强化学习发展历程
1.思想萌芽期
- 心理学源头 : 比如汽车路口等红绿灯,对于闯红的行为,要对其罚款扣分处理,做好事要 对其进行奖励。 通过尝试得到惩罚或奖励,塑造其行为。 产出了 "强化" 概念。
- 控制论与早期 AI 实践: 控制论与早期 AI 实践: 提出反馈闭环优化,奠定 RL(强化) "智能体 - 环境交互" 循环逻辑。
2.数学理论奠基期
- 动态规划DP
- 贝尔曼方程
- 马尔可夫决策过程
- 局限: 早期"动态规划" 属于有模型必须完整掌握环境转移概率,无法用于未知环境,状态空间稍大就无法计算。
3.经典表格强化学习时代
- 无模型算法爆发
- 时序差分
- **局限:**二维表格存储动作价值,高维/大规模场景(图像、围棋)状态数爆炸,表格无法存储,泛化能力极差
4.深度强化学习革命
- 神经网络解决高维输入,深度学习作为价值函数 / 策略近似器,彻底打破表格型限制,RL 从小网格、小游戏走向复杂视觉、博弈场景。
5.大模型对齐时代
RL 不再局限游戏 / 机器人,成为大语言模型对齐、通用人工智能核心工具。
- **RLHF(基于人类反馈的强化学习)**2020 OpenAI 提出,ChatGPT 核心训练流程:预训练大模型 → 人类标注偏好奖励模型 → PPO 微调语言模型,让输出符合人类价值观、指令、安全约束。 如今 顶流大模型全部使用 RLHF 技术。
什么是强化学习
广泛地讲,强化学习是机器 通过与环境 交互来实现目标 的一种计算方法。机器在环境的一个状态 下做一个动作 ,这个环境发生相应的改变并且将相应的奖励 反馈和下一轮状态传回机器。这个动作决策 对未来产生(影响)的收益价值 。分为三个层次结构组成:基本元素 、主要元素 、核心元素
实例说明
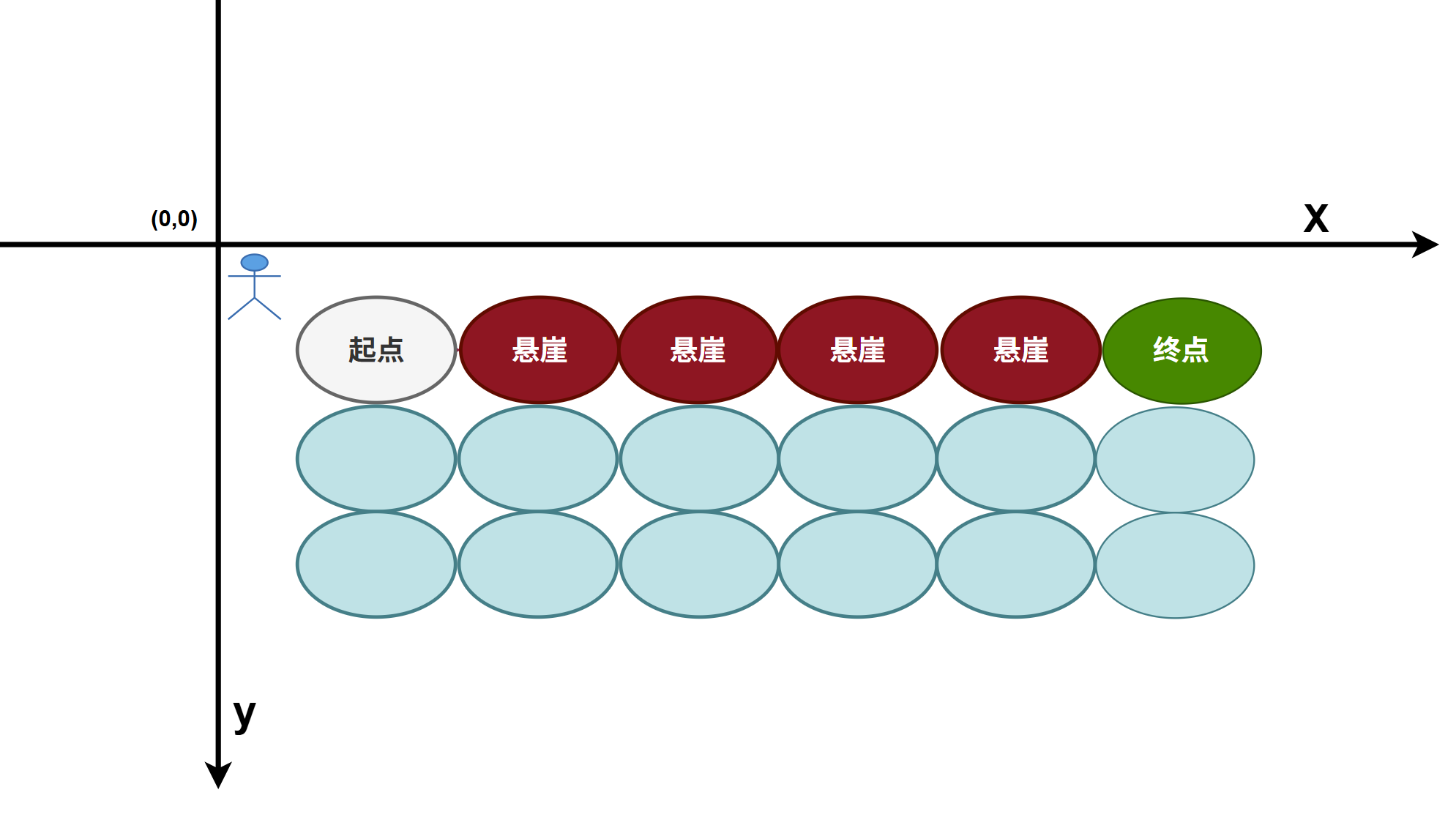
悬崖漫步问题 是一个非常经典的强化学习环境,它要求一个玩家(agent) 从起点 左上角开始出发,避开悬崖 行走,最终到达终点 。如图所示:一个 3×6 的椭圆网格世界,一共有18个椭圆,在椭圆网格内有 4 种动作:上、下、左、右 。如果采取动作后触碰到边界墙壁则状态不发生改变(还在原来的位置),否则就会相应到达下一个椭圆。环境中有一段悬崖 。掉入悬崖或到达终点就会结束游戏每走一步的奖励是 −1,掉入悬崖的奖励是 −100也就是失败了,达到终点的奖励是 1。
基本元素
- 环境: 18个椭圆网格世界
- Agent: 玩家
- 目标: 达到终点、起点到 终点的线路
主要元素
- 状态:18个椭圆位置
- 动作: 每位置可选动作:上、下、左、右
- 奖励: 移动奖励是 −1,掉入悬崖是 −100,到终点奖励是 1
核心元素
- 决策: 选择动作时要避开悬崖并能通向终点
- 价值: 通向终点 线路,步数最少(价值最大)
感谢大家的支持。