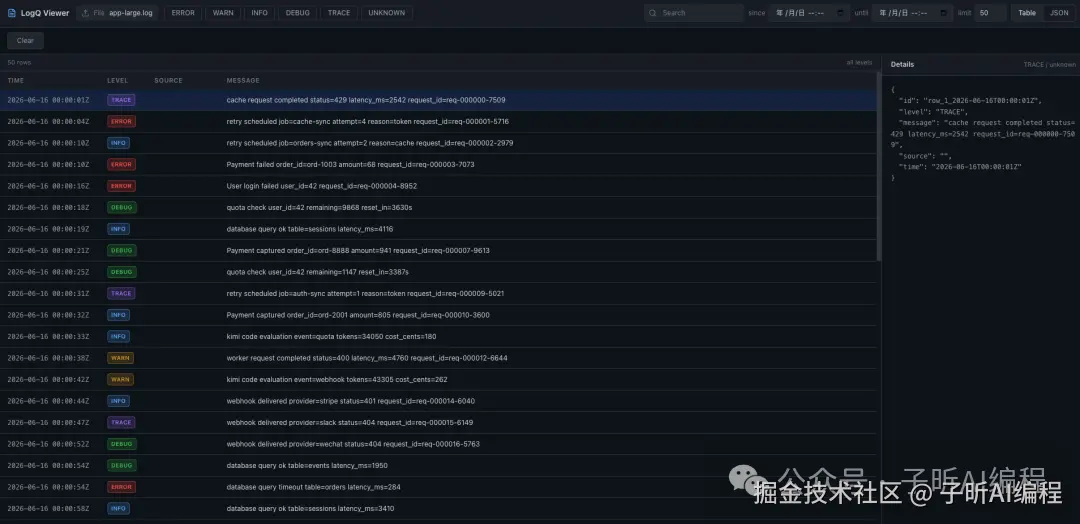
我上传了大日志文件,页面能解析并展示出来。
首页这张图看的是基础还原度:筛选栏、日志表格、详情区域、状态分布这些骨架有没有搭起来。
点击一条 ERROR 日志,左侧表格高亮,右侧展示 JSON 详情。搜索 payment 后,表格会只保留相关日志。
这张筛选和详情图更关键。它说明这个页面不是静态截图,而是有真实筛选、选中、高亮和详情联动。
这个任务里,我觉得它有两个表现不错的地方。
第一,它能把录屏里的结构还原出来。
左侧表格、右侧详情、顶部过滤栏、Table / JSON 视图切换,这些都在。
第二,它能把前一个 CLI 项目的能力迁移到前端形态。
前面 logq 是命令行过滤日志,这里变成了浏览器里上传文件、表格查看、搜索过滤、点击详情。
前端这块也有一个很真实的点。
第一版并不是截图级完美,但视频里的页面结构和主要交互基本都复刻出来了。
我之前点日志行的时候,视觉上会像全选了一样。这个后来修了,原因是默认 mock 数据没有稳定 id,点击后所有 undefined id 都被当成选中。
所以这个小 bug 更像是前端状态处理 / 数据建模问题,不是没看懂视频。
这类细节其实很适合用来测前端 Agent:
它不只是要把页面搭出来,还要能根据反馈继续修交互。
所以多模态这块,我的感受是可用的,尤其适合前端复刻、截图反馈修 UI 这类程序员日常场景。
真实场景里,我会把它用在"先把管理页、调试页、内部工具页搭出来"这类任务上。
视觉细节和复杂设计系统还要人继续磨,但第一版结构可以让它先跑。
第三关:SQLite 工单系统
这关翻译成人话,就是测它能不能把前端、后端、数据库和浏览器验证串成一个闭环。
第三个任务,我专门设计成 Agentic 工具链。
不是只写前端,也不是只写后端,而是让它完成一条本地闭环:
读需求文档,改代码,写 SQLite migration,启动服务,用浏览器验证 CRUD,再生成 changelog。
我给的任务是实现一个本地工单管理系统。
要求包括:
- SQLite 表
tickets - migration / 初始化脚本
- CRUD API
- 前端页面
- 创建、搜索、编辑、删除
- 自动化测试
- changelog
- 浏览器验证
这个任务测的是它到底会不会"干活"。
因为它必须把几个东西串起来:文件、数据库、后端服务、前端页面、浏览器验证。
最后页面长这样:
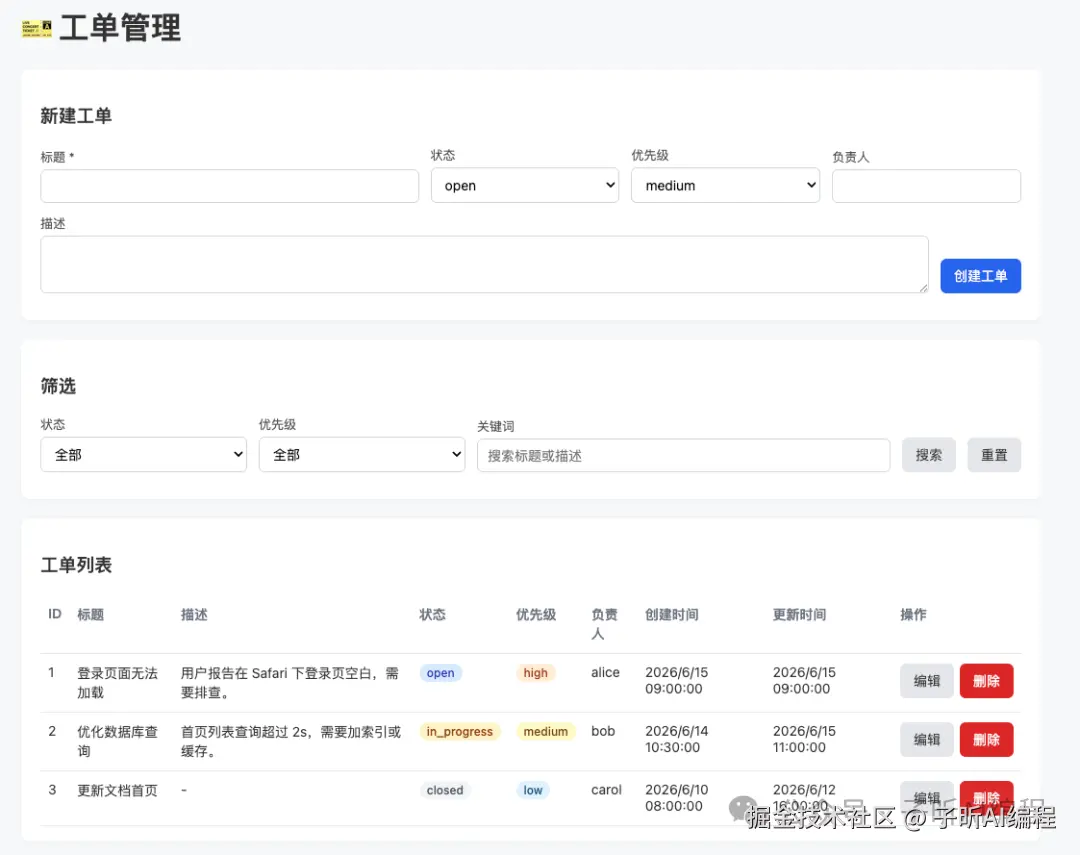
我实际在浏览器里跑了一遍。
创建一条工单,搜索它,进入编辑态,把状态改成 in_progress,优先级改成 urgent,负责人改成 zixin,保存后页面能看到更新时间变化。
这关的价值不在 UI 多好看。
说实话,这个 UI 很普通,就是一个能用的后台页面。
但它证明了一件事:Kimi Code 不只是写代码,它能把本地工程链路跑起来。
对开发者来说,这个很重要。
很多时候我们要的不是一段漂亮代码,而是一个能启动、能验证、能修改的本地闭环。
这个任务里,它做到了。
我原本担心它会卡在 migration、服务启动或者浏览器验证其中某一环。结果这条链路是能闭上的。
真实项目里,这类本地 CRUD、临时后台、数据修复工具,可以让它先做第一轮实现。
第四关:真实大型 Java 项目审查
这关翻译成人话,就是测它进入复杂业务仓库后,能不能做一个靠谱的第一轮 reviewer。
前三个任务都是我设计的沙箱任务。
第四个,我换成了真实项目。
这里涉及公司内部系统,所以我把具体项目名、平台名、类名、接口路径、字段名和业务对象都做了脱敏,只保留任务类型和工程判断。
我在一个现有大型 Java 项目里,让 Kimi 审查一个复杂任务执行链路,并要求它对照另一个已经比较成熟的实现。
这个任务比前面几个难很多。
因为它不只是"读代码",还涉及业务状态机、重试链路、多阶段参数传递、异常恢复、父子任务状态、数据持久化和执行边界这些工程语义。
我给它的 prompt 很长,大概要求它检查这些点:
- 新链路是否和成熟链路在关键状态流转上对齐
- 失败后的业务重试链路是否正确
- 失败记录恢复为待处理状态的逻辑是否完整
- 父任务状态和统计数据是否会及时刷新
- 前置步骤失败后,父子任务状态是否一致
- 关键执行结果是否正确持久化
- 多阶段创建流程里,前一步生成的关键 ID 是否被后续步骤正确读取
- 执行侧是否只读取前置快照,不反向写入前置参数
这类任务,才是真正能看出同类 coding agent 差距的地方。
结果怎么说?
我对它的评价是:第一轮代码审查很有价值,尤其适合先扫风险、对齐相似实现、做局部修复。
它表现好的地方很明显。
第一,审查结构清楚。
它能按严重程度列问题、说明修改点、保留差异和验证结果,不是泛泛总结。
第二,能找到真实风险。
它识别到了联调开关、执行后残留校验、多阶段参数传递、失败原因表达这些关键点。说明它不是只扫表面。
第三,能做跨实现对比。
它会拿成熟实现作为对照,这对迁移类、扩展类需求很有用。
第四,它会跑验证命令。
这点比只做静态审查可靠很多。
我把这轮审查结果进一步脱敏整理一下,大概是这样:
| 问题类型 | Kimi 的判断 | 我的处理 | 说明 |
|---|---|---|---|
| 联调开关判断 | 发现某个临时开关可能影响真实链路验证 | 保留结论,但结合环境重新判断 | 这类问题能体现它会看运行策略,但背景信息必须由人补齐 |
| 执行结束校验 | 认为任务结束后还需要检查残留状态 | 认可方向 | 这是复杂流程里很实用的审查点,适合让模型先扫 |
| 跨阶段参数传递 | 关注前置步骤生成的关键 ID 是否在后续步骤正确使用 | 认可方向,继续人工确认 | 多阶段链路很容易漏场景,它能抓到这个点不错 |
| 失败原因表达 | 认为异常信息要更清楚,避免排障时只看到泛化错误 | 认可方向 | 这属于真实工程里很有价值的可维护性问题 |
| 防御式写法 | 倾向加更多空值保护,降低运行时风险 | 部分调整 | 我们团队更偏契约式代码,不希望到处铺防御判断,这个约定要人补充 |
| 对照成熟模块 | 倾向把已有成熟实现当参照 | 只作为参考 | 相似模块可以借鉴,但不能因为已有模块这么做就直接照搬 |
这张表其实比"它发现了几个问题"更有意义。
它说明 Kimi 适合做第一轮审查,但隐藏上下文、团队代码风格、环境策略和业务状态机,还是必须由人补上。
这个任务也暴露出一个真实边界。
大型业务仓库里,很多判断依赖隐藏上下文。
有些地方它会把"表面上对齐成熟实现"当成"设计上正确",但没有充分判断新链路当前逻辑是不是承担了额外的质量闸门。
复杂业务项目里,这个差别很大,所以我更愿意把它当作一个很强的辅助 reviewer,而不是让它直接替我拍板。
不过这里也要补充两点,避免评价不公平。
第一,它识别到某个联调开关后,建议关闭这个开关。
这件事不能完全算它错。因为我之前只在和 Codex 的对话里说过:当前处在临时联调环境,外部依赖没法真实调用,所以需要暂时保留这个开关。Kimi 不知道这个背景。
如果把这个上下文告诉它,它大概率不会直接建议关掉。
第二,它修空指针风险时用了比较重的防御式写法。
这和我现在偏好的"契约式编程、少防御式代码"不太一致。
但这个也更像是上下文没给全。因为这个偏好是我长期和 Codex 协作后形成的团队约定,Codex 已经记住了,Kimi 并不知道。
所以这个任务给我的结论也很清楚:
Kimi 适合先扫一轮、提问题、做局部修复。涉及架构取舍、环境策略、业务状态机的地方,人再来做最终判断。
这其实已经挺有价值了。
很多真实项目的第一轮审查,本来就很耗时间。如果它能先帮你扫出一批明显问题,人再来做最终判断,这个效率提升是实打实的。
我的整体感受和使用建议
这次测完,我对 Kimi K2.7 Code 的感觉比较清楚。
我会用三个词概括它:快、多模态可用、稳定。
第一是快。高速版把等待感降下来了,连续读文件、改代码、跑命令的时候,体验会明显更顺。
第二是多模态可用。录屏和截图不只是能看,它确实能进入真实前端任务,先把页面结构和交互复刻出来,再根据反馈继续修。
第三是稳定。CLI、前端、本地 CRUD、真实大型项目审查这几类任务跑下来,它不是只会某一个单点,而是都能推进到可用状态。
更重要的是,高速版的体验确实很舒服。
我自己用的时候,最明显的感受就是:等待感少了很多。它写代码、改文件、跑命令、输出总结的时候,节奏非常快,屏幕上代码几乎是在飞速刷新。
这个对 coding agent 很关键。
因为很多时候,模型不是不能做,而是你等它等到失去耐心。速度快起来之后,你更愿意把一些中等复杂度的任务交给它先跑一轮。
我的使用策略是把它放到真实工作流里,但只让它先干第一轮。
如果你是个人开发者,我会这么用:
- 小工具、小脚本、内部页面,可以让它先做一版
- 前端复刻、后台管理页,可以让它先出结构,再人工细调
- 本地 CRUD、SQLite、API 这类闭环任务,值得交给它跑
如果你是团队试点,我会先把它放在这些位置:
- 第一轮需求实现
- 第一轮 PR review
- 局部 bug 修复
- 单元测试补齐
- 内部工具和管理后台原型
但权限、密钥、数据库 migration、支付、外部系统调用、权限系统、业务状态机这些地方,不要让模型直接过线。
这些不是 Kimi 一个工具的问题,而是所有 coding agent 进生产流程都要守的边界。
生产流程里,我建议至少保留三件事:
- 代码必须进 PR,不要直接合主干
- 关键改动必须有人 review,尤其是数据、权限、外部系统调用、支付相关
- 模型跑出的结论只能当审查输入,不能当最终裁决
至于高速版怎么选,我的建议也比较简单。
如果只是偶尔写小脚本,普通版或者 Kimi Code 先体验就够了。
如果你经常让它连续改项目、调前端、跑长任务,高速版的价值会明显很多。
团队要试点的话,先拿一两个真实但低风险的流程测成本和收益,不要一上来就把核心生产链路交出去。
坦白说,如果你已经在用 Codex、Claude Code、GLM、MiniMax 这些 coding agent,Kimi K2.7 Code 给我的感觉不是"替代谁",而是多了一个很快、也足够能干活的选择。
更现实的问题是:你怎么把它放进自己的工作流里,让它帮你承担那些重复、琐碎、但又需要工程判断的第一轮工作。
Kimi K2.7 Code 这次给我的答案是:
可以用,而且值得认真用。
它很适合当一个速度很快、执行力很强的工程助手;至于最终方案是不是该这么做,还是得你自己负责。
如果这篇对你有帮助,欢迎关注「子昕AI编程」,也顺手点个赞、在看,或者转发给同样在折腾 AI 编程工具的朋友。