在大模型推理进入"长文本、高并发、多Agent"的后半场,核心的物理阻碍已经从算力(Compute Bound)变成了内存(Memory Bound)。业界都在谈 PD 分离(Prefill & Decode 分离),但PD分离的本质不是算力的解耦,而是KV Cache的高效流动。
当业界顶尖的开源KV Cache分布式存储引擎 Mooncake,碰撞上绿算技术(GroundPool 系列 )硬件级全卸载的GP-5000/ 6000/ 7000 新型上下文存储平台 ,一场大模型推理架构的"存算分离"技术革命正在悄然发生。
一、 悬在长文本推理头上的两把"达摩克利斯之剑"
在大模型(LLM)推理场景中,长文本(如200k+ Token)和多轮对话已经成为新常态。然而,业界在堆叠算力的同时,正面临着两个致命的物理瓶颈:
- 显存墙(HBM Storage Wall):长文本产生的KV Cache极其惊人。单次请求的KV Cache动辄几个GB,瞬间吞噬掉昂贵的 GPU HBM 显存。
- 首字延迟与吞吐量的两难(TTFT vs Goodput):在传统的统一推理架构中,Prefill(算力密集型,计算首字)和 Decode(带宽密集型,生成后续字)在同一张 GPU 上抢夺算力和显存,导致集群整体吞吐量急速下滑,长尾延迟暴增。
为了解决这一痛点,由月之暗面(Moonshot AI)团队开源的Mooncake 推理架构横空出世。它通过PD分离 ,将Prefill节点和Decode节点解耦。更重要的是,它将KV Cache视为"一等公民",通过Mooncake Store 构建了一个跨节点的、由HBM - CPU DRAM - 本地 SSD 组成的多级混合存储金字塔。
然而,在纯软件和本地硬件的框架下,Mooncake的混合存储层依然面临着"本地 SSD 调度的阿喀琉斯之踵"。
二、 纯软件架构的隐痛:本地 SSD 是解药,还是慢性毒药?
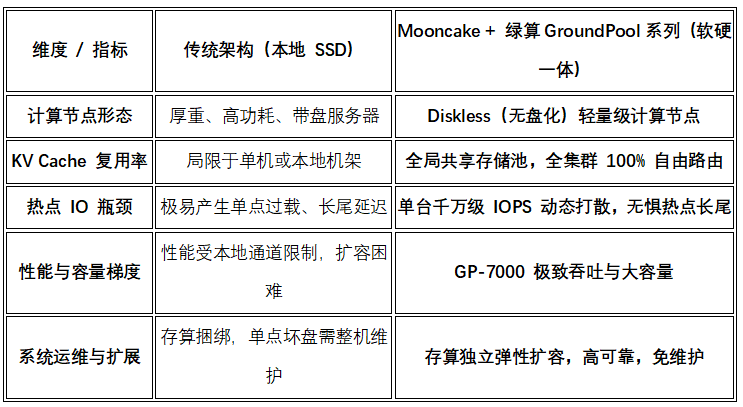
在 Mooncake 现有的分级存储中,当本地 CPU 内存(DRAM)放不下海量的冷缓存时,数据会被驱逐(Evict)落盘到本地的 NVMe SSD 中。
虽然 Mooncake 引入了Intel SPDK(用户态驱动) 技术来优化 IO,但在万卡规模的超级推理集群中,本地SSD方案的弊端正逐渐暴露:
- 隐痛一:CPU 算力被无情蚕食。即便绕过了Linux内核,SPDK的轮询(Polling)机制依然需要绑定 1~2 个CPU核心不断刷新IO队列。在并发洪峰到来时,负责推理调度的CPU主核心极易受到干扰。
- 隐痛二:网络抢道与"长尾延迟"。当节点A遇到高频热点请求(例如某个爆火的Agent提示词),而对应的KV Cache恰好落盘在节点A的本地SSD时,节点A 就会成为单点IO瓶颈。如果其他节点去远程拉取,极易引发跨节点网络的混乱抢道。
- 隐痛三:数据孤岛,无法真正池化。本地SSD无法做到真正的全局共享。一旦节点死机,其内部落盘的通用前缀缓存(如系统 Prompt)将彻底锁死,集群无法做到自由路由。
- 隐痛四:东西向网络流量雪崩,计算通信严重抢道。在大规模分布式推理中,多个GPU节点之间为了协同运行一个大模型,本身就需要通过Tensor Parallel (TP) 或Pipeline Parallel (PP) 产生海量的东西向流量(East-West Traffic)来进行激活值和梯度的同步。如果此时多节点之间再频繁跨网络传输GB级别的KV Cache巨型文件,会导致原本就脆弱的算力网络带宽被瞬间挤占、拥堵,从而导致全网推理响应时间发生雪崩式的长尾延迟。
三、 硬件降维打击:绿算 GP-5000/6000/7000 带来的"无盘化(Diskless)"革命
如果将 Mooncake Store 底层的本地 NVMe SSD,替换为绿算技术(GroundPool)的 GP-5000/6000/7000新型 NVMe-oF CMX 全闪存储 平台,原有的软件痛点将瞬间被硬件级手段"降维打击"。
绿算GroundPool系列不是简单的网络存储服务器,而是专为 AI 智算与长文本推理设计、具备全栈硬件卸载能力的分布式存储底座 。
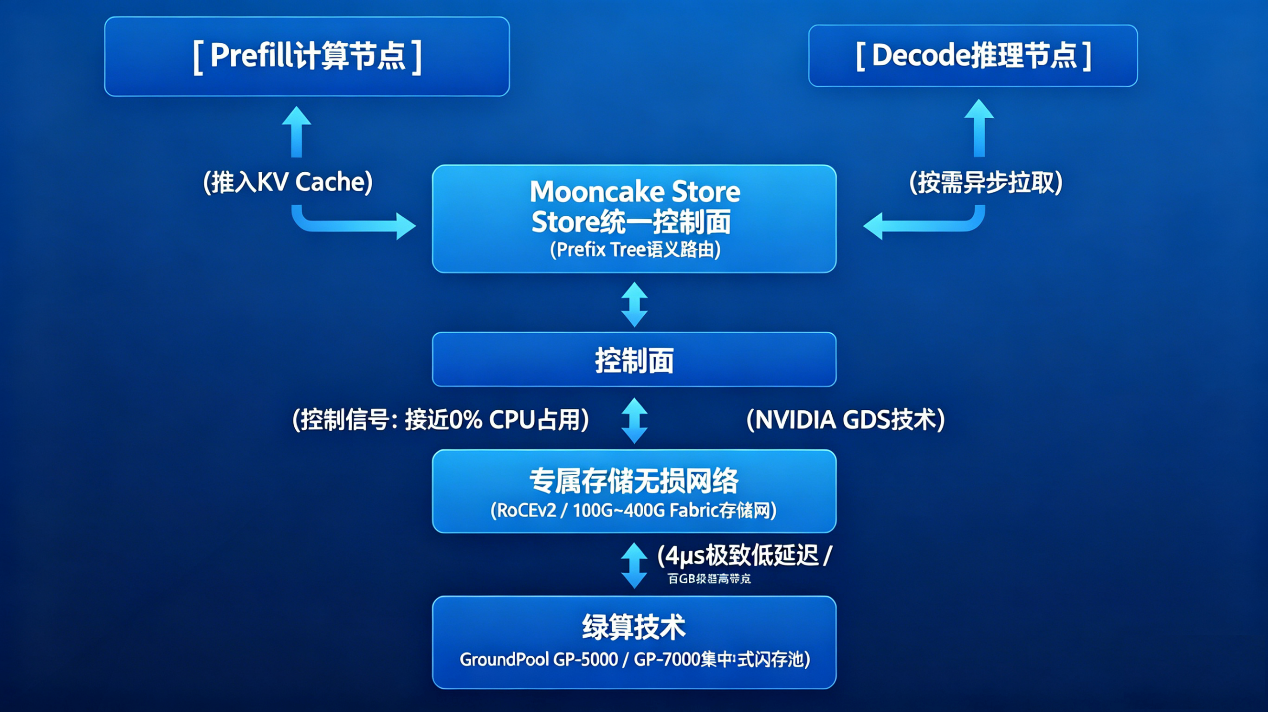
【大模型推理集群:软硬协同存算分离演进】
1. 硬件级协议卸载:CPU 占用的"终极解耦"
GroundPool系列内部集成了专用的异构计算芯片(DPU/ASIC),将整个NVMe-oF协议栈、RoCEv2网络流控彻底固化在硬件中。当Mooncake Store需要换入/换出 KV Cache 时,GPU节点只需要下发控制指令,具体的 IO 数据搬运完全由硬件网卡和存储芯片对接,主机CPU占用率直接归零。
2. 原生 NVIDIA GDS 技术:数据直达显存
传统的远程存储读取,数据需要经过"网卡 -> 节点内存 -> CPU 寄存器 -> GPU 显存"的漫长链路。而绿算系列全闪存储原生支持 GPUDirect Storage (GDS) ,数据直接通过 RoCEv2 网络绕过 CPU,通过 PCIe Switch 直达 GPU HBM(显存) 。配合绿算独家的优化,端到端延迟低至 4μs 级别 。尤其是旗舰款GP-7000更是进一步推高了并发吞吐上限 ,提供了更为恐怖的T B 级单节点带宽,满配带宽达到2.4TB。这让远程存储的吞吐性能远超本地SSD,彻底消除了首字延迟(TTFT)的焦虑。
3. 物理隔离存储专用网:释放东西向计算带宽
针对"计算与存储抢网"的隐痛,绿算架构提供了完美的解法。通过引入超低时延的RoCE v2 交换机,GPU计算节点与GroundPool系列存储阵列之间构建了一张物理隔离的存储专用网络。KV Cache 的高频换入换出走独立的存储网卡(如 GP-7000 支持的高密 200G/400G 网络端口),将巨量存储流量从原有的计算网络中彻底剥离,绝不占用 GPU 节点之间宝贵的 NVLink、InfiniBand 或百G算力网。这让负责 TP/PP 节点的计算通信能够全速运转,彻底解决了由于网络挤占引发的卡顿,绝不占用 GPU 之间进行 Tensor Parallel(张量并行)或大模型参数同步的前端计算网(如NVLink或高规格InfiniBand算力网)。
四、 软硬协同:Mooncake + 绿算双子星组合拳的商业图景
当开源界的"顶流软件架构"遇到工业界的"硬核全闪底座",两者的合力将直接重构下一代大模型智算中心的 TCO(总体拥有成本):
Prefill Once, Reuse Everywhere(一次计算,到处复用)。
在Mooncake强大的前缀树(Prefix Tree)语义路由和全局调度下,任何Prefill节点计算出的通用上下文,都会被瞬间写入由GroundPool系列构建的集中式闪存池;而任何一个地方的Decode节点,都能以微秒级的速度将其拉回本地显存。
对于中小规模及高性价比集群,GP-5000 /6000 提供了完美的轻量化演进方案;而对于万卡规模、拥有极高长文本吞吐需求的头部 AI Factory,GP-7000 则以其更高的 IOPS、更宽的网络管道以及海量的池化容量,成为了承载高频冷热 KVCache 动态换入换出的不二之选。
五、 结语:迈向"存算分离"的智算新时代
大模型推理的竞争,本质上是一场关于效率与成本的极致压榨。
Mooncake 从软件层面重新定义了大模型时代的"内存层次结构";而绿算技术GroundPool系列则从硬件底座上,为这个结构接上了最强韧的物理延伸。随着 Mooncake 开源社区对远程NVMe-oF存储后端(Storage Backend)支持的日益完,这种****"软件定义大模型 Serving + 硬件级全卸载网络存储"****的软硬协同模式,正成为大模型长文本推理集群无可争议的工业标准答案。
大模型推向产业深水区的下半场,谁能更低成本、更高吞吐地让 KV Cache 自由流动,谁就能率先拿到商业化落地的通关船票。
在长文本和 Agent 时代,你认为存算分离会是智算中心的标准配置吗?GP-5000 /6000 和旗舰 GP-7000 谁更契合你目前的集群规模?欢迎在评论区留言交流!
(注:文中技术参数与架构部分参考自 GitHub 开源项目 kvcache-ai/Mooncake。)