作为服务家居零售全链路的 B 端中台团队,洞窝在日常迭代中深刻感受到 AI 编程"提效不提质"的痛点------需求还原失真、代码复用率低、Token 成本高 。口头描述的需求易被 AI 脑补曲解,存量架构被无视导致重复造轮,盲目扫描文件让成本持续失控。直到落地 OpenSpec(规范驱动框架)+ CodeGraph(代码知识图谱) 组合,才实现 AI 编程从"随性编码"到"工程化研发"的转变。
前者将模糊需求转化为可追溯的标准化契约,解决需求跑偏与编码不规范问题;后者为 AI 搭建本地代码地图,从根源削减无效文件读取与 Token 损耗。二者形成"前置规范定边界 + 后置图谱读代码"的完整闭环,也是目前 AI 编程工业化落地的核心实践。本文结合工具原理、实操流程与洞窝真实落地案例,全方位拆解这套方案的价值与实战经验。
一、当下AI编程的三大核心痛点
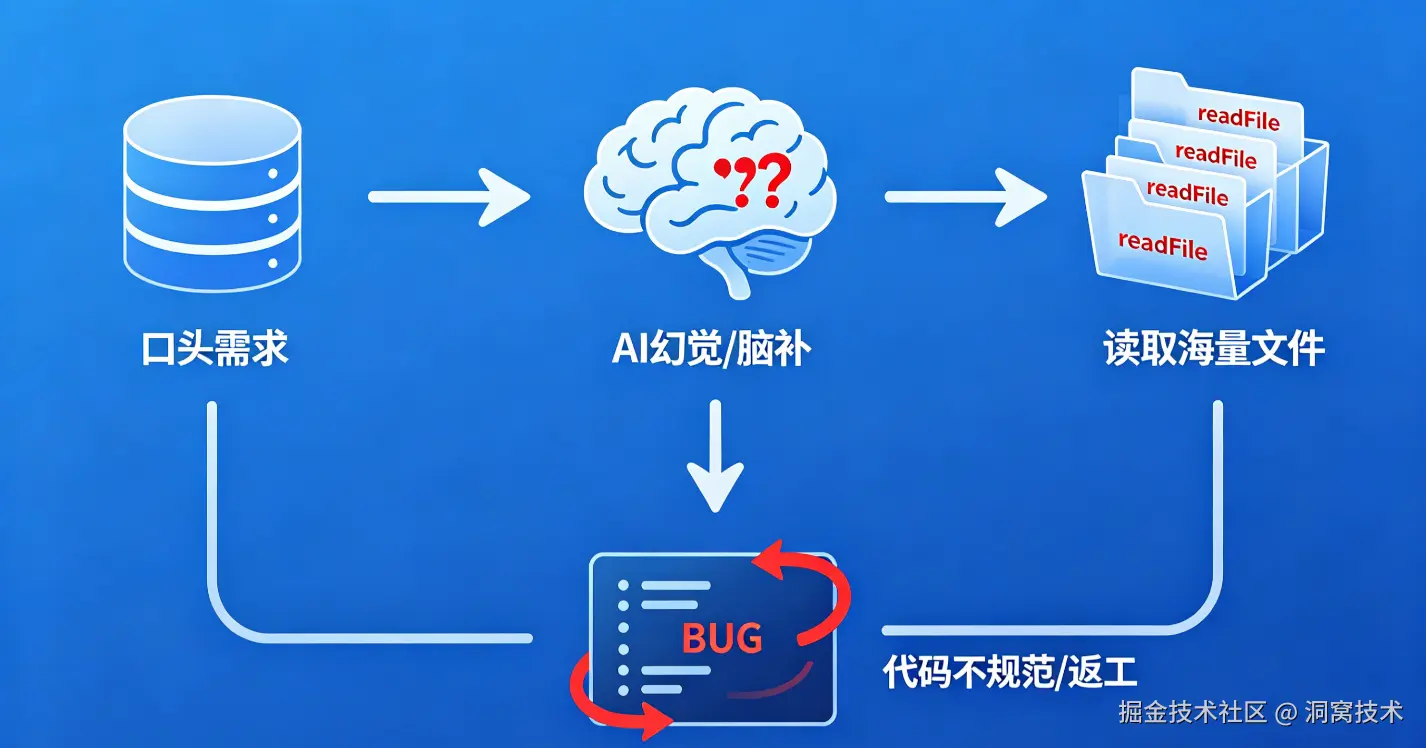
在正式介绍工具之前,我们先结合日常开发场景,拆解AI编程普遍存在的痛点,这也是两款工具诞生与组合使用的核心意义。
1. 需求仅存于会话,还原度差且极易返工
绝大多数开发者使用AI编程的模式为"口头提需求,AI直接写代码"。需求、业务规则、边界条件全部依附于临时聊天会话,存在三大隐患:一是会话断层 ,关闭对话、切换设备或更换AI工具后,历史需求完全丢失,新会话中AI只能重新揣测意图;二是AI幻觉 ,面对复杂项目,大模型容易凭空编造不存在的接口、工具类或依赖包,代码编译、运行直接报错;三是隐性规则遗漏,项目中表单校验、数据缓存、空状态兜底等隐性业务逻辑,口头描述容易遗漏,AI生成代码看似功能完整,实则无法满足生产要求。
在中小型业务迭代中,因需求理解偏差导致的返工率普遍超过50%,简单功能往往需要多轮沟通修正,AI"提速"效果大打折扣。
2. 代码兼容性弱,上线采用率偏低
不同项目拥有专属的技术栈、组件封装规范、目录架构与编码风格。纯对话模式下,AI无法深度记忆项目存量代码规则,常常出现"重复造轮子"的问题:项目已有全局封装的弹窗、请求工具、空状态组件,AI却从零手写实现;原有数据库实体类、接口路由、权限逻辑被无视,新代码与存量架构冲突。
这类代码无法直接合并上线,开发者需要大面积重构,最终AI产出代码的实际可用率大多维持在30%~40%,看似生成了大量代码,实则沦为"无效产出"。
3. 全量扫描文件,Token成本持续失控
这是AI编程最直观的成本问题。传统模式下,AI不具备项目全局认知,想要理解业务逻辑、调用关系,只能反复执行文件读取、全局检索操作。对于拥有几十甚至上百个文件的项目,单次功能开发,AI可能发起数十次文件读取请求,整项目源码被批量灌入模型上下文。
一方面,海量冗余内容挤占模型有效注意力,进一步降低代码质量;另一方面,持续上涨的Token消耗直接转化为API调用成本,个人开发者额度快速耗尽,团队长期使用更是一笔不小的开支。据开源社区实测,中大型项目单次复杂需求,无效文件读取带来的Token损耗占比可达60%以上。
二、两款核心工具深度解析:定位、原理与核心能力
OpenSpec与CodeGraph并非功能重叠的竞品,而是针对不同环节的互补工具。前者聚焦需求与流程标准化 ,后者聚焦代码库轻量化检索,二者结合才能打通AI编程全链路。
1. OpenSpec:规范驱动开发(SDD)的轻量级框架
OpenSpec是由Fission-AI团队开发的开源SDD(Spec-Driven Development,规格驱动开发)框架,GitHub Stars已突破52000+,基于MIT协议开源,主打"先共识,再构建"的核心理念------在编写第一行代码前,开发者与AI先通过结构化规范文档对齐所有需求、规则与技术方案,彻底摆脱"拍脑袋编码"的模式。
核心定位与基础信息
OpenSpec属于流程规范层工具 ,不替代Cursor、Claude Code等AI编码工具,而是作为上层规划层存在。它无需额外API密钥、不依赖第三方服务,仅要求运行环境Node.js ≥ 20.19.0,原生支持25+主流AI编程工具,兼容性极强。其核心设计面向存量项目迭代,无需为全项目补全历史规范,仅针对每次变更生成增量文档,轻量化无负担。
核心工作机制
OpenSpec通过一套标准化目录与文档体系,将临时对话中的需求沉淀为Git可管理的持久化文件。项目执行openspec init初始化后,会自动生成核心目录结构:
-
openspec/specs:存储项目长期生效的主规范,是系统功能、编码规则的"唯一可信源";
-
openspec/changes:存放正在进行的功能变更提案,包含提案说明、技术设计、任务清单与增量规范;
-
openspec/changes/archive:归档已完成的变更,留存完整开发历史,方便后续追溯复盘。
每次需求变更会生成四类核心文档:proposal.md(变更目的、范围与边界)、design.md(技术方案与取舍)、tasks.md(可落地的分步任务)、增量spec.md(基于GIVEN-WHEN-THEN格式定义业务行为与验收标准)。同时其独创的**Delta Spec(增量规范)**机制,仅记录本次变更内容,避免规范文档无限膨胀,归档时自动合并到主规范中,兼顾完整性与可维护性。
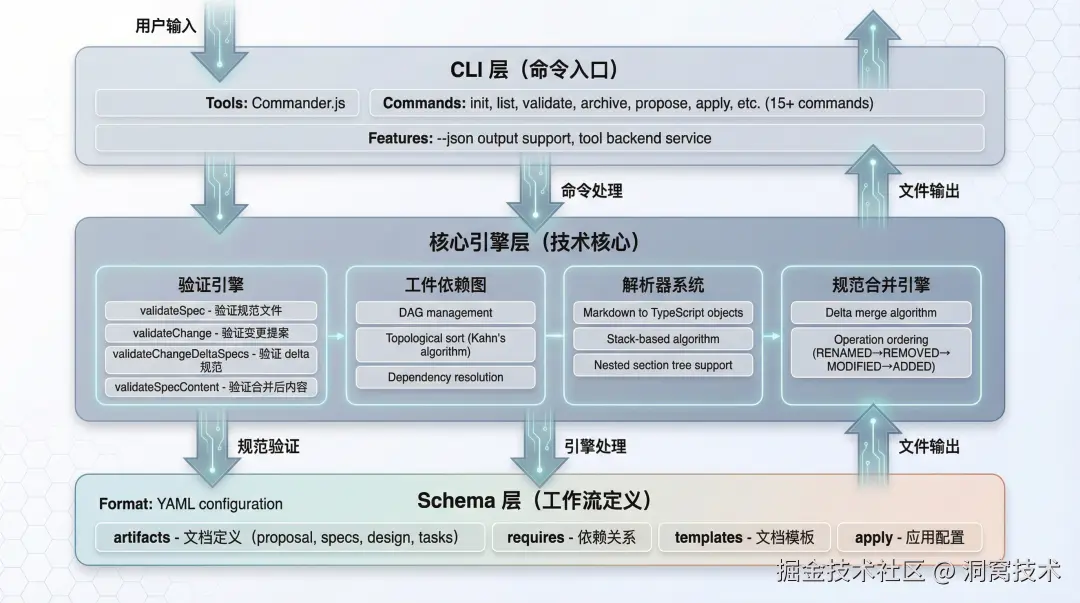
OpenSpec 架构示意图
核心价值
一是需求持久化 ,规范文件随代码提交至Git,跨会话、跨设备、跨人员都能快速对齐需求;二是流程标准化 ,强制遵循"定规范→做开发→存历史"的流程,杜绝需求随意变更;三是团队协作友好,统一编码约束与变更流程,多人协作时避免风格混乱、逻辑冲突。
2. CodeGraph:本地代码知识图谱工具
CodeGraph是一款专注于代码索引与语义分析的开源工具,GitHub Stars达28000+,主打为AI编程工具打造本地代码地图。它基于AST(抽象语法树)解析项目代码,提前构建包含函数、类、接口、依赖、调用链路的知识图谱,让AI从"盲目翻文件"转变为"精准查图谱",是解决Token浪费、代码理解偏差的核心利器。
核心定位与基础信息
CodeGraph属于代码检索层工具,全程100%本地运行,代码与索引文件不会上传至外网,兼顾数据安全。支持JavaScript、Python、Java、Go等主流编程语言,适配Cursor、Claude Code等主流AI工具,通过MCP协议与AI工具联动。项目执行codegraph init -i后完成全量索引构建,后续文件修改会自动增量同步,无需手动重建。
核心工作机制
传统AI读取代码是"文件级遍历",而CodeGraph是"符号级检索"。首次初始化时,工具扫描全项目代码,解析出所有代码符号及相互调用关系,存入本地数据库。当AI需要查询组件用法、接口定义、函数调用链、模块依赖时,不再读取完整文件,而是向CodeGraph发起图谱查询,仅获取目标代码片段与关联关系,从源头砍掉无效文件读取操作。
同时它支持影响范围分析、调用方检索等高级能力,修改公共方法、核心接口前,可快速排查全项目影响范围,有效避免"改一处、崩多处"的连锁Bug。
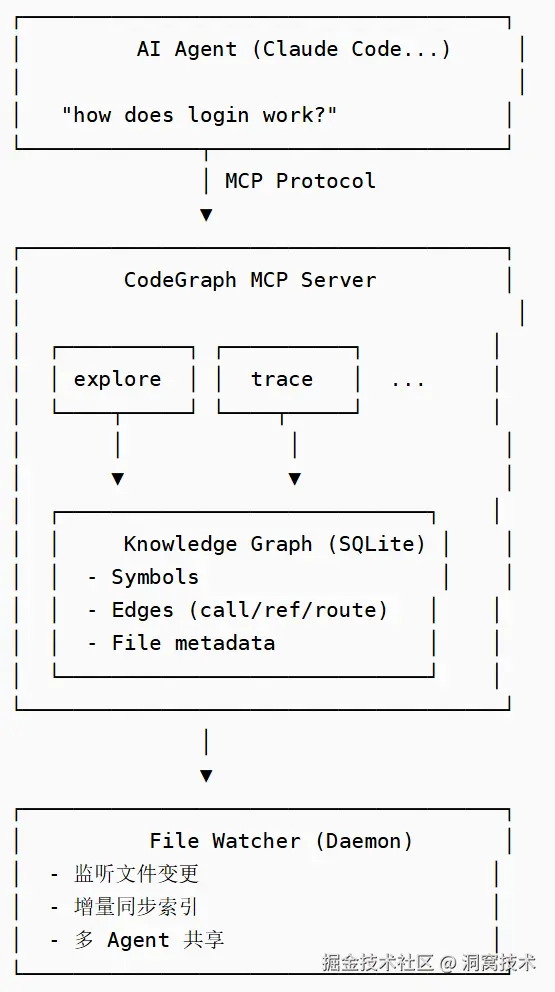
核心价值
一是大幅削减Token ,官方实测数据显示,接入CodeGraph后,AI工具调用次数平均减少71%,Token整体消耗下降57%以上;二是精准理解存量代码 ,AI快速掌握项目架构、公共组件与历史逻辑,生成代码天然兼容原有项目;三是提升排错与重构效率,复杂老项目中可秒级定位代码位置与调用链路,降低维护难度。
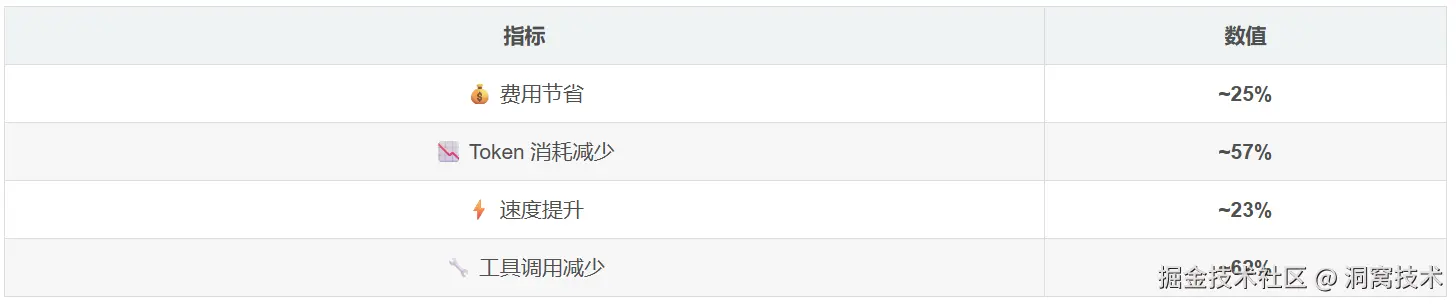
官方基准数据(2026-05-29 验证,Opus 4.8)
了解两款工具的核心能力后,结合洞窝中台前端迭代的真实场景,我们拆解这套组合如何落地到日常开发全流程。
三、OpenSpec+CodeGraph组合逻辑:全链路工作流拆解
两款工具并非简单叠加,而是形成**"上游定规则、中游查代码、下游做开发"**的完整闭环,完美适配AI编程全流程。结合日常开发场景,标准工作流分为环境准备、项目初始化、日常迭代、收尾归档四大环节,全程操作简单,上手门槛极低。
1. 环境统一安装(全局仅需执行一次)
两款工具均支持npm全局安装,一台电脑配置一次即可,切换项目无需重复安装。若使用nvm管理多版本Node,需在当前使用的Node版本下执行安装命令;若担心环境变量问题,也可使用npx临时调用,规避命令找不到的问题。
| bash # 安装OpenSpec-CN(中文汉化版,适配国内使用) npm install -g @studyzy/openspec-cn # 安装CodeGraph npm install -g @codegraph/cli |
|---|
安装完成后,分别执行openspec-cn --version、codegraph --version,输出版本号即代表安装成功。
2. 单项目初始化(每个项目仅执行一次)
进入目标项目根目录,依次执行两条初始化命令,分别完成规范目录创建与代码图谱构建,初始化完成后必须重启Cursor,让工具规则与MCP配置生效:
| bash # 1. 初始化OpenSpec:生成规范目录、Cursor专属规则与斜杠命令 openspec-cn init # 2. 初始化CodeGraph:构建全项目代码索引图谱 codegraph init -i |
|---|
-
OpenSpec初始化过程中,会交互式选择当前使用的AI工具(Cursor),自动生成.cursor/rules规则文件,内置专属斜杠命令,如果没有生成对应的 openspec/project.md 文件则需手动创建(项目上下文(技术栈、规范、业务背景));
-
CodeGraph初始化后,生成隐藏索引目录,建议将该目录加入.gitignore,避免索引文件提交至代码仓库。
3. 日常开发标准流程(核心闭环)
这是每日开发的核心流程,无需记忆复杂命令,依托Cursor内置斜杠命令即可完成,分为四大步骤:
- 发起需求提案(OpenSpec主导)
在Cursor对话框输入/opsx:propose,并用自然语言描述需求。AI会自动在openspec/changes目录生成全套规范文档,明确需求范围、业务规则、技术方案与分步任务。开发者重点审核文档,补充隐性业务规则、编码约束(如必须使用全局组件、指定接口等),确保规范无偏差。
-
proposal.md- 为什么做、做什么 -
specs/{xxx}/spec.md- 需求场景详情 -
design.md- 技术方案 -
tasks.md- 实现清单
- 代码图谱查询(CodeGraph静默联动)
审核通过后,AI需要查阅存量代码时,会自动调用CodeGraph图谱。例如查询全局弹窗组件、统一请求方法、数据库实体等,仅获取精准代码片段,不再批量读取文件,全程无感运行。
- 执行编码开发(双工具协同)
输入/opsx:apply,AI严格按照OpenSpec的任务清单与规范要求编写代码。一方面遵循编码规则、业务逻辑,避免偏离需求;另一方面依托CodeGraph复用存量代码,保证架构兼容性。开发过程中,任务清单会自动勾选完成状态,进度清晰可查。
- 验证与归档(流程收尾)
代码开发完成后,可执行openspec-cn validate验证代码与规范的一致性。测试无误后,输入/opsx:archive完成归档:增量规范合并至主规范,变更文档移动至归档目录,本次迭代完整留存,流程闭环。
4. 两种灵活使用模式,适配不同场景
针对需求明确程度不同,两套工具组合支持两种开发模式,兼顾效率与规范性:
-
快速模式:适用于简单功能、小Bug修复。流程:/opsx:new → /opsx:ff(快速生成所有规范制品)→/opsx:apply → /opsx:archive,精简步骤,保证基础规范落地;
-
探索模式:适用于需求模糊、技术调研、架构优化等场景。流程:/opsx:explore(先调研梳理思路)→ /opsx:new → /opsx:continue(逐步完善规范)→ /opsx:apply,边探索边开发,避免盲目编码。
以下是洞窝在大型中台项目中落地该方案的实测效果,用数据验证组合价值。
四、真实落地案例:多场景验证组合方案价值
结合前端、后端、老项目维护等主流开发场景,分享几个真实落地案例,所有数据均为实操实测,客观反映组合方案在代码采用率、需求还原度、Token控制三方面的优化效果。
案例1:大型中台前端迭代|洞窝运营管理平台
项目真实背景
本次落地项目为洞窝运营管理平台 ,是面向家居零售全链路的B端中台运营后台。技术栈基于 React17 + Ant Design4 + Umi3 + Dva 开发,采用Ant Design Pro脚手架搭建,为TS/JS混用的大型存量单体前端项目。
项目业务体量庞大,按业务域划分为36个一级业务模块,涵盖订单、营销、招商、支付、清结算、财务、CDP、小程序入驻等全链路家居零售业务,页面级源码超1900个,路由配置文件超3000行。整体服务于总部运营、卖场招商、财务对账、渠道配置等多角色,核心能力包含复杂列表筛选、动态表单配置、多级审批流、财务对账报表、全局权限管控等。
项目技术规范极强,拥有统一的工程惯例:固定 index.ts 页面入口、配套 services.ts 接口请求、data.d.ts 类型定义、可选 model.ts 状态管理、局部业务组件目录;全局请求统一封装在 @/utils/request,UI 严格复用 Ant Design 及 Pro 系列组件;多业务模块共用底层 API,存在大量跨模块接口复用场景,同时区分 dev/sit/uat/prod 多套生产环境。
本次迭代需求:为列表新增多条件筛选能力,支持价格区间、门店区域、户型、上架时间筛选,适配现有列表结构,复用项目全局弹窗、空状态、表单组件,新增筛选条件本地缓存刷新回填、表单必填校验、空数据兜底展示能力。
传统纯AI开发(无规范、无代码图谱)真实痛点
在原生Cursor纯对话开发模式下,大型中台项目暴露的问题极其典型:
- 盲目全量扫文件,Token损耗失控
AI为理解招商模块代码结构、接口用法,会批量读取数十个无关业务文件,单次开发触发30+次无效文件读取,Token消耗高达3w+,冗余占比超70%,模型注意力被大量无效信息稀释。
- 无视工程规范与跨模块复用,强行重复造轮
项目拥有成熟的统一开发范式,但纯对话模式下AI无法精准记忆存量规范:未复用项目封装的全局弹窗组件、ProTable列表组件,强行手写原生实现;未识别 services.ts 已有列表筛选API,私自新增接口请求,破坏统一架构;未使用全局封装的 request 工具,重复自建请求实例。代码风格与中台规范严重脱节。
- 遗漏隐性业务规则,返工成本极高
B端中台存在大量隐性约束:价格区间起止值必填校验、筛选参数本地持久化、空数据统一兜底。口头需求无法完整传递,AI仅实现基础筛选,遗漏多项核心业务逻辑。最终代码可用率仅30%左右,大部分需重构重写,无法直接上线。
OpenSpec + CodeGraph 双工具落地真实效果
项目提前完成 openspec-cn init、codegraph init -i 初始化,重启Cursor生效后,执行标准化SDD开发流程,完美适配大型中台项目的规范与架构要求:
- OpenSpec 前置锁定规范,杜绝需求跑偏与违规编码
通过 /opsx:propose 生成完整功能规范文档,提前固化所有约束条件:明确必须复用招商模块原有列表接口、全局ProTable组件、统一空状态组件;强制遵循项目TS类型定义、表单校验规则;划定功能边界,禁止新增冗余接口。
其中,隐性业务规则通过 GIVEN-WHEN-THEN 格式精准定义:例如在 spec.md 中我们明确写入------"GIVEN 用户输入价格区间为空,WHEN 点击筛选按钮,THEN 触发表单必填校验并展示洞窝统一兜底文案",AI 完全遵循该规则开发,无遗漏。类似的价格区间起止值校验、筛选参数本地缓存、初始化自动回填历史条件等所有隐性逻辑全部以同样方式沉淀到规范中。所有需求、验收标准结构化留存,永久存入Git,彻底解决会话丢失与AI脑补问题。

- CodeGraph 精准图谱检索,彻底终结无效读文件
AI无需遍历上千个项目文件。在洞窝中台项目中,CodeGraph 精准识别了 @/utils/request 的封装逻辑,以及招商模块 services.ts 中已有的列表筛选接口,AI 仅调取这 2 个核心文件片段,而非遍历 3000+ 行路由配置与 1900+ 页面文件。无效文件读取减少80%以上,单次需求Token消耗从3w+降至5k-6k。同时精准识别跨模块复用逻辑,完全沿用项目成熟接口与工具,无新增冗余代码。
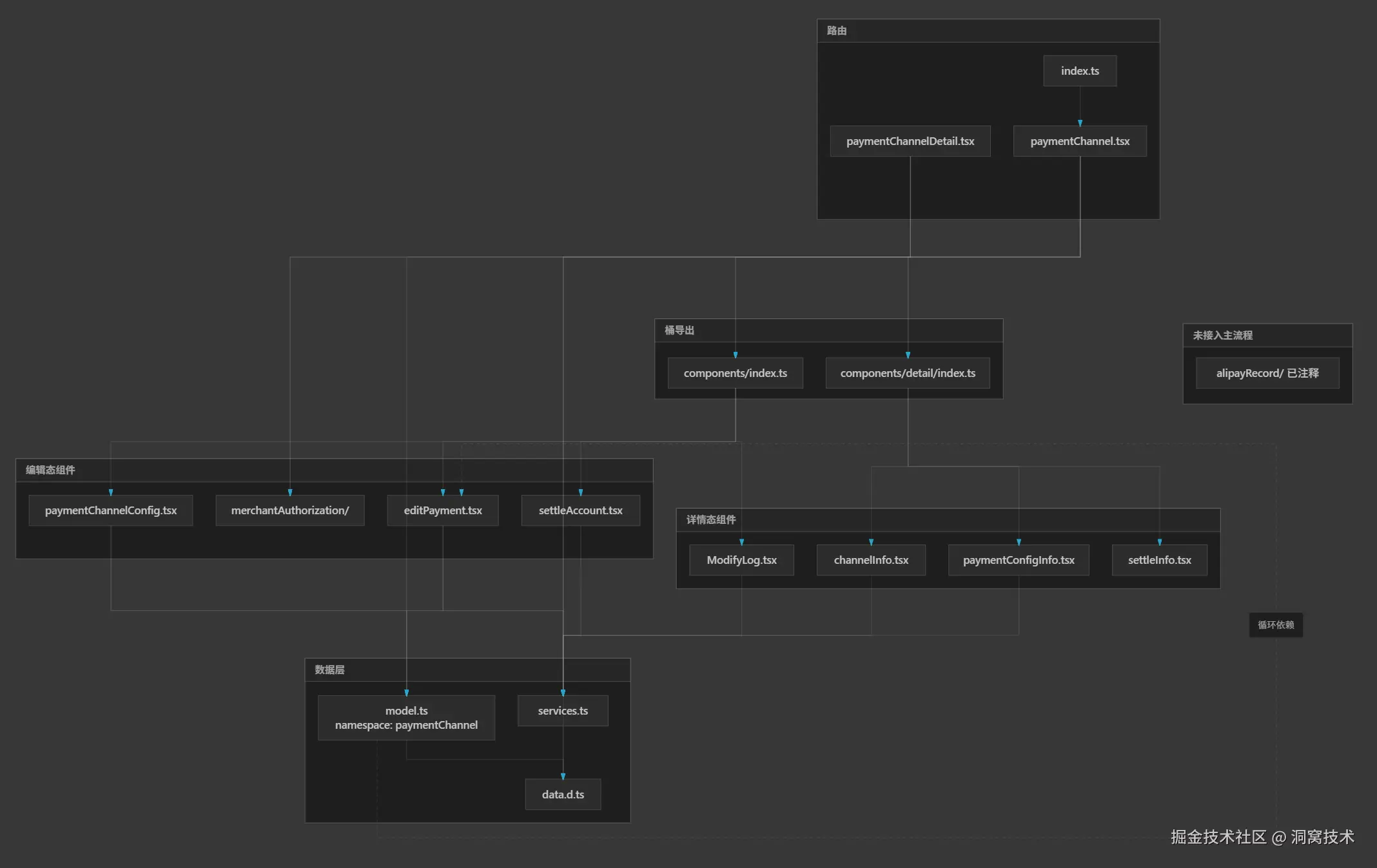
CodeGraph生成的模块内依赖图
- 标准化落地编码,大幅提升代码上线率
通过 /opsx:apply 执行编码,AI严格遵循Spec规范+项目存量架构开发,代码结构、组件使用、接口请求、类型定义完全贴合洞窝中台工程规范,无需大规模重构,代码落地可用率提升至85%以上,仅需微调细节即可提交测试上线。
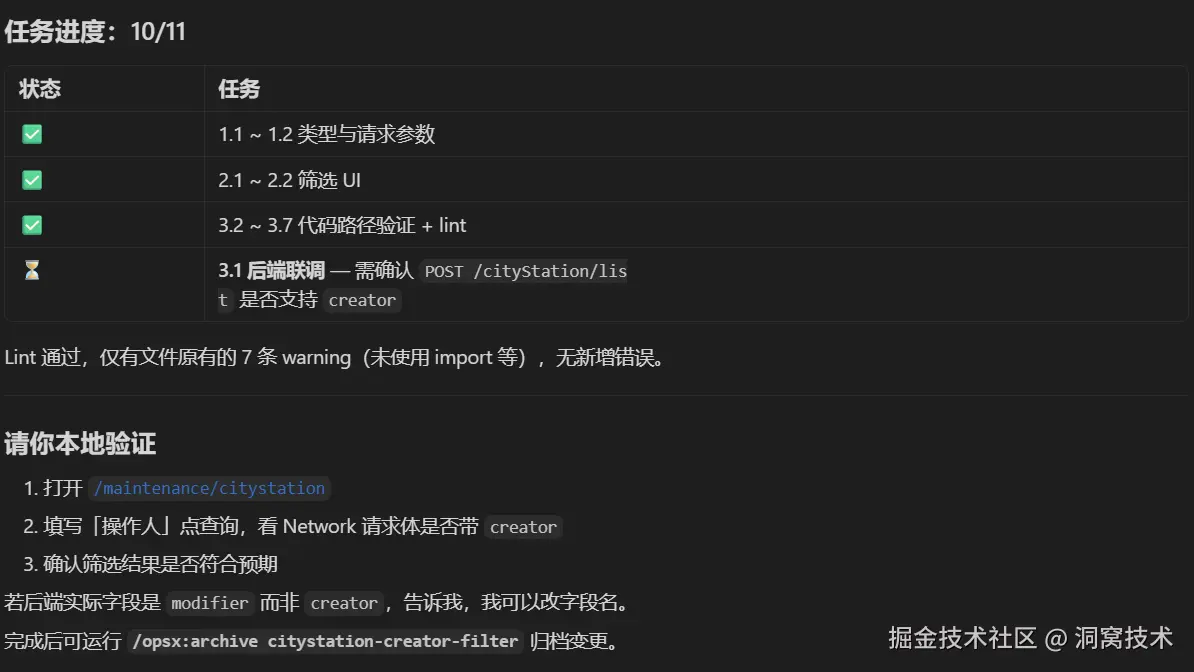
/opsx:apply 之后会生成完整的任务进度和需要确认的点,可以继续修改。
- 零隐性需求遗漏,彻底减少返工
所有隐性业务规则、边界校验、交互逻辑全部写入规范文档,AI严格按照GIVEN-WHEN-THEN验收标准开发,无功能遗漏、无逻辑缺失,一次开发即可满足生产业务需求,规避多轮返工。
本案例真实优化小结
针对大型多业务线单体中台前端,双工具组合完美解决了传统AI编码「看不懂复杂项目、无视工程规范、遗漏隐性规则、Token疯狂浪费、代码无法上线」的核心痛点。在保证中台项目架构统一、规范统一的前提下,极大提升迭代效率,降低AI编码试错成本。
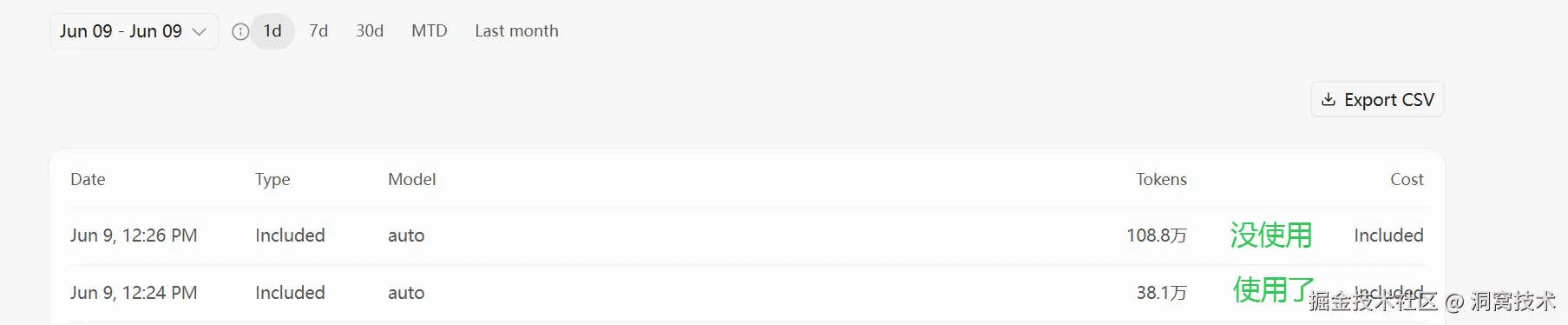
此图是同一个问题在此项目中,使用CodeGraph和未使用CodeGraph的token消耗对比图;真实数据来源于Cursor Usage;
其余场景实战总结
除了上述大型中台前端迭代核心案例外,我还在日常开发的Python后端迭代、老旧项目Bug修复、全新工具开发等几类常见场景中,落地验证了OpenSpec+CodeGraph组合的实战价值,均取得了稳定、正向的优化效果,适配绝大多数开发者日常迭代场景。
在Python爬虫后端迭代中,双工具组合有效解决了AI随意新建实体、重复编写入库逻辑、代码适配性差的问题,保证代码复用原有业务逻辑,大幅减少冗余开发;
在无文档、结构混乱的老旧项目Bug修复场景下,依托代码图谱可快速定位故障链路,规避AI盲目扫文件、错改代码的问题,极大缩短排错修复周期。
在轻量化TS工具全新开发场景中,前置规范锁定技术栈与依赖白名单,杜绝版本冲突与不规范编码,实现一次开发、一次打包上线;
多场景实测数据统一印证:这套组合方案无论是新项目开发、存量业务迭代还是老旧项目维护,都能稳定提升代码上线可用率、降低返工率与Token损耗,适配前后端各类常规开发需求。各类场景实测优化区间可参考下表:
落地效果汇总表
| 开发场景 | 代码可用率提升 | 返工减少幅度 | Token优化区间 |
|---|---|---|---|
| 大型中台前端迭代 | 50%~55% | 70%~80% | 75%~82% |
| Python后端迭代 | 40%~50% | 60%~70% | 62%~75% |
| 老旧项目Bug修复 | 50%~60% | 75%~85% | 75%~88% |
| 全新小工具开发 | 40%~55% | 70%~90% | 40%~55% |
五、落地避坑指南与长期最佳实践
两款工具上手简单,但想要长期稳定发挥价值,需要遵循对应的使用规范,规避常见误区,结合社区经验与实操总结,整理出以下核心建议。
1. 环境与初始化避坑
-
nvm多版本Node注意事项 :OpenSpec与CodeGraph为全局包,仅对当前激活的Node版本生效。切换Node版本后,需重新执行全局安装;临时使用可优先采用npx调用命令,解决"命令找不到"的问题,需 Node.js ≥20.19.0。
-
初始化必重启Cursor:openspec-cn init会修改Cursor规则文件,codegraph init -i会配置MCP协议,初始化后必须重启编辑器,否则工具无法联动生效。
-
索引文件纳入忽略列表:CodeGraph生成的索引目录、OpenSpec的临时缓存文件,均需写入.gitignore,避免冗余文件提交到代码仓库,增大仓库体积。
2. 规范编写与流程规范
-
规范区分"行为"与"实现":编写spec.md时,只定义用户行为、业务规则、验收标准,不要写入具体技术实现(如指定某个函数、某行代码)。实现逻辑交由design.md管理,避免规范僵化,失去迭代空间。
-
明确需求边界,拒绝范围膨胀:在proposal.md中明确"本次做什么、本次不做什么"。AI容易顺着需求额外扩展功能,划定边界可有效避免项目范围失控。
-
规范同步Git管理:OpenSpec的所有规范文档、归档文件都需要随代码提交Git。一方面保证团队成员信息同步,另一方面留存完整开发历史,新人接手、问题排查时可快速溯源。
3. CodeGraph使用优化
-
无需手动重建索引:日常开发中,文件修改后CodeGraph会自动增量更新索引,无需频繁执行重建命令。仅在项目技术架构大改版、大量文件迁移时,手动重建索引即可。
-
大型项目分批索引:十万行以上的超大型项目,首次构建图谱耗时较长,可拆分模块分批初始化,降低硬件资源占用。
-
善用影响分析能力:修改公共函数、核心接口前,借助CodeGraph查询全量调用方,提前评估风险,避免线上故障。
4. 团队协作长期规范
-
统一基础模板:团队统一修改OpenSpec默认模板,确定编码风格、文档格式、规则粒度,保证全项目规范口径一致。
-
区分场景选用流程:极小Bug、单行代码修改可简化流程,直接对话开发;中等及以上功能迭代、跨模块修改、架构调整,必须完整走propose-apply-archive流程。
-
定期梳理归档文档:周期性查看归档目录,沉淀通用业务规范与技术方案,逐步完善项目知识库,降低新人上手成本。
六、总结:从"随性AI编码"到"工程化AI研发"
AI编程的发展早已从"能不能用"进入"好不好用、省不省钱、稳不稳定"的阶段。传统纯对话模式,本质是"随性编码",短期提升书写速度,但长期面临需求失真、代码混乱、成本失控等一系列问题,无法支撑正规项目与团队协作。
OpenSpec与CodeGraph的组合,构建了一套完整的AI编程工程化方案:OpenSpec守住"需求与规范"入口,把模糊的口头约定变成可审查、可追溯、可迭代的标准化契约,解决需求还原度低、编码不规范的问题;CodeGraph打通"代码检索"通路,用本地知识图谱替代全量文件扫描,从根源削减Token消耗,同时保证新代码与存量架构兼容,提升代码上线采用率。
对于个人开发者而言,这套组合可以减少返工、节约Token成本,让AI真正成为高效生产力;对于团队而言,它统一了开发流程与编码规范,沉淀项目知识资产,降低协作与维护成本。
对洞窝而言,OpenSpec+CodeGraph 的落地不仅降低了 AI 编程的成本与返工率,更让中台团队的技术规范沉淀为可复用的知识资产------家居零售业务场景复杂、迭代快,这套方案让 AI 真正适配洞窝的业务特性,实现**"规范提效、成本可控、代码可用"**的三重目标。未来我们也会持续探索 AI 编程在家居零售中台的落地边界,为行业提供可参考的实战经验。