大家好,我是孟健。
Fable 5 被暂停那天,我第一反应是庆幸------庆幸自己没有把生产流程全押在它身上。
01 先承认一件事:Fable 5 确实很强
Fable 5 发布的时候,我认真研究了一下。它属于 Mythos-class,能力层级比 Opus 还高,Anthropic 官方的说法是:任务越长、越复杂,Fable 5 相对其他模型的领先越大。
有个 Stripe 的案例很说明问题:5000 万行 Ruby 代码的迁移任务,Fable 5 一天完成,团队手工做可能超过两个月。价格也不便宜: 10/millioninputtokens,50 / million output tokens,是明显的旗舰定位。
这种级别的模型,正常情况下会让人产生一个念头:是不是该把所有 Agent 都切过去?
但"最强"这个标签有个问题:它描述的是能力上限,跟生产可靠性没关系。
02 它突然暂停,暴露的是生产风险
2026 年 6 月 12 日,Anthropic 发布了一则公告:
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance. Access to all other Anthropic models will not be affected.
美国政府以国家安全权力发出出口管制指令,要求暂停所有 foreign national 对 Fable 5 和 Mythos 5 的访问。结果是 Anthropic 必须对所有客户禁用这两个模型。
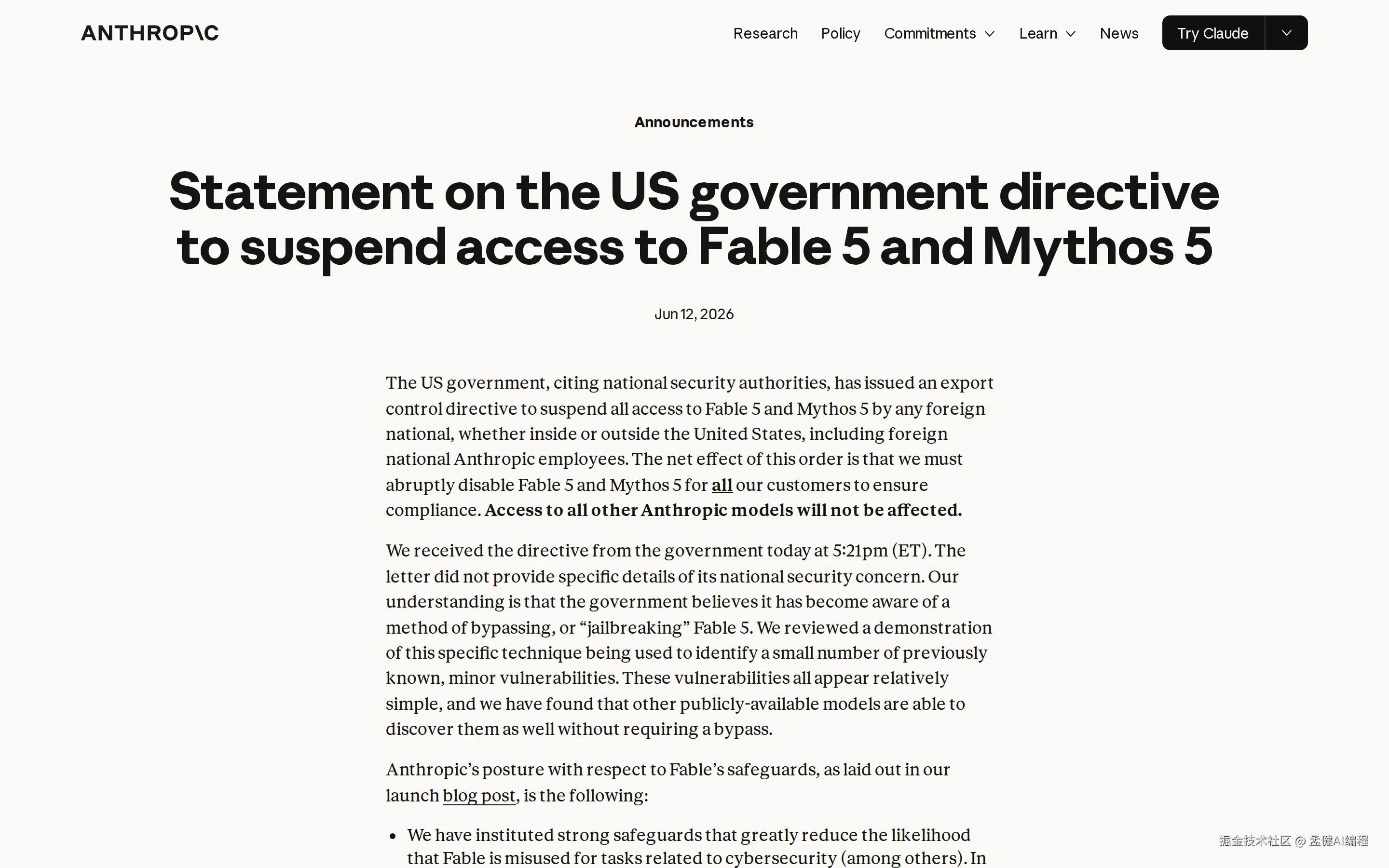
Anthropic 在公告里表示他们不同意这个判断,也在努力恢复访问。这些争议我不做政治评论。作为开发者,真正值得关注的只有一件事:
一个模型可以因为合规、政策、安全或供应商策略,在任何一天突然消失。
模型能力是上限,模型可用性才是生产底线。
如果你的生产流程深度依赖 Fable 5,6 月 12 日那天你只有两个选择:临时切换(如果你有备用流程)或者等着(如果没有)。等着意味着整个工作流停摆。单点依赖的必然结果,就是一个节点挂掉,整条链路跟着停------跟供应商有没有问题无关,跟意不意外无关。
如果 Fable 5 是你的唯一模型,那天会发生什么?
我的多 Agent 工作流里有明确的依赖链:设计 Agent 出配色、排版建议、组件规范;前端 Agent 拿这些规范写代码;QA Agent 接住代码跑测试;运营 Agent 负责选题、文案、发布节奏。
设计 Agent 一停,前端 Agent 没有输入可用。前端 Agent 停了,QA 空转,运营也失去了可发布的产物。整条链路的停摆,比单个任务失败严重得多------一个任务出错是局部故障,唯一模型失联是全线停产。
这是我在 6 月 12 日之前就想清楚、之后再次确认的判断。
03 我最近反而在拆模型,而不是追最强
有意思的是,Fable 5 被暂停的这段时间,我刚好在做一件相反的事:把不同 Agent 切到不同模型。
目前的分配是这样的:
- 设计 Agent、前端 Agent:换成了 Kimi K2.7
- 运营 Agent:换成了 GLM 5.2
- 其他 Agent:仍以 GPT 5.5 为主
背后的逻辑很简单:每个 Agent 的模型需求根本不一样,用同一个模型是掩盖这种差异,不是解决它。
设计 Agent 和前端 Agent 的需求为什么相近?
设计 Agent 主要做两件事:读截图或原型、输出组件规范。这需要模型能处理图文混合输入、理解 UI 层级结构、把视觉信息翻译成可执行的文本描述。前端 Agent 接手这些描述,生成组件代码,同时持有整个组件库作为上下文。两者的共同需求是:长上下文稳定、多模态理解可用、代码生成精准。
运营 Agent 的需求完全是另一个方向。
运营 Agent 处理的是:平台数据分析、选题决策、文案生成、发布时间规划。任务多为纯文本,代码生成需求低。它需要的是中文输出质量高、指令遵循稳定、长文本跑完不跑题。这和前端 Agent 的"精准代码生成 + 大上下文持有"完全是两套要求,塞给同一个模型,哪个角色都不会跑得顺。
选 Kimi K2.7 给设计和前端,有几个具体理由。
Kimi K2.7 Code 是 Kimi 当前最强的 coding model,支持 256K context window,官方定位是 long-context coding、工具调用、多模态分析和复杂代码生成/调试。设计 Agent 需要读完整 UI 上下文、理解页面结构;前端 Agent 需要长时间持有组件代码、生成可执行交互逻辑。这两个需求和 Kimi K2.7 的定位对得上,值得放进这两个角色里跑一段时间观察。
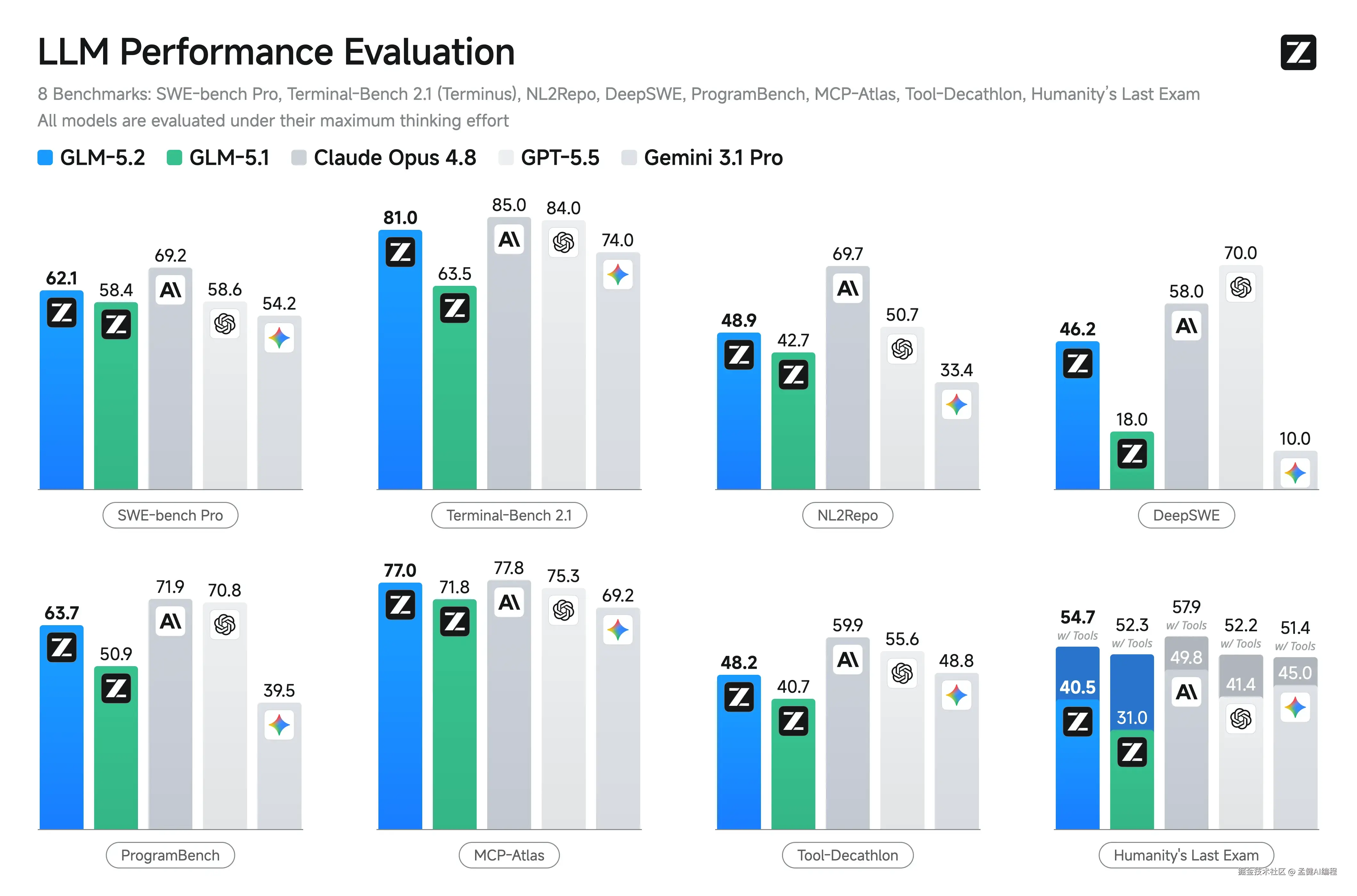
运营 Agent 选 GLM 5.2,选的是它在长程 agentic 任务上的实测表现。
GLM-5.2 是 Z.AI 面向 long-horizon agentic coding 的旗舰模型,MIT 开放权重,context window 最高 1M tokens。最新评测中,它在 FrontierSWE、SWE-Marathon 等长程工程任务上是排名最高的开源模型之一,Terminal-Bench 81.0,SWE-bench Pro 62.1,比 GLM-5.1 有明显提升。运营 Agent 的核心需求------多步规划稳定、长文本不跑题、工具调用可靠------和这个方向对得上。
我不会说"Kimi K2.7 一定比某模型强"或者"GLM 5.2 跑分更高"------这类说法在生产里没有意义。我只能说:我现在按角色分配,按任务观察,按结果调整。
04 生产级 AI 编程,应该按四个维度选模型
有了这段经历,我梳理了一下自己在选模型时真正在看的东西:
一、任务类型
前端、后端、运营、写作、QA、调研,每类任务对模型的需求是不同的。前端需要代码生成精准、上下文长;运营需要指令遵循稳定、文本生成连贯;QA 需要能覆盖边界条件。把所有任务塞给同一个模型,是对差异的抹平,而不是对能力的利用。
二、风险等级
有些任务跑错了可以重来,有些任务影响发布或数据。低风险的高频任务,可以用新模型、便宜模型、测试中的模型。高风险动作,必须用最稳的路径------而且要有人工确认点。
三、可替换性
这是最容易被忽视的维度。每个 Agent 换掉当前模型,流程还能继续工作吗?如果切换成本极高,说明耦合太深。
可替换性体现在四个地方:
- Prompt 层:不依赖某个模型的特定怪癖或格式偏好,按通用指令结构写,换模型时 prompt 不需要大改
- 验收标准:定义清楚什么叫"输出合格",标准要和用哪个模型无关------比如"代码跑通测试"、"文案字数在区间内且主题对应选题"
- 调用日志:每次 Agent 调用记录用的是哪个模型、输入输出 token 数、耗时,出问题知道去哪查
- 回滚路径:新模型效果变差,能用日志定位、能一行配置切回旧模型
这四点做到了,换模型就是改一行配置,改不到就是半天工作。
四、供应商风险
限流、临时下架、合规、价格调整、地区访问限制------这些都是真实发生过的事。单一供应商意味着这些风险会同时命中你的所有流程。多供应商的意义,就是让这些风险变成局部影响,而不是全线停产。
按这四个维度,可以粗略地这样分配:
- 攻坚任务:用最强模型,但只给它,不依赖它成为唯一出口
- 高频生产任务:用稳定模型,宁可能力稍弱,也要可靠
- 成本敏感任务:用便宜但可验收的模型,设置输出检验
- 关键发布动作:必须有人类确认,模型只是辅助
05 以后不要问"哪个模型最强",要问"哪里必须能换"
Fable 5 这件事,让我对一个问题的答案更确定了:AI 编程的生产体系,不应该围绕"最强模型"构建,而应该围绕"可替换的节点"构建。
给个人开发者的模型组合参考:
你不需要用十个模型,但至少要覆盖四个角色:
- 主力 Coding 模型:当前最适合代码生成的,用于核心开发 Agent
- 备用 Coding 模型:主力挂了能顶上,最好来自不同供应商,平时可以跑轻量任务
- 文本 / 运营模型:专门处理写作、分析、长文本,代码能力不必强
- 快速响应模型:轻量、低延迟,用于高频小任务和实时反馈
四个位置,四个不同来源。最差情况下任何一个出问题,其他三个还在跑。这个清单不需要每个位置都用最贵的,要的是每个位置有备份、整体不单点。
我建议每个做 AI 编程的团队或个人,还要配套准备好:
- 备模型:主模型不可用时能顶上的选择
- 低成本模型:高频、低风险任务的日常选择
- 长上下文模型:需要大上下文的任务专用
- 人工确认点:关键动作不能全自动
- 可回滚日志:出问题能知道发生了什么
这不是什么大架构,这是真实创业者在被打了几次之后养成的习惯。
最强模型会继续出现,也会继续消失。生产流程不能跟着它一起消失。
孟健,AI 编程创业者。做一人公司,跑多 Agent 工作流,记录真实踩坑。
👋 我是孟健,前腾讯 T11 / 前字节技术 Leader,现在全职做 AI 编程。
🔥 更多 AI 编程实战:
- GitHub:@mengjian-github
- 专栏:AI编程实战
觉得有用?点赞+收藏 就是最大支持 🙏