Docling 文档转换以及技术架构分析
背景:
由于现在的主流的大语言模型 (LLM) 通常以纯文本序列作为输入,本身不能直接处理 PDF、Word、wps、image 等二进制文件的内容做为上下文。在项目工程中要想让LLM读取这些非结构化的文档需要借助专门的工程技术,将这些原始的非结构化的文档转换为保留语义和结构的文本格式内容(如:markdown、结构化的JSON等)。
使用传统的工程要想将非结构化的文档转换为能保持自然阅读顺序 、层次结构 、智能识别表格 、理解图表语义等还需要借助多种技术(各种文档解析器,ocr技术、专用格式识别小模型等 ),然后再结合工程技术、算法等手段将文档内容进行拼接、校验、审核等多种步骤。
虽然这几年LLM的发展,也有很多文档识别的专用ocr模型发布,包括但不限于MinerU、DeepSeekOCR、GLM-OCR、Qianfan-OCR等,这些模型在内容识别和提取上面比传统的 ocr 提取会更好更便捷。
传统 OCR 是"基于规则与特征工程"的字符识别,而现在的 OCR 模型是"数据驱动、端到端学习与语义理解"的视觉理解系统。
传统的 OCR:工程拼接
传统 OCR 想要拿到准确结果,必须依赖一套复杂的设计规则。
• 人工干预多: 工程师必须针对特定场景,编写大量规则。
• 工作繁琐: 必须先做去噪、二值化、矫正、字符切割。
• 容错率极低: 只要前面某一步(比如切字)切歪了,后面就彻底识别错误。
- 工程重心: 怎么把字切干净、怎么去噪点、怎么让机器看清这个字。
现在的 OCR:端到端、数据驱动的统一模型
现代 OCR 实现了真正的"输入图片 获得结果"(即端到端 End-to-End 模式)。
• 模型自己学: 复杂的裁剪、矫正、特征提取,全部在神经网络内部自动完成。
• 抗干扰强: 即使图片有折痕、反光、字迹粘连,模型也能结合上下文"猜"出正确内容。
- 工程重点:怎么把识别出来的文字结构化。
Docling 正是使用传统工程框架技术和现代的识别技术(VLM、端到端ocr)深度融合,提供了一体化的解决方案,专门解决复杂的非结构化文档转换为结构化的文档的工程化难题,减低了开发者快速构建文档解析的功能和项目的门槛。
一、Docling 项目概述
Docling 是 IBM Research 开发的文档处理库,专为生成式 AI 应用设计。其核心目标是简化多种文档格式的解析,并提供与 AI 生态系统的无缝集成。
官方资源:
-
GitHub: github.com/docling-pro...
-
开源协议:MIT License
-
社区支持:Discord, GitHub Discussions
Python 版本: 3.10+
核心特性概览:
- 🗂️ 支持文档格式:PDF、DOCX、PPTX、XLSX、HTML、Markdown、LaTeX、 图片(PNG、JPEG/JPG、TIFF、WEBP)、音频(WAV、MP3)
- 📑 高级 PDF 理解(布局分析、阅读顺序、表格结构、公式、代码)
- 🧬 统一的 DoclingDocument 文档表示
- ↪️ 多种导出格式(Markdown、HTML、JSON、DocTags 等)
- 🔍 完整的 OCR 支持(Tesseract、EasyOCR、RapidOCR 等)
- 👓 多 VLM 模型集成(Granite-Docling、Qwen2.5-VL 等)
- 🎙️ 音频处理能力(Whisper ASR)
- 🤖 丰富的 AI 框架集成(LangChain、LlamaIndex、Haystack 等)
二、目录结构和模块组织
bash
docling/
├── docling/ # 主 Python 包
│ ├── backend/ # 文档后端解析器
│ │ ├── abstract_backend.py # 抽象后端基类
│ │ ├── pdf_backend.py # PDF 后端接口
│ │ ├── docling_parse_backend.py
│ │ ├── pypdfium2_backend.py
│ │ ├── msword_backend.py # Word 文档后端
│ │ ├── msexcel_backend.py # Excel 后端
│ │ ├── mspowerpoint_backend.py # PowerPoint 后端
│ │ ├── html_backend.py # HTML 后端
│ │ ├── md_backend.py # Markdown 后端
│ │ ├── latex_backend.py # LaTeX 后端
│ │ ├── csv_backend.py # CSV 后端
│ │ └── xml/ # XML 格式后端
│ │ ├── jats_backend.py # JATS 学术文章
│ │ ├── uspto_backend.py # USPTO 专利
│ │ └── xbrl_backend.py # XBRL 财务报告
│ │
│ ├── datamodel/ # 数据模型层
│ │ ├── document.py # 核心文档模型 (InputDocument, ConversionResult)
│ │ ├── base_models.py # 基础模型 (Page, Cluster, Table 等)
│ │ ├── pipeline_options.py # 管道配置选项
│ │ ├── backend_options.py # 后端配置选项
│ │ ├── settings.py # 全局设置
│ │ ├── accelerator_options.py # 加速器配置
│ │ ├── layout_model_specs.py # 布局模型规格
│ │ ├── stage_model_specs.py # 阶段模型规格
│ │ └── vlm_model_specs.py # VLM 模型规格
│ │
│ ├── pipeline/ # 处理管道层
│ │ ├── base_pipeline.py # 管道抽象基类
│ │ ├── simple_pipeline.py # 简单管道(无 ML 模型)
│ │ ├── standard_pdf_pipeline.py # 标准 PDF 管道(多线程)
│ │ ├── vlm_pipeline.py # VLM 管道
│ │ ├── asr_pipeline.py # 音频识别管道
│ │ └── extraction_vlm_pipeline.py # 提取管道
│ │
│ ├── models/ # 模型层
│ │ ├── base_model.py # 模型基类
│ │ ├── base_layout_model.py # 布局模型基类
│ │ ├── base_ocr_model.py # OCR 模型基类
│ │ ├── base_table_model.py # 表格模型基类
│ │ ├── picture_description_base_model.py
│ │ ├── factories/ # 模型工厂
│ │ │ ├── base_factory.py # 工厂基类
│ │ │ ├── ocr_factory.py
│ │ │ ├── layout_factory.py
│ │ │ ├── table_factory.py
│ │ │ └── picture_description_factory.py
│ │ ├── stages/ # 处理阶段模型
│ │ │ ├── layout/ # 布局分析
│ │ │ ├── ocr/ # OCR 引擎
│ │ │ ├── table_structure/ # 表格结构
│ │ │ ├── page_preprocessing/ # 页面预处理
│ │ │ ├── page_assemble/ # 页面组装
│ │ │ ├── reading_order/ # 阅读顺序
│ │ │ ├── picture_classifier/ # 图片分类
│ │ │ ├── picture_description/ # 图片描述
│ │ │ ├── code_formula/ # 代码/公式提取
│ │ │ └── chart_extraction/ # 图表提取
│ │ └── inference_engines/ # 推理引擎
│ │ ├── vlm/ # VLM 引擎
│ │ ├── object_detection/ # 目标检测
│ │ └── image_classification/ # 图像分类
│ │
│ ├── utils/ # 工具模块
│ │ ├── profiling.py # 性能分析
│ │ ├── visualization.py # 可视化
│ │ ├── ocr_utils.py # OCR 工具
│ │ └── model_downloader.py # 模型下载
│ │
│ ├── chunking/ # 文档分块(RAG 支持)
│ ├── cli/ # 命令行接口
│ │ ├── main.py # 主 CLI 入口
│ │ └── tools.py # 工具命令
│ │
│ ├── document_converter.py # 文档转换器(主入口)
│ ├── document_extractor.py # 文档提取器
│ └── exceptions.py # 异常定义
│
├── tests/ # 测试套件
├── docs/ # 文档
└── packages/ # 元包
├── docling/ # 完整包
└── docling-slim/ # 精简包三、核心模块和职责
3.1 入口点模块 (Entrypoints Layer)
作用:提供用户与 Docling 交互的主要接口,包括 Python API 和命令行工具。
| 模块 | 职责 | 关键类 |
|---|---|---|
document_converter.py |
文档转换主入口,管理格式到后端的映射 | DocumentConverter, FormatOption |
document_extractor.py |
结构化信息提取入口 | DocumentExtractor, ExtractionFormatOption |
cli/main.py |
命令行接口 | app (Typer), convert() |
3.2 数据模型层 (Data Model Layer)
作用:定义核心数据结构和配置选项。
| 模块 | 职责 | 关键类 |
|---|---|---|
document.py |
文档表示和转换结果 | InputDocument, ConversionResult, DoclingDocument |
base_models.py |
基础数据结构 | Page, Cluster, Table, LayoutPrediction |
pipeline_options.py |
管道配置 | PipelineOptions, PdfPipelineOptions, OcrOptions |
3.3 后端层 (Backend Layer)
作用:负责解析各种输入格式的原始文档,提取文档内容和结构信息,并转换为统一的 DoclingDocument 格式。
| 后端类型 | 支持格式 | 实现类 |
|---|---|---|
| PDF 后端 | DoclingParseDocumentBackend, PyPdfiumDocumentBackend |
|
| Office 后端 | DOCX, PPTX, XLSX | MsWordDocumentBackend, MsPowerpointDocumentBackend, MsExcelDocumentBackend |
| Web 后端 | HTML, Markdown | HTMLDocumentBackend, MarkdownDocumentBackend |
| 图像后端 | JPG, PNG, TIFF 等 | ImageDocumentBackend |
| XML 后端 | USPTO, JATS, XBRL | PatentUsptoDocumentBackend, JatsDocumentBackend, XBRLDocumentBackend |
| 其他 | LaTeX, CSV, VTT, Audio | LatexDocumentBackend, CsvDocumentBackend, WebVTTDocumentBackend |
3.4 管道层 (Pipeline Layer)
作用:组织和管理文档处理的各个阶段(预处理、OCR、布局分析、表格识别等),实现流水线式的多级处理。
| 管道类型 | 职责 | 关键类 |
|---|---|---|
BasePipeline |
管道抽象基类 | execute(), _build_document(), _assemble_document(), _enrich_document() |
SimplePipeline |
无 ML 模型的简单转换 | 直接后端转换 |
StandardPdfPipeline |
完整 PDF 处理管道 | 多线程流水线处理 |
VlmPipeline |
VLM 驱动的文档理解 | 端到端视觉语言模型处理 |
AsrPipeline |
音频转文本 | Whisper 等 ASR 模型 |
3.5 模型层 (Models Layer)
作用:提供具体的机器学习模型实现(布局检测、OCR、表格识别、图片分类等),执行文档理解的核心 AI 推理任务。
| 阶段 | 模型类型 | 实现 |
|---|---|---|
| 布局分析 | Object Detection | LayoutModel, LayoutObjectDetectionModel |
| OCR | 多引擎支持 | EasyOcrModel, TesseractOcrModel, RapidOcrModel |
| 表格结构 | TableFormer | TableStructureModel, TableStructureModelV2 |
| 图片分类 | Image Classification | DocumentPictureClassifier |
| 图片描述 | VLM | PictureDescriptionVlmModel, PictureDescriptionApiModel |
| 代码/公式 | VLM | CodeFormulaVlmModel |
| 阅读顺序 | Rule-based | ReadingOrderModel |
四、完整示例代码
4.1 本地模型完整配置
py
from ast import arg
import os
import logging
from pathlib import Path
from typing import Optional
model_dir = Path(__file__).parent / "model"
os.environ["HF_HOME"] = str(model_dir)
os.environ["HF_HUB_OFFLINE"] = "1" # 离线模式,使用本地模型
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
from docling.document_converter import (
DocumentConverter,
ExcelFormatOption,
ImageFormatOption,
PdfFormatOption,
PowerpointFormatOption,
WordFormatOption,
)
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import (
PdfPipelineOptions,
RapidOcrOptions,
LayoutOptions,
TableStructureOptions,
)
from docling.datamodel.accelerator_options import AcceleratorOptions
from docling.datamodel.document import ConversionResult
# 配置日志
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
)
logger = logging.getLogger(__name__)
class LocalDoclingConverter:
"""本地 Docling 转换器(完整配置)"""
def __init__(self, model_dir: Optional[Path] = None):
"""
初始化本地转换器
Args:
model_dir: 模型存储目录,默认为脚本所在目录的 model 文件夹
"""
self.model_dir = model_dir or Path(__file__).parent / "model"
self.model_dir.mkdir(parents=True, exist_ok=True)
# 设置环境变量(离线模式)
os.environ["HF_HOME"] = str(self.model_dir)
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 使用镜像源
os.environ["DOCLING_ARTIFACTS_PATH"] = str(self.model_dir)
os.environ["HF_HUB_OFFLINE"] = "1" # 强制离线模式,使用本地缓存
logger.info(f"模型目录:{self.model_dir}")
logger.info(f"模型目录存在:{self.model_dir.exists()}")
def _build_pipeline_options(self) -> PdfPipelineOptions:
"""构建完整的 PDF 管道配置"""
# 1. 配置加速器选项
accelerator_options = AcceleratorOptions(
device="auto", # 或 "cuda", "cpu", "mps"
num_threads=1, # 具体使用进行数(越大越快、占用内存越高)
)
# 2. 配置 RapidOCR 选项(使用 V5 server 模型,最高精度)
rapidocr_base = self.model_dir / "rapidocr_ms" / "onnx" / "PP-OCRv5"
det_path = rapidocr_base / "det" / "ch_PP-OCRv5_det_server.onnx"
rec_path = rapidocr_base / "rec" / "ch_PP-OCRv5_rec_server.onnx"
cls_path = rapidocr_base / "cls" / "ch_PP-LCNet_x1_0_textline_ori_cls_server.onnx"
# 检查模型文件
for model_path, model_name in [
(det_path, "检测模型"),
(rec_path, "识别模型"),
(cls_path, "分类模型"),
]:
if not model_path.exists():
logger.error(f"{model_name}不存在:{model_path}")
logger.error("请先运行 download_models() 下载模型")
raise FileNotFoundError(f"{model_name}不存在:{model_path}")
ocr_options = RapidOcrOptions(
det_model_path=str(det_path), # 检测模型地址(检测图片中文字的位置,找出包含文字的区域,文本区域画框,并裁剪)
rec_model_path=str(rec_path),# 识别模型地址(识别被裁剪出来的文字内容)
cls_model_path=str(cls_path), # 分类模型地址(识别文字的具体方向、角度)
backend="onnxruntime",
lang=["chinese", "english"],
use_det=True,
use_rec=True,
use_cls=True,
force_full_page_ocr=True,
)
# 3. 配置布局模型选项
layout_options = LayoutOptions(
model_path=str(self.model_dir / "docling-layout-heron"),
confidence_threshold=0.8,
)
# 4. 配置表格结构选项
from docling.datamodel import pipeline_options
table_options = TableStructureOptions(
model_path=str(self.model_dir / "docling-models" / "model_artifacts" / "tableformer"),
do_cell_matching=True,
mode=pipeline_options.TableFormerMode.ACCURATE #(ACCURATE, FAST)
)
# 5. 配置代码公式选项和图片描述(使用本地 SmolVLM 模型)
from docling.datamodel.pipeline_options import CodeFormulaVlmOptions, PictureDescriptionVlmEngineOptions
from docling.datamodel.stage_model_specs import VlmModelSpec, EngineModelConfig
from docling.models.inference_engines.vlm.base import VlmEngineType
# 创建自定义 model_spec,指定本地模型路径
local_model_spec = VlmModelSpec(
name="SmolVLM-Local",
default_repo_id="HuggingFaceTB/SmolVLM-256M-Instruct",
revision="main",
prompt="Describe this image in a few sentences.",
response_format="plaintext",
# 关键:通过 engine_overrides 指定本地路径
engine_overrides={
VlmEngineType.TRANSFORMERS: EngineModelConfig(
repo_id=str(self.model_dir / "SmolVLM-256M-Instruct"), # 本地绝对路径
)
},
)
# 代码公式配置
code_formula_options = CodeFormulaVlmOptions.from_preset(
"codeformulav2",
model_spec=local_model_spec,
)
# 图片描述配置(使用本地模型)
picture_description_options = PictureDescriptionVlmEngineOptions.from_preset(
"smolvlm",
model_spec=local_model_spec,
)
# 6. 配置 PDF 管道选项
pipeline_options = PdfPipelineOptions(
# 加速器配置
accelerator_options=accelerator_options,
# 功能开关 - 全部启用
do_ocr=True, # 启用 OCR
do_table_structure=True, # 启用表格识别
do_code_enrichment=True, # 启用代码识别(SmolVLM 已下载)
do_formula_enrichment=True, # 启用公式识别(SmolVLM 已下载)
do_picture_description=True, # 启用 VLM 图片描述(SmolVLM 已下载)
# 图片生成 - 全部开启
generate_page_images=True,
generate_picture_images=True,
generate_table_images=True,
# 模型配置
layout_options=layout_options,
ocr_options=ocr_options,
table_structure_options=table_options,
code_formula_options=code_formula_options,
picture_description_options=picture_description_options,
# 图片缩放(平衡质量和内存)
images_scale=1.0, # 100% 原始分辨率
# 批处理配置(控制内存峰值)
ocr_batch_size=1, # OCR 批处理大小:1=单页处理(省内存),大值=批量处理(速度快但占用更多内存)
layout_batch_size=1, # 布局检测批处理大小:1=逐页检测,大值=批量检测
table_batch_size=1, # 表格识别批处理大小:1=逐页识别,大值=批量识别
# 超时配置
document_timeout=600, # 10 分钟超时
)
return pipeline_options
def create_converter(self) -> DocumentConverter:
"""创建转换器实例(支持 PDF 和 DOCX)"""
pipeline_options = self._build_pipeline_options()
converter = DocumentConverter(
allowed_formats=[
InputFormat.PDF,
InputFormat.DOCX,
InputFormat.PPTX,
InputFormat.XLSX,
InputFormat.IMAGE
],
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_options=pipeline_options,
),
InputFormat.DOCX: WordFormatOption(
pipeline_options=pipeline_options,
),
InputFormat.PPTX: PowerpointFormatOption(
pipeline_options=pipeline_options
),
InputFormat.XLSX: ExcelFormatOption(
pipeline_options=pipeline_options
),
InputFormat.IMAGE: ImageFormatOption(
pipeline_options=pipeline_options
)
},
)
return converter
def convert(self, source: Path) -> Optional[ConversionResult]:
"""
转换文档(支持 PDF 和 DOCX)
Args:
source: 输入文件路径(PDF 或 DOCX)
Returns:
转换结果,失败返回 None
"""
try:
# 检查文件格式
suffix = Path(source).suffix.lower()
if suffix not in [".pdf", ".docx"]:
logger.error(f"不支持的文件格式:{suffix},仅支持 .pdf 和 .docx")
return None
converter = self.create_converter()
result = converter.convert(source)
if result.document is None:
logger.error(f"转换失败:{source}")
return None
logger.info(f"转换成功:{source}")
return result
except Exception as e:
logger.error(f"转换异常:{e}")
return None
def convert_to_markdown(self, source: Path, export_images: bool = False) -> Optional[str]:
"""
转换为 Markdown
Args:
source: 输入文件路径
export_images: 是否导出图片到单独文件夹
Returns:
Markdown 内容,失败返回 None
"""
result = self.convert(source)
if result is None:
return None
output_path = Path(source).with_suffix(".md")
output_dir = output_path.parent / (output_path.stem + "_images")
if export_images:
# 导出图片并生成带图片引用的 Markdown
output_dir.mkdir(parents=True, exist_ok=True)
# 导出页面图片
for page_no, page in enumerate(result.document.pages.values()):
if page.image:
img_path = output_dir / f"page_{page_no + 1:03d}.png"
page.image.save(img_path, format="PNG")
logger.info(f"导出页面图片:{img_path}")
markdown = result.document.export_to_markdown(
image_placeholder="",
)
else:
markdown = result.document.export_to_markdown()
output_path.parent.mkdir(parents=True, exist_ok=True)
with open(output_path, "w", encoding="utf-8") as f:
f.write(markdown)
logger.info(f"Markdown 已保存:{output_path}")
return markdown
# 使用示例
if __name__ == "__main__":
# 1. 创建转换器(自动设置模型目录)
converter_app = LocalDoclingConverter()
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--action', type=str, help='please input download or convert;\n download action do model download \nconvert action do document convert \ndefaule action is convert', default="convert")
args = parser.parse_args()
if (args.action == "download"):
# 2. 下载模型(首次运行需要)
print("*" * 30)
print("模型目录 docling_demo")
print("*" * 30)
print()
if (args.action == "convert"):
# 3. 转换文档
input_pdf = Path("pdf/UVD_UVS_demo_LLM.pdf")
markdown = converter_app.convert_to_markdown(input_pdf)
if markdown:
print("=" * 60)
print("OK: Conversion completed!")
print("=" * 60)
print(markdown[:1000].encode('utf-8').decode('utf-8', errors='ignore'))4.2 远程 VLM API 完整配置
py
#!/usr/bin/env python
"""
Docling 远程 VLM API 完整示例
- 支持 OpenAI 兼容 API
- 支持 VLLM 服务器
- 支持 Watsonx.ai
- 完整的流水线配置
"""
import os
import logging
from pathlib import Path
from typing import Optional, Dict, Any
from dataclasses import dataclass
import requests
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import (
VlmPipelineOptions,
VlmConvertOptions,
ResponseFormat,
)
from docling.datamodel.vlm_engine_options import (
ApiVlmEngineOptions,
VlmEngineType,
)
from docling.pipeline.vlm_pipeline import VlmPipeline
from docling.datamodel.document import ConversionResult
# 配置日志
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
)
logger = logging.getLogger(__name__)
@dataclass
class VlmConfig:
"""VLM 配置数据类"""
name: str
url: str
api_key: str
model: str
temperature: float = 0.0
max_tokens: int = 32000
timeout: int = 90
extra_params: Optional[Dict[str, Any]] = None
# 预定义的 VLM 配置
VLM_CONFIGS = {
"openai": VlmConfig(
name="OpenAI GPT-4 Vision",
url="https://api.openai.com/v1/chat/completions",
api_key=os.environ.get("OPENAI_API_KEY", ""),
model="gpt-4-vision-preview",
max_tokens=4096,
),
"azure_openai": VlmConfig(
name="Azure OpenAI",
url=os.environ.get("AZURE_OPENAI_ENDPOINT", ""),
api_key=os.environ.get("AZURE_OPENAI_KEY", ""),
model=os.environ.get("AZURE_OPENAI_DEPLOYMENT", ""),
),
"vllm_local": VlmConfig(
name="VLLM 本地服务器",
url="http://localhost:8000/v1/chat/completions",
api_key="not-needed", # VLLM 不需要 API Key
model="Qwen/Qwen3.5-397B-A17B",
max_tokens=32000,
extra_params={"skip_special_tokens": False},
),
"deepseek": VlmConfig(
name="DeepSeek",
url="https://api.deepseek.com/v1/chat/completions",
api_key=os.environ.get("DEEPSEEK_API_KEY", ""),
model="deepseek-chat",
),
"siliconflow": VlmConfig(
name="SiliconFlow",
url="https://api.siliconflow.cn/v1/chat/completions",
api_key=os.environ.get("SILICONFLOW_API_KEY", ""),
model="Qwen/Qwen3.5-397B-A17B",
max_tokens=32000,
),
}
# 文档转换提示词模板
DEFAULT_PROMPT_TEMPLATE = """
你现在是专业文档转 Markdown 文件的格式转换专家,请严格按照以下规则处理所提供的原始文档内容:
规则:
1. 文字内容:**100% 最大化原样照搬**,不修改、不润色、不删减、不改写原文措辞、语序、标点、层级、专有名词、数字、表格内容,仅做格式结构化转为标准 Markdown 语法。
2. 排版结构:严格还原原文的标题层级、段落、列表(有序/无序)、引用、加粗、换行、分段、缩进逻辑,用标准 Markdown 语法对应还原。
3. 表格/代码:原文有表格直接转为 Markdown 标准表格;代码片段用 ``` 代码块包裹,保留原格式。
4. 图片处理:对于原文档中所包含的所有图片、截图、示意图、流程图、配图,**转换后不要使用图片占位符**,基于图片上下文、前后文字语义、画面内容,智能生成精准并与原图片内容语义一致的文字描述。文字描述简洁专业,不编造任何无关内容。**对于图片的语义解释,不需要添加图片描述的说明文字**。
5. 内容过滤:自动识别并移除原文中的页码、页眉页脚、水印、印章、批注、广告、版权声明、二维码、联系方式、背景图信息等非正文内容,仅保留核心文档正文。若上述内容与正文语义强相关(如引用的法律条款、署名作者等),则予以保留。
6. 禁止行为:不额外增加解释、不总结、不翻译、不删减原文任何文字、不改变原始语义、不添加额外标点和话术,只做格式转换 + 图片内容的语义文字替代。
7. 输出格式:只返回纯净 Markdown 内容,无多余开场白、无结束语、无额外说明。
"""
class RemoteVlmConverter:
"""远程 VLM 转换器(完整配置)"""
def __init__(self, config_name: str = "vllm_local", custom_config: Optional[VlmConfig] = None):
"""
初始化远程转换器
Args:
config_name: 预定义配置名称(openai, azure_openai, vllm_local, deepseek, siliconflow)
custom_config: 自定义 VLM 配置(如果提供,将覆盖预定义配置)
"""
if custom_config:
self.config = custom_config
else:
if config_name not in VLM_CONFIGS:
raise ValueError(f"未知配置:{config_name},可用配置:{list(VLM_CONFIGS.keys())}")
self.config = VLM_CONFIGS[config_name]
# 验证 API Key
if not self.config.api_key and config_name != "vllm_local":
logger.warning(f"API Key 为空,可能无法访问 {self.config.name}")
logger.info(f"使用 VLM 配置:{self.config.name}")
logger.info(f"API URL: {self.config.url}")
logger.info(f"Model: {self.config.model}")
def check_server_health(self, timeout: int = 5) -> bool:
"""
检查 VLM 服务器健康状态
Args:
timeout: 超时时间(秒)
Returns:
bool: 服务器是否可用
"""
try:
# 尝试获取模型列表
base_url = self.config.url.replace("/chat/completions", "")
response = requests.get(f"{base_url}/models", timeout=timeout)
if response.status_code == 200:
logger.info("VLM 服务器响应正常")
return True
else:
logger.warning(f"VLM 服务器响应异常:{response.status_code}")
return False
except requests.exceptions.RequestException as e:
logger.warning(f"VLM 服务器不可用:{e}")
return False
def _build_vlm_options(self) -> VlmConvertOptions:
"""构建 VLM 选项"""
# 构建 API 参数
params = {
"model": self.config.model,
"temperature": self.config.temperature,
"max_tokens": self.config.max_tokens,
}
# 添加额外参数
if self.config.extra_params:
params.update(self.config.extra_params)
# 创建 VLM 选项
vlm_options = VlmConvertOptions.from_preset(
"granite_docling",
engine_options=ApiVlmEngineOptions(
runtime_type=VlmEngineType.API,
url=self.config.url,
api_key=self.config.api_key,
params=params,
timeout=self.config.timeout,
),
)
# 设置响应格式为 MARKDOWN
vlm_options.model_spec.response_format = ResponseFormat.MARKDOWN
# 设置自定义提示词
vlm_options.model_spec.prompt = DEFAULT_PROMPT_TEMPLATE
return vlm_options
def _build_pipeline_options(self) -> VlmPipelineOptions:
"""构建 VLM 管道选项"""
vlm_options = self._build_vlm_options()
pipeline_options = VlmPipelineOptions(
vlm_options=vlm_options,
enable_remote_services=True,
)
return pipeline_options
def create_converter(self) -> DocumentConverter:
"""创建转换器实例"""
pipeline_options = self._build_pipeline_options()
converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_options=pipeline_options,
pipeline_cls=VlmPipeline,
),
InputFormat.DOCX: PdfFormatOption(
pipeline_options=pipeline_options,
pipeline_cls=VlmPipeline,
),
InputFormat.PPTX: PdfFormatOption(
pipeline_options=pipeline_options,
pipeline_cls=VlmPipeline,
),
InputFormat.IMAGE: PdfFormatOption(
pipeline_options=pipeline_options,
pipeline_cls=VlmPipeline,
),
},
)
return converter
def convert(self, source: Path) -> Optional[ConversionResult]:
"""
转换文档
Args:
source: 输入文件路径
Returns:
转换结果,失败返回 None
"""
# 检查服务器状态(仅对远程 API)
if self.config.name != "vllm_local":
if not self.check_server_health():
logger.error("VLM 服务器不可用,跳过转换")
return None
try:
converter = self.create_converter()
result = converter.convert(source)
if result.document is None:
logger.error(f"转换失败:{source}")
return None
logger.info(f"转换成功:{source}")
return result
except Exception as e:
logger.error(f"转换异常:{e}")
return None
def convert_to_markdown(self, source: Path, output_path: Optional[Path] = None) -> Optional[str]:
"""
转换为 Markdown
Args:
source: 输入文件路径
output_path: 输出文件路径(可选)
Returns:
Markdown 内容,失败返回 None
"""
result = self.convert(source)
if result is None:
return None
markdown = result.document.export_to_markdown()
if output_path:
output_path.parent.mkdir(parents=True, exist_ok=True)
with open(output_path, "w", encoding="utf-8") as f:
f.write(markdown)
logger.info(f"Markdown 已保存:{output_path}")
return markdown
@classmethod
def create_openai_converter(cls) -> "RemoteVlmConverter":
"""快速创建 OpenAI 转换器"""
return cls(config_name="openai")
@classmethod
def create_vllm_converter(cls,
url: str = "http://localhost:8000/v1/chat/completions",
model: str = "Qwen/Qwen3.5-397B-A17B") -> "RemoteVlmConverter":
"""快速创建 VLLM 转换器"""
config = VlmConfig(
name="VLLM 自定义",
url=url,
api_key="not-needed",
model=model,
max_tokens=32000,
extra_params={"skip_special_tokens": False},
)
return cls(custom_config=config)
@classmethod
def create_siliconflow_converter(cls, api_key: Optional[str] = None) -> "RemoteVlmConverter":
"""快速创建 SiliconFlow 转换器"""
config = VlmConfig(
name="SiliconFlow",
url="https://api.siliconflow.cn/v1/chat/completions",
api_key=api_key or os.environ.get("SILICONFLOW_API_KEY", ""),
model="Qwen/Qwen3.5-397B-A17B",
max_tokens=32000,
)
return cls(custom_config=config)
# 使用示例
if __name__ == "__main__":
# ========== 方式 1:使用预定义配置 ==========
# 使用 VLLM 本地服务器
converter = RemoteVlmConverter(config_name="vllm_local")
# 或使用 OpenAI
# converter = RemoteVlmConverter(config_name="openai")
# 或使用 SiliconFlow
# converter = RemoteVlmConverter(config_name="siliconflow")
# ========== 方式 2:使用快速创建方法 ==========
# VLLM 转换器
# converter = RemoteVlmConverter.create_vllm_converter(
# url="http://localhost:8000/v1/chat/completions",
# model="Qwen/Qwen3.5-397B-A17B",
# )
# SiliconFlow 转换器
# converter = RemoteVlmConverter.create_siliconflow_converter(api_key="your-api-key")
# ========== 方式 3:使用自定义配置 ==========
# custom_config = VlmConfig(
# name="自定义 VLM",
# url="https://your-api.com/v1/chat/completions",
# api_key="your-api-key",
# model="your-model-name",
# max_tokens=32000,
# )
# converter = RemoteVlmConverter(custom_config=custom_config)
# ========== 执行转换 ==========
input_pdf = Path("document.pdf")
output_md = Path("output.md")
markdown = converter.convert_to_markdown(input_pdf, output_md)
if markdown:
print("=" * 60)
print("转换完成!")
print("=" * 60)五、数据流和处理流程
5.1 整体处理流程图
5.2 OCR 三个模型处理流程
RapidOCR 使用三个独立的模型协同工作,完成从图片到文本的转换:
三个模型的职责:
| 模型 | 输入 | 输出 | 作用 |
|---|---|---|---|
| 检测模型 (det) | 整页图片 | 文字框坐标 | 定位文字在哪里 |
| 分类模型 (cls) | 文字区域图片 | 方向角度 | 判断文字方向,纠正旋转 |
| 识别模型 (rec) | 纠正后的文字图片 | 文本内容 | 将图片转换为可读文本 |
为什么需要三个独立模型?
- 模块化设计 - 每个模型专注一个任务,可以独立优化
- 性能优化 - 检测模型可以处理大图片,识别模型专注小区域
- 准确性 - 专用模型比单一模型更准确
5.3 复杂文档处理流程
5.3.1 DOCX (Word) 文档转换流程
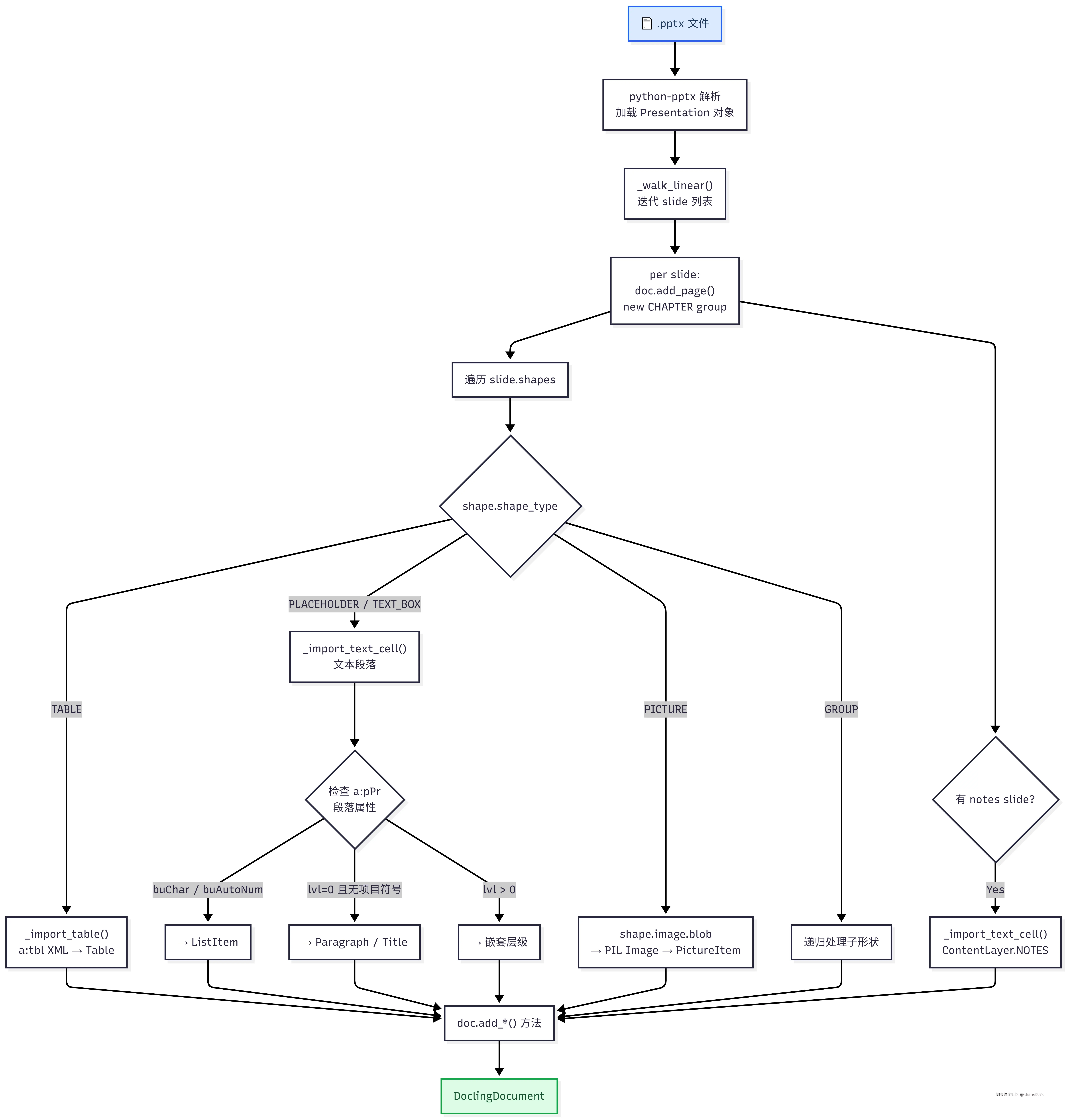
5.3.2 PPTX (PowerPoint) 文档转换流程
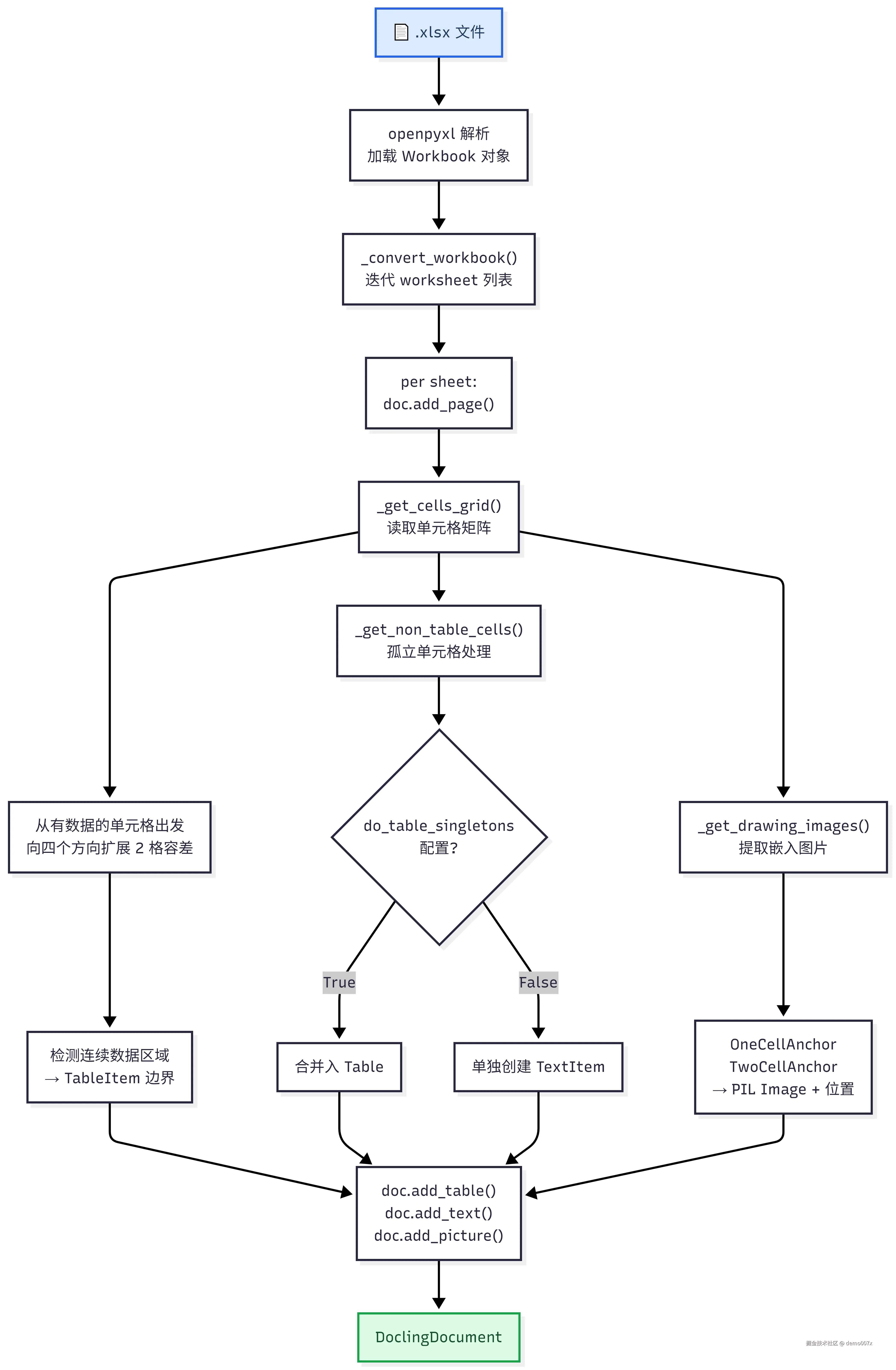
5.3.3 XLSX (Excel) 文档转换流程
5.3.4 PDF/image 文档转换流程
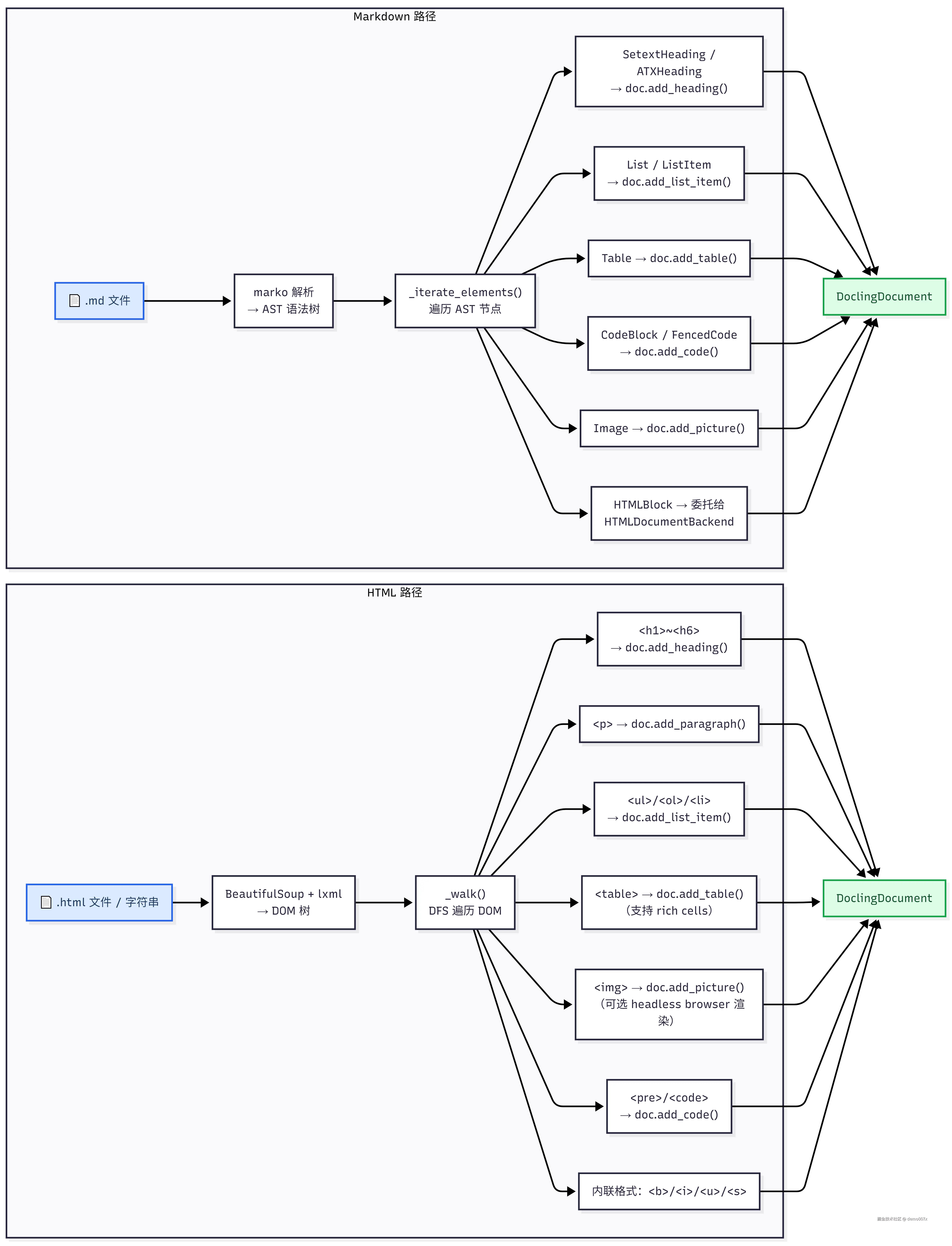
5.3.5 HTML / Markdown 文档转换流程
5.4 页面元素组装
5.4.1 页面元素类型
说明:下图展示了 Docling 中页面元素的继承关系和核心数据结构。
- TextElement:文本元素(段落、标题、列表项、代码、公式等)
- Table:表格元素(包含行列数和单元格列表)
- FigureElement:图片元素(包含标注和分类信息)
- ContainerElement:容器元素(表单、键值对区域)
- Cluster:布局分析阶段的临时容器,包含多个 TextCell(文本单元格)
- DocItemLabel:17 种元素标签枚举
5.4.2 元素类型详细说明
| 元素类型 | 对应 DocItemLabel | 描述 | 示例 |
|---|---|---|---|
| TextElement | TEXT, PARAGRAPH | 普通文本段落 | 正文内容 |
| TextElement | SECTION_HEADER, TITLE | 章节标题/文档标题 | "第一章 引言" |
| TextElement | PAGE_HEADER, PAGE_FOOTER | 页眉页脚 | 页码、公司名 |
| TextElement | FOOTNOTE | 脚注/尾注 | 参考文献注 |
| TextElement | CAPTION | 图注/表注 | "图 1: 系统架构" |
| TextElement | LIST_ITEM | 列表项 | "• 项目一" |
| TextElement | CODE | 代码块 | print("Hello") |
| TextElement | FORMULA | 数学公式 | "E = mc²" |
| TextElement | CHECKBOX_SELECTED | 已选复选框 | "☑ 同意" |
| TextElement | CHECKBOX_UNSELECTED | 未选复选框 | "☐ 选项" |
| Table | TABLE, DOCUMENT_INDEX | 表格/索引 | 数据表格 |
| FigureElement | PICTURE | 图片/图表 | 流程图、截图 |
| ContainerElement | FORM | 表单区域 | 申请表单 |
| ContainerElement | KEY_VALUE_REGION | 键值对区域 | 发票信息区 |
5.4.3 页面组装流程 (PageAssembleModel)
说明:PageAssembleModel仅用于 PDF 和图像文档!
DOCX、PPTX、XLSX、HTML、Markdown 等结构化格式不使用 PageAssembleModel
这些格式通过SimplePipeline直接解析为DoclingDocument
只有 PDF/图像等非结构化格式才需要 StandardPdfPipeline+PageAssembleModel
5.5 阅读顺序
5.5.1 阅读顺序处理流程
5.5.2 阅读顺序排序规则
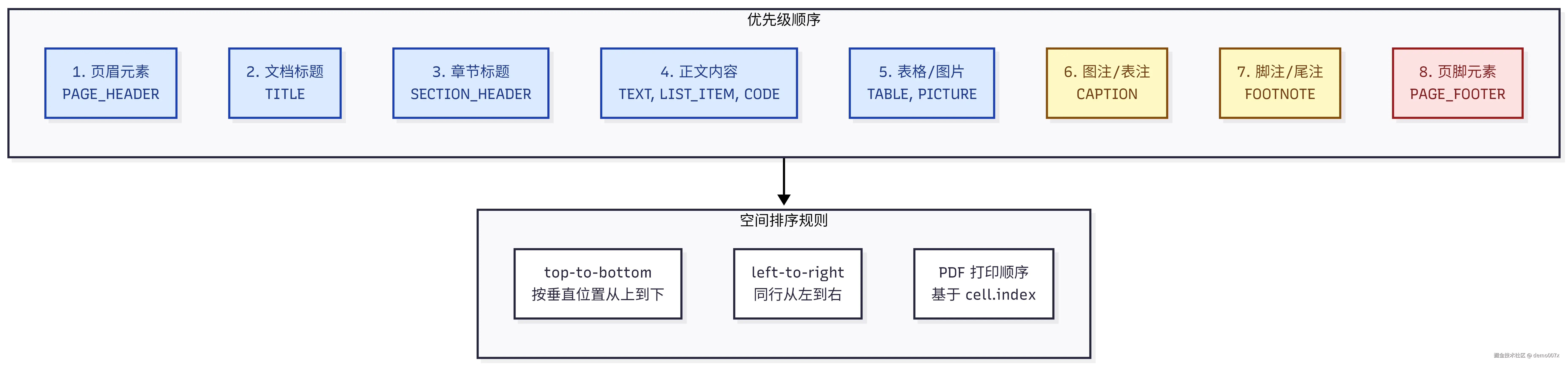
5.5.3 元素合并机制 (跨页文本处理)
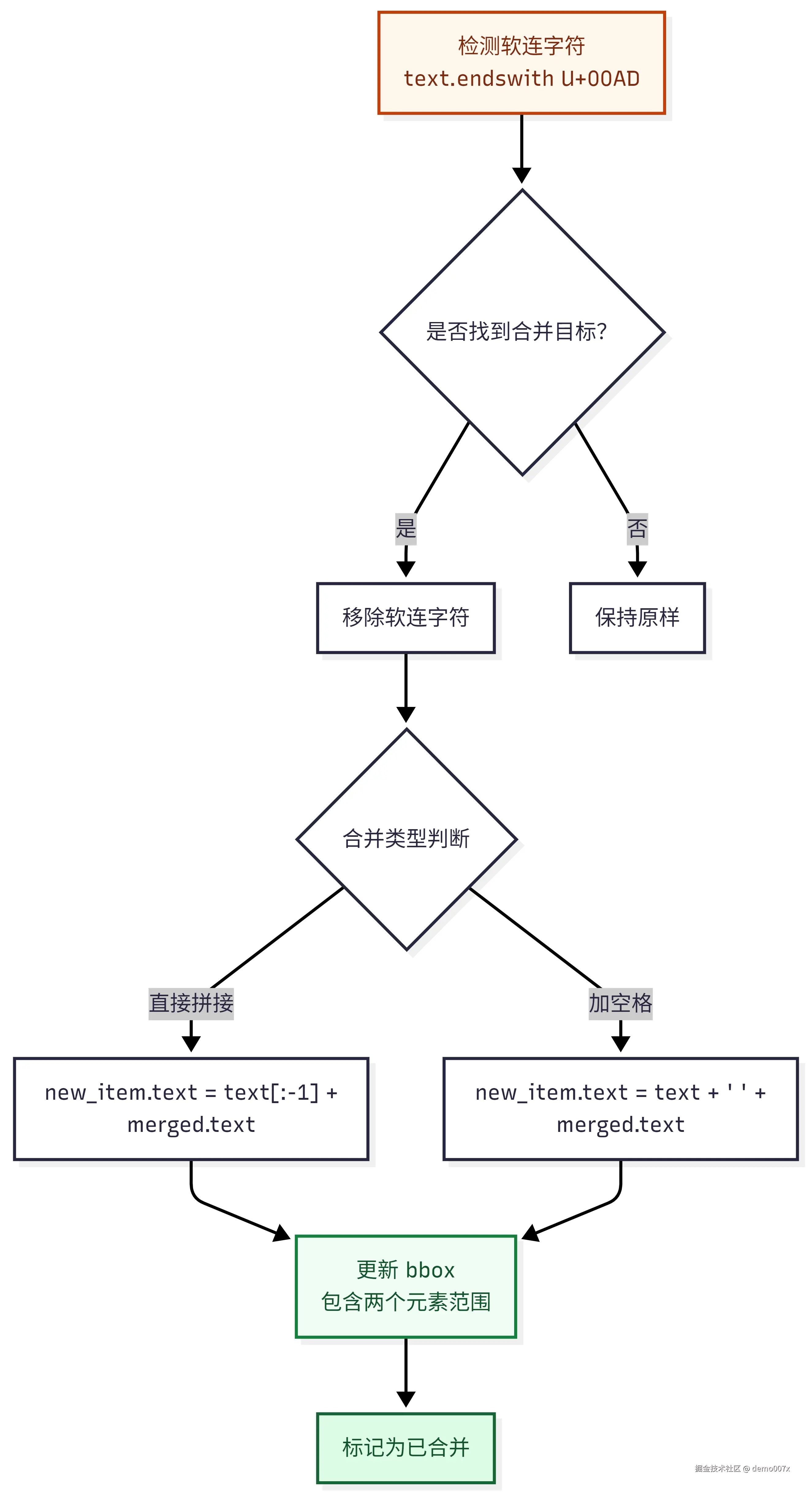
5.6 完整处理流程
六、外部依赖和集成点
6.1 核心依赖
| 类别 | 包 | 用途 |
|---|---|---|
| 基础 | pydantic>=2.0 |
数据验证和序列化 |
docling-core>=2.73 |
核心类型定义 | |
pydantic-settings |
配置管理 | |
| PDF 处理 | pypdfium2>=4.30 |
PDF 渲染 |
docling-parse>=5.3 |
高级 PDF 解析 | |
| ML 框架 | torch>=2.2 |
深度学习推理 |
transformers>=4.42 |
HuggingFace 模型 | |
accelerate>=1.0 |
模型加速 | |
| OCR | rapidocr>=3.8 |
快速 OCR |
easyocr>=1.7 |
深度学习 OCR | |
tesserocr>=2.7 |
Tesseract 绑定 | |
| Office | python-docx>=1.1 |
Word 处理 |
python-pptx>=1.0 |
PowerPoint 处理 | |
openpyxl>=3.1 |
Excel 处理 | |
| Web | beautifulsoup4>=4.12 |
HTML 解析 |
lxml>=4.0 |
XML/HTML 解析 | |
| CLI | typer>=0.12 |
CLI 框架 |
rich>=13.0 |
终端美化 | |
| 插件 | pluggy>=1.0 |
插件系统 |
6.2 支持的输入格式
diff
InputFormat 枚举:
- PDF, DOCX, PPTX, XLSX (Office)
- HTML, Markdown, AsciiDoc (Web/Text)
- IMAGE (JPG, PNG, TIFF, BMP, WebP)
- XML_USPTO, XML_JATS, XML_XBRL (专业 XML)
- METS_GBS (Google Books 元数据)
- AUDIO (WAV, MP3, M4A, FLAC)
- VTT (WebVTT 字幕)
- LATEX (LaTeX 文档)
- CSV, JSON_DOCLING6.3 支持的输出格式
diff
OutputFormat 枚举:
- MARKDOWN (.md)
- JSON (.json) - Docling JSON
- YAML (.yaml)
- HTML (.html) - 单页/分页
- TEXT (.txt)
- DOCTAGS (.doctags)
- VTT (.vtt)八、硬件资源需求
8.1 系统要求
操作系统:
- macOS(Intel 和 Apple Silicon)
- Linux(x86_64 和 ARM64)
- Windows(x86_64)
Python 版本:
- Python 3.10 或更高版本(3.9 已在 v2.70.0 中放弃支持)
- 支持 Python 3.10, 3.11, 3.12, 3.13, 3.14
8.2 CPU 模式
推荐配置(CPU 模式) :
- CPU:8 核以上
- 内存:16GB 以上
- 存储:SSD 推荐
8.3 GPU 加速配置
支持的 GPU 类型:
- NVIDIA CUDA:支持 CUDA 的 GPU
- Apple MPS:Apple Silicon (M1/M2/M3 等)
- Intel XPU:Intel GPU
推荐配置(GPU 模式) :
| 组件 | 最低要求 | 推荐配置 |
|---|---|---|
| GPU | NVIDIA GTX 1060 (6GB) | NVIDIA RTX 3090/4090 或 RTX 5090 |
| 显存 | 6GB | 24GB 以上 |
| CUDA 版本 | 12.0+ | 13.0+ |
| 系统内存 | 16GB | 64GB 以上 |
| CPU | 4 核 | 16 核以上 |
九、可下载模型清单
Docling 支持下载以下模型:
9.1 核心模型(默认下载)
| 模型名称 | 用途 | 厂商/来源 | 系统内存 (RAM) | 显存 (VRAM) | 默认 |
|---|---|---|---|---|---|
| Layout Model (Heron/Egret) | 版面分析,检测页面区域类型和阅读顺序 | IBM Research | 2 GB | 2-4 GB | ✅ |
| TableFormer | 表格结构识别(行列、单元格) | IBM Research | 2-4 GB | 4-6 GB | ✅ |
| TableFormer V2 | 表格结构识别增强版 | IBM Research | 4-6 GB | 6-8 GB | ❌ |
| Document Picture Classifier | 图像分类(图表、示意图等) | IBM Research | 1-2 GB | 2-4 GB | ✅ |
| Code Formula Model | 代码块和数学公式识别 | IBM Research | 2-4 GB | 4-6 GB | ✅ |
| RapidOCR (torch/onnxruntime) | 光学字符识别(多后端) | github | 1-2 GB | 2-4 GB (torch 后端) | ✅ |
| SmolVLM-256M | 图片识别/描述生成 | Hugging Face | 4-8 GB | 4-8 GB | ❌ |
9.2 OCR 引擎模型
| 模型名称 | 用途 | 厂商/来源 | 系统内存 (RAM) | 显存 (VRAM) | 默认 |
|---|---|---|---|---|---|
| RapidOCR (torch) | OCR 识别(PyTorch 后端,支持 GPU) | 开源社区 | 1-2 GB | 2-4 GB | ✅ |
| RapidOCR (onnxruntime) | OCR 识别(ONNX 后端,CPU 优化) | 开源社区 | 1-2 GB | N/A (仅 CPU) | ✅ |
| EasyOCR | OCR 识别(PyTorch 后端) | Jaided AI | 2-4 GB | 4-6 GB | ❌ |
十、Docling 特点总结
- 模块化设计: 清晰的分层架构,各层职责明确
- 可扩展性: 插件系统支持第三方模型扩展
- 多格式支持: 统一的接口支持 15+ 种输入格式,支持输出多种转换格式
- 灵活性: 丰富的配置选项,灵活控制每个步骤;同时支持本地和远程推理
- RAG : 内置文档分块支持,为构建 RAG 系统提供支持