1、研究动机
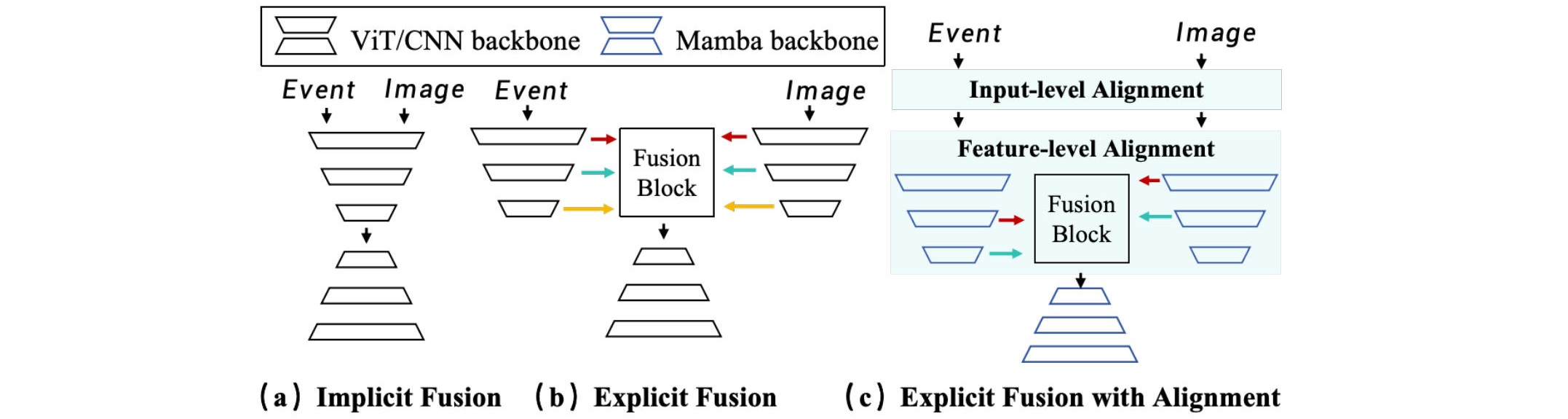
该论文研究事件相机+图像结合用于深度估计。如下图所示,当前方法包括隐式融合(多模态数据直接拼接输入编码器),显示融合(多模态分别提取特征,由融合模块融合特征),作者提出一种全新方案,输入数据先进行特征对齐(SCPG),同时构建非对称模态编码器(AME),然后中间进行模态交互局部细化(ModiLocal)。
2、模型框架
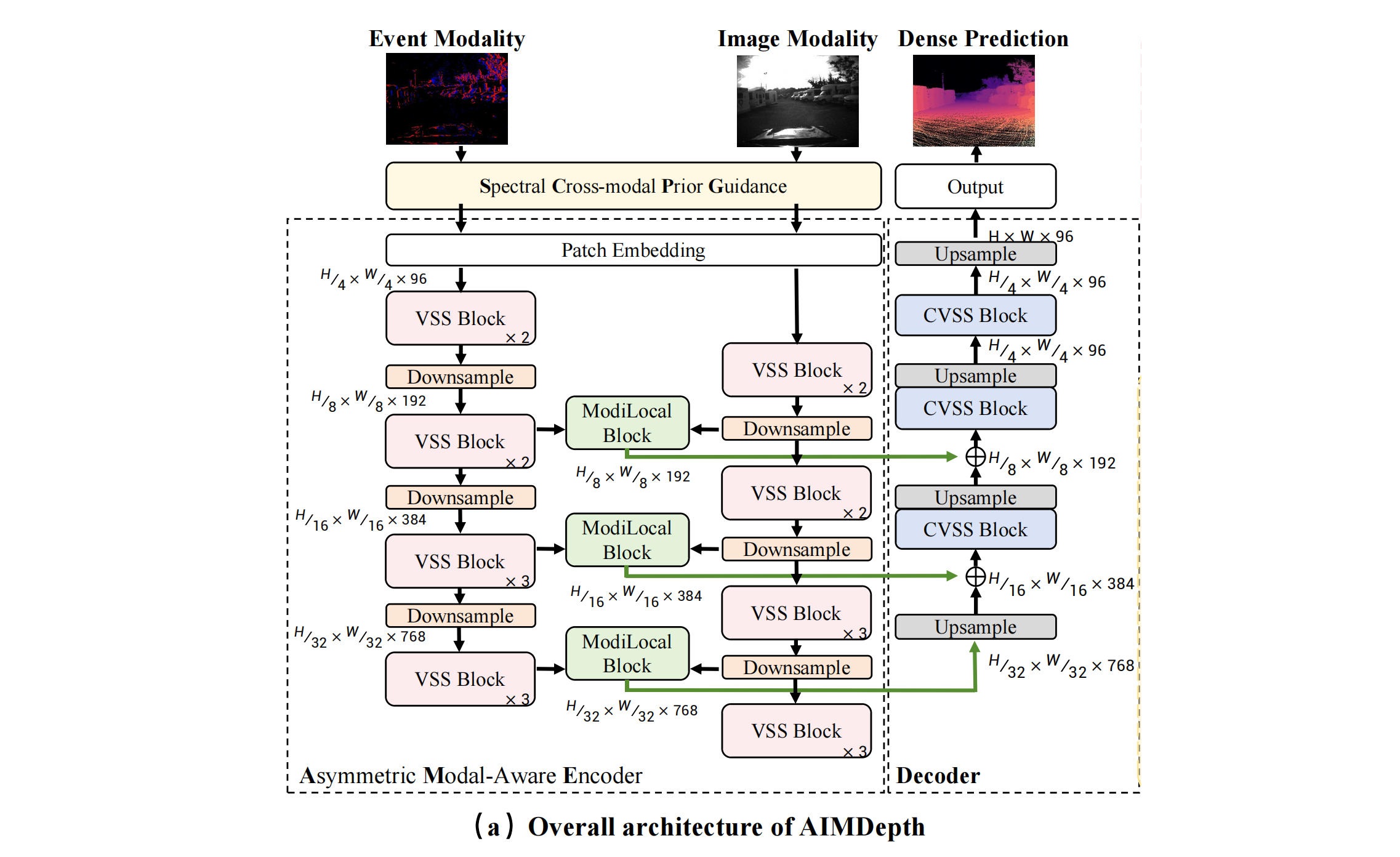
AIMDepth 采用类 U-Net结构,全程基于 SSM 搭建,整体分为四大核心模块,流程:输入预处理 → 输入层对齐 (SCPG) → 非对称模态编码器 (AME) → 模态交互局部细化 (ModiLocal) → Mamba 解码器 → 深度图输出。
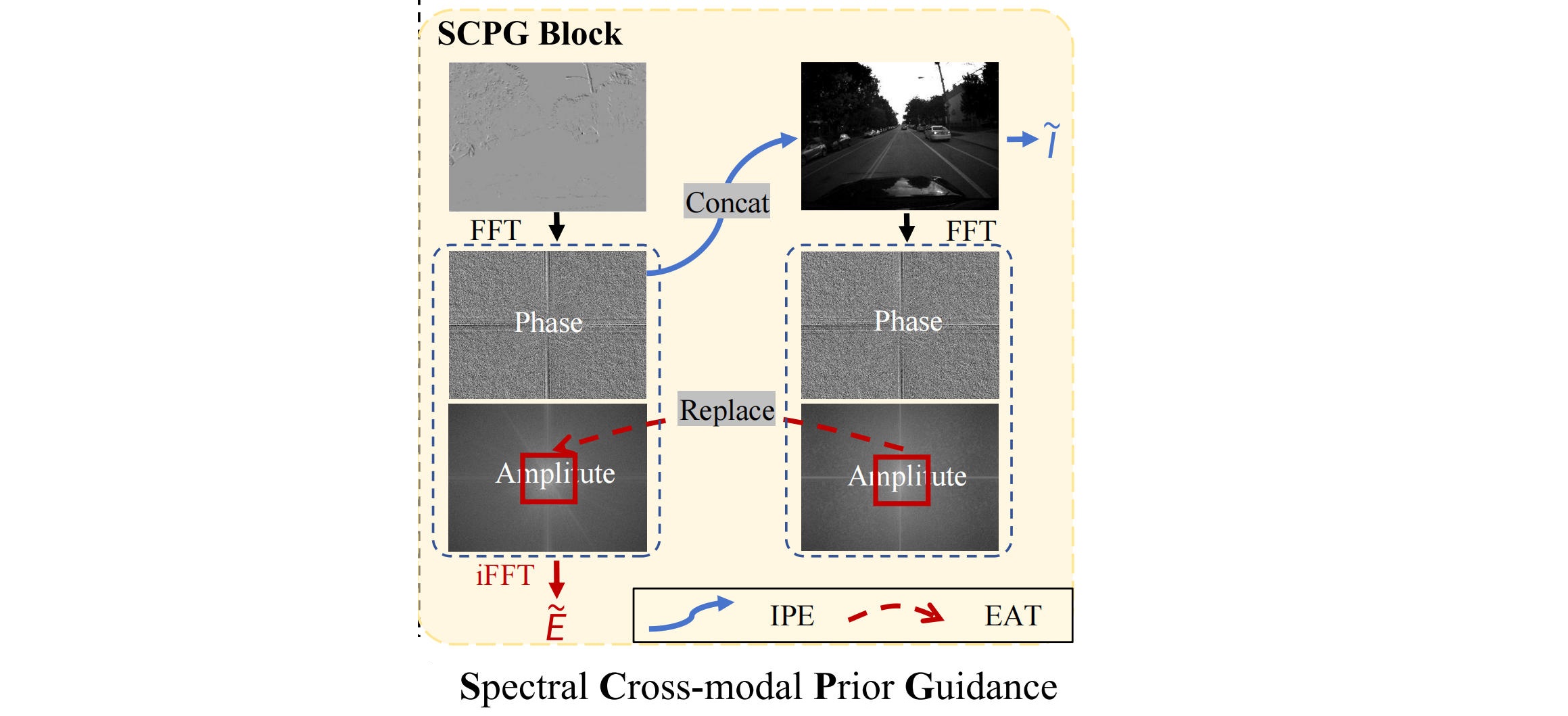
(1)Spectral Cross-Modal Prior Guidance (SCPG)。 对图像、事件做二维离散傅里叶变换 (DFT),分解为振幅谱 + 相位谱。 **事件表征增强:**用掩码选取低频区域,将图像低频振幅替换事件低频振幅,保留事件原有高频时域动态,逆傅里叶变换得到结构增强后的事件表征。 图像表征增强: 事件相位谱保留精细边缘与运动边界,弥补静态图像时域缺失问题。选取全局响应最强的两个事件通道,提取其相位图;将原图与相位图通道拼接,为图像注入动态运动线索。
(2)Asymmetric Modal-Aware Encoder (AME)。 图像是稠密纹理,浅层网络可提取空间细节。事件是稀疏动态,深层网络才能挖掘时空语义。非对称特征选择即对图像特征,保留前 3 层浅层特征。对于事件特征,保留后3层深层特征。共享权重控制参数量,分层特征选择完成特征级模态对齐,适配两种模态的表达规律。
(3)ModiLocal Block。 先进行 ISS 全局交互式扫描,然后进行LSS局部空间扫描。模块收尾加入SE注意力,自适应加权通道特征。