写给前端工程师的正则教程:不背符号表,先理解"正则引擎怎么找东西"。
1. 正则到底是什么?先把它想成"文本侦探"
日常开发里,我们每天都在和字符串打交道:
- 用户输入手机号、邮箱、身份证号;
- 后端返回一段日志,需要从里面提取错误码;
- 页面模板里写了
{{name}},需要替换成真实数据; - 文件名、路由、URL 参数、金额格式都要做校验和转换。
如果只用 if、for、split、includes 去处理这些问题,很快就会陷入一堆分支判断。正则表达式(Regular Expression)就是为了解决这类"文本模式匹配"问题而生的工具。
你可以把正则想象成一个文本侦探。它拿着一张"通缉令",在字符串街区里从左往右巡逻:
\d:我要找数字;[a-z]:我要找小写字母;+:前面的东西至少出现一次,越多越好;^:必须从街区门口开始;$:必须刚好走到街区尽头;():把抓到的关键人单独带回审讯室,也就是捕获分组。
正则不是魔法,而是一套字符串扫描规则。理解这一点,后面所有符号都会变得合理。
2. 第一准则:永远不要相信用户输入
任何面向用户的系统,都应该默认用户输入是不可靠的。
用户可能在手机号输入框里输入:
txt
hello
13888888888
<script>alert(1)</script>
100元这些内容如果不处理就发给后端,轻则接口报错,重则引发安全风险。前端校验不能代替后端校验,但它是第一道体验防线:能提前拦住明显错误,减少无效请求,也能给用户更及时的反馈。
例如手机号校验,最常见的需求是:
- 总长度为 11 位;
- 第一位是
1; - 第二位通常是
3-9; - 后面 9 位都是数字。
对应正则:
js
const phoneReg = /^1[3-9]\d{9}$/;
console.log(phoneReg.test('13888888888')); // true
console.log(phoneReg.test('12888888888')); // false
console.log(phoneReg.test('13888888888 ')); // false这里最关键的是 ^ 和 $。很多初学者写成:
js
/1[3-9]\d{9}/这个写法看似也能匹配手机号,但它只是说"字符串里出现过一段像手机号的内容"就行。比如:
js
console.log(/1[3-9]\d{9}/.test('abc13888888888xyz')); // true这显然不是严格校验。严格校验必须加上边界锚点:
js
/^1[3-9]\d{9}$/这就像安检,不是"包里有身份证就行",而是"你整个人从头到脚都必须符合规则"。
3. JavaScript 里的正则是什么类型?
在 JavaScript 中,正则是对象,准确说是 RegExp 对象。
js
const reg = /\d+/;
console.log(typeof reg); // "object"
console.log(Object.prototype.toString.call(reg)); // "[object RegExp]"typeof 对引用类型区分能力有限。数组、对象、正则都会被归类为 object。如果想精确判断类型,常用:
js
Object.prototype.toString.call(value)正则对象可以通过两种方式创建。
第一种是字面量:
js
const reg = /\d+/g;第二种是构造函数:
js
const reg = new RegExp('\\d+', 'g');日常开发优先使用字面量,清晰、直观、少写转义。只有当正则规则需要动态拼接时,才更适合使用 new RegExp()。
js
const keyword = 'vue';
const reg = new RegExp(keyword, 'i');
console.log(reg.test('Vue Router')); // true4. 正则基础语法:先记"动作",再记符号
很多人学正则痛苦,是因为一上来就背符号。更好的方式是先问:我想让引擎做什么动作?
4.1 匹配某类字符
js
\d // 数字,等价于 [0-9]
\D // 非数字
\w // 字母、数字、下划线,等价于 [A-Za-z0-9_]
\W // 非 \w
\s // 空白字符,如空格、换行、制表符
\S // 非空白字符
. // 除换行外的任意单个字符示例:
js
const text = '订单 A1024 金额 99 元';
console.log(text.match(/\d+/g)); // ['1024', '99']
console.log(text.match(/\w+/g)); // ['A1024', '99']注意:\w 只覆盖英文、数字、下划线,不包含中文。如果你想匹配中文,常见写法是:
js
const chineseReg = /[\u4e00-\u9fa5]+/g;4.2 自定义字符集合
字符集合用 []:
js
[abc] // a、b、c 中任意一个
[0-9] // 任意数字
[a-z] // 任意小写字母
[^0-9] // 非数字手机号第二位为什么写 [3-9]?
js
/^1[3-9]\d{9}$/因为第二位只能从 3 到 9 之间选一个,而不是随便一个数字。
4.3 控制出现次数
量词决定"前面的规则出现多少次"。
js
* // 0 次或多次
+ // 1 次或多次
? // 0 次或 1 次
{n} // 恰好 n 次
{n,} // 至少 n 次
{n,m} // n 到 m 次示例:
js
console.log('abc123'.match(/\d+/)); // ['123']
console.log('abc'.match(/\d*/)); // [''],因为 * 允许 0 次
console.log('aaa'.match(/a{2}/)); // ['aa']初学者最容易被 * 坑到,因为它可以匹配空字符串。做校验时,如果业务要求必须有内容,通常更应该考虑 +。
4.4 控制位置
位置锚点不匹配具体字符,它匹配"位置"。
js
^ // 字符串开头
$ // 字符串结尾
\b // 单词边界
\B // 非单词边界严格校验邮箱、手机号、身份证号时,通常都需要 ^ 和 $。否则正则只要在字符串中间找到一段符合规则的内容,就会返回成功。
js
const reg = /^\d{6}$/;
console.log(reg.test('123456')); // true
console.log(reg.test('xx123456yy')); // false5. 正则引擎怎么工作?它不是一次看完整个字符串
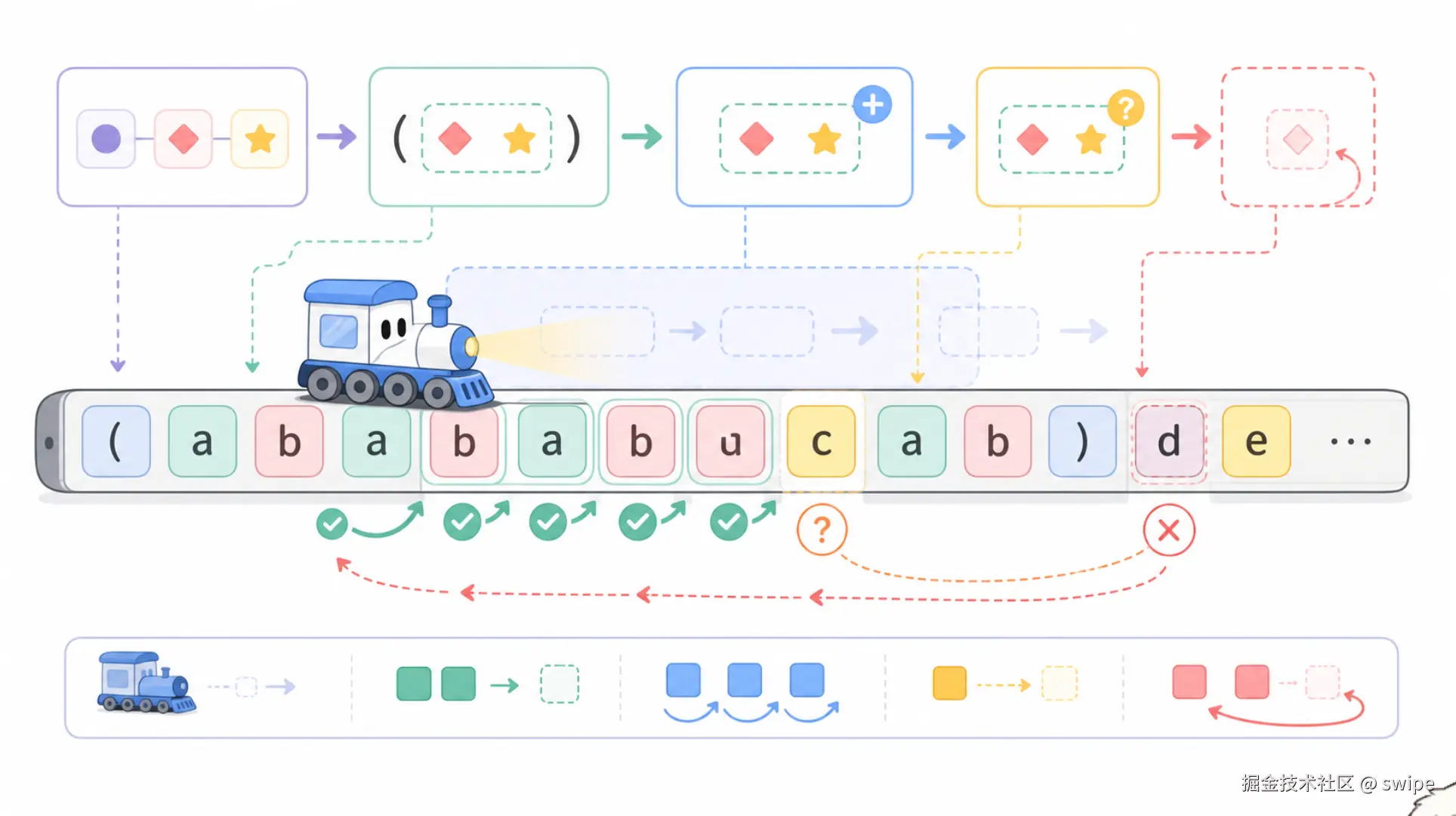
正则引擎大多数时候是从左到右扫描字符串。它不会一眼看完整个文本,而是像拿着手电筒在走廊里移动:
- 从当前位置开始尝试匹配;
- 当前字符不符合,就移动到下一个位置;
- 符合后继续匹配后续规则;
- 如果后续规则失败,可能会回退,也就是回溯;
- 找到结果后,根据是否有
g决定继续扫描还是停止。
看一个例子:
js
const str = '价格是100元,进价是80,赚了20';
const reg = /\d+/g;
console.log(str.match(reg)); // ['100', '80', '20']执行过程可以理解为:
- 扫描到"价格是",不是数字,跳过;
- 遇到
1,符合\d; - 因为后面有
+,继续吃掉0、0; - 遇到"元",数字中断,得到
100; - 因为有
g,继续往后扫描; - 最终得到
80和20。
这就是 + 的"贪婪"特性:只要还能匹配,它就尽可能多拿一点。
6. 贪婪、惰性和回溯:正则里的"我全都要"和"我先少拿点"
默认情况下,量词是贪婪的。
js
const html = '<span>hello</span><span>world</span>';
console.log(html.match(/<span>.*<\/span>/)[0]);
// <span>hello</span><span>world</span>.* 会尽可能多地匹配,因此它从第一个 <span> 一路吃到最后一个 </span>。
如果只想匹配第一个标签内容,可以使用惰性量词:
js
console.log(html.match(/<span>.*?<\/span>/)[0]);
// <span>hello</span>*?、+?、??、{n,m}? 都是惰性写法。惰性不是"不匹配",而是"先尽量少匹配,如果后续规则不成立,再一点点扩张"。
回溯则是正则引擎为了让整体匹配成功而做的"后悔一步"。
js
const str = 'aaab';
console.log(/a+b/.test(str)); // truea+ 会先吃掉三个 a,然后 b 匹配最后一个字符成功,不需要回溯。如果字符串是 aaac,引擎会尝试回退 a+ 吃掉的内容,希望后面的 b 能成功,但怎么退都找不到 b,最后失败。
小规模回溯很正常。可怕的是灾难性回溯。
js
/^(a+)+$/面对一长串 aaaaaaaaaaaaab,这种嵌套量词可能让引擎尝试大量组合,造成性能问题,甚至形成 ReDoS(Regular Expression Denial of Service,正则拒绝服务)风险。
工程建议:
- 避免在用户可控长文本上使用复杂嵌套量词;
- 能写明确范围就不要写过度宽泛的
.*; - 对输入长度做限制;
- 对高风险正则做性能测试;
- 服务端不要随便执行用户提交的正则。
7. 分组:把抓到的内容装进口袋
括号 () 有两个作用:
- 改变优先级;
- 捕获内容。
7.1 捕获分组
js
const date = '2026-06-18';
const reg = /^(\d{4})-(\d{2})-(\d{2})$/;
const result = date.match(reg);
console.log(result[0]); // 2026-06-18
console.log(result[1]); // 2026
console.log(result[2]); // 06
console.log(result[3]); // 18result[0] 是完整匹配,result[1] 开始才是括号捕获到的内容。
7.2 命名分组
现代 JavaScript 支持命名捕获分组:
js
const reg = /^(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})$/;
const result = '2026-06-18'.match(reg);
console.log(result.groups.year); // 2026
console.log(result.groups.month); // 06
console.log(result.groups.day); // 18命名分组让代码更可读,特别适合解析日期、URL、日志。
7.3 非捕获分组
如果你只想分组,不想保存捕获结果,可以写:
js
(?:abc)例如:
js
const reg = /^(?:https?:\/\/)?example\.com$/;这里 (?:https?:\/\/)? 只是为了把协议部分整体设为可选,不需要把它捕获出来。
7.4 反向引用
反向引用可以匹配"之前捕获过的同样内容"。
js
const reg = /\b(\w+)\s+\1\b/;
console.log(reg.test('hello hello')); // true
console.log(reg.test('hello world')); // false这里 \1 表示第一个捕获分组的内容。它常用于检测重复词、成对标签等场景。
8. 常用修饰符:正则的模式开关
JavaScript 常见修饰符:
js
g // global,全局匹配
i // ignoreCase,忽略大小写
m // multiline,多行模式,影响 ^ 和 $
s // dotAll,让 . 可以匹配换行符
u // unicode,按 Unicode 语义处理
y // sticky,粘连匹配,从 lastIndex 精确位置开始
d // indices,返回匹配索引信息常用组合:
js
/hello/i // 忽略大小写
/\d+/g // 提取所有连续数字
/^title/gm // 多行中匹配每一行开头的 title
/[\s\S]*/ // 兼容匹配任意字符,包括换行
/.*?/s // dotAll 模式下,. 也能跨行注意一个很容易面试被问到的坑:带 g 的正则调用 test() 会记录 lastIndex。
js
const reg = /\d/g;
console.log(reg.test('1')); // true
console.log(reg.test('1')); // false
console.log(reg.test('1')); // true为什么第二次是 false?因为第一次匹配后,lastIndex 移到了 1,第二次从索引 1 开始找,已经到末尾了。日常做表单校验时,不建议给 .test() 使用的正则加 g。
js
const safeReg = /^\d$/;这比 /^\d$/g 稳定。
9. 字符串 API 实战:正则不是单兵作战
正则真正强大,是因为它能和 JavaScript 字符串 API 配合。
9.1 test:只问是否匹配
js
const reg = /^1[3-9]\d{9}$/;
if (!reg.test(phone)) {
console.log('手机号格式不正确');
}.test() 返回布尔值,适合校验。
9.2 match:提取匹配结果
js
const text = '苹果 12 元,香蕉 8 元,西瓜 25 元';
console.log(text.match(/\d+/g));
// ['12', '8', '25']不带 g 时,match() 会返回更详细的信息:
js
const result = '2026-06-18'.match(/^(\d{4})-(\d{2})-(\d{2})$/);
console.log(result[0]); // 完整匹配
console.log(result[1]); // 年
console.log(result.index); // 匹配起始位置
console.log(result.input); // 原始字符串带 g 时,它返回所有完整匹配项,不返回每个捕获分组的详细信息。如果你既想全局匹配,又想拿分组,优先考虑 matchAll()。
9.3 matchAll:全局捕获的优雅写法
js
const text = 'name=张三; age=18; city=杭州';
const reg = /(\w+)=([^;]+)/g;
for (const item of text.matchAll(reg)) {
console.log(item[1], item[2]);
}输出:
txt
name 张三
age 18
city 杭州matchAll() 返回的是迭代器,适合配合 for...of 或 Array.from()。
9.4 exec:正则对象自己的扫描器
js
const reg = /(\d+)/g;
const text = 'a1 b22 c333';
let match;
while ((match = reg.exec(text)) !== null) {
console.log(match[0], match.index);
}exec() 很适合手动控制扫描过程。带 g 时,它会不断更新 lastIndex。
9.5 replace:正则进阶的核心战场
replace() 不只是替换固定字符串,它还可以接收函数。
js
const str = 'hello-world';
const result = str.replace(/-(\w)/g, (_, letter) => {
return letter.toUpperCase();
});
console.log(result); // helloWorld这段代码的含义是:
- 找到
-w这种结构; (\w)把w捕获出来;- 回调函数返回
W; - 用
W替换掉整个-w。
replace 回调参数顺序大致是:
js
replace((match, group1, group2, ..., offset, input, groups) => {})如果你看到面试题问"replace 第二个参数是函数时会收到什么",核心答案就是:完整匹配、捕获分组、匹配索引、原字符串,以及命名分组对象。
10. 经典需求:把 kebab-case 转成 camelCase
需求:
txt
user-name -> userName
border-left -> borderLeft
hello-world-js -> helloWorldJs实现:
js
function toCamelCase(str) {
return str.replace(/-([a-zA-Z])/g, (_, letter) => {
return letter.toUpperCase();
});
}
console.log(toCamelCase('hello-world-js')); // helloWorldJs为什么要加 g?因为一个字符串里可能有多个连字符。
如果不加:
js
'hello-world-js'.replace(/-([a-zA-Z])/, (_, s) => s.toUpperCase());
// helloWorld-js只替换了第一处。
11. 终极实战:手写一个微型模板引擎
现在进入最有意思的地方。很多模板语法长这样:
txt
我是 {{name}},今年 {{age}} 岁,来自 {{city}}我们希望用数据对象替换占位符:
js
const data = {
name: '张三',
age: 18,
city: '杭州'
};最小实现:
js
function render(template, data) {
return template.replace(/{{\s*(\w+)\s*}}/g, (_, key) => {
return data[key] ?? '';
});
}
const template = '我是 {{name}},今年 {{age}} 岁,来自 {{city}}';
console.log(render(template, data));
// 我是 张三,今年 18 岁,来自 杭州这里有几个关键点:
{{和}}是普通字符,但{}在正则里有特殊含义,所以写法要谨慎;\s*允许占位符内有空格;(\w+)捕获变量名;g表示替换所有占位符;- 回调函数根据变量名去
data里取值。
如果想支持点路径:
txt
{{user.name}}
{{user.profile.city}}可以写:
js
function getValueByPath(data, path) {
return path.split('.').reduce((obj, key) => {
return obj == null ? undefined : obj[key];
}, data);
}
function render(template, data) {
return template.replace(/{{\s*([\w.]+)\s*}}/g, (_, path) => {
const value = getValueByPath(data, path);
return value == null ? '' : String(value);
});
}
const template = '用户:{{user.name}},城市:{{user.profile.city}}';
const data = {
user: {
name: '小明',
profile: {
city: '深圳'
}
}
};
console.log(render(template, data));
// 用户:小明,城市:深圳这就是模板引擎的核心雏形。真实框架当然复杂得多,还会涉及 AST、依赖收集、编译优化、XSS 防护等问题,但"扫描模板 → 捕获变量 → 替换内容"这条主线是一样的。
安全提醒:如果模板渲染结果会插入 HTML,不要直接信任用户数据。需要做 HTML 转义,否则可能引发 XSS。
js
function escapeHTML(str) {
return String(str)
.replace(/&/g, '&')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/"/g, '"')
.replace(/'/g, ''');
}12. 常见业务正则速查
下面这些写法可以作为学习材料。真实业务中要根据产品规则调整,不要盲目复制。
12.1 去除首尾空格
js
function trim(str) {
return str.replace(/^\s+|\s+$/g, '');
}12.2 提取 URL 参数
js
function parseQuery(url) {
const query = url.split('?')[1] || '';
const result = {};
query.replace(/([^&=]+)=([^&]*)/g, (_, key, value) => {
result[decodeURIComponent(key)] = decodeURIComponent(value);
return '';
});
return result;
}
console.log(parseQuery('https://a.com?a=1&name=%E5%BC%A0%E4%B8%89'));更推荐工程中使用 URLSearchParams,但面试中手写解析能体现正则和字符串处理能力。
12.3 手机号脱敏
js
function maskPhone(phone) {
return phone.replace(/^(\d{3})\d{4}(\d{4})$/, '$1****$2');
}
console.log(maskPhone('13888889999')); // 138****999912.4 金额千分位
js
function formatMoney(num) {
const [integer, decimal] = String(num).split('.');
const formatted = integer.replace(/\B(?=(\d{3})+(?!\d))/g, ',');
return decimal ? `${formatted}.${decimal}` : formatted;
}
console.log(formatMoney(1234567.89)); // 1,234,567.89这里的 (?=...) 是正向先行断言,它只检查后面是否符合条件,不消费字符。\B 表示非单词边界。这个题是大厂面试高频题。
12.5 密码强度校验
要求:至少 8 位,必须包含字母和数字。
js
const passwordReg = /^(?=.*[A-Za-z])(?=.*\d)[A-Za-z\d]{8,}$/;解释:
(?=.*[A-Za-z]):后面必须能找到一个字母;(?=.*\d):后面必须能找到一个数字;[A-Za-z\d]{8,}:整体只能由字母数字组成,至少 8 位。
如果还要求特殊符号,可以继续加先行断言。
13. 进阶语法:断言像"门口保安",看一眼但不带走
断言不会消费字符,只判断某个位置是否满足条件。
13.1 正向先行断言
js
const reg = /\d+(?=元)/g;
console.log('苹果10元,香蕉8元'.match(reg)); // ['10', '8']\d+(?=元) 的意思是:匹配数字,但要求数字后面跟着"元"。最终结果不包含"元"。
13.2 负向先行断言
js
const reg = /\d+(?!元)/g;
console.log('苹果10元,库存20个'.match(reg)); // ['2', '0'] 或受扫描细节影响负向断言要谨慎使用,因为它判断的是当前位置后面"不是什么",复杂场景容易产生意外结果。更好的做法通常是先明确上下文,再提取。
13.3 后行断言
js
const reg = /(?<=¥)\d+/g;
console.log('价格¥99,优惠¥20'.match(reg)); // ['99', '20'](?<=¥) 表示当前位置前面必须是 ¥。注意,后行断言在现代环境中支持较好,但如果要兼容老旧浏览器,需要谨慎。
14. 正则可读性:写给机器,也写给未来的自己
正则很容易变成"天书"。工程里要避免炫技。
不推荐:
js
/^([a-z0-9_\.-]+)@([\da-z\.-]+)\.([a-z\.]{2,6})$/更推荐:
js
const emailReg = /^[^\s@]+@[^\s@]+\.[^\s@]+$/;这不是最严格的邮箱标准,但对大多数业务表单足够。真正严格的邮箱规范非常复杂,不建议在前端用一条巨型正则硬扛。
提升可读性的建议:
- 给正则变量取清晰名字,如
phoneReg、templateVarReg; - 为复杂正则写注释;
- 把复杂规则拆成多个步骤;
- 有现成标准 API 时优先使用标准 API,比如 URL 解析用
URL和URLSearchParams; - 校验规则和业务文案放在同一处,方便维护。
15. 正则与性能:别让一条规则拖垮页面
正则性能问题主要来自三个地方:
- 输入字符串太长;
- 正则写得太模糊;
- 嵌套量词导致大量回溯。
危险示例:
js
/^(a+)+$/改进思路:
js
/^a+$/如果业务规则本来只是"全是 a",就不需要嵌套。
再看一个常见危险写法:
js
/^.*(error).*$/很多时候可以改成:
js
/error/如果你只是判断是否包含 error,就不要让正则从头吃到尾再回溯。
工程中处理用户输入时,除了正则本身,还要限制输入长度:
js
if (value.length > 1000) {
throw new Error('输入过长');
}安全不是靠一条正则完成的,而是靠"长度限制 + 类型校验 + 白名单规则 + 后端兜底"一起完成。
16. 大厂面试题精选
下面这些题目覆盖阿里、腾讯、字节、美团、拼多多等前端面试中常见的正则方向。题目不一定原样出现,但考点高度重合。
题 1:严格校验手机号
要求:1 开头,第二位 3-9,总共 11 位。
js
const reg = /^1[3-9]\d{9}$/;考点:锚点、字符集合、量词、严格匹配。
题 2:为什么 /\d/g.test('1') 连续调用结果会变?
js
const reg = /\d/g;
console.log(reg.test('1')); // true
console.log(reg.test('1')); // false答案:带 g 的正则会维护 lastIndex。第一次匹配后 lastIndex 移到末尾,第二次从末尾继续找,自然失败。表单校验不要给 test() 正则加 g。
题 3:实现字符串首尾空格 trim
js
function trim(str) {
return str.replace(/^\s+|\s+$/g, '');
}考点:^、$、\s、或运算 |。
题 4:提取字符串中的所有数字
js
const str = '价格100,库存20,优惠5';
console.log(str.match(/\d+/g)); // ['100', '20', '5']追问:返回值是什么类型?如果没有匹配到呢?
答案:匹配到返回数组;没有匹配到返回 null。
题 5:把 hello-world-js 转成 helloWorldJs
js
function camelize(str) {
return str.replace(/-([a-zA-Z])/g, (_, letter) => {
return letter.toUpperCase();
});
}考点:捕获分组、replace 回调、全局替换。
题 6:把手机号中间四位替换为星号
js
function maskPhone(phone) {
return phone.replace(/^(\d{3})\d{4}(\d{4})$/, '$1****$2');
}考点:捕获分组、替换占位符 $1 和 $2。
题 7:实现千分位格式化
js
function format(num) {
const [int, dec] = String(num).split('.');
const res = int.replace(/\B(?=(\d{3})+(?!\d))/g, ',');
return dec ? `${res}.${dec}` : res;
}考点:先行断言、非单词边界、从右向左的分组思维。
题 8:解析模板字符串
js
function render(template, data) {
return template.replace(/{{\s*([\w.]+)\s*}}/g, (_, path) => {
return path.split('.').reduce((obj, key) => obj?.[key], data) ?? '';
});
}考点:模板引擎原理、分组捕获、对象路径读取。
题 9:match、exec、matchAll 有什么区别?
简答:
test():只返回布尔值;match():字符串方法,不带g返回详细信息,带g返回完整匹配数组;exec():正则方法,可配合g手动迭代;matchAll():适合全局匹配并保留捕获分组。
题 10:写一个密码校验规则
要求:至少 8 位,包含数字和字母。
js
const reg = /^(?=.*[A-Za-z])(?=.*\d)[A-Za-z\d]{8,}$/;考点:正向先行断言。
题 11:判断是否有连续重复单词
js
const reg = /\b(\w+)\s+\1\b/;
console.log(reg.test('hello hello')); // true考点:反向引用。
题 12:提取价格中的数字,但不包含货币符号
js
const str = '¥99 ¥128';
console.log(str.match(/(?<=¥)\d+/g)); // ['99', '128']考点:后行断言。
题 13:为什么不建议用一条超复杂正则校验所有邮箱?
答案:邮箱规范本身复杂,前端业务多数只需要基础格式校验。超复杂正则可读性差、维护成本高,也不一定覆盖所有合法邮箱。工程上常用:
js
const emailReg = /^[^\s@]+@[^\s@]+\.[^\s@]+$/;后端再做更严格校验或发送验证邮件。
题 14:什么是灾难性回溯?如何避免?
示例:
js
/^(a+)+$/当输入接近匹配但最终失败时,可能触发大量回溯。避免方式:
- 不写不必要的嵌套量词;
- 限制输入长度;
- 用更明确的字符集合;
- 将复杂规则拆成多个简单判断。
题 15:如何匹配 HTML 标签?
面试陷阱:不要试图用一条正则完整解析 HTML。HTML 是嵌套结构,正则不适合完整解析。简单提取可以用正则,可靠解析应使用 DOMParser 或 HTML parser。
js
const parser = new DOMParser();
const doc = parser.parseFromString(html, 'text/html');这道题考的是边界意识,而不是让你写出一条"神级正则"。
题 16:如何删除字符串中所有非数字字符?
js
function onlyNumber(str) {
return str.replace(/\D/g, '');
}
console.log(onlyNumber('a1b2c3')); // 123考点:\D 和全局替换。
题 17:如何判断一个字符串是否全是中文?
js
const reg = /^[\u4e00-\u9fa5]+$/;注意:这只是常用中文范围,不覆盖所有 CJK 扩展字符。业务若涉及多语言姓名,应谨慎设计。
题 18:解释 /a.*?b/ 和 /a.*b/ 的区别
答案:
/a.*b/是贪婪匹配,会尽可能匹配更长内容;/a.*?b/是惰性匹配,会尽可能匹配更短内容,但仍要保证整体成功。
17. 学习路线:从会写到写得稳
建议按这条路线练习:
- 先掌握字符类:
\d、\w、\s、[]; - 再掌握量词:
+、*、?、{n,m}; - 接着理解位置:
^、$、\b; - 然后学习分组:
(),(?:),(?<name>); - 再练
replace回调; - 最后研究断言、回溯、性能和安全。
练习题建议:
- 写手机号校验;
- 写邮箱基础校验;
- 从一段日志里提取时间、等级和错误码;
- 写 kebab-case 到 camelCase;
- 写手机号脱敏;
- 写千分位;
- 写模板引擎;
- 找出一条正则的性能风险。
18. 总结
正则表达式的核心不是背符号,而是理解"规则如何驱动引擎移动"。它像一个文本侦探,从左到右扫描字符串,按规则寻找目标;量词决定它拿多少,分组决定它把什么装进口袋,修饰符决定它找一个还是找全部。
在真实工程中,正则最常见的价值有三类:
- 校验:手机号、邮箱、密码、表单字段;
- 提取:金额、日期、URL 参数、日志信息;
- 转换:命名格式转换、模板渲染、数据脱敏。
但正则不是万能钥匙。遇到复杂嵌套结构、HTML 解析、超严格国际化校验时,不要硬写一条巨型正则。专业工程师的能力不只是"能写正则",还包括知道什么时候不用正则。
把正则写得正确,是入门;把正则写得可读、可维护、性能稳定,才是进阶。