AI 写代码不能自己审自己。拆成三个角色各干各的------一个写、一个审、一个验收------效果反而更好。
问题出在哪
在驭缰工程的实践中,有一个反复出现的痛点:
AI 不能准确评估自己的工作。
Anthropic 的工程团队在实验中直接验证了这一点。他们让 Claude 独立完成一个前端设计任务,然后自我评估。
结果:无论实际质量如何,智能体都倾向于给自己打高分。
自己批卷,分数当然不会低。
Anthropic 从 GAN(生成对抗网络)找到了灵感:用一个 AI 生成,用另一个 AI 来判别。
三智能体架构
| 角色 | 职责 | 类比 |
|---|---|---|
| Planner(规划者) | 把 1-4 句人类提示词转化为完整产品规格 | 产品经理 |
| Generator(实现者) | 按规格逐特性编码 | 开发工程师 |
| Evaluator(评估者) | 用 Playwright 实际操作应用,逐条验证 | QA 工程师 |
关键设计:三个智能体是独立的,各有自己的上下文和判断标准。Generator 不能评价自己,只有 Evaluator 能。

Sprint 合同:最精妙的机制
三智能体架构里最有价值的发明是 Sprint 合同。
问题:人类给的一句"做一个好看的前端"太模糊了,AI 之间对"好看"的理解也不一样。
解决:
两个 AI 自己协商"完成"的标准,不需要人类在中间传话。
四维度评分标准
Evaluator 不是泛泛地说"好"或"不好",而是按四个维度打分:
| 维度 | 检查什么 | 默认表现 |
|---|---|---|
| Design Quality | 是否有连贯的视觉身份 | 权重高 |
| Originality | 是否有原创设计决策(而非 AI 模板感) | 权重高 |
| Craft | 排版、间距、对比度等技术执行 | 默认就好 |
| Functionality | 可用性(独立于美学) | 默认就好 |
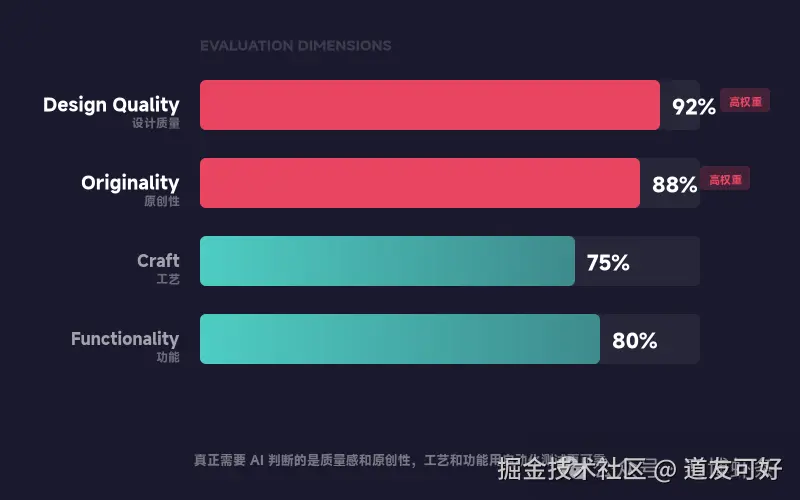
注意:Craft 和 Functionality 默认就好,AI 在这些方面已经足够强。Design Quality 和 Originality 才是 Evaluator 真正要花力气判断的------也是 AI 最难自评的维度。
Harness 不只是约束,也能释放创造力
Anthropic 的三智能体实验中有一个意外的发现。
前 9 轮迭代产生了常规的前端设计------干净的深色主题页面,符合预期。然后第 10 轮,Generator 完全推翻了之前的方案,创造了一个3D 空间体验:CSS 透视渲染的棋盘格地板,画作自由悬挂在墙上,通过门口在展厅间导航。
这是单次生成从未见过的创造性飞跃。人类没有要求 3D,没有暗示空间感------是 Harness 给了 Generator 足够的自由度(在边界内),让它做出了超出预期的创造。
好的 Harness 在保证质量底线的同时,也给 AI 留出了突破的空间。
Harness 会进化:V1 → V2 的瘦身
Anthropic 的实验揭示了一个重要规律:Harness 不是一成不变的,它需要随模型升级而进化。
| 版本 | 模型 | 架构 | 时长 | 成本 |
|---|---|---|---|---|
| Solo baseline | Opus 4.5 | 单智能体 | 20 分钟 | $9 |
| V1 Harness | Opus 4.5 | Planner + Generator(按 sprint)+ Evaluator(每个 sprint) | ~6 小时 | $200 |
| V2 Harness | Opus 4.6 | Planner + Generator(无 sprint)+ Evaluator(单次 pass) | ~4 小时 | $125 |
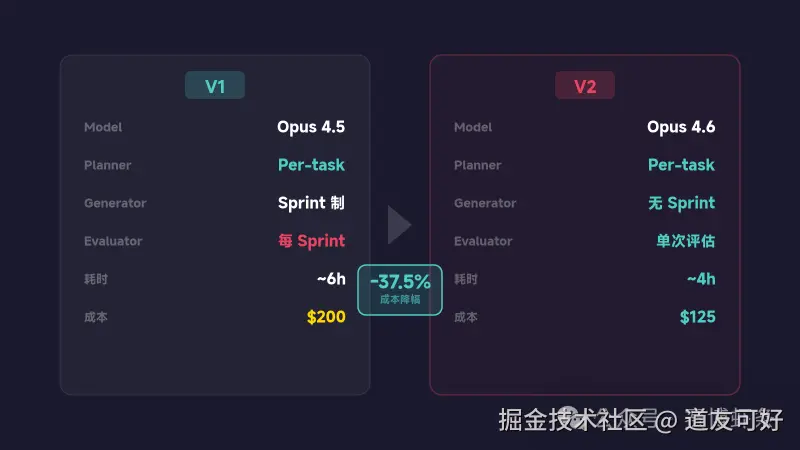
从 V1 到 V2 的变化:
- 去掉了 Sprint 分期 --- 模型更强了,不需要拆那么细
- Evaluator 从每个 sprint 跑变成跑一次 --- 省钱省时间
- 成本从 200降到125 --- 效率提升 37.5%
每个 Harness 组件都编码了一个假设------"模型不能独立做 X"。模型升级后,这些假设需要重新验证,不再成立的组件就应该被精简。
两个关键发现的深度解读
Context Anxiety(上下文焦虑)
模型接近上下文窗口极限时,会产生一种奇怪的行为:提前收尾。
即使任务还没完成,模型也会急急忙忙地"完成"------因为它害怕上下文溢出。Sonnet 4.5 尤为明显。
解决方案:Context Reset --- 在关键节点重置上下文窗口,让模型以全新的窗口继续工作。Ralph 循环里的 "Fresh Context" 也是同样的思路。
Self-Evaluation 的根本缺陷
为什么 AI 不能准确评估自己?
分离 Evaluator 解决了锚定效应,Sprint 合同解决了标准漂移。完整性偏差目前没有完美解法,所以人类的最终确认仍然必要。
这对普通开发者意味着什么
你不需要 Anthropic 的预算和算力。但你可以借鉴核心思路:
个人开发者的"轻量三智能体"
bash
你 = Planner(写清楚要做什么)
AI = Generator(编码)
AI + 自动化测试 = Evaluator(验证)具体做法:
核心就一个道理:"生成"和"评估"得分开。
一个需要常问的问题
模型升级后,某些 Harness 组件不再必要,但总有新的约束需要被发现。
定期审视你的 Harness:这条规则还有必要吗?这个组件还在承重吗?有没有新的能力我没用上?
这是驭缰工程系列的第六篇。上一篇:《Ralph 循环:让 AI 自己干活、自己查、自己改》 下一篇:《熵管理:AI 写代码的最大隐患和解决方案》
觉得有用?转发给正在用 AI 写代码的朋友,或者点个在看让更多人看到。