Copilot已经支持非常多的模型,为什么要接入更多的第三方模型
- 因为Github Copilot 在2026年6月开始新的计费策略,导致订阅价格陡峭攀升;
- 习惯了VS Code中使用Copilot的工作方式。
copilot adapter
copilot adapter不是一个独立的AI Agent工具,而是对原生Copilot Chat的增强。
项目开源地址:copilot-adapter
安装扩展
在VS Code扩展商店搜索copilot adapter然后安装或者到marketplace visualstudio页面触发安装。
copilot官方已经支持了Custom Endpoint,为什么还需要安装额外扩展?因为通过Custom Endpoint构建的模型选项无法使用视觉代理和复杂的思考模式选项。
添加模型
内置支持的模型列表: 如需其它模型请参阅自定义模型
| 提供商 | 端点平台 | 模型 |
|---|---|---|
| DeepSeek | platform.deepseek.com |
V4 Pro V4 Flash |
| MiniMax | minimaxi.com minimax.io |
M3 M2.7 M2.7 Highspeed M2.5 M2.5 Highspeed M2.1 M2.1 Highspeed M2 |
| Moonshot (Kimi) | platform.moonshot.cn platform.moonshot.ai |
Kimi K2.7 Code Kimi K2.7 Code High-Speed Kimi K2.6 Kimi K2.5 |
| Qwen | bailian.console.aliyun.com |
Qwen3.7 Max Qwen3.7 Plus Qwen3.6 Max Qwen3.6 Plus Qwen3.6 Flash Qwen3.5 Plus Qwen3.5 Flash Qwen3 Max Qwen3 Coder Plus Qwen3 Coder Flash Qwen Plus (US) Qwen Flash (US) |
| 智谱 (GLM) | open.bigmodel.cn api.z.ai |
GLM-5.2 GLM-5.1 GLM-5 GLM-5-Turbo GLM-4.7 GLM-4.7-FlashX GLM-4.6 GLM-4.5-Air GLM-4.5-AirX GLM-4-Long GLM-4-FlashX-250414 GLM-4.7-Flash GLM-4.5-Flash GLM-4-Flash-250414 GLM-5V-Turbo GLM-4.6V GLM-OCR GLM-4.1V-Thinking-FlashX GLM-4.6V-Flash GLM-4.1V-Thinking-Flash GLM-4V-Flash |
请至各提供商官网注册并获取 API Key。
本文以 DeepSeek 为例,演示通过 VS Code 语言模型面板添加提供商的完整流程------这是官方推荐的原生方式。
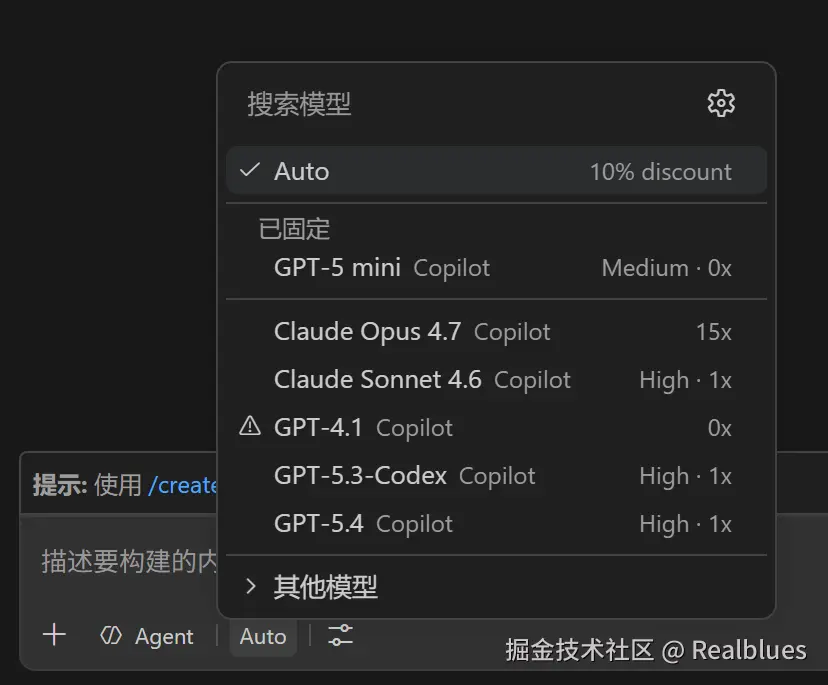
第 1 步 打开 Copilot Chat 的模型选择器
点击 Copilot Chat 输入框底部的模型选择器,可以看到当前可用的模型列表。此时 DeepSeek 和 MiniMax 尚未出现。
第 2 步 打开语言模型面板,点击"添加模型..."
在模型管理面板或通过 Ctrl/Cmd+Shift+P 语言模型 打开语言模型 面板,点击右上角的 + 添加模型...。安装插件后,下拉列表中会出现插件支持的提供商,选择你需要的即可。
** 第 3 步 确认分组名称 **
弹出输入框要求填写分组名称。默认已填入提供商名称,你也可以输入任意喜欢的名字,只要不与已有分组重复即可。确认后按 Enter。

第 4 步 输入 API Endpoint 和 API Key
如果某个 provider 支持多个 endpoint,请先选择或输入 endpoint,如下图所示。
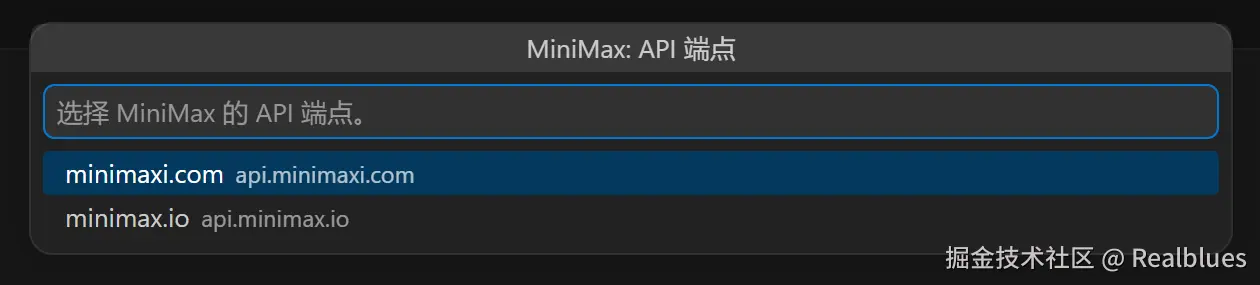
 然后输入以
然后输入以 sk- 开头的 API Key 并按 Enter。Key 会立即存入 VS Code Secret Storage,不会写入磁盘或任何配置文件。
Tip:同一个 provider 支持添加多个 group,但请确保它们的 Group Name 和 API Key 都不相同。
第 5 步 供应商出现在语言模型面板中
语言模型面板中现在显示 DeepSeek 分组,其下列出了两个模型。随时可点击分组名称旁的 ⚙ 图标修改 API Key 或调整配置。
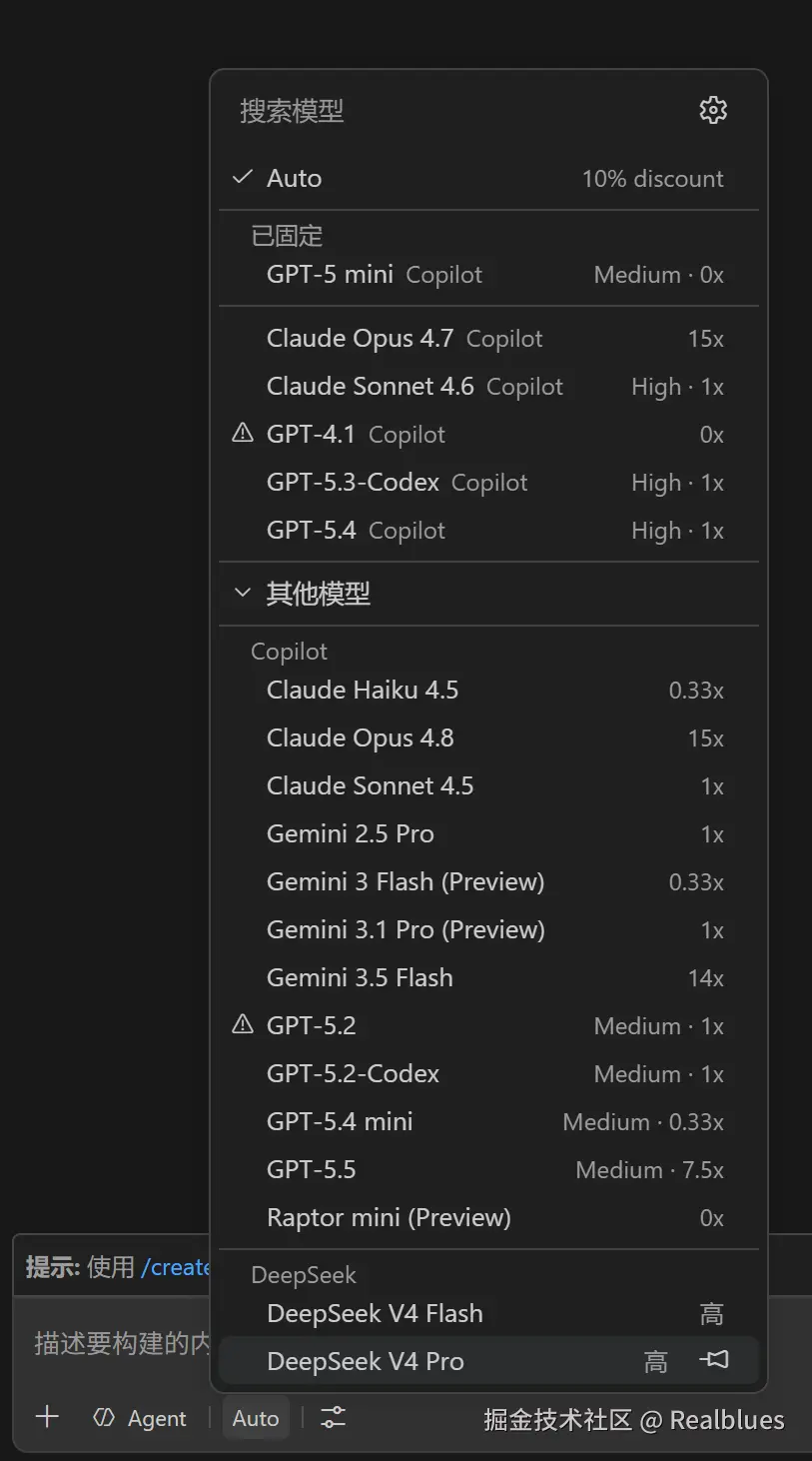
第 6 步 在 Copilot Chat 中使用模型
再次打开 Copilot Chat 的模型选择器,DeepSeek V4 Flash 和 DeepSeek V4 Pro 已出现在其他模型分组下。选择其中一个即可开始对话。
安全性
API Key 仅存储于 VS Code Secret Storage,底层由操作系统凭据管理器保护------macOS 上为 Keychain,Windows 上为 Credential Manager,Linux 上为 libsecret。
- 永远不会写入
settings.json--- Key 作为 Secret 存储,与 VS Code 设置完全隔离,不会通过 Settings Sync 同步,也不会出现在磁盘上的任何配置文件中。 - 不可能被意外提交 --- Key 仅存在于操作系统凭据库中,不存在可被 git 追踪的文件。
- 零运行时依赖 --- 扩展在运行时没有任何第三方库依赖或外部服务依赖,所有网络通信均使用 VS Code 内置的 HTTP 设施。
功能特性
思考模式
推理模型(DeepSeek V4 系列、MiniMax M 系列、Qwen3、GLM、Kimi K2)支持配置推理深度,可在 Language Models 面板的模型设置中调整:
| 级别 | 说明 |
|---|---|
| None(无) | 不进行推理步骤,输出最快 |
| High(高) | 均衡深度,适合日常编程任务 |
| Max(最大) | 全力推理,适合复杂问题 |
以上级别以 DeepSeek V4 为例;不同提供商的选项名称可能不同。
视觉代理
纯文本模型无法直接处理图片附件。配置视觉代理后,扩展会自动使用一个具备视觉能力的模型描述附件图片,并将描述以文本形式注入上下文,从而让纯文本模型也能无缝处理图片输入。
通过命令 Copilot Adapter: Set Vision Proxy Model 或设置项 copilot-adapter.visionProxyModel 进行配置。
将值设为 off 即可随时禁用。
前缀缓存命中率
扩展会调整连续对话中消息的顺序,优先将可以被缓存的内容放在前面,以提升支持前缀缓存和主动缓存的模型(DeepSeek、Qwen、Zhipu)的缓存命中率。在日志级别为 info 或更高时,输出频道中会记录每次请求的缓存命中详情:
yaml
model: deepseek-v4-pro, tokens: prompt=18576 reasoning=40 completion=57, cache: hit=12160 miss=6516 rate=65%上下文窗口计算
扩展会为每次请求向 VS Code 上报 Token 用量,具体策略分为两种:
-
API 返回用量 (DeepSeek、Qwen、Zhipu、Moonshot)------ 模型在流式响应中返回精确的
prompt_tokens和completion_tokens。这是主要路径,无需估算。 -
降级估算(MiniMax 等不返回流式用量的提供商)------ 当 API 未包含用量数据时,扩展通过请求和响应文本的字符数估算 Token 用量。日志中会标明降级模式:
yamlUsing fallback usage estimation (API returned no usage data) --- prompt chars: 15234, response chars: 487
动态比例校准
provideTokenCount(VS Code 的上下文窗口计算)使用的字符/Token 比例初始为 4.0,会根据每次 API 返回的真实用量自动校准。每次返回精确用量的请求都会用 EMA 平滑方式(旧值 80%、新值 20%)更新比例。为避免噪声,仅当变化 ≥ 10% 时才会存储:
vbnet
Chars-per-token ratio calibrated for deepseek: 4.00 to 3.38 (based on API usage: 63200 chars / 18703 tokens)无法获取精确用量的提供商(如 MiniMax)保持静态默认比例。
自定义模型
自定义模型的功能提供了可以自行配置不在内置模型列表的模型
VS Code Copilot Chat 官方的 Custom Endpoint 仅支持基础的模型配置(名称、端点、API Key),无法使用视觉代理、定制化思考模式和缓存命中率日志。Copilot Adapter 的 Custom Models 填补了这些缺口:
- 视觉代理 --- 纯文本模型也能通过自动视觉代理管线处理图片附件。
- 可定制的思考模式 --- 针对不同厂商的请求体格式(DeepSeek、Qwen、Anthropic 等)配置各模型的推理强度,在模型选择器中即可切换。
- 缓存命中率日志 --- 在输出频道中查看每次请求的前缀缓存命中/未命中率。
通过在配置文件中定义元数据(名称、端点、能力、token 限制),可将任意兼容 OpenAI 接口的模型接入 Copilot Chat。思考模型("thinking": true)会根据模型 ID 自动匹配预置的推理强度配置,同时支持完整自定义。
详细图文教程请参阅(如何添加自定义模型)涵盖 DeepSeek、OpenAI、Anthropic、通义千问、智谱、MiniMax、Gemini、Grok 等的即用型模板见 custom-models-template)。
实测的缓存命中率